
Monitoring of Inland Excess Water Inundations Using Machine Learning Algorithms

Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Methodology
2.3. Validation
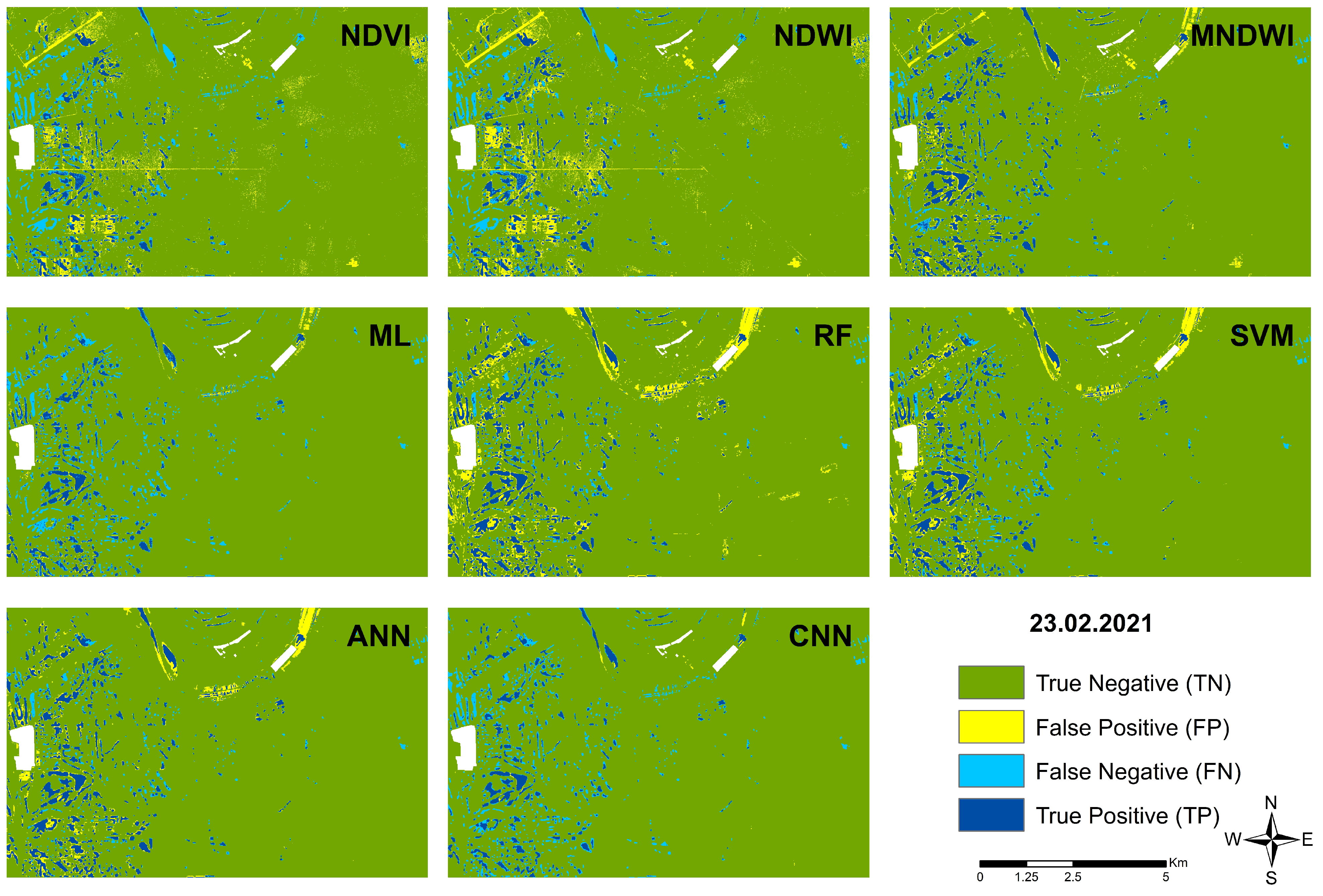
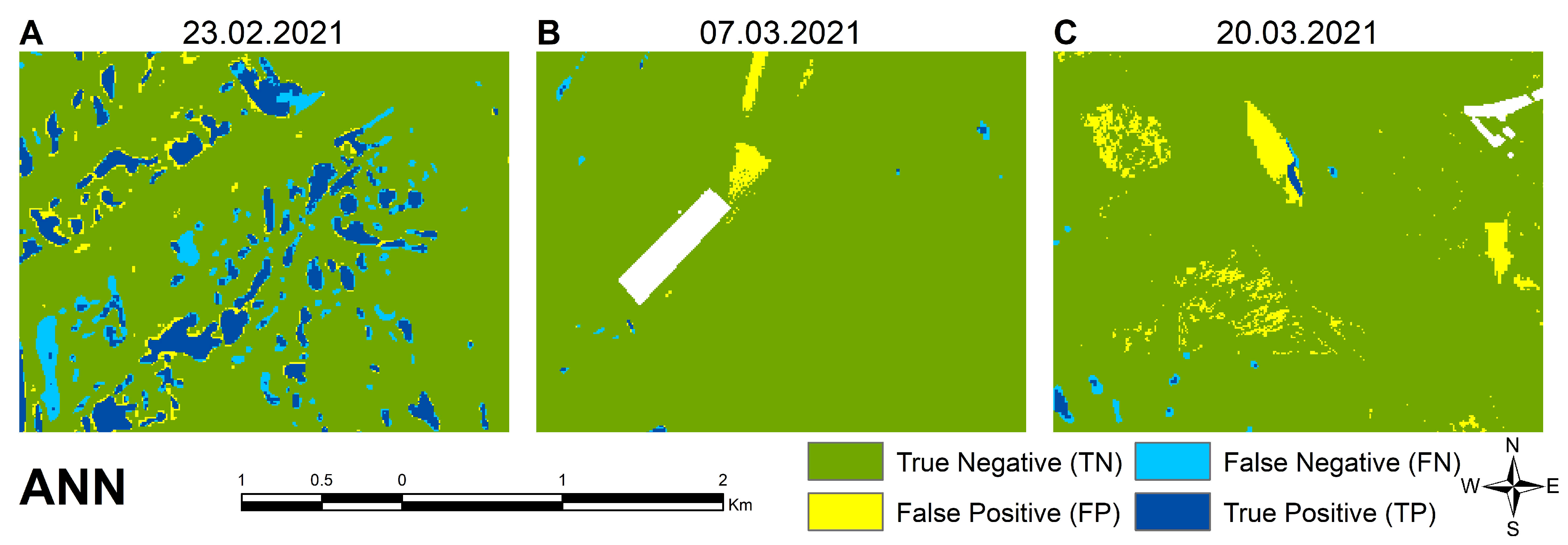
3. Results
- TN (True Negative–dark green): areas where no water was identified on the reference map and the model-generated map;
- TP (True Positive–dark blue): where water has been identified on the reference map and by the model;
- FP (False Positive–yellow): where no water was identified in the reference map, but the model identified water:
- FN (False Negative–light blue): where water was identified in the reference map but not by the model.
3.1. Results of the Total Study Area
3.2. Detailed Analyis of Classiciation Methods
3.3. Validation Results
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Van Leeuwen, B.; Tobak, Z.; Kovács, F. Sentinel-1 and -2 Based near Real Time Inland Excess Water Mapping for Optimized Water Management. Sustainability 2020, 12, 2854. [Google Scholar] [CrossRef] [Green Version]
- Pálfai, I. Definitions of inland excess waters. Vízü. Közl. 2001, 83, 376–392. (In Hungarian) [Google Scholar]
- Lászlóffy, W. The Tisza: Water Works and Watermanagement in the Tisza Water System; Akadémiai Kiadó Zrinyi: Budapest, Hungary, 1982; 609p. (In Hungarian) [Google Scholar]
- Rakonczai, J.; Farsang, A.; Mezősi, G.; Gál, N. Conceptual background to the formation of inland excess water. Földr. Közl. 2011, 35, 339–350. (In Hungarian) [Google Scholar]
- Rakonczai, J.; Bódis, K. Application of Geoinformatics to the Quantitative Assessment of Environmental Change; Magyar Földrajzi Konferencia kiadványa: Budapest, Hungary, 2001. (In Hungarian) [Google Scholar]
- Kozák, P. The Evaluation of Inland Excess Water on the Hungarian Lowland’s South-East Part, in the Framework of European Water Management. Ph.D. Thesis, University of Szeged, Szeged, Hungary, 2006; p. 86. Available online: https://doktori.bibl.u-szeged.hu/id/eprint/1679/3/Disszert%C3%A1ci%C3%B3.pdf (accessed on 15 November 2022). (In Hungarian).
- Salamin, P. Study on domestic inland excess water management. Hidrológiai Közlöny 1942, 1–6, 85. (In Hungarian) [Google Scholar]
- Szatmári, J.; Van Leeuwen, B. Inland Excess Water—Belvíz—Suvišne Unutrašnje Vode; Szegedi Tudományegyetem: Szeged, Hungary; Újvidéki Egyetem: Újvidék, Srbija, 2013; p. 154. [Google Scholar]
- Kuti, L.; Kerék, B.; Vatai, J. Problem and prognosis of excess water inundation based on agrogeological factors. Carpth. J. Earth Environ. Sci. 2006, 1, 5–18. [Google Scholar]
- Wallender, W.W.; Tanji, K.K. Agricultural Salinity Assessment and Management; American Society of Civil Engineers (ASCE): Reston, VA, USA, 2011. [Google Scholar] [CrossRef]
- Asselman, N.E.M.; Middelkoop, H. Floodplain sedimentation: Quantities, patterns and processes. Earth Surf. Process. Landf. 1995, 20, 481–499. [Google Scholar] [CrossRef]
- Yeung, E.; van Veen, H.; Vashisht, D.; Paiva, A.L.S.; Hummel, M.; Rankenberg, T.; Steffens, B.; Steffen-Heins, A.; Sauter, M.; de Vries, M.; et al. A stress recovery signaling network for enhanced flooding tolerance inArabidopsis thaliana. Proc. Natl. Acad. Sci. USA 2018, 115, E6085–E6094. [Google Scholar] [CrossRef] [Green Version]
- Fukao, T.; Barrera-Figueroa, B.E.; Juntawong, P.; Peña-Castro, J.M. Submergence and Waterlogging Stress in Plants: A Review Highlighting Research Opportunities and Understudied Aspects. Front. Plant Sci. 2019, 10, 340. [Google Scholar] [CrossRef]
- Besten, N.D.; Steele-Dunne, S.; de Jeu, R.; van der Zaag, P. Towards Monitoring Waterlogging with Remote Sensing for Sustainable Irrigated Agriculture. Remote Sens. 2021, 13, 2929. [Google Scholar] [CrossRef]
- Houk, E.; Frasier, M.; Schuck, E. The agricultural impacts of irrigation induced waterlogging and soil salinity in the Arkansas Basin. Agric. Water Manag. 2006, 85, 175–183. [Google Scholar] [CrossRef]
- Valipour, M. Drainage, waterlogging, and salinity. Arch. Agron. Soil Sci. 2014, 60, 1625–1640. [Google Scholar] [CrossRef]
- Hassan, M.S.; Mahmud-ul-islam, S. Detection of Water-logging Areas Based on Passive Remote Sensing Data in Jessore District of Khulna Division, Bangladesh. Int. J. Sci. Res. Publ. 2014, 4, 702–708. [Google Scholar]
- Mezösi, G.; Meyer, B.C.; Loibl, W.; Aubrecht, C.; Csorba, P.; Bata, T. Assessment of regional climate change impacts on Hungarian landscapes. Reg. Environ. Chang. 2012, 13, 797–811. [Google Scholar] [CrossRef]
- Joseph, L.A.; Kiema, K.; John, B. Environmental Science and Engineering. In Environmental Geoinformatics, Image Interpretation and Analysis; Prentice Hall: Hoboken, NJ, USA, 2013; Chapter 10; pp. 145–155. [Google Scholar] [CrossRef]
- Bozán, C.; Takács, K.; Körösparti, J.; Laborczi, A.; Túri, N.; Pásztor, L. Integrated spatial assessment of inland excess water hazard on the Great Hungarian Plain. Land Degrad. Dev. 2018, 29, 4373–4386. [Google Scholar] [CrossRef]
- Túri, N.; Körösparti, J.; Kajári, B.; Kerezsi, G.; Zain, M.; Rakonczai, J.; Bozán, C. Spatial assessment of the inland excess water presence on subsurface drained areas in the Körös Interfluve (Hungary). Agrokémia Talajt. 2022, 71, 23–42. [Google Scholar] [CrossRef]
- Spanoudaki, K.; Stamou, A.I.; Nanou-Giannarou, A. Development and verification of a 3-D integrated surface water–groundwater model. J. Hydrol. 2009, 375, 410–427. [Google Scholar] [CrossRef]
- Graham, N.D.; Refsgaard, A. MIKE SHE: A distributed, physically based modelling system for surface water/groundwater interactions. In Proceedings of the Modflow 2001 and Other Modeling Odysseys-Conference Proceedings 2001, Fort Collins, CO, USA, 11–14 September 2001; pp. 321–327. [Google Scholar]
- Restrepo, J.I.; Montoya, A.M.; Obeysekera, J. A Wetland Simulation Module for the MODFLOW Ground Water Model. Groundwater 1998, 36, 764–770. [Google Scholar] [CrossRef]
- Slagter, B.; Tsendbazar, N.-E.; Vollrath, A.; Reiche, J. Mapping wetland characteristics using temporally dense Sentinel-1 and Sentinel-2 data: A case study in the St. Lucia wetlands, South Africa. Int. J. Appl. Earth Obs. Geoinf. 2020, 86, 102009. [Google Scholar] [CrossRef]
- Hird, J.N.; DeLancey, E.R.; McDermid, G.J.; Kariyeva, J. Google Earth Engine, Open-Access Satellite Data, and Machine Learning in Support of Large-Area Probabilistic Wetland Mapping. Remote. Sens. 2017, 9, 1315. [Google Scholar] [CrossRef] [Green Version]
- Kozma, Z.; Jolánkai, Z.; Kardos, M.K.; Muzelák, B.; Koncsos, L. Adaptive Water Management-land Use Practice for Improving Ecosystem Services—A Hungarian Modelling Case Study. Period. Polytech. Civ. Eng. 2022, 66, 256–268. [Google Scholar] [CrossRef]
- Kriegler, F.; Malila, W.; Nalepka, R.; Richardson, W. Preprocessing transformations and their effect on multispectral recognition. In Proceedings of the 6th International Symposium on Remote Sensing of Environment 1969, Ann Arbor, MI, USA, 13–16 October 1969; pp. 97–131. [Google Scholar]
- Rouse, J.W.; Haas, R.H.; Schell, J.A.; Deering, D.W. Monitoring Vegetation Systems in the Great Plains with ERTS (Earth Resources Technology Satellite). In Proceedings of the 3rd Earth Resources Technology Satellite Symposium 1973, Greenbelt, Philippines, 10–14 December 1973; SP-351. pp. 309–317. [Google Scholar]
- Huang, S.; Tang, L.; Hupy, J.P.; Wang, Y.; Shao, G.F. A commentary review on the use of normalized difference vegetation index (NDVI) in the era of popular remote sensing. J. For. Res. 2021, 32, 1–6. [Google Scholar] [CrossRef]
- McFeeters, S.K. The use of the Normalized Difference Water Index (NDWI) in the delineation of open water features. Int. J. Remote Sens. 1996, 17, 1425–1432. [Google Scholar] [CrossRef]
- Xu, H. Modification of normalised difference water index (NDWI) to enhance open water features in remotely sensed imagery. Int. J. Remote Sens. 2006, 27, 3025–3033. [Google Scholar] [CrossRef]
- Du, Y.; Zhang, Y.; Ling, F.; Wang, Q.; Li, W.; Li, X. Water Bodies’ Mapping from Sentinel-2 Imagery with Modified Normalized Difference Water Index at 10-m Spatial Resolution Produced by Sharpening the SWIR Band. Remote Sens. 2016, 8, 354. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Statistical Challenges in Astronomy. Random For. Find. Quasars 2003, 16, 243–254. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Mahdavi, S.; Salehi, B.; Granger, J.; Amani, M.; Brisco, B.; Huang, W. Remote sensing for wetland classification: A comprehensive review. GISci. Remote Sens. 2018, 55, 623–658. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Sheykhmousa, M.; Mahdianpari, M.; Ghanbari, H.; Mohammadimanesh, F.; Ghamisi, P.; Homayouni, S. Support Vector Machine Versus Random Forest for Remote Sensing Image Classification: A Meta-Analysis and Systematic Review. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2020, 13, 6308–6325. [Google Scholar] [CrossRef]
- Richards, J.; Jia, X. Remote Sensing Digital Image Analysis, 4th ed.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 359–388. [Google Scholar]
- Szabó, L.; Deák, M.; Szabó, S. Comparative analysis of Landsat TM, ETM+, OLI and EO-1 ALI satellite images at the Tisza-tó area, Hungary. Landsc. Environ. 2016, 10, 53–62. [Google Scholar] [CrossRef]
- Sisodia, P.S.; Tiwari, V.; Kumar, A. Analysis of Supervised Maximum Likelihood Classification for remote sensing image. International Conference on Recent Advances and Innovations in Engineering (ICRAIE-2014), Jaipur, India, 9–11 May 2014; pp. 1–4. [Google Scholar] [CrossRef]
- Molnár, V.; Simon, E.; Szabó, S. Species-level classification of urban trees from worldview-2 imagery in Debrecen, Hungary: An effective tool for planning a comprehensive green network to reduce dust pollution. Eur. J. Geogr. 2020, 11, 33–46. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Graupe, D. Principles of Artificial Neural Networks, 3rd ed.; World Scientific Publishing Company: Singapore; University of Illinois: Chicago, IL, USA, 2013; p. 384. [Google Scholar] [CrossRef]
- Jiang, W.; He, G.; Long, T.; Ni, Y.; Liu, H.; Peng, Y.; Lv, K.; Wang, G. Multilayer Perceptron Neural Network for Surface Water Extraction in Landsat 8 OLI Satellite Images. Remote Sens. 2018, 10, 755. [Google Scholar] [CrossRef] [Green Version]
- Devi, M.S.; Chib, S. Classification of Satellite Images Using Perceptron Neural Network. Int. J. Comput. Intell. Res. 2019, 15, 1–10. [Google Scholar]
- Bravo-López, E.; Del Castillo, T.F.; Sellers, C.; Delgado-García, J. Landslide Susceptibility Mapping of Landslides with Artificial Neural Networks: Multi-Approach Analysis of Backpropagation Algorithm Applying the Neuralnet Package in Cuenca, Ecuador. Remote. Sens. 2022, 14, 3495. [Google Scholar] [CrossRef]
- Pritt, M.; Chern, G. Satellite Image Classification with Deep Learning. In Proceedings of the 2017 IEEE Applied Imagery Pattern Recognition Workshop (AIPR), Washington, DC, USA, 10–12 October 2017; pp. 1–7. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; The MIT Press: Cambridge, MA, USA, 2016; 800p, Available online: http://www.deeplearningbook.org (accessed on 15 November 2022).
- Sánchez, A.-M.S.; González-Piqueras, J.; de la Ossa, L.; Calera, A. Convolutional Neural Networks for Agricultural Land Use Classification from Sentinel-2 Image Time Series. Remote Sens. 2022, 14, 5373. [Google Scholar] [CrossRef]
- James, T.; Schillaci, C.; Lipani, A. Convolutional neural networks for water segmentation using sentinel-2 red, green, blue (RGB) composites and derived spectral indices. Int. J. Remote. Sens. 2021, 42, 5338–5365. [Google Scholar] [CrossRef]
- Corbane, C.; Syrris, V.; Sabo, F.; Politis, P.; Melchiorri, M.; Pesaresi, M.; Soille, P.; Kemper, T. Convolutional neural networks for global human settlements mapping from Sentinel-2 satellite imagery. Neural Comput. Appl. 2020, 33, 6697–6720. [Google Scholar] [CrossRef]
- Drusch, M.; Del Bello, U.; Carlier, S.; Colin, O.; Fernandez, V.; Gascon, F.; Meygret, A. Sentinel-2: ESA’s optical high-resolution mission for GMES operational services. Remote Sens. Environ. 2012, 120, 25–36. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: https://arxiv.org/pdf/1603.04467.pdf (accessed on 15 November 2022).
- Chollet, F. Keras. 2015. Available online: https://github.com/fchollet/keras (accessed on 15 November 2022).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. Cornell University. 2019. Available online: https://arxiv.org/pdf/1912.01703v1.pdf (accessed on 15 November 2022).
- Howard, J.; Gugger, S. Fastai: A Layered API for Deep Learning. Information 2020, 11, 108. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Navab, N., Hornegger, J., Wells, W., Frangi, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2015; Volume 9351. [Google Scholar] [CrossRef] [Green Version]
- Feizizadeh, B.; Darabi, S.; Blaschke, T.; Lakes, T. QADI as a New Method and Alternative to Kappa for Accuracy Assessment of Remote Sensing-Based Image Classification. Sensors 2022, 22, 4506. [Google Scholar] [CrossRef] [PubMed]
- Maksimovic, V.; Lekic, P.; Petrovic, M.; Jaksic, B.; Spalevic, P. Experimental analysis of wavelet decomposition on edge detection. Proc. Est. Acad. Sci. 2019, 68, 284. [Google Scholar] [CrossRef]
- Wen, Z.; Zhang, C.; Shao, G.; Wu, S.; Atkinson, P.M. Ensembles of multiple spectral water indices for improving surface water classification. Int. J. Appl. Earth Obs. Geoinf. 2020, 96, 102278. [Google Scholar] [CrossRef]
- Mahdianpari, M.; Rezaee, M.; Zhang, Y.; Salehi, B. Wetland Classification Using Deep Convolutional Neural Network. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018. [Google Scholar] [CrossRef]
- Hagolle, O.; Huc, M.; Desjardins, C.; Auer, S.; Richter, R. MAJA Algorithm Theoretical Basis Document; Zenodo: Geneve, Switzerland, 2017. [Google Scholar] [CrossRef]
- Frantz, D.; Haß, E.; Uhl, A.; Stoffels, J.; Hill, J. Improvement of the Fmask algorithm for Sentinel-2 images: Separating clouds from bright surfaces based on parallax effects. Remote. Sens. Environ. 2018, 215, 471–481. [Google Scholar] [CrossRef]
- Parajuli, J.; Fernandez-Beltran, R.; Kang, J.; Pla, F. Attentional Dense Convolutional Neural Network for Water Body Extraction From Sentinel-2 Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2022, 15, 6804–6816. [Google Scholar] [CrossRef]
- Mucsi, L.; Henits, L. Creating excess water inundation maps by sub-pixel classification of medium resolution satellite images. J. Environ. Geogr. 2010, 3, 31–40. [Google Scholar] [CrossRef]
- Balázs, B.; Bíró, T.; Dyke, G.; Singh, S.K.; Szabó, S. Extracting water-related features using reflectance data and principal component analysis of Landsat images. Hydrol. Sci. J. 2018, 63, 269–284. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 23 February 2021 | ||||||||
|---|---|---|---|---|---|---|---|---|
| NDVI | NDWI | MNDWI | ML | RF | SVM | ANN | CNN | |
| TN | 734,684 | 726,729 | 742,485 | 755,355 | 726,584 | 738,619 | 740,276 | 758,902 |
| FP | 25,519 | 33,471 | 17,715 | 4845 | 33,616 | 21,581 | 19,924 | 1298 |
| FN | 27,607 | 24,131 | 15,278 | 28,099 | 11,965 | 15,262 | 13,359 | 30,437 |
| TP | 24,921 | 28,397 | 37,250 | 24,429 | 40,563 | 37,266 | 39,169 | 22,091 |
| OA | 0.93 | 0.93 | 0.96 | 0.96 | 0.94 | 0.95 | 0.96 | 0.96 |
| Sensitivity | 0.47 | 0.54 | 0.71 | 0.47 | 0.77 | 0.71 | 0.75 | 0.42 |
| Precision | 0.49 | 0.46 | 0.68 | 0.83 | 0.55 | 0.63 | 0.66 | 0.94 |
| Kappa | 0.45 | 0.46 | 0.67 | 0.58 | 0.61 | 0.64 | 0.68 | 0.56 |
| QADI | 0.063 | 0.060 | 0.038 | 0.031 | 0.040 | 0.038 | 0.034 | 0.036 |
| 7 March 2021 | ||||||||
|---|---|---|---|---|---|---|---|---|
| NDVI | NDWI | MNDWI | ML | RF | SVM | ANN | CNN | |
| TN | 779,223 | 759,835 | 780,620 | 784,139 | 785,293 | 658,481 | 777,756 | 785,208 |
| FP | 7317 | 26,705 | 5920 | 2401 | 1247 | 127,059 | 8784 | 1332 |
| FN | 6882 | 8788 | 8380 | 14,655 | 12,412 | 4316 | 7682 | 12,653 |
| TP | 19,174 | 17,268 | 17,676 | 11,401 | 13,644 | 21,740 | 18,374 | 13,403 |
| OA | 0.98 | 0.96 | 0.98 | 0.98 | 0.98 | 0.84 | 0.98 | 0.98 |
| Sensitivity | 0.74 | 0.66 | 0.68 | 0.44 | 0.52 | 0.83 | 0.71 | 0.51 |
| Precision | 0.72 | 0.39 | 0.75 | 0.83 | 0.92 | 0.15 | 0.68 | 0.91 |
| Kappa | 0.72 | 0.47 | 0.70 | 0.56 | 0.66 | 0.21 | 0.68 | 0.65 |
| QADI | 0.023 | 0.031 | 0.015 | 0.016 | 0.014 | 0.152 | 0.019 | 0.014 |
| 20 March 2021 | ||||||||
|---|---|---|---|---|---|---|---|---|
| NDVI | NDWI | MNDWI | ML | RF | SVM | ANN | CNN | |
| TN | 774,311 | 741,398 | 781,403 | 787,527 | 595,276 | 682,714 | 779,740 | 787,458 |
| FP | 14,637 | 47,550 | 7545 | 1421 | 193,672 | 106,234 | 9208 | 1490 |
| FN | 2556 | 4368 | 7080 | 11,576 | 3920 | 4498 | 7972 | 9289 |
| TP | 15,802 | 13,990 | 11,278 | 6782 | 14,438 | 13,860 | 10,386 | 9069 |
| OA | 0.98 | 0.94 | 0.98 | 0.98 | 0.76 | 0.86 | 0.98 | 0.99 |
| Sensitivity | 0.86 | 0.76 | 0.61 | 0.37 | 0.79 | 0.75 | 0.57 | 0.49 |
| Precision | 0.52 | 0.23 | 0.60 | 0.83 | 0.07 | 0.12 | 0.53 | 0.86 |
| Kappa | 0.64 | 0.33 | 0.60 | 0.50 | 0.09 | 0.17 | 0.54 | 0.62 |
| QADI | 0.016 | 0.055 | 0.018 | 0.013 | 0.235 | 0.127 | 0.020 | 0.010 |
| NDVI | NDWI | MNDWI | ML | RF | SVM | ANN | CNN | |
|---|---|---|---|---|---|---|---|---|
| OA average | 0.97 | 0.94 | 0.97 | 0.97 | 0.89 | 0.89 | 0.97 | 0.98 |
| Kappa average | 0.60 | 0.42 | 0.66 | 0.55 | 0.45 | 0.34 | 0.63 | 0.61 |
| Precision average | 0.58 | 0.36 | 0.68 | 0.83 | 0.51 | 0.30 | 0.62 | 0.90 |
| QADI average | 0.032 | 0.049 | 0.023 | 0.020 | 0.096 | 0.105 | 0.024 | 0.020 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kajári, B.; Bozán, C.; Van Leeuwen, B. Monitoring of Inland Excess Water Inundations Using Machine Learning Algorithms. Land 2023, 12, 36. https://doi.org/10.3390/land12010036
Kajári B, Bozán C, Van Leeuwen B. Monitoring of Inland Excess Water Inundations Using Machine Learning Algorithms. Land. 2023; 12(1):36. https://doi.org/10.3390/land12010036
Chicago/Turabian StyleKajári, Balázs, Csaba Bozán, and Boudewijn Van Leeuwen. 2023. "Monitoring of Inland Excess Water Inundations Using Machine Learning Algorithms" Land 12, no. 1: 36. https://doi.org/10.3390/land12010036
APA StyleKajári, B., Bozán, C., & Van Leeuwen, B. (2023). Monitoring of Inland Excess Water Inundations Using Machine Learning Algorithms. Land, 12(1), 36. https://doi.org/10.3390/land12010036