Exposing Video Compression History by Detecting Transcoded HEVC Videos from AVC Coding


Abstract
:1. Introduction
2. Analysis of HEVC Footprints
2.1. High-Efficiency Video Coding
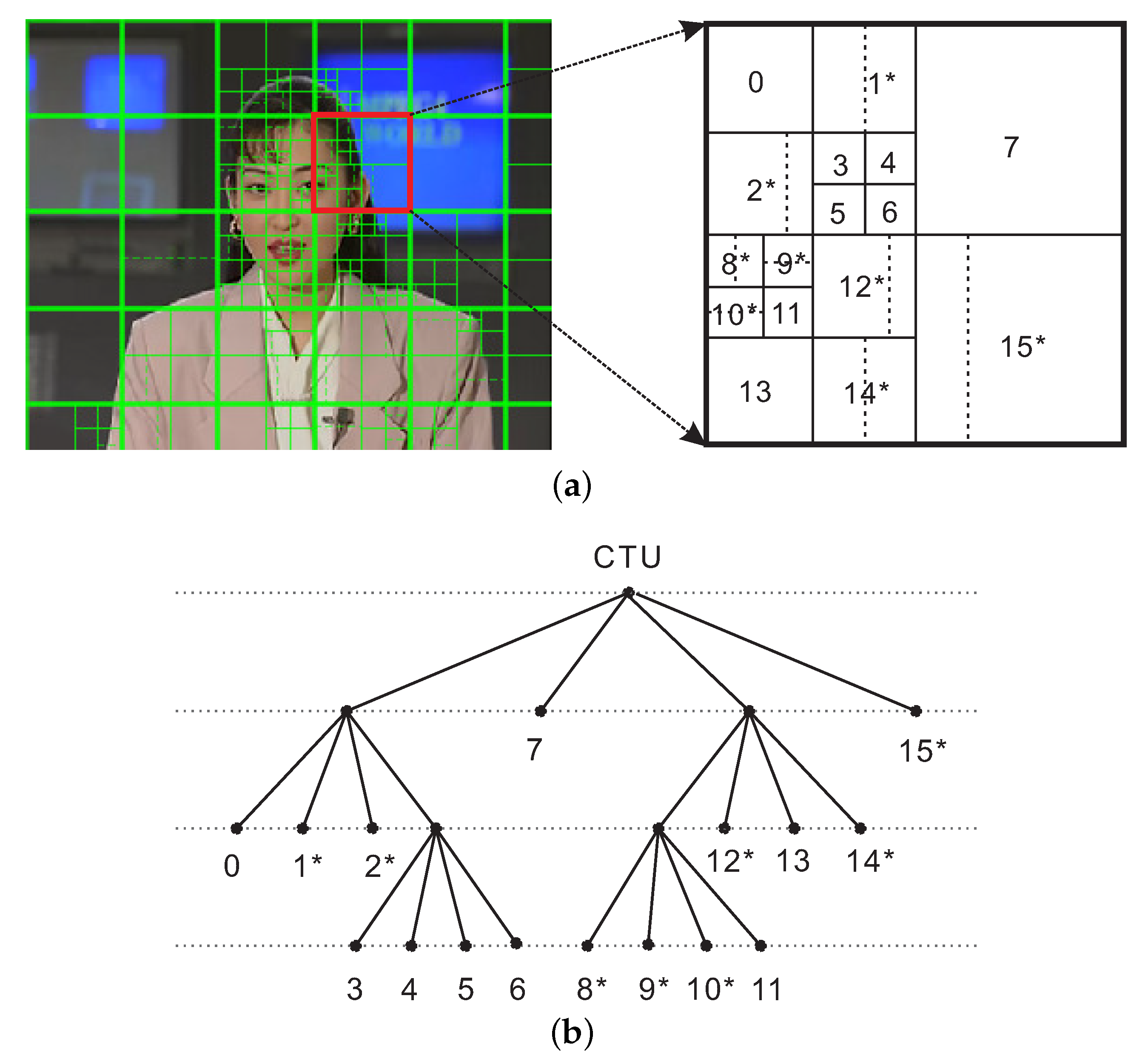
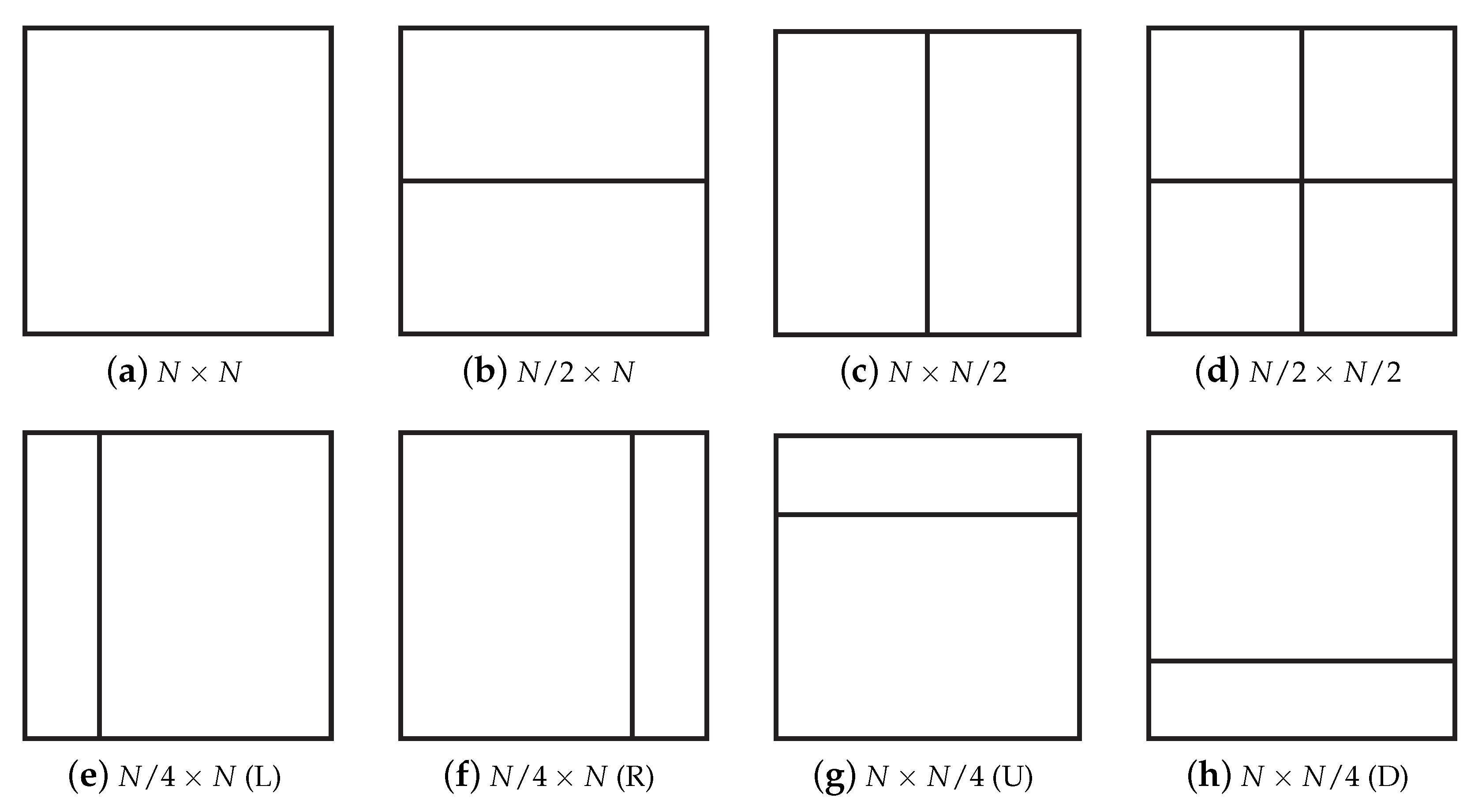
2.2. CU and PU Partition
2.3. Footprints of HEVC
2.4. Footprint Analysis
3. Proposed Method
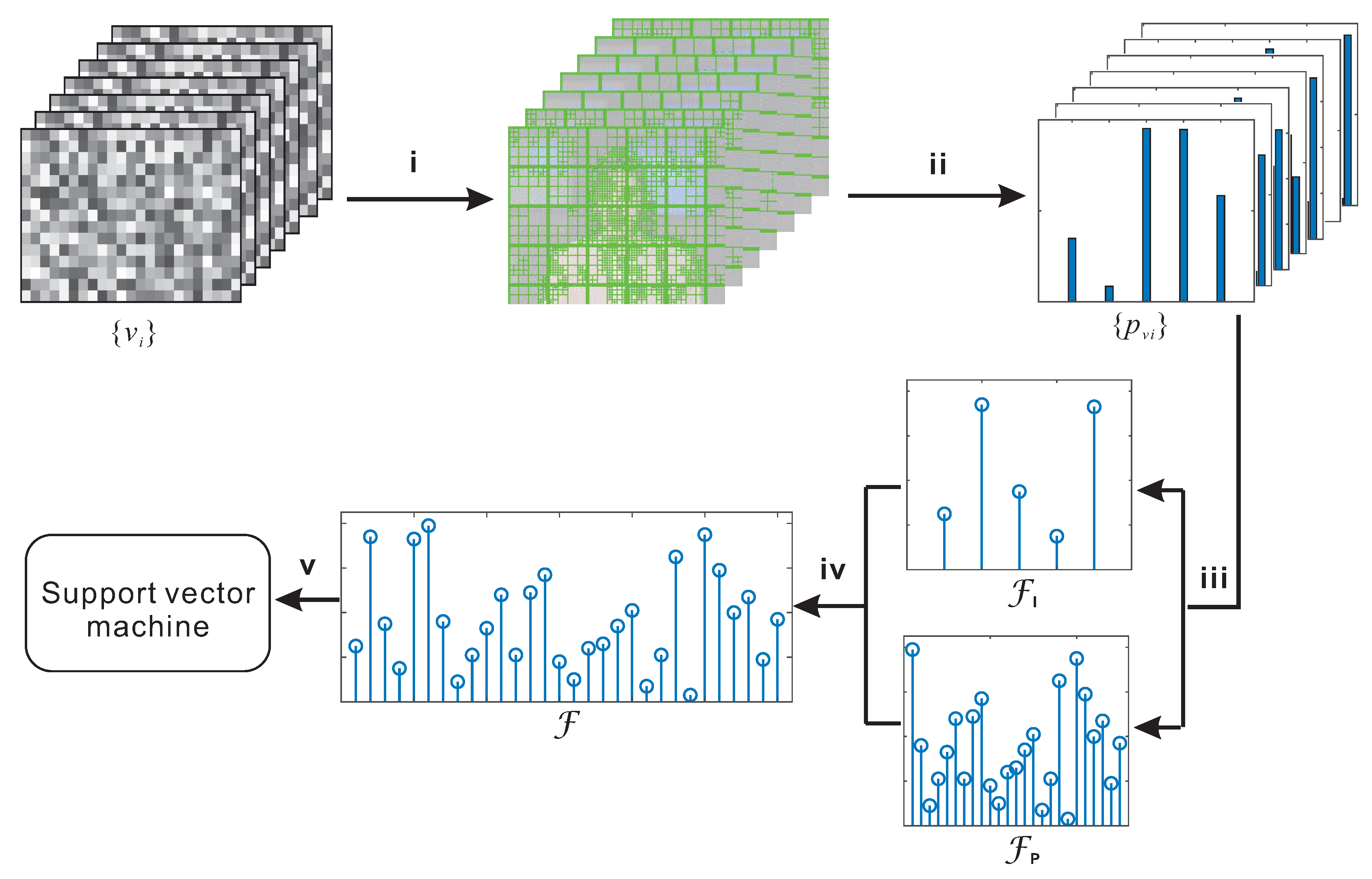
3.1. Feature Extraction
3.2. Detection Method
- Step i.
- Assuming a given HEVC video , firstly decode it, and parse the bitstream for each frame to obtain the data of PU partitions.
- Step ii.
- For each frame , calculate the frequencies of PUs depending on the frame type denoted as . In I frames, five sizes of PUs are taken into account, while in P frames, twenty-five sorts of PUs are calculated. Please note that we only count once for a PU split to prevent double counting. For example, we only count once for PU of in size when a root CU is split into two PUs of and in size.
- Step iii.
- Divide frames of into the set of I frames and the set of P frames . Then, compute the mean of for and , respectively, denoted as and . These two feature sets are 5D and 25D, respectively.
- Step iv.
- Combine and as feature vector of 30D.
- Step v.
- The 30D feature vector is fed to a pre-trained classifier (support vector machine) for identification.
4. Experimental Results
4.1. Experiment Setup
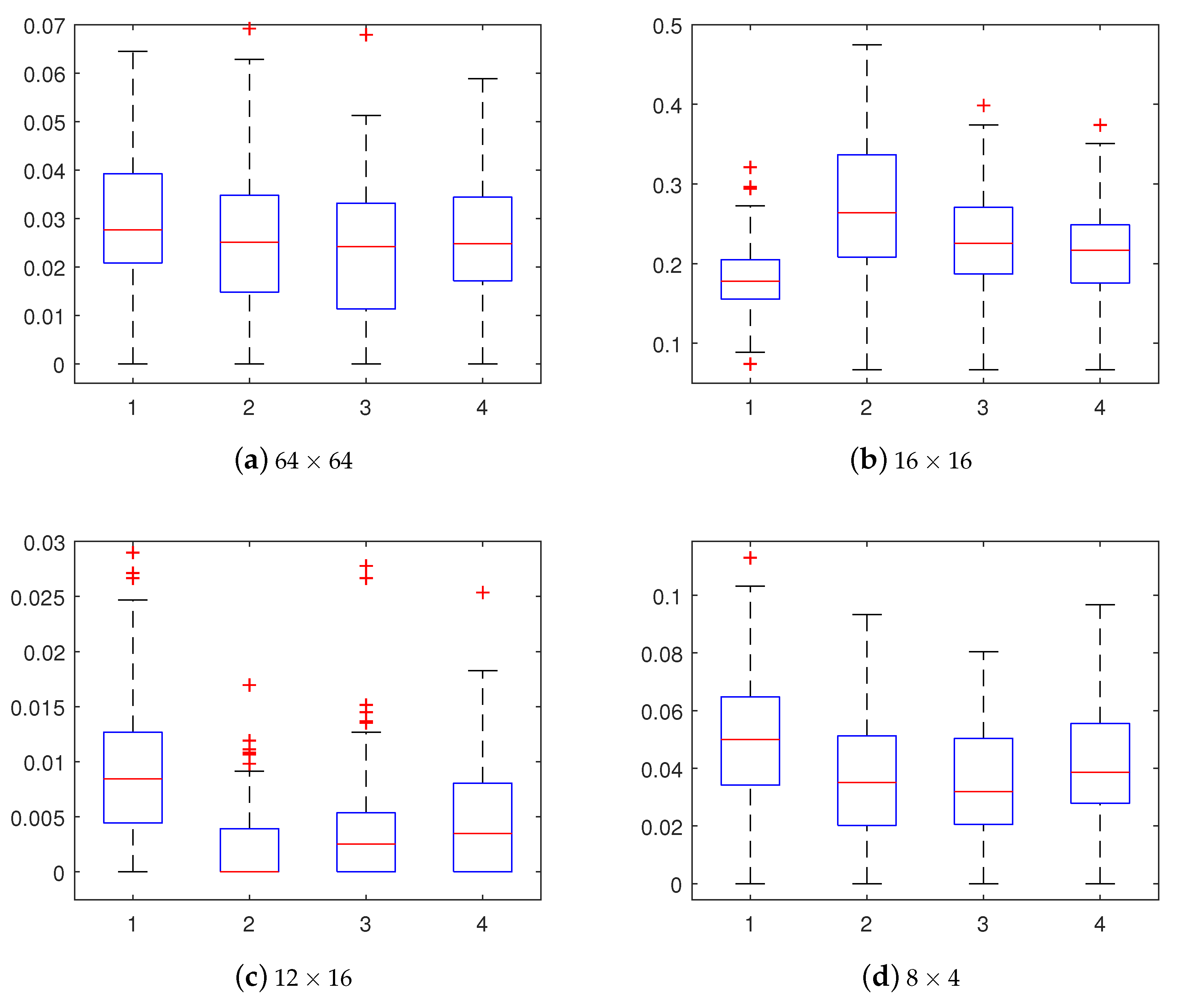
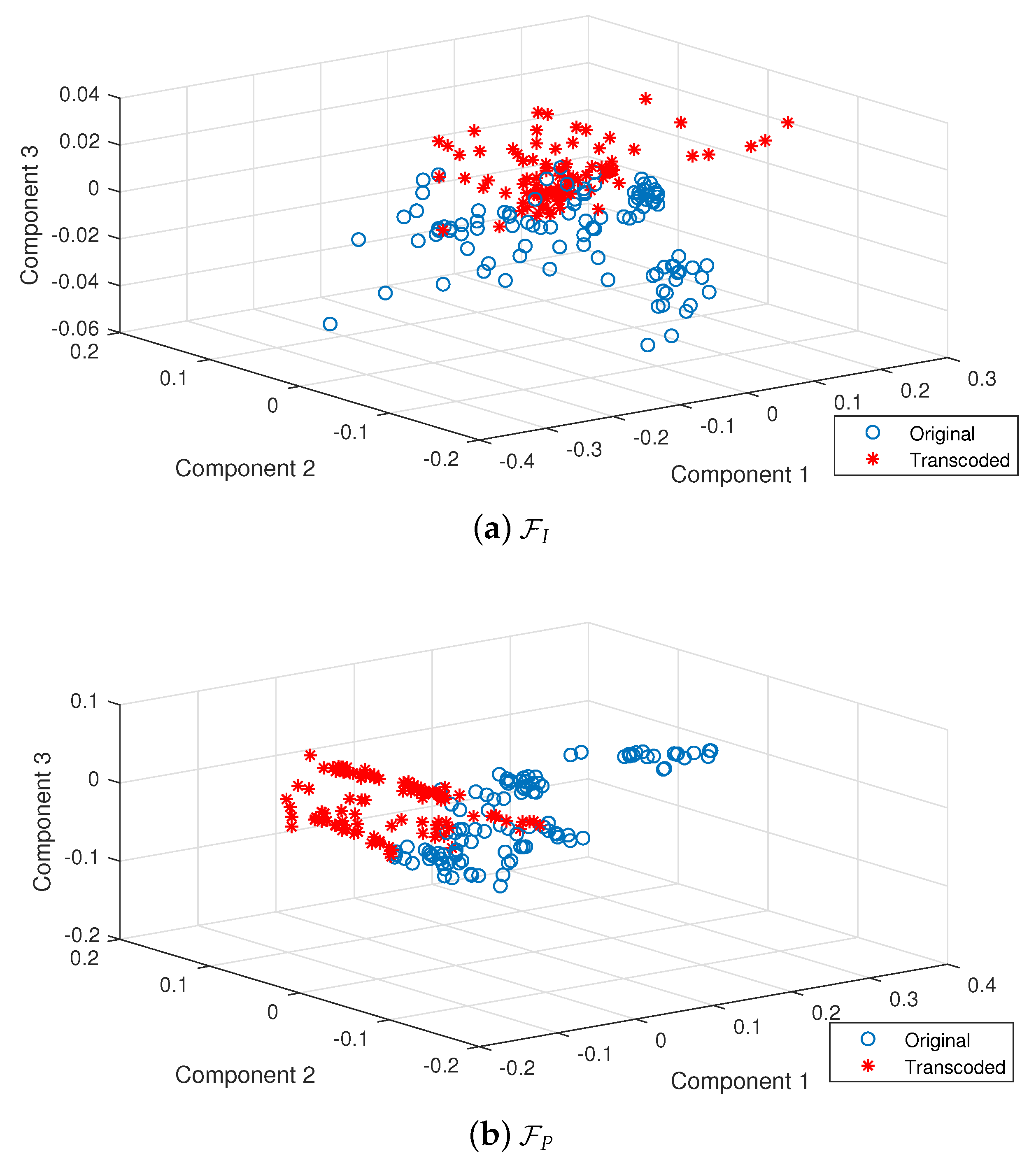
4.2. Results on Different Feature Sets
4.3. Comparison with Existing Methods
4.4. Robustness to Encoding Parameters
4.5. Robustness against Video Enhancement
4.6. Results on High Definition Videos
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Xiph.org Video Test Media [Derf’s Collection]. Available online: https://media.xiph.org/video/derf/ (accessed on 4 November 2018).
- Milani, S.; Fontani, M.; Bestagini, P.; Barni, M.; Piva, A.; Tagliasacchi, M.; Tubaro, S. An overview on video forensics. In Proceedings of the APSIPA Transactions on Signal and Information Processing, Bucharest, Romania, 27–31 August 2012; Volume 1. [Google Scholar]
- Bestagini, P.; Milani, S.; Tagliasacchi, M.; Tubaro, S. Codec and GOP Identification in Double Compressed Videos. IEEE Trans. Image Process. 2016, 25, 2298–2310. [Google Scholar] [CrossRef] [PubMed]
- Bian, S.; Luo, W.; Huang, J. Exposing fake bit rate videos and estimating original bit rates. IEEE Trans. Circuits Syst. Video Technol. 2014, 24, 2144–2154. [Google Scholar] [CrossRef]
- Stamm, M.; Wu, M.; Liu, K. Information forensics: An overview of the first decade. IEEE Access 2013, 1, 167–200. [Google Scholar] [CrossRef]
- Singh, R.D.; Aggarwal, N. Video content authentication techniques: A comprehensive survey. Multimed Syst. 2018, 24, 211–240. [Google Scholar] [CrossRef]
- Wang, W.; Farid, H. Exposing Digital Forgeries in Video by Detecting Double MPEG Compression. In Proceedings of the 8th Workshop on Multimedia and Security, Geneva, Switzerland, 26–27 September 2006; ACM: New York, NY, USA, 2006; pp. 37–47. [Google Scholar] [CrossRef]
- Wang, W.; Farid, H. Exposing digital forgeries in video by detecting double quantization. In Proceedings of the MMandSec’09—11th ACM Multimedia Security Workshop, Princeton, NJ, USA, 7–8 September 2009; pp. 39–47. [Google Scholar]
- Liao, D.; Yang, R.; Liu, H.; Li, J.; Huang, J. Double H.264/AVC compression detection using quantized nonzero AC coefficients. In Media Watermarking, Security, and Forensics III; International Society for Optics and Photonics: Bellingham, WA, USA, 2011; Volume 7880, p. 78800Q. [Google Scholar]
- Luo, W.; Wu, M.; Huang, J. MPEG recompression detection based on block artifacts. In Security, Forensics, Steganography, and Watermarking of Multimedia Contents X; International Society for Optics and Photonics: Bellingham, WA, USA, 2008; Volume 6819, p. 68190X. [Google Scholar]
- He, P.; Jiang, X.; Sun, T.; Wang, S. Detection of double compression in MPEG-4 videos based on block artifact measurement. Neurocomputing 2017, 228, 84–96. [Google Scholar] [CrossRef]
- Chen, W.; Shi, Y. Detection of double MPEG compression based on first digit statistics. In Digital Watermarking. IWDW 2008; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelber, Germany, 2009; Volume 5450, pp. 16–30. [Google Scholar]
- Sun, T.; Wang, W.; Jiang, X. Exposing video forgeries by detecting MPEG double compression. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 1389–1392. [Google Scholar]
- Jiang, X.; Wang, W.; Sun, T.; Shi, Y.; Wang, S. Detection of double compression in MPEG-4 videos based on Markov statistics. IEEE Signal Process. Lett. 2013, 20, 447–450. [Google Scholar] [CrossRef]
- Jia, R.S.; Li, Z.H.; Zhang, Z.Z.; Li, D.D. Double HEVC Compression Detection with the Same QPs Based on the PU Numbers. ITM Web Conf. 2016, 7, 02010. [Google Scholar] [CrossRef] [Green Version]
- Xu, Q.; Sun, T.; Jiang, X.; Dong, Y. HEVC Double Compression Detection Based on SN-PUPM Feature. In Proceedings of the International Workshop on Digital Watermarking, Magdeburg, Germany, 23–25 August 2017; pp. 3–17. [Google Scholar]
- Liang, X.; Li, Z.; Yang, Y.; Zhang, Z.; Zhang, Y. Detection of Double Compression for HEVC Videos with Fake Bitrate. IEEE Access 2018, 6, 53243–53253. [Google Scholar] [CrossRef]
- Costanzo, A.; Barni, M. Detection of double AVC/HEVC encoding. In Proceedings of the 2016 24th European Signal Processing Conference (EUSIPCO), Budapest, Hungary, 28 August–2 September 2016; pp. 2245–2249. [Google Scholar]
- Yu, L.F.; Zhang, Z.Z.; Yang, X.; Li, Z.H. P Frame PU Partitioning Mode Based H.264 to HEVC Video Transcoding Detection. J. Appl. Sci. 2018, 36, 278–286. [Google Scholar]
- Apple Inc. Using HEIF or HEVC Media on Apple Devices. Available online: https://support.apple.com/en-us/HT207022 (accessed on 4 November 2018).
- Sammobile. Galaxy S9 and Galaxy S9+ Support Video Recording in HEVC Format. Available online: https://www.sammobile.com/news/galaxy-s9-series-support-video-recording-in-hevc-format/ (accessed on 4 November 2018).
- Cannon Inc. 4K UHD/50P 4:2:2 10-Bit Support with HEVC. Available online: https://www.canon.co.uk/pro/video-cameras/xf705-4k-uhd-support/ (accessed on 4 November 2018).
- International Telecommunication Union. H.265: High Efficieny Video Coding. Available online: https://www.itu.int/rec/T-REC-H.265 (accessed on 4 November 2018).
- International Organization for Standardization. ISO/IEC 23008-2:2017. Information Technology—High Efficiency Coding and Media Delivery in Heterogeneous Environments—Part 2: High Efficiency Video Coding. Available online: https://www.iso.org/standard/69668.html (accessed on 4 November 2018).
- Sullivan, G.J.; Ohm, J.; Han, W.; Wiegand, T. Overview of the High Efficiency Video Coding (HEVC) Standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Ohm, J.; Sullivan, G.J.; Schwarz, H.; Tan, T.K.; Wiegand, T. Comparison of the Coding Efficiency of Video Coding Standards—Including High Efficiency Video Coding (HEVC). IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1669–1684. [Google Scholar] [CrossRef]
- HEVC Test Model (HM). Available online: https://hevc.hhi.fraunhofer.de/ (accessed on 4 November 2018).
- Cho, S.; Kim, M. Fast CU Splitting and Pruning for Suboptimal CU Partitioning in HEVC Intra Coding. IEEE Trans. Circuits Syst. Video Technol. 2013, 23, 1555–1564. [Google Scholar] [CrossRef]
- Ahn, S.; Lee, B.; Kim, M. A Novel Fast CU Encoding Scheme Based on Spatiotemporal Encoding Parameters for HEVC Inter Coding. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 422–435. [Google Scholar] [CrossRef]
- Jolliffe, I. Principal Component Analysis. In International Encyclopedia of Statistical Science; Lovric, M., Ed.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 1094–1096. [Google Scholar]
- JM Software. Available online: http://iphome.hhi.de/suehring/ (accessed on 4 November 2018).
- Li, H.; Chao, H. GitlHEVCAnalyzer. Available online: https://github.com/lheric/GitlHEVCAnalyzer/ (accessed on 4 November 2018).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Bitrate (AVC∖HEVC) | Feature Set | 100 Kbps | 200 Kbps | 300 Kbps | 400 Kbps |
|---|---|---|---|---|---|
| 100 Kbps | 91.54 | 94.77 | 93.15 | 91.43 | |
| 90.08 | 97.86 | 98.39 | 98.99 | ||
| 92.73 | 98.47 | 99.52 | 99.55 | ||
| 200 Kbps | 89.03 | 94.92 | 93.44 | 92.40 | |
| 76.32 | 96.36 | 98.55 | 99.86 | ||
| 89.52 | 98.39 | 100.00 | 100.00 | ||
| 300 Kbps | 81.27 | 94.64 | 94.67 | 90.61 | |
| 68.51 | 92.08 | 97.47 | 98.90 | ||
| 77.08 | 95.67 | 98.52 | 99.52 | ||
| 400 Kbps | 79.02 | 94.76 | 95.25 | 91.10 | |
| 65.84 | 85.95 | 95.51 | 98.24 | ||
| 72.78 | 95.19 | 96.40 | 99.55 | ||
| Average | 85.22 | 94.77 | 94.13 | 91.39 | |
| 75.19 | 93.06 | 97.48 | 99.00 | ||
| 83.03 | 96.93 | 98.61 | 99.66 |
| Bitrate (AVC∖HEVC) | 100 Kbps | 200 Kbps | 300 Kbps | 400 Kbps |
|---|---|---|---|---|
| 100 Kbps | 3.74 ↑ | 2.33 ↑ | 4.81 ↑ | 2.38 ↑ |
| 200 Kbps | 8.50 ↑ | 5.98 ↑ | 4.79 ↑ | 1.89 ↑ |
| 300 Kbps | 4.62 ↑ | 5.66 ↑ | 5.67 ↑ | 3.81 ↑ |
| 400 Kbps | 5.59 ↑ | 8.21 ↑ | 4.17 ↑ | 5.31 ↑ |
| Average | 5.61 ↑ | 5.54 ↑ | 4.86 ↑ | 3.35 ↑ |
| Bitrate (AVC∖HEVC) | 100 Kbps | 200 Kbps | 300 Kbps | 400 Kbps |
|---|---|---|---|---|
| 100 Kbps | 90.58 | 97.07 | 97.19 | 97.66 |
| 200 Kbps | 79.55 | 95.17 | 97.31 | 98.00 |
| 300 Kbps | 75.79 | 93.63 | 95.00 | 97.14 |
| 400 Kbps | 70.47 | 88.46 | 94.14 | 95.18 |
| Average | 79.10 | 93.58 | 95.91 | 97.00 |
| Bitrate (AVC∖HEVC) | 100 Kbps | 200 Kbps | 300 Kbps | 400 Kbps |
|---|---|---|---|---|
| 100 Kbps | 94.71 | 98.14 | 99.52 | 99.55 |
| 200 Kbps | 88.72 | 98.14 | 98.59 | 100 |
| 300 Kbps | 77.65 | 94.78 | 96.69 | 96.23 |
| 400 Kbps | 76.29 | 91.94 | 94.8 | 97.59 |
| Average | 84.34 | 95.75 | 97.4 | 98.34 |
| Bitrate (AVC∖HEVC) | 2 Mbps | 3 Mbps | 4 Mbps | 5 Mbps |
|---|---|---|---|---|
| 2 Mbps | 97.90 | 98.66 | 98.71 | 99.33 |
| 3 Mbps | 97.99 | 98.62 | 98.71 | 98.75 |
| 4 Mbps | 97.29 | 98.04 | 98.75 | 98.71 |
| 5 Mbps | 95.23 | 97.50 | 97.90 | 98.62 |
| Average | 97.10 | 98.21 | 98.52 | 98.85 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bian, S.; Li, H.; Gu, T.; Kot, A.C. Exposing Video Compression History by Detecting Transcoded HEVC Videos from AVC Coding. Symmetry 2019, 11, 67. https://doi.org/10.3390/sym11010067
Bian S, Li H, Gu T, Kot AC. Exposing Video Compression History by Detecting Transcoded HEVC Videos from AVC Coding. Symmetry. 2019; 11(1):67. https://doi.org/10.3390/sym11010067
Chicago/Turabian StyleBian, Shan, Haoliang Li, Tianji Gu, and Alex Chichung Kot. 2019. "Exposing Video Compression History by Detecting Transcoded HEVC Videos from AVC Coding" Symmetry 11, no. 1: 67. https://doi.org/10.3390/sym11010067
APA StyleBian, S., Li, H., Gu, T., & Kot, A. C. (2019). Exposing Video Compression History by Detecting Transcoded HEVC Videos from AVC Coding. Symmetry, 11(1), 67. https://doi.org/10.3390/sym11010067