A Bidirectional Searching Strategy to Improve Data Quality Based on K-Nearest Neighbor Approach



Abstract
:1. Introduction
2. Literature Review
3. Data Analysis and Model Selection
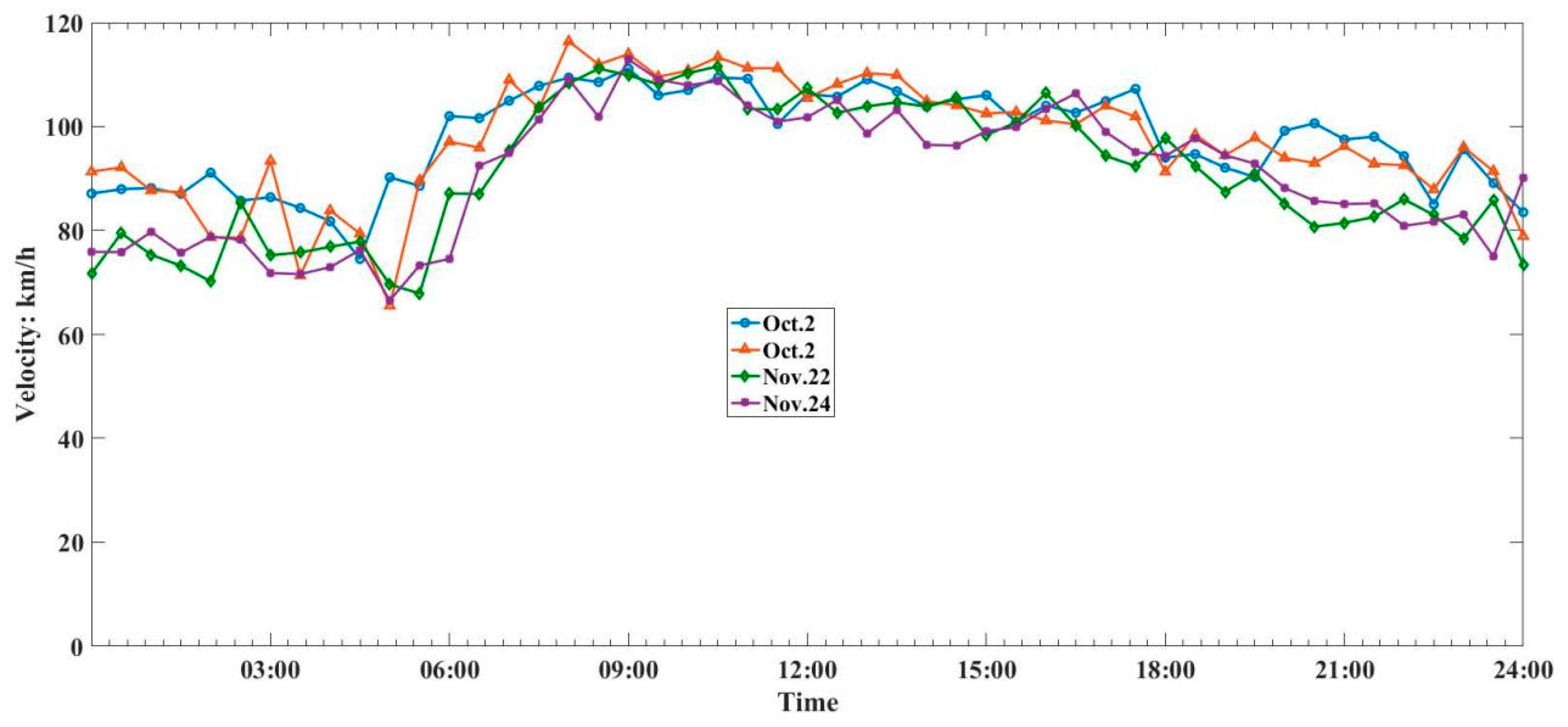
3.1. Data Relevance Analysis
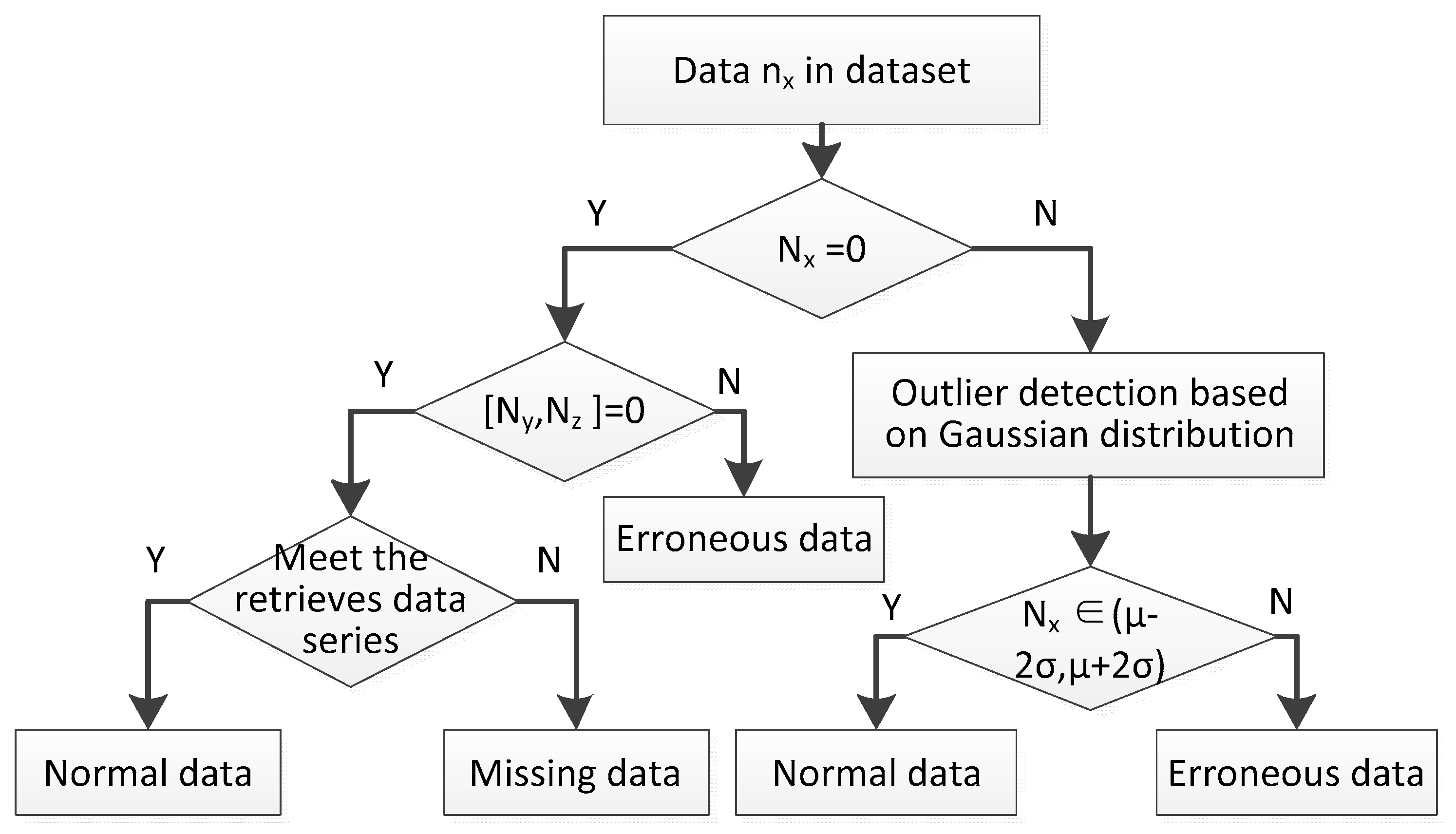
3.2. Abnormal Data Identification
4. Basic KNN Algorithm
4.1. Nearest Neighbor
4.2. State Vector
4.3. Distance Measurement Method
4.4. Recovery Algorithm
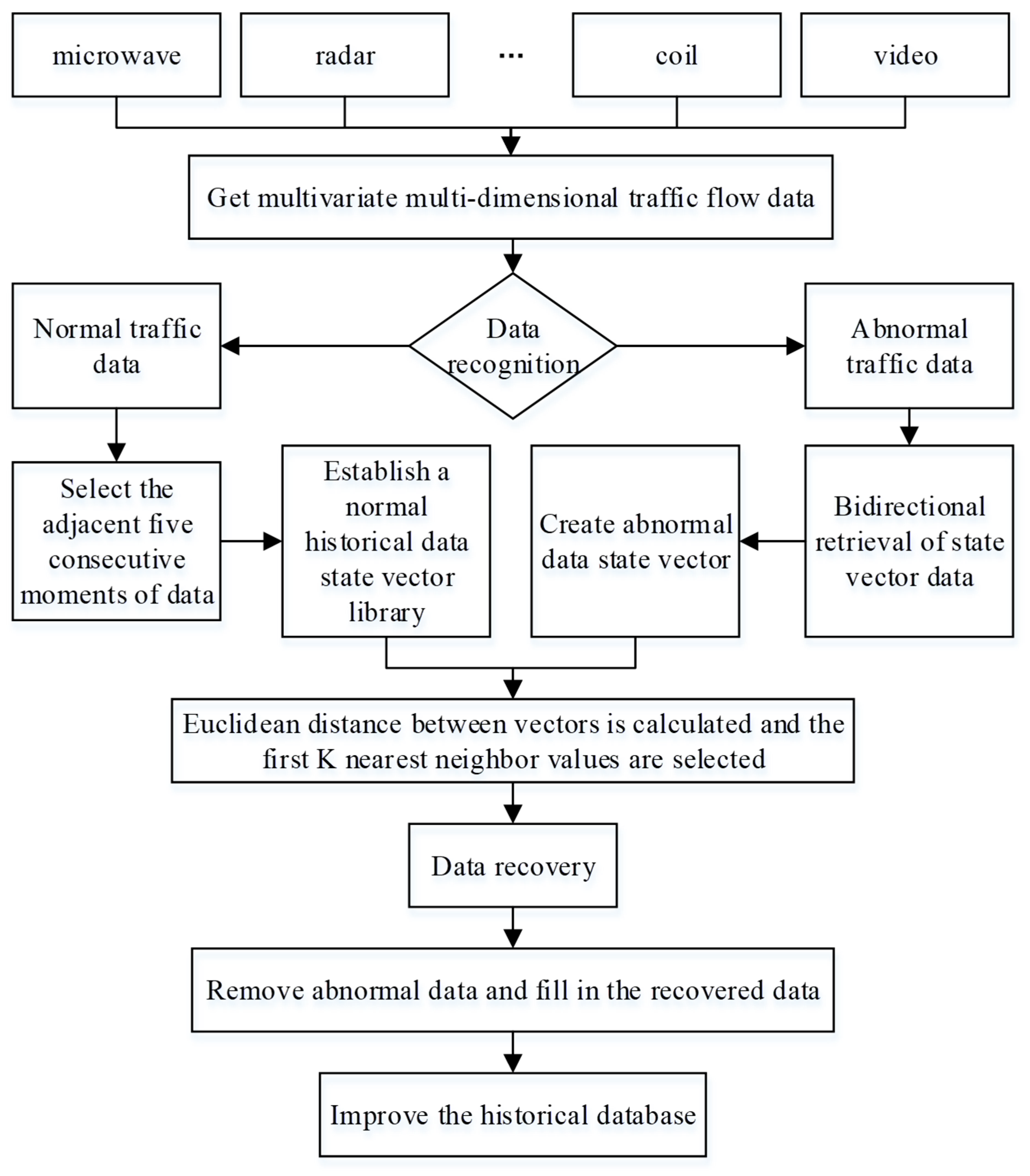
5. Bidirectional Data Recovery Approach
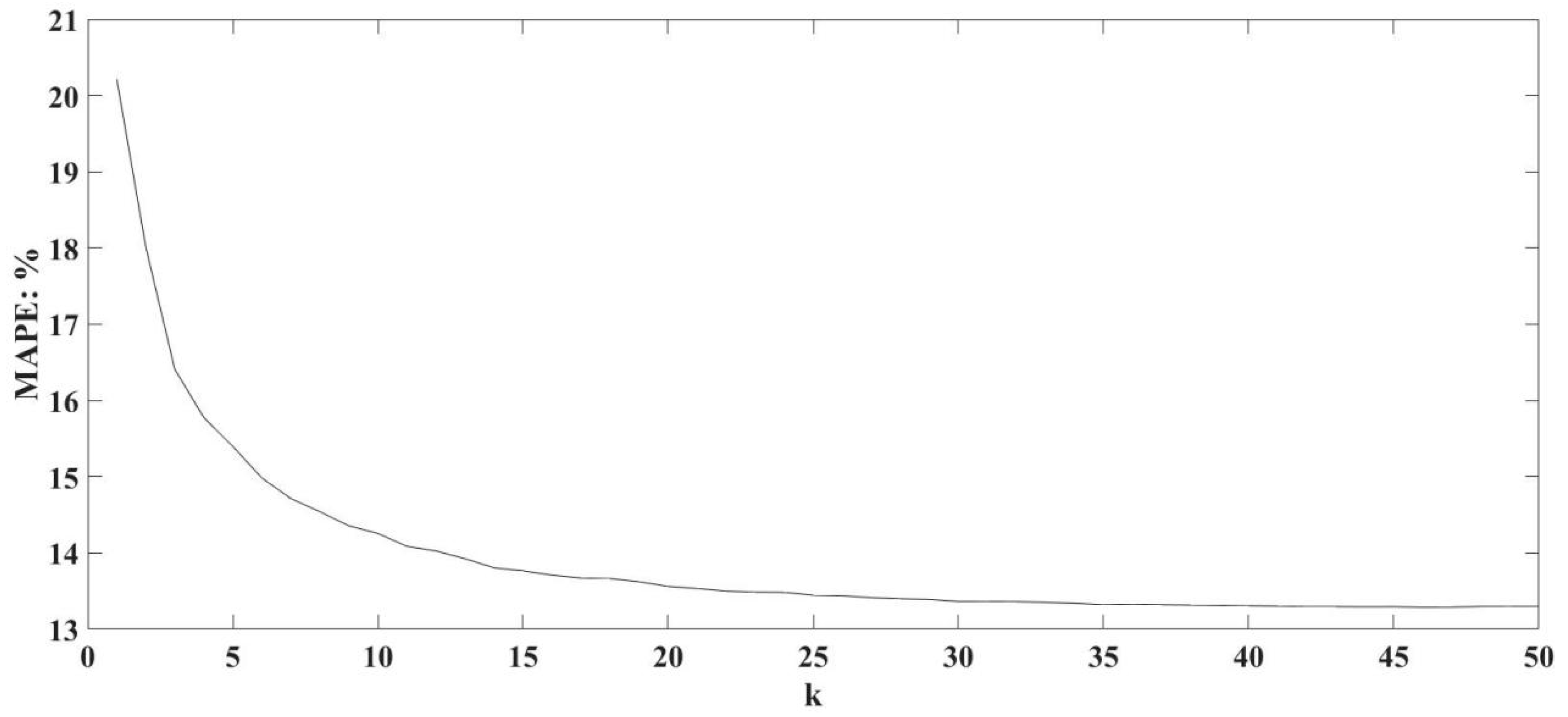
5.1. Parameter K Selection
5.2. Designed State Vector
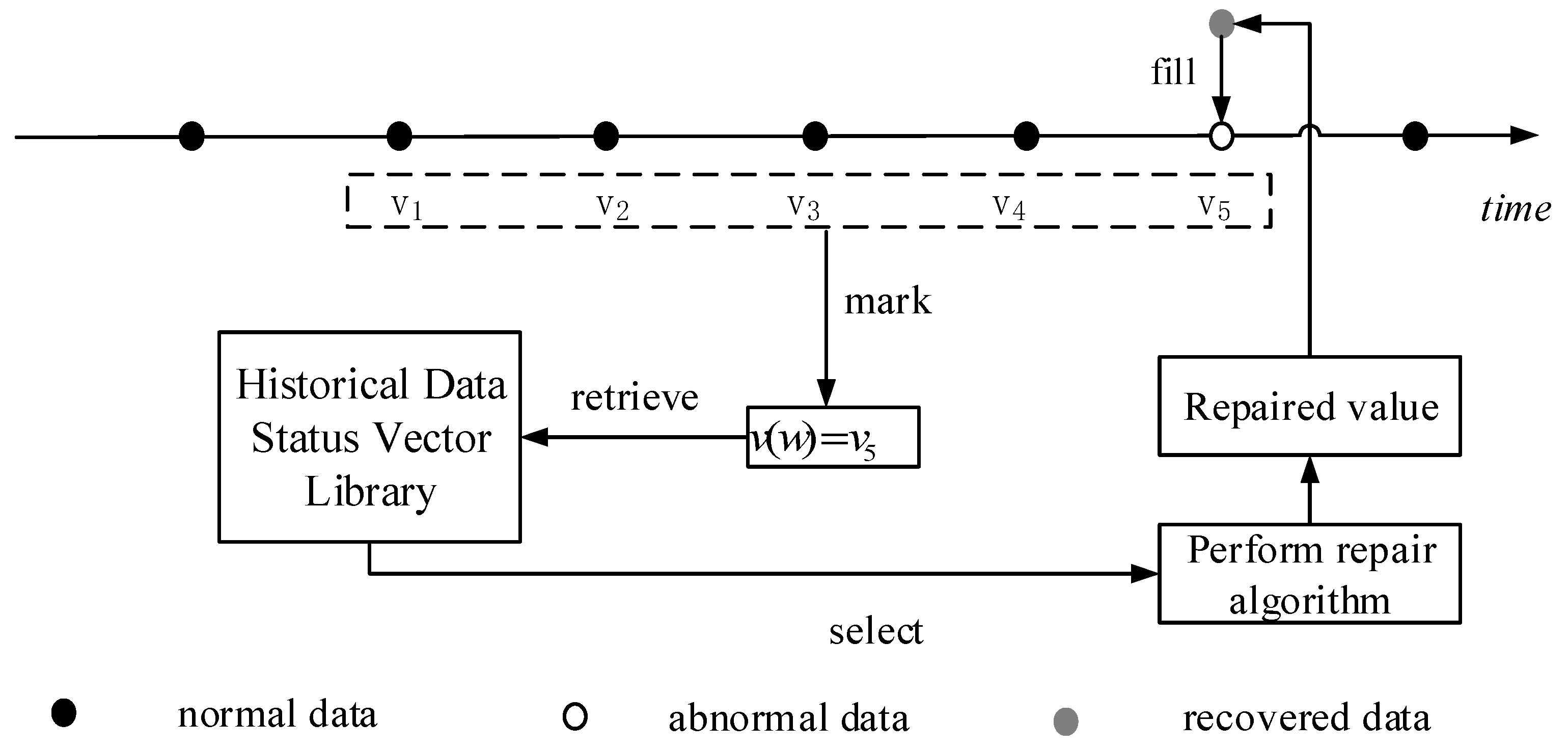
5.2.1. Historical Data Status Vector Library
5.2.2. Unidirectional abnormal data state vector
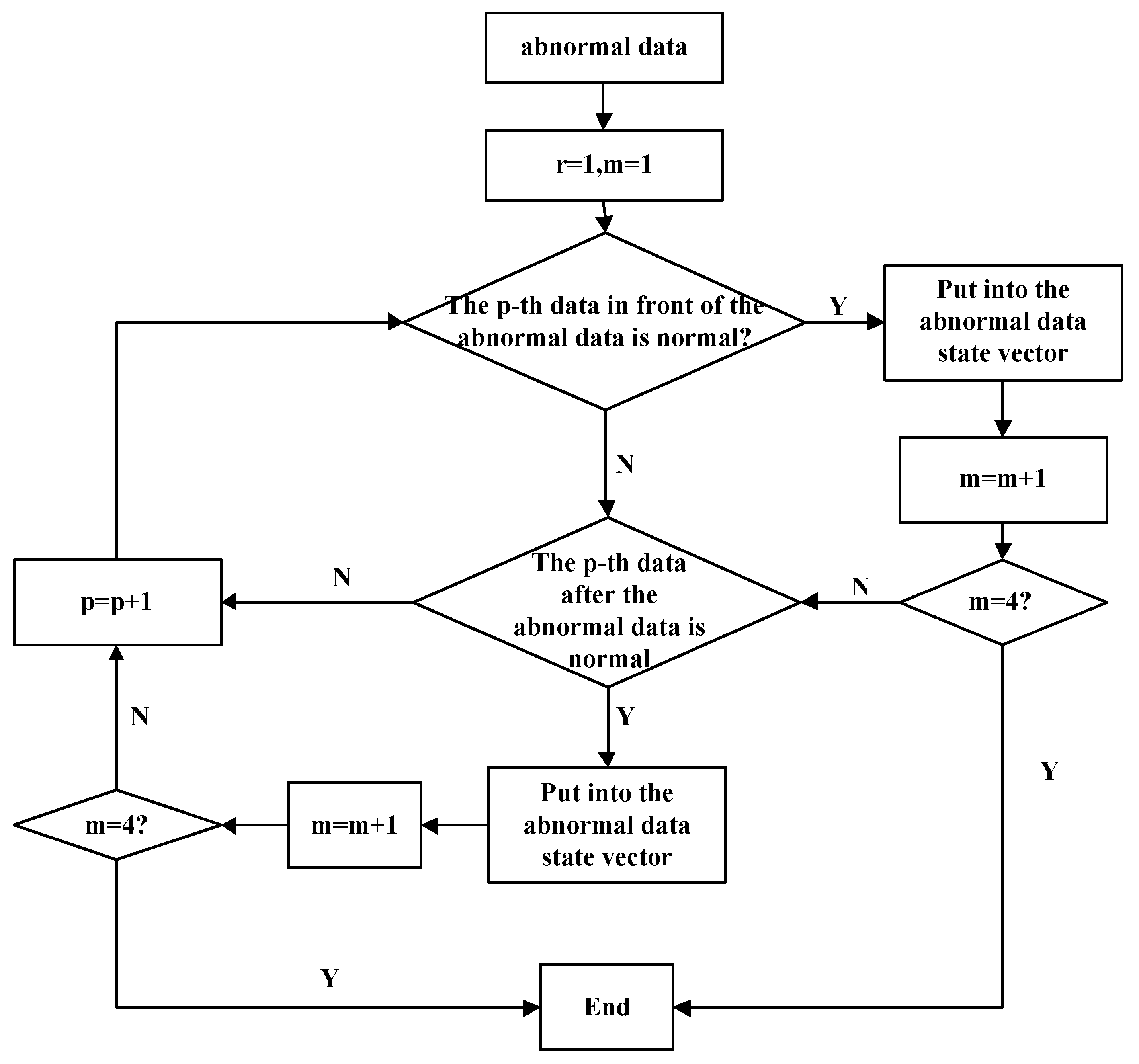
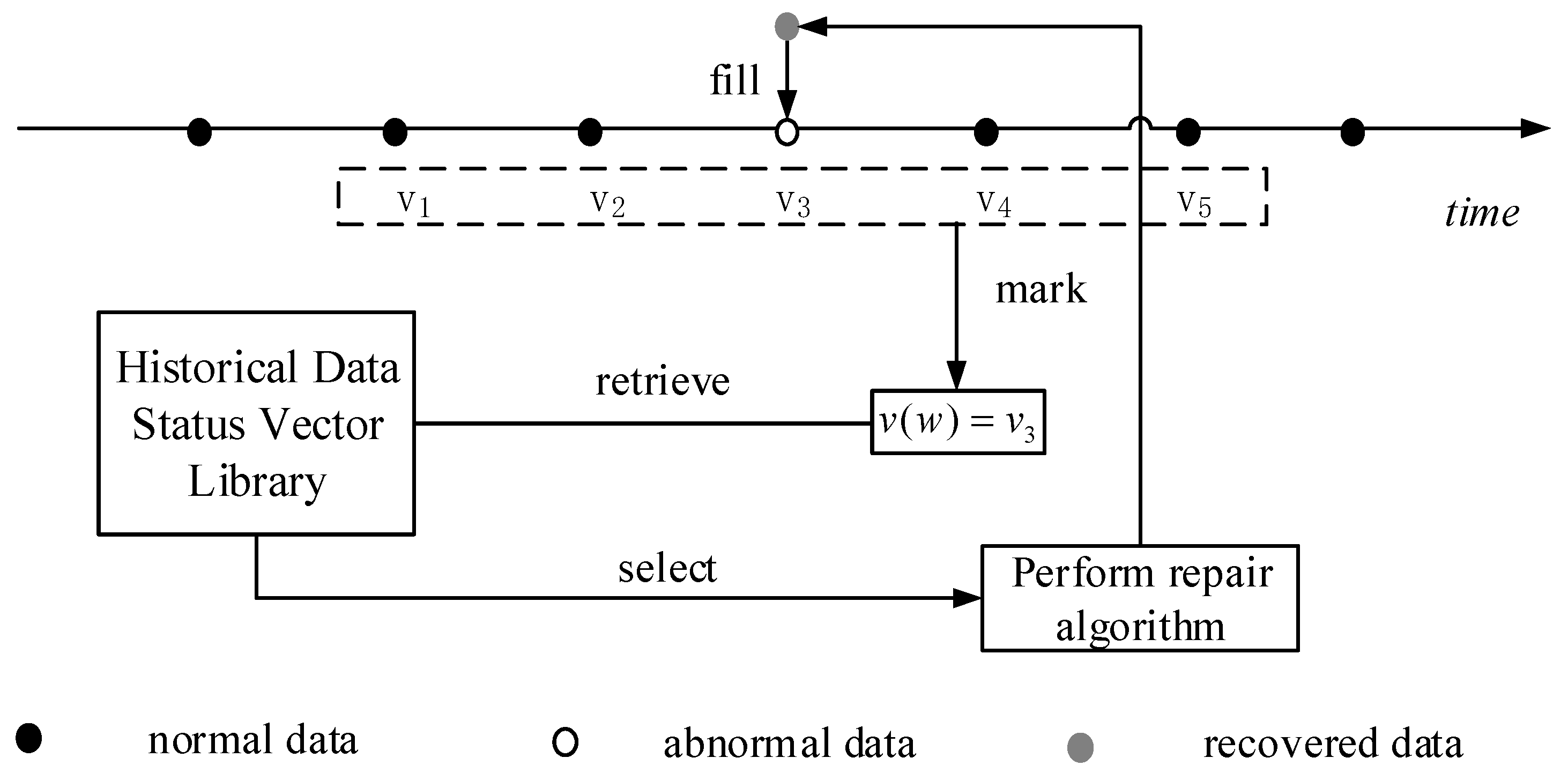
5.2.3. Bidirectional Abnormal Data State Vector
5.3. Weight Assignment
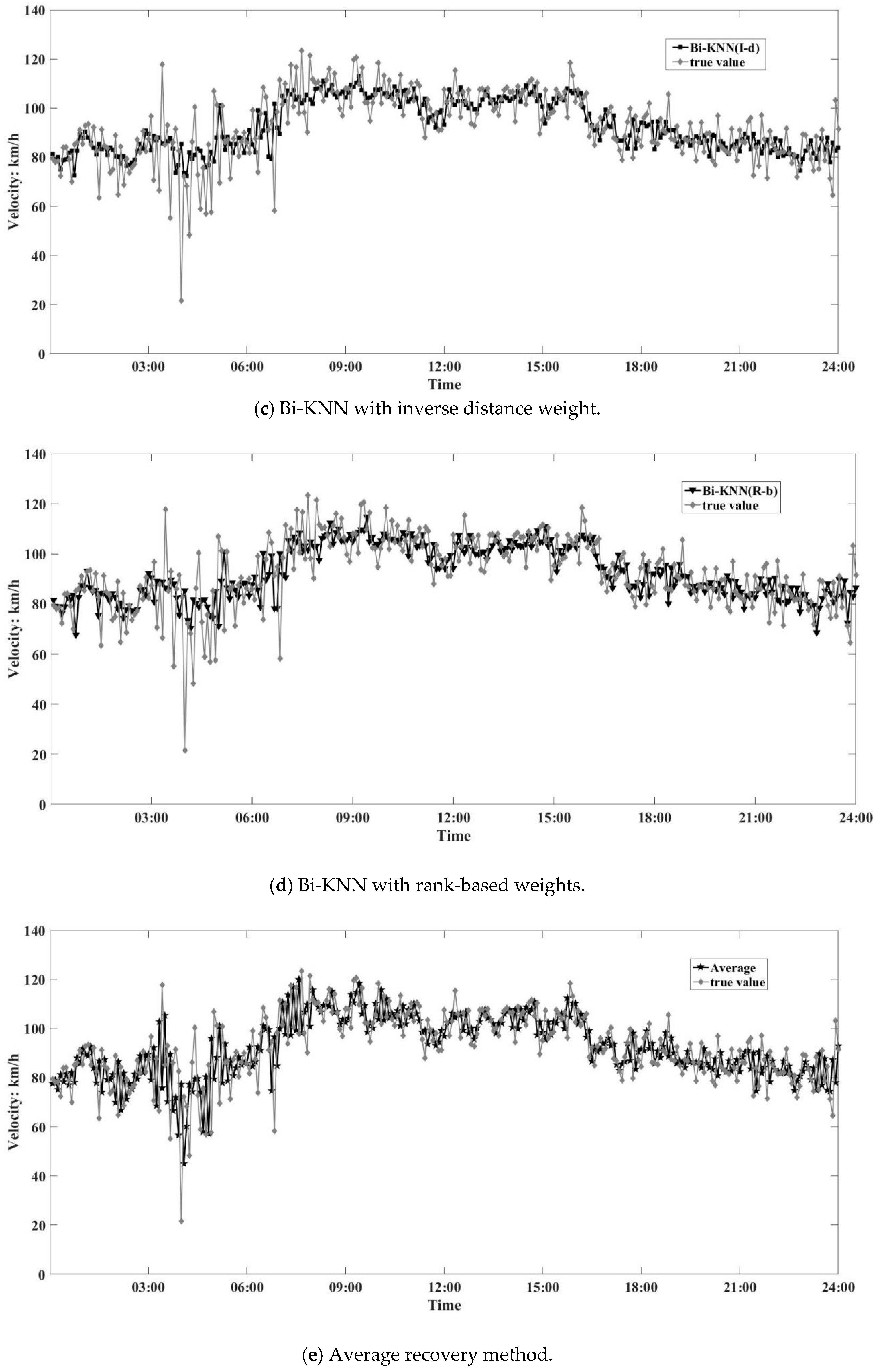
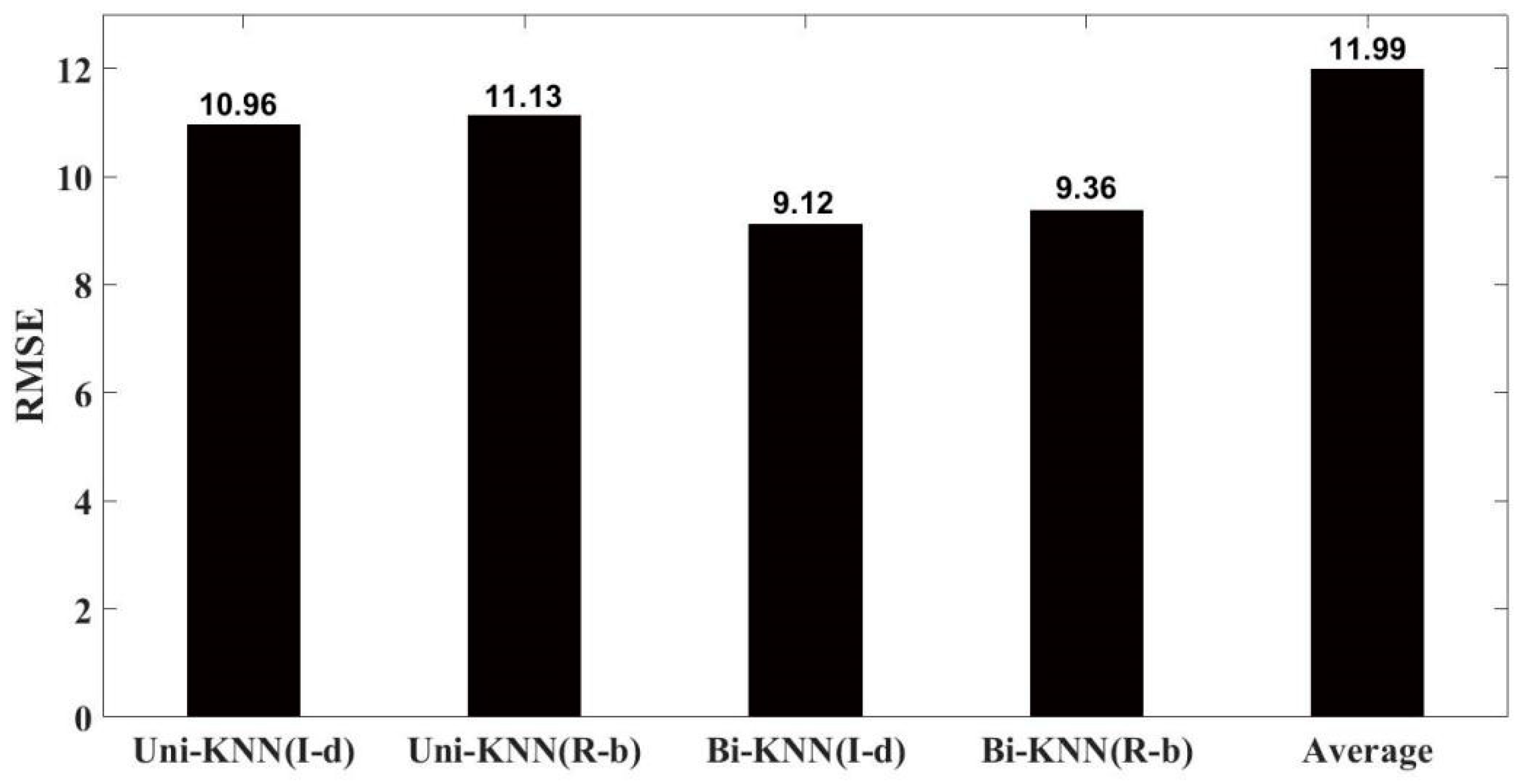
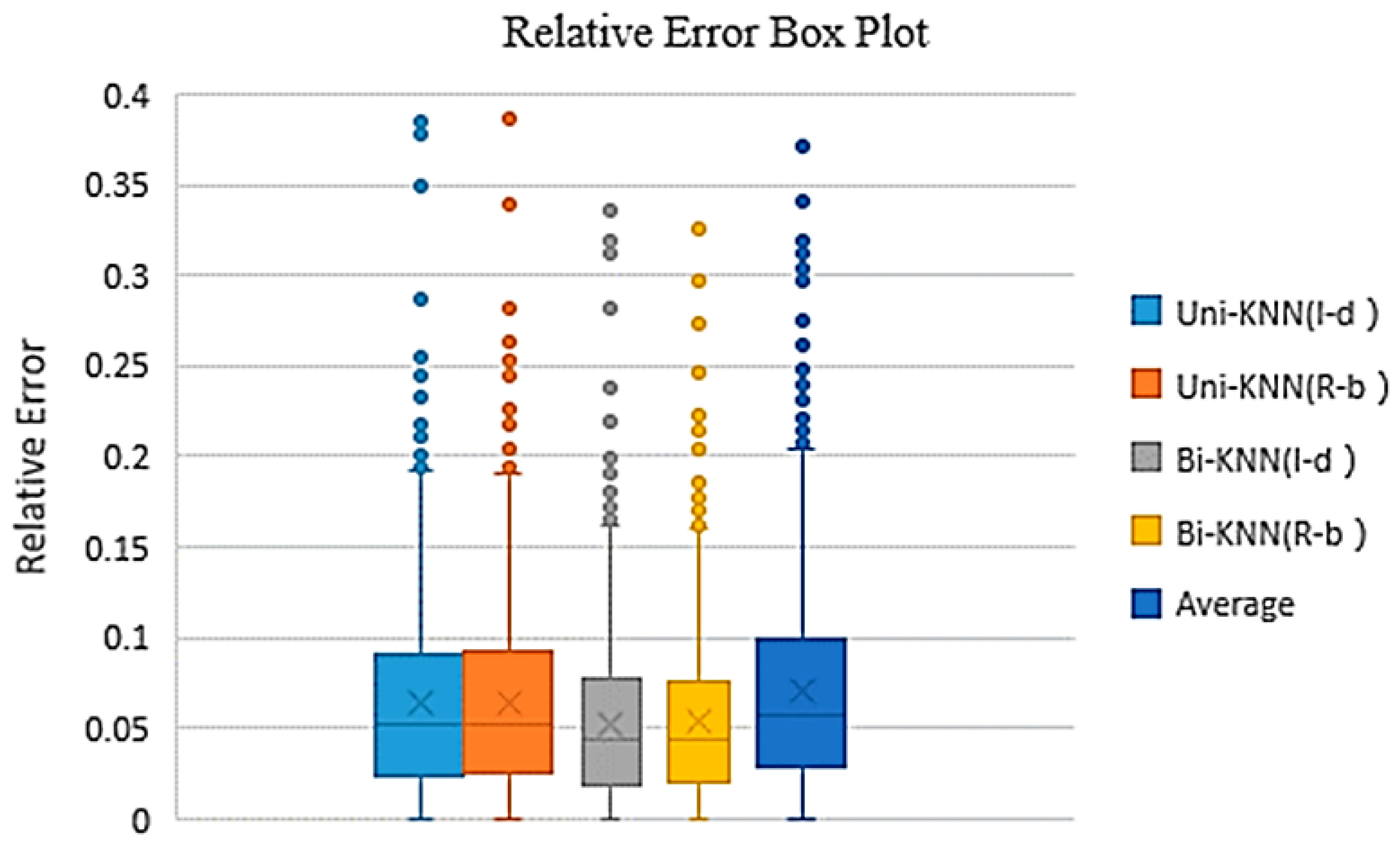
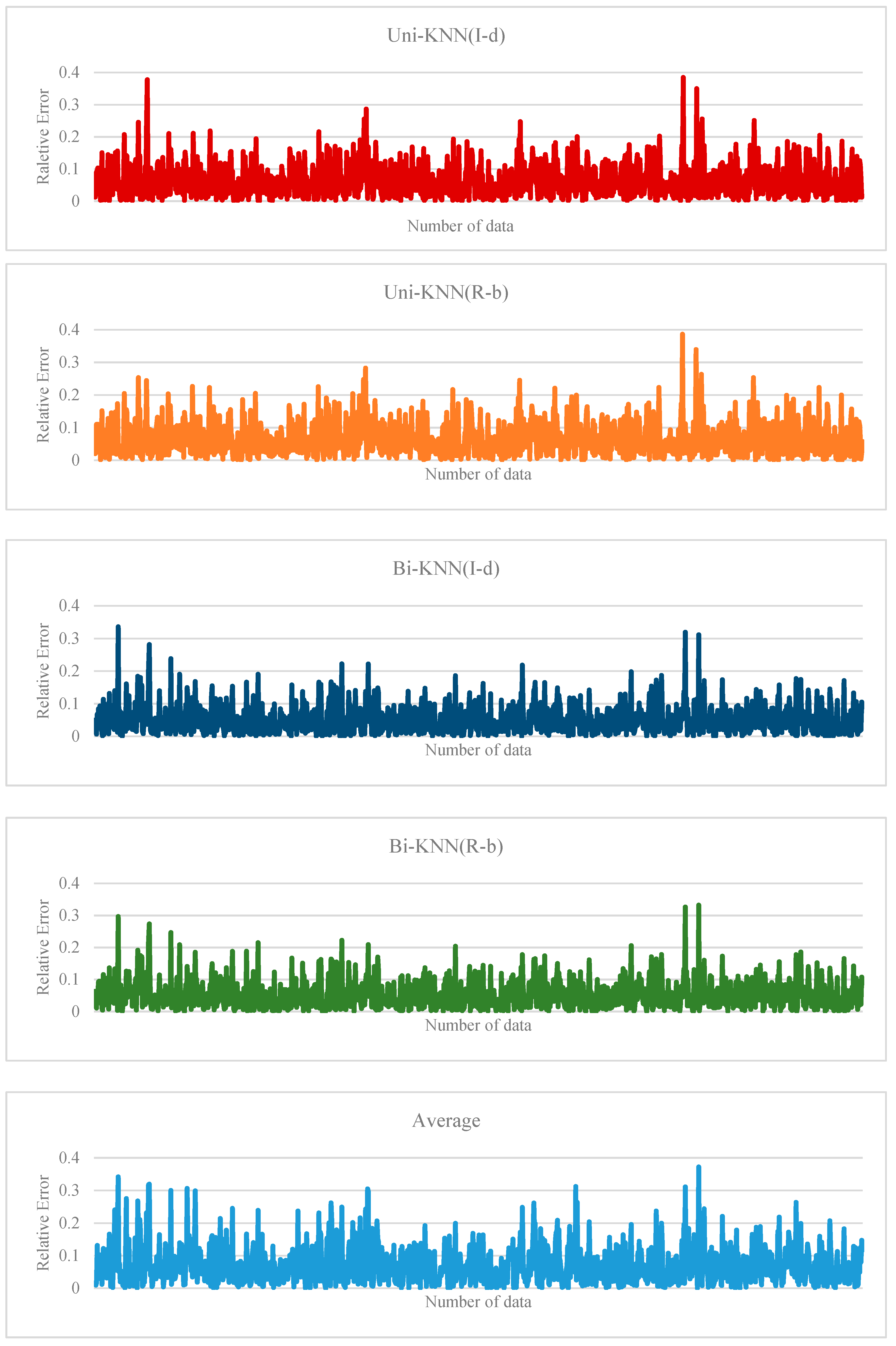
6. Experiment and Results
6.1. Performance Evaluation
6.2. Experimental Design
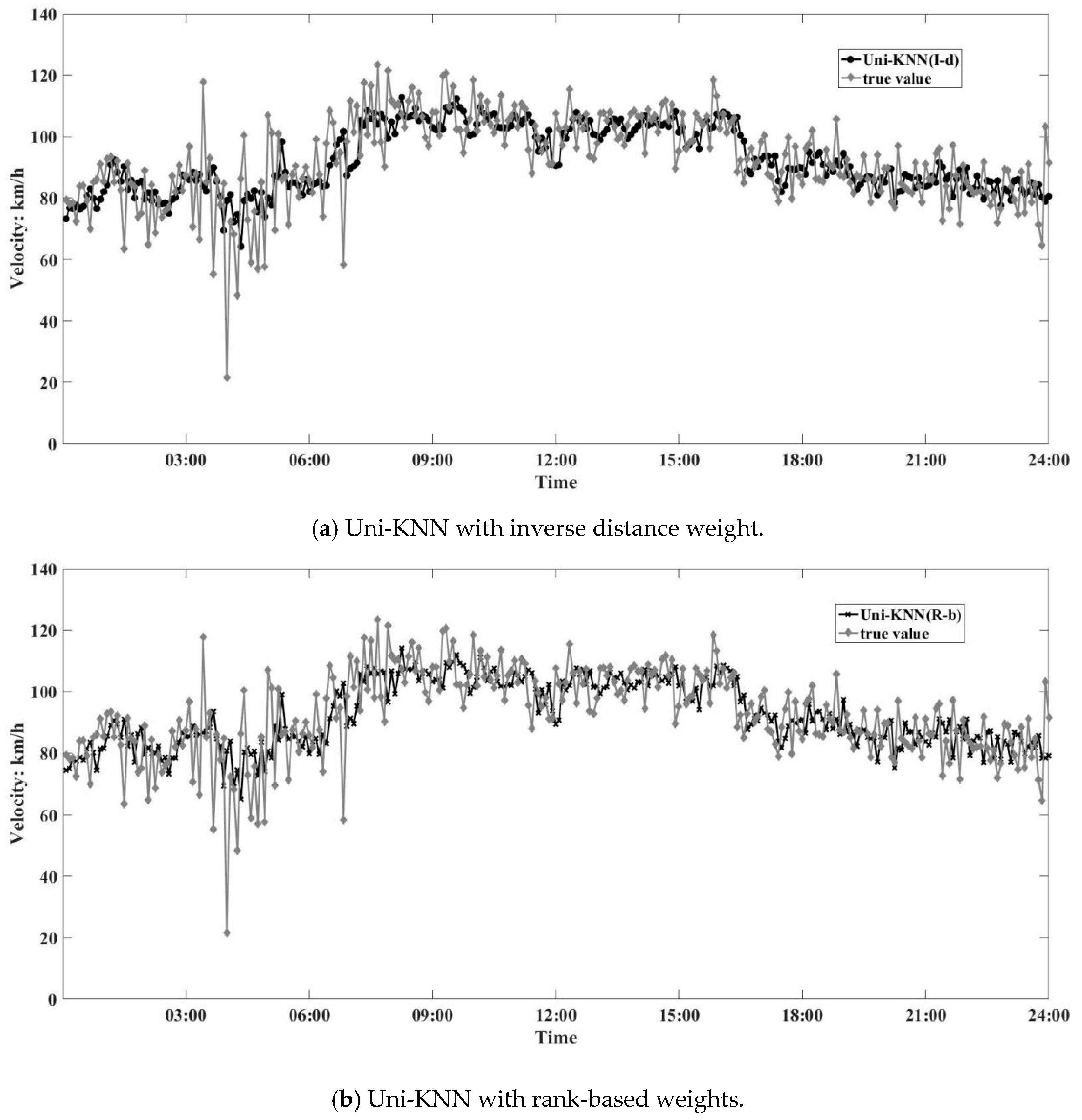
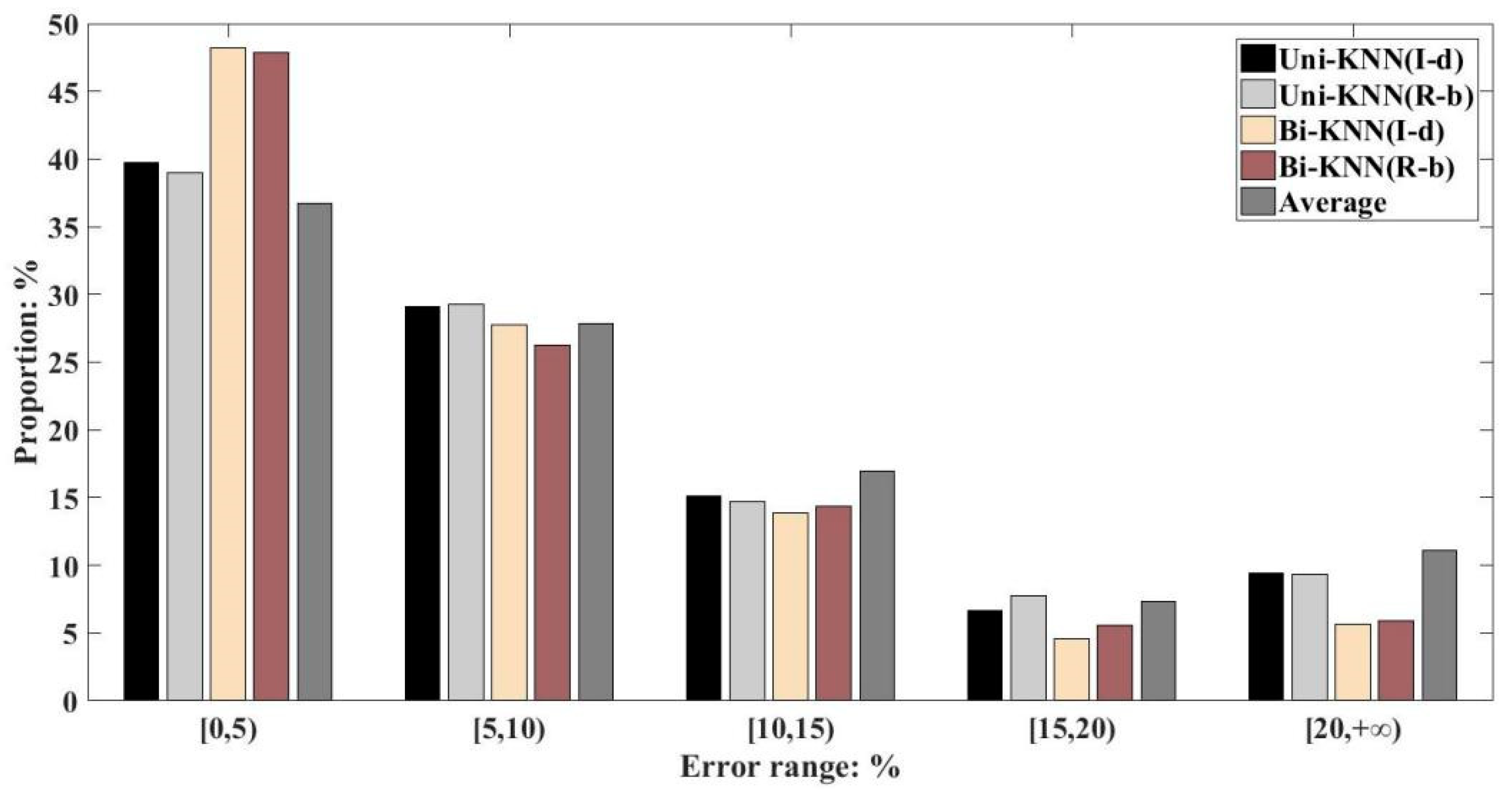
6.3. Results
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
Nomenclature
| K | Number of candidate values |
| Rank of the i-th candidate | |
| Distance between the current data and the group i data in the historical set | |
| Weight of subdata in the i-th data in the historical set | |
| Recovered value of abnormal data | |
| Real value. | |
| Mean of | |
| i-th recovered value | |
| Mean of | |
| n | Number of abnormal value |
References
- Guo, M.; Lan, J.; Li, J.; Lin, Z.; Sun, X. Traffic flow data recovery algorithm based on gray residual GM (1, N) model. J. Transp. Syst. Eng. Inf. Technol. 2012, 12, 42–47. [Google Scholar] [CrossRef]
- Ma, M.; Liang, S. An integrated control method based on the priority of ways in a freeway network. Trans. Inst. Meas. Control 2018, 40, 843–852. [Google Scholar] [CrossRef]
- Ma, M.; Liang, S. An optimization approach for freeway network coordinated traffic control and route guidance. PLoS ONE 2018, 13. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.; Margaret, B. Instrumented city database analysts using multi-agents. Transp. Res. Part C Emerg. Technol. 2002, 10, 419–432. [Google Scholar] [CrossRef]
- Liang, S.; Ma, M. Analysis of bus bunching impact on car delays at signalized intersections. KSCE J. Civ. Eng. 2019, 23, 833–843. [Google Scholar] [CrossRef]
- Liang, S.; Ma, M.; He, S.; Zhang, H.; Yuan, P. Coordinated control method to self-equalize bus headways: An analytical method. Transportmetrica B Transp. Dyn. 2019, 7, 1175–1202. [Google Scholar] [CrossRef]
- Zhang, J.; el Kamel, A. Virtual traffic simulation with neural network learned mobility model. Adv. Eng. Softw. 2018, 115, 103–111. [Google Scholar] [CrossRef]
- Duan, Y.; Lv, Y.; Liu, Y.; Wang, F. An efficient realization of deep learning for traffic data imputation. Transp. Res. Part C Emerg. Technol. 2016, 72, 168–181. [Google Scholar] [CrossRef]
- Sharma, S.; Lingras, P.; Zhong, M. Effect of missing values estimations on traffic parameters. Transp. Plan. Technol. 2004, 27, 119–144. [Google Scholar] [CrossRef]
- Ma, M.; Liang, S.; Guo, H.; Yang, J. Short-term traffic flow prediction using a self-adaptive two-dimensional forecasting method. Adv. Mech. Eng. 2017, 9, 168781401771900. [Google Scholar] [CrossRef]
- Patil, D.V.; Bichkar, R.S. Multiple imputation of missing data with genetic algorithm based techniques. IJCA Spec. Issue Evol. Comput. Optim. Tech. 2010, 74–78. [Google Scholar]
- Van Lint, J.W.C.; Hoogendoorn, S.P.; van Zuylen, H.J. Accurate freeway travel time prediction with state-space neural networks under missing data. Transp. Res. Part C Emerg. Technol. 2005, 13, 347–369. [Google Scholar] [CrossRef]
- Silva-Ramírez, E.-L.; Pino-Mejías, R.; López-Coello, M. Missing value imputation on missing completely at random data using multilayer perceptrons. Neural Netw. Off. J. Int. Neural Netw. Soc. 2011, 24, 121–129. [Google Scholar] [CrossRef]
- Bálint, D.; Jäntschi, L. Missing data calculation using the antioxidant activity in selected herbs. Symmetry 2019, 11, 779. [Google Scholar] [CrossRef]
- Laña, I.; Olabarrieta, I.I.; Vélez, M.; Del Ser, J. On the imputation of missing data for road traffic forecasting: New insights and novel techniques. Transp. Res. Part C Emerg. Technol. 2018, 90, 18–33. [Google Scholar] [CrossRef]
- Yan, Y.; Zhang, S.; Tang, J.; Wang, X. Understanding characteristics in multivariate traffic flow time series from complex network structure. Phys. A Stat. Mech. App. 2017, 477, 149–160. [Google Scholar] [CrossRef]
- Pushkar, A.; Hall, F.L.; Acha-Daza, J.A. Estimation of speeds from single-loop freeway flow and occupancy data using cusp catastrophe theory model. Transp. Res. Rec. 1994, 1457, 149–157. [Google Scholar]
- Chen, J.; Shao, J. Nearest neighbor imputation for survey data. J. Off. Stat. 2000, 16, 113–131. [Google Scholar]
- Yuan, K.H.; Marshall, L.L.; Bentler, P.M. A unified approach to exploratory factor analysis with missing data, nonnormal data, and in the presence of outliers. Psychometrika 2002, 67, 95–121. [Google Scholar] [CrossRef]
- Troyanskaya, O.; Cantor, M.; Sherlock, G.; Brown, P.; Hastie, T.; Tibshirani, R.; Botstein, D.; Altman, R.B. Missing value estimation methods for DNA microarrays. Bioinformatics 2001, 17, 520–525. [Google Scholar] [CrossRef] [Green Version]
- Smith, B.; Scherer, W.; Conklin, J. Exploring Imputation techniques for missing data in transportation management systems. Transp. Res. Rec. J. Transp. Res. Board 2003, 1836, 132–142. [Google Scholar] [CrossRef]
- Chen, C.; Kwon, J.; Rice, J.; Skabardonis, A.; Varaiya, P. Detecting errors and imputing missing data for single-loop surveillance systems. Transp. Res. Rec. J. Transp. Res. Board 2003, 1855, 53–57. [Google Scholar] [CrossRef]
- Abdella, M.; Marwala, T. The use of genetic algorithms and neural networks to approximate missing data in database. In Proceedings of the IEEE 3rd International Conference on Computational Cybernetics, Mauritius, 13–16 April 2005; pp. 207–212. [Google Scholar]
- Tang, J.; Zhang, G.; Wang, Y.; Wang, H.; Liu, F. A hybrid approach to integrate fuzzy C-means based imputation method with genetic algorithm for missing traffic volume data estimation. Transp. Res. Part C Emerg. Technol. 2015, 51, 29–40. [Google Scholar] [CrossRef]
- Min, W.; Wynter, L. Real-time road traffic prediction with spatio-temporal correlations. Transp. Res. Part C Emerg. Technol. 2011, 19, 606–616. [Google Scholar] [CrossRef]
- Aydilek, I.B.; Arslan, A. A novel hybrid approach to estimating missing values in databases using k-nearest neighbors and neural networks. Int. J. Innov. Comput. Inf. Control 2012, 8, 4705–4717. [Google Scholar]
- Lobato, F.; Sales, C.; Araujo, I.; Tadaiesky, V.; Dias, L.; Ramos, L.; Santana, A. Multi-objective genetic algorithm for missing data imputation. Pattern Recognit. Lett. 2015, 68, 126–131. [Google Scholar] [CrossRef]
- Bae, B.; Kim, H.; Lim, H.; Liu, Y.; Han, L.D.; Freeze, P.B. Missing data imputation for traffic flow speed using spatio-temporal cokriging. Transp. Res. Part C Emerg. Technol. 2018, 88, 124–139. [Google Scholar] [CrossRef]
- Shang, Q.; Yang, Z.; Gao, S.; Tan, D. An imputation method for missing traffic data based on FCM optimized by PSO-SVR. J. Adv. Transp. 2018, 2018, 1–21. [Google Scholar] [CrossRef]
- Smith, L.B.; Williams, B.M.; Oswald, R.K. Comparison of parametric and nonparametric models for traffic flow forecasting. Transp. Res. Part C Emerg. Technol. 2002, 10, 303–321. [Google Scholar] [CrossRef]
- Guo, F.; Krishnan, R.; Polak, J.W. Short-term traffic prediction under normal and incident conditions using singular spectrum analysis and the k-nearest neighbour method. In Proceedings of the 17th International Conference on Road Transport Information and Control (RTIC), London, UK, 25–26 September 2012. [Google Scholar] [CrossRef]
- Hodge, V.J.; Austin, J. A survey of outlier detection methodologies. In Artificial Intelligence Review; Springer: Berlin/Heidelberg, Germany, 2004; Volume 22, pp. 85–126. [Google Scholar]
- Kindzerske, M.D.; Ni, D. Composite nearest neighbor nonparametric regression to improve traffic prediction. Transp. Res. Rec. 2007, 1993, 30–35. [Google Scholar] [CrossRef]
- Hodge, V.J.; Krishnan, R.; Austin, J.; Polak, J.; Jackson, T. Short-term prediction of traffic flow using a binary neural network. Neural Comput. Appl. 2014, 25, 1639–1655. [Google Scholar] [CrossRef] [Green Version]
- Davis, G.A.; Nihan, N.L. Nonparametric regression and short-term freeway traffic forecasting. J. Transp. Eng. 1991, 117, 178–188. [Google Scholar] [CrossRef]
- Zhang, L.; Liu, Q.; Yang, W.; Wei, N.; Dong, D. An improved k-nearest neighbor model for short-term traffic flow prediction. Procedia-Soc. Behav. Sci. 2013, 96, 653–662. [Google Scholar] [CrossRef]
- Liu, Z.; Guo, J.; Cao, J.; Wei, Y.; Huang, W. A hybrid short-term traffic flow forecasting method based on neural networks combined with k-nearest neighbor. Promet-Traffic Transp. 2018, 30, 445–456. [Google Scholar] [CrossRef]
- Habtemichael, F.G.; Cetin, M. Short-term traffic flow rate forecasting based on identifying similar traffic patterns. Transp. Res. Par. C 2016, 66, 61–78. [Google Scholar] [CrossRef]
- Heng, L.; Zhengyu, D.; Xiaofa, S. Correlation analysis and data repair of loop data in urban expressway based on co-integration theory. Procedia-Soc. Behav. Sci. 2013, 96, 798–806. [Google Scholar] [CrossRef]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. 2009, 41, 15. [Google Scholar] [CrossRef]
- Li, L.; Zhang, J.; Yang, F.; Ran, B. Robust and flexible strategy for missing data imputation in intelligent transportation system. IET Intell. Transp. Syst. 2017, 12, 151–157. [Google Scholar] [CrossRef]
- Yilmaz, M.U.; Bihrat, Ö.N.Ö.Z. Evaluation of statistical methods for estimating missing daily streamflow data. Teknik Dergi 2019, 30. [Google Scholar] [CrossRef]
- Shaikh, S.A.; Kitagawa, H. Fast top-k distance-based outlier detection on uncertain data. Web-Age Inf. Manag. 2013. [Google Scholar] [CrossRef]
- Turochy, R. Enhancing short-term traffic forecasting with traffic condition information. J. Transp. Eng. 2006, 132, 469–474. [Google Scholar] [CrossRef]
- Shepard, D. A two-dimensional interpolation function for irregularly-spaced data. In Proceedings of the 1968 23rd ACM National Conference, New York, NY, USA, 27–29 August 1968; pp. 517–524. [Google Scholar] [CrossRef]
- Habtemichael, F.G.; Cetin, M.; Anuar, K.A. Methodology for quantifying incident-induced delays on freeways by grouping similar traffic patterns. In Proceedings of the Transportation Research Board 94th Annual Meeting, Washington, DC, USA, 11–15 January 2015; pp. 15–4824. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Date | 2 October | 4 October | 22 November | 24 November |
|---|---|---|---|---|
| 2 October | 1 | 0.854 | 0.816 | 0.845 |
| 4 October | 0.854 | 1 | 0.822 | 0.871 |
| 22 November | 0.816 | 0.822 | 1 | 0.909 |
| 24 November | 0.845 | 0.871 | 0.909 | 1 |
| Time | Flow (Vehicles) | Average Velocity (km/h) | Average Occupancy Od | Status |
|---|---|---|---|---|
| 1:00 | 3 | 74.9 | 4.2 | Normal |
| 1:01 | 1 | 62.5 | 1.9 | Normal |
| 1:02 | 4 | 72.7 | 5.8 | Normal |
| 1:03 | 1 | 0 | 1.6 | Abnormal |
| 1:04 | 5 | 68.5 | 7 | Normal |
| 1:05 | 7 | 71.5 | 11.6 | Normal |
| 1:06 | 3 | 66.2 | 5 | Normal |
| 1:07 | 1 | 0 | 1.9 | Abnormal |
| 1:08 | 5 | 53.3 | 13 | Normal |
| 1:09 | 2 | 98 | 2.1 | Normal |
| 1:10 | 2 | 67.4 | 2.1 | Normal |
| 1:11 | 3 | 64 | 3.7 | Normal |
| 1:12 | 3 | 66.2 | 6 | Normal |
| 1:13 | 1 | 61.3 | 2.4 | Normal |
| 1:14 | 1 | 0 | 2.1 | Abnormal |
| 1:15 | 1 | 69.2 | 2 | Normal |
| 1:16 | 3 | 75.1 | 4.2 | Normal |
| 1:17 | 2 | 71.6 | 3.8 | Normal |
| r | Uni-KNN | Bi-KNN |
|---|---|---|
| Inverse distance | 0.7109 | 0.8033 |
| Rank-based | 0.7016 | 0.7911 |
| Average | 0.6652 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, M.; Liang, S.; Qin, Y. A Bidirectional Searching Strategy to Improve Data Quality Based on K-Nearest Neighbor Approach. Symmetry 2019, 11, 815. https://doi.org/10.3390/sym11060815
Ma M, Liang S, Qin Y. A Bidirectional Searching Strategy to Improve Data Quality Based on K-Nearest Neighbor Approach. Symmetry. 2019; 11(6):815. https://doi.org/10.3390/sym11060815
Chicago/Turabian StyleMa, Minghui, Shidong Liang, and Yifei Qin. 2019. "A Bidirectional Searching Strategy to Improve Data Quality Based on K-Nearest Neighbor Approach" Symmetry 11, no. 6: 815. https://doi.org/10.3390/sym11060815
APA StyleMa, M., Liang, S., & Qin, Y. (2019). A Bidirectional Searching Strategy to Improve Data Quality Based on K-Nearest Neighbor Approach. Symmetry, 11(6), 815. https://doi.org/10.3390/sym11060815