Multivariate Chemometrics as a Strategy to Predict the Allergenic Nature of Food Proteins



Abstract
:
1. Introduction
2. Materials and Methods
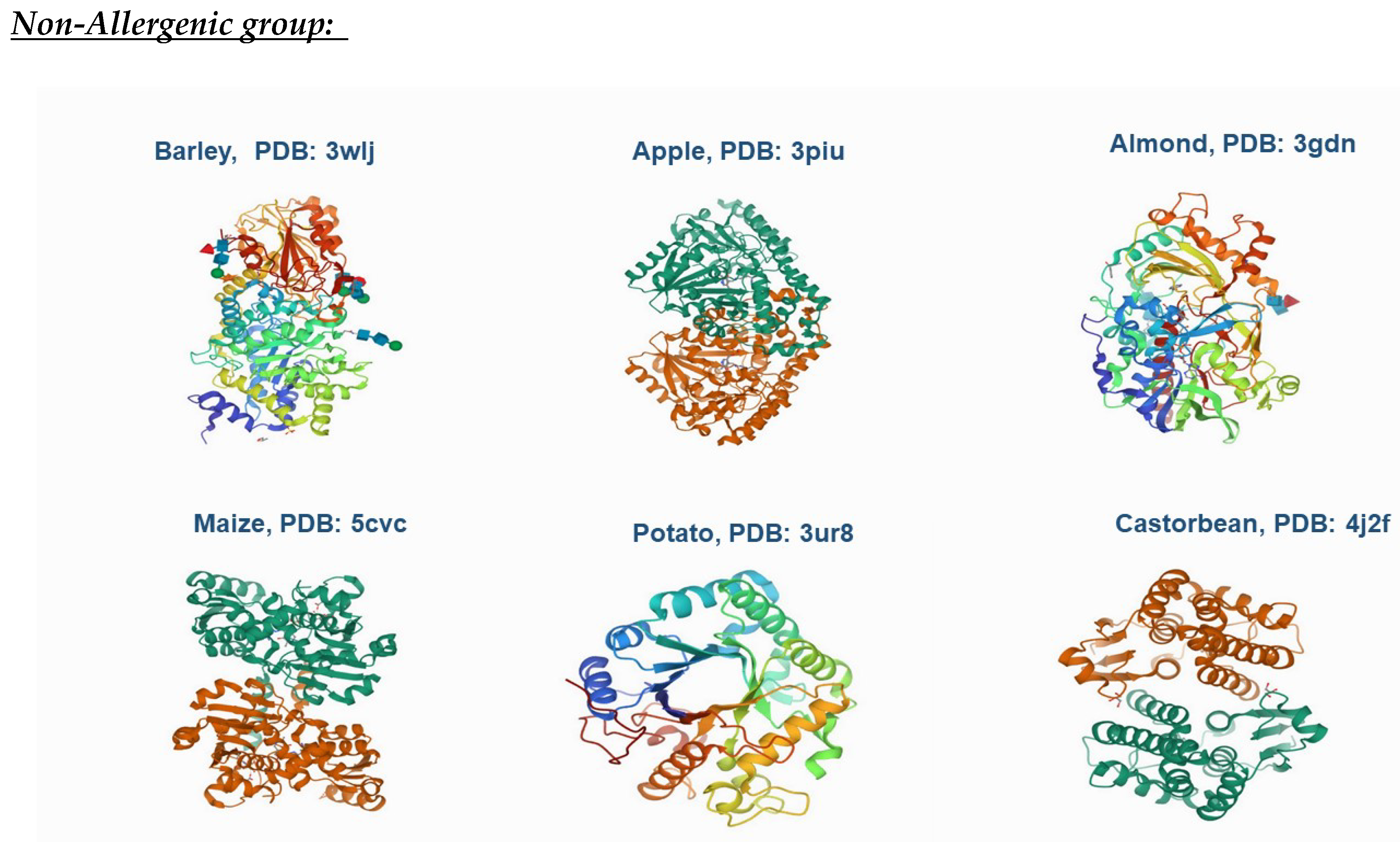
2.1. Data Preparation
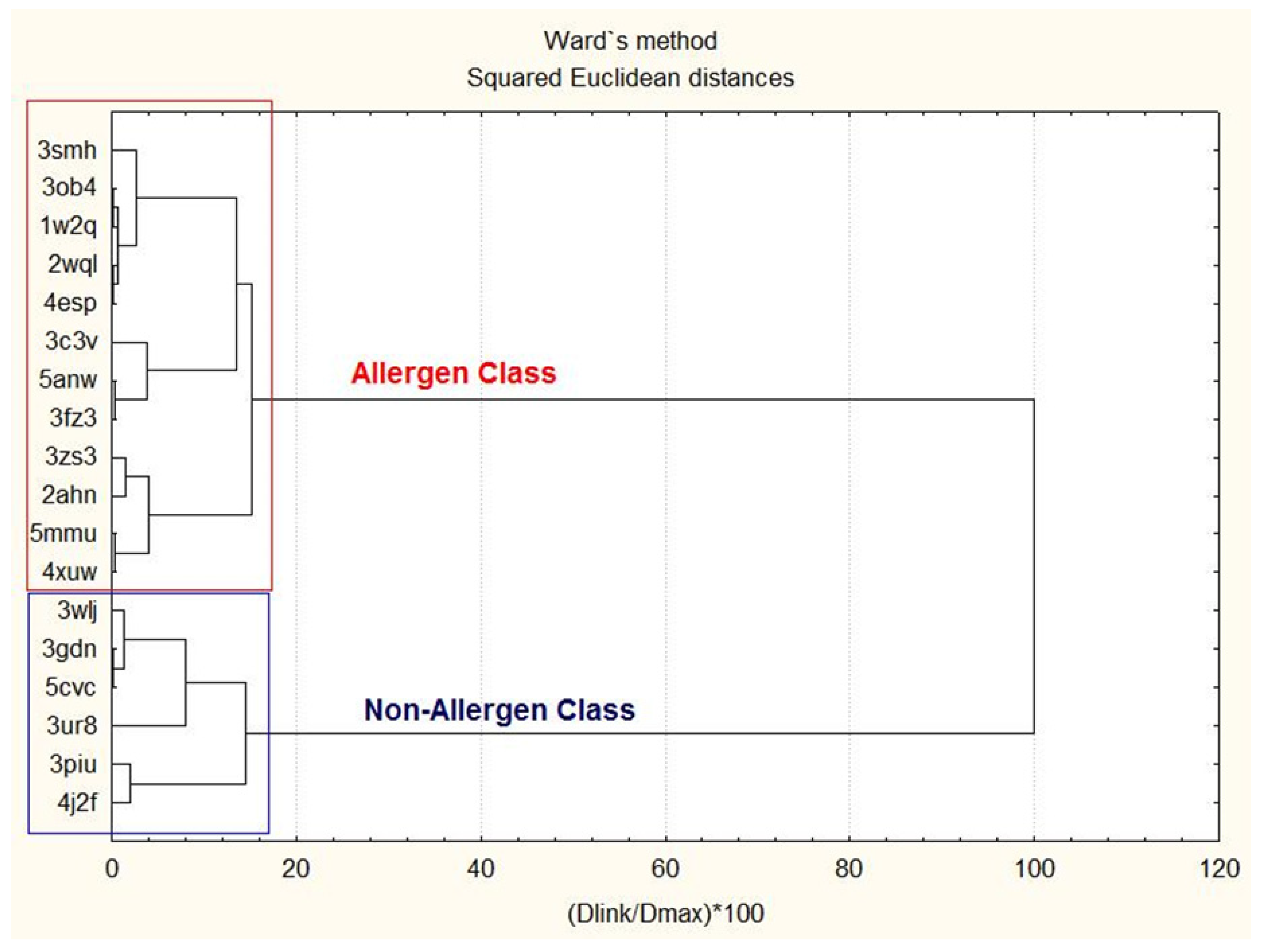
2.2. Cluster Analysis for Protein Separation
2.3. Principal Component Analysis for Protein Separation
3. Results and Discussion
3.1. Cluster Analysis for Protein Classification Based on 2D and 3D Molecular Descriptors
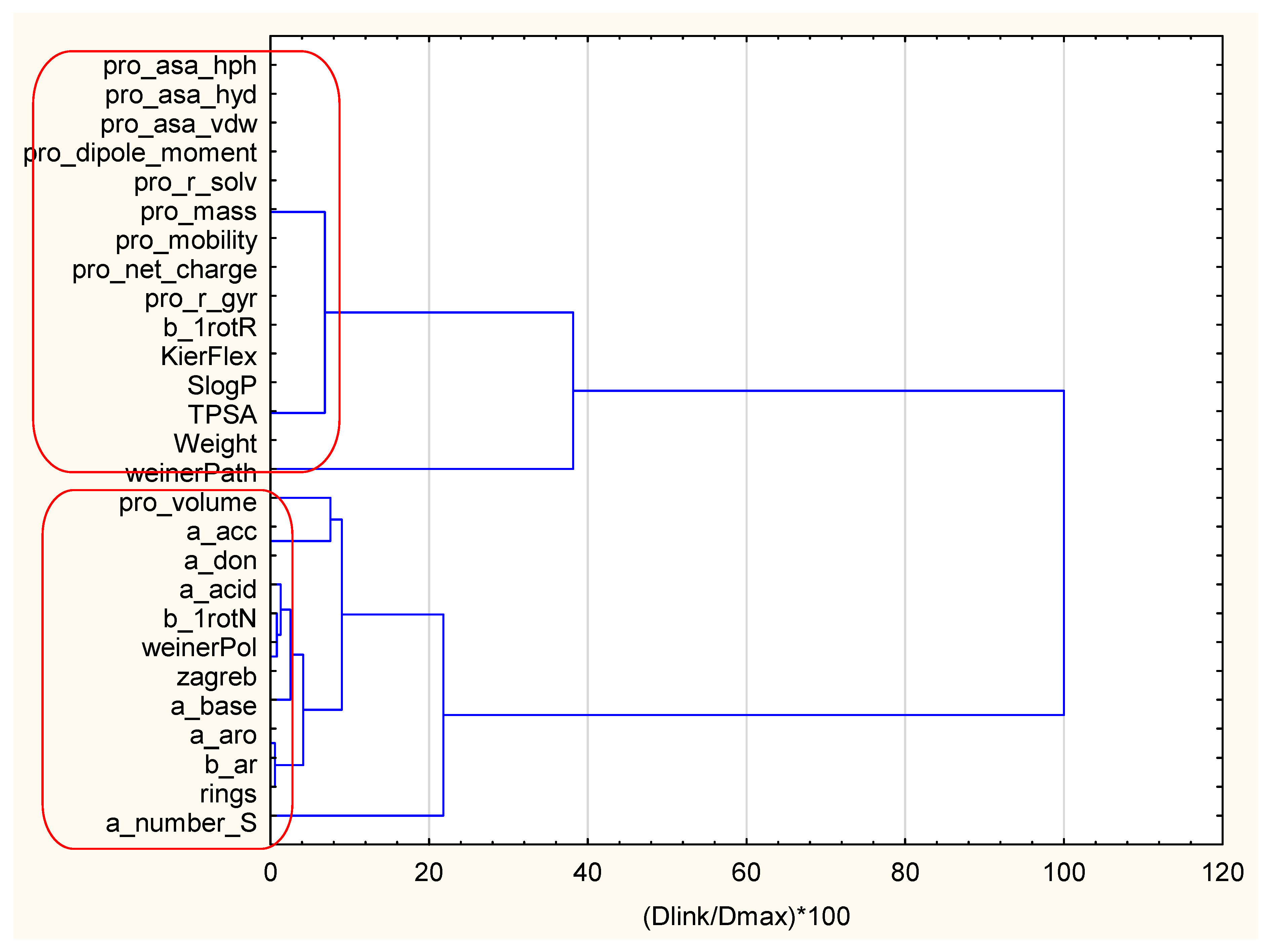
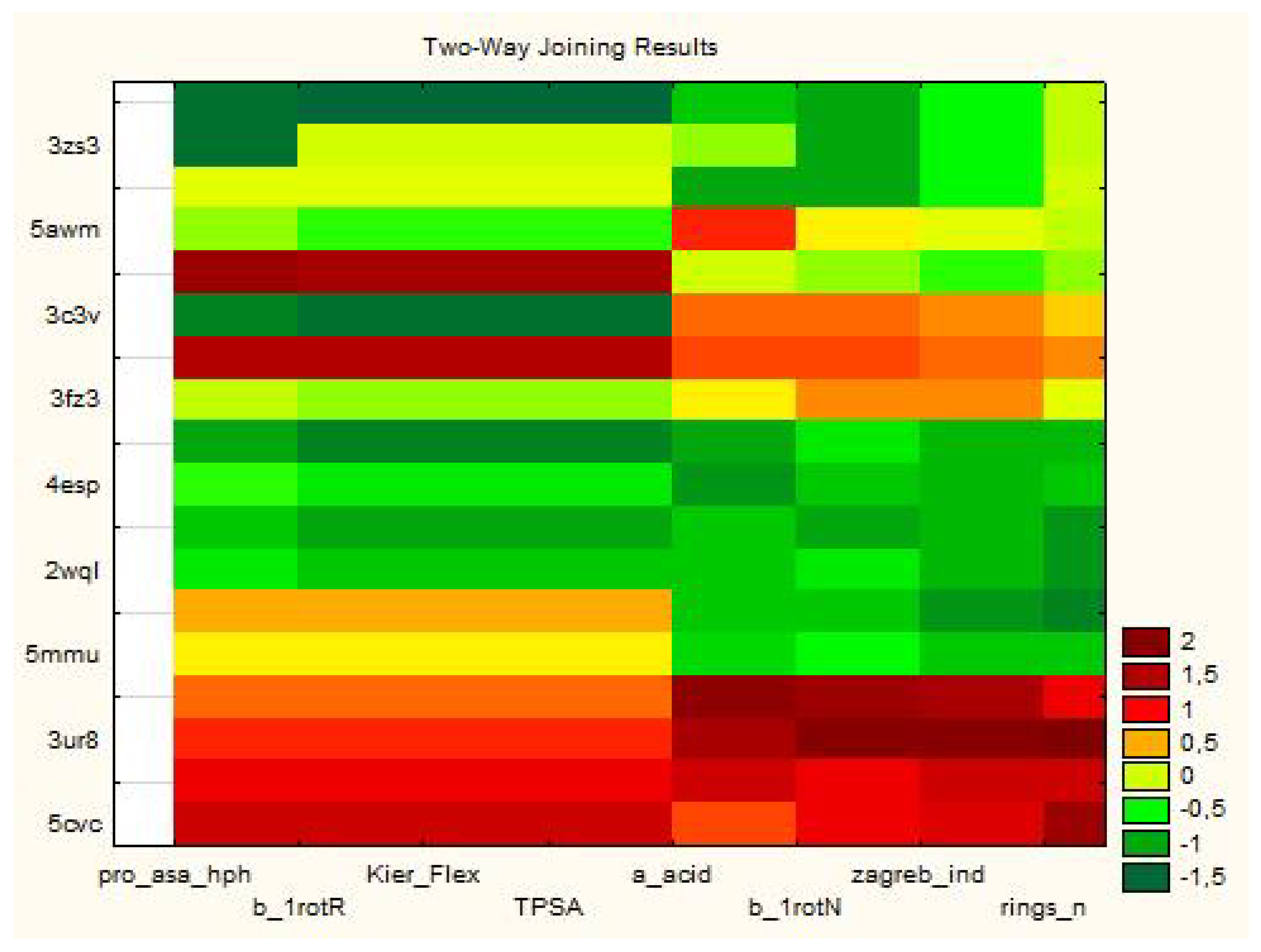
3.1.1. Two-Way Clustering
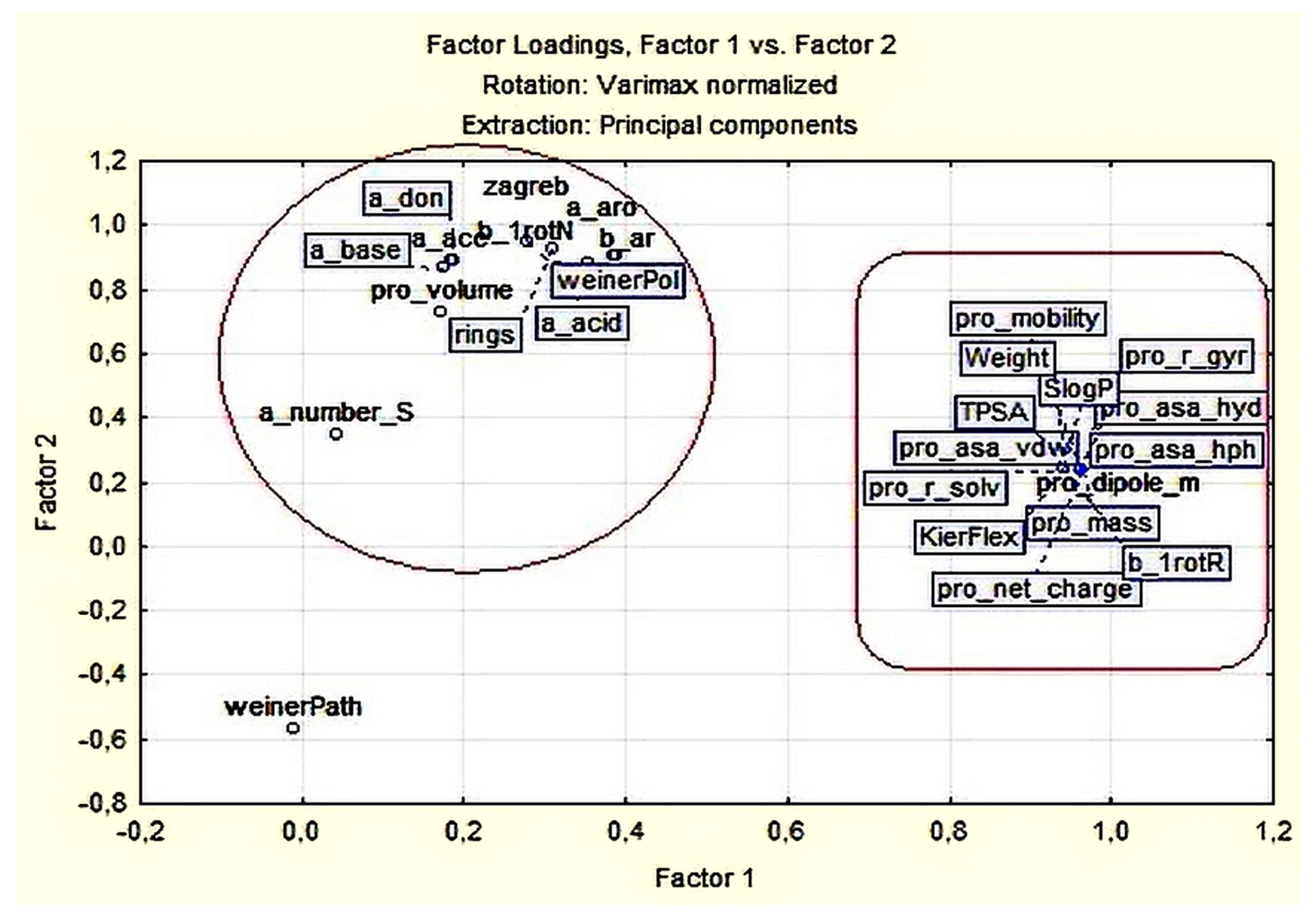
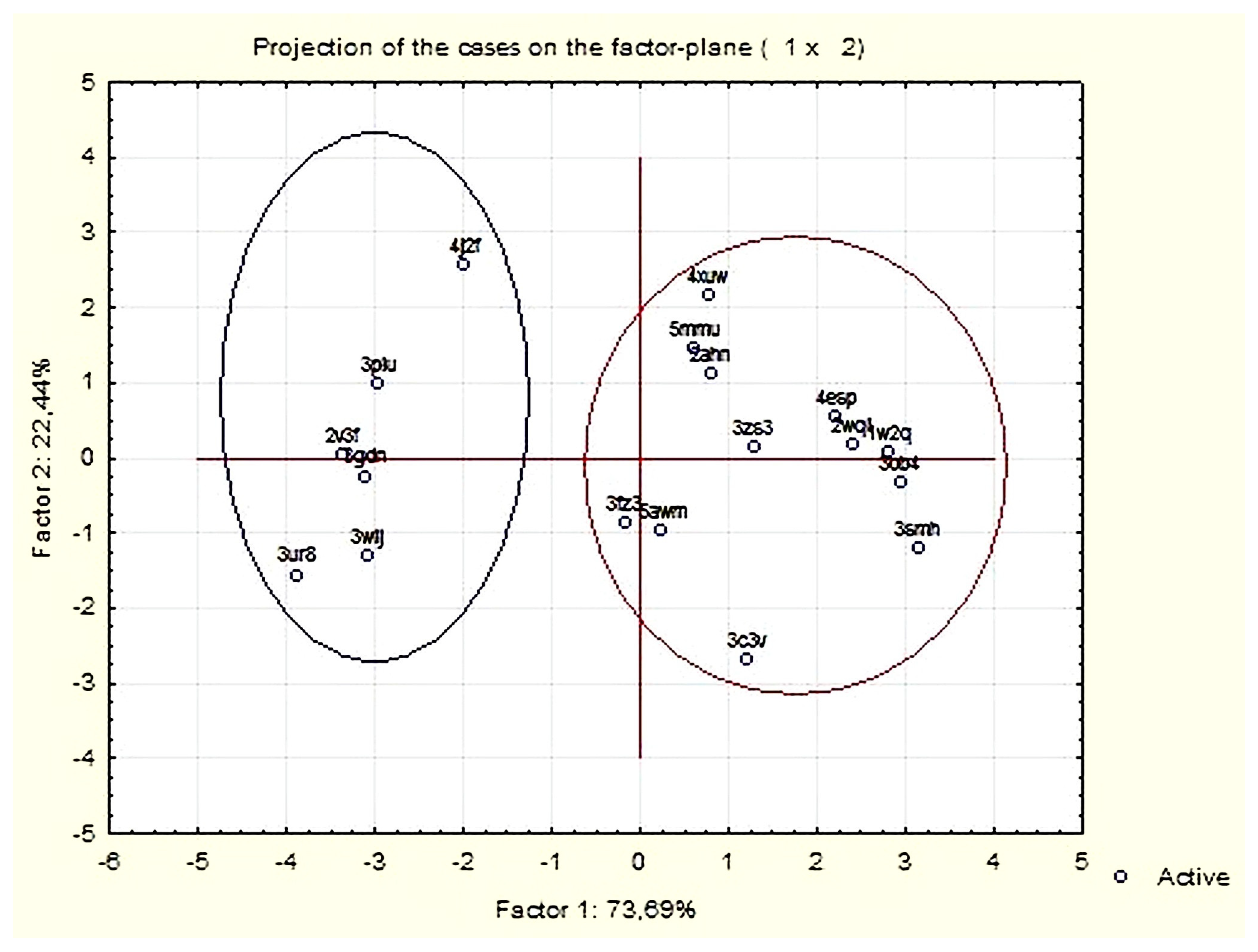
3.1.2. Principal Components and Factor Analysis
3.1.3. Data Mining with Reduced Number of Descriptors
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Anderson, A.; Shah, S.; Nurruzzaman, F. Increasing anaphylaxis hospitalizations in the first 2 decades of life: New York State, 1990–2006. Ann. Allergy Asthma Immunol. 2008, 101, 387–393. [Google Scholar]
- Branum, A.; Lukacs, S. Food Allergy Among Children in the United States. Pediatrics 2009, 124, 1549–1555. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gupta, R.; Kim, J.; Springston, E.; Pongracic, J.; Wang, X.; Holl, J. Development of the chicago food allergy research surveys: Assessing knowledge, attitudes, and beliefs of parents, physicians, and the general public. BMC Health Serv Res. 2009, 9, 142. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bock, S.; Munoz-Furlong, A.; Sampson, H.A. Fatalities due to anaphylactic reactions to foods. J. Allergy Clin. Immunol. 2001, 107, 191–193. [Google Scholar] [CrossRef] [PubMed]
- Maleki, S.J.; Schmitt, D.A.; Galeano, M.; Hurlburt, B.K. Comparison of the Digestibility of the Major Peanut Allergens in Thermally Processed Peanuts and in Pure Form. Foods 2014, 3, 290–303. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dyer, S.; Nesbit, J.B.; Cabanillas, B.; Cheng, H.; Hurlburt, B.K.; Maleki, S.J. Contribution of chemical modifications and conformational epitopes to ige binding by ara h 3. Foods 2018, 7, 189. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Naneva, L.; Nedyalkova, M.; Madurga, S.; Mas, F.; Simeonov, V. Applying Discriminant and Cluster Analyses to Separate Allergenic from Non-Allergenic Proteins. Open Chem. 2019, 17, 401–407. [Google Scholar] [CrossRef]
- Krause, A.; Stoye, J.; Vingron, M. Large scale hierarchical clustering of protein sequences. BMC 2005, 6, 15–26. [Google Scholar]
- Paccanaro, A.; Casbon, J.A.; Saqi, M.A. Spectral clustering of protein sequences. Nucleic Acids Res. 2006, 34, 1571–1580. [Google Scholar] [CrossRef] [PubMed]
- Kelil, A.; Wang, S.; Brzezinski, R.; Fleury, A. CLUSS: Clustering of protein sequences based on a new similarity measure. BMC Bioinform. 2007, 8, 286. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yu, C.; Deng, M.; Cheng, S.Y.; Yau, S.C.; He, R.L.; Yau, S.S. Protein space: A natural method for realizing the nature of protein universe. J. Theor. Biol. 2013, 318, 197–204. [Google Scholar] [CrossRef] [PubMed]
- Steinegger, M.; Söding, J. Clustering huge protein sequence sets in linear time. Nat. Commun. 2018, 9, 2542. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gasteiger, J. Chemoinformatics: Achievements and Challenges, a Personal View. Molecules 2016, 21, 151. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Engel, T. Basic Overview of Chemoinformatics. J. Chem. Inf. Model. 2006, 46, 2267–2277. [Google Scholar] [CrossRef] [PubMed]
- Peña-Castillo, A.; Méndez-Lucio, O.; Owen, J.R.; Martínez-Mayorga, K.; Medina-Franco, J.L. Chemoinformatics in Food Science. In Applied Chemoinformatics; Engel, T., Gasteiger, J., Eds.; John Wiley and Sons: Hoboken, NJ, USA, 2020. [Google Scholar]
- Massart, D.L.; Kaufman, L. The Interpretation of Analytical Chemical Data by the Use of Cluster Analysis; John Wiley and Sons: Hoboken, NJ, USA, 1989. [Google Scholar]
- Vandeginste, B.; Massart, D.; De Jong, S.; Massaart, D.; Buydens, L. Handbook of Chemometrics And Qualimetrics: Part B; Elsevier: Amsterdam, The Netherlands, 1998. [Google Scholar]
- Bartholomew, D.J. Principal Components Analysis. In International Encyclopedia of Education, 3rd ed.; Peterson, P., Baker, E., Mc Gaw, B., Eds.; Elsevier: Amsterdam, The Netherlands, 2010; pp. 374–377. ISBN 9780080448947. [Google Scholar] [CrossRef]
- Guarino, C.; Sciarrillo, R. The identification of allergen proteins in two different varieties of strawberry by two different approaches: Proteomic and western blotting method. Ann. Agric. Sci. 2018, 63, 181–189. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CODE | DESCRIPTION |
|---|---|
| pro_asa_hph | Water accessible surface area of all hydrophobic (|qi| < 0.2) atoms. |
| pro_asa_hyd | Water accessible surface area of all hydrophilic (|qi| < 0.2) atoms. |
| pro_vdw | Van der Waals surface area |
| pro_dipole_moment | Dipole moment calculated from the partial charges of the molecule. |
| dens | Mass density: molecular weight divided by van der Waals volume as calculated in the vol descriptor. |
| pro_mobility | mobility |
| pro_charge | Total charge of the molecule (sum of formal charges). |
| pro_r_gyr | Radius of gyration. |
| pro_r_solv | Radius of cross-section |
| pro_volume | van der Waals volume calculated using a grid approximation (spacing 0.75 A). |
| a_acc | Hydrogen bond acceptor atoms (number) |
| a_acid | Number of acidic atoms. |
| a_aro | Number of aromatic atoms. |
| a_base | Number of basic atoms. |
| a_don | Number of hydrogen bond donor atoms (not counting basic atoms but counting atoms that are both hydrogen bond donors and acceptors such as -OH). |
| b_1rotR | Fraction of rotatable single bonds: b_1rotN divided by b_heavy. |
| KierFlex | Kier molecular flexibility index: (KierA1) (KierA2) / n |
| rings | The number of rings. |
| SlogP | Log of the octanol/water partition coefficient (including implicit hydrogens). |
| TPSA (topological polar surface area based on fragments) | Polar surface area (Å2) calculated using group contributions to approximate the polar surface area from connection table information only. |
| Weight | Molecular weight (including implicit hydrogens) |
| weinerPath | Wiener path number |
| weinerPol | Wiener polarity number |
| Zagreb index | Zagreb index: the sum of di2 over all heavy atoms i. |
| Variable (2D Descriptors) | Members of Cluster Number 1 and Distances from Respective Cluster Center Cluster Contains 15 Variables |
| Distance | |
| pro_asa_hph | 0.149240 |
| pro_asahyd | 0.149240 |
| pro_asa_vdw | 0.149240 |
| pro_dipole_moment | 0.149240 |
| pro_mass | 0.149240 |
| pro_mobility | 0.149240 |
| pro_net_charge | 0.149240 |
| pro_r_gyr | 0.149240 |
| pro_r_solv | 0.149240 |
| B_1rotR | 0.243133 |
| KierFlex | 0.243133 |
| SlogP | 0.243133 |
| TPSA | 0.243133 |
| Variable (2D Descriptors) | Members of Cluster Number 2 and Distances from Respective Cluster Center Cluster Contains 12 Variables |
| Distance | |
| pro_volume | 0.649643 |
| a_acc | 0.413425 |
| a_acid | 0.382602 |
| a_aro | 0,230073 |
| a_base | 0.469422 |
| a_don | 0.418075 |
| a_number_S | 1.026357 |
| b_1rotN | 0.322417 |
| b_ar | 0.231530 |
| rings | 0.236831 |
| weinerPol | 0.180442 |
| zagreb | 0.178149 |
| Proteins | Members of Cluster Number 1 and Distances from Respective Cluster Center Cluster Contains 6 Cases |
|---|---|
| Distance | |
| 3wlj | 0.624337 |
| 3ur8 | 0.919784 |
| 3gdn | 0.250043 |
| 2v3f | 0.266641 |
| 3piu | 0.357769 |
| 4j2f | 0.929623 |
| Proteins | Members of Cluster Number 2 and Distances from Respective Cluster Center Cluster Contains 12 Cases |
|---|---|
| Distance | |
| 3smh | 0.745996 |
| 3c3v | 0.895197 |
| 2c3b | 0.491340 |
| 1w2q | 0.492303 |
| 2wql | 0.569632 |
| 3vor | 0.343808 |
| 5amw | 0.490781 |
| 3fz3 | 0.660688 |
| 3zs3 | 0.633154 |
| 2ahn | 0.616859 |
| 5mmu | 0.672782 |
| 4cpv | 0.928246 |
| Variable | Factor Loadings (Varimax Normalized) Extraction: Principal Components (Marked Loadings are >0.700000) | |
|---|---|---|
| Factor 1 | Factor 2 | |
| pro_mass | 0.96464 | 0.236248 |
| pro_mobility | 0.96464 | 0.236248 |
| pro_net_charge | 0.96464 | 0.236248 |
| pro_r_gyr | 0.96464 | 0.236248 |
| pro_r_solv | 0.96464 | 0.236248 |
| pro_volume | 0.17264 | 0.728891 |
| a_acc | 0.18398 | 0.890058 |
| a_acid | 0.31796 | 0.867425 |
| a_aro | 0.38478 | 0.907553 |
| a_base | 0.17497 | 0.864993 |
| a_don | 0.18896 | 0.886082 |
| a_number_S | 0.04313 | 0.346071 |
| b_1rotN | 0.35525 | 0.884013 |
| b_1rotR | 0.94226 | 0.244491 |
| b_ar | 0.38999 | 0.905283 |
| KierFlex | 0.94226 | 0.244491 |
| rings | 0.31002 | 0.924282 |
| SlogP | 0.94226 | 0.244491 |
| TPSA | 0.94226 | 0.244491 |
| Weight | 0.94226 | 0.244491 |
| weinerPath | −0.00924 | −0.568203 |
| weinerPol | 0.27742 | 0.948778 |
| zagreb | 0.27791 | 0.949411 |
| Expl. Var % | 50.83 | 36.79 |
| Variable | Factor Loadings (Varimax Normalized) Extraction: Principal Components (Marked Loadings are >0.700000) | |
|---|---|---|
| Factor 1 | Factor 2 | |
| pro_asa_hph | 0.920048 | 0.292616 |
| a_acid | 0.272915 | 0.923270 |
| b_1rotN | 0.282057 | 0.936526 |
| b_1rotR | 0.959852 | 0.268366 |
| KierFlex | 0.959852 | 0.268366 |
| TPSA | 0.959852 | 0.268366 |
| rings | 0.294110 | 0.903245 |
| zagreb | 0.232500 | 0.968740 |
| Expl. Var % | 48.81 | 47.32 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nedyalkova, M.; Simeonov, V. Multivariate Chemometrics as a Strategy to Predict the Allergenic Nature of Food Proteins. Symmetry 2020, 12, 1616. https://doi.org/10.3390/sym12101616
Nedyalkova M, Simeonov V. Multivariate Chemometrics as a Strategy to Predict the Allergenic Nature of Food Proteins. Symmetry. 2020; 12(10):1616. https://doi.org/10.3390/sym12101616
Chicago/Turabian StyleNedyalkova, Miroslava, and Vasil Simeonov. 2020. "Multivariate Chemometrics as a Strategy to Predict the Allergenic Nature of Food Proteins" Symmetry 12, no. 10: 1616. https://doi.org/10.3390/sym12101616
APA StyleNedyalkova, M., & Simeonov, V. (2020). Multivariate Chemometrics as a Strategy to Predict the Allergenic Nature of Food Proteins. Symmetry, 12(10), 1616. https://doi.org/10.3390/sym12101616