Automated Sustainable Multi-Object Segmentation and Recognition via Modified Sampling Consensus and Kernel Sliding Perceptron



Abstract
:1. Introduction
- Modified maximum likelihood estimation sampling consensus is proposed for the segmentation of depth objects.
- To reduce the dimensions of feature sets, and for better accuracy and efficiency, Isometric Mapping (IsoMap) is used.
- To recognize single and multiple objects in an image, a collective set of descriptors named depth kernel descriptors (DKDES) is applied to three benchmark datasets.
- To the best of our knowledge, the integrated KSP multi-depth kernel descriptor for identification of multiple objects is originally introduced here.
- To evaluate the reliability and consistency of the proposed system, a comprehensive statistical study is performed and compared with the latest methods.
2. Related Work
2.1. Sustainable Multi-Objects Segmentation via RGB Images
2.2. Sustainable Multi-Object Recognition via RGB Images
2.3. Sustainable Multi-Object Segmentation via Depth Images
2.4. Sustainable Multi-Objects Recognition via Depth Images
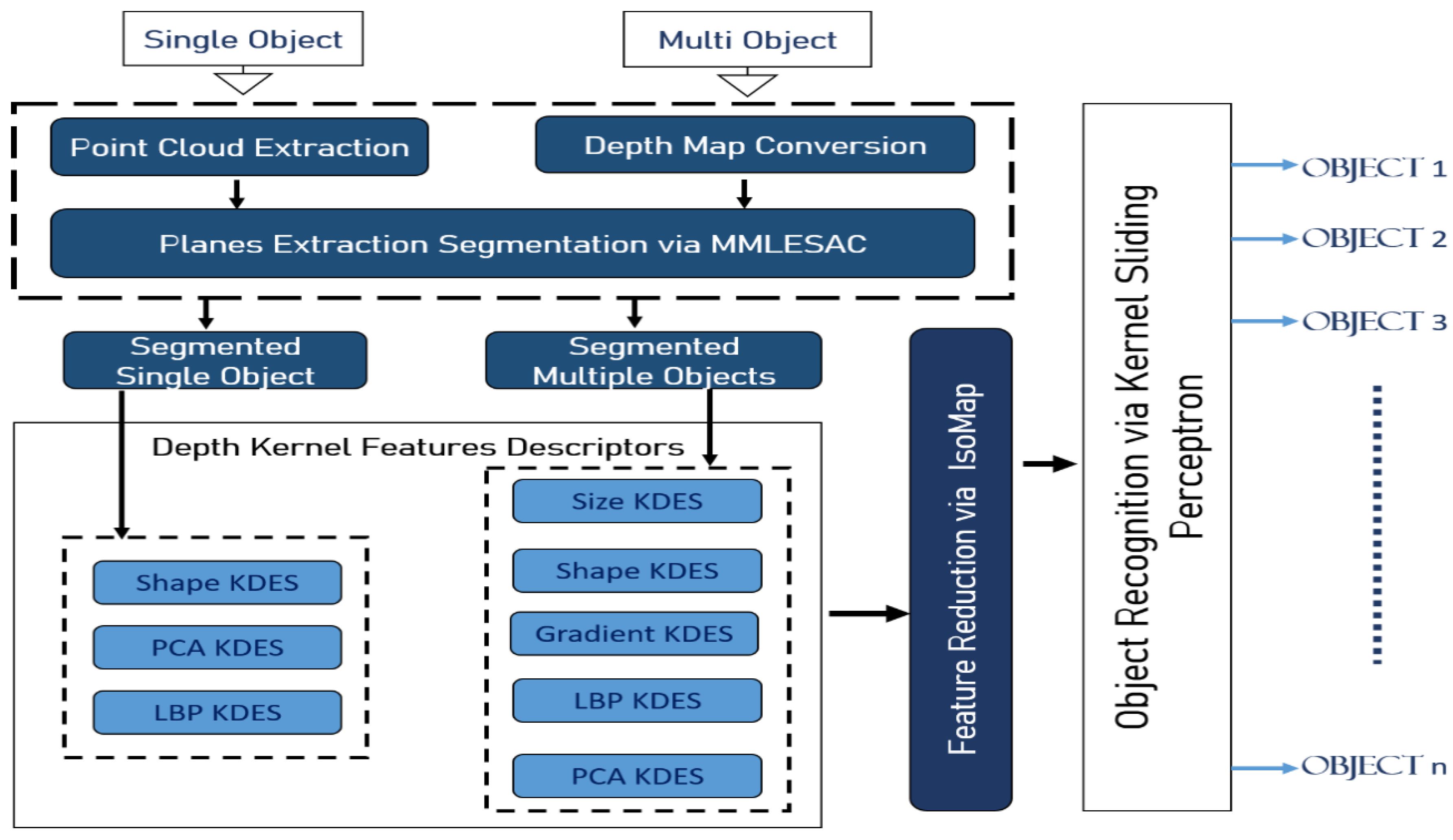
3. Proposed System Methodology
3.1. Image Acquisition and Preprocessing
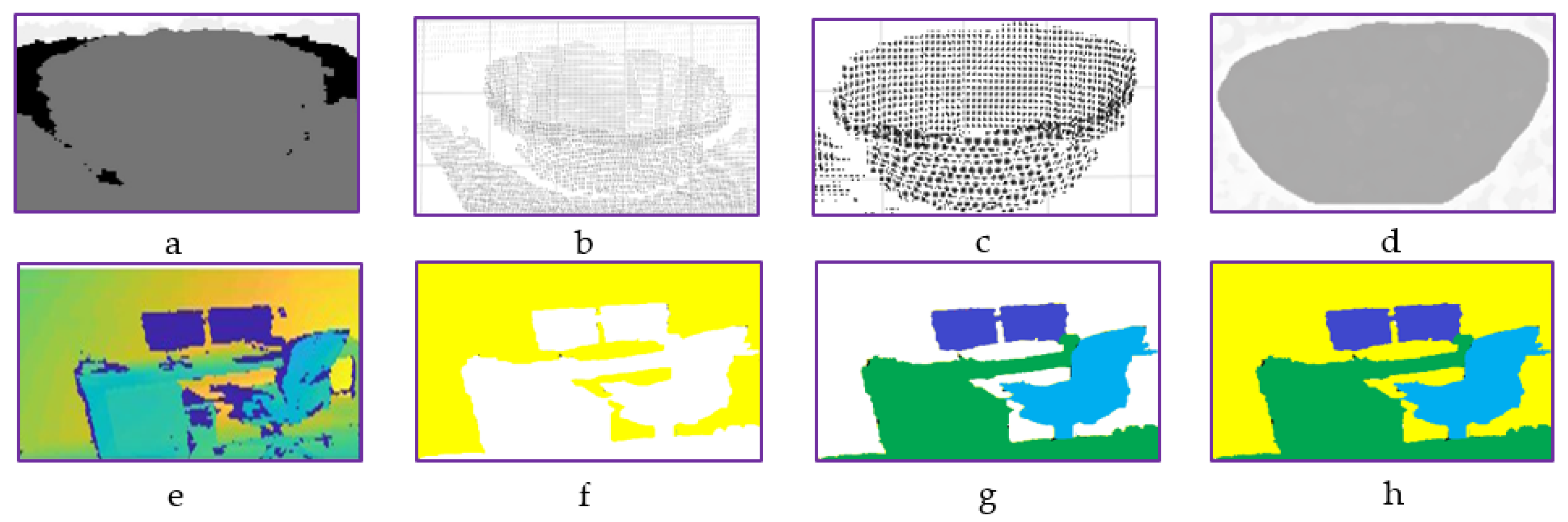
3.2. Objects Segmentation
3.2.1. Single-Object Segmentation Using Point Cloud
3.2.2. Multi-Objects Segmentation Using MMLESAC
Maximum Likelihood Estimation (MLE)
Modified Maximum Likelihood Estimation Sample Consensus (MMLESAC)
| Algorithm 1. Modified Maximum Likelihood Estimation Sample Consensus (MMLESAC). |
 |
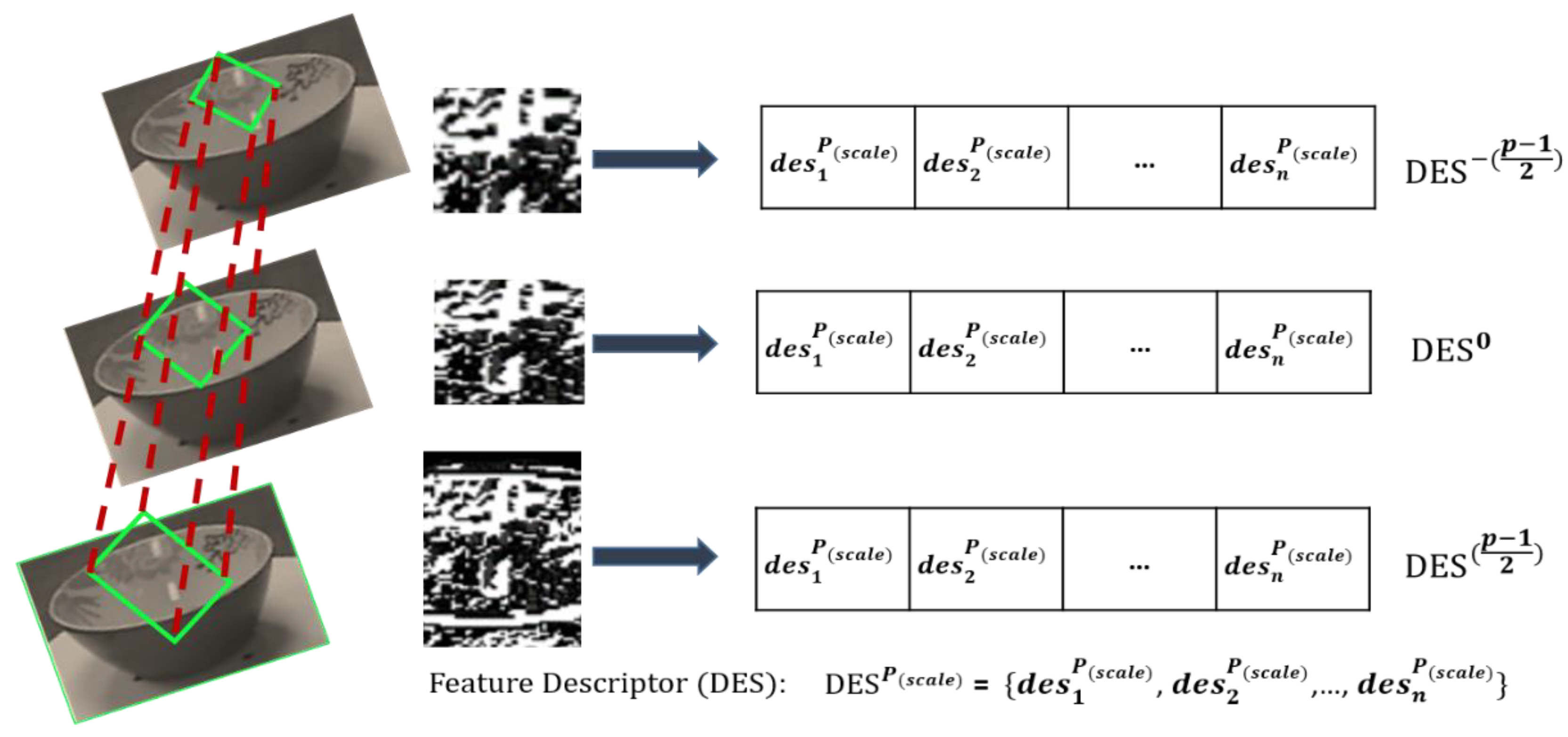
3.3. Feature Extraction via DKDES over Segmented Objects
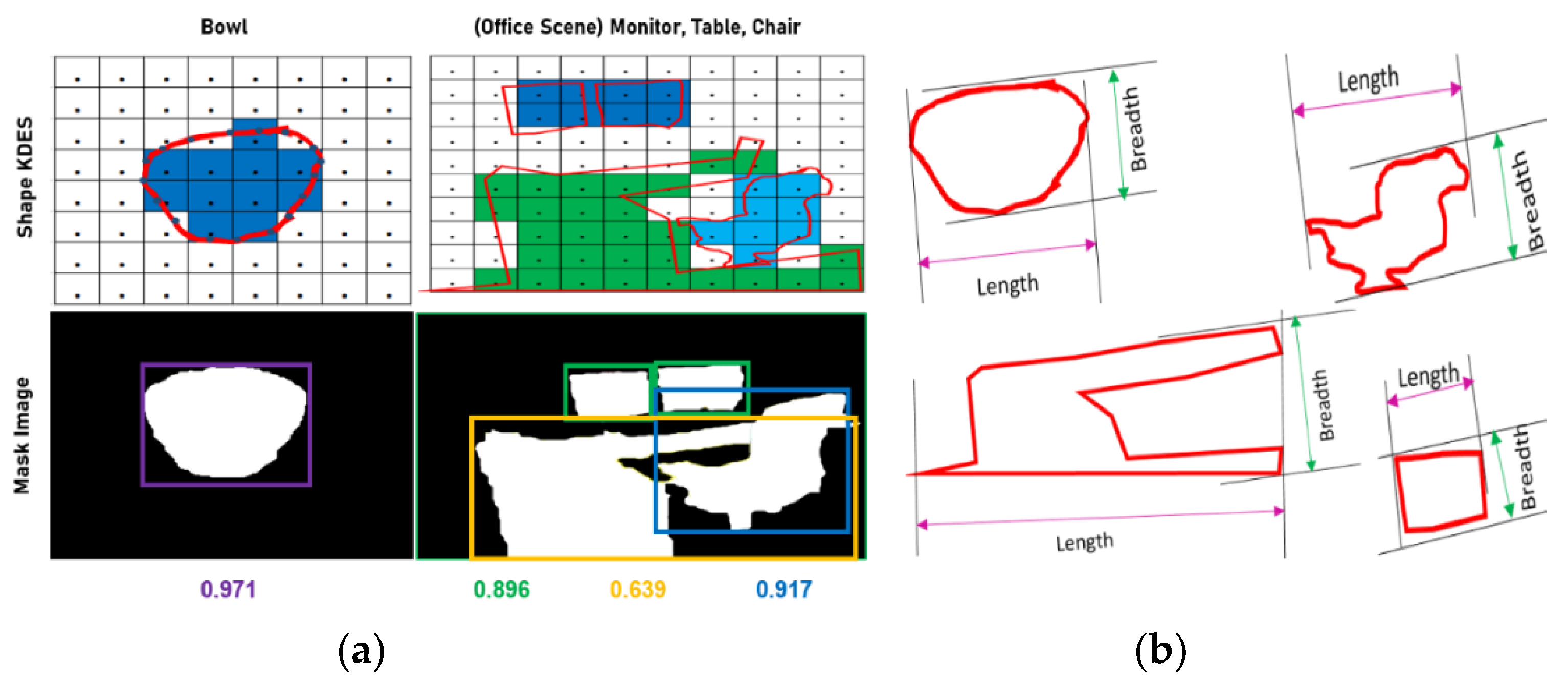
3.3.1. Size Kernel Descriptor over Segmented Objects
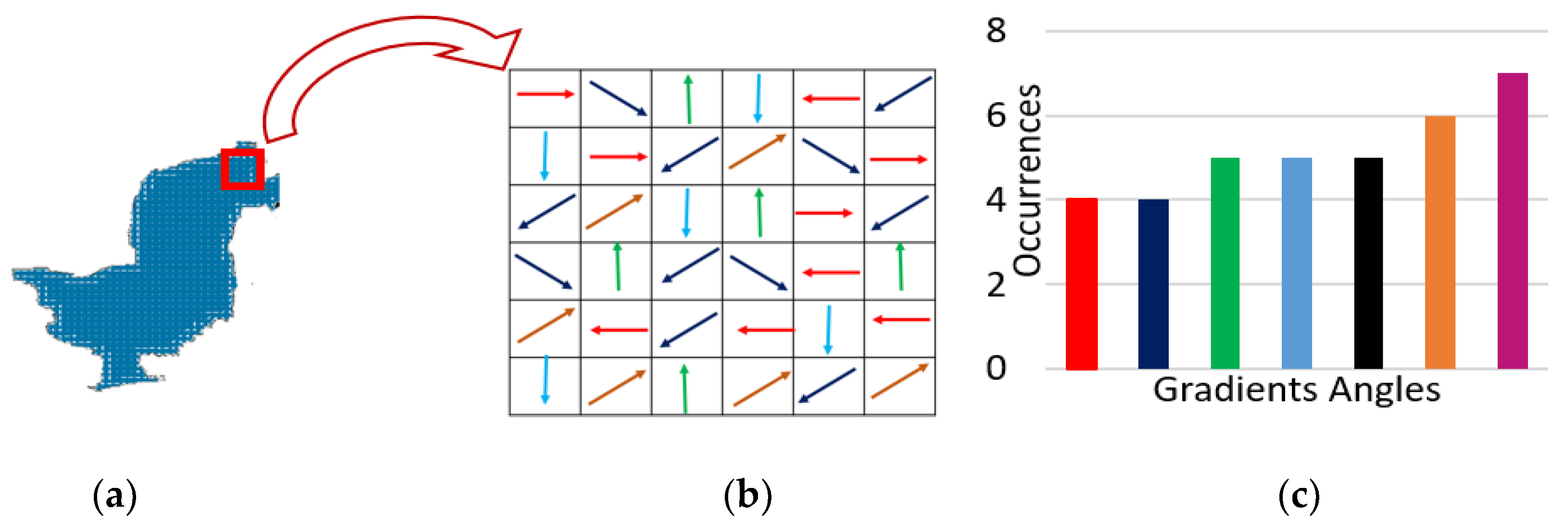
3.3.2. Gradient Kernel Descriptor over Segmented Objects
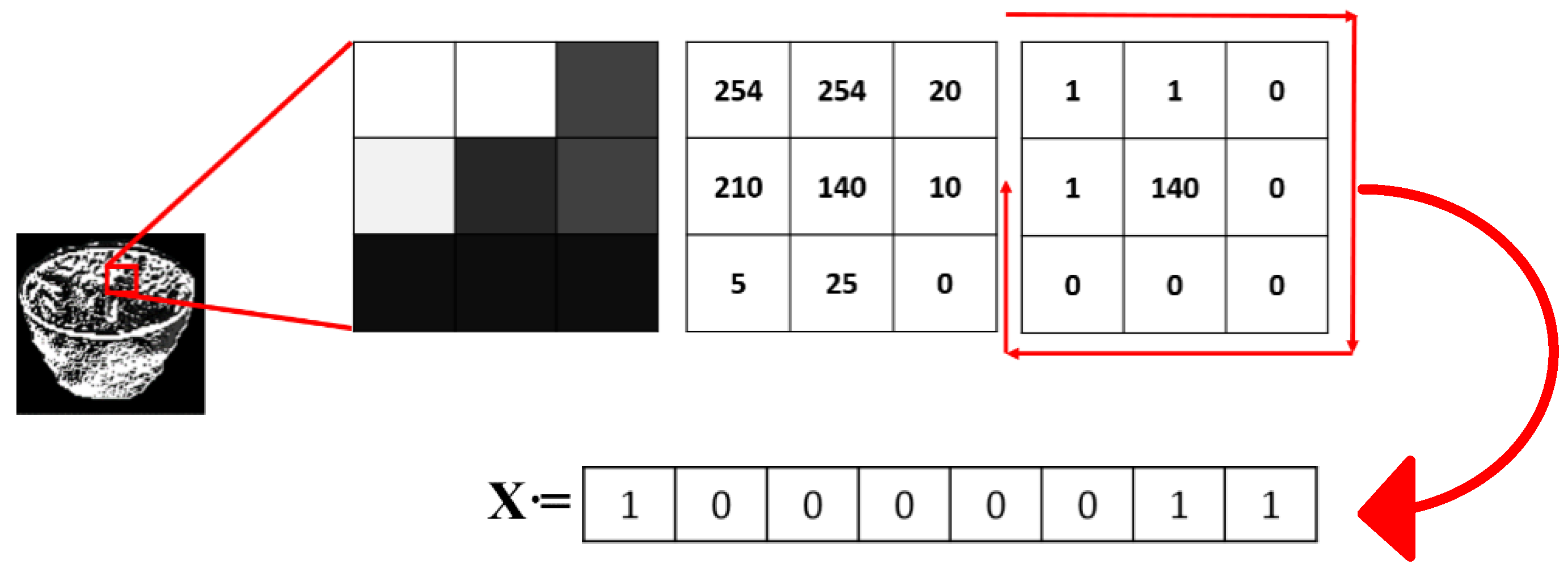
3.3.3. LBP Kernel Descriptor over Segmented Objects
3.3.4. Kernel Principal Copponent Aanalysis (PCA) and Shape Kernel Descriptor over Segmented Objects
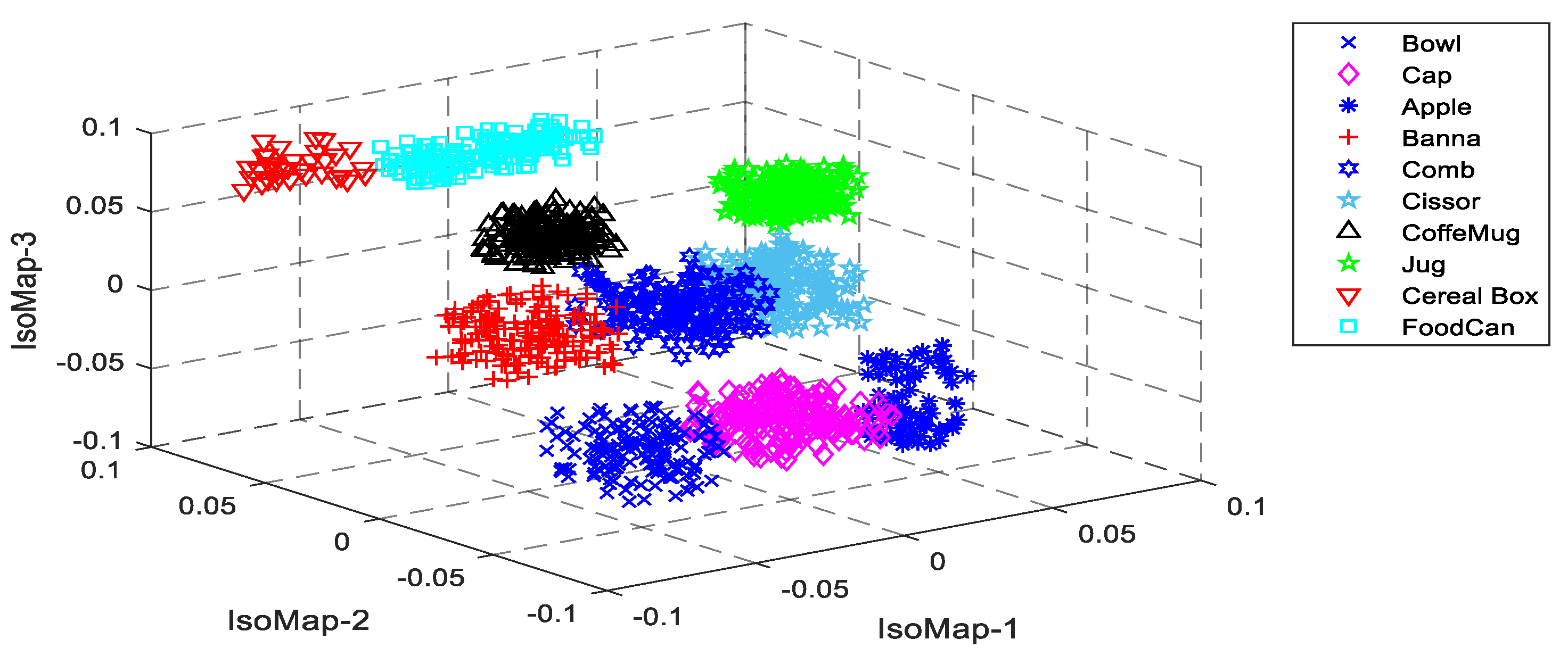
3.4. Feature Reduction using IsoMap
| Algorithm 2. Feature Extraction and Reduction. |
 |
3.5. Multi-Object Recognition
| Algorithm 3. Multi-Object Recognition by Kernel Sliding Perceptron (KSP). |
| 1: Input: Reduced features set from RGB-D images 2: Output: Yj Recognized Multi-object in a RGB-D image 3: % set Max. # of repetitions% 4: m = number of repetitions 5: Initialize for every j 6: WHILE ((t) and k <= n) a. t = 0; b. for (k = 1: m) i. if ii. t = t + 1; iii. + iv. end c. end 7: k = k + 1; 8: end 9: return Y |
4. Experimental Setup and Results
4.1. Datasets Descriptions
4.1.1. The RGB-D Object Dataset
4.1.2. The RGB-D Scenes Dataset
4.1.3. The NYU-Dv1 Dataset
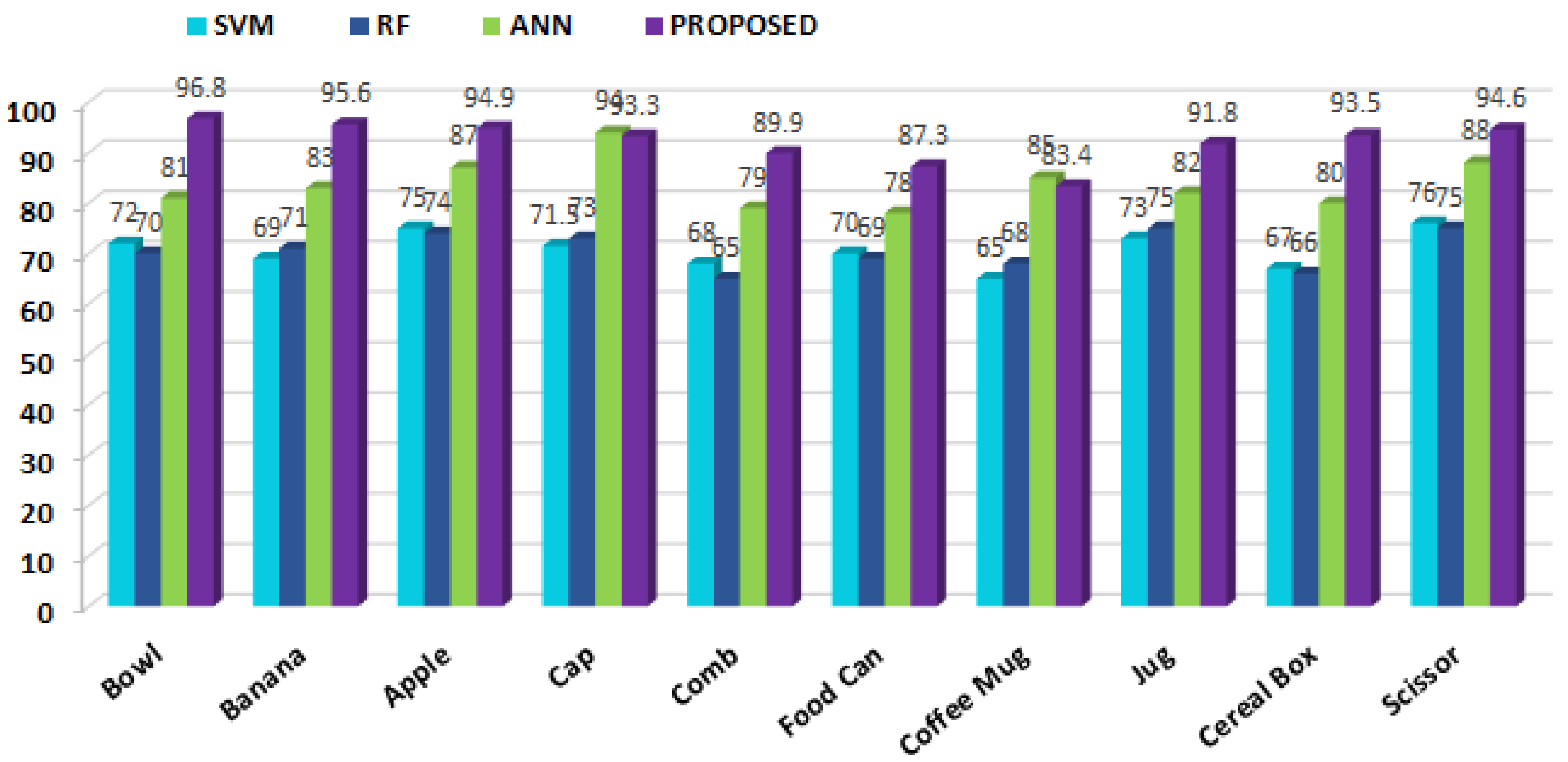
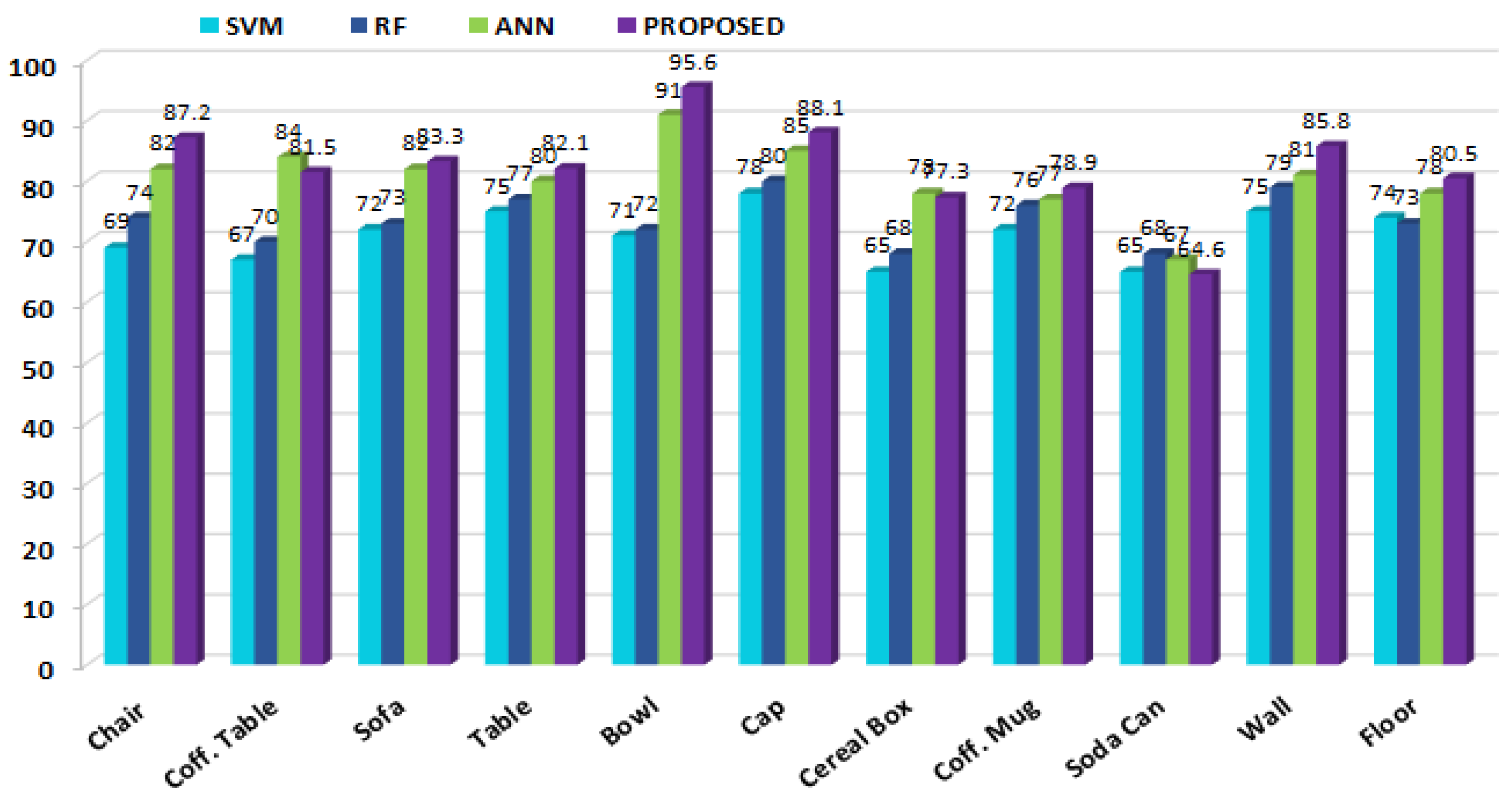
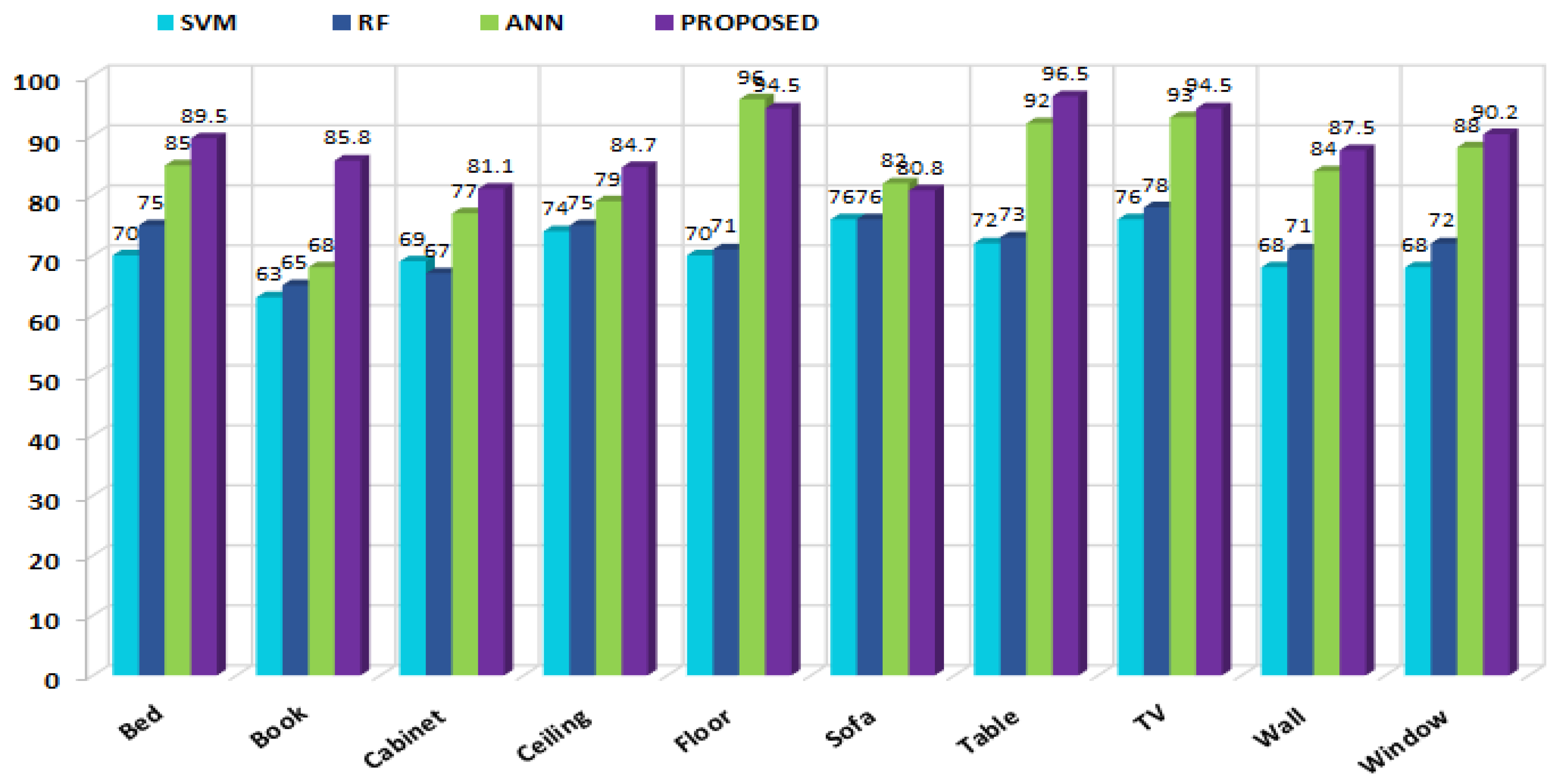
4.2. First Experiment: Recognition Accuracy
4.2.1. Experimental Setup
4.2.2. Observations
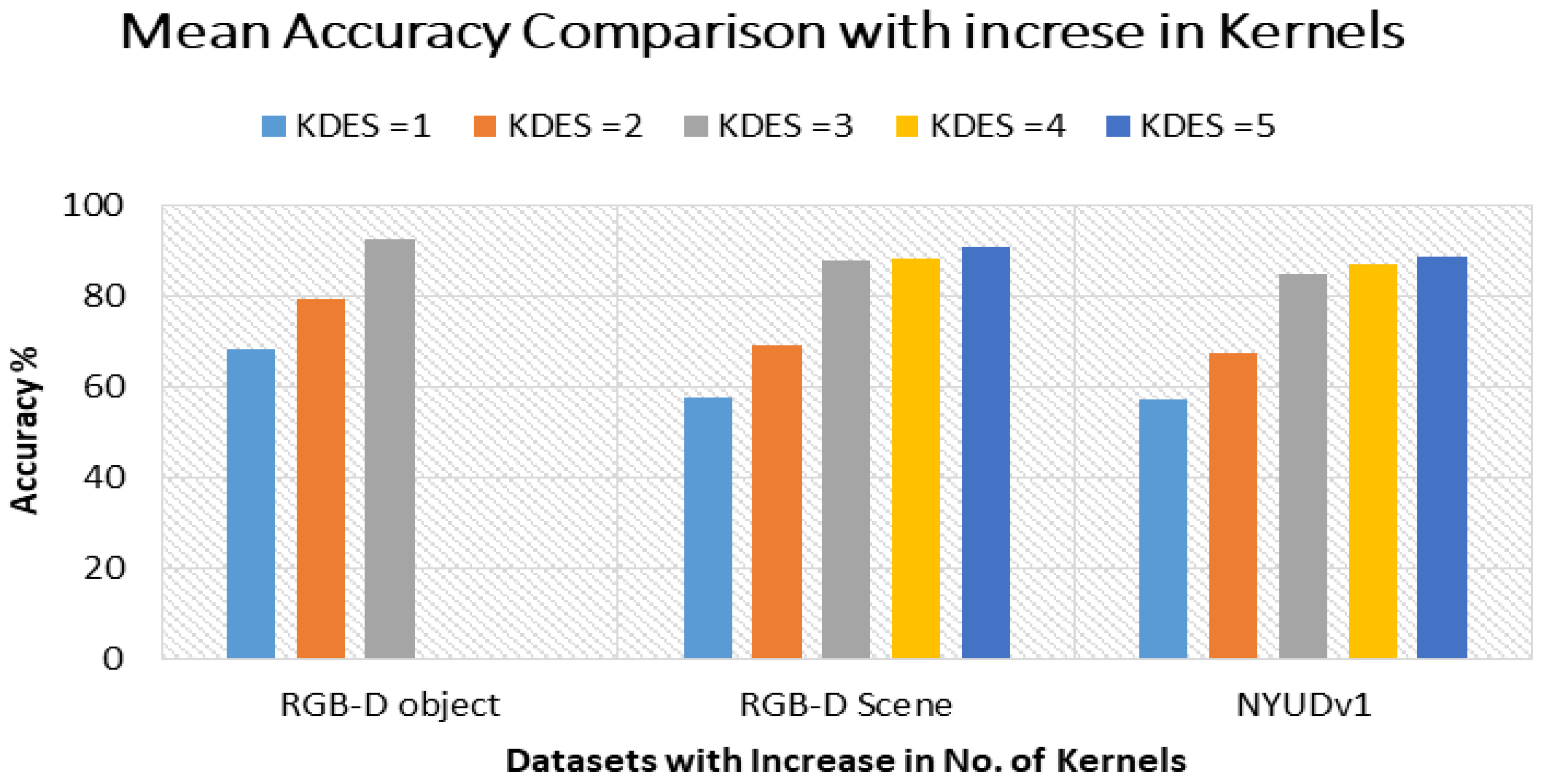
4.3. Second Experiment: Level of Kernels
Experimental Setup
4.4. The Third Experiment: Conventional Methods vs. the Proposed Method
4.4.1. Experimental Setup
4.4.2. Observations
4.5. Fourth Experiment: Comparison with the Latest Techniques
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ly, H.-B.; Le, T.-T.; Vu, H.-L.T.; Tran, V.Q.; Le, L.M.; Pham, B.T. Computational Hybrid Machine Learning Based Prediction of Shear Capacity for Steel Fiber Reinforced Concrete Beams. Sustainability 2020, 12, 2709. [Google Scholar] [CrossRef] [Green Version]
- Cioffi, R.; Travaglioni, M.; Piscitelli, G.; Petrillo, A.; De Felice, F. Artificial Intelligence and Machine Learning Applications in Smart Production: Progress, Trends, and Directions. Sustainability 2020, 12, 492. [Google Scholar] [CrossRef] [Green Version]
- Buenestado, P.; Acho, L. Image Segmentation Based on Statistical Confidence Intervals. Entropy 2018, 20, 46. [Google Scholar] [CrossRef] [Green Version]
- Khan, M.W. A Survey: Image Segmentation Techniques. Int. J. Futur. Comput. Commun. 2014, 3, 89. [Google Scholar] [CrossRef] [Green Version]
- Dhanachandra, N.; Chanu, Y.J. A Survey on Image Segmentation Methods using Clustering Techniques. Eur. J. Eng. Res. Sci. 2017, 2, 15–20. [Google Scholar] [CrossRef] [Green Version]
- Alata, O.; Quintard, L. Is there a best color space for color image characterization or representation based on Multivariate Gaussian Mixture Model? Comput. Vis. Image Underst. 2009, 113, 867–877. [Google Scholar] [CrossRef]
- Pagola, M.; Ortiz, R.; Irigoyen, I.; Bustince, H.; Barrenechea, E.; Aparicio-Tejo, P.; Lamsfus, C.; Lasa, B. New method to assess barley nitrogen nutrition status based on image colour analysis. Comput. Electron. Agric. 2009, 65, 213–218. [Google Scholar] [CrossRef]
- Jurio, A.; Pagola, M.; Galar, M.; Lopez-Molina, C.; Paternain, D. A comparison study of different color spaces in clustering based image segmentation. In International Conference on Information Processing and Management of Uncertainty in Knowledge-Based Systems; Springer: Berlin/Heidelberg, Germany, 2010; pp. 532–541. [Google Scholar]
- Sinop, A.K.; Grady, L. A seeded image segmentation framework unifying graph cuts and random walker which yields a new algorithm. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Rashid, M.; Khan, M.A.; Alhaisoni, M.; Wang, S.-H.; Naqvi, S.R.; Rehman, A.; Saba, T. A Sustainable Deep Learning Framework for Object Recognition Using Multi-Layers Deep Features Fusion and Selection. Sustainability 2020, 12, 5037. [Google Scholar] [CrossRef]
- Ahmed, A.; Jalal, A.; Rafique, A.A. Salient Segmentation based Object Detection and Recognition using Hybrid Genetic Transform. In Proceedings of the 2019 International Conference on Applied and Engineering Mathematics (ICAEM), Taxila, Pakistan, 27–29 August 2019; pp. 203–208. [Google Scholar]
- Zia, S.; Yüksel, B.; Yuret, D.; Yemez, Y. RGB-D object recognition using deep convolutional neural networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Ahmed, A.; Jalal, A.; Kim, K. A Novel Statistical Method for Scene Classification Based on Multi-Object Categorization and Logistic Regression. Sensors 2020, 20, 3871. [Google Scholar] [CrossRef]
- Bo, L.; Ren, X.; Fox, D. Kernel descriptors for visual recognition. In Proceedings of the Advances in Neural Information Processing Systems 23: 24th Annual Conference on Neural Information Processing Systems 2010, Vancouver, BC, Canada, 6–9 December 2010; pp. 244–252. Available online: https://papers.nips.cc/paper/2010/hash/4558dbb6f6f8bb2e16d03b85bde76e2c-Abstract.html (accessed on 25 June 2020).
- Venkatrayappa, D.; Montesinos, P.; Diep, D.; Magnier, B. A novel image descriptor based on anisotropic filtering. In International Conference on Computer Analysis of Images and Patterns; Springer: Cham, Switzerland, 2015; pp. 161–173. [Google Scholar]
- Song, S.; Xiao, J. Sliding shapes for 3d object detection in depth images. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 634–651. [Google Scholar]
- Shi, W.; Zhu, D.; Zhang, G.; Chen, L.; Wang, L.; Li, J.; Zhang, X. Multilevel Cross-Aware RGBD Semantic Segmentation of Indoor Environments. In Proceedings of the 2019 IEEE International Conference on Cyborg and Bionic Systems (CBS), Munich, Germany, 18–20 September 2019; pp. 346–351. [Google Scholar]
- Asif, U.; Bennamoun, M.; Sohel, F.A. RGB-D object recognition and grasp detection using hierarchical cascaded forests. IEEE Trans. Robot. 2017, 33, 547–564. [Google Scholar] [CrossRef] [Green Version]
- Ahmed, A.; Jalal, A.; Kim, K. RGB-D images for object segmentation, localization and recognition in indoor scenes using feature descriptor and Hough voting. In Proceedings of the 2020 17th International Bhurban Conference on Applied Sciences and Technology (IBCAST), Islamabad, Pakistan, 14–18 January 2020; pp. 290–295. [Google Scholar]
- Tang, L.; Yang, Z.-X.; Jia, K. Canonical Correlation Analysis Regularization: An Effective Deep Multiview Learning Baseline for RGB-D Object Recognition. IEEE Trans. Cogn. Dev. Syst. 2019, 11, 107–118. [Google Scholar] [CrossRef]
- Liu, H.; Li, F.; Xu, X.; Sun, F. Multi-modal local receptive field extreme learning machine for object recognition. Neurocomputing 2018, 277, 4–11. [Google Scholar] [CrossRef]
- Hasan, M.M.; Mishra, P.K. Improving morphology operation for 2D hole filling algorithm. Int. J. Image Process. (IJIP) 2012, 6, 635–646. [Google Scholar]
- Cho, J.-H.; Song, W.; Choi, H.; Kim, T.; Kim, T. Hole filling method for depth image based rendering based on boundary decision. IEEE Signal Process. Lett. 2017, 24, 329–333. [Google Scholar] [CrossRef]
- Tingting, Y.; Junqian, W.; Lintai, W.; Yong, X. Three-stage network for age estimation. CAAI Trans. Intell. Technol. 2019, 4, 122–126. [Google Scholar] [CrossRef]
- Zhu, C.; Miao, D. Influence of kernel clustering on an RBFN. CAAI Trans. Intell. Technol. 2019, 4, 255–260. [Google Scholar] [CrossRef]
- Guo, X.; Xiao, J.; Wang, Y. A survey on algorithms of hole filling in 3D surface reconstruction. Vis. Comput. 2018, 34, 93–103. [Google Scholar] [CrossRef]
- Jin, Z.; Tillo, T.; Zou, W.; Li, X.; Lim, E.G. Depth image-based plane detection. Big Data Anal. 2018, 3, 10. [Google Scholar] [CrossRef]
- Li, L.; Sung, M.; Dubrovina, A.; Yi, L.; Guibas, L.J. Supervised fitting of geometric primitives to 3d point clouds. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 2647–2655. [Google Scholar]
- Anh-Vu, V.; Truong-Hong, L.; Debra; Laefer, F.; Bertolotto, M. Octree-based region growing for point cloud segmentation. ISPRS J. Photogramm. Remote Sens. 2015, 104, 88–100. [Google Scholar]
- Dantanarayana, H.G.; Huntley, J.M. Object recognition in 3D point clouds with maximum likelihood estimation. In Automated Visual Inspection and Machine Vision; Nternational Society for Optics and Photonics: Munich, Germany, 2015; Volume 9530, p. 95300F. [Google Scholar]
- Zhang, L.; Rastgar, H.; Wang, D.; Vincent, A. Maximum Likelihood Estimation sample consensus with validation of individual correspondences. In International Symposium on Visual Computing; Springer: Berlin/Heidelberg, Germany, 2009; pp. 447–456. [Google Scholar]
- Zhao, B.; Hua, X.; Yu, K.; Xuan, W.; Chen, X.; Tao, W. Indoor Point Cloud Segmentation Using Iterative Gaussian Mapping and Improved Model Fitting. IEEE Trans. Geosci. Remote. Sens. 2020, 58, 7890–7907. [Google Scholar] [CrossRef]
- Wiens, T. Engine speed reduction for hydraulic machinery using predictive algorithms. Int. J. Hydromechatronics 2019, 2, 16–31. [Google Scholar] [CrossRef]
- Ádám, Á.; Chatzilari, E.; Nikolopoulos, S.; Kompatsiaris, I. H-RANSAC: A hybrid point cloud segmentation combining 2D and 3D data. ISPRS Ann. Photogramm. Remote. Sens. Spat. Inf. Sci. 2018, 4, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Barath, D.; Matas, J. Graph-Cut RANSAC. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6733–6741. [Google Scholar] [CrossRef]
- Kulkarni, S.M.; Bormane, D.S.; Nalbalwar, S.L. RANSAC algorithm for matching inlier correspondences in video stabilisation. Int. J. Signal Imaging Syst. Eng. 2017, 10, 178–184. [Google Scholar] [CrossRef]
- Shokri, M.; Tavakoli, K. A review on the artificial neural network approach to analysis and prediction of seismic damage in infrastructure. Int. J. Hydromechatronics 2019, 2, 178–196. [Google Scholar] [CrossRef]
- Gao, G.-Q.; Zhang, Q.; Zhang, S. Pose detection of parallel robot based on improved RANSAC algorithm. Meas. Control. 2019, 52, 855–868. [Google Scholar] [CrossRef] [Green Version]
- Tran, N.-T.; Le Tan, F.-T.; Doan, A.-D.; Do, T.-T.; Bui, T.-A.; Tan, M.; Cheung, N.-M. On-device scalable image-based localization via prioritized cascade search and fast one-many ransac. IEEE Trans. Image Process 2018, 28, 1675–1690. [Google Scholar] [CrossRef]
- Tahir, S.B.U.D.; Jalal, A.; Kim, K. Wearable Inertial Sensors for Daily Activity Analysis Based on Adam Optimization and the Maximum Entropy Markov Model. Entropy 2020, 22, 579. [Google Scholar] [CrossRef]
- Shojaedini, E.; Majd, M.; Safabakhsh, R. Novel adaptive genetic algorithm sample consensus. Appl. Soft Comput. 2019, 77, 635–642. [Google Scholar] [CrossRef] [Green Version]
- Carlos, G.; Martín, D.; Armingol, J.M. Joint object detection and viewpoint estimation using CNN features. In Proceedings of the 2017 IEEE International Conference on Vehicular Electronics and Safety (ICVES), Vienna, Austria, 27–28 June 2017; pp. 145–150. [Google Scholar]
- Alqaisi, A.; Altarawneh, M.; Al, J.; Sharadqah, A.A. Analysis of color image features extraction using texture methods. TELKOMNIKA Telecommun. Comput. Electron. Control. 2019, 17, 1220–1225. [Google Scholar] [CrossRef] [Green Version]
- Jalal, A.; Khalid, N.; Kim, K. Automatic Recognition of Human Interaction via Hybrid Descriptors and Maximum Entropy Markov Model Using Depth Sensors. Entropy 2020, 22, 817. [Google Scholar] [CrossRef]
- Dadi, H.S.; Pillutla, G.K.M. Improved Face Recognition Rate Using HOG Features and SVM Classifier. IOSR J. Electron. Commun. Eng. 2016, 11, 34–44. [Google Scholar] [CrossRef]
- Korkmaz, S.A.; Akcicek, A.; Binol, H.; Korkmaz, M.F. Recognition of the stomach cancer images with probabilistic HOG feature vector histograms by using HOG features. In Proceedings of the 2017 IEEE 15th International Symposium on Intelligent Systems and Informatics (SISY), Subotica, Serbia, 14–16 September 2017; pp. 000339–000342. [Google Scholar] [CrossRef]
- Bheda, D.; Joshi, M.; Agrawal, V. A study on features extraction techniques for image mosaicing. Int. J. Innov. Res. Comput. Commun. Eng. 2014, 2, 3432–3437. [Google Scholar]
- Jalal, A.; Kim, Y.-H.; Kim, Y.-J.; Kamal, S.; Kim, D. Robust human activity recognition from depth video using spatiotemporal multi-fused features. Pattern Recognit. 2017, 61, 295–308. [Google Scholar] [CrossRef]
- Salahat, E.; Qasaimeh, M. Recent advances in features extraction and description algorithms: A comprehensive survey. In Proceedings of the 2017 IEEE International Conference on Industrial Technology (ICIT), Toronto, ON, Canada, 22–25 March 2017; pp. 1059–1063. [Google Scholar]
- Bo, L.; Lai, K.; Ren, X.; Fox, D. Object recognition with hierarchical kernel descriptors. In Proceedings of the CVPR 2011, Providence, RI, USA, 20–25 June 2011; pp. 1729–1736. [Google Scholar]
- Wang, P.; Wang, J.; Zeng, G.; Xu, W.; Zha, H.; Li, S. Supervised kernel descriptors for visual recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2858–2865. [Google Scholar]
- Jalal, A.; Batool, M.; Kim, K. Stochastic Recognition of Physical Activity and Healthcare Using Tri-Axial Inertial Wearable Sensors. Appl. Sci. 2020, 10, 7122. [Google Scholar] [CrossRef]
- Rafique, A.A.; Jalal, A.; Ahmed, A. Scene Understanding and Recognition: Statistical Segmented Model using Geometrical Features and Gaussian Naïve Bayes. In Proceedings of the IEEE Conference on International Conference on Applied and Engineering Mathematics, Taxila, Pakistan, 27–29 August 2019; Volume 57, pp. 225–230. [Google Scholar] [CrossRef]
- Bo, L.; Ren, X.; Fox, D. Depth kernel descriptors for object recognition. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; pp. 821–826. [Google Scholar]
- Zhu, X.; Wong, K.Y.K. Single-frame hand gesture recognition using color and depth kernel descriptors. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012; pp. 2989–2992. [Google Scholar]
- Quaid, M.A.K.; Jalal, A. Wearable sensors based human behavioral pattern recognition using statistical features and reweighted genetic algorithm. Multimed. Tools Appl. 2020, 79, 6061–6083. [Google Scholar] [CrossRef]
- Kong, Y.; Satarboroujeni, B.; Fu, Y. Learning hierarchical 3D kernel descriptors for RGB-D action recognition. Comput. Vis. Image Underst. 2016, 144, 14–23. [Google Scholar] [CrossRef] [Green Version]
- Caputo, B.; Jie, L. A performance evaluation of exact and approximate match kernels for object recognition. ELCVIA Electron. Lett. Comput. Vis. Image Anal. 2010, 8, 15–26. [Google Scholar] [CrossRef] [Green Version]
- Asilian Bidgoli, A.; Ebrahimpour-Komle, H.; Askari, M.; Mousavirad, S.J. Parallel Spatial Pyramid Match Kernel Algorithm for Object Recognition using a Cluster of Computers. J. AI Data Min. 2019, 7, 97–108. [Google Scholar]
- Rafique, A.A.; Jalal, A.; Kim, K. Statistical multi-objects segmentation for indoor/outdoor scene detection and classification via depth images. In Proceedings of the 2020 17th International Bhurban Conference on Applied Sciences and Technology (IBCAST), Islamabad, Pakistan, 14–18 January 2020; pp. 271–276. [Google Scholar]
- Hanif, M.S.; Ahmad, S.; Khurshid, K. On the improvement of foreground–background model-based object tracker. IET Comput. Vis. 2017, 11, 488–496. [Google Scholar] [CrossRef]
- Liu, Z.; Zhao, C.; Wu, X.; Chen, W. An effective 3D shape descriptor for object recognition with RGB-D sensors. Sensors 2017, 17, 451. [Google Scholar] [CrossRef] [Green Version]
- Susan, S.; Agrawal, P.; Mittal, M.; Bansal, S. New shape descriptor in the context of edge continuity. CAAI Trans. Intell. Technol. 2019, 4, 101–109. [Google Scholar] [CrossRef]
- Unlu, E.; Zenou, E.; Riviere, N. Using shape descriptors for UAV detection. Electron. Imaging 2018, 2018. [Google Scholar] [CrossRef] [Green Version]
- Lavi, B.; Serj, M.F.; Valls, D.P. Comparative study of the behavior of feature reduction methods in person re-identification task. In Proceedings of the 7th International Conference on Pattern Recognition Applications and Methods, Funchal, Madeira, Portogal, 16–18 January 2018; Volume 1, pp. 614–621. [Google Scholar] [CrossRef]
- Jenkins, O.C.; Mataric, M.J. A spatio-temporal extension to Isomap nonlinear dimension reduction. In Proceedings of the Twenty-First International Conference on Machine Learning, New York, NY, USA, 4–8 July 2004; p. 56. [Google Scholar] [CrossRef]
- Lai, K.; Bo, L.; Ren, X.; Fox, D. A large-scale hierarchical multi-view RGB-D object dataset. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 1817–1824. [Google Scholar]
- Lai, K.; Bo, L.; Fox, D. Unsupervised feature learning for 3D scene labeling. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 3050–3057. [Google Scholar]
- Silberman, N.; Fergus, R. Indoor scene segmentation using a structured light sensor. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 601–608. [Google Scholar]
- Eitel, A.; Springenberg, J.T.; Spinello, L.; Riedmiller, M.; Burgard, W. Multimodal deep learning for robust RGB-D object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 681–687. [Google Scholar]
- Hermans, A.; Floros, G.; Leibe, B. Dense 3D semantic mapping of indoor scenes from RGB-D images. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 2631–2638. [Google Scholar]
- Caglayan, A.; Imamoglu, N.; Can, A.B.; Nakamura, R. When CNNs Meet Random RNNs: Towards Multi-Level Analysis for RGB-D Object and Scene Recognition. arXiv 2020, arXiv:2004.12349. [Google Scholar]
- Antonello, M.; Wolf, D.; Prankl, J.; Ghidoni, S.; Menegatti, E.; Vincze, M. Multi-View 3D Entangled Forest for Semantic Segmentation and Mapping. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 1855–1862. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Obj. Classes | bow | ban | app | cap | com | fcn | cmg | jug | cbx | scs |
|---|---|---|---|---|---|---|---|---|---|---|
| bow | 0.97 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 |
| ban | 0.00 | 0.96 | 0.00 | 0.00 | 0.04 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| app | 0.05 | 0.00 | 0.95 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| cap | 0.03 | 0.00 | 0.00 | 0.93 | 0.00 | 0.04 | 0.00 | 0.00 | 0.00 | 0.00 |
| com | 0.00 | 0.08 | 0.00 | 0.00 | 0.90 | 0.00 | 0.00 | 0.00 | 0.00 | 0.02 |
| ccn | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.87 | 0.00 | 0.00 | 0.13 | 0.00 |
| cmg | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.83 | 0.14 | 0.00 | 0.00 |
| jug | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.08 | 0.00 | 0.92 | 0.00 | 0.00 |
| cbx | 0.00 | 0.00 | 0.00 | 0.02 | 0.00 | 0.07 | 0.00 | 0.00 | 0.93 | 0.00 |
| scs | 0.00 | 0.05 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.95 |
| Mean Accuracy = 92.16% | ||||||||||
| Obj. Classes | bed | bok | cab | cel | flr | sof | tab | tvn | wal | Win |
|---|---|---|---|---|---|---|---|---|---|---|
| bed | 0.89 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.11 | 0.00 | 0.00 | 0.00 |
| bok | 0.00 | 0.86 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.14 | 0.00 | 0.00 |
| cab | 0.05 | 0.00 | 0.81 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.14 | 0.00 |
| cel | 0.00 | 0.00 | 0.00 | 0.85 | 0.00 | 0.00 | 0.00 | 0.00 | 0.15 | 0.00 |
| flr | 0.05 | 0.00 | 0.00 | 0.00 | 0.95 | 0.00 | 0.00 | 0.00 | 0.00 | 0.04 |
| sof | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.81 | 0.12 | 0.00 | 0.07 | 0.00 |
| tab | 0.04 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.96 | 0.00 | 0.00 | 0.00 |
| tvn | 0.00 | 0.05 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.95 | 0.00 | 0.00 |
| wal | 0.00 | 0.00 | 0.00 | 0.07 | 0.00 | 0.00 | 0.00 | 0.00 | 0.87 | 0.06 |
| win | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.10 | 0.90 |
| Mean Accuracy = 88.5% | ||||||||||
| Obj. Classes | chr | ctl | sof | tab | bow | cap | cbx | cmg | scn | wal | flr |
|---|---|---|---|---|---|---|---|---|---|---|---|
| chr | 0.87 | 0.00 | 0.13 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| ctl | 0.00 | 0.82 | 0.00 | 0.18 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| sof | 0.17 | 0.00 | 0.83 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| tab | 0.00 | 0.18 | 0.00 | 0.82 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| bow | 0.00 | 0.00 | 0.00 | 0.04 | 0.96 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| cap | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.88 | 0.00 | 0.12 | 0.00 | 0.00 | 0.00 |
| cbx | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.77 | 0.09 | 0.14 | 0.00 | 0.00 |
| cmg | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.21 | 0.00 | 0.79 | 0.00 | 0.00 | 0.00 |
| scn | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.09 | 0.26 | 0.65 | 0.00 | 0.00 |
| wal | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.86 | 0.14 |
| flr | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.20 | 0.80 |
| Mean Accuracy = 90.5% | |||||||||||
| Parameters | Performance | ||
|---|---|---|---|
| Kernels | Iterations | Accuracy (%) | Comp. Time (s) |
| k = 1 | i = 10 | 85.76 | 1.93 |
| i = 15 | 85.94 | 2.17 | |
| i = 20 | 86.47 | 2.82 | |
| i = 25 | 86.89 | 3.21 | |
| k = 2 | i = 10 | 87.21 | 3.97 |
| i = 15 | 87.96 | 4.56 | |
| i = 20 | 88.32 | 4.89 | |
| i = 25 | 89.03 | 5.14 | |
| k = 3 | i = 10 | 90.55 | 5.78 |
| i = 15 | 91.14 | 6.49 | |
| i = 20 | 91.95 | 6.86 | |
| i = 25 | 92.20 | 7.65 | |
| Parameters | Performance | ||
|---|---|---|---|
| Kernels | Iterations | Accuracy (%) | Comp. Time (s) |
| k = 1 | i = 10 | 82.16 | 1.63 |
| i = 15 | 82.94 | 1.97 | |
| i = 20 | 83.47 | 2.52 | |
| i = 25 | 84.62 | 2.89 | |
| k = 2 | i = 10 | 85.51 | 3.17 |
| i = 15 | 86.36 | 3.68 | |
| i = 20 | 86.91 | 4.01 | |
| i = 25 | 87.65 | 4.59 | |
| k = 3 | i = 10 | 88.58 | 4.95 |
| i = 15 | 89.97 | 5.31 | |
| i = 20 | 90.50 | 5.81 | |
| i = 25 | 90.05 | 6.11 | |
| Parameters | Performance | ||
|---|---|---|---|
| Kernels | Iterations | Accuracy (%) | Comp. Time (s) |
| k = 1 | i = 10 | 81.95 | 1.35 |
| i = 15 | 82.74 | 1.99 | |
| i = 20 | 83.31 | 2.41 | |
| i = 25 | 83.89 | 2.87 | |
| k = 2 | i = 10 | 84.82 | 3.13 |
| i = 15 | 85.19 | 3.56 | |
| i = 20 | 85.91 | 4.03 | |
| i = 25 | 86.77 | 4.75 | |
| k = 3 | i = 10 | 87.29 | 5.16 |
| i = 15 | 87.98 | 5.95 | |
| i = 20 | 88.50 | 6.12 | |
| i = 25 | 88.12 | 6.84 | |
| Method | Accuracy on Single Object % | Accuracy on Multi-Object (%) | |
|---|---|---|---|
| RGB-D Object | RGB-D Scenes | NYUDv1 | |
| Saliency map [19] | 86.9 | - | - |
| AlexNet-RNN [72] | 90.9 | - | - |
| 3DEF-FFSM [73] | - | - | 52.6 |
| Fus-CNN(jet) [70] | 91.3 | - | - |
| MM-ELM-LRF [71] | 89.3 | - | - |
| CRF [69] | - | - | 56.6 |
| STEM-CaRFs [18] | 92.2 | 81.7 | - |
| Deep CNN [12] | 91.8 | - | - |
| Full 2D Segmentation [71] | - | - | 59.5 |
| HMP3D [68] | - | 82.1 | - |
| Proposed | 92.2 | 90.5 | 88.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rafique, A.A.; Jalal, A.; Kim, K. Automated Sustainable Multi-Object Segmentation and Recognition via Modified Sampling Consensus and Kernel Sliding Perceptron. Symmetry 2020, 12, 1928. https://doi.org/10.3390/sym12111928
Rafique AA, Jalal A, Kim K. Automated Sustainable Multi-Object Segmentation and Recognition via Modified Sampling Consensus and Kernel Sliding Perceptron. Symmetry. 2020; 12(11):1928. https://doi.org/10.3390/sym12111928
Chicago/Turabian StyleRafique, Adnan Ahmed, Ahmad Jalal, and Kibum Kim. 2020. "Automated Sustainable Multi-Object Segmentation and Recognition via Modified Sampling Consensus and Kernel Sliding Perceptron" Symmetry 12, no. 11: 1928. https://doi.org/10.3390/sym12111928
APA StyleRafique, A. A., Jalal, A., & Kim, K. (2020). Automated Sustainable Multi-Object Segmentation and Recognition via Modified Sampling Consensus and Kernel Sliding Perceptron. Symmetry, 12(11), 1928. https://doi.org/10.3390/sym12111928