1. Introduction
Recently, the industrial Internet of Things (IIoT) has been widely adopted by various companies, as it provides connectivity and analysis capabilities, which are the key technologies for advanced manufacturing [
1,
2,
3,
4]. In IIoT, a large number of sensors are used to periodically detect changes in machine health, manufacturing process, industrial environment, etc. [
5,
6,
7,
8,
9,
10]. Hence, a huge amount of data is collected from the sensors used in IIoT. In general, the collected data are analyzed to provide useful information for productivity improvement [
11]. In particular, failure prediction through data analysis is considered one of the most important issues in IIoT [
12]. The failure, such as execution error, long delay, and defective product, leads to a fatal system malfunction and huge maintenance cost, resulting in productivity degradation of enterprises in industrial fields [
13]. Therefore, many enterprises have endeavored to predict when and why failures occur for improving their capabilities of failure prevention and recovery, also known as resilience capacity [
14]. Especially, the accuracy of failure prediction is an important factor that determines the resilience capacity of enterprises; thus, its improvement is crucial in the IIoT.
To predict failures, we need to build a failure prediction model that determines whether or not a failure occurs [
15,
16,
17]. In order to build such a failure prediction model, most of the existing studies have used machine learning techniques. Abu-Samah et al. built the failure prediction model on the basis of a Bayesian network, and Kwon and Kim (i.e., our previous work) used the nearest centroid classification to predict machine failures [
18,
19]. The results of both the studies showed that the built failure prediction model achieved approximately 80% prediction accuracy. However, they did not conduct the feature selection. In other words, they used all the data in the dataset when building the model. Accordingly, in a real IIoT context where a very large number of sensors are used, the prediction accuracy might be significantly degraded because of the impact of the data irrelevant to the failures.
Therefore, feature selection has been considered one of the most important steps in building a failure prediction model. There have been many studies to build the failure prediction model using feature selection, most of which have selected features considering the importance of each feature [
20,
21,
22]. Moldovan et al. built a failure prediction model using the selected features to improve prediction accuracy and performed feature selection using three algorithms (i.e., random forest, regression analysis, and orthogonal linear transformation) to compare the prediction accuracy of each for the comparative study [
20]. Mahadevan and Shah used a support vector machine recursive feature elimination (SVM-RFE) algorithm to rank the features by their importance [
21]. The SVM-RFE algorithm was used to compute the norm of the weights of each feature (i.e., the importance of each feature). For feature selection, the authors determined a threshold value specified by the limit of the number of selected features, and then selected the features considering their importance until the number of selected features reached the threshold. The selected features were used for failure detection and diagnosis. Hasan et al. focused on a two-step approach of random forest based-feature selection, which consists of the feature importance measurement and feature selection [
22]. In the first step, the importance of each feature was measured using average permutation importance (APIM) score. APIM score is obtained by calculating the mean decreases in the forest’s classification accuracy when a specific feature is not available. In the second step, the features with an APIM score greater than a threshold were selected. However, in the existing feature selection methods, the optimal prediction accuracy cannot be obtained because the number of selected features is fixed or all the features in which the importance is greater than a predefined threshold are selected. Specifically, the number of selected features might be too large to obtain optimal prediction accuracy or vice versa.
In this paper, we propose a novel failure prediction model using iterative feature selection, which aims to accurately predict the occurrence of failures. To build the model, the collected data are processed and analyzed using the following steps: (1) preprocessing, (2) importance measurement, (3) feature selection, (4) model building, and (5) model selection. The preprocessing step includes feature elimination, missing data imputation, normalization, and data division. In the importance measurement step, to measure the importance of each feature, the relevancy between each feature and the failure is analyzed using the random forest algorithm [
23,
24,
25,
26]. Then, the feature selection and model building steps are conducted iteratively. In particular, in the feature selection step, a new feature is selected considering its importance in each iteration and is added to the selected feature set. In the model building step, the failure prediction model is built via the SVM on the basis of the selected feature set updated in each iteration [
27,
28,
29,
30]. Finally, one of the failure prediction models is selected considering the prediction accuracy in the model selection step. To evaluate the performance of the proposed model, we conducted an experimental implementation using open-source R. We used the semiconductor manufacturing (SECOM) dataset provided by the University of California Irvine (UCI) repository [
31]. The results showed that the proposed failure prediction model achieved high prediction accuracy.
The rest of this paper is organized as follows.
Section 2 describes the proposed failure prediction model in detail. In
Section 3, the results of the implementation and performance evaluation are presented. Finally,
Section 4 concludes this paper.
2. Failure Prediction Model Using Iterative Feature Selection
In this section, we present the design of the failure prediction model using iterative feature selection in detail. It is assumed that sensors with unique identification (ID) employed in an IIoT environment periodically generate data, and the data is collected by a data analysis server. In this paper, the sensor device is represented as a feature, and its ID is represented by a feature index. The data analysis server collects data from sensor devices and builds and evaluates the failure prediction model. The data is represented in the form of a matrix format (i.e., dataset) in which each column and row means the feature and data collection time, respectively.
We built the failure prediction model on the basis of the features selected to maximize the prediction accuracy. To this end, feature selection was iteratively conducted, and multiple failure prediction models were built on the basis of the features selected in each iteration. Then, the failure prediction model with the highest prediction accuracy was selected. To build the failure prediction model, we considered five steps, namely preprocessing, importance measurement, feature selection, model building, and model selection. In this section, each step for building the failure prediction model is described in detail.
Figure 1 shows the overall procedure for building the failure prediction model. In the figure, the white square indicates each step, and the grey square indicates the input or output of each step. In the preprocessing step, feature elimination, missing data imputation, normalization, and data division are sequentially conducted. To eliminate invalid features from the input dataset (i.e., collected data), the not applicable (NA) data of each feature are searched, and the variance of each feature is calculated. If the ratio of the NA data of a specific feature is greater than the predefined validity factor determined in the range [0, 1], the corresponding feature is eliminated from the input dataset. Moreover, if the variance of a certain feature is close to zero, the corresponding feature is eliminated from the input dataset. This is because the closer the variance of a certain feature is to zero, the more similar is the value of all the data. In particular, if the variance of a certain feature is zero, all the data of this feature have the same value, which means that the feature is meaningless for the data analysis. To replace the remaining missing data with the appropriate data, an average of the non-missing data of each feature is calculated and imputed. Then, normalization is conducted to match the data scale of each feature. To this end, the standard score is used, which calculates the normalized data of each feature according to Equation (1):
where
is the
-th normalized data of the feature,
is the
-th data of the feature,
is the average of the feature, and
is the standard deviation of the feature [
32]. The
and
values are calculated using Equations (2) and (3), respectively [
33].
where
is the amount of data of the feature. Finally, the normalized dataset is divided into training and test datasets, which are used to build the failure prediction model and to evaluate the performance of the prediction model, respectively.
To measure the importance of each feature, the training dataset (i.e., a part of the preprocessed dataset) is analyzed using the random forest algorithm, which is one of the machine learning techniques for importance measurement. In particular, via the random forest, multiple decision trees are built, and the relevancy between each feature and the failure is analyzed considering the built decision trees comprehensively. In the random forest, multiple subsets of the training dataset are created to build each decision tree differently. Note that each subset consists of different data and features. For this, n data (i.e., n rows) and mtry features (i.e., mtry columns) are randomly selected from the training dataset. This operation repeats until the number of created subsets reaches the number of decision trees predefined as ntree. Then, each decision tree is built separately using one of the created subsets. After building ntree decision trees, the importance of each feature is measured through the mean decrease Gini, which indicates the extent to which each feature affects the correct prediction results. More specifically, in each decision tree, the sum of the difference for Gini impurities between the parent nodes using a particular feature and their child nodes is calculated. Then, the average of the results of all the decision trees is calculated. Note that the decision tree consists of multiple nodes that make decisions using the threshold of a specific feature. In addition, each node has a Gini impurity that is a measurement of the likelihood of an incorrect decision.
Then, the feature selection and model building steps are conducted iteratively. Algorithm 1 shows the overall operation of both the steps. In the algorithm, the set of the importance of features and the set of features are represented by Equations (4) and (5), respectively.
where
is the number of features and
is the importance of the
-th feature. The index of each element in
and
(i.e., index of each importance and feature) denotes the sequence number of each feature. At the beginning of the algorithm, the variables are initialized: the selected feature at the
-th iteration (
), the prediction accuracy for the built model at the
-th iteration (
), and the iteration counter (
). Then, the feature selection and model building steps are repeated until the importance of a newly selected feature is smaller than the importance threshold. In the algorithm, the maximum number of iterations (
) is equal to the number of features whose importance is greater than the importance threshold. Therefore, the iteration terminates when
reaches
. In each iteration, the feature selection step selects a new feature with the highest importance and adds it to the selected feature set represented by Equation (6).
Consequently, the number of features included in is incremented by one as the number of iteration increases. Once
is updated, the model building step builds the failure prediction model through SVM on the basis of
. Then, it evaluates the prediction accuracy to update the prediction accuracy set that is expressed by Equation (7).
Note that the index of each element in
and
(i.e., index of each selected feature and prediction accuracy) refers to the number of iterations. In the algorithm, modelBuildEvalFunction() is a function to build and evaluate the prediction model. It derives the prediction accuracy by taking
he prediction model. It derives the prediction accuracy by taking
as the input. For example, if
(i.e., the third iteration) and the selected feature set is equal to the
(i.e.,
,
, and
), modelBuildEvalFunction() first builds the failure prediction model using the training data of the features in the
. Then, it derives
by evaluating the built model using the test data of the features and updates the prediction accuracy set from
to
. In the example, the number of elements in
increases from two to three. When
reaches
, the operation is terminated. The outputs of this operation are shown in Equations (8) and (9).
| Algorithm 1: Operation of feature selection and model building steps. |
| 1: | INITIALIZE to NULL, to 0, and to 0 //Initialize variables |
| 2: | REPEAT //Start iteration |
| 3: | /* ========== Feature Selection Step ========== */ |
| 4: | ← //Find the highest importance from |
| 5: | FOR each feature index, , |
| 6: | IF == //Find feature index with the highest importance |
| 7: | ← //Select a new feature |
| 8: | ← 0 //Remove the selected feature from and |
| 9: | ENDIF |
| 10: | ENDFOR |
| 11: | ← //Update the selected feature set |
| 12: | /* ========== Model Building Step ========== */ |
| 13: | ← modelBuildEvalFunction() //Build and evaluate model |
| 14: | ← //Update the prediction accuracy set |
| 15: | ← //Increment iteration counter by one |
| 16: | UNTIL //Terminate iteration if condition becomes TRUE |
| 17: | RETURN and //Return selected feature set and prediction accuracy set |
The model selection step selects the failure prediction model having the highest prediction accuracy, referring to and . In particular, this step first searches for the highest prediction accuracy in by using , where is the function that searches the element having the maximum value in a given set. Then, it derives the index of from . For this, each element in is compared with , and the index of the element that is equal to is derived from . Finally, a failure prediction model is selected, taking into account the index of and . More specifically, the elements (i.e., selected features) in which the index is less than or equal to the index of are extracted from . Then, one of the failure prediction models built in the model building step is selected by comparing the features used in the model building step and the extracted features from .
3. Implementation and Performance Evaluation
An experimental implementation was conducted to verify the feasibility of the proposed failure prediction model by using the open-source R version 3.4.3. For this, the SECOM dataset provided by the UCI repository was used. This dataset consists of 1567 data elements and 591 features, and the data were collected from a semiconductor manufacturing process by monitoring the sensors and the process measurement point. The data of 590 features were measured from different sensors, and the data of the remaining feature were the results of the house line test represented by Pass and Fail.
For feature elimination, we set the validity factor to 0.1, which was empirically determined to maximize the prediction accuracy. Thus, features with more than 10% NA data and features having zero variance were eliminated from the dataset. Through feature elimination, the number of features reduced from 591 to 393. The ratio of the training dataset and the test dataset was set to 7:3. To measure the importance of each feature, we used the randomForest and caret packages. We set
n,
mtry, and
ntree to 1000, 19, and 500, respectively. Through this setting, 500 decision trees were built using the randomly created 1000 × 19 matrix. The importance of each feature was measured through the mean decrease Gini.
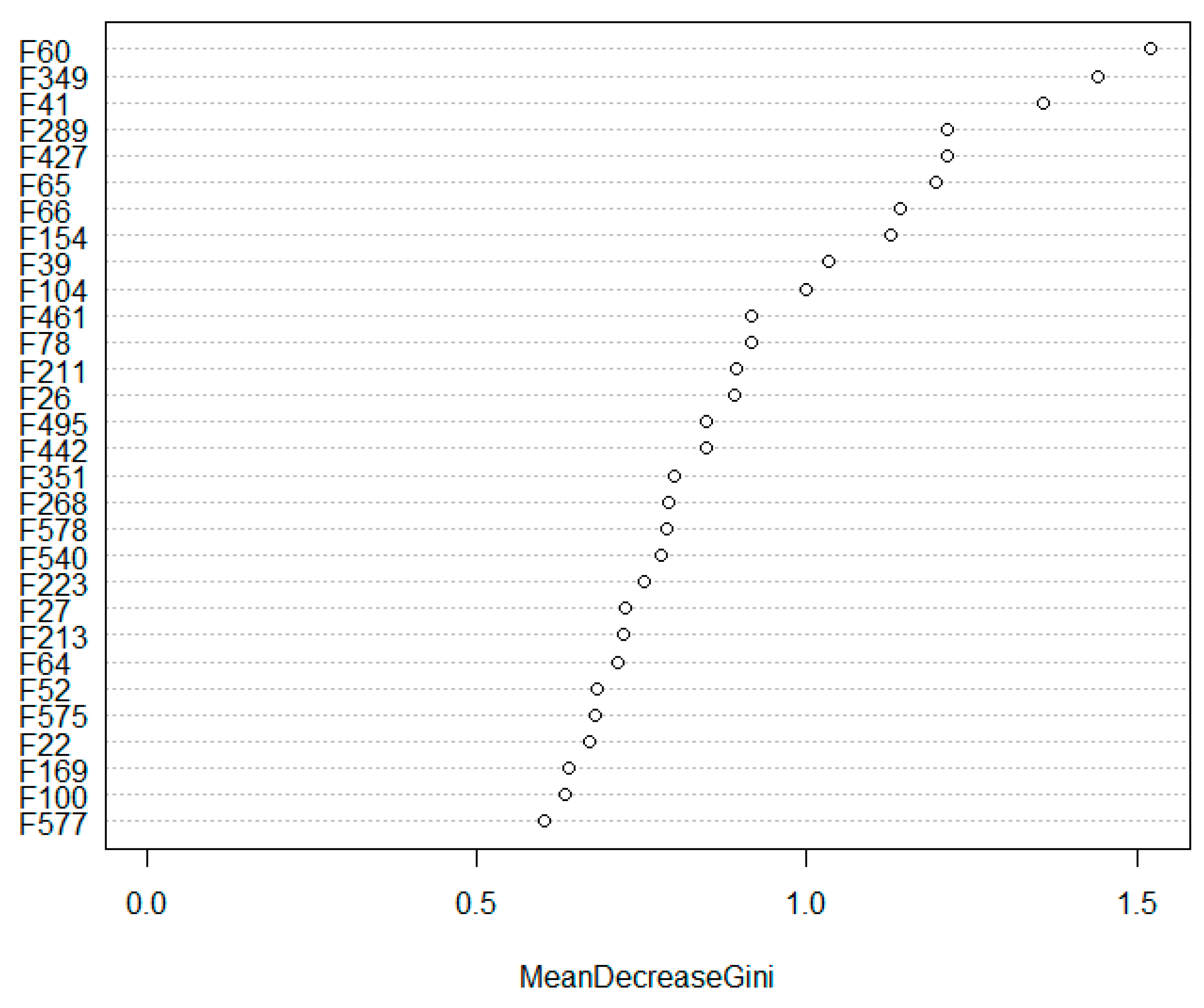
Figure 2 shows the importance of the top 30 features. The
x-axis and the
y-axis denote the mean decrease Gini and the feature, respectively. In the figure, F60 has the highest mean decrease Gini (i.e., 1.52) among all the features.
For iterative feature selection, we set the importance threshold to 0.7, which was chosen in the range of [0.1, 1], taking into account the feature selection results of the existing research for the comparative study. Therefore,
was determined as 24. This implied that the number of iterations was 24. The training dataset contained 70 fails and 1038 passes. This imbalance of the training dataset made it difficult for the failure prediction model to predict a fail case. To address this problem, the sampling was conducted before building the failure prediction model. In particular, some of the pass data were removed to have less effect on the model building. With the results of feature selection and the sampled training dataset, the failure prediction model was built using the SVM. To this end, we used the e1071 package in R.
Table 1 lists the obtained
and
. In the table,
is 0.72, and its index is 7. As a result, the failure prediction model that was built using eight features (i.e., F60, F349, F41, F289, F427, F65, F66, and F154) was selected.
For the performance evaluation, the prediction accuracy of the proposed model was compared to that of the existing models. We considered three existing models, which were built on the basis of a fixed number of features (i.e., 12 and 24 features) and all the features, respectively.
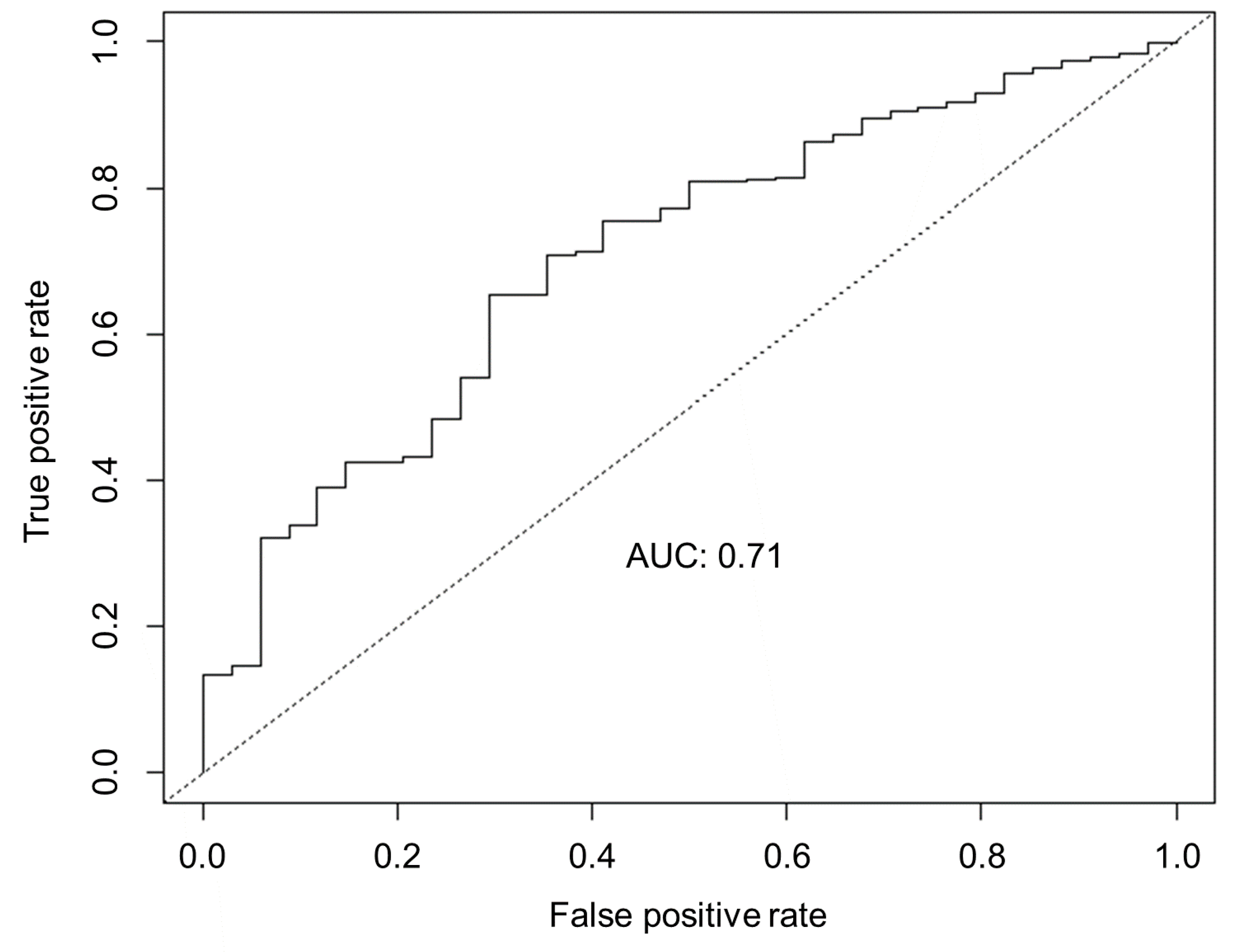
Figure 3,
Figure 4,
Figure 5 and
Figure 6 show the receiver operating characteristic (ROC) curve for the three failure prediction models that used different numbers of features. The ROC curve is a performance measure of the prediction model and presents the relationship between the true positive rate (TPR) and the false positive rate (FPR) [
34]. The TPR and FPR values were calculated using Equations (10) and (11), respectively.
where
,
,
, and
are the true positive, false negative, false positive, and true negative, respectively. With the ROC curve, the area under the curve (AUC) was used to evaluate the prediction accuracy of the model. In particular, the greater the AUC was, the higher was the prediction accuracy. In
Figure 3, the failure prediction model that was built on the basis of iterative feature selection has the greatest AUC among the considered models. This was because the model was iteratively built using a different number of features; one of the models, i.e., the one with the highest prediction accuracy, was selected. As shown in
Figure 4 and
Figure 5, if a fixed number of features are used for building the model, the prediction accuracy might be relatively degraded. The reason was that irrelevant features made it difficult to build accurate prediction models. If more features irrelevant to the failure were used to build the model, the prediction accuracy of the model decreased. Therefore, in the case that all the features in the dataset were used as shown in
Figure 6, the AUC decreased significantly. Quantitatively, the proposed model achieved 14.3% and 22.0% higher AUC than in the fixed number of features and the all features cases, respectively.
4. Conclusions
In this paper, we proposed a failure prediction model using iterative feature selection with the aim of predicting the failure occurrences. The procedure for building the failure prediction model consisted of the following five steps: (1) preprocessing, (2) importance measurement, (3) feature selection, (4) model building, and (5) model selection. In the first step, feature elimination, missing data imputation, normalization, and data division are sequentially conducted. The importance measurement step is to measure the importance of each feature by using the random forest. The third and the fourth steps were iteratively performed to build the failure prediction models using the various selected feature sets and to obtain the prediction accuracy of the built models. In the last step, the failure prediction model with the highest prediction accuracy was selected. The experimental implementation was conducted to evaluate the performance of the proposed model using the open-source R and the SECOM dataset given by the UCI repository. Through the experimental implementation, we obtained the importance of features representing the relevancy between each feature and failure. Moreover, we obtained the selected feature set and prediction accuracy set, each of which contains twenty-four features and prediction accuracy measurements. In the experiments, the proposed failure prediction model was built with eight features, and we compared the prediction accuracy of the proposed model with that of the failure prediction model built based on 12 features, 24 features, and all features. The results showed that the proposed model achieved 1.4%, 14.3%, and 22.0% higher AUC than that of other models. Comprehensively, the contributions of this paper are as follows. (1) We presented and discussed the problems of the existing failure prediction models for IIoT. (2) Through the importance measurement and iterative feature selection, we derived the feature index and the number of features that maximize the prediction accuracy of the failure prediction model. (3) We verified the feasibility of our work by conducting open-source-based implementation and extensive experiments. In our work, the proposed failure prediction model was implemented using only a limited dataset. Therefore, future work involves performing additional experiments with extended datasets to assess whether the proposed model is useful for various IIoT applications.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}