A Face Image Virtualization Mechanism for Privacy Intrusion Prevention in Healthcare Video Surveillance Systems



Abstract
:1. Introduction
2. Examination of the Existing Data Privacy Preservation Techniques
2.1. Blurring
2.2. Mosaic Masking
2.3. Removal and Transformation
2.4. Encryption
2.5. Related Research
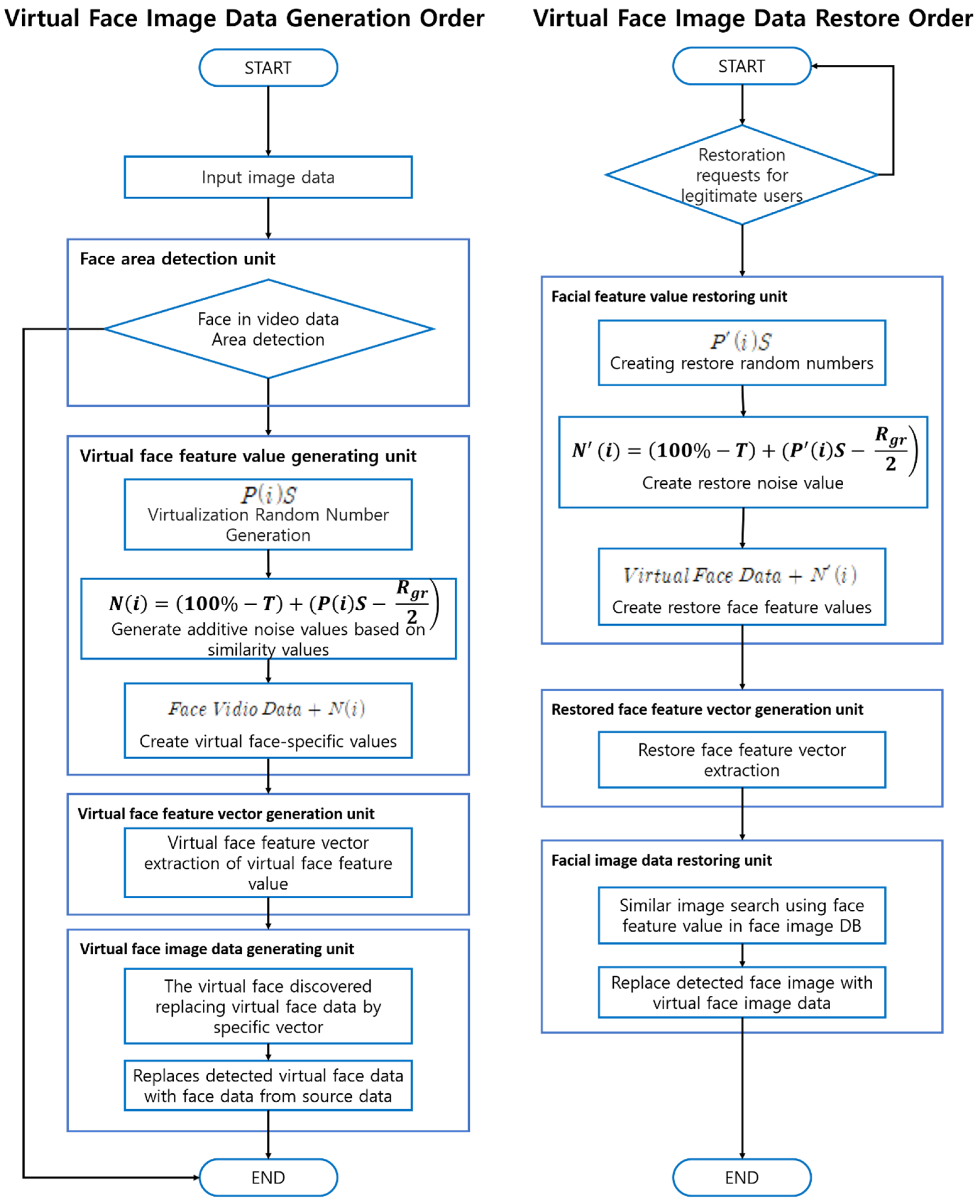
3. Proposed Mechanism for Changing Face Information to Prevent Privacy Infiltration
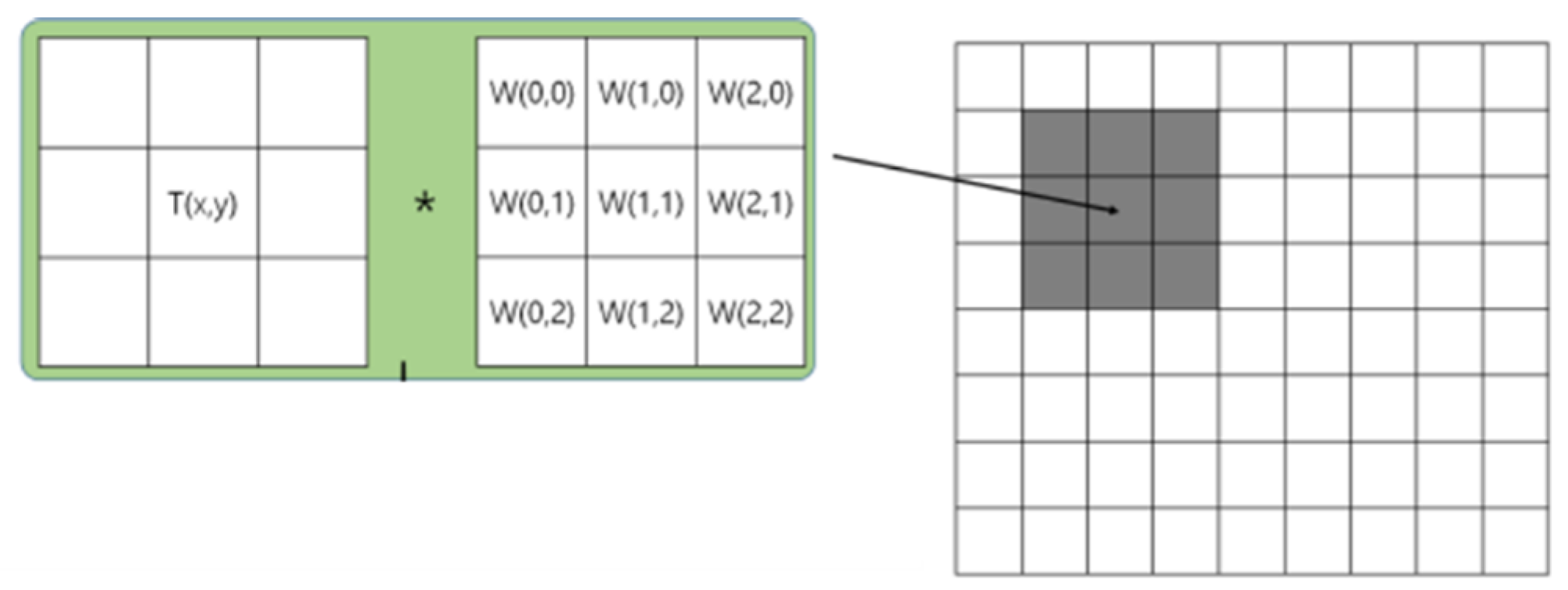
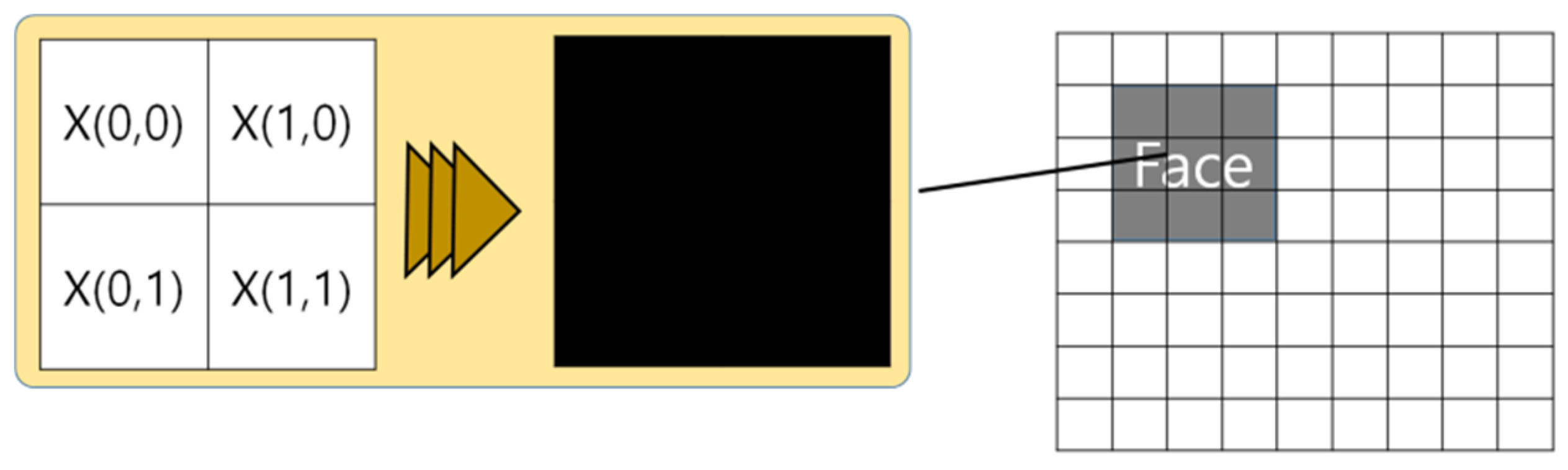
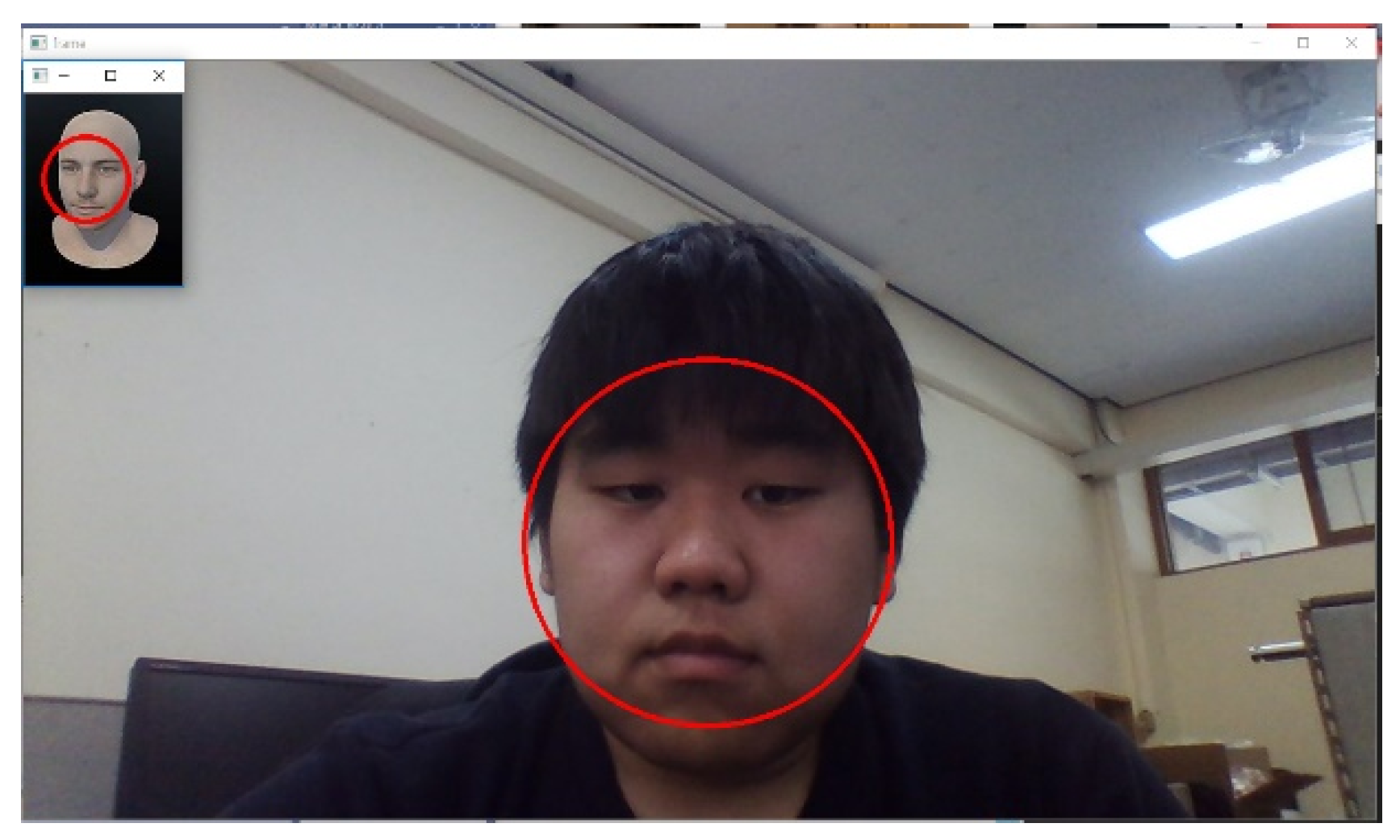
3.1. Face Region Detection Module
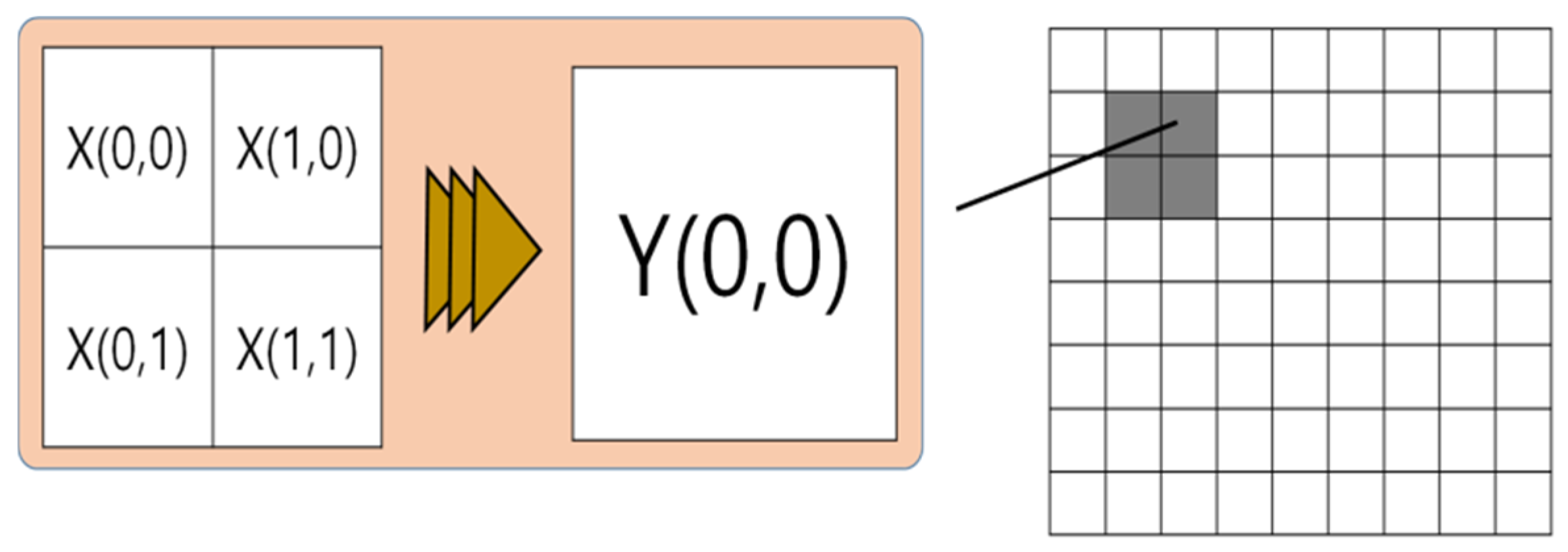
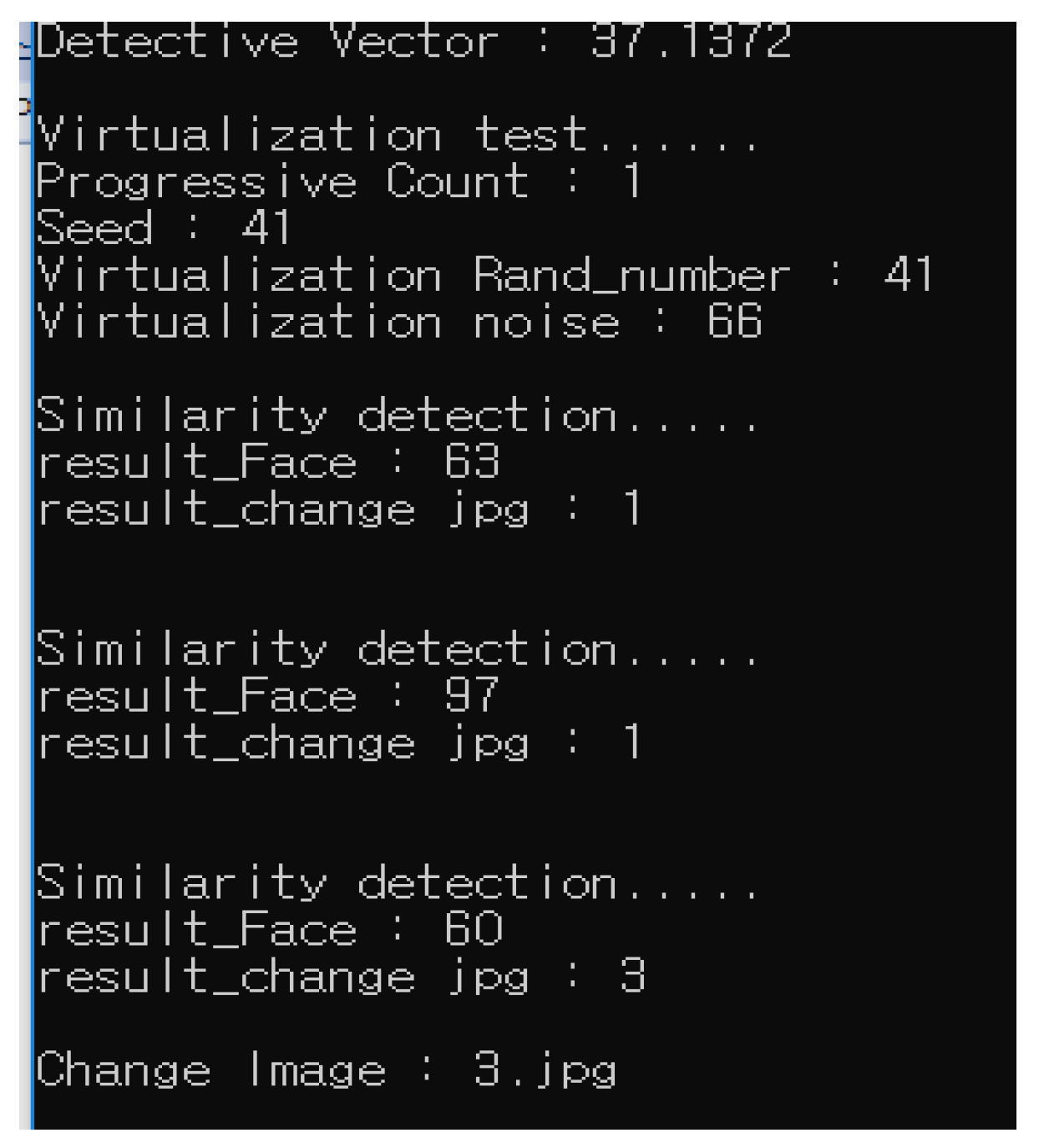
3.2. Virtual Face Features Generation Module
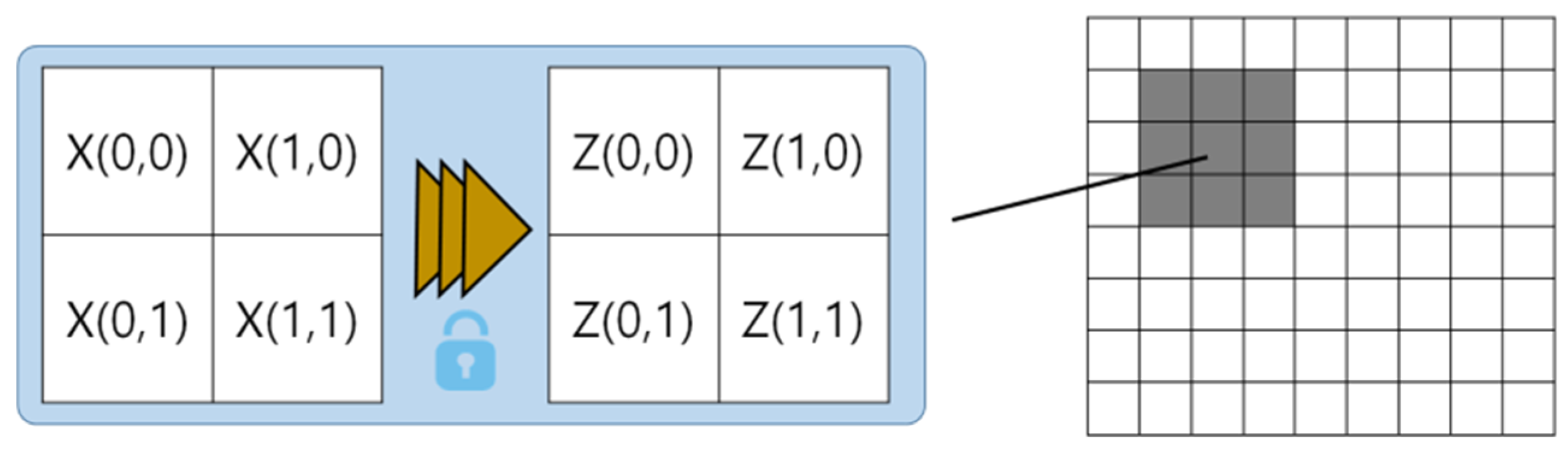
3.3. Virtual Face Feature Vector and Data Generation Module
3.4. Face Features Recovery Module
3.5. Face Image Restore Module
4. Comparison and Analysis of the Proposed Mechanism and the Existing Techniques
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Yuxi, P.; Luuk, J.S.; Raymond, N.J.V. Low-resolution face recognition and the importance of proper alignment. IET Biom. 2019, 8, 267–276. [Google Scholar]
- Ling, J.; Zhang, K.; Zhang, Y.; Yang, D.; Chen, Z. A saliency prediction model on 360 degree images using color dictionary based sparse representation. Signal Process. Image Commun. 2018, 69, 60–68. [Google Scholar] [CrossRef]
- Kim, J.; Park, N.; Kim, G.; Jin, S. CCTV Video Processing Metadata Security Scheme Using Character Order Preserving-Transformation in the Emerging Multimedia. Electronics 2019, 8, 412. [Google Scholar] [CrossRef] [Green Version]
- Creasey, M.S.; Albalooshi, F.A.; Rajarajan, M. Continuous face authentication scheme for mobile devices with tracking and liveness detection. Microprocess. Microsyst. 2018, 63, 147–157. [Google Scholar] [CrossRef] [Green Version]
- Chhokra, P.; Chowdhury, A.; Goswami, G.; Vatsa, M.; Singh, R. Unconstrained Kinect video face database. Inf. Fusion 2018, 44, 113–125. [Google Scholar] [CrossRef]
- Kim, N.; Seo, D.; Lee, S.; Shin, C.; Cho, K.; Kim, S. Hierarchical image encryption with orthogonality. J. KJOP 2006, 17, 231–239. [Google Scholar]
- Park, N. The Core Competencies of SEL-based Innovative Creativity Education. Int. J. Pure Appl. Math. 2018, 118, 837–849. [Google Scholar]
- Arceda, V.E.M.; Fabián, K.M.F.; Laura, P.C.L.; Tito, J.J.R.; Cáceres, J.C.G. Fingertip Detection and Tracking for Recognition of Air-Writing in Videos. Exp. Syst. Appl. 2019, 136, 217–229. [Google Scholar]
- Mutneja, V.; Singh, S. GPU accelerated face detection from low resolution surveillance videos using motion and skin color segmentation. Optik 2018, 157, 1155–1165. [Google Scholar] [CrossRef]
- Rashedi, E.; Barati, E.; Nokleby, M.; Chen, X. “Stream loss”: ConvNet learning for face verification using unlabeled videos in the wild. Neurocomputing 2019, 329, 311–319. [Google Scholar] [CrossRef]
- Park, N.; Hu, H.; Jin, Q. Security and Privacy Mechanisms for Sensor Middleware and Application in Internet of Things (IoT). Int. J. Distrib. Sens. Networks 2016, 12, 2965438. [Google Scholar] [CrossRef] [Green Version]
- Girod, B. The Information Theoretical Significance of Spatial and Temporal Masking in Video Signals. OE/LASE ’89 1989, 1077, 178–189. [Google Scholar] [CrossRef]
- Lee, K.; Yeuk, H.; Kim, J.; Hyungjoon Park, K.Y. An efficient key management solution for privacy masking, restoring and user authentication for video surveillance servers. Comput. Stand. Interfaces 2016, 44, 137–143. [Google Scholar] [CrossRef]
- Milosavljević, A.; Rančić, D.; Dimitrijević, A.; Predić, B.; Mihajlović, V. Integration of GIS and video surveillance. Int. J. Geogr. Inf. Sci. 2016, 1–19. [Google Scholar] [CrossRef]
- Park, N.; Kim, M. Implementation of load management application system using smart grid privacy policy in energy management service environment. Clust. Comput. 2014, 17, 653–664. [Google Scholar] [CrossRef]
- Wang, L.; Yu, X.; Bourlai, T.; Metaxas, N.D. A coupled encoder–decoder network for joint face detection and landmark localization. Image Vis. Comput. 2019, 87, 37–46. [Google Scholar] [CrossRef]
- Hagmann, J. Security in the Society of Control: The Politics and Practices of Securing Urban Spaces. Int. Political Sociol. 2017, 11, 418–438. [Google Scholar] [CrossRef]
- Essa, A.; Asari, V.K. Face recognition based on modular histogram of oriented directional features. In Proceedings of the 2016 IEEE National Aerospace and Electronics Conference (NAECON) and Ohio Innovation Summit (OIS), Dayton, OH, USA, 25–29 July 2016. [Google Scholar]
- Kose, N.; Dugelay, J.L. Countermeasure for the protection of face recognition systems against mask attacks. In Proceedings of the 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Shanghai, China, 22–26 April 2013. [Google Scholar]
- Kim, H.A. Data Blurring Method for Dollaborative Filtering. Ph.D. Thesis, Department of Computer Engineering, The Graduate School of Dongguk University, Seoul, Korea, 2004. [Google Scholar]
- Wang, Z.; Yang, X.; Cheng, K.T. Accurate face alignment and adaptive patch selection for heart rate estimation from videos under realistic scenarios. PLoS ONE 2018, 13, e0197275. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dimoulas, C.; Papanikolaou, G.; Petridis, V. Pattern Classification and Audiovisual Content Management techniques using Hybrid Expert Systems: A video-assisted Bioacoustics Application in Abdominal Sounds Pattern Analysis. Exp. Syst. Appl. 2011, 38, 13082–13093. [Google Scholar] [CrossRef]
- Dimoulas, C.; Avdelidis, A.; Kalliris, G.; Papanikolaou, G. Joint Wavelet Video Denoising and Motion Activity Detection in multi-modal human activity analysis: Application to video—Assisted bioacoustic/psycho-physiological monitoring. EURASIP J. Adv. Signal Process. 2007, 2008, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Peng, Y.; Lin, C.; Sun, M.; Landis, C.A. Multimodality Sensor System for Long-Term Sleep Quality Monitoring. IEEE Trans. Biomed. Circuits Syst. 2007, 1, 217–227. [Google Scholar] [CrossRef] [PubMed]
- Park, N.; Lee, D. Electronic identity information hiding methods using a secret sharing scheme in multimedia-centric internet of things environment. Person. Ubiquitous Comput. 2018, 22, 3–10. [Google Scholar] [CrossRef]
- Jeon, B.; Shin, S.; Jung, K.; Lee, J.; Yoo, K. Reversible Secret Sharing Scheme Using Symmetric Key Encryption Algorithm in Encrypted Image. J. KMS 2015, 18, 1332–1341. [Google Scholar]
- Liu, S.; Yu, M.; Li, M.; Xu, Q. The research of virtual face based on Deep Convolutional Generative Adversarial Networks using TensorFlow. J. Phys. A SMA 2019, 521, 667–680. [Google Scholar] [CrossRef]
- Huh, J. PLC-based design of monitoring system for ICT-integrated vertical fish farm. Hum.-Cent. Comput. Inf. Sci. 2017, 7, 7. [Google Scholar] [CrossRef] [Green Version]
- Yan, J.; Zhang, X.; Lei, Z.; Li, S.Z. Face detection by structural models, Image annotation: Then and now. Image Vis. Comput. 2014, 32, 790–799. [Google Scholar] [CrossRef]
- Lee, D.; Park, N.; Kim, G.; Jin, S. De-identification of metering data for smart grid personal security in intelligent CCTV-based P2P cloud computing environment. J. Peer-to-Peer Network. Appl. 2018, 11, 1299–1308. [Google Scholar] [CrossRef]
- Bhagat, P.K.; Choudhary, P. Image annotation: Then and now. Image Vis. Comput. 2018, 80, 1–23. [Google Scholar] [CrossRef]
- Lee, D.; Park, N. ROI-based efficient video data processing for large-scale cloud storage in intelligent CCTV environment. J. IJET 2018, 7, 151–154. [Google Scholar]
- Cucchiara, R.; Grana, C.; Prati, A.; Vezzani, R. Computer vision system for in-house video surveillance. IEE Proc. Vis. Image Signal Process. 2005, 152, 242–249. [Google Scholar] [CrossRef]
- Park, N.; Kang, N. Mutual Authentication Scheme in Secure Internet of Things Technology for Comfortable Lifestyle. Sensors 2016, 16, 20. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Azhar, H.; Amer, A. Classification of surveillance video objects using chaotic series. IET Image Process. 2012, 6, 919–931. [Google Scholar] [CrossRef]
- Zhang, L.; Dou, P.; Kakadiaris, I.A. Patch-based face recognition using a hierarchical multi-label matcher, Image annotation: Then and now. Image Vis. Comput. 2018, 73, 28–39. [Google Scholar] [CrossRef] [Green Version]
- Hu, J. Discriminative transfer learning with sparsity regularization for single-sample face recognition, Image annotation: Then and now. Image Vis. Comput. 2017, 60, 48–57. [Google Scholar] [CrossRef]
- Teferi, D.; Bigun, J. Damascening video databases for evaluation of face tracking and recognition—The DXM2VTS database. Pattern Recognit. Lett. 2007, 28, 2143–2156. [Google Scholar] [CrossRef]
- Wang, C.; Li, Y. Combine image quality fusion and illumination compensation for video-based face recognition. Neurocomputing 2010, 73, 1478–1490. [Google Scholar] [CrossRef]
- Li, H.; Achim, A.; Bull, D. Unsupervised video anomaly detection using feature clustering. IET Signal Process. 2012, 6, 521–533. [Google Scholar] [CrossRef]
- Leung, V.; Colombo, A.; Orwell, J.; Velastin, S.A. Modelling periodic scene elements for visual surveillance. IET Comput. Vis. 2001, 37, 20–21. [Google Scholar]
- Loideain, N.N. Cape Town as a smart and safe city: Implications for governance and data privacy. Int. Data Priv. Law 2017, 7, 314–334. [Google Scholar] [CrossRef]
- Lee, D.; Park, N. Geocasting-based synchronization of Almanac on the maritime cloud for distributed smart surveillance. J. Supercomput. 2017, 73, 1103–1118. [Google Scholar] [CrossRef]
- Ayesha, C.; Santanu, C. Video analytics revisited. IET Comput. Vis. 2016, 10, 237–249. [Google Scholar]
- Pons, J.; Prades-Nebot, J.; Albiol, A.; Molina, J. Fast motion detection in compressed domain for video surveillance. Electron. Lett. 2002, 38, 409–411. [Google Scholar] [CrossRef]
- Park, N.; Bang, H. Mobile middleware platform for secure vessel traffic system in IoT service environment. Secur. Commun. Netw. 2016, 9, 500–512. [Google Scholar] [CrossRef]
- Jeong, M.; Jeong, J. Uniform Motion Deblurring using Shock Filter and Convolutional Neural Network. J. KSBE 2018, 23, 484–494. [Google Scholar]
- Park, N.; Kwak, J.; Kim, S.; Won, D.; Kim, H. WIPI Mobile Platform with Secure Service for Mobile RFID Network Environment, Advanced Web and Network Technologies, and Applications. LNCS 2006, 3842, 741–748. [Google Scholar]
- Dahl, R.; Norouzi, M.; Shlens, J. Pixel Recursive Super Resolution. J. ICCV 2017, 7, 7. [Google Scholar] [CrossRef] [Green Version]
- Raghavendra, R.; Busch, C. Novel presentation attack detection algorithm for face recognition system: Application to 3D face mask attack. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014. [Google Scholar]
- Guo, J.M.; Lin, C.C.; Wu, M.F.; Chang, C.H.; Lee, H. Complexity Reduced Face Detection Using Probability-Based Face Mask Prefiltering and Pixel-Based Hierarchical-Feature Adaboosting. IEEE Signal Process. Lett. 2011, 18, 447–450. [Google Scholar] [CrossRef]
- Niu, G.; Chen, Q. Learning an video frame-based face detection system for security fields. J. Vis. Commun. Image Represent. 2018, 55, 457–463. [Google Scholar] [CrossRef]
- Du, L.; Zhang, W.; Fu, H.; Ren, W.; Zhang, X. An efficient privacy protection scheme for data security in video surveillance. Vis. Commun. Image Represent. 2019, 59, 347–362. [Google Scholar] [CrossRef]
- Hu, X.; Peng, S.; Wang, L.; Yang, Z.; Li, Z. Surveillance video face recognition with single sample per person based on 3D modeling and blurring. Neurocomputing 2017, 235, 46–58. [Google Scholar] [CrossRef]
- Hu, M.; Wang, H.; Wang, X.; Yang, J.; Wang, R. Video facial emotion recognition based on local enhanced motion history image and CNN-CTSLSTM networks. Vis. Commun. Image Represent. 2019, 59, 176–185. [Google Scholar] [CrossRef]
- Hsu, C.Y.; Wang, H.F.; Wang, H.C.; Tseng, K.K. Automatic extraction of face contours in images and videos. Future Gener. Comput. Syst. 2012, 28, 322–335. [Google Scholar] [CrossRef]
- Cui, D.; Zhang, G.; Hu, K.; Han, W.; Huang, G.B. Face recognition using total loss function on face database with ID photos. Opt. Laser Technol. 2019, 110, 227–233. [Google Scholar] [CrossRef]
- Huh, J.H.; Seo, K. Smart Grid Test Bed Using OPNET and Power Line Communication. In Proceedings of the 2016 Joint 8th International Conference on Soft Computing and Intelligent Systems (SCIS) and 17th International Symposium on Advanced Intelligent Systems (ISIS), Sapporo, Japan, 25–28 August 2016. [Google Scholar]
- Naveen, S.; Fathima, R.S.; Moni, R.S. Face recognition and authentication using LBP and BSIF mask detection and elimination. In Proceedings of the 2016 International Conference on Communication Systems and Networks (ComNet), Ahmedabad, India, 19–20 February 2016. [Google Scholar]
- Cakiroglu, O.; Ozer, C.; Gunsel, B. Design of a Deep Face Detector by Mask R-CNN. In Proceedings of the 27th Signal Processing and Communications Applications Conference (SIU), Sivas, Turkey, 24–26 Nisan 2019. [Google Scholar]
- Ramkumar, G.; Logashanmugam, E. An effectual face tracking based on transformed algorithm using composite mask. In Proceedings of the 2016 IEEE International Conference on Computational Intelligence and Computing Research (ICCIC), Chennai, India, 15–17 December 2016. [Google Scholar]
- Kim, D.; Park, S. A Study on Face Masking Scheme in Video Surveillance System. In Proceedings of the 2018 Tenth International Conference on Ubiquitous and Future Networks (ICUFN), Prague, Czech Republic, 3–6 July 2018. [Google Scholar]
- Uddin, M.; Alam, A.; Tu, N.; Islam, M.; Lee, Y. SIAT: A Distributed Video Analytics Framework for Intelligent Video Surveillance. Symmetry 2019, 11, 911. [Google Scholar] [CrossRef] [Green Version]
- Brkić, K.; Hrkać, T.; Kalafatić, Z. Protecting the privacy of humans in video sequences using a computer vision-based de-identification pipeline. Exp. Syst. Appl. 2017, 87, 41–55. [Google Scholar] [CrossRef]
- Gross, R.; Sweeney, L.; de la Torre, F.; Baker, S. Model-Based Face De-Identification. In Proceedings of the 2006 Conference on Computer Vision and Pattern Recognition Workshop (CVPRW’06), New York, NY, USA, 17–22 June 2006. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation | Content |
|---|---|
| P | Random number generation function |
| (i) | Random number generation circuit |
| S | Seed value defined by user |
| N | Face virtualization noise |
| Rgr | Random number generation range |
| Comparison Item | Blurring | Mosaic | Removal and Transformation | Encryption | The Proposed Mechanism |
|---|---|---|---|---|---|
| De-identification | O | O | O | O | O |
| Unable to restore an image by the illegal user | X | X | O | X | O |
| Image reconstruction by legitimate users | O | X | X | O | O |
| Identification of de-identified public information | X | X | X | X | O |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.; Park, N. A Face Image Virtualization Mechanism for Privacy Intrusion Prevention in Healthcare Video Surveillance Systems. Symmetry 2020, 12, 891. https://doi.org/10.3390/sym12060891
Kim J, Park N. A Face Image Virtualization Mechanism for Privacy Intrusion Prevention in Healthcare Video Surveillance Systems. Symmetry. 2020; 12(6):891. https://doi.org/10.3390/sym12060891
Chicago/Turabian StyleKim, Jinsu, and Namje Park. 2020. "A Face Image Virtualization Mechanism for Privacy Intrusion Prevention in Healthcare Video Surveillance Systems" Symmetry 12, no. 6: 891. https://doi.org/10.3390/sym12060891
APA StyleKim, J., & Park, N. (2020). A Face Image Virtualization Mechanism for Privacy Intrusion Prevention in Healthcare Video Surveillance Systems. Symmetry, 12(6), 891. https://doi.org/10.3390/sym12060891