Transfer Detection of YOLO to Focus CNN’s Attention on Nude Regions for Adult Content Detection

 ,
, 

 ,
,  ,
,
Abstract
:1. Introduction
- YOLO3 was utilised as a human detector. To the best of our knowledge, this is the first paper that uses YOLO for the nudity detection task.
- Pre-trained CNNs that have already been trained on the ImageNet dataset were demonstrated as feature extractors having fixed parameters of the first layers. The fully connected layers were removed. The objective was to find discriminative features for the normal/nude classification task.
- Various classifiers were used to replace the top layer of pre-trained CNNs to fit the proposed nudity dataset, in providing two distinct classes: normal and nude.
- An ablation study was undertaken to demonstrate the impact of adding YOLO before CNN.
- An ablation study was performed to provide further insight into the added advantage of data augmentation in nudity detection applications.
- A new challenging nudity dataset was proposed containing humans in various scales with complex backgrounds such as forest, snowing, beach, supermarket, indoor, and streets.
2. Materials and Methods
2.1. Datasets Overview
2.1.1. ImageNet Dataset
2.1.2. COCO Dataset
2.1.3. NDPI Dataset
2.1.4. Our Challenging MMU Dataset
- (1)
- Flip image horizontally.
- (2)
- Convert the two versions of the image (original and flipped) to grey.
- (3)
- Lighten (whiten) the two versions.
- (4)
- Darken the two versions.
2.1.5. Testing Film Dataset
2.2. Methodology
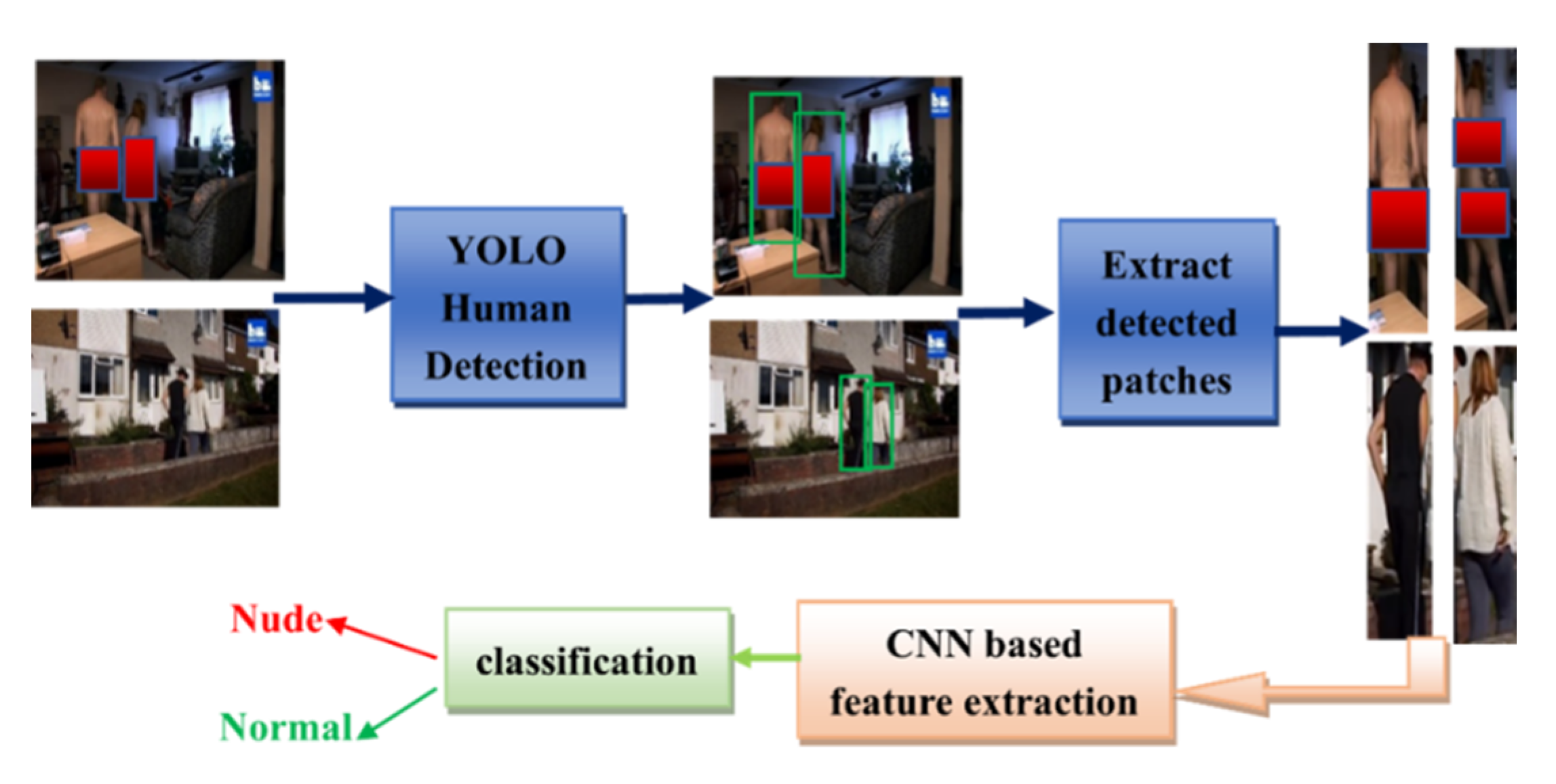
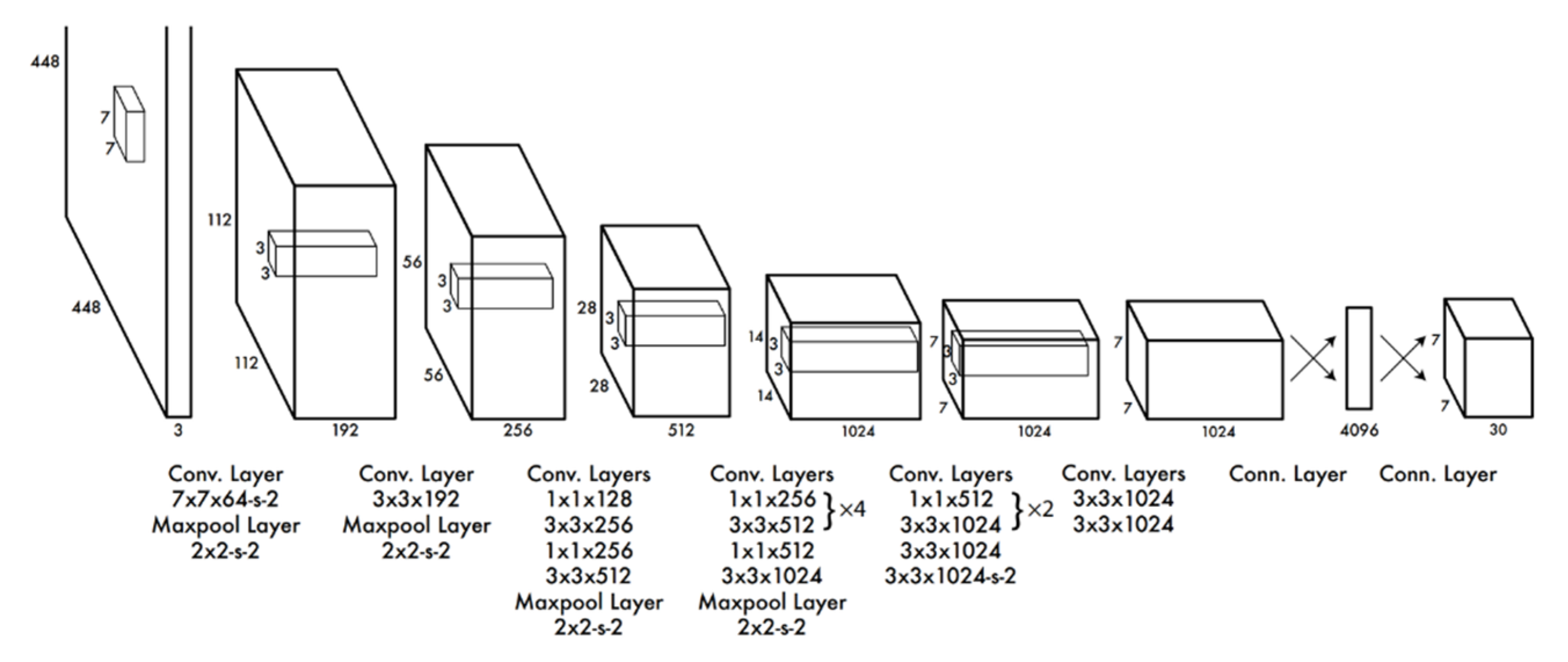
2.2.1. YOLO-Based Human Detection
- Batch normalisation to enhance convergence.
- Fine tuning the classification network on ImageNet at a higher resolution 448 × 448 instead of 224 × 224.
- Using anchor boxes to predict bounding boxes and removing the fully connected layers from YOLO. This plays an important role to enhance recall.
- Shrinking the network to use 416 × 416 input images.
- k-means clustering of the training set of the boxes’ dimensions to find good priors automatically instead of by hand.
- To overcome the model’s instability resulting from anchor boxes, location prediction is directed in making the network more stable.
- Concatenating the higher and lower resolution features by stacking them into different channels instead of spatial locations.
- Training with a variety of input dimensions.
2.2.2. CNN-Based Feature Extraction
- Supervised CNN Model
- Pre-trained CNN Model
2.2.3. Various CNN Architectures
- AlexNet
- VGG
- GoogleNet
- Inception3
- ResNet
2.2.4. Classification
- Support Vector Machine (SVM)
- Extreme Learning Machine (ELM)
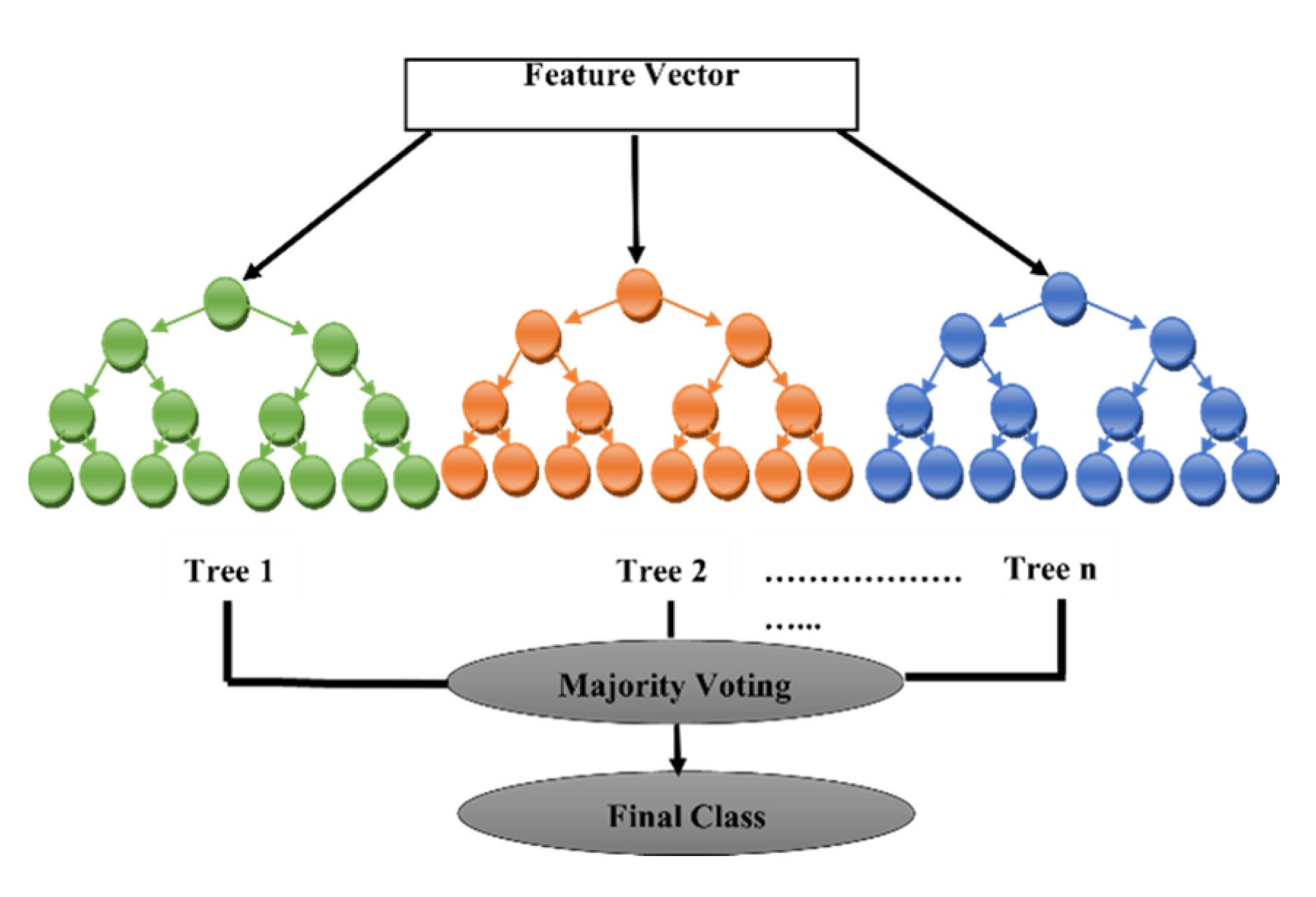
- Random Forest (RF)
- K Nearest Neighbour (KNN)
- Initialise the number of neighbours K.
- The distance between the unseen sample and each sample in the dataset is calculated.
- Store the distance and the index of the sample in a buffer.
- Order the distances and indices inside the buffer in ascending order.
- Pick the first K sample from the sorted buffer.
- Check the labels of the K first samples.
- For the classification task, the mode of the K labels is found and is considered as the predicted category.
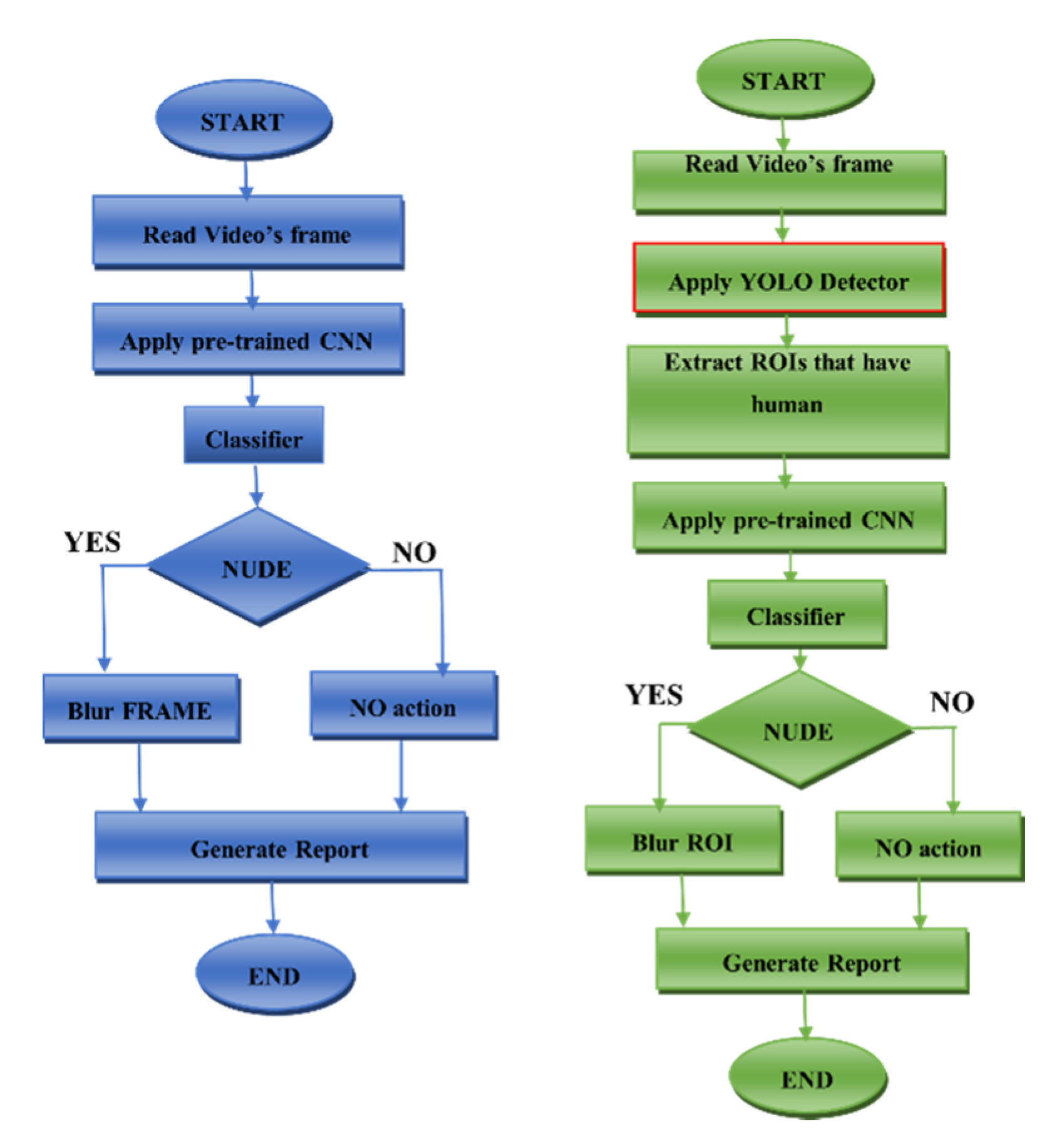
2.2.5. The Proposed YOLO–CNN–SVM Method
3. Experimental Setup and Results
3.1. Performance Metrics
3.2. Experiments
3.2.1. The First Experiment
3.2.2. The Second Experiment
3.2.3. Ablation Study
3.2.4. The Third Experiment
3.2.5. Class Activation Mapping
4. Conclusions and Future Work
- YOLO is a good object detector that can be transferred to detect humans in the nudity dataset as a significant stage in the proposed nudity detection pipeline. This stage plays a role to apply CNN on ROI instead of applying CNN on the whole frame.
- Pre-trained CNN can be transferred after removing the final layers to extract features from visual nudity content.
- Various classifiers such as SVM, RF, and ELM were used to replace the final layers of CNN to fit the extracted features and classify them into normal and nude.
- The proposed system can automatically detect nude humans with various scales in complex backgrounds such as forest, snowing, beach, supermarket, and streets.
- The proposed system runs in real-time as only one frame is sufficient to detect human patches and classify them as normal and nude. This helps to censor live-captured videos.
- The proposed nude/normal classifier is robust against various scales, positions, cloth, and skin colour.
- It outperforms the state-of-the-art methods, such as CNN-only regarding the accuracy, F1 score, and AUC.
- The proposed method can also edit and blur only nude regions inside the frames. In other words, there is no need to blur or cut the whole detected frames from the video.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Nuraisha, S.; Pratama, F.I.; Budianita, A.; Soeleman, M.A. Implementation of K-NN based on histogram at image recognition for pornography detection. In Proceedings of the 2017 International Seminar on Application for Technology of Information and Communication (iSemantic), Semarang, Indonesia, 7–8 October 2017; pp. 5–10. [Google Scholar]
- Garcia, M.B.; Revano, T.F.; Habal, B.G.M.; Contreras, J.O.; Enriquez, J.B.R. A Pornographic Image and Video Filtering Application Using Optimized Nudity Recognition and Detection Algorithm. In Proceedings of the 2018 IEEE 10th International Conference on Humanoid, Nanotechnology, Information Technology, Communication and Control, Environment and Management (HNICEM), Baguio City, Philippines, 29 November–2 December 2018; pp. 1–5. [Google Scholar]
- Ries, C.X.; Lienhart, R. A survey on visual adult image recognition. Multimed. Tools Appl. 2014, 69, 661–688. [Google Scholar] [CrossRef]
- Santos, C.; Dos Santos, E.M.; Souto, E. Nudity detection based on image zoning. In Proceedings of the 2012 11th International Conference on Information Science, Signal Processing and their Applications (ISSPA), Montreal, QC, Canada, 2–5 July 2012; pp. 1098–1103. [Google Scholar]
- Moreira, D.C.; Fechine, J.M. A Machine Learning-based Forensic Discriminator of Pornographic and Bikini Images. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Moustafa, M. Applying deep learning to classify pornographic images and videos. Pacific Rim Symposium on Image and Video Technology. arXiv 2015, arXiv:1511.08899v1. [Google Scholar]
- Automated Nudity Recognition using Very Deep Residual Learning Network. Int. J. Recent Technol. Eng. 2019, 8, 136–141. [CrossRef]
- Nurhadiyatna, A.; Cahyadi, S.; Damatraseta, F.; Rianto, Y. Adult content classification through deep convolution neural network. In Proceedings of the 2017 International Conference on Computer, Control, Informatics and its Applications (IC3INA), Jakarta, Indonesia, 23–26 October 2017; pp. 106–110. [Google Scholar]
- Wehrmann, J.; Simões, G.S.; Barros, R.C.; Cavalcante, V.F. Adult content detection in videos with convolutional and recurrent neural networks. Neurocomputing 2018, 272, 432–438. [Google Scholar] [CrossRef]
- Perez, M.; Avila, S.; Moreira, D.; Moraes, D.; Testoni, V.; Valle, E.; Goldenstein, S.; Rocha, A. Video pornography detection through deep learning techniques and motion information. Neurocomputing 2017, 230, 279–293. [Google Scholar] [CrossRef]
- Wang, Y.; Jin, X.; Tan, X. Pornographic image recognition by strongly-supervised deep multiple instance learning. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 4418–4422. [Google Scholar]
- AlDahoul, N.; Karim, H.A.; Abdullah, M.H.L.; Fauzi, M.F.A.; Mansour, S.; See, J.; Alfrahoul, N. Local Receptive Field-Extreme Learning Machine based Adult Content Detection. In Proceedings of the 2019 IEEE International Conference on Signal and Image Processing Applications (ICSIPA), Kuala Lumpur, Malaysia, 17–19 September 2019; pp. 128–133. [Google Scholar]
- Kiefer, J.; Wolfowitz, J. Stochastic Estimation of the Maximum of a Regression Function. Ann. Math. Stat. 1952, 23, 462–466. [Google Scholar] [CrossRef]
- Bottou, L.; Curtis, F.; Nocedal, J. Optimization Methods for Large-Scale Machine Learning. SIAM Rev. 2018, 60, 223–311. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. IEEE Conf. Comput. Vis. Pattern Recognit. 2009, 248–255. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). arXiv 2014, arXiv:10.1007/978-3-319-10602-1_48. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. Conf. Proc. 2016, 2818–2826. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hearst, M.A.; Scholkopf, B.; Dumais, S.; Osuna, E.; Platt, J. Support vector machines. IEEE Intell. Syst. 1998, 13, 18–28. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Da Silva, M.V.; Marana, A.N. Spatiotemporal CNNs for pornography detection in videos. In Proceedings of the Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Madrid, Spain, 19–22 November 2019; pp. 547–555. [Google Scholar] [CrossRef] [Green Version]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A Closer Look at Spatiotemporal Convolutions for Action Recognition. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6450–6459. [Google Scholar]
- NPDI Pornography Database, 2013. Available online: https://sites.google.com/site/pornographydatabase/ (accessed on 1 April 2019).
- Avila, S.; Thome, N.; Cord, M.; Valle, E.; Araújo, A.D.A. Pooling in image representation: The visual codeword point of view. Comput. Vis. Image Underst. 2013, 117, 453–465. [Google Scholar] [CrossRef]
- Nian, F.; Li, T.; Wang, Y.; Xu, M.; Wu, J. Pornographic image detection utilizing deep convolutional neural networks. Neurocomputing 2016, 210, 283–293. [Google Scholar] [CrossRef]
- Liu, B.-B.; Su, J.-Y.; Lu, Z.-M.; Li, Z. Pornographic Images Detection Based on CBIR and Skin Analysis. In Proceedings of the 2008 Fourth International Conference on Semantics, Knowledge and Grid, Beijing, China, 3–5 December 2008; pp. 487–488. [Google Scholar]
- Dollár, P.; Belongie, S.; Perona, P. The fastest pedestrian detector in the west. In Proceedings of the British Machine Vision Conference, BMVC 2010-Proceedings, Aberystwyth, UK, 31 August–3 September 2010; pp. 68.1–68.11. [Google Scholar] [CrossRef] [Green Version]
- AlDahoul, N.; Sabri, A.Q.M.; Mansoor, A.M. Real-Time Human Detection for Aerial Captured Video Sequences via Deep Models. Comput. Intell. Neurosci. 2018, 2018, 1639561. [Google Scholar] [CrossRef] [Green Version]
- Shinde, S.; Kothari, A.; Gupta, V. YOLO based Human Action Recognition and Localization. Procedia Comput. Sci. 2018, 133, 831–838. [Google Scholar] [CrossRef]
- Ivašić-Kos, M.; Krišto, M.; Pobar, M. Human detection in thermal imaging using YOLO. In Proceedings of the 2019 5th International Conference on Computer and Technology Applications, Istanbul, Turkey, 16–17 April 2019; pp. 254–267. [Google Scholar] [CrossRef]
- Simoes, G.S.; Wehrmann, J.; Barros, R.C. Attention-based Adversarial Training for Seamless Nudity Censorship. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]
- Ion, C.; Minea, C. Application of Image Classification for Fine-Grained Nudity Detection. In Proceedings of the Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Lake Tahoe, NV, USA, 7–9 October 2019; pp. 3–15. [Google Scholar] [CrossRef]
- Connie, T.; Al-Shabi, M.; Goh, M. Smart content recognition from images using a mixture of convolutional neural networks. In IT Convergence and Security 2017; Springer: Singapore, 2018; pp. 11–18. [Google Scholar] [CrossRef] [Green Version]
- Shen, R.; Zou, F.; Song, J.; Yan, K.; Zhou, K. EFUI: An ensemble framework using uncertain inference for pornographic image recognition. Neurocomputing 2018, 322, 166–176. [Google Scholar] [CrossRef]
- Li, D.; Li, N.; Wang, J.; Zhu, T. Pornographic images recognition based on spatial pyramid partition and multi-instance ensemble learning. Knowl. Based Syst. 2015, 84, 214–223. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Altman, N.S. An Introduction to Kernel and Nearest-Neighbor Nonparametric Regression. Am. Stat. 1992, 46, 175. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.-B.; Zhu, Q.-Y.; Siew, C.-K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Moreira, D.; Avila, S.; Perez, M.; Moraes, D.; Testoni, V.; Valle, E.; Goldenstein, S.; Torres, R.D.S. Pornography classification: The hidden clues in video space–time. Forensic Sci. Int. 2016, 268, 46–61. [Google Scholar] [CrossRef]
- SciKit Learn Library for Machine Learning. Available online: https://scikit-learn.org/ (accessed on 20 September 2020).
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. In Proceedings of Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2921–2929. [Google Scholar]
- Narayanan, B.N.; Silva, M.S.D.; Hardie, R.C.; Kueterman, N.K.; Ali, R. Understanding Deep Neural Network Predictions for Medical Imaging Applications. arXiv 2019, arXiv:1912.09621v1. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10778–10787. [Google Scholar]
- AlDahoul, N.; Karim, H.A.; Mansour, S. Convolutional Neural Network-based Transfer Learning and Classification of Visual Contents for Film Censorship. J. Eng. Technol. Appl. Phys. 2020, 2, 28–35. [Google Scholar]
- Mahajan, D.; Girshick, R.; Ramanathan, V.; He, K.; Paluri, M.; Li, Y.; Bharambe, A.; van der Maaten, L. Exploring the Limits of Weakly Supervised Pretraining. In Proceedings of the European Conference on Computer Vision. In Proceedings of the Lecture Notes in Computer Science, Munich, Germany, 8–14 September 2018; pp. 185–201. [Google Scholar] [CrossRef] [Green Version]
- Flaute, D.; Narayanan, B.N. Video captioning using weakly supervised convolutional neural networks, Proc. SPIE 11511. Appl. Mach. Learn. 2020. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Frames | Training (no AUG) | Training (AUG) | Validation | Total (no AUG) |
|---|---|---|---|---|
| Total | 640 | 5120 | 160 | 800 |
| Negative | 320 | 2560 | 80 | 400 |
| Positive | 320 | 2560 | 80 | 400 |
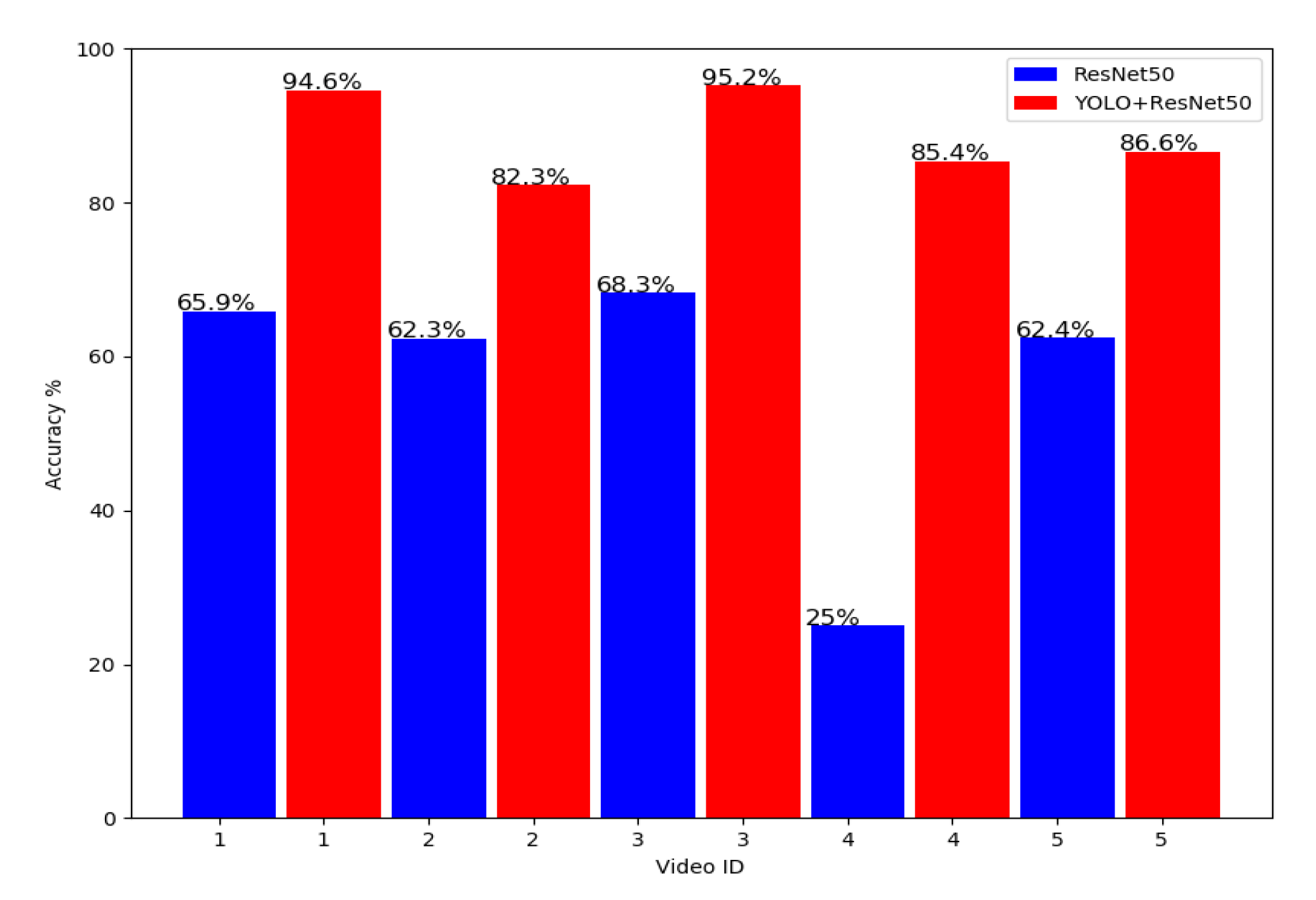
| Video ID | Video Title | Length (M:S) |
|---|---|---|
| 1 | world naked bike rider | 02:03 |
| 2 | Naked Parents | 45:22 |
| 3 | Il est de retour…uniforme et képi restauré | 01:09 |
| 4 | Naked European Walking Tour 2017 | 14:40 |
| 5 | World naked bike ride London June 8th, 2013 | 02:17 |
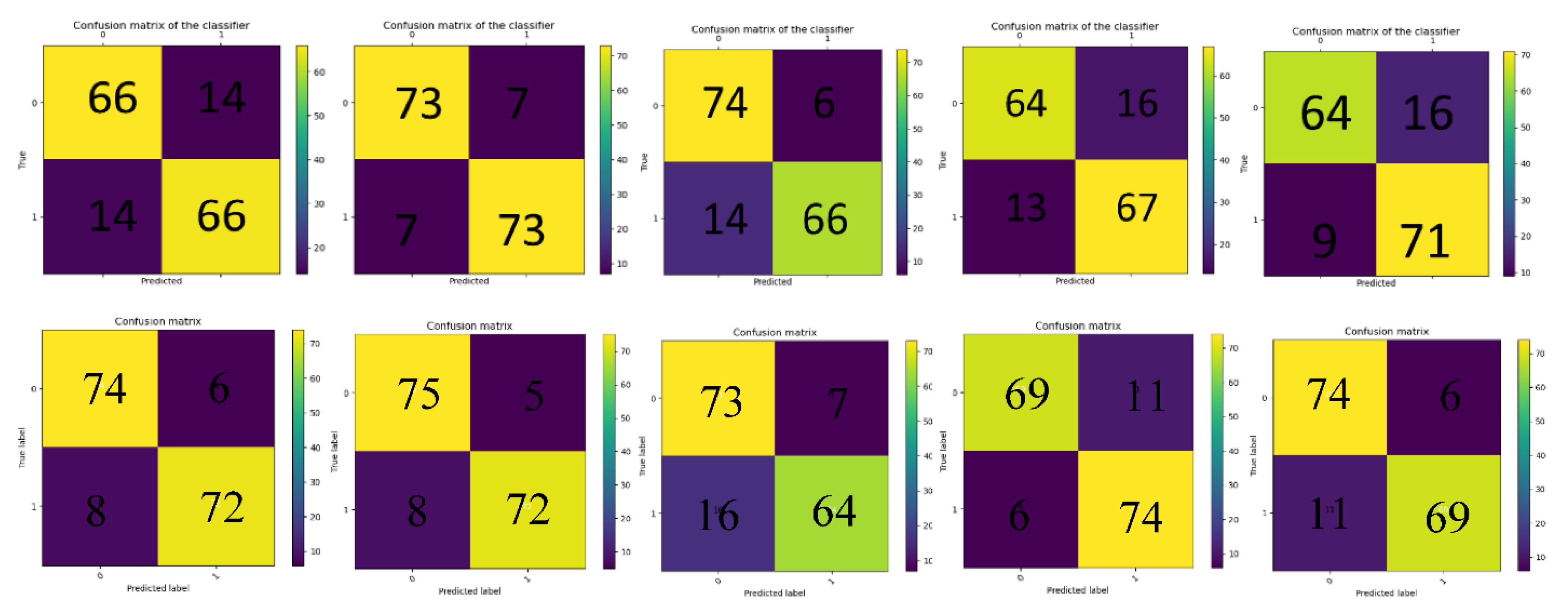
| Video ID | Precision% | FNR% | FPR% | NPV% | F1-Score% |
|---|---|---|---|---|---|
| 1 | 97 | 65.8 | 68.2 | 11.2 | 50.57 |
| 2 | 62.8 | 80.8 | 7.9 | 62.3 | 29.41 |
| 3 | - | 100 | 0 | 68.3 | - |
| 4 | 88.7 | 90.4 | 5.5 | 18.8 | 17.32 |
| 5 | 90.5 | 37.9 | 35.8 | 23.6 | 73.66 |
| Video ID | Precision% | FNR% | FPR% | NPV% | F1-Score% |
|---|---|---|---|---|---|
| 1 | 94.6 | 0 | 90.9 | 100 | 97.23 |
| 2 | 73 | 10 | 23.1 | 91.8 | 80.61 |
| 3 | 86.9 | 0 | 7 | 100 | 92.99 |
| 4 | 87.5 | 4.1 | 61.7 | 67.4 | 91.51 |
| 5 | 87.7 | 2.1 | 75.5 | 68.4 | 92.52 |
| 5 Cross-Validations | ResNet50 (No AUG) Accuracy% | ResNet50 (AUG) Accuracy% | YOLO-ResNet50 (AUG) Accuracy% |
|---|---|---|---|
| K = 1 | 82.500 | 82.500 | 91.250 |
| K = 2 | 89.375 | 91.250 | 91.875 |
| K = 3 | 84.375 | 87.500 | 85.625 |
| K = 4 | 78.125 | 81.875 | 89.375 |
| K = 5 | 84.375 | 84.375 | 89.375 |
| Average % | 83.500 | 85.500 | 89.500 |
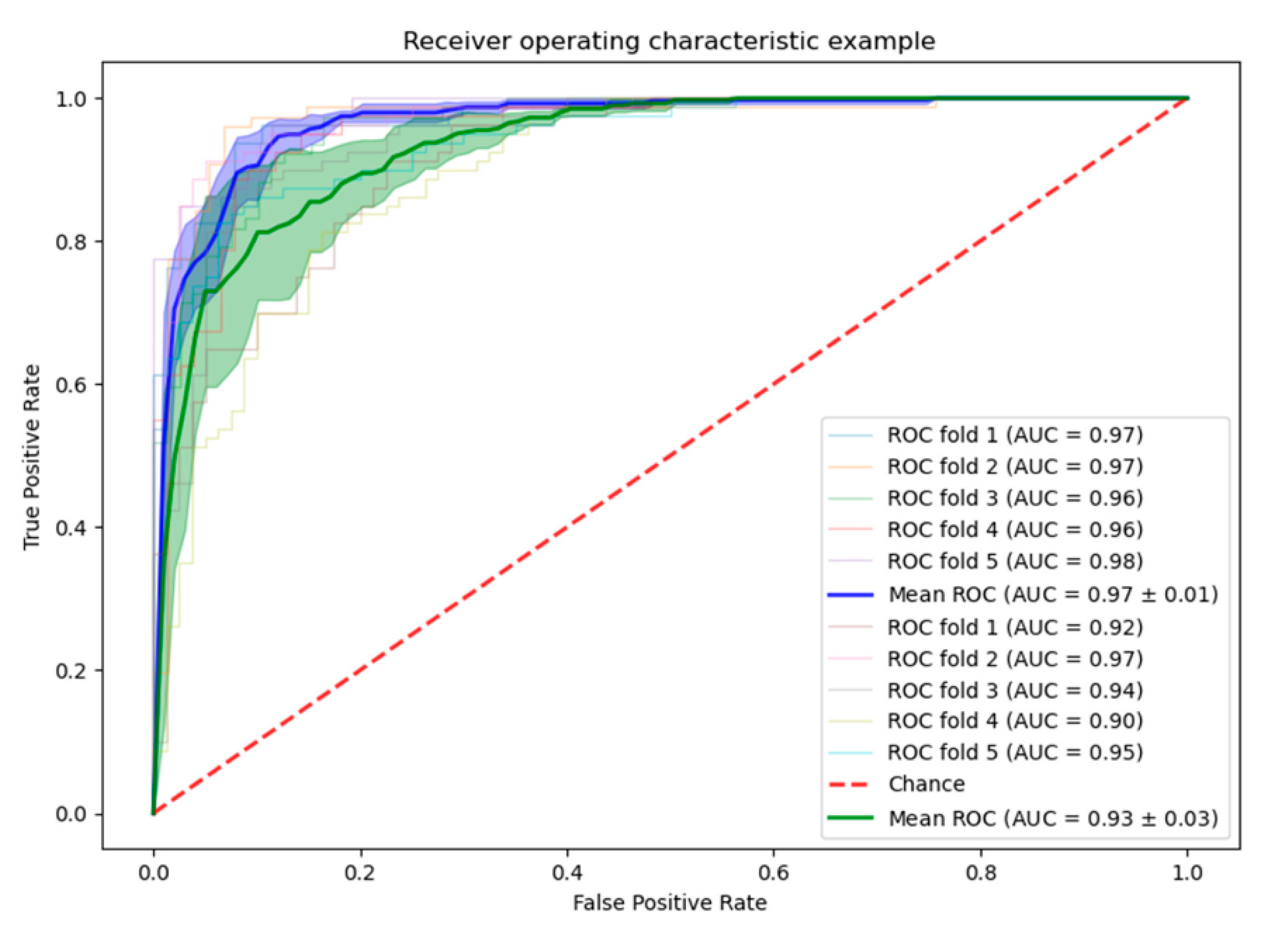
| Performance Metric | ResNet50 (AUG) | YOLO-ResNet50 (AUG) |
|---|---|---|
| Average Precision | 85.5498 | 91.0028 |
| Average Recall | 85.7500 | 87.7500 |
| Average FNR | 14.2500 | 12.2500 |
| Average FPR | 14.7500 | 8.7500 |
| Average NPV | 85.7258 | 88.3373 |
| Average F1 score | 85.5661 | 89.2713 |
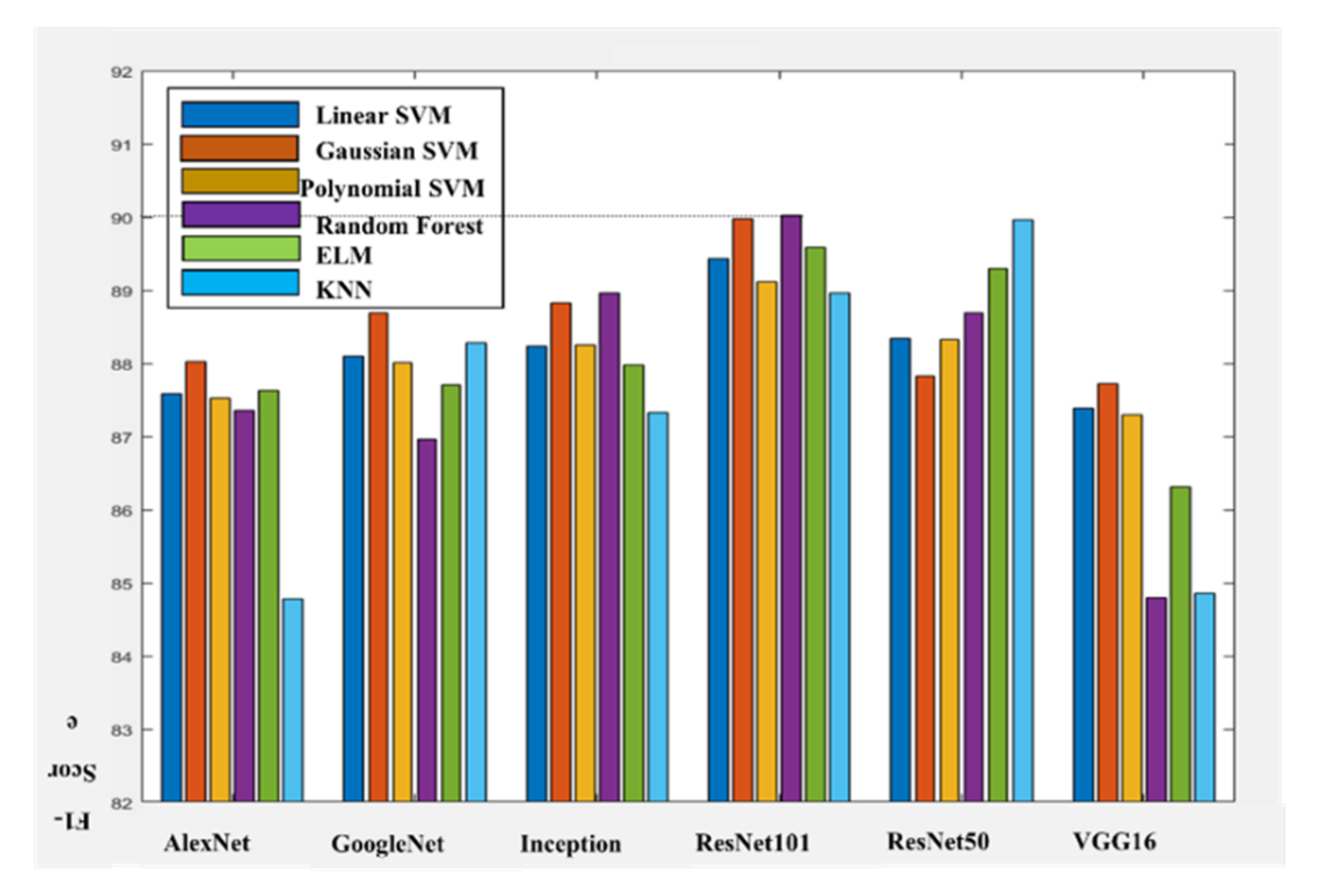
| Feature Extractor | Classifier | LSVM [7,10] | GSVM (Proposed) | PSVM (Proposed) | KNN (Proposed) | RF (Proposed) | ELM (Proposed) |
|---|---|---|---|---|---|---|---|
| AlexNet [7] | Accuracy (%) | 83.8093 | 84.6136 | 83.8210 | 79.3799 | 84.0657 | 83.8326 |
| Precision (%) | 80.2326 | 81.6636 | 80.5257 | 75.3211 | 82.3971 | 80.1207 | |
| FNR (%) | 3.5820 | 4.5463 | 4.1330 | 3.0506 | 7.0459 | 3.3064 | |
| FPR (%) | 34.5054 | 31.1321 | 33.6764 | 46.1407 | 28.8451 | 34.8485 | |
| NPV (%) | 7.3595 | 8.7500 | 8.3004 | 7.6018 | 12.5746 | 6.8655 | |
| F1 score (%) | 87.5838 | 88.0218 | 87.5292 | 84.7775 | 87.3578 | 87.6305 | |
| VGG16 (proposed) | Accuracy (%) | 84.1940 | 84.5437 | 83.9375 | 80.0443 | 81.2566 | 82.6786 |
| Precision (%) | 82.8541 | 82.8177 | 82.0940 | 77.0863 | 81.6130 | 81.1040 | |
| FNR (%) | 7.5576 | 6.7506 | 6.7900 | 5.6485 | 11.7693 | 7.7544 | |
| FPR (%) | 27.7873 | 28.1018 | 29.5312 | 40.7376 | 28.8736 | 31.2178 | |
| NPV (%) | 13.1959 | 12.0014 | 12.2776 | 12.1610 | 19.3778 | 14.0714 | |
| F1 score (%) | 87.3860 | 87.7245 | 87.2996 | 84.8495 | 84.7929 | 86.3168 | |
| GoogleNet [7] | Accuracy (%) | 84.9866 | 86.2805 | 84.9400 | 85.0332 | 84.2522 | 84.3222 |
| Precision (%) | 83.0573 | 86.6779 | 83.2543 | 82.2929 | 85.2819 | 81.8771 | |
| FNR (%) | 6.2192 | 9.2108 | 6.6522 | 4.7825 | 11.2773 | 5.5698 | |
| FPR (%) | 27.7873 | 20.2687 | 27.2727 | 29.7599 | 22.2413 | 30.3602 | |
| NPV (%) | 11.1189 | 14.3691 | 11.7280 | 9.0000 | 17.4005 | 10.4082 | |
| F1 score (%) | 88.0939 | 88.6859 | 88.0126 | 88.2847 | 86.9683 | 87.7068 | |
| Inception3 (proposed) | Accuracy (%) | 85.5461 | 86.5602 | 85.4528 | 83.7860 | 86.5952 | 85.3363 |
| Precision (%) | 85.1804 | 87.4952 | 84.6001 | 81.2924 | 86.8416 | 85.5099 | |
| FNR (%) | 8.4826 | 9.8012 | 7.7741 | 5.6682 | 8.8172 | 9.4076 | |
| FPR (%) | 23.1275 | 18.7250 | 24.3854 | 31.5323 | 20.0686 | 22.2985 | |
| NPV (%) | 13.8141 | 14.9057 | 12.9934 | 10.7343 | 13.8101 | 14.9562 | |
| F1 score (%) | 88.2353 | 88.8264 | 88.2486 | 87.3280 | 88.9593 | 87.9778 | |
| ResNet50 [10] | Accuracy (%) | 84.9400 | 84.0774 | 84.8584 | 87.6559 | 85.7443 | 86.3154 |
| Precision (%) | 81.5803 | 80.2771 | 81.3079 | 86.7373 | 83.6180 | 83.1495 | |
| FNR (%) | 3.6804 | 3.0703 | 3.3458 | 6.5538 | 5.5698 | 3.5623 | |
| FPR (%) | 31.5895 | 34.5912 | 32.2756 | 20.7547 | 26.8725 | 28.3877 | |
| NPV (%) | 7.2481 | 6.3830 | 6.6955 | 10.7246 | 9.9613 | 6.7386 | |
| F1 score (%) | 88.3394 | 87.8210 | 88.3194 | 89.9669 | 88.6958 | 89.3020 | |
| ResNet101 [10] | Accuracy (%) | 86.5252 | 87.4228 | 86.1056 | 86.7001 | 87.7492 | 86.8400 |
| Precision (%) | 83.5184 | 85.2289 | 83.1656 | 87.4952 | 86.9048 | 84.3652 | |
| FNR (%) | 3.7591 | 4.7235 | 4.0346 | 9.5257 | 6.6129 | 4.5267 | |
| FPR (%) | 27.5872 | 23.9851 | 28.2161 | 18.7822 | 20.4403 | 25.7004 | |
| NPV (%) | 7.0117 | 8.2787 | 7.5479 | 14.5564 | 10.7727 | 8.1301 | |
| F1 score (%) | 89.4294 | 89.9731 | 89.1082 | 88.9598 | 90.0294 | 89.5762 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
AlDahoul, N.; Abdul Karim, H.; Lye Abdullah, M.H.; Ahmad Fauzi, M.F.; Ba Wazir, A.S.; Mansor, S.; See, J. Transfer Detection of YOLO to Focus CNN’s Attention on Nude Regions for Adult Content Detection. Symmetry 2021, 13, 26. https://doi.org/10.3390/sym13010026
AlDahoul N, Abdul Karim H, Lye Abdullah MH, Ahmad Fauzi MF, Ba Wazir AS, Mansor S, See J. Transfer Detection of YOLO to Focus CNN’s Attention on Nude Regions for Adult Content Detection. Symmetry. 2021; 13(1):26. https://doi.org/10.3390/sym13010026
Chicago/Turabian StyleAlDahoul, Nouar, Hezerul Abdul Karim, Mohd Haris Lye Abdullah, Mohammad Faizal Ahmad Fauzi, Abdulaziz Saleh Ba Wazir, Sarina Mansor, and John See. 2021. "Transfer Detection of YOLO to Focus CNN’s Attention on Nude Regions for Adult Content Detection" Symmetry 13, no. 1: 26. https://doi.org/10.3390/sym13010026
APA StyleAlDahoul, N., Abdul Karim, H., Lye Abdullah, M. H., Ahmad Fauzi, M. F., Ba Wazir, A. S., Mansor, S., & See, J. (2021). Transfer Detection of YOLO to Focus CNN’s Attention on Nude Regions for Adult Content Detection. Symmetry, 13(1), 26. https://doi.org/10.3390/sym13010026