
Intelligent Detection of False Information in Arabic Tweets Utilizing Hybrid Harris Hawks Based Feature Selection and Machine Learning Models




Abstract
:1. Introduction
- Conducting different feature extraction models (i.e., TF, BTF, and TF-IDF) and eight well-known ML algorithms to identify suitable models for detecting fake news in Arabic tweets.
- Adapting a binary variant of the HHO algorithm, for the first time in the text classification domain, with the sake of eliminating the irrelevant/redundant features and enhancing the performance of classification models. HHO has been recently utilized as an FS approach to deal with complex datasets by the first author of this work and his co-authors in [22,23]. HHO has shown its superiority compared to several recent optimization algorithms such as Binary Gray Wolf Optimization (BGWO) and Binary WOA in the FS domain. For this reason, it has been nominated in this work to tackle the problem of FS in Arabic text classification.
- The efficiency of the proposed model has been verified by comparing it with other state-of-the-art approaches and has shown promising results.
2. Review of Related Works
2.1. Sentiment Analysis
2.2. False Information Detection
3. Theoretical Background (Preliminaries)
3.1. Natural Language Processing (NLP)
3.1.1. Tokenization and Linguistic Modules
3.1.2. Text Vectorization
3.1.3. Term Frequency-Based Model
3.1.4. Term Frequency-Inverse Document Frequency Scheme
3.2. Harris Hawks Optimizer (HHO)
3.2.1. Exploration Phase
3.2.2. Shifting from Exploration to Exploitation
3.2.3. Exploitation Phase
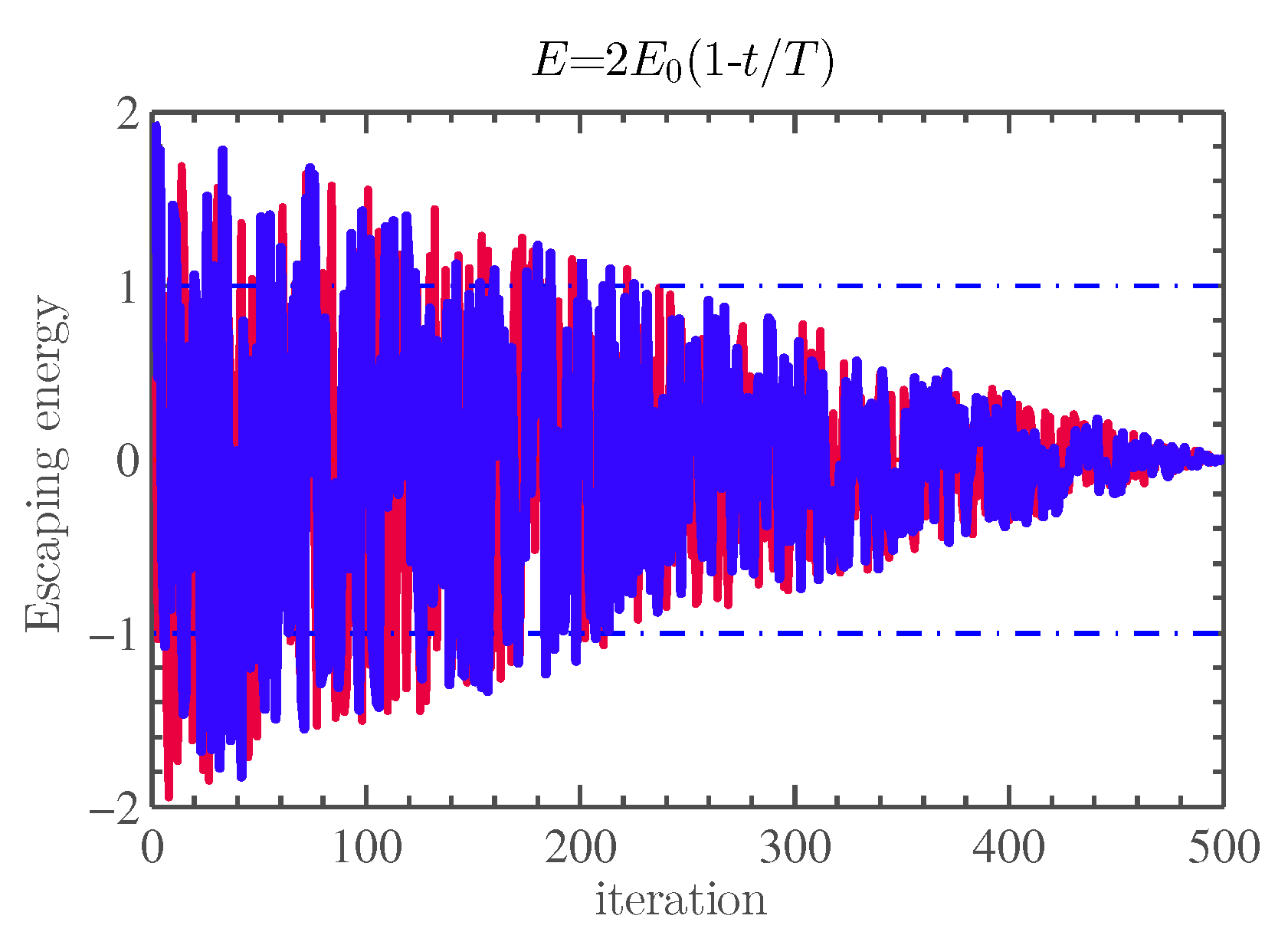
- Soft besiege: This phase simulates the behavior of the rabbit when it still has energy and tries to escape ( and ). During these attempts, the hawks try to encircle the prey softly. This behavior is modeled by Equations (8) and (9):where refers to the difference between the prey’s position and the current hawk’s location in iteration t, represents the random jump strength of the prey during the escaping operation. The J value changes randomly in each iteration to simulate the nature of rabbit motions [20].
- Hard besiege: The next level of the encircling process will be performed when the rabbit is extremely exhausted, and its escaping energy is low ( and ). Accordingly, the hawks encircle the intended prey hardly. This behavior is modeled by Equation (10):
- Soft besiege with progressive rapid dives: When the prey still has sufficient energy to escape () but (), hawks can decide (evaluate) their next action based on the rule represented in Equation (11):
- Hard besiege with progressive rapid dives: In the case of ( and ), the hawks perform a hard besiege to approach the prey. They try to decrease the distances between their average location and the targeted prey. Accordingly, the rule given in Equation (16) is performed:where Y and Z can be calculated using Equations (17) and (18):
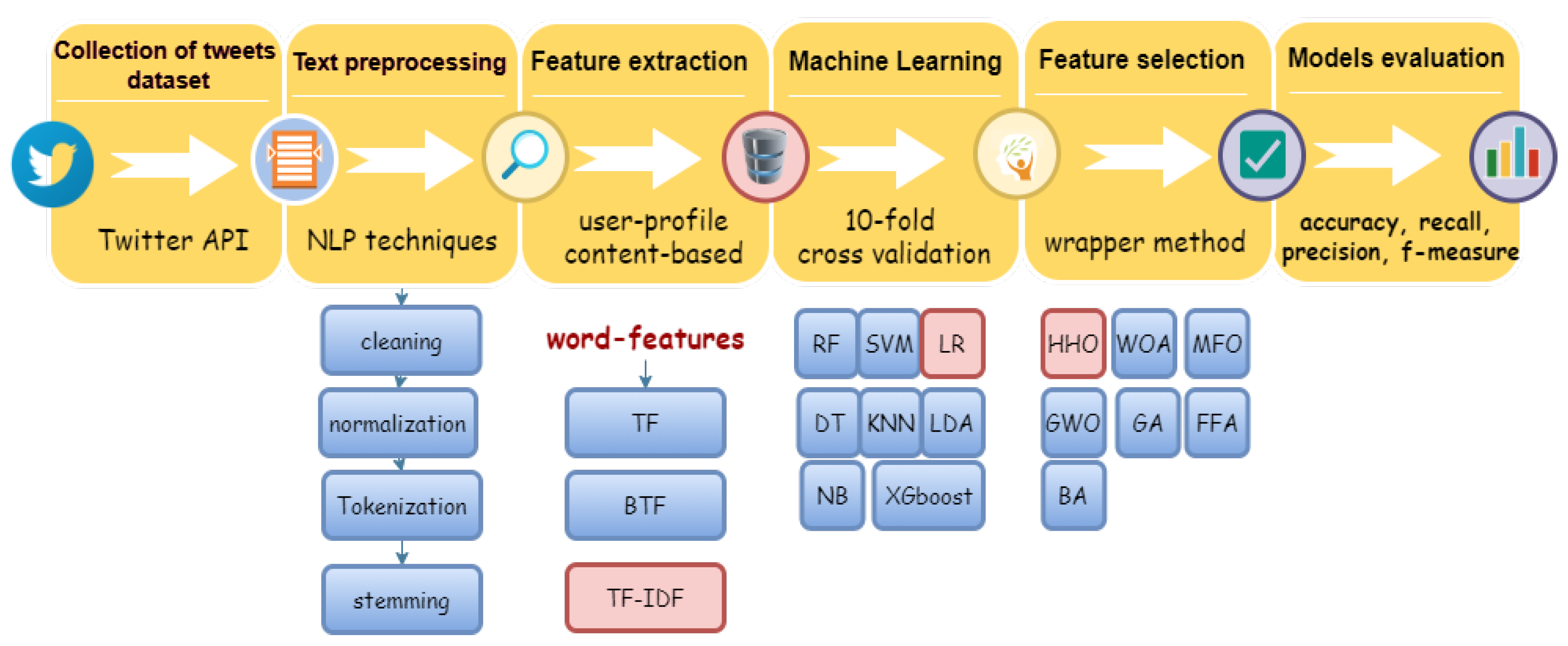
4. The Proposed Methodology
4.1. Collection of the Tweets Dataset
4.2. Data Preprocessing
4.3. Feature Extraction
- User-profile features only.
- Contend-based features only.
- Word features only including either TF, TF-IDF, or BoW.
- User-profile and content-based features
- User-profile features and one set of word features (TF, TF-IDF, BoW).
- Content-based features and one set of word features (TF, TF-IDF, BoW).
- User-profile features and content-based features and one set of word features (TF, TF-IDF, BoW).
4.4. Selection of Classification Algorithms
4.5. Feature Selection Using Binary HHO
4.6. Performance Evaluation Measures
- Accuracy: It is the number of correctly classified real and fake tweets divided by the total number of predictions. Accuracy is calculated using Equation (22):
- Recall: It is known as true positive rate, which is the ratio of correctly recognized tweets as positive (real) over the total number of actual positives, calculated as in Equation (23):
- Precision: It is known as a positive predictive value, which is the fraction of tweets that are correctly recognized as positive (real) among the total number of positive predictions, calculated as in Equation (24):
- F1_measure: It is defined as a harmonic mean of recall and precision metrics and can be computed as given in Equation (25). It is known as a balanced F-score since recall and precision are evenly weighted. This measure is informative in terms of incorrectly classified instances and useful to balance the prediction performances on the fake and real classes:
5. Results and Discussion
5.1. Experimental Setup
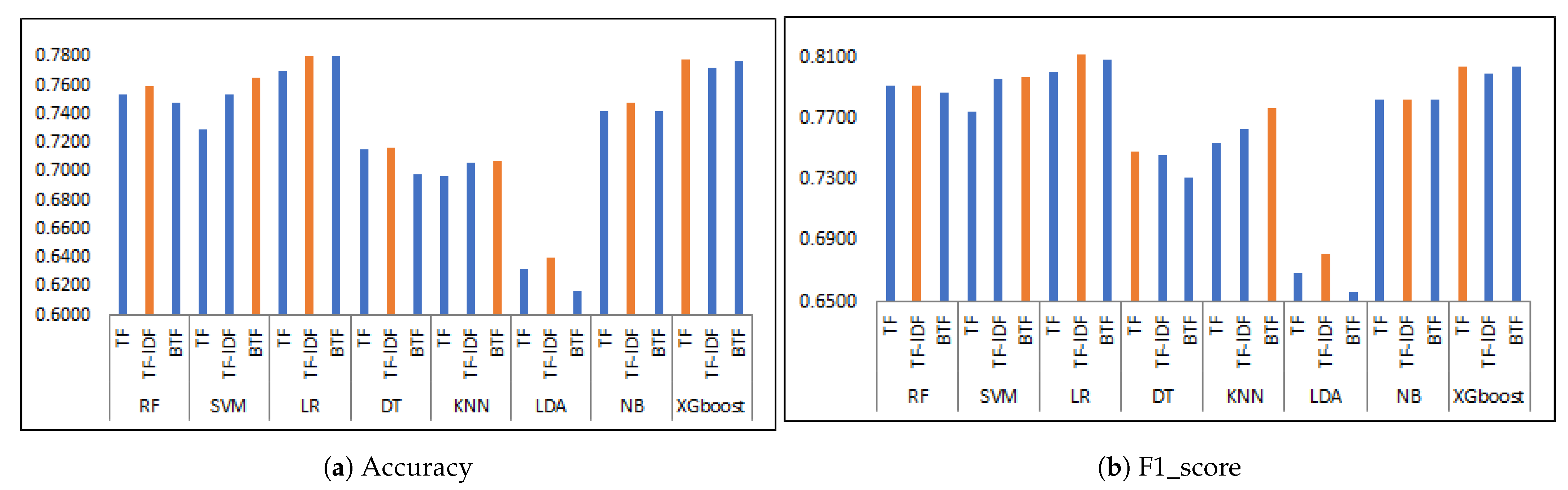
5.2. Evaluation of Classification Methods
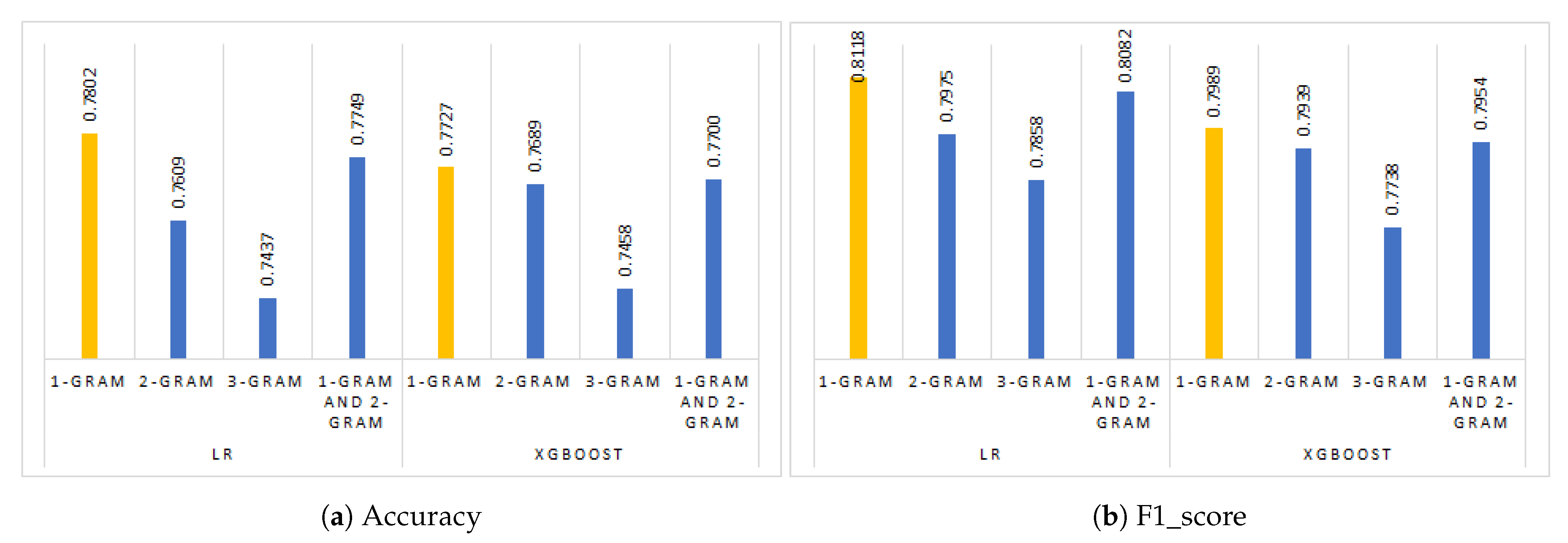
5.3. Assessing the Impact of n-Grams
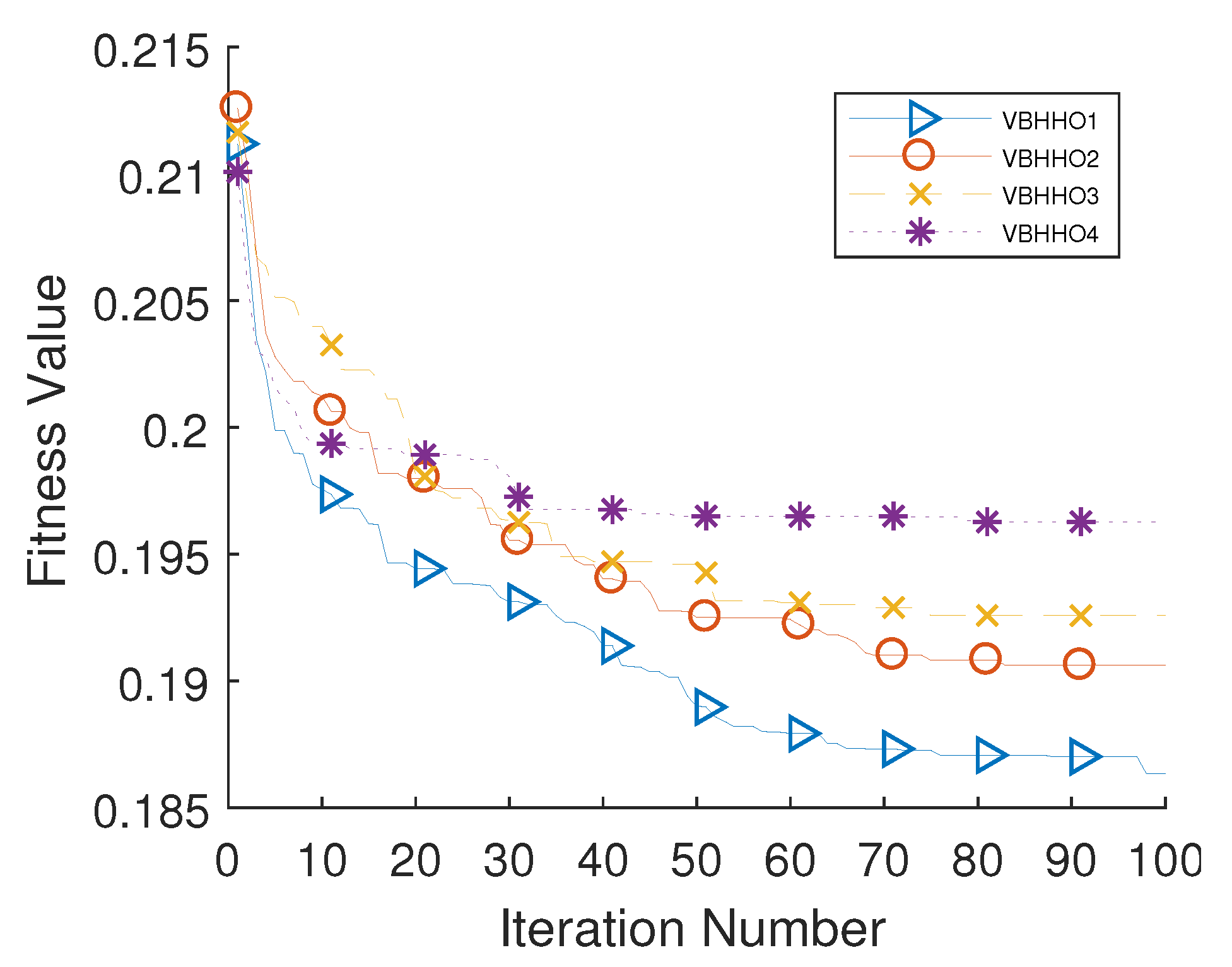
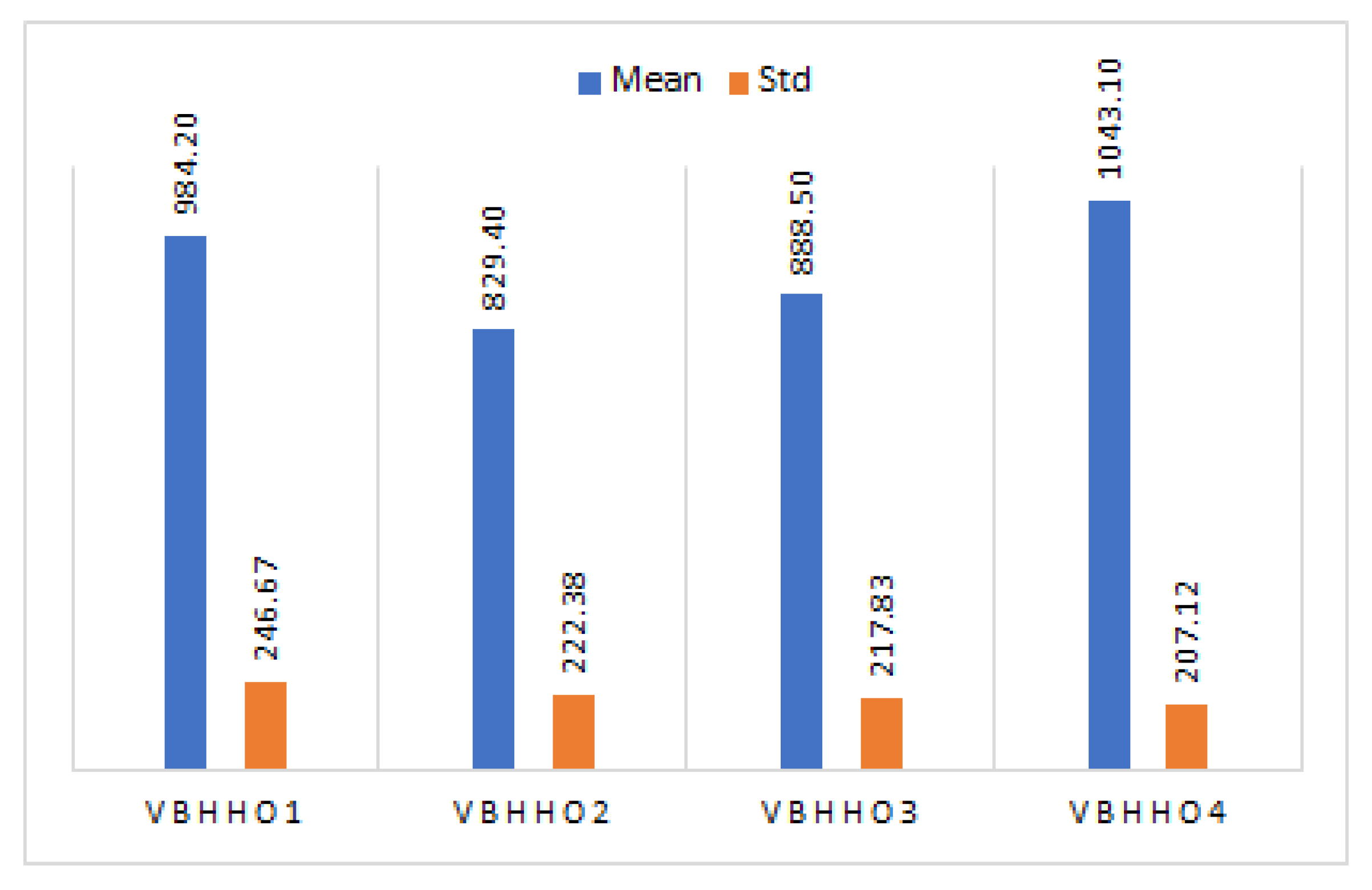
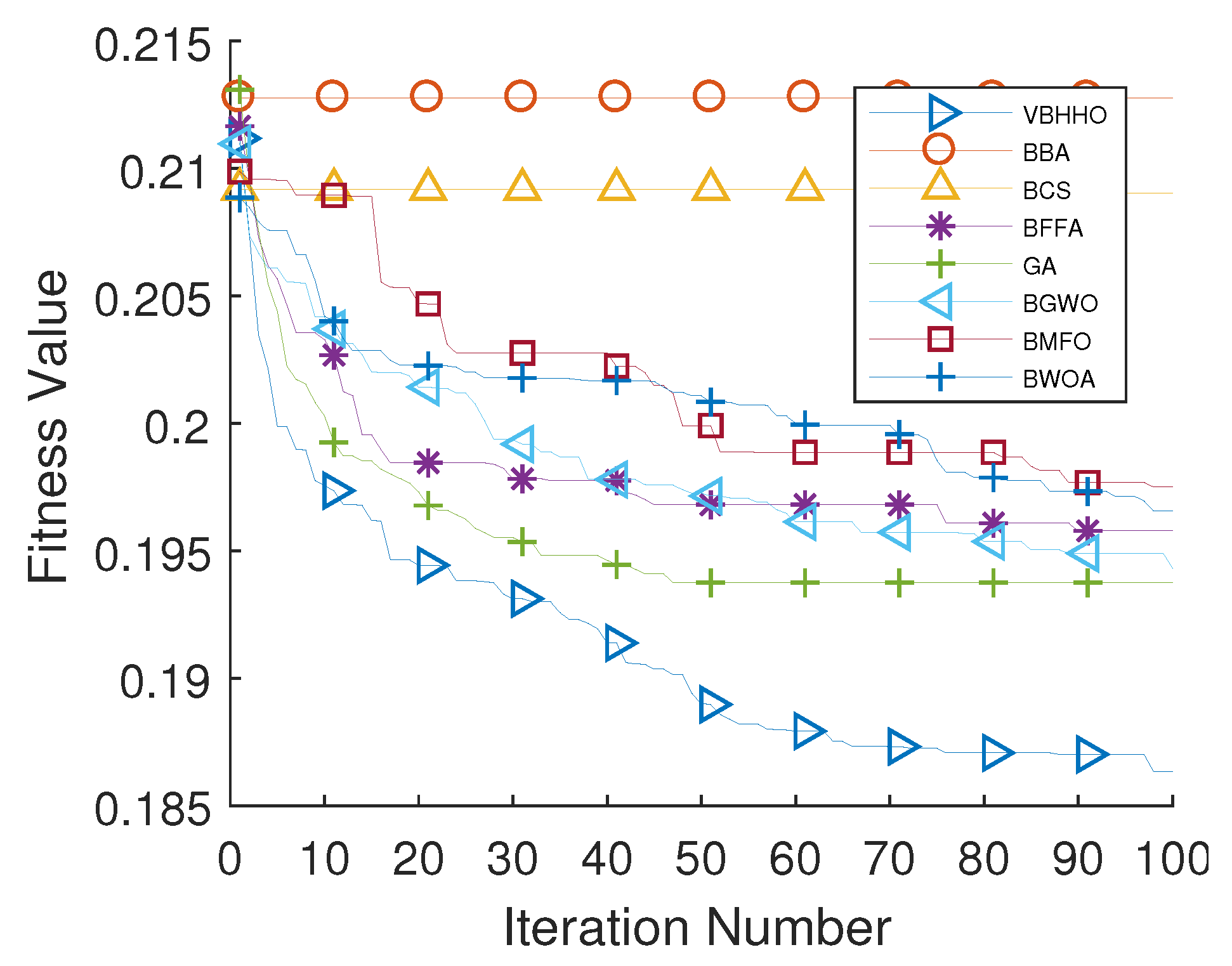
5.4. Analysis of BHHO-Based Feature Selection
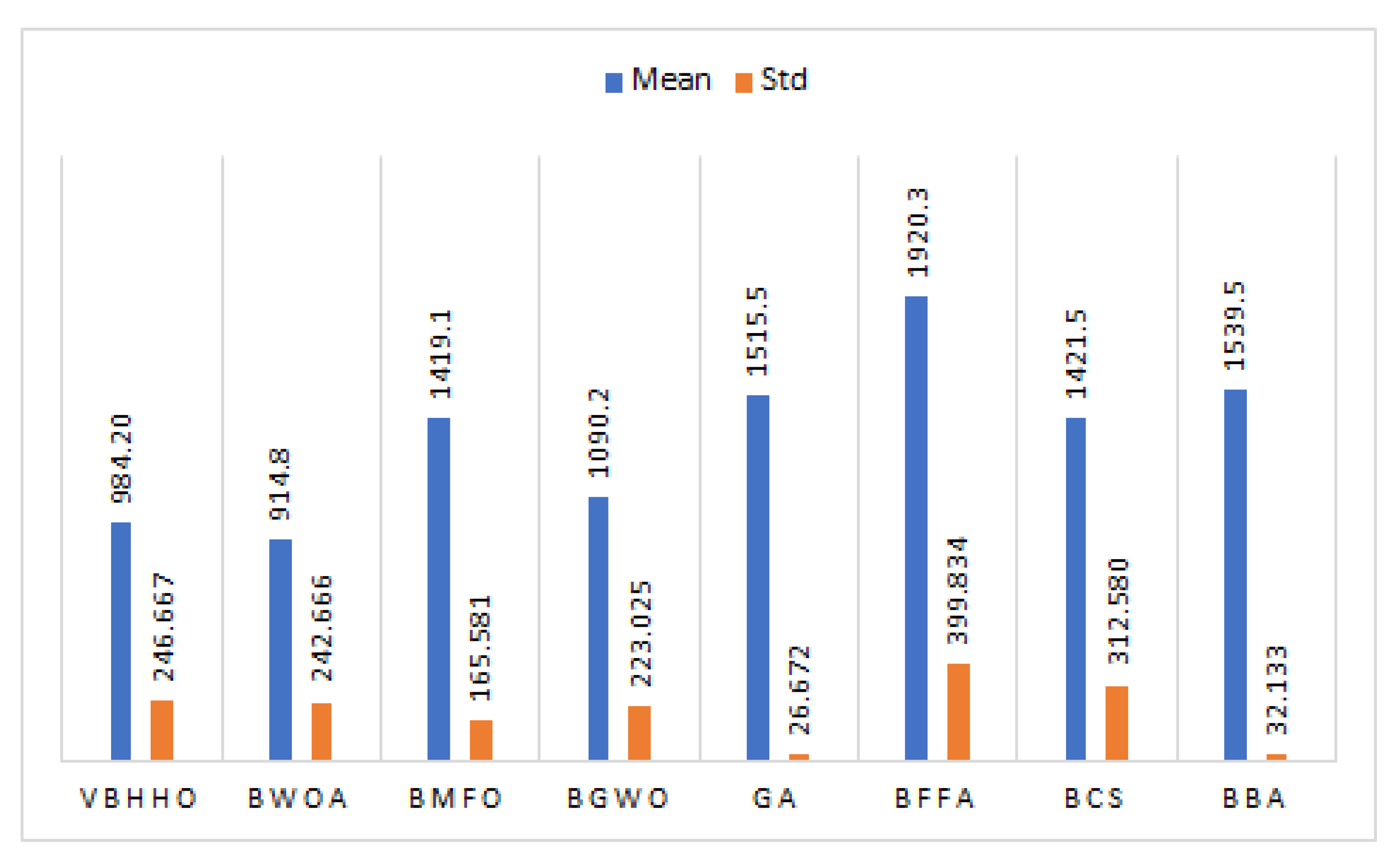
5.5. Comparison with Results of the Literature
6. Conclusions and Future Perspectives
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Rout, J.; Choo, K.K.R.; Dash, A.; Bakshi, S.; Jena, S.; Williams, K. A model for sentiment and emotion analysis of unstructured social media text. Electron. Commer. Res. 2018, 18. [Google Scholar] [CrossRef]
- Aljarah, I.; Habib, M.; Hijazi, N.; Faris, H.; Qaddoura, R.; Hammo, B.; Abushariah, M.; Alfawareh, M. Intelligent detection of hate speech in Arabic social network: A machine learning approach. J. Inf. Sci. 2020. [Google Scholar] [CrossRef]
- Tubishat, M.; Abushariah, M.; Idris, N.; Aljarah, I. Improved whale optimization algorithm for feature selection in Arabic sentiment analysis. Appl. Intell. 2019, 49. [Google Scholar] [CrossRef]
- Boudad, N.; Faizi, R.; Rachid, O.H.T.; Chiheb, R. Sentiment analysis in Arabic: A review of the literature. Ain Shams Eng. J. 2017, 9. [Google Scholar] [CrossRef]
- Ajao, O.; Bhowmik, D.; Zargari, S. Sentiment Aware Fake News Detection on Online Social Networks. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2507–2511. [Google Scholar] [CrossRef] [Green Version]
- Ajao, O.; Bhowmik, D.; Zargari, S. Fake News Identification on Twitter with Hybrid CNN and RNN Models. In Proceedings of the 9th International Conference on Social Media and Society, Copenhagen, Denmark, 18–20 July 2018. [Google Scholar] [CrossRef] [Green Version]
- Gupta, A.; Lamba, H.; Kumaraguru, P.; Joshi, A. Faking Sandy: Characterizing and Identifying Fake Images on Twitter during Hurricane Sandy. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 729–736. [Google Scholar] [CrossRef]
- Castillo, C.; Mendoza, M.; Poblete, B. Information credibility on Twitter. In Proceedings of the 20th International Conference on World Wide Web, Hyderabad, India, 28 March–1 April 2011; pp. 675–684. [Google Scholar] [CrossRef]
- Ferrara, E.; Varol, O.; Davis, C.; Menczer, F.; Flammini, A. The Rise of Social Bots. Commun. ACM 2014, 59. [Google Scholar] [CrossRef] [Green Version]
- Biltawi, M.; Etaiwi, W.; Tedmori, S.; Hudaib, A.; Awajan, A. Sentiment classification techniques for Arabic language: A survey. In Proceedings of the 2016 7th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 5–7 April 2016; pp. 339–346. [Google Scholar] [CrossRef]
- Badaro, G.; Baly, R.; Hajj, H.; El-Hajj, W.; Shaban, K.; Habash, N.; Sallab, A.; Hamdi, A. A Survey of Opinion Mining in Arabic: A Comprehensive System Perspective Covering Challenges and Advances in Tools, Resources, Models, Applications and Visualizations. ACM Trans. Asian Lang. Inf. Process. 2019, 18. [Google Scholar] [CrossRef] [Green Version]
- Chantar, H.; Mafarja, M.; Alsawalqah, H.; Heidari, A.A.; Aljarah, I.; Faris, H. Feature selection using binary grey wolf optimizer with elite-based crossover for Arabic text classification. Neural Comput. Appl. 2020, 32, 12201–12220. [Google Scholar] [CrossRef]
- Chantar, H.K.; Corne, D.W. Feature subset selection for Arabic document categorization using BPSO-KNN. In Proceedings of the 2011 Third World Congress on Nature and Biologically Inspired Computing, Salamanca, Spain, 19–21 October 2011; pp. 546–551. [Google Scholar]
- Liu, H.; Motoda, H. Feature Selection for Knowledge Discovery and Data Mining; Springer Science & Business Media: New York, NY, USA, 2012; Volume 454. [Google Scholar]
- Ahmed, S.; Mafarja, M.; Faris, H.; Aljarah, I. Feature Selection Using Salp Swarm Algorithm with Chaos. In Proceedings of the 2nd International Conference on Intelligent Systems, Metaheuristics & Swarm Intelligence; ACM: New York, NY, USA, 2018; pp. 65–69. [Google Scholar] [CrossRef]
- Zawbaa, H.M.; Emary, E.; Parv, B.; Sharawi, M. Feature selection approach based on moth-flame optimization algorithm. In Proceedings of the 2016 IEEE Congress on Evolutionary Computation (CEC), Vancouver, BC, Canada, 24–29 July 2016; pp. 4612–4617. [Google Scholar]
- Mafarja, M.M.; Eleyan, D.; Jaber, I.; Hammouri, A.; Mirjalili, S. Binary Dragonfly Algorithm for Feature Selection. In Proceedings of the 2017 International Conference on New Trends in Computing Sciences (ICTCS), Amman, Jordan, 11–13 October 2017; pp. 12–17. [Google Scholar]
- Zawbaa, H.M.; Emary, E.; Parv, B. Feature selection based on antlion optimization algorithm. In Proceedings of the 2015 Third World Conference on Complex Systems (WCCS), Marrakech, Morocco, 23–25 November 2015; pp. 1–7. [Google Scholar]
- Mafarja, M.; Heidari, A.A.; Habib, M.; Faris, H.; Thaher, T.; Aljarah, I. Augmented whale feature selection for IoT attacks: Structure, analysis and applications. Future Gener. Comput. Syst. 2020, 112, 18–40. [Google Scholar] [CrossRef]
- Heidari, A.A.; Mirjalili, S.; Faris, H.; Aljarah, I.; Mafarja, M.; Chen, H. Harris hawks optimization: Algorithm and applications. Future Gener. Comput. Syst. 2019, 97, 849–872. [Google Scholar] [CrossRef]
- Al-Betar, M.A.; Awadallah, M.A.; Heidari, A.A.; Chen, H.; Al-khraisat, H.; Li, C. Survival exploration strategies for Harris Hawks Optimizer. Expert Syst. Appl. 2020, 114243. [Google Scholar] [CrossRef]
- Thaher, T.; Arman, N. Efficient Multi-Swarm Binary Harris Hawks Optimization as a Feature Selection Approach for Software Fault Prediction. In Proceedings of the 2020 11th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 7–9 April 2020; pp. 249–254. [Google Scholar] [CrossRef]
- Thaher, T.; Heidari, A.A.; Mafarja, M.; Dong, J.S.; Mirjalili, S.; Hawks, B.H. Optimizer for High-Dimensional, Low Sample Size Feature Selection. In Evolutionary Machine Learning Techniques: Algorithms and Applications; Springer: Singapore, 2020; pp. 251–272. [Google Scholar] [CrossRef]
- Elouardighi, A.; Maghfour, M.; Hammia, H.; Aazi, F.Z. A Machine Learning Approach for Sentiment Analysis in the Standard or Dialectal Arabic Facebook Comments. In Proceedings of the 2017 3rd International Conference of Cloud Computing Technologies and Applications (CloudTech), Rabat, Morocco, 24–26 October 2017. [Google Scholar] [CrossRef]
- Biltawi, M.; Al-Naymat, G.; Tedmori, S. Arabic Sentiment Classification: A Hybrid Approach. In Proceedings of the 2017 International Conference on New Trends in Computing Sciences (ICTCS), Amman, Jordan, 11–13 October 2017; pp. 104–108. [Google Scholar] [CrossRef]
- Daoud, A.S.; Sallam, A.; Wheed, M.E. Improving Arabic document clustering using K-means algorithm and Particle Swarm Optimization. In Proceedings of the 2017 Intelligent Systems Conference (IntelliSys), London, UK, 7–8 September 2017; pp. 879–885. [Google Scholar] [CrossRef]
- Al-Ayyoub, M.; Nuseir, A.; Alsmearat, K.; Jararweh, Y.; Gupta, B. Deep learning for Arabic NLP: A survey. J. Comput. Sci. 2018, 26, 522–531. [Google Scholar] [CrossRef]
- Al-Azani, S.; El-Alfy, E.M. Combining emojis with Arabic textual features for sentiment classification. In Proceedings of the 2018 9th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 3–5 April 2018; pp. 139–144. [Google Scholar] [CrossRef]
- McCabe, T.J. A Complexity Measure. IEEE Trans. Softw. Eng. 1976, SE-2, 308–320. [Google Scholar] [CrossRef]
- Paredes-Valverde, M.; Colomo-Palacios, R.; Salas Zarate, M.; Valencia-García, R. Sentiment Analysis in Spanish for Improvement of Products and Services: A Deep Learning Approach. Sci. Program. 2017, 2017, 1–6. [Google Scholar] [CrossRef] [Green Version]
- Jardaneh, G.; Abdelhaq, H.; Buzz, M.; Johnson, D. Classifying Arabic Tweets Based on Credibility Using Content and User Features. In Proceedings of the 2019 IEEE Jordan International Joint Conference on Electrical Engineering and Information Technology (JEEIT), Amman, Jordan, 9–11 April 2019; pp. 596–601. [Google Scholar] [CrossRef]
- Al-Khalifa, H.; Binsultan, M. An experimental system for measuring the credibility of news content in Twitter. IJWIS 2011, 7, 130–151. [Google Scholar] [CrossRef]
- Sabbeh, S.; Baatwah, S. Arabic news credibility on twitter: An enhanced model using hybrid features. J. Theor. Appl. Inf. Technol. 2018, 96, 2327–2338. [Google Scholar]
- Zubiaga, A.; Liakata, M.; Procter, R. Learning Reporting Dynamics during Breaking News for Rumour Detection in Social Media. arXiv 2016, arXiv:1610.07363. [Google Scholar]
- Ruchansky, N.; Seo, S.; Liu, Y. CSI: A Hybrid Deep Model for Fake News Detection. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 797–806. [Google Scholar] [CrossRef] [Green Version]
- Manning, C.; Raghavan, P.; Schtextbackslashütze, H.; Corporation, E. Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2008; Volume 13. [Google Scholar]
- El-Khair, I.A. Effects of Stop Words Elimination for Arabic Information Retrieval: A Comparative Study. arXiv 2017, arXiv:1702.01925. [Google Scholar]
- Gupta, D.; Saxena, K. Software bug prediction using object-oriented metrics. Sadhana Acad. Proc. Eng. Sci. 2017, 42, 655–669. [Google Scholar] [CrossRef] [Green Version]
- Willett, P. The Porter stemming algorithm: Then, and now. Program Electron. Libr. Inf. Syst. 2006, 40. [Google Scholar] [CrossRef]
- Taghva, K.; Elkhoury, R.; Coombs, J. Arabic stemming without a root dictionary. In Proceedings of the International Conference on Information Technology: Coding and Computing (ITCC’05), Las Vegas, NV, USA, 4–6 April 2005; Volume 1, pp. 152–157. [Google Scholar] [CrossRef]
- Salton, G.; Wong, A.; Yang, C. A Vector Space Model for Automatic Indexing. Commun. ACM 1975, 18, 613. [Google Scholar] [CrossRef] [Green Version]
- Zaatari, A.; El Ballouli, R.; Elbassuoni, S.; El-Hajj, W.; Hajj, H.; Shaban, K.; Habash, N.; Yehya, E. Arabic Corpora for Credibility Analysis. In Proceedings of the 10th International Conference on Language Resources and Evaluation, LREC 2016, Portorož, Slovenia, 23–28 May 2016; pp. 4396–4401. [Google Scholar]
- Loper, E.; Bird, S. NLTK: The Natural Language Toolkit. CoRR 2002. [Google Scholar] [CrossRef]
- Faris, H.; Aljarah, I.; Habib, M.; Castillo, P.A. Hate Speech Detection using Word Embedding and Deep Learning in the Arabic Language Context. In Proceedings of the 9th International Conference on Pattern Recognition Applications and Methods, Valletta, Malta, 22–24 February 2020; pp. 453–460. [Google Scholar] [CrossRef]
- Abuelenin, S.; Elmougy, S.; Naguib, E. Twitter Sentiment Analysis for Arabic Tweets. In Proceedings of the International Conference on Advanced Intelligent Systems and Informatics 2017; Springer International Publishing: Cham, Switzerland, 2018; pp. 467–476. [Google Scholar]
- Wolpert, D.H.; Macready, W.G. No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef] [Green Version]
- Larranaga, P.; Calvo, B.; Santana, R.; Bielza, C.; Galdiano, J.; Inza, I.; Lozano, J.; Armañanzas, R.; Santafé, G.; Pérez, A.; et al. Machine learning in bioinformatics. Briefings Bioinform. 2006, 7, 86–112. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Mirjalili, S.; Lewis, A. S-shaped versus V-shaped transfer functions for binary particle swarm optimization. Swarm Evol. Comput. 2013, 9, 1–14. [Google Scholar] [CrossRef]
- Rashedi, E.; Nezamabadi-Pour, H.; Saryazdi, S. BGSA: Binary gravitational search algorithm. Nat. Comput. 2010, 9, 727–745. [Google Scholar] [CrossRef]
- Mafarja, M.; Eleyan, D.; Abdullah, S.; Mirjalili, S. S-shaped vs. V-shaped transfer functions for ant lion optimization algorithm in feature selection problem. In Proceedings of the International Conference on Future Networks and Distributed Systems, Cambridge, UK, 19–20 July 2017; pp. 1–7. [Google Scholar]
- Kennedy, J.; Eberhart, R.C. A discrete binary version of the particle swarm algorithm. In Proceedings of the 1997 IEEE International Conference on Systems, Man, and Cybernetics, Computational Cybernetics and Simulation, Orlando, FL, USA, 12–15 October 1997; Volume 5, pp. 4104–4108. [Google Scholar]
- Tumar, I.; Hassouneh, Y.; Turabieh, H.; Thaher, T. Enhanced Binary Moth Flame Optimization as a Feature Selection Algorithm to Predict Software Fault Prediction. IEEE Access 2020, 8, 8041–8055. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer Series in Statistics; Springer: New York, NY, USA, 2009. [Google Scholar]
- Thaher, T.; Mafarja, M.; Abdalhaq, B.; Chantar, H. Wrapper-based Feature Selection for Imbalanced Data using Binary Queuing Search Algorithm. In Proceedings of the 2019 2nd International Conference on new Trends in Computing Sciences (ICTCS), Amman, Jordan, 9–11 October 2019; pp. 1–6. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description |
|---|---|
| X | Position vector of hawks (search agents) |
| Position of randomly selected agent | |
| Position vector of best agent so far (rabbit) | |
| Average position of all agents | |
| , , , , , q | uniformly random numbers within [0,1] |
| t, T, N | current iteration, number of iterations, number of search agents |
| , | Lower and upper bounds of decision variables |
| D | dimension |
| J | Random jump strength of the prey during the fleeing procedure |
| S | Random vector by size 1 × D |
| , E | Initial value of escaping energy, escaping energy |
| Query Topic | No. of Tweets | Credible (%) | Non-Credible (%) | Undecidable (%) |
|---|---|---|---|---|
| The forces of the Syrian government | 1791 | 63.1% | 28.5% | 8.4% |
| Syrian revolution | 1232 | 35.6% | 51.0% | 13.4% |
| User-Profile Features | Content-Based Features | |||
|---|---|---|---|---|
| avg_hashtags | avg_URLs | has_mention | mentions_count | URL_shortner |
| followers_to_friends | avg_retweet | retweets_num | is_retweet | is_reply |
| followers_count | tweet_time_spacing | retweeted | day_of_week | #_words |
| focused_topic | default_image | length_chars | has_URL | URLs_count |
| has_desc | desc_len | has_hashtag | hashtags_count | #_unique_words |
| username_len | avg_tweet_len | # unique chars | has_? | #_? |
| listed_count | status_count | has_! | #_! | #_ellipses |
| retweet_fraction | friends_to_follower | #_symbols | has_pos_sent | has_neg_sent |
| is_verified | registration_diff | pos_score | neg_score | |
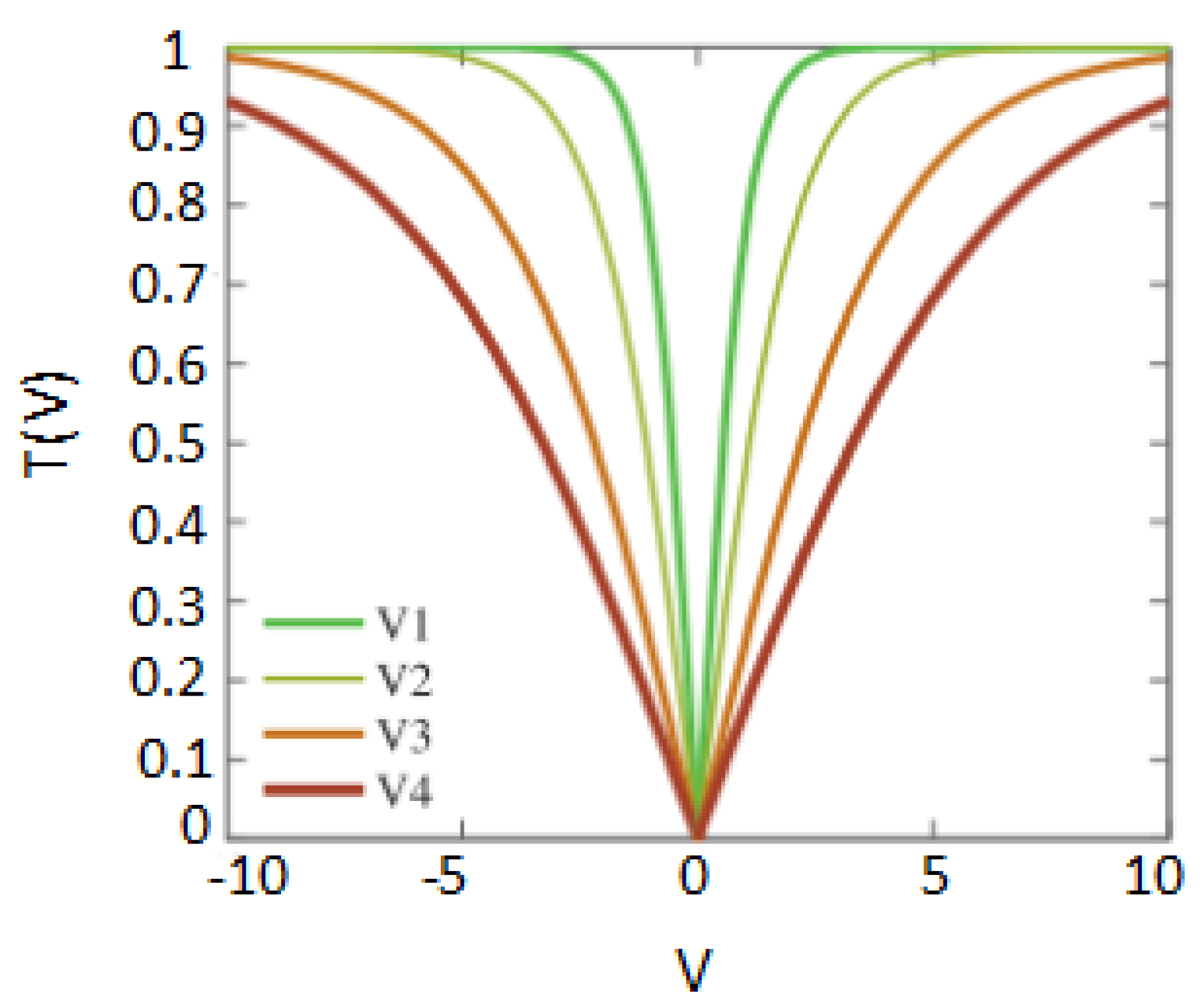
| Name | Transfer Function Formula Function |
|---|---|
| V1 | |
| V2 | |
| V3 | |
| V4 |
| Predicted Class | |||
|---|---|---|---|
| positive | negative | ||
| Actual class | positive | TP | FN |
| negative | FP | TN | |
| Common Parameters | ||
|---|---|---|
| population size | 20 | |
| Number of iterations | 100 | |
| Number of runs | 10 | |
| Dimension | #features | |
| K for cross validation | 5 | |
| Fitness function | alpha = 0.99, Beta = 0.01 | |
| Internal Parameters | ||
| Algorithm | parameter | value |
| BHHO | Convergence constant E | [2 0] |
| BWOA | convergence constant a | [2 0] |
| Spiral factor b | 1 | |
| BBA | , | 0, 2 |
| loudness A | 0.5 | |
| Pulse rate r | 0.5 | |
| BGWO | convergence constant a | [2 0] |
| BFFA | 0.5 | |
| 0.2 | ||
| 1 | ||
| BMFO | Convergence constant a | [−1 −2] |
| Spiral factor b | 1 | |
| GA | crossover probability | 0.9 |
| mutation probability | 0.01 | |
| crossover type | single point | |
| selection strategy | roulette wheel | |
| elite | 2 | |
| BCS | Discovery rate of alien solutions | 0.25 |
| Classifier | Vectorizer | Accuracy | Recall | Precision | F1_Score | Rank |
|---|---|---|---|---|---|---|
| RF | TF | 0.7539 | 0.8240 | 0.7603 | 0.7909 | 8.63 |
| TF-IDF | 0.7598 | 0.8059 | 0.7771 | 0.7912 | 10.25 | |
| BTF | 0.7480 | 0.8211 | 0.7544 | 0.7863 | 10.50 | |
| SVM | TF | 0.7297 | 0.8202 | 0.7330 | 0.7741 | 14.75 |
| TF-IDF | 0.7539 | 0.8497 | 0.7485 | 0.7959 | 8.13 | |
| BTF | 0.7652 | 0.8145 | 0.7796 | 0.7966 | 8.50 | |
| LR | TF | 0.7695 | 0.8192 | 0.7827 | 0.8006 | 7.00 |
| TF-IDF | 0.7802 | 0.8392 | 0.7861 | 0.8118 | 2.63 | |
| BTF | 0.7802 | 0.8173 | 0.7983 | 0.8077 | 4.63 | |
| DT | TF | 0.7152 | 0.7507 | 0.7465 | 0.7486 | 17.75 |
| TF-IDF | 0.7163 | 0.7364 | 0.7551 | 0.7457 | 16.75 | |
| BTF | 0.6980 | 0.7279 | 0.7349 | 0.7314 | 19.75 | |
| KNN | TF | 0.6964 | 0.8221 | 0.6957 | 0.7536 | 16.25 |
| TF-IDF | 0.7055 | 0.8382 | 0.6998 | 0.7628 | 14.75 | |
| BTF | 0.7077 | 0.9001 | 0.6830 | 0.7767 | 13.75 | |
| LDA | TF | 0.6319 | 0.6584 | 0.6798 | 0.6689 | 23.00 |
| TF-IDF | 0.6400 | 0.6803 | 0.6816 | 0.6810 | 22.00 | |
| BTF | 0.6169 | 0.6489 | 0.6647 | 0.6567 | 24.00 | |
| NB | TF | 0.7415 | 0.8211 | 0.7465 | 0.7821 | 12.38 |
| TF-IDF | 0.7474 | 0.8049 | 0.7615 | 0.7826 | 12.50 | |
| BTF | 0.7415 | 0.8211 | 0.7465 | 0.7821 | 12.38 | |
| XGboost | TF | 0.7781 | 0.8069 | 0.8015 | 0.8042 | 5.50 |
| TF-IDF | 0.7727 | 0.7992 | 0.7985 | 0.7989 | 7.75 | |
| BTF | 0.7770 | 0.8097 | 0.7983 | 0.8040 | 6.50 |
| Word Features | User-Related | Content-Related | Classifier | Accuracy | Recall | Precision | F1_Score |
|---|---|---|---|---|---|---|---|
| √ | √ | √ | RF | 0.7598 | 0.8059 | 0.7771 | 0.7912 |
| SVM | 0.7539 | 0.8497 | 0.7485 | 0.7959 | |||
| LR | 0.7802 | 0.8392 | 0.7861 | 0.8118 | |||
| DT | 0.7163 | 0.7364 | 0.7551 | 0.7457 | |||
| KNN | 0.7055 | 0.8382 | 0.6998 | 0.7628 | |||
| LDA | 0.6400 | 0.6803 | 0.6816 | 0.6810 | |||
| NB | 0.7474 | 0.8049 | 0.7615 | 0.7826 | |||
| XGboost | 0.7727 | 0.7992 | 0.7985 | 0.7989 | |||
| ╳ | √ | √ | RF | 0.7238 | 0.7545 | 0.7560 | 0.7552 |
| SVM | 0.7093 | 0.8639 | 0.6953 | 0.7705 | |||
| LR | 0.7082 | 0.8192 | 0.7092 | 0.7603 | |||
| DT | 0.6711 | 0.7012 | 0.7121 | 0.7066 | |||
| KNN | 0.6722 | 0.7688 | 0.6877 | 0.7260 | |||
| LDA | 0.7131 | 0.8145 | 0.7163 | 0.7622 | |||
| NB | 0.5287 | 0.2969 | 0.6933 | 0.4157 | |||
| XGboost | 0.7303 | 0.7764 | 0.7535 | 0.7648 | |||
| √ | ╳ | ╳ | RF | 0.7534 | 0.7774 | 0.7841 | 0.7807 |
| SVM | 0.7636 | 0.7840 | 0.7946 | 0.7893 | |||
| LR | 0.7571 | 0.7926 | 0.7807 | 0.7866 | |||
| DT | 0.7045 | 0.7412 | 0.7370 | 0.7391 | |||
| KNN | 0.7179 | 0.8934 | 0.6945 | 0.7815 | |||
| LDA | 0.6239 | 0.6708 | 0.6657 | 0.6682 | |||
| NB | 0.7474 | 0.8049 | 0.7615 | 0.7826 | |||
| XGboost | 0.7480 | 0.7631 | 0.7847 | 0.7738 | |||
| ╳ | √ | ╳ | RF | 0.6889 | 0.7022 | 0.7351 | 0.7182 |
| SVM | 0.6577 | 0.8107 | 0.6605 | 0.7279 | |||
| LR | 0.6432 | 0.7650 | 0.6585 | 0.7077 | |||
| DT | 0.6486 | 0.6832 | 0.6910 | 0.6871 | |||
| KNN | 0.6373 | 0.6993 | 0.6718 | 0.6853 | |||
| LDA | 0.6464 | 0.7507 | 0.6658 | 0.7057 | |||
| NB | 0.5787 | 0.3958 | 0.7363 | 0.5149 | |||
| XGboost | 0.6711 | 0.6993 | 0.7129 | 0.7061 | |||
| ╳ | ╳ | √ | RF | 0.6932 | 0.7878 | 0.7041 | 0.7436 |
| SVM | 0.6975 | 0.8839 | 0.6781 | 0.7675 | |||
| LR | 0.7012 | 0.8259 | 0.6994 | 0.7574 | |||
| DT | 0.6244 | 0.6594 | 0.6702 | 0.6647 | |||
| KNN | 0.6760 | 0.7764 | 0.6892 | 0.7302 | |||
| LDA | 0.7012 | 0.8316 | 0.6975 | 0.7587 | |||
| NB | 0.4718 | 0.1979 | 0.5977 | 0.2974 | |||
| XGboost | 0.6814 | 0.7517 | 0.7041 | 0.7271 | |||
| √ | √ | ╳ | RF | 0.7614 | 0.7954 | 0.7850 | 0.7902 |
| SVM | 0.7603 | 0.7935 | 0.7846 | 0.7890 | |||
| LR | 0.7577 | 0.7973 | 0.7788 | 0.7880 | |||
| DT | 0.6862 | 0.6927 | 0.7361 | 0.7137 | |||
| KNN | 0.7200 | 0.8773 | 0.7017 | 0.7797 | |||
| LDA | 0.6271 | 0.6784 | 0.6670 | 0.6726 | |||
| NB | 0.7474 | 0.8049 | 0.7615 | 0.7826 | |||
| XGboost | 0.7517 | 0.7688 | 0.7868 | 0.7777 | |||
| √ | ╳ | √ | RF | 0.7555 | 0.7992 | 0.7749 | 0.7869 |
| SVM | 0.7517 | 0.8411 | 0.7498 | 0.7928 | |||
| LR | 0.7711 | 0.8344 | 0.7768 | 0.8046 | |||
| DT | 0.7109 | 0.7479 | 0.7422 | 0.7450 | |||
| KNN | 0.7157 | 0.8649 | 0.7014 | 0.7746 | |||
| LDA | 0.6421 | 0.6813 | 0.6839 | 0.6826 | |||
| NB | 0.7474 | 0.8049 | 0.7615 | 0.7826 | |||
| XGboost | 0.7577 | 0.7812 | 0.7879 | 0.7845 |
| Classifier | n-Grams | Accuracy | Recall | Precision | F1_Score | Rank |
|---|---|---|---|---|---|---|
| LR | 1-gram | 0.7802 | 0.8392 | 0.7861 | 0.8118 | 2.00 |
| 2-grams | 0.7609 | 0.8335 | 0.7644 | 0.7975 | 5.00 | |
| 3-grams | 0.7437 | 0.8325 | 0.7440 | 0.7858 | 6.75 | |
| 1-gram and 2-grams | 0.7749 | 0.8402 | 0.7787 | 0.8082 | 2.50 | |
| XGboost | 1-gram | 0.7727 | 0.7992 | 0.7985 | 0.7989 | 3.50 |
| 2-grams | 0.7689 | 0.7878 | 0.8000 | 0.7939 | 4.75 | |
| 3-grams | 0.7458 | 0.7697 | 0.7779 | 0.7738 | 7.25 | |
| 1-gram and 2-grams | 0.7700 | 0.7916 | 0.7992 | 0.7954 | 4.25 |
| Method | Measure | Accuracy | Recall | Precision | F1_Score | Rank |
|---|---|---|---|---|---|---|
| VBHHO1 | Mean | 0.8150 | 0.8552 | 0.8235 | 0.8390 | 1.00 |
| Std | 0.0060 | 0.0058 | 0.0098 | 0.0044 | ||
| VBHHO2 | Mean | 0.8102 | 0.8540 | 0.8175 | 0.8352 | 2.25 |
| Std | 0.0049 | 0.0151 | 0.0065 | 0.0056 | ||
| VBHHO3 | Mean | 0.8084 | 0.8441 | 0.8210 | 0.8323 | 2.75 |
| Std | 0.0061 | 0.0127 | 0.0079 | 0.0059 | ||
| VBHHO4 | Mean | 0.8052 | 0.8432 | 0.8170 | 0.8299 | 4.00 |
| Std | 0.0052 | 0.0070 | 0.0061 | 0.0045 |
| Algorithm | Metric | Accuracy | Recall | Precision | F1_Score | Rank |
|---|---|---|---|---|---|---|
| VBHHO1 | Mean | 0.8150 | 0.8552 | 0.8235 | 0.8390 | 1.00 |
| Std | 0.0060 | 0.0058 | 0.0098 | 0.0044 | ||
| BWOA | Mean | 0.8045 | 0.8413 | 0.8174 | 0.8290 | 5.75 |
| Std | 0.0038 | 0.0163 | 0.0093 | 0.0045 | ||
| BMFO | Mean | 0.8052 | 0.8432 | 0.8171 | 0.8298 | 5.13 |
| Std | 0.0027 | 0.0157 | 0.0067 | 0.0044 | ||
| BGWO | Mean | 0.8073 | 0.8463 | 0.8182 | 0.8319 | 3.50 |
| Std | 0.0025 | 0.0118 | 0.0085 | 0.0025 | ||
| BGA | Mean | 0.8093 | 0.8457 | 0.8213 | 0.8333 | 2.50 |
| Std | 0.0052 | 0.0096 | 0.0080 | 0.0045 | ||
| BFFA | Mean | 0.8086 | 0.8432 | 0.8219 | 0.8323 | 3.13 |
| Std | 0.0025 | 0.0132 | 0.0059 | 0.0038 | ||
| BCS | Mean | 0.7936 | 0.8295 | 0.8091 | 0.8191 | 7.00 |
| Std | 0.0056 | 0.0105 | 0.0079 | 0.0050 | ||
| BBA | Mean | 0.7902 | 0.8292 | 0.8045 | 0.8166 | 8.00 |
| Std | 0.0057 | 0.0094 | 0.0083 | 0.0049 |
| Method | No. Features | Accuracy | Recall | Precision | F1_Score |
|---|---|---|---|---|---|
| LR | 3054 | 78% | 84% | 79% | 81% |
| VBHHO1-LR | 984.2 | 82% | 86% | 82% | 84% |
| Algorithm | Accuracy | Recall | Precision | F1_Score | |
|---|---|---|---|---|---|
| proposed approach | LR | 78% | 84% | 79% | 81% |
| VBHHO1-LR | 82% | 86% | 82% | 84% | |
| Jardaneh et al. [31] | RF | 76% | 82% | 79% | 80% |
| DT | 70% | 74% | 75% | 74% | |
| LR | 76% | 83% | 79% | 81% | |
| Ada Boost | 77% | 82% | 80% | 81% | |
| Zaatari et al. [42] | CAT | - | 0.791 | 0.79 | 0.788 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Thaher, T.; Saheb, M.; Turabieh, H.; Chantar, H. Intelligent Detection of False Information in Arabic Tweets Utilizing Hybrid Harris Hawks Based Feature Selection and Machine Learning Models. Symmetry 2021, 13, 556. https://doi.org/10.3390/sym13040556
Thaher T, Saheb M, Turabieh H, Chantar H. Intelligent Detection of False Information in Arabic Tweets Utilizing Hybrid Harris Hawks Based Feature Selection and Machine Learning Models. Symmetry. 2021; 13(4):556. https://doi.org/10.3390/sym13040556
Chicago/Turabian StyleThaher, Thaer, Mahmoud Saheb, Hamza Turabieh, and Hamouda Chantar. 2021. "Intelligent Detection of False Information in Arabic Tweets Utilizing Hybrid Harris Hawks Based Feature Selection and Machine Learning Models" Symmetry 13, no. 4: 556. https://doi.org/10.3390/sym13040556
APA StyleThaher, T., Saheb, M., Turabieh, H., & Chantar, H. (2021). Intelligent Detection of False Information in Arabic Tweets Utilizing Hybrid Harris Hawks Based Feature Selection and Machine Learning Models. Symmetry, 13(4), 556. https://doi.org/10.3390/sym13040556