
Building a Fuzzy Classifier Based on Whale Optimization Algorithm to Detect Network Intrusions



Abstract
:1. Introduction
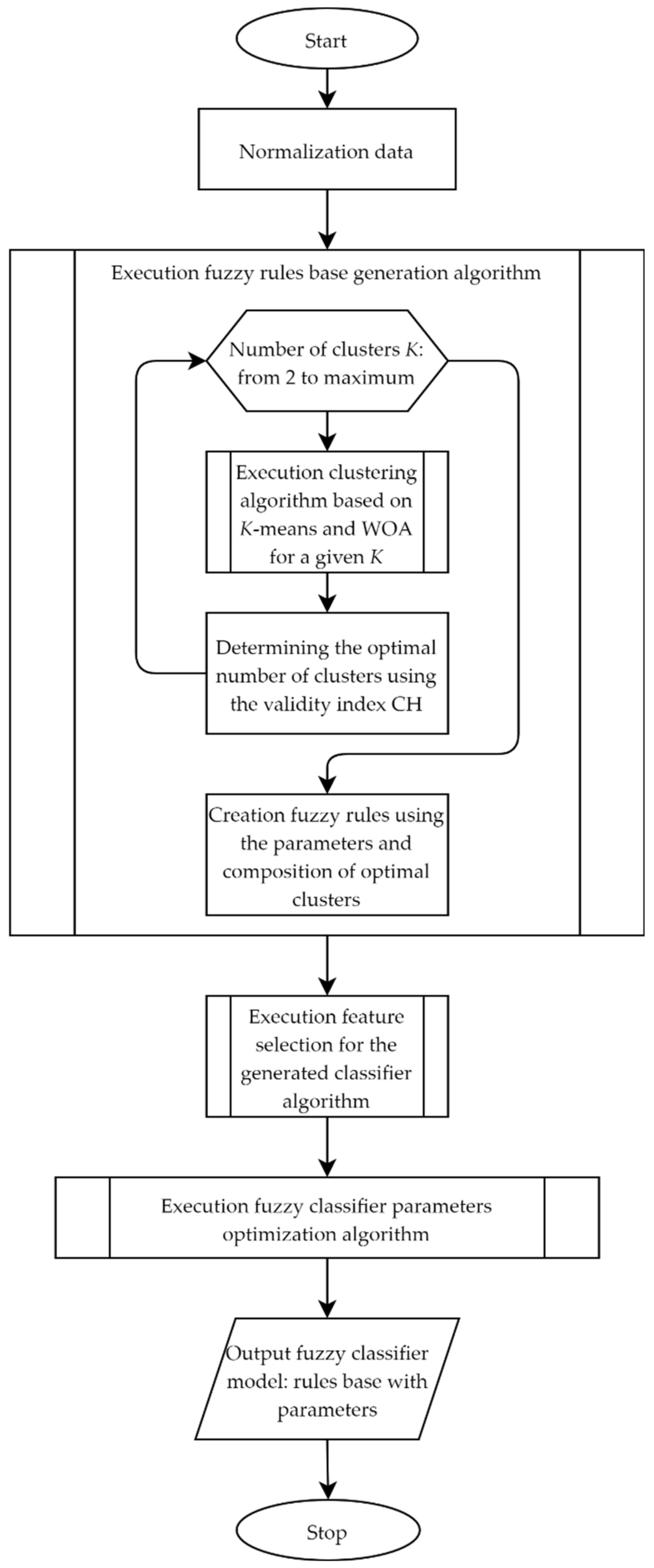
- Algorithms for performing the stages of constructing a fuzzy classifier based on WOA are presented:
- An algorithm for generating fuzzy rules of classifier using the K-means algorithm, WOA, cluster validity index, and symmetric Gaussian membership function;
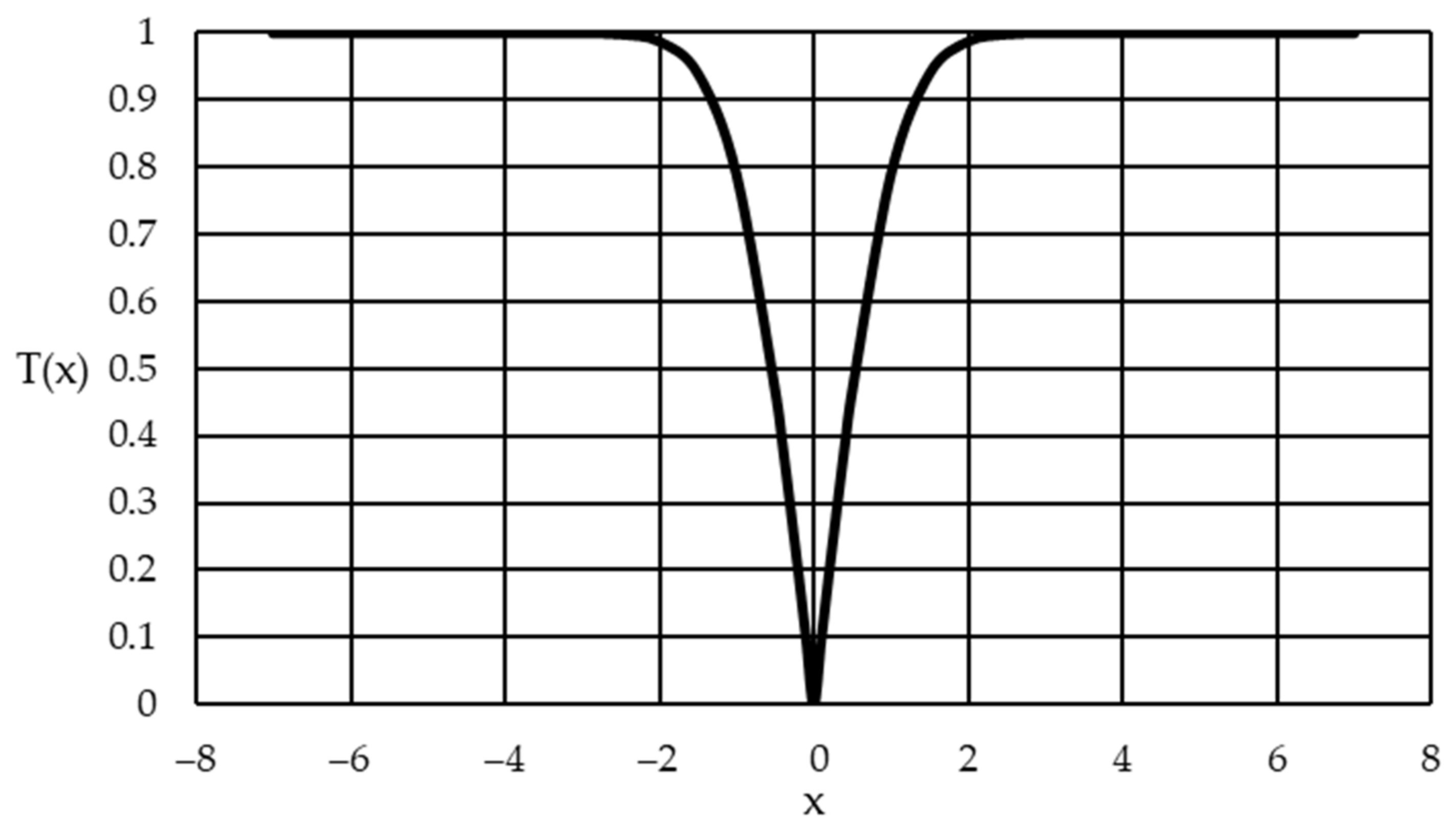
- An algorithm for selecting informative features for a fuzzy classifier using WOA and a symmetric transformation function;
- An algorithm for tuning the parameters of a fuzzy classifier using a WOA algorithm.
- The results of testing the performance of algorithms for constructing a fuzzy classifier on the KDD Cup 1999 dataset are presented. This dataset contains information about normal network connections and network attacks.
2. Related Works
2.1. Fuzzy Classifier
2.2. Clustering
2.3. Feature Selection
3. Materials and Methods
3.1. Description of Fuzzy Classifier
3.2. Description of WOA
3.3. Algorithms for Constructing a Fuzzy Classifier Based on WOA
3.3.1. Fuzzy Rules Generation Algorithm
| Algorithm 1 The clustering algorithm based on K-means and WOA |
| Input: X (the set of objects); K; J; MaxIter (maximum number of iterations) Output begin as the vector (4) begin K-means iteration for1 to J do for1 to N do for1 to K do end for end for for1 to K do if ( is not empty) according to the Equation (3) else from X end if end for using Equation (2) end for end K-means iteration while (t < MaxIter) Execute one iteration of the WOA over the entire population P Execute K-means iteration (given above) if there is a better solution t= t + 1 end while end |
| Algorithm 2 The fuzzy rules generation algorithm |
| Input: X; Y (set of labels); MaxClass (maximum number of classes) Output: base, which are consisting of K fuzzy rules begin Normalize the features values of the data instances from X for2 to MaxClass do Perform the clustering algorithm based on the K-means and WOA: Algorithm 1 Define the value of the validity index CH(K) using the equation (5) Memorize the received index value CH(K) and the found centroids end for Determine the best found value of the quality index CH(K) (the maximum value of CH) Define the optimal number of clusters K that is corresponding to the best CH(K) value for1 to K do Define the mathematical expectation and stand. dev. of the k-th optimal cluster Determine class label from Y set for the k-th optimal cluster by the majority principle Generate the k-th fuzzy “IF-THEN” type rule using the found antecedents and consequent end for end |
3.3.2. Feature Selection Algorithm
| Algorithm 3 The feature selection algorithm based on WOA |
| Input: train data; J; MaxIter (maximum number of iterations) Output that indicates the subset of informative features begin randomly while (t < MaxIter) to by executing one iteration of the continuous WOA goes beyond the search space and amend it if necessary elements using the Equations (7) and (6) Update S if there is a better solution t = t + 1 end while end |
3.3.3. Algorithm for Optimizing Parameters of Fuzzy Classifier
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cavusoglu, U. A new hybrid approach for intrusion detection using machine learning methods. Appl. Intell. 2019, 49, 2735–2761. [Google Scholar] [CrossRef]
- Zamani, M.; Movahedi, M. Machine Learning Techniques for Intrusion Detection. arXiv, 2013; arXiv:1312.2177. [Google Scholar]
- Elhag, S.; Fernandez, A.; Bawakid, A.; Alshomrani, S.; Herrera, F. On the combination of genetic fuzzy systems and pairwise learning for improving detection rates on intrusion detection systems. Expert Syst. Appl. 2015, 42, 193–202. [Google Scholar] [CrossRef]
- Azad, C.; Jha, V.K. Fuzzy min–max neural network and particle swarm optimization based intrusion detection system. Microsyst. Technol. 2017, 23, 907–918. [Google Scholar] [CrossRef]
- Bardamova, M.; Konev, A.; Hodashinsky, I.; Shelupanov, A. Application of the Gravitational Search Algorithm for Constructing Fuzzy Classifiers of Imbalanced Data. Symmetry 2019, 11, 1458. [Google Scholar] [CrossRef] [Green Version]
- Al-Akhras, M.; Alawairdhi, M.; Alkoudari, A.; Atawneh, S. Using machine learning to build a classification model for iot networks to detect attack signatures. Int. J. Comput. Netw. Commun. (IJCNC) 2020, 12, 99–116. [Google Scholar] [CrossRef]
- Kuang, F.; Xu, W.; Zhang, S. A novel hybrid KPCA and SVM with GA model for intrusion detection. Appl. Soft Comput. 2014, 18, 178–184. [Google Scholar] [CrossRef]
- Osareh, A.; Shadgar, B. Intrusion Detection in Computer Networks based on Machine Learning Algorithms. Int. J. Comput. Sci. Netw. Secur. (IJCSNS) 2008, 8, 15–23. [Google Scholar]
- Kaja, N.; Shaout, A.; Ma, D. An intelligent intrusion detection system. Appl. Intell. 2019, 49, 3235–3247. [Google Scholar] [CrossRef]
- Haghnegahdar, L.; Wang, Y. A whale optimization algorithm-trained artificial neural network for smart grid cyber intrusion detection. Neural Comput. Appl. 2020, 32, 9427–9441. [Google Scholar] [CrossRef]
- Mekh, M.A.; Hodashinsky, I.A. Comparative analysis of differential evolution methods to optimize parameters of fuzzy classifiers. J. Comput. Syst. Sci. Int. 2017, 56, 616–626. [Google Scholar] [CrossRef]
- Alcala-Fdez, J.; Alcala, R.; Herrera, F. A fuzzy association rule-based classification model for high-dimensional problems with genetic rule selection and lateral tuning. IEEE Trans. Fuzzy Syst. 2011, 19, 857–872. [Google Scholar] [CrossRef] [Green Version]
- Fazzolari, M.; Alcala, R.; Herrera, F. A multi-objective evolutionary method for learning granularities based on fuzzy discretization to improve the accuracy-complexity trade-off of fuzzy rule-based classification systems: D-MOFARC algorithm. Appl. Soft Comput. 2014, 24, 470–481. [Google Scholar] [CrossRef]
- Elhag, S.; Fernandez, A.; Altalhi, A.; Alshomrani, S.; Herrera, F. A multi-objective evolutionary fuzzy system to obtain a broad and accurate set of solutions in intrusion detection systems. Soft Comput. 2019, 23, 1321–1336. [Google Scholar] [CrossRef]
- Bardamova, M.; Konev, A.; Hodashinsky, I.; Shelupanov, A. A Fuzzy Classifier with Feature Selection Based on the Gravitational Search Algorithm. Symmetry 2018, 10, 609. [Google Scholar] [CrossRef] [Green Version]
- Bardamova, M.; Konev, A.; Hodashinsky, I.; Shelupanov, A. Gravitational search for designing a fuzzy rule-based classifiers for handwritten signature verification. J. Commun. Softw. Syst. 2019, 15, 254–261. [Google Scholar] [CrossRef]
- Hodashinsky, I.A.; Mech, M.A. Constructing a fuzzy network intrusion classifier based on differential evolution and harmonic search. Int. J. Comput. Netw. Commun. (IJCNC) 2018, 10, 85–91. [Google Scholar]
- Abraham, A.; Das, S.; Roy, S. Swarm intelligence algorithms for data clustering. In Soft Computing for Knowledge Discovery and Data Mining, 1st ed.; Maimon, O., Rokach, L., Eds.; Springer: Boston, MA, USA, 2008; pp. 279–313. [Google Scholar]
- Li, Y.; Shang, Y.; Yang, Y. Clustering coefficients of large networks. Inf. Sci. 2017, 350–358, 382–383. [Google Scholar] [CrossRef]
- Shang, Y. Resilient group consensus in heterogeneously robust networks with hybrid dynamics. Math. Methods Appl. Sci. 2021, 44, 1456–1469. [Google Scholar] [CrossRef]
- Shafiq, A.; Gillian, D.; Saeed, U.R. Analysis of particle swarm optimization based hierarchical data clustering approaches. Swarm Evol. Comput. 2015, 25, 36–51. [Google Scholar]
- Xu, R.; Wunsch, D.C., II. Clustering, 1st ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2009; p. 357. [Google Scholar]
- Gupta, R.; Muttoo, S.K.; Pal, S.K. Fuzzy C-Means Clustering and Particle Swarm Optimization based scheme for Common Service Center location allocation. Appl. Intell. 2017, 47, 624–643. [Google Scholar] [CrossRef]
- Jagannath, N.S.; Ganapati, P. A survey on nature inspired metaheuristic algorithms for partitional clustering. Swarm Evol. Comput. 2014, 16, 1–18. [Google Scholar]
- Wang, W.; Guyet, A.T.; Quiniou, R.; Cordier, M.O.; Masseglia, F.; Zhang, X. Autonomic intrusion detection: Adaptively detecting anomalies over unlabeled audit data streams in computer networks. Knowl. Based Syst. 2014, 70, 103–117. [Google Scholar] [CrossRef] [Green Version]
- Porto-Dıaz, L.; Martınez-Rego, D.; Alonso-Betanzos, A.; Fontenla-Romero, O. Combining Feature Selection and Local Modelling in the KDD Cup 99 Dataset. In Artificial Neural Networks—ICANN 2009; Lecture Notes in Computer Science; Alippi, C., Polycarpou, M., Panayiotou, C., Ellinas, G., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; Volume 5768, pp. 824–833. [Google Scholar]
- Liu, H.; Yu, L. Toward Integrating Feature Selection Algorithms for Classification and Clustering. IEEE Trans. Knowl. Data Eng. 2005, 17, 491–502. [Google Scholar]
- Kohavi, R.; John, G.H. Wrappers for feature subset selection. Artif. Intell. 1997, 97, 273–324. [Google Scholar] [CrossRef] [Green Version]
- Vijayanand, R.; Devaraj, D. A Novel Feature Selection Method Using Whale Optimization Algorithm and Genetic Operators for Intrusion Detection System in Wireless Mesh Network. IEEE Access 2020, 8, 56847–56854. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. The Whale Optimization Algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Deb, S.; Tian, Z.; Fong, S.; Wong, R.; Millham, R.; Wong, K.K.L. Elephant search algorithm applied to data clustering. Soft Comput. 2018, 22, 6035–6046. [Google Scholar] [CrossRef]
- Lloyd, S.P. Least Squares Quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Davis, CA, USA, 21 June–18 July 1965; Le Cam, L.M., Neyman, J., Eds.; University of California Press: Berkeley, CA, USA, 1967; Volume 1, pp. 281–296. [Google Scholar]
- Niu, B.; Duan, Q.; Liu, J.; Tan, L.; Liu, Y. A population-based clustering technique using particle swarm optimization and k-means. Nat. Comput. 2017, 16, 45–59. [Google Scholar] [CrossRef]
- Das, S.; Abraham, A.; Konar, A. Automatic clustering using an improved differential evolution algorithm. IEEE Trans. Syst. Man Cybern. 2008, 38, 218–237. [Google Scholar] [CrossRef]
- Chen, C.Y.; Fun, Y. Particle swarm optimization algorithm and its application to clustering analysis. In Proceedings of the 2004 IEEE International Conference on Networking, Sensing & Control, Taipei, Taiwan, 21–23 March 2004; pp. 789–794. [Google Scholar]
- Merwe, D.W.; Engelbrecht, A.P. Data clustering using particle swarm optimization. In Proceedings of the 2003 Congress on Evolutionary Computation, 2003. CEC’03, Canberra, ACT, Australia, 8–12 December 2003; Volume 1, pp. 215–220. [Google Scholar]
- Alok, A.K.; Saha, S.; Ekbal, A. Development of An External Cluster Validity Index using Probabilistic Approach and Min-max Distance. Int. J. Comput. Inf. Syst. Ind. Manag. Appl. 2014, 6, 494–504. [Google Scholar]
- Charrad, M.; Ghazzali, N.; Boiteau, V.; Niknafs, A. NbClust: An R Package for Determining the Relevant Number of Clusters in a Data Set. J. Stat. Softw. 2014, 61, 1–36. [Google Scholar] [CrossRef] [Green Version]
- Arbelaitz, O.; Gurrutxaga, I.; Muguerza, J.; Perez, J.M.; Perona, I. An extensive comparative study of cluster validity indices. Pattern Recognit. 2013, 46, 243–256. [Google Scholar] [CrossRef]
- Yaru, W.; Shihong, Y.; Zhenhua, H.; Mingliang, D.; Jia, L. An unsupervised and robust validity index for clustering analysis. Soft Comput. 2019, 23, 10303–10319. [Google Scholar]
- Mafarja, M.; Mirjalili, S. Whale optimization approaches for wrapper feature selection. Appl. Soft Comput. 2018, 62, 441–453. [Google Scholar] [CrossRef]
- Hussien, A.G.; Hassanien, A.E.; Houssein, E.H.; Bhattacharyya, S.; Amin, M. S-shaped Binary Whale Optimization Algorithm for Feature Selection. Adv. Intell. Syst. Comput. 2019, 727, 79–87. [Google Scholar]
- Hussien, A.G.; Houssein, E.H.; Hassanien, A.E. A binary whale optimization algorithm with hyperbolic tangent fitness function for feature selection. In Proceedings of the 2017 Eighth International Conference on Intelligent Computing and Information Systems (ICICIS), Cairo, Egypt, 5–7 December 2017; pp. 166–172. [Google Scholar]
- Mirjalili, S.; Lewis, A. S-shaped versus V-shaped transfer functions for binary particle swarm optimization. Swarm Evol. Comput. 2013, 9, 1–14. [Google Scholar] [CrossRef]
- Saremi, S.; Mirjalili, S.; Lewis, A. How important is a transfer function in discrete heuristic algorithms. Neural Comput. Appl. 2014, 26, 625–640. [Google Scholar] [CrossRef] [Green Version]
- Faraoun, K.M.; Boukelif, A. Genetic Programming Approach for Multi-category Pattern Classification Applied to Network Intrusions Detection. Int. J. Comput. Electr. Autom. Control. Inf. Eng. 2007, 1, 3098–3109. [Google Scholar] [CrossRef] [Green Version]
- Sheikhan, M.; Jadidi, Z. Misuse Detection Using Hybrid of Association Rule Mining and Connectionist Modeling. World Appl. Sci. J. 2009, 7, 31–37. [Google Scholar]
- UNSW Sydney. Available online: https://research.unsw.edu.au/projects/unsw-nb15-dataset (accessed on 3 June 2021).
- University of New Brunswick. Canadian Institute for Cybersecurity. Available online: https://www.unb.ca/cic/datasets/ids.html (accessed on 3 June 2021).
- GitHub. Available online: https://github.com/verazuo/a-labelled-version-of-the-ADFA-LD-dataset (accessed on 3 June 2021).



{kind=link}
{kind=link}
| Feature Group | Feature Names and Numbers (the Number Is Shown in Round Brackets) |
|---|---|
| TCP features | duration (1), protocol_type (2), service (3), flag (4), src_bytes (5), dst_bytes (6), land (7), wrong_fragment (8), urgent (9) |
| Features of connecting to a domain | hot (10), num _failed_logins (11), logged_in (12), num_compromised (13), root_shell (14), su_attempted (15), num_root (16), num_file_creations (17), num_shells (18), num_access_files (19), num_outbound_cmds (20), is_hot_login (21), is_guest_login (22) |
| Features received in the two-second interval | count(23), srv_count (24), serror_rate (25), srv_serror_rate (26), rerror_rate (27), srv_rerror_rate (28), same_srv_rate (29), diff_srv_rate (30), srv_diff_host_rate (31), dst_host_count (32), dst_host_srv_count (33), dst_host_same_srv_rate (34), dst_host_diff_srv_rate (35),dst_host_same_src_port_rate (36), dst_host_srv_diff_host_rate (37), dst_host_serror_rate (38), dst_host_srv_serror_rate (39), dst_host_rerror_rate (40), dst_host_srv_rerror_rate (41) |
| Creating Fuzzy Rules | Membership Function: Gaussian Function (Two Parameters: the Expected Value and Standard Deviation); Population Size: 50; Number of Iterations: 250; Generated up to 10 Clusters; Actual Number of Classes: 2 (Attacks and Normal Connections). | |||||
|---|---|---|---|---|---|---|
| Number of generated rules | 7 | 6 | 4 | 3 | 9 | 7 |
| Accuracy (tran.), % | 98.750 | 98.600 | 98.100 | 91.975 | 98.825 | 97.950 |
| Accuracy (test.), % | 98.200 | 98.400 | 98.000 | 92.500 | 98.300 | 97.600 |
| Computational time, s | 8275 | 8628 | 8832 | 8453 | 8344 | 8918 |
| Feature Selection | Population size: 30; quantity of iterations: 100. | |||||
| Number of selected features | 9 | 7 | 9 | 5 | 6 | 3 |
| Solution vector (feature numbers according to KEEL) | 5, 6, 8, 11, 13, 16, 28, 34, 38 | 6, 7, 22, 25, 34, 40, 41 | 1, 11, 13, 21, 29, 31, 32, 36, 37 | 1, 5, 18, 32, 36 | 6, 14, 23, 26, 37, 40 | 6, 29, 36 |
| Accuracy (tran.), % | 99.150 | 99.300 | 98.825 | 98.550 | 99.125 | 99.050 |
| Accuracy (test.), % | 99.200 | 99.500 | 98.500 | 98.400 | 99.000 | 98.700 |
| Type I errors(tran.), % | 1.525 | 0.762 | 0.508 | 1.525 | 0.254 | 1.525 |
| Type I errors(test.), % | 0.000 | 0.000 | 1.523 | 1.523 | 0.000 | 2.030 |
| Type II errors(tran.), % | 0.685 | 0.685 | 1.338 | 1.432 | 1.027 | 0.809 |
| Type II errors(test.), % | 0.996 | 0.623 | 1.494 | 1.619 | 1.245 | 1.121 |
| Computational time, s | 119 | 108 | 94 | 106 | 91 | 92 |
| Fine-tuning the fuzzy classifier | Population size: 30; quantity of iterations: 500. | |||||
| Accuracy (tran.), % | 99.325 | 99.300 | 98.875 | 98.725 | 99.400 | 99.050 |
| Accuracy (test.), % | 99.100 | 99.500 | 98.600 | 98.500 | 99.300 | 98.700 |
| Type I errors(tran.), % | 0.762 | 0.762 | 0.508 | 0.254 | 0.254 | 1.525 |
| Type I errors(test.), % | 0.000 | 0.000 | 1.015 | 0.508 | 0.000 | 2.030 |
| Type II errors(tran.), % | 0.656 | 0.685 | 1.276 | 1.525 | 0.685 | 0.809 |
| Type II errors(test.), % | 1.121 | 0.623 | 1.494 | 1.743 | 0.872 | 1.121 |
| Computational time, s | 817 | 763 | 590 | 364 | 841 | 658 |
| Classifier | Type I Errors (Test), % | Type II Errors (Test), % | Number of Selected Features |
|---|---|---|---|
| Fuzzy Classifier + WOA (proposed method) | 0.92 | 1.07 | 8.4 |
| Fuzzy Classifier + BHS + DE | 1.21 | 0.39 | 10 |
| GP-mt | 2.00 | 0.07 | 41 |
| MLP | 1.49 | 5.29 | 16 |
| CPAR/MLP | 1.58 | 4.86 | 16 |
| PKID + Cons + FVQIT | 7.27 | 0.48 | 6 |
| EMD + Cons + FVQIT | 5.5 | 1.54 | 7 |
| k-NN | 1.22 | 1.6 | 41 |
| AP | 1.01 | 1.6 | 41 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koryshev, N.; Hodashinsky, I.; Shelupanov, A. Building a Fuzzy Classifier Based on Whale Optimization Algorithm to Detect Network Intrusions. Symmetry 2021, 13, 1211. https://doi.org/10.3390/sym13071211
Koryshev N, Hodashinsky I, Shelupanov A. Building a Fuzzy Classifier Based on Whale Optimization Algorithm to Detect Network Intrusions. Symmetry. 2021; 13(7):1211. https://doi.org/10.3390/sym13071211
Chicago/Turabian StyleKoryshev, Nikolay, Ilya Hodashinsky, and Alexander Shelupanov. 2021. "Building a Fuzzy Classifier Based on Whale Optimization Algorithm to Detect Network Intrusions" Symmetry 13, no. 7: 1211. https://doi.org/10.3390/sym13071211
APA StyleKoryshev, N., Hodashinsky, I., & Shelupanov, A. (2021). Building a Fuzzy Classifier Based on Whale Optimization Algorithm to Detect Network Intrusions. Symmetry, 13(7), 1211. https://doi.org/10.3390/sym13071211