
Introducing Urdu Digits Dataset with Demonstration of an Efficient and Robust Noisy Decoder-Based Pseudo Example Generator


Abstract
:1. Introduction
- We propose an efficient way of generating pseudo-examples by using only the decoder network separately for each class that has shown to be effective for both SSL and FSL.
- In the proposed approach, the decoder is trained for each class sample using random noise, and multiple samples are generated using the trained decoder.
- Furthermore, we are the first to release a manually labeled Urdu digits dataset consisting of 10,000 images in total collected through various methods for diversity (https://www.kaggle.com/teerathkumar142/Urdudigits, accessed on (11 April 2022).
- A varied range of experiments were performed, specifically on the Urdu digits dataset, which elucidate the competitiveness and superiority of the proposed network in terms of performance over existing state-of-the-art models.
- Our generator-based approach outperforms previous state-of-the-art SSL and FSL approaches, obtaining an absolute average improvement of 3.04 and 1.50 in terms of accuracy, respectively.
2. Related Work
2.1. Semi-Supervised Learning
2.2. Few-Shot Learning
3. Proposed Approach
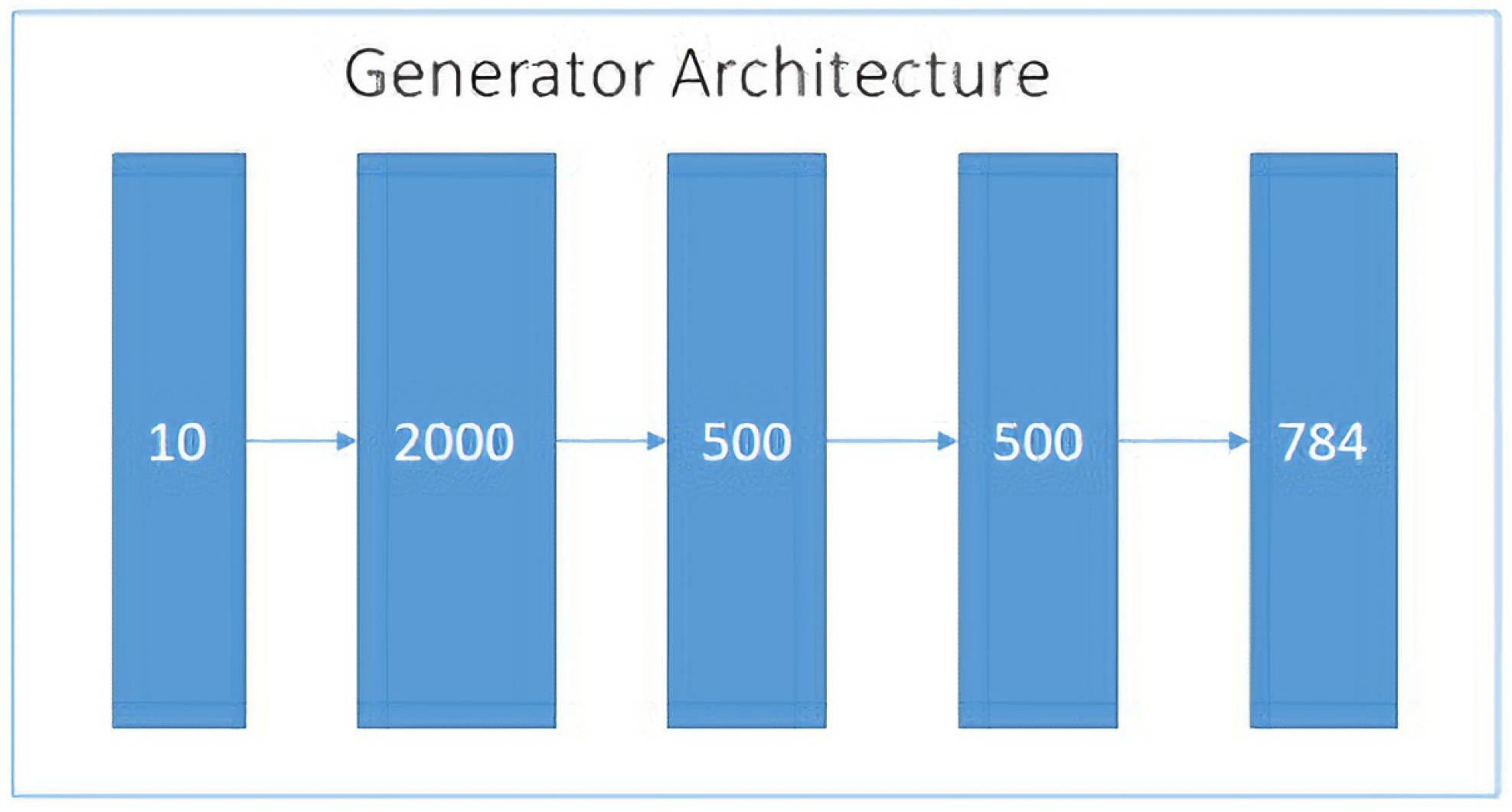
3.1. Decoder Architecture
Training
3.2. Work Flow
| Algorithm 1 Decoder-Training-And-Generating(,,N) |
| Input: : Samples only : Labels of the Samples N: Number of samples per class to be generated |
| Output: dataGenerated, Labels |
 |
4. Newly Introduced Urdu Digits Dataset
4.1. Dataset Motivation
4.2. Dataset Collection
4.2.1. Microsoft (MS) Paint-Based Collection
4.2.2. Online Data Collection
4.2.3. Paper-Based Data Collection
5. Experiment and Results
5.1. Datasets
5.2. Result from Semi-Supervised Learning
5.3. Results from Few-Shot Learning
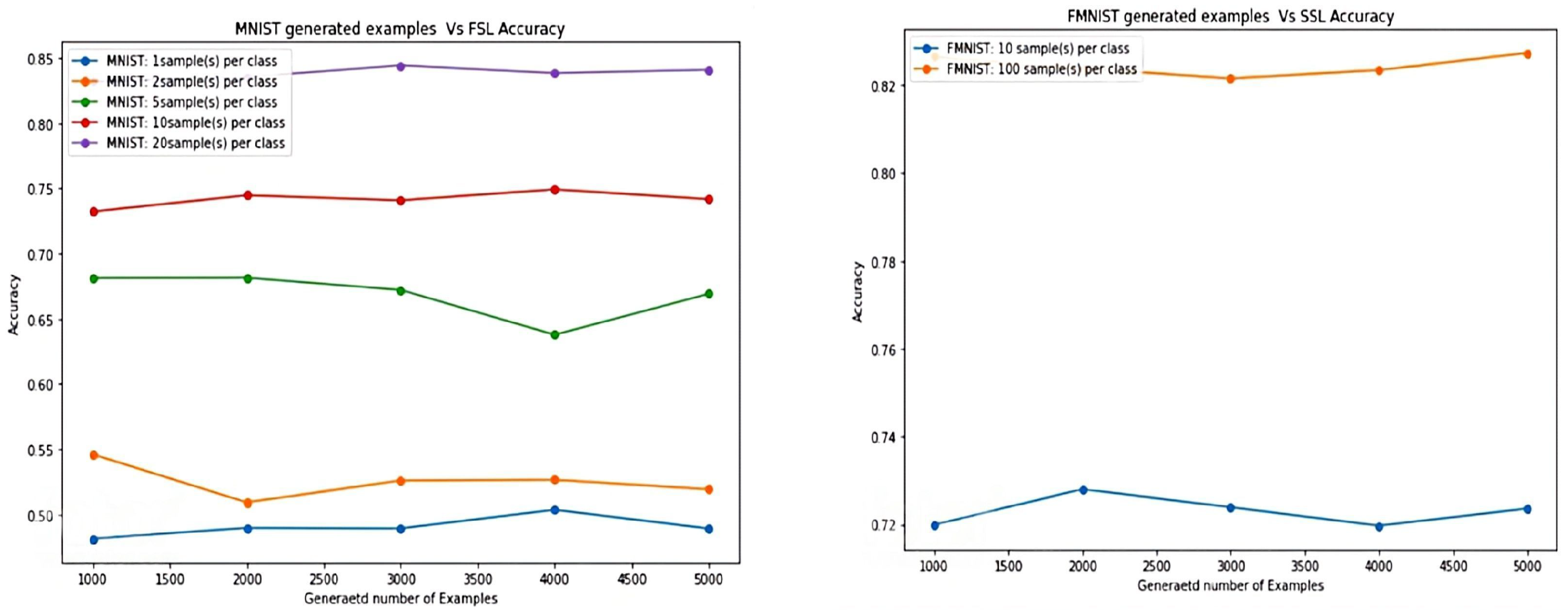
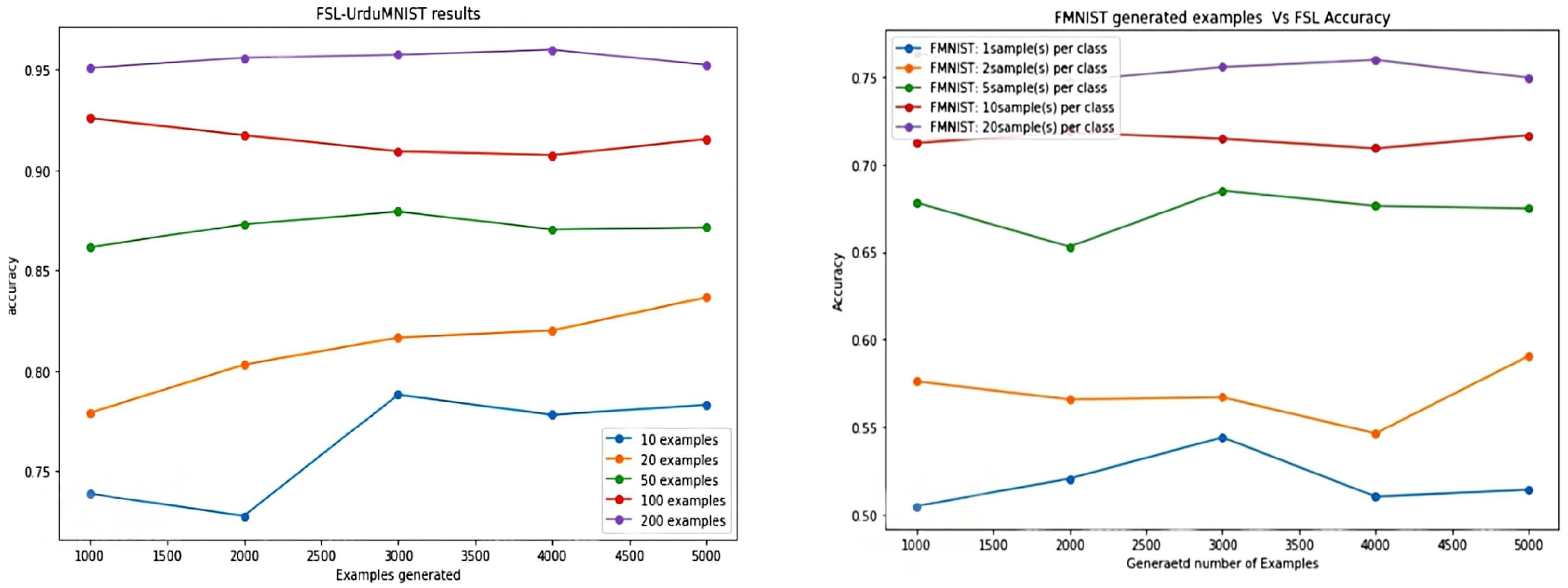
6. Parametric Study
6.1. Performance of SSL
6.2. Performance of FSL
7. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Vailaya, A.; Jain, A.; Zhang, H. On image classification: City images vs. landscapes. Pattern Recognit. 1998, 31, 1921–1935. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 1–48. [Google Scholar] [CrossRef]
- Kumar, T.; Park, J.; Ali, M.; Uddin, A.; Ko, J.; Bae, S. Binary-classifiers-enabled filters for semi-supervised learning. IEEE Access 2021, 9, 167663–167673. [Google Scholar] [CrossRef]
- Kumar, T.; Park, J.; Ali, M.; Uddin, A.; Bae, S. Class Specific Autoencoders Enhance Sample Diversity. J. Broadcast Eng. 2021, 26, 844–854. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 84–90. [Google Scholar] [CrossRef]
- Jamil, S.; Abbas, M.S.; Roy, A.M. Distinguishing Malicious Drones Using Vision Transformer. AI 2022, 3, 260–273. [Google Scholar] [CrossRef]
- Alam, A.; Ullah, I.; Lee, Y. Video Big Data Analytics in the Cloud: A Reference Architecture, Survey, Opportunities, and Open Research Issues. IEEE Access 2020, 8, 152377–152422. [Google Scholar] [CrossRef]
- Roy, A.M.; Bhaduri, J. A Deep Learning Enabled Multi-Class Plant Disease Detection Model Based on Computer Vision. AI 2022, 2, 413–428. [Google Scholar] [CrossRef]
- Roy, A.M.; Bose, R.; Bhaduri, J. A fast accurate fine-grain object detection model based on YOLOv4 deep neural network Neural Comput. Appl. 2022, 34, 3895–3921. [Google Scholar]
- Roy, A.M.; Bose, R.; Bhaduri, J. Real-time growth stage detection model for high degree of occultation using DenseNet-fused YOLOv4. Comput. Electron. Agric. 2022, 193, 106694. [Google Scholar] [CrossRef]
- Ullah, I.; Khan, S.; Imran, M.; Lee, Y. RweetMiner: Automatic identification and categorization of help requests on twitter during disasters. Expert Syst. Appl. 2021, 176, 114787. [Google Scholar]
- Kowsari, K.; Jafari Meimandi, K.; Heidarysafa, M.; Mendu, S.; Barnes, L.; Brown, D. Text classification algorithms: A survey. Information 2019, 10, 150. [Google Scholar]
- Aggarwal, C.; Zhai, C. Aggarwal, C.; Zhai, C. A survey of text classification algorithms. In Mining Text Data; Springer: Boston, MA, USA, 2012; pp. 163–222. [Google Scholar]
- Ikonomakis, M.; Kotsiantis, S.; Tampakas, V. Text classification using machine learning techniques. WSEAS Trans. Comput. 2005, 4, 966–974. [Google Scholar]
- Kumar, T.; Park, J.; Bae, S. Intra-Class Random Erasing (ICRE) augmentation for audio classification. In Proceedings of the Korean Society of Broadcast Engineers Conference; The Korean Institute of Broadcast and Media Engineers: Anseong, Korea, 2020; pp. 244–247. [Google Scholar]
- Park, J.; Kumar, T.; Bae, S. Search for optimal data augmentation policy for environmental sound classification with deep neural networks. J. Broadcast Eng. 2020, 25, 854–860. [Google Scholar]
- Chandio, A.; Shen, Y.; Bendechache, M.; Inayat, I.; Kumar, T. AUDD: Audio Urdu digits dataset for automatic audio Urdu digit recognition. Appl. Sci. 2021, 11, 8842. [Google Scholar]
- Turab, M.; Kumar, T.; Bendechache, M.; Saber, T. Investigating Multi-Feature Selection and Ensembling for Audio Classification. arXiv 2022, arXiv:2206.07511. [Google Scholar] [CrossRef]
- Roy, A.M. An efficient multi-scale CNN model with intrinsic feature integration for motor imagery EEG subject classification in brain-machine interfaces Biomed. Signal Process. Control 2022, 74, 103496. [Google Scholar]
- Roy, A.M. A multi-scale fusion CNN model based on adaptive transfer learning for multi-class MI-classification in BCI system. bioRxiv 2022. [Google Scholar] [CrossRef]
- Roy, A.M. Adaptive transfer learning-based multiscale feature fused deep convolutional neural network for EEG MI multiclassification in brain–computer interface Eng. Appl. Artif. Intell. 2022, 116, 105347. [Google Scholar] [CrossRef]
- Ranjbarzadeh, R.; Tataei Sarshar, N.; Jafarzadeh Ghoushchi, S.; Saleh Esfahani, M.; Parhizkar, M.; Pourasad, Y.; Anari, S.; Bendechache, M. MRFE-CNN: Multi-route feature extraction model for breast tumor segmentation in Mammograms using a convolutional neural network. Ann. Oper. Res. 2022, 11. [Google Scholar] [CrossRef]
- Baseri Saadi, S.; Tataei Sarshar, N.; Sadeghi, S.; Ranjbarzadeh, R.; Kooshki Forooshani, M.; Bendechache, M. Investigation of Effectiveness of Shuffled Frog-Leaping Optimizer in Training a Convolution Neural Network. J. Healthc. Eng. 2022, 2022, 4703682. [Google Scholar] [CrossRef] [PubMed]
- Saadi, S.; Ranjbarzadeh, R.; Amirabadi, A.; Ghoushchi, S.; Kazemi, O.; Azadikhah, S.; Bendechache, M. Others Osteolysis: A literature review of basic science and potential computer-based image processing detection methods. Comput. Intell. Neurosci. 2021, 2021, 4196241. [Google Scholar] [CrossRef] [PubMed]
- Valizadeh, A.; Jafarzadeh Ghoushchi, S.; Ranjbarzadeh, R.; Pourasad, Y. Presentation of a segmentation method for a diabetic retinopathy patient’s fundus region detection using a convolutional neural network. Comput. Intell. Neurosci. 2021, 2021, 7714351. [Google Scholar]
- Jafarzadeh Ghoushchi, S.; Memarpour Ghiaci, A.; Rahnamay Bonab, S.; Ranjbarzadeh, R. Barriers to circular economy implementation in designing of sustainable medical waste management systems using a new extended decision-making and FMEA models. Environ. Sci. Pollut. Res. 2022, 32. [Google Scholar] [CrossRef]
- Ranjbarzadeh, R.; Dorosti, S.; Jafarzadeh Ghoushchi, S.; Safavi, S.; Razmjooy, N.; Tataei Sarshar, N.; Anari, S.; Bendechache, M. Nerve optic segmentation in CT images using a deep learning model and a texture descriptor. Complex Intell. Syst. 2022, 8, 3543–3557. [Google Scholar]
- Ghoushchi, S.; Ranjbarzadeh, R.; Dadkhah, A.; Pourasad, Y.; Bendechache, M. An extended approach to predict retinopathy in diabetic patients using the genetic algorithm and fuzzy C-means. BioMed Res. Int. 2021, 2021, 5597222. [Google Scholar] [CrossRef] [PubMed]
- Roy, A.M. Evolution of martensitic nanostructure in NiAl alloys: Tip splitting and bending. Mater. Sci. Res. India. 2020, 17, 3–6. [Google Scholar] [CrossRef]
- Roy, A.M. Finite element framework for efficient design of three dimensional multicomponent composite helicopter rotor blade system. Eng 2021, 2, 69–79. [Google Scholar] [CrossRef]
- Li, W.; Wang, Z.; Li, J.; Polson, J.; Speier, W.; Arnold, C. Semi-supervised learning based on generative adversarial network: A comparison between good GAN and bad GAN approach. In Proceedings of the CVPR Workshops, Long Beach, CA, USA, 16–20 June 2019; pp. 55–65. [Google Scholar]
- Kingma, D.; Mohamed, S.; Jimenez Rezende, D.; Welling, M. Semi-supervised learning with deep generative models. In Proceedings of the Advances In Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Khan, W.; Kumar, T.; Cheng, Z.; Raj, K.; Roy, A.M.; Luo, B. SQL and NoSQL Databases Software architectures performance analysis and assessments—A Systematic Literature review. arXiv 2022, arXiv:2209.06977. [Google Scholar] [CrossRef]
- Kimura, A.; Ghahramani, Z.; Takeuchi, K.; Iwata, T.; Ueda, N. Few-shot learning of neural networks from scratch by pseudoexample optimization. arXiv 2018, arXiv:1802.03039. [Google Scholar]
- Weston, J.; Ratle, F.; Mobahi, H.; Collobert, R. Deep learning via semi-supervised embedding. In Neural Networks: Tricks of the Trade; Springer: Cham, Switzerland, 2012; pp. 639–655. [Google Scholar]
- Li, Y.; Pan, Q.; Wang, S.; Peng, H.; Yang, T.; Cambria, E. Disentangled variational auto-encoder for semi-supervised learning. Inf. Sci. 2019, 482, 73–85. [Google Scholar] [CrossRef] [Green Version]
- Tachibana, R.; Matsubara, T.; Uehara, K. Semi-supervised learning using adversarial networks. In Proceedings of the 2016 IEEE/ACIS 15th International Conference On Computer And Information Science (ICIS), Okayama, Japan, 26–29 June 2016; pp. 1–6. [Google Scholar]
- Berkhahn, F.; Keys, R.; Ouertani, W.; Shetty, N.; Geißler, D. Augmenting variational autoencoders with sparse labels: A unified framework for unsupervised, semi-(un) supervised, and supervised learning. arXiv 2019, arXiv:1908.03015. [Google Scholar]
- Asadulaev, A.; Kuznetsov, I.; Filchenkov, A. Interpretable few-shot learning via linear distillation. arXiv 2019, arXiv:1906.05431. [Google Scholar]
- Lee, D. Others Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. Workshop Chall. Represent. Learn. ICML 2013, 3, 896. [Google Scholar]
- Haiyan, W.; Haomin, Y.; Xueming, L.; Haijun, R. Semi-supervised autoencoder: A joint approach of representation and classification. In Proceedings of the 2015 International Conference On Computational Intelligence And Communication Networks (CICN), Jabalpur, India, 12–14 December 2015; pp. 1424–1430. [Google Scholar]
- Robbins, H.; Monro, S. A stochastic approximation method. Ann. Math. Stat. 1951, 22, 400–407. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference On Computer Vision, Santiago, Chile, 7–13 December2015; pp. 1026–1034. [Google Scholar]
- Mohammed Abd-Alsalam Selami, A.; Freidoon Fadhil, A. A study of the effects of gaussian noise on image features. Kirkuk Univ. J.-Sci. Stud. 2016, 11, 152–169. [Google Scholar] [CrossRef]
- Russo, F. A method for estimation and filtering of Gaussian noise in images. IEEE Trans. Instrum. Meas. 2003, 52, 1148–1154. [Google Scholar] [CrossRef]
- Kaur, P.; Singh, J. A study on the effect of Gaussian noise on PSNR value for digital images. Int. J. Comput. Electr. Eng. 2011, 3, 319. [Google Scholar] [CrossRef]
- Hussain, S. Resources for Urdu language processing. In Proceedings of the 6th Workshop On Asian Language Resources, Hyderabad, India, 11–12 January 2008. [Google Scholar]
- Plötz, T.; Fink, G. Markov models for offline handwriting recognition: A survey. Int. J. Doc. Anal. Recognit. (IJDAR). 2009, 12, 269–298. [Google Scholar] [CrossRef]
- Lee, C.; Leedham, C. A new hybrid approach to handwritten address verification. Int. J. Comput. Vis. 2004, 57, 107–120. [Google Scholar] [CrossRef]
- Ul-Hasan, A.; Ahmed, S.; Rashid, F.; Shafait, F.; Breuel, T. Offline printed Urdu Nastaleeq script recognition with bidirectional LSTM networks. In Proceedings of the 2013 12th International Conference On Document Analysis and Recognition, Washington, DC, USA, 25–28 August 2013; pp. 1061–1065. [Google Scholar]
- LeCun, Y. The MNIST Database of Handwritten Digits. 1998. Available online: http://yann.Lecun.Com/exdb/mnist/ (accessed on 11 December 2021).
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | 100 Labels | 1000 Labels |
|---|---|---|
| CCNs [38] | 76.51 ± 3.21 | 89.11 ± 2.10 |
| CCNs (MS) [38] | 81.10 ± 6.16 | 94.51 ± 1.13 |
| CNNss (AE) [4] | 78.89 ± 1.92 | 89.33 ± 2.17 |
| CNNss (Ours) | 78.16 ± 1.10 | 95.11 ± 2.30 |
| Model | 100 Labels | 1000 Labels |
|---|---|---|
| CCNs [38] | 66.22 ± 1.02 | 80.30 ± 1.98 |
| CCNs (MS) [38] | 72.41 ± 0.87 | 83.67 ± 1.09 |
| CNNs (AE) [4] | 72.51 ± 2.57 | 79.93 ± 1.46 |
| CNNs (Ours) | 74.52 ± 1.42 | 82.71 ± 1.47 |
| Labels | 10 | 20 | 50 | 100 | 200 |
|---|---|---|---|---|---|
| SSL (Ours) | 80.15 | 84.90 | 89.05 | 93.45 | 96.70 |
| Labels | 10 | 20 | 50 | 100 | 200 |
|---|---|---|---|---|---|
| NN [34] | 37.90 | 46.00 | 66.00 | 78.30 | 86.70 |
| GP [34] | 39.90 | 51.60 | 64.60 | 73.20 | 80.00 |
| Imt [34] | 43.50 | 51.20 | 67.70 | 78.10 | 86.10 |
| Imt, opt [34] | 44.10 | 53.70 | 70.00 | 79.50 | 86.70 |
| Imt, opt, fd [34] | 44.10 | 53.90 | 70.40 | 80.00 | 86.60 |
| CNN (AE) [4] | 46.30 | 54.30 | 59.40 | 67.40 | 76.40 |
| FSL (Ours) | 50.33 | 54.59 | 68.14 | 76.34 | 86.41 |
| Labels | 10 | 20 | 50 | 100 | 200 |
|---|---|---|---|---|---|
| NN [34] | 39.30 | 47.90 | 58.30 | 64.90 | 71.30 |
| GP [34] | 44.60 | 52.40 | 59.90 | 65.70 | 71.40 |
| Imt [34] | 43.60 | 50.90 | 60.00 | 67.30 | 72.50 |
| Imt, opt [34] | 41.20 | 49.70 | 60.10 | 67.30 | 72.20 |
| Imt, opt, fd [34] | 44.80 | 52.70 | 62.10 | 67.30 | 72.50 |
| CNN (AE) [4] | 48.20 | 56.10 | 58.80 | 65.80 | 69.49 |
| FSL (Ours) | 54.42 | 59.06 | 67.51 | 70.82 | 74.37 |
| Labels | 10 | 20 | 50 | 100 | 200 |
|---|---|---|---|---|---|
| Our | 78.80 | 83.65 | 87.95 | 92.56 | 96.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, W.; Raj, K.; Kumar, T.; Roy, A.M.; Luo, B. Introducing Urdu Digits Dataset with Demonstration of an Efficient and Robust Noisy Decoder-Based Pseudo Example Generator. Symmetry 2022, 14, 1976. https://doi.org/10.3390/sym14101976
Khan W, Raj K, Kumar T, Roy AM, Luo B. Introducing Urdu Digits Dataset with Demonstration of an Efficient and Robust Noisy Decoder-Based Pseudo Example Generator. Symmetry. 2022; 14(10):1976. https://doi.org/10.3390/sym14101976
Chicago/Turabian StyleKhan, Wisal, Kislay Raj, Teerath Kumar, Arunabha M. Roy, and Bin Luo. 2022. "Introducing Urdu Digits Dataset with Demonstration of an Efficient and Robust Noisy Decoder-Based Pseudo Example Generator" Symmetry 14, no. 10: 1976. https://doi.org/10.3390/sym14101976
APA StyleKhan, W., Raj, K., Kumar, T., Roy, A. M., & Luo, B. (2022). Introducing Urdu Digits Dataset with Demonstration of an Efficient and Robust Noisy Decoder-Based Pseudo Example Generator. Symmetry, 14(10), 1976. https://doi.org/10.3390/sym14101976