1. Introduction
With the progress of technology, human–machine communication has been merged into our lives [
1,
2,
3,
4]. The applications of facial expression recognition (FER) have become ever more essential, such as human–computer interaction, online testing, medical care, etc. [
5,
6,
7]. When applying a facial expression classification system, the various expressions have serious differences. That can be demonstrated by the FACS (Facial Action Coding System) [
8]. AU (action unit) [
9] and expressions have some correspondence. For example, there is a greater symmetrical similarity between happiness and contempt compared with the symmetrical similarity between happiness and sadness because happiness and contempt contain AU12, and there is no intersection between the AU domain of happiness and sadness. Similar facial expressions can sometimes make it difficult to make a distinction.
Computer recognition of facial expressions mainly consists of three steps, viz., image preprocessing, feature extraction, and classification. Among them, feature extraction is an important step. It relates to the recognition accuracy of facial expressions. Traditional feature extraction methods are mainly designed manually, such as Gabor wavelet, local binary pattern (LBP), histogram of gradient (HOG), etc. Rujirakul et al. [
10] proposed a facial expression recognition method that contained histogram equalization (HE), principal component analysis (PCA), and extreme learning machine (ELM). HE was utilized for preprocessing to adjust the histogram curve of the input image. Then, PCA was employed to extract the features. Finally, ELM was employed for classification. Kumary et al. [
11] put forward a facial expression recognition system which was the feature selection approach from the quantum-inspired binary gravitational search algorithm (QIBGSA). The idea of the QIBGSA was a modified binary version of the gravitational search algorithm by impersonating the properties of quantum mechanics. The experiment has achieved certain results. Islam et al. [
12] presented a framework for recognizing human emotion through facial expression recognition by analyzing a large number of facial expression images and the possible locations of the expression regions in these images to manually segment the expression regions in an efficient and unique way. The experiment obtained better results. Xi et al. [
13] raised surface electromyography (sEMG)-based emotion distribution learning (EDL) for predicting the intensity of underlying emotions. Choudhary et al. [
14] proposed a systematic comparison of the facial features. Traditional methods in facial expression recognition applications can be found in [
15,
16,
17,
18]. Traditional feature extraction methods have many drawbacks, such as incomplete and limited information extraction, and insufficient robustness of image size and illumination.
As computer software and hardware evolve, environments for deep learning are well developed. The advantage of the convolutional neural network (CNN) is remarkable. The CNN can extract the features of images more completely and has strong robustness to the size and illumination of the images. It also has achieved good results in facial expression recognition. AlexNet [
19,
20], VGGNet [
21,
22], GoogLeNet [
23], etc., have been commonly used for facial expression recognition. Due to the poor effect of traditional methods of facial expression recognition, Wu et al. [
24] optimized and improved the internal structure based on LeNet-5 network. Batch normalization had been added to settle the over-fitting issue of the network owing to distinct features. Maximum pooling and average pooling were symmetrically used to fully extract facial expression features and to reduce the redundant data. Using deep learning to recognize facial expressions can enable the learning of important and robust features for different samples. This is a key problem with facial expression recognition. Ye et al. [
25] presented a region-based convolutional fusion network (RCFN) to solve the problems by three aspects, which were a built muscle movement model, a constructed network, and constrained punitive loss. The experiment results showed that RCFN was effective in commonly used datasets. Singh et al. [
26] proposed the classification of FER which used CNNs based on static images. Feature extraction was used to extract features of the facial part, such as eyes, nose, and eyebrows. The experiment achieved better results. Chen et al. [
27] put forward an improved method of facial expression recognition based on CNN. A new convolution neural network structure was designed which uses a convolution kernel to extract key features and max pooling to reduce the redundant features. There are also deep learning methods in facial expression recognition applications, such as [
28,
29,
30,
31,
32,
33,
34,
35,
36,
37].
Many deep learning methods brought excellent results in cases of large amounts of computation, limiting their applications for small devices or offline scenarios. To effectively address this problem, Zhou et al. [
38] proposed a frequency multiplication network (FMN), which was a deep learning method running in the frequency domain and could significantly reduce network capacity and computing workload. Combined with the uniform rectangle feature (URF), this method further improves the performance and reduces the training workload. Cotter et al. [
39] put forward a new lightweight deep learning model, MobiExpressNet for FER. The model relied on depthwise separable convolutions to limit the complexity and used a fast down sampling method and several layers in the architecture to keep the model size very small. It achieved good results. Nan et al. [
40] proposed a lightweight A-MobileNet model. The method significantly improved recognition accuracy without increasing the number of model parameters.
The continuous development of facial expression recognition technology has led to the continuous advancement of face detection and recognition technology. This promotes the development of facial expression recognition technology. Ding et al. [
41] proposed a shared generative adversarial network, SharedGAN, to expand the gallery dataset. Experimental results illustrated the effectiveness of SharedGAN and showed satisfactory results. Abdulhussain et al. [
42] presented a new scheme for face recognition which used hybrid orthogonal polynomials to extract features.
The above facial expression recognition methods have been improved in several aspects, but some problems still exist:
- (1)
The cross-dataset facial expression comes from different facial expression datasets with fuzziness and asymmetry, so differences among facial expressions are huge. It becomes more difficult for network learning on cross-dataset facial expressions, which results in a decrease in recognition accuracy.
- (2)
Multi-region learning on an image does not extract the overall image information. The corresponding network lacks global information. So, it also makes identification more difficult.
- (3)
A frequency multiplication network could reduce the network complexity, but it does not take into account the inter-class and intra-class features in image classification. This results in a low facial expression recognition rate.
Focusing on the above problems, we put forward a symmetric mode to extract the inter-class features and intra-class diversity features, and then propose a triple-structure network model, which is trained via a new multi-branch loss function. The proposed network consists of triple structures, i.e., a global branch network, an attention mechanism branch network, and a diversified feature learning branch network. The proposed network is based upon MobileNet V1, which has the characteristics of being lightweight and a high recognition rate. The focus is different from each branch loss function. The global branch network mainly focuses on learning the global features of images. The attention mechanism branch network mainly concentrates on learning the inter-class features, and the diversified feature learning branch network mainly focuses on learning the intra-class diversity features.
In summary, the main contributions of our work are as follows:
- (1)
A facial expression recognition network is proposed based upon MobileNet V1. Our network is a simple and effective network, which can achieve a better recognition rate.
- (2)
We propose an improved multi-loss function network, which includes a global branch network, an attention mechanism branch network based on SENet, and a diversified feature learning branch network. The global branch network is employed to extract the global features of facial expression images. A symmetric mode is raised to extract the inter-class key features and intra-class diversity features. In detail, the attention mechanism branch network concentrates to extract inter-class key features, while the diversified feature learning branch network is used to extract intra-class diverse features.
- (3)
We put forward a multi-branch network. The network avoids only focusing on the local or global regions of the image, but both global and local images participate in the learning.
The remainder of this study is organized as described next.
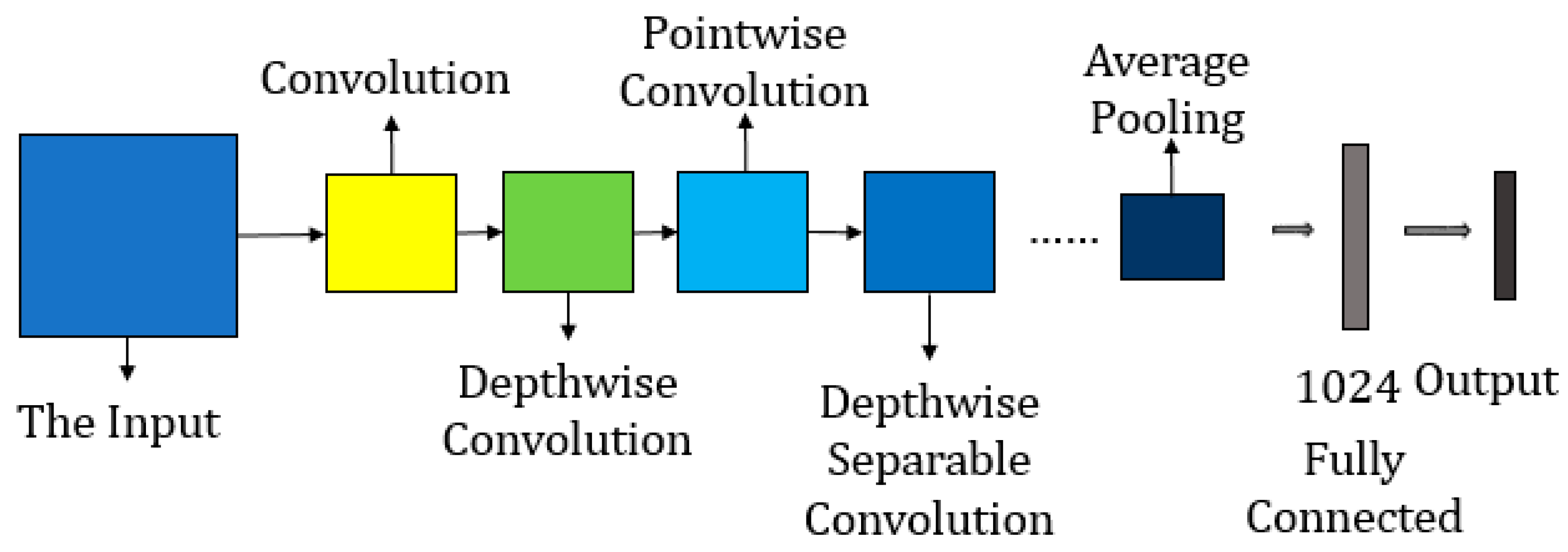
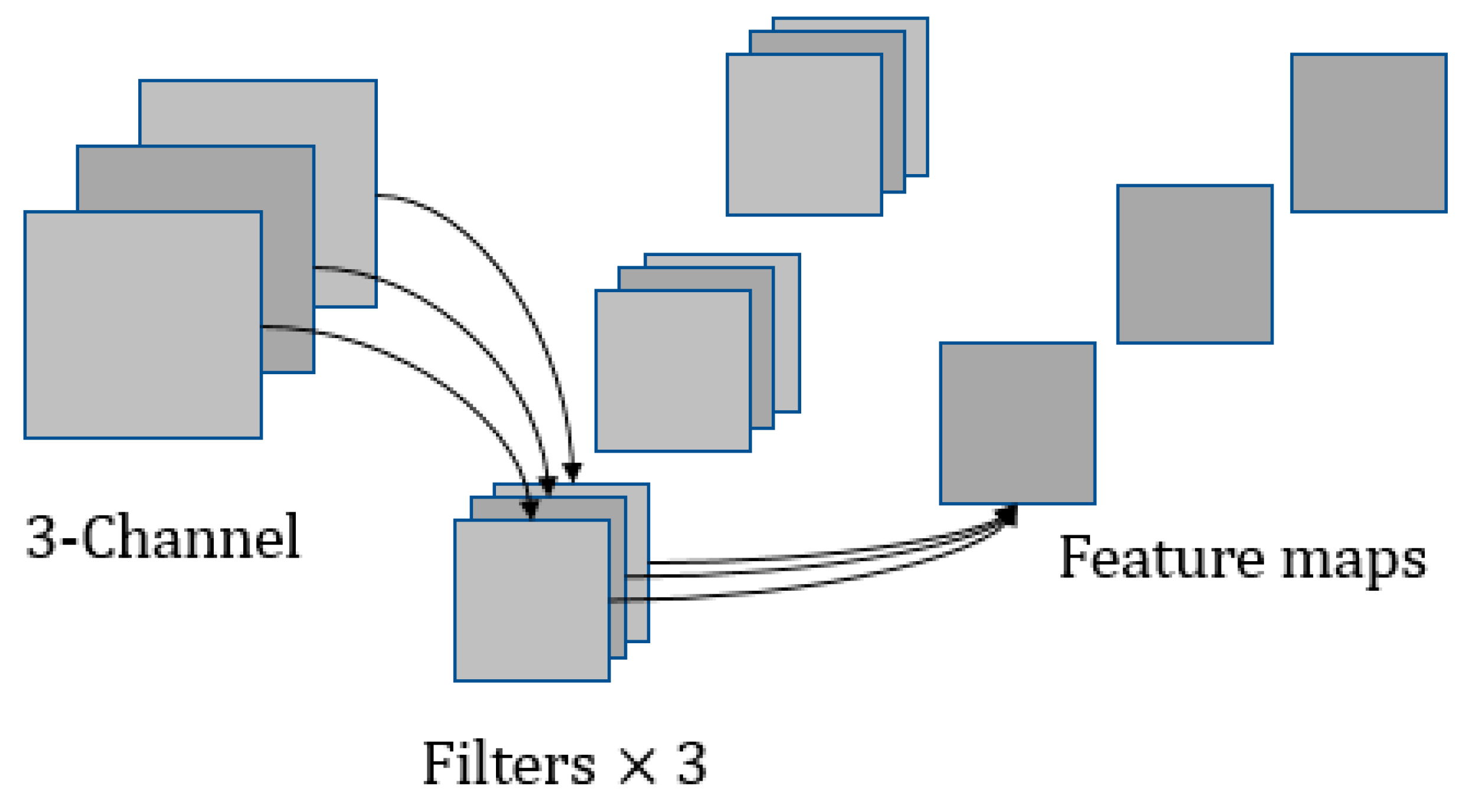
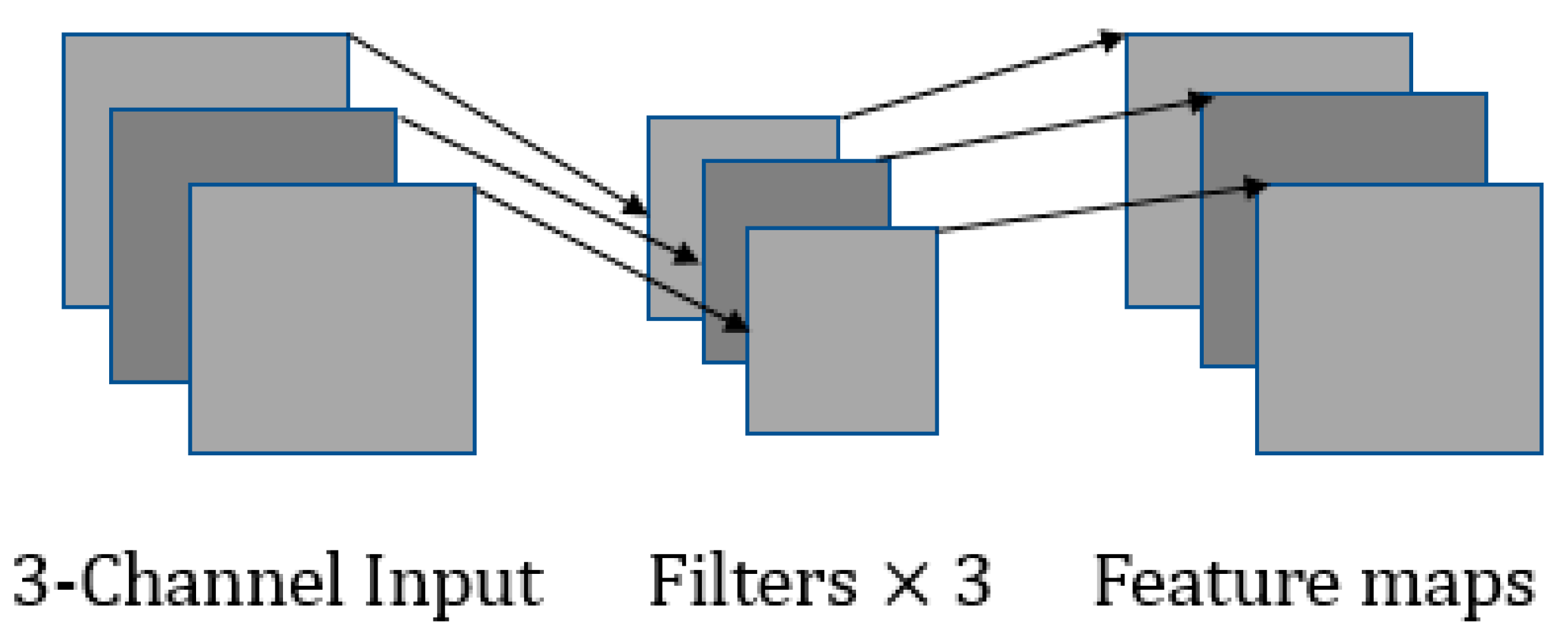
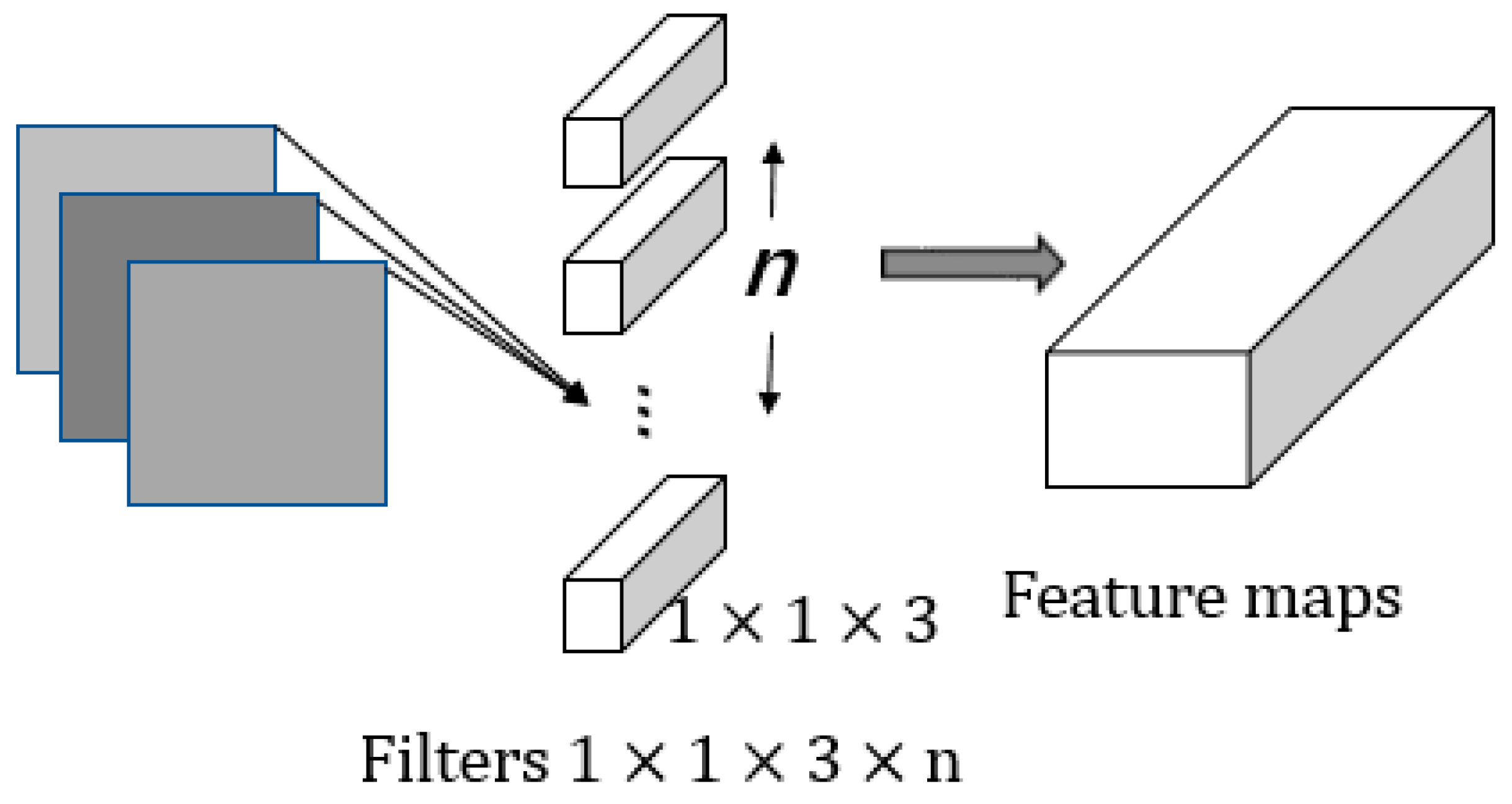
Section 2 introduces related works, including MobileNet V1 and SENet.
Section 3 depicts the details of our proposed network of triple structures. In
Section 4, the effectiveness of our network is verified by comparison and ablation experiments with some facial expression recognition models, respectively. In
Section 5, to further test the effectiveness of our network, a class activation map visualization is performed on each branch of the model.
Section 6 summarizes and discusses future research plans.
3. The Proposed Triple-Structure Network Model
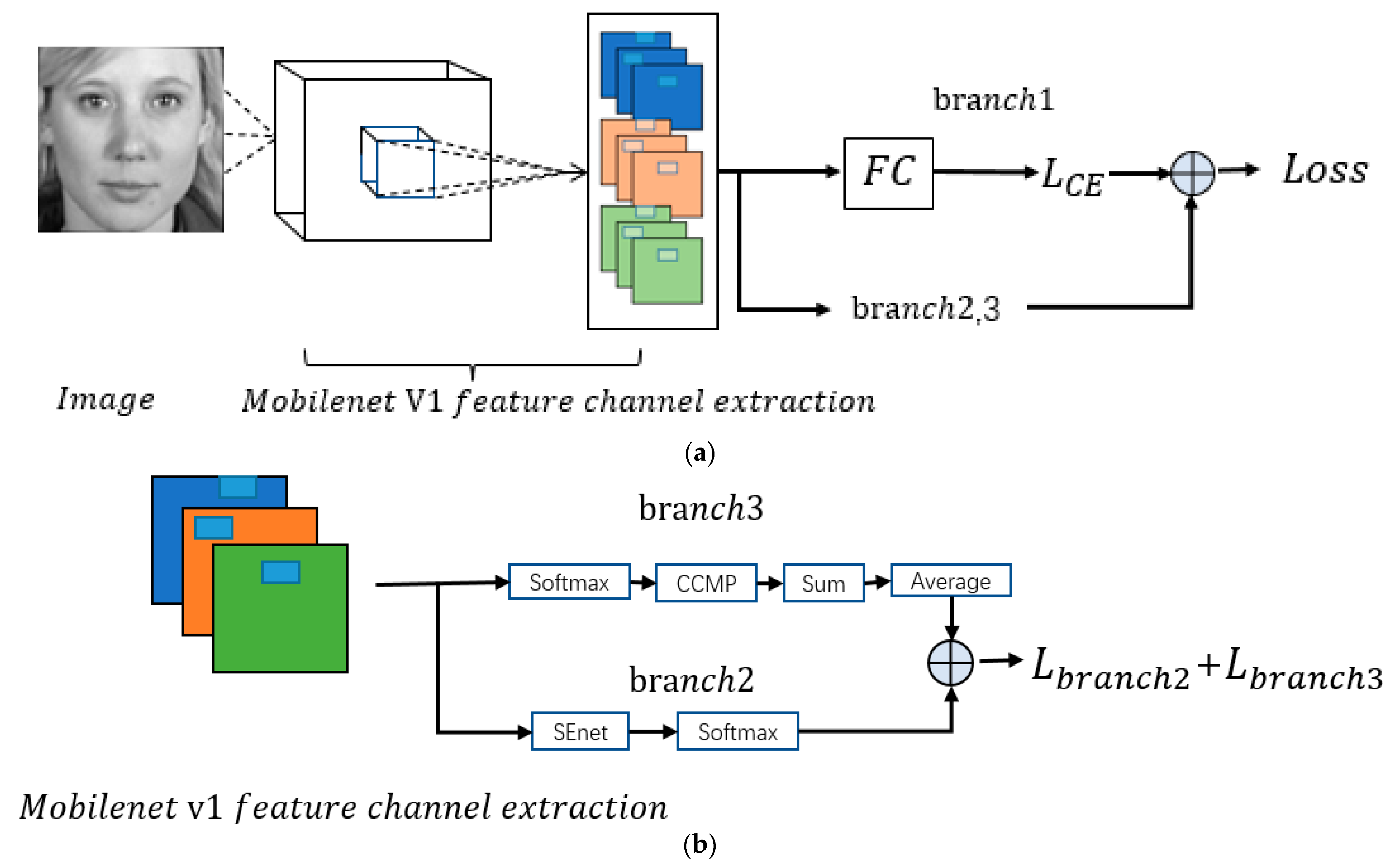
In this study, we propose a symmetric mode to extract the inter-class features and intra-class diversity features, and then put forward a triple-structure network model based on MobileNet V1, which is trained via a new multi-branch loss function. Such a proposed network consists of triple structures, which incorporates a global branch network, an attention mechanism branch network, and a diversified feature learning branch network. The overall architecture model of the proposed triple-structure network model is shown in
Figure 6.
In what follows, we show the details for the proposed triple-structure network model.
3.1. The General Idea of the Triple-Structure Network Model
Inspired by Ref. [
49], our network introduces mutual channel loss (MC-loss) to discover multiple discriminative regions and restrict feature distribution. MC-loss has the following advantages:
- ⯀
It makes the network easier to train, because the network does not introduce any additional network parameters.
- ⯀
The method combines global and local regions and forces the network to capture subtle differences by discriminant components.
- ⯀
It can effectively improve the recognition rate for solving fine-grained image classification.
In the meantime, MC-loss avoids too much attention to localized regions of an image. Thus, a global branch has been introduced to extract information from the overall regions of an image.
Based on the above advantages, our study applies MC-loss to facial expression recognition. The network is adjusted according to the differences between the expression image set and the fine-grained image set. For example, fine-grained image classification emphasizes the problem of distinguishing among subcategories of common visual categories. Meanwhile, facial expression recognition emphasizes the classification of facial motion.
MobileNet V1 is used instead of the ResNet/VGG on MC-loss. Additionally, MC-loss has utilized the discriminative component to promote network learning. However, the discriminative component contains a random attention mechanism, such as the feature corresponding to each class of the feature extracted by the basic network is randomly discarded by the half. This random discarding method influences the recognition accuracy. Our network employs the attention mechanism branch network to take the place of the discriminative component. The attention mechanism branch does not contain the random discarding method. This branch can effectively distinguish the inter-class features of facial expression images.
The overall framework is displayed in
Figure 6. Based on the basic backbone network of MobileNet V1, our network consists of triple structures (or branches), i.e., the global branch network (branch1), the attention mechanism branch network (branch2), and the diversified feature learning branch network (branch3).
Branch1 learns mainly the global features. Branch2 acquires primarily to extract inter-class key features, and branch3 focuses to extract intra-class diverse features. Note that branch2 and the branch3 construct a symmetric mode to extract the inter-class features and intra-class diversity features.
The total network loss function
can be defined as follows:
represents the branch1 loss function.
stands for the branch2 loss function.
denotes the branch3 loss function.
and
are hyper-parameters. During the training phase, the global network branch (branch1) can fully learn the inter-class and intra-class features in facial expression images through the guidance of branch2 and branch3. Thus, branch2 and branch3 do not participate in the test phase.
3.2. Basic Backbone Network and Global Branch Network
In our research, to enter an image, we first extract the feature map by feeding the image into MobileNet V1. The extracted feature maps are represented as . H stands for the height, W represents the width, and N is the number of channels.
Additionally, we need to set the value of to be equal to . is the number of classes in a dataset. stands for the number of feature channels employed to express each class.
Therefore, the
-th vectored feature channel of
can be expressed by
Please notice that we reshaped each channel matrix of
of dimension
to a vector of size
multiplied by
, i.e.,
. Therefore, the grouped feature channels relevant to the
i-th class is pointed to by
, where
namely:
As a consequence, we obtained the grouped deep features
, in which
.
represents the
processed by the fully connected layer. We made use of the cross-entropy loss function
, calculating the dissimilarity between the ground-truth label
and the predicted probability
. Here,
is expressed by the following form:
To sum up, the loss function of branch1 (i.e.,
) can be described as below:
3.3. Attention Mechanism Branch Network
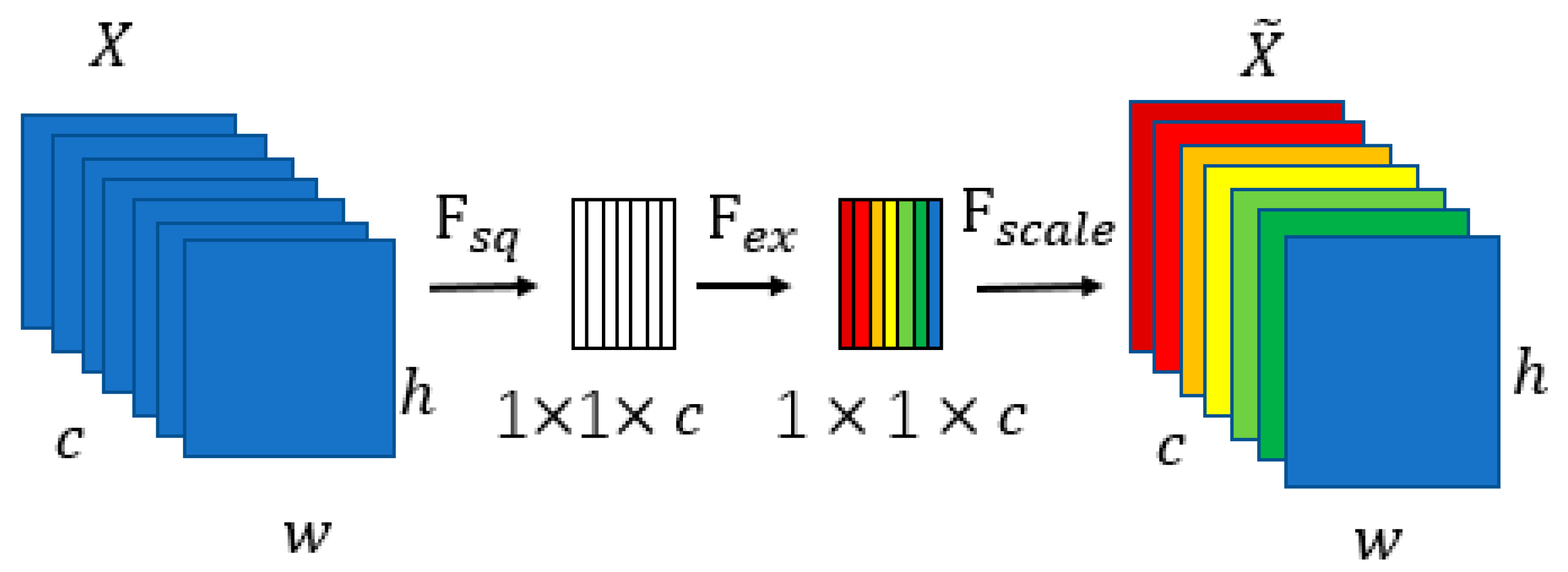
In facial expression recognition, because muscle activity is very similar to intra-class facial expression, the intra-class similarity is high. Distinguishing different facial expressions is a significant step in recognition that directly affects the accuracy of recognition. Feature extraction is carried out for facial expression images, while differentiated weighting is performed on the extracted features. Features processed by SENet can improve the discrepant features, and thus better distinguish different emotions.
For this reason, we employed SENet to assign weights to facial expression features, which makes the important feature channels play a bigger role and weakens the unimportant feature channels. Through the SENet operation, the weight of each channel is different, which makes it easier to distinguish efficiently different facial expressions. We define
as follows:
Here, represents the feature processed by SENet. We used the cross-entropy loss function to calculate the dissimilarity between the ground-truth label and the predicted probability .
Following that, the loss function of branch2 (i.e.,
) can be characterized by the following formula:
3.4. Diversified Feature Learning Branch Network
Considering facial expression images, different feature channels of the same class should focus on dissimilar areas of the facial expression images, instead of the total of the channels concentrating on discriminative areas. For example, the global branch network and the attention mechanism branch network have difficulty in capturing different regions on the same facial expressions, resulting in a low recognition rate.
To better solve the above problem, a diversified feature learning branch network was introduced to our research. We attempted to learn multiple regions within a class and utilize multiple losses to supervise the training, which allows multiple regions to work commonly and symmetrically complement each other. The fundamental purpose of the diversity loss function is to yield the feature maps within a class, which is different regions during learning. Thus, the learned feature of the class is more diverse. The specific expression of the loss function of branch3 (i.e.,
) is shown as follows:
in which
Here,
expresses the width of the feature map, and
represents the height of the feature map.
stands for the number of characteristic graphs in each intra-class of expressions. As shown in
Figure 6, the feature map is normalized by softmax, and then dealt with by CCMP (cross channel max pooling). The CCMP comes from the concept of maxout [
50], which takes out the channels of each class and their maximum values. Through the above, some distinguished features within a class can be concentrated on a one-dimensional feature map. Then, salient regions of each group of features are obtained by accumulation, which are averaged to obtain the feature diversity loss
.
4. Experiments and Analyses
4.1. Experimental Dataset
To evaluate the proposed triple-structure network model, we conducted experiments on the MMI [
51], KDEF [
52], and CK+ [
53] databases. KDEF images are captured in controlled lab environments, containing 4900 images consisting of 70 people, of which 35 are females and 35 are males, aged between 20 to 30, which display 7 basic facial expressions. We only employed the 980 front view images. MMI is also a lab-controlled database with six basic expressions. We selected the three peak pictures from each sequence. CK+ is also a lab-controlled database with seven basic expressions. As in the case of the MMI database, we chose also the three peak frames from each sequence.
Figure 7 shows part of the processed images. The first three images are the processed pictures in the MMI, and the middle three pictures are the processed pictures in the KDEF dataset, and the last three pictures are the processed images in the CK+ dataset.
Table 2 displays the number of different emotion pictures in KDEF, MMI, and CK+ datasets. In this study, we tested a total of 2570 images: 609 for the MMI dataset, 980 for the KDEF dataset, and 981 for CK+.
In order to prevent over fitting and increase prediction robustness, we conducted data augmentation to the MMI, KDEF, and CK+ datasets. Specifically, we randomly created 10 cropped images of size 224 × 224 for the original images, whose sizes were all 240 × 240. Furthermore, we also collected 10 processed images for each facial expression to test by cropping the top left corner, bottom left corner, top right corner, bottom right corner, the center, and subsequently taking the reflection of each of these cropped images. We made the final decision by taking the average results of these 10 processed images to reduce the classification error.
4.2. Experimental Settings
The experiments were used in the environment of Python 3.6.10, pytorch 1.6.0, TensorFlow 1.14.0 and an operating system of 18.04.1-Ubuntu. The proposed triple-structure network model in the experiments was run on a computer with Intel(R) Xeon(R) CPU
[email protected] in CPU and two 12G Nvidia GeForce GTX1080Ti graphics cards in GPU. In the experiments, GPUs were used to speed up the model calculation and reduce the training time. The stochastic gradient descent (SGD) method of momentum parameters in small batches was selected as the model parameter optimizer. The learning rate of the network was initially set to 0.1. Between the 150th and 225th iterations, the rate was set to 0.01. Beyond 225 iterations, we set it to 0.001. μ and λ were set to 1.5 and 20, respectively. The rest of the relevant settings are shown in
Table 3 below.
4.3. Ablation Experiments
For the sake of analysis, we performed an extensive ablation study by removing certain portions of our proposed triple-structure network model to see how that affected performance. This was carried out using the MMI, KDEF, and CK+ databases.
Our triple-structure network model is mainly composed of three branches, i.e., a global branch network (MobileNet), an attention branch network (SENet), and a diversified feature learning branch network (Div). To verify its effectiveness, we compared it with MobileNet, MobileNet+SENet, and MobileNet+Div, respectively. MobileNet stands for a global branch network. MobileNet+SENet represents the combination of the global branch network and attention mechanism branch network. Finally, MobileNet+Div denotes the combination of the global branch network and diversified feature learning branch network. Since our study is inspired by Ref. [
49], the network of [
49] was also used as a comparison. Each network was under the same setting as in
Section 4.2.
Table 4 displays the outcomes of comparative data. The recognition accuracy (%) was used for performance evaluation.
From the backbone network, MobileNet had a good recognition rate for facial expression images. In the case of the KDEF dataset, we can discover the advantages of our proposed triple-structure network model. Compared with the backbone network, the recognition rate of MobileNet+SENet was increased by nearly 1%. Because the KDEF dataset is mainly composed of images of young men and women aged 20 to 30, inter-class features have great differences. Therefore, the recognition effect was significantly improved. However, when MobileNet+Div learns intra-class features, the similarity of intra-class features was too high. Therefore, the recognition rate of MobileNet+SENet was better than that of MobileNet+Div. Our triple-structure network model combines the strengths of the MobileNet+SENet and the MobileNet+Div. Therefore, the recognition rate has been significantly improved.
In
Table 4, the recognition rate of the MMI dataset was obviously not as high as the one in the KDEF dataset. This was due to the following reasons: the age, facial shape, facial occlusions, and so on, resulting in the overall recognition effect as not as ideal as the KDFE dataset. In the MMI dataset, compared with MobileNet, the improvement of the recognition rate of MobileNet+SENet was not obvious. This was due to the huge differences in facial expression images or face occlusions. Therefore, it is difficult to have further improvement. In the MobileNet+Div, it learned a wealth of intra-class features in the MMI dataset. Thus, the learnable range of intra-class features was increased, which makes a remarkable improvement. Our triple-structure network model combines the advantages of the MobileNet+SENet and the MobileNet+Div, so the overall improvement effect was better in the MMI dataset. The feature extraction network applied in Ref. [
49] is VGG16 (with MC-loss (VGG16)). It can be discovered from the comparison of
Table 4 that Ref. [
49] has a little advantage in the KDEF dataset. This is because the facial expression differences in the KDEF dataset are small. The MMI dataset can reflect the benefits of our triple-structure network model, which shows that our triple-structure network model also has great advantages for expression images with large differences.
Since the expressions in the CK+ database have obvious characteristics and are mainly composed of young men and women, they have achieved good recognition results in the MobileNet. With the progress of learning, MobileNet+SENet had a good effect in learning the inter-class features in the CK+ database, because the distinction of the inter-class features in the CK+ database was obvious, so the learning effect was good. Ref. [
49] obtain better results in the CK+ database, but its effect is not so obvious compared with our network. Note that our network learns from multiple aspects, but Ref. [
49] randomly throws away some inter-class features, resulting in its recognition effect being not as good as our network.
4.4. Comparison with Other Methods
Table 5 displays the performance comparisons with the same approaches. To summarize, our triple-structure network model obtained competitive results on KDEF.
Ref. [
10] uses the traditional PCA method to extract features and employs ELM for classification, because the feature information extracted by CNN is richer than PCA. Therefore, the recognition rate of [
10] is lower than that of our triple-structure network model. Ref. [
11] makes use of LBP and Gabor filtering methods to extract features. Due to the limitations of traditional feature extraction methods, its recognition rate is not as high as our triple-structure network model. Ref. [
12] learns the possible locations of expression regions in many images, but the expression regions vary widely across datasets. Recognized cross-image datasets tend to lead to more recognition errors and use traditional feature extraction methods, which is not an ideal result.
The muscle models proposed in Ref. [
25] are segmented, the key region features are fused, and a penalty loss function is added simultaneously. These methods can enhance the expression recognition rate. However, there is also a gap compared to the global-to-local loss function in our triple-structure network model. Ref. [
54] utilizes the FER network to effectively identify FER with the help of the softmax classifier. Since only a single network is used and there is no multi-angle learning, the recognition accuracy of the network of [
54] is not so high as that of our triple-structure network model.
Table 5.
The recognition accuracy (%) of the related methods in the KDEF datset.
Table 5.
The recognition accuracy (%) of the related methods in the KDEF datset.
| Methods | KDEF |
|---|
| HE+DeepPCA+ELM [10] | 83.00 |
| QIBGSA [11] | 92.35 |
| Ref. [12] | 86.84 |
| RCFN [25] | 91.60 |
| FER-net [54] | 83.00 |
| Our network model | 96.53 |
Table 6 shows the performance comparisons with the same approaches. To summarize, our triple-structure network models obtained competitive results from the MMI datasets.
Ref. [
38] shows good advantages but did not involve regional learning. Single global learning leads to a low recognition rate. By comparison, our triple-structure network model is more ideal. Ref. [
55] proposes an expectation maximization algorithm that estimates emotion labels. This reveals those facial expressions of the real world that often express complex or even mixed emotions, and multi-label facial expressions often lead to false recognition in learning and result in low classification accuracy. Ref. [
56] employs de-expression residual learning (DeRL) to extract the information about expression components to recognize facial expressions. Since neutral expressions are generated in the generative model, it will inevitably result in the deformation of some expressions. Thus, the recognition rate is not as good as that of our triple-structure network model which used the original images directly. Ref. [
57] learns the spatial features and temporal dynamics of FER, but the corresponding temporal and spatial dynamics learning results in many learning features, which are causing redundancy. Overall, our triple-structure network model performs the best.
Table 7 shows the performance comparisons with the same approaches. To summarize, our triple-structure network model obtained competitive results on the CK+ datasets.
Ref. [
58] proposed a multi-feature-based MLP (MF-MLP) classifier which is focused on the facial appearance detection problem. MF-MLP used LBP to extract features, but traditional feature extraction methods have some limitations. Therefore, the performance of our network is better than that of MF-MLP. Ref. [
59] presented a smile classification method which is based on an association of row transform-based feature extraction algorithm and ensemble classifier. The methods lacks global features, so the effect is not as good as that of our network. Ref. [
60] used the LDA and PCA to decrease the dimensions of the face images and maintain the most important features. The effective information extracted by LDA and PCA is not as comprehensive and robust as CNN, and the experimental effect is slightly worse than our network. Ref. [
61] used the VGG16 model for a modified trained model and attaches additional layers on it. However, the model lacks local information, and so our network has a certain advantage. Ref. [
62] leveraged spectral graph wavelet transform to extract information. Mobile V1 can automatically find key feature information, while spectral graph wavelet transform can only be used to extract information (containing redundant information). Therefore, our network performs better than spectral graph wavelet transform.
In [
10,
11,
12,
58,
60], they all used the traditional feature extraction methods. Due to the traditional methods having their limitations in feature extraction, their recognition rate is not as high as that of our triple-structure network model. This again verifies that the traditional feature extraction method does have certain limitations for the feature information extraction of images. Comparing the results of the method in this paper with [
25,
38,
54,
59,
61], it can be concluded that single local or global learning is not as good as joint local and global learning. The images used in Refs. [
55,
56] contain multiple expressions, extracting many redundant features, resulting in a low recognition rate.
According to the experimental results and analyses, the proposed triple-structure network model is more competitive than other methods.
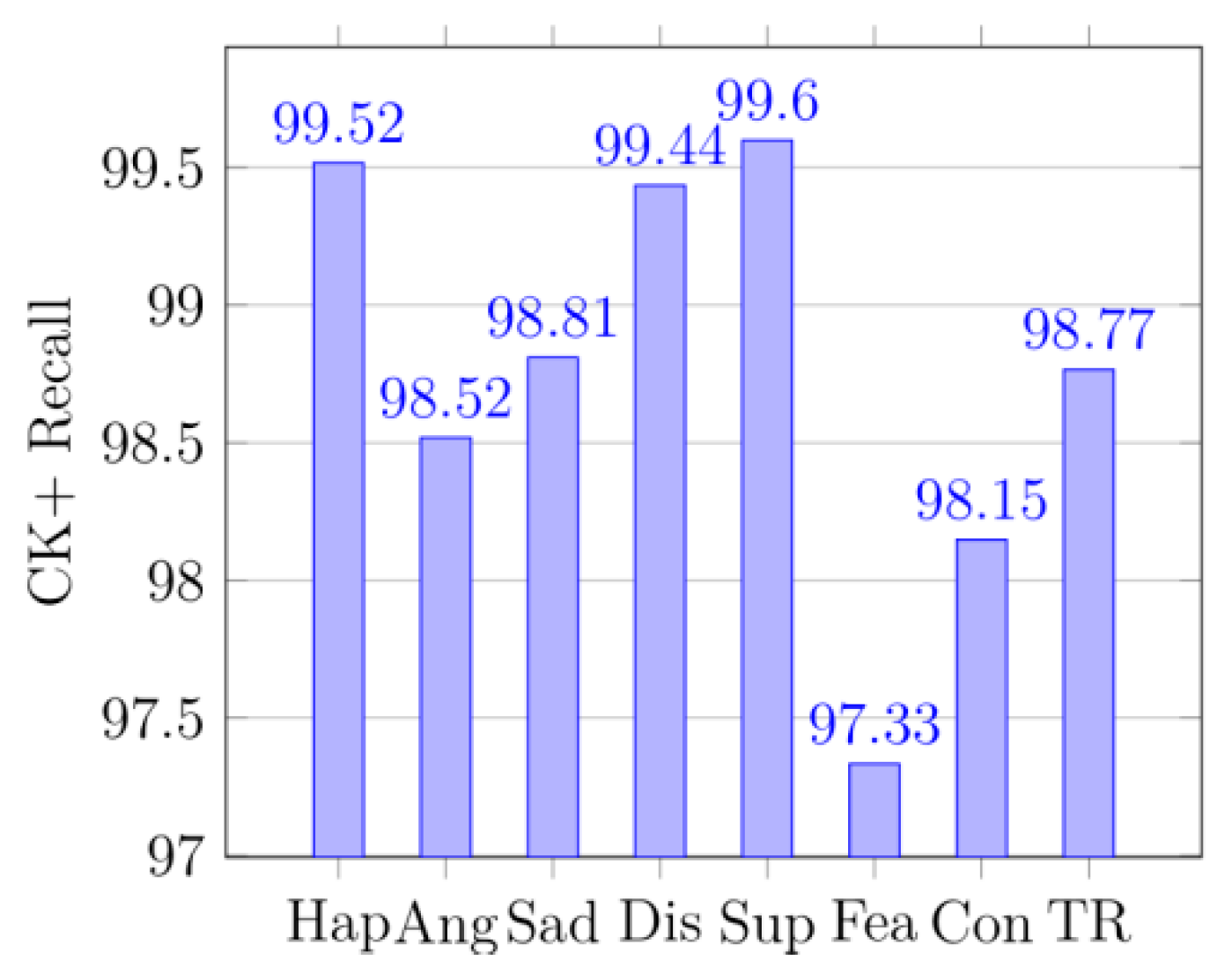
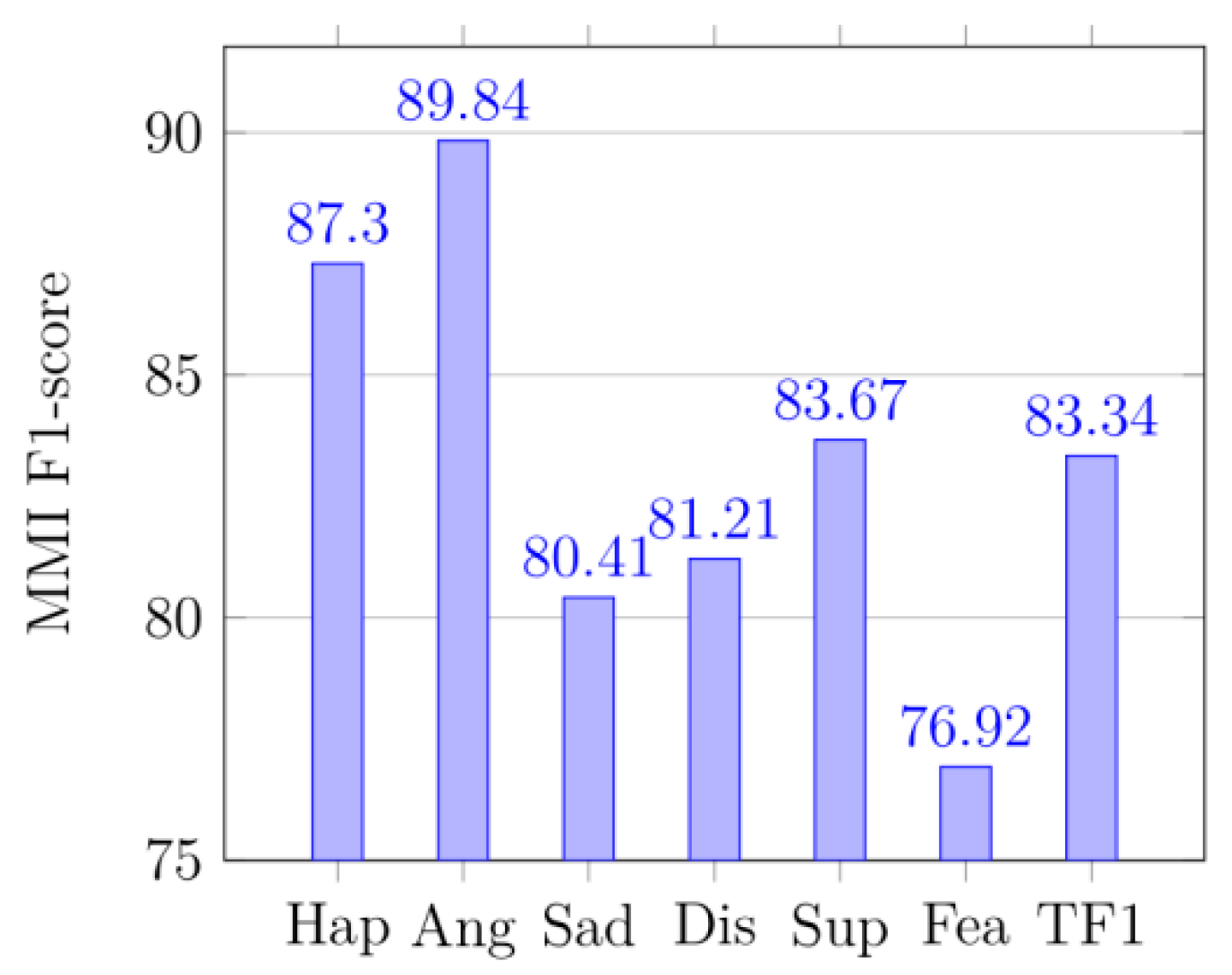
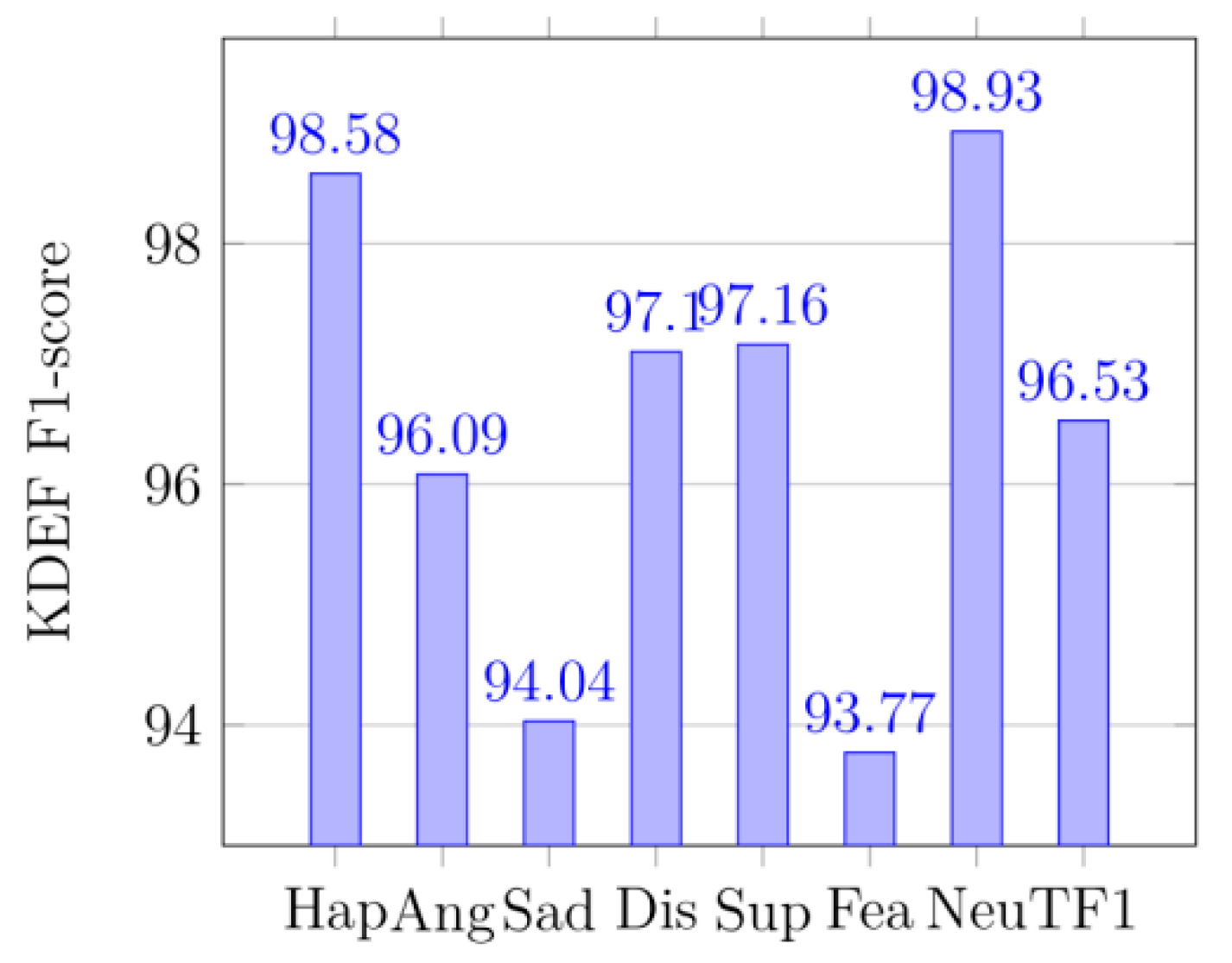
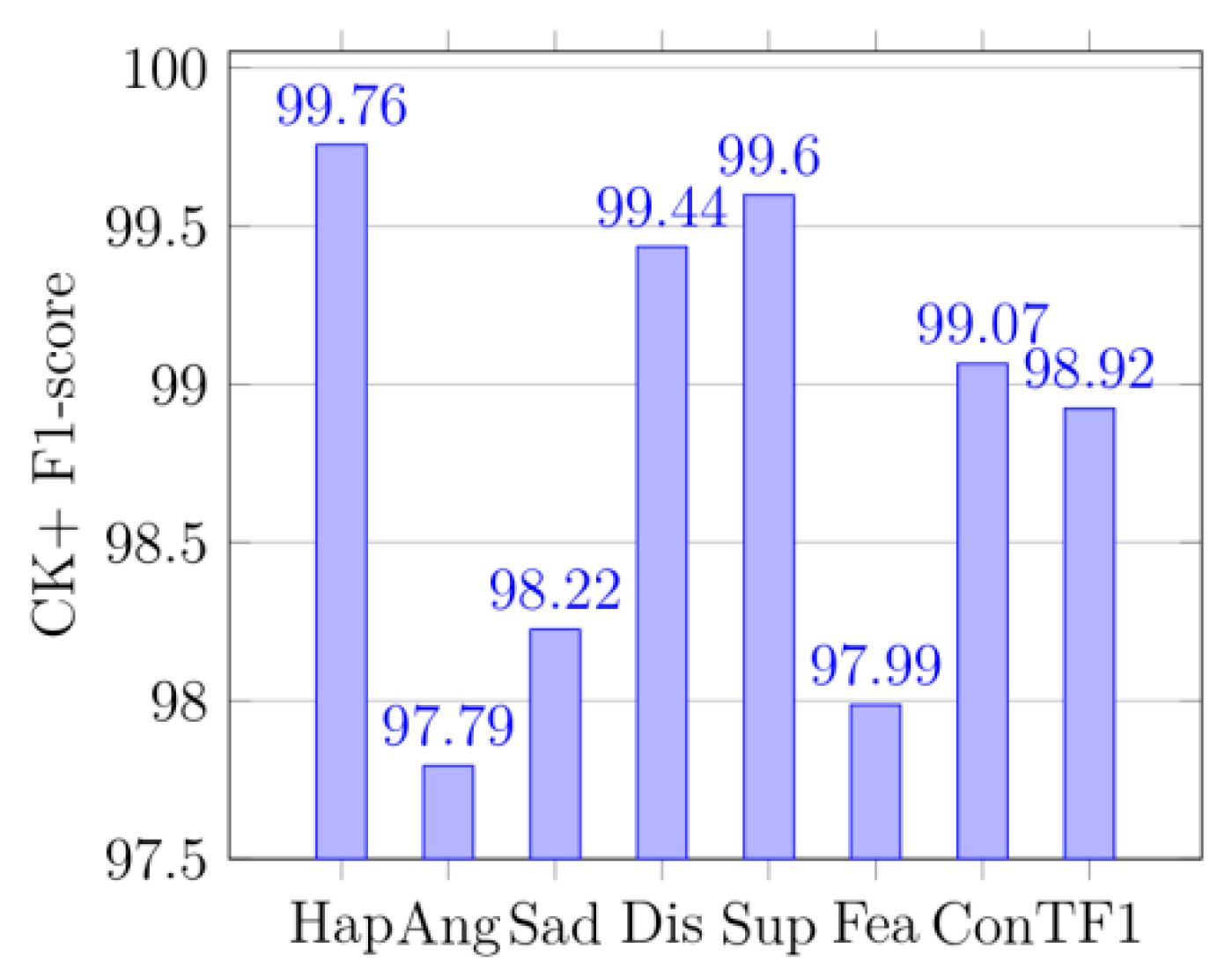
4.5. Confusion Matrices and the Classification Report
In
Figure 8,
Figure 9,
Figure 10,
Figure 11,
Figure 12,
Figure 13,
Figure 14,
Figure 15,
Figure 16,
Figure 17,
Figure 18 and
Figure 19, Hap represents happy, Ang is anger, and Sad stands for sad. Dis means disgust, Sup is surprise, and Fea denotes fear. Neu means neutral and Con is contempt. The precision is the proportion of correctly predicted data in each class to all data of that class. The recall rate (recall) reflects the proportion of correctly predicted data in each class to all data predicted to be of that class. F1 reflects the performance of the model by combining the two indicators of precision and recall, as shown below:
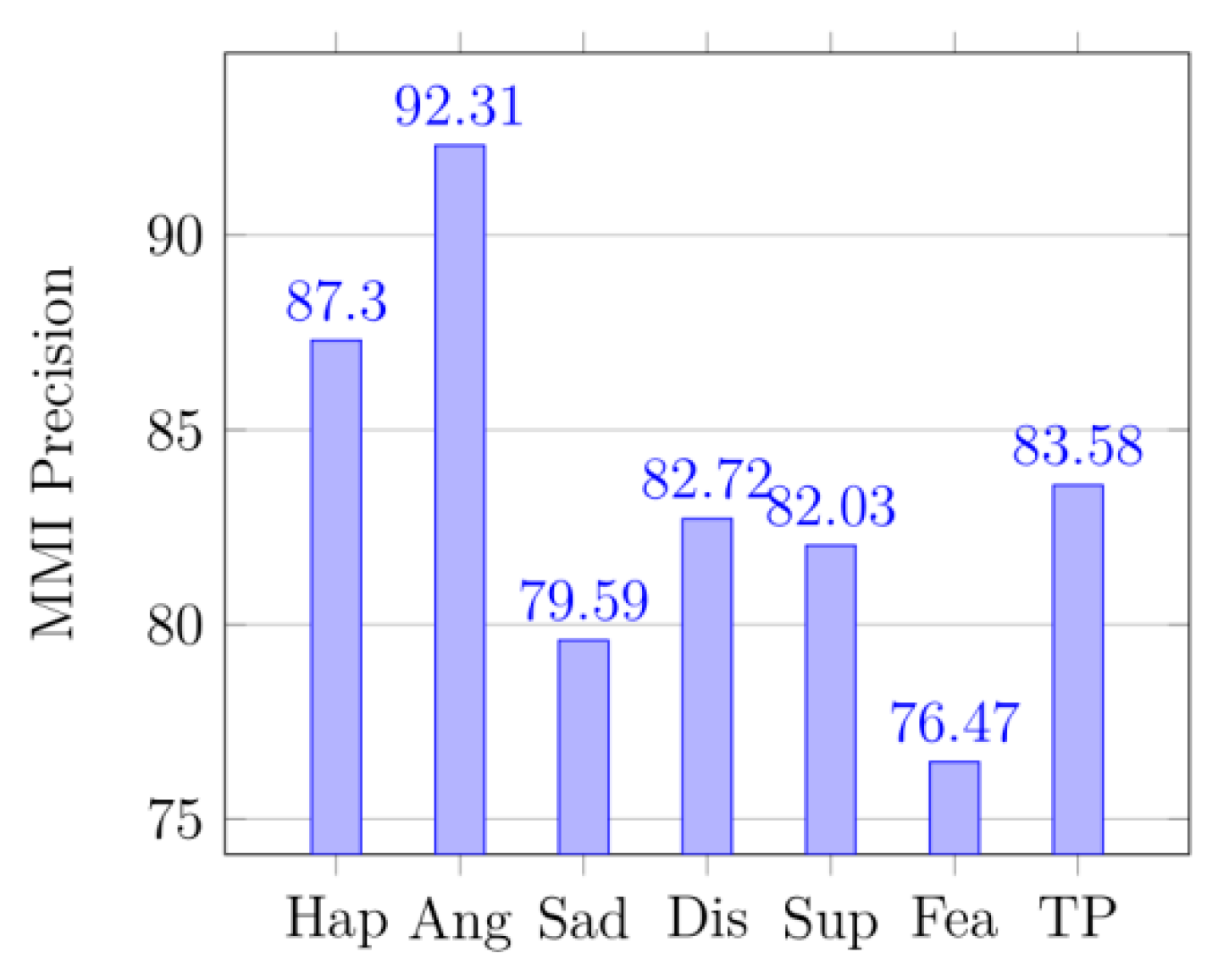
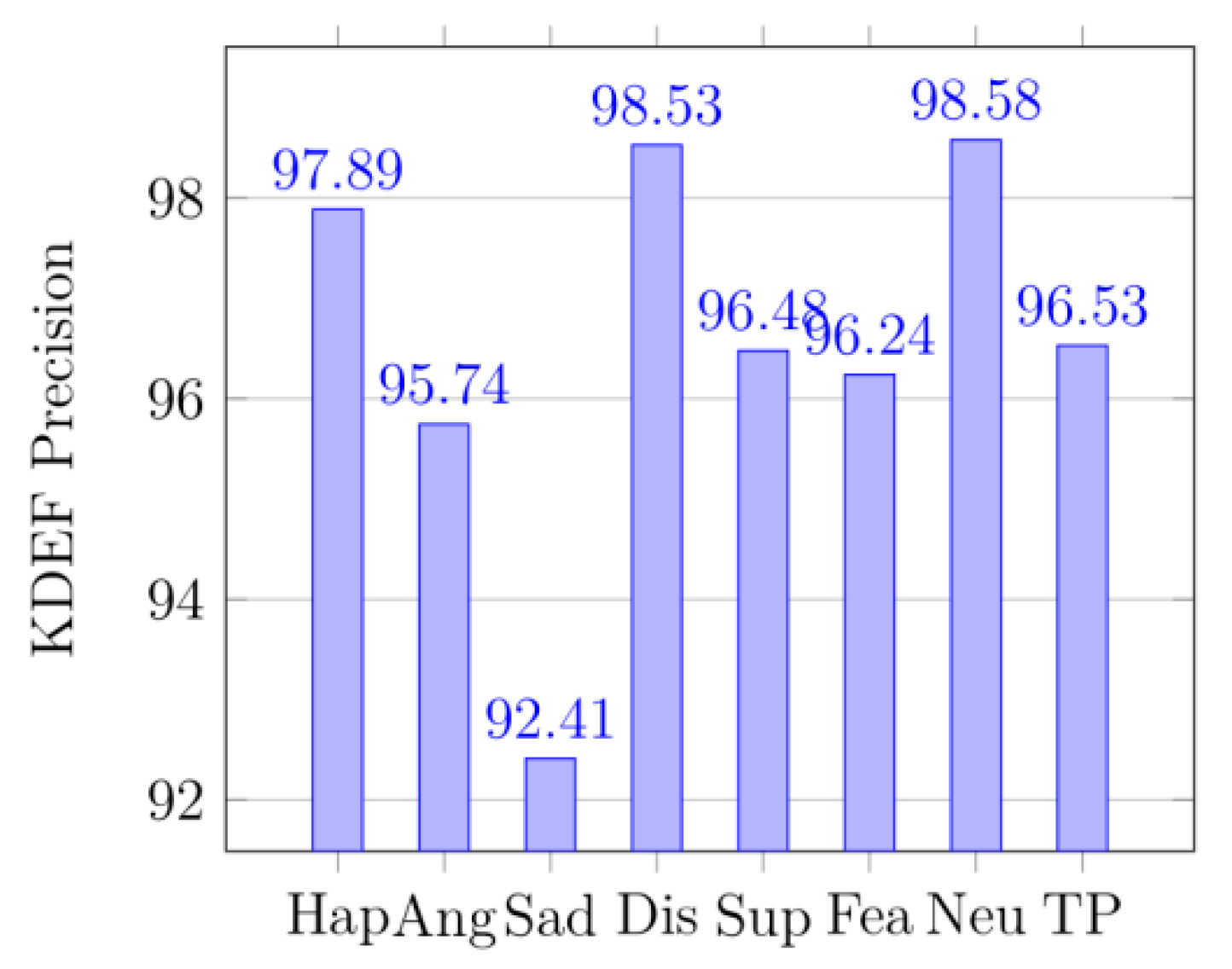
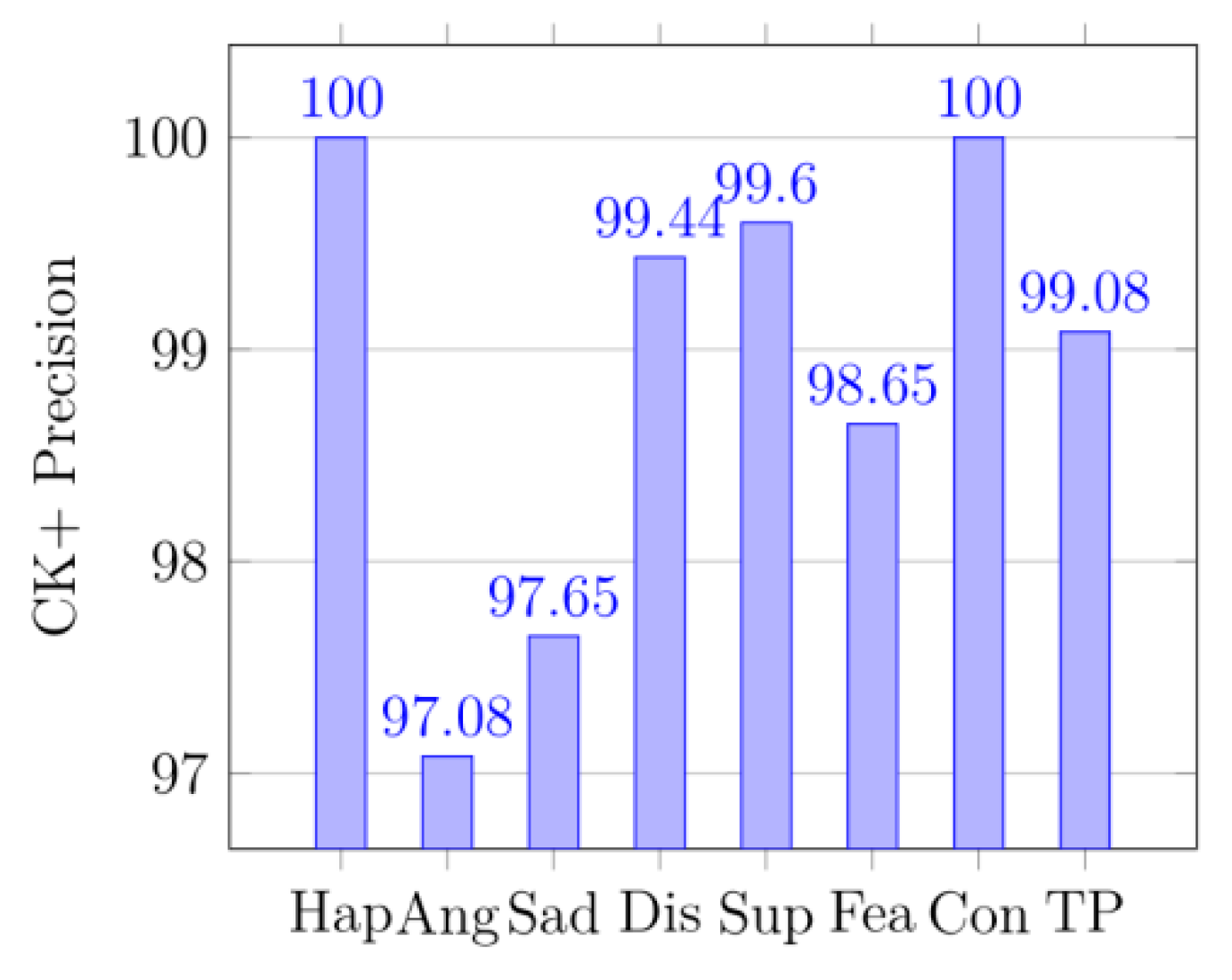
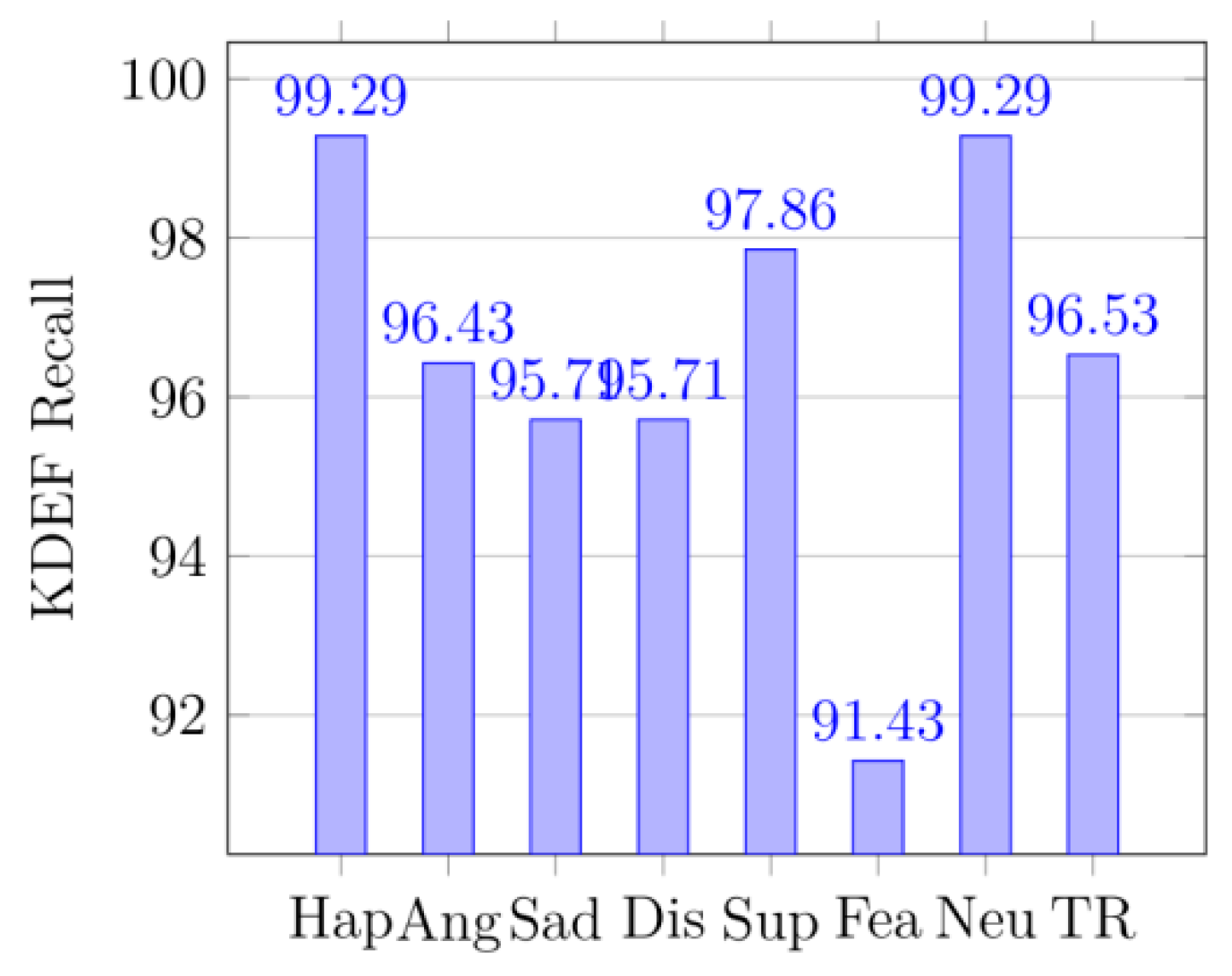
In (17), P represents precision and R is recall. TR is total recall, and TP is total precision, and TF1 is total F1-score.
In the task, four popularly used evaluation metrics, namely, accuracy, precision, recall, and F1-score [
63,
64,
65,
66], were deliberated in the research to contrast the performance of our network to 21 models. However, the values of all the metrics were computed from the confusion matrix. Confusion matrices can compute the values of metrics, which were employed further to dissect the function of our network.
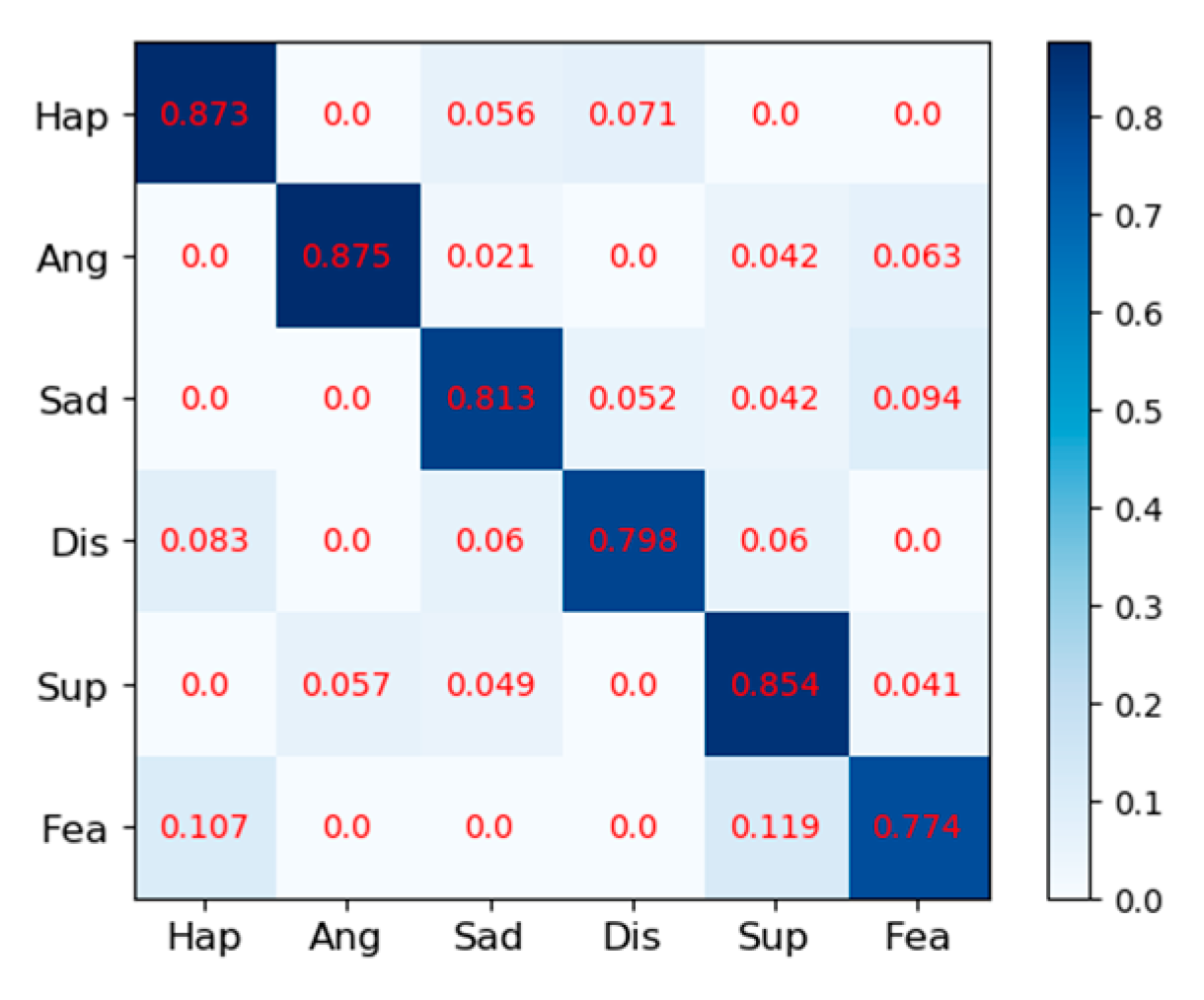
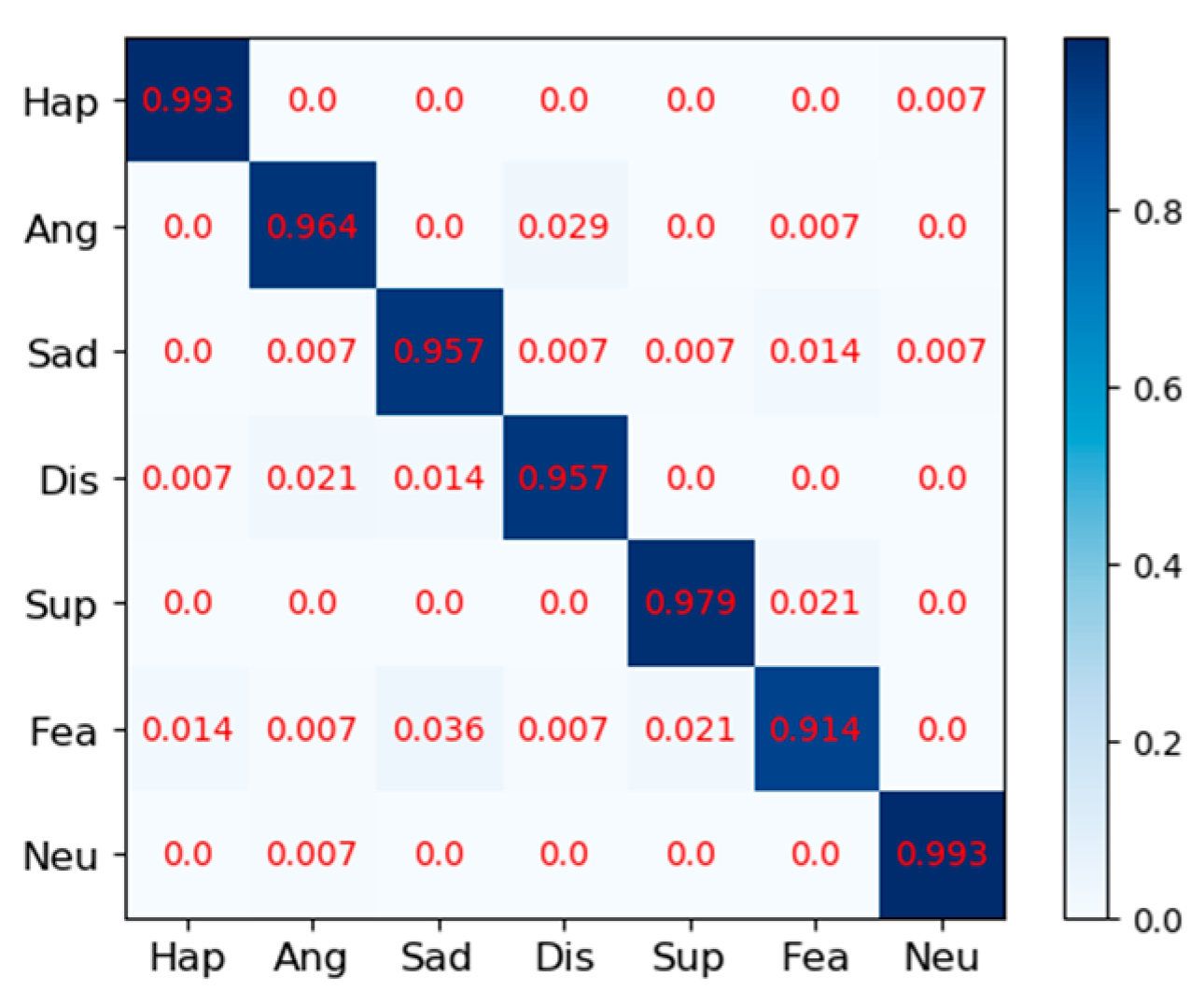
Figure 12 displays the confusion matrix of the KDEF dataset. The size of the confusion matrix is seven by seven as seven facial expressions were premeditated for this research. The confusion matrices for MMI datasets are shown in
Figure 8, and their produced metrics are displayed in
Figure 11,
Figure 14, and
Figure 17. The confusion matrices in
Figure 9 are displayed for KDEF datasets, and their generated metrics are reported in
Figure 12,
Figure 15, and
Figure 18. Similarly, the confusion matrices for CK+ datasets are shown in
Figure 10, and their produced metrics are reported in
Figure 13,
Figure 16, and
Figure 19.
From the precision, it can be seen that the method in the paper does have a significant effect on identifying the probability of being classified as correct, especially in
Figure 12 and
Figure 13 (KDEF and CK+). From the recall, it can be seen that the proportion of the correctly predicted data in each category is still quite high, especially in
Figure 15 and
Figure 16 (KDEF and CK+).
F1 takes into account the precision and recall rate. F1 can be seen on the CK+ and KDEF dataset, which show a good performance in
Figure 18 and
Figure 19. It may be that the MMI dataset contains some occluded images, which leads to its poor performance in precision, recall, and F1. However, compared with other methods in terms of recognition accuracy, our network still has a great advantage as shown in
Table 6.
It is clear from
Figure 8,
Figure 9,
Figure 10,
Figure 11,
Figure 12,
Figure 13,
Figure 14,
Figure 15,
Figure 16,
Figure 17,
Figure 18 and
Figure 19 that the proposed network brings good classification accuracy along with other metrics for KDEF, MMI, and CK+ datasets in almost all the instances. An exhaustive review of these methods is outside the range of our research, and that can be mentioned to [
16,
17,
18,
29,
30,
31,
32,
33,
34,
35,
36]. It is clear from
Table 8 that Ref. [
35] gives good outcomes for the KDEF dataset and AlexNet gives good results for the CK+ data only. However, our recognition rate is completely beyond Broad learning and AlexNet. We can summarize that our network is effective, but it shows the right prediction accuracy in more instances compared to 21 models.
4.6. Performance Comparison of Execution Time
In comparison, we provide comparative results against 21 state-of-the-art algorithms, for example, HOG-TOP [
15], SCNN [
28], MCNN [
28], SCNN-LBP [
16], SCNN-gray [
16], P-VGG16 [
16], WMDC [
16], WFTS [
29], ACNN-LBP [
17], Fusion(ACNN-LBP+GF) [
17], STF+LSTM [
18], DCNN-BC [
31], IACNN [
32], 2B(N+M) Softmax [
33], CF+GT [
34], Broad learning [
35], Deep emotion [
36], VGG19 [
37]-1, and ResNet150 [
37]-2, on two datasets. However, the contrast is limited to average recognition accuracy only. Some methods in
Table 9 were executed on videos. Rare works premeditated a fewer number of classes.
Table 9 shows the average classification accuracy obtained by the above mentioned 21 methods. It is obvious from
Table 9 that our network conquers the twenty-one above models on CK+ and KDEF, and it occurs due to the use of a triple-structure network model. However, the above models are still contrasted according to training and testing time. The training time of a model usually relies on the size of the network, size of the input images, and so on. In the research, the above models were used in the light of their respective specifications. We used tenfold cross validation and 300 epochs when training our network on KDEF and CK+ datasets. The training and testing times required by the above 22 models, including our network on the two databases, are displayed in
Table 9. However, testing time for onefold cross validation is noted only in
Table 9. Testing time per image (TTPI) is the same for all the images of a database as their size is equal. IACNN takes about 700 min to train KDEF and about 633 min to train CK+, which is quite large. While the proposed method processes an image in 0.278 s, our method is still quite dominant in terms of accuracy.
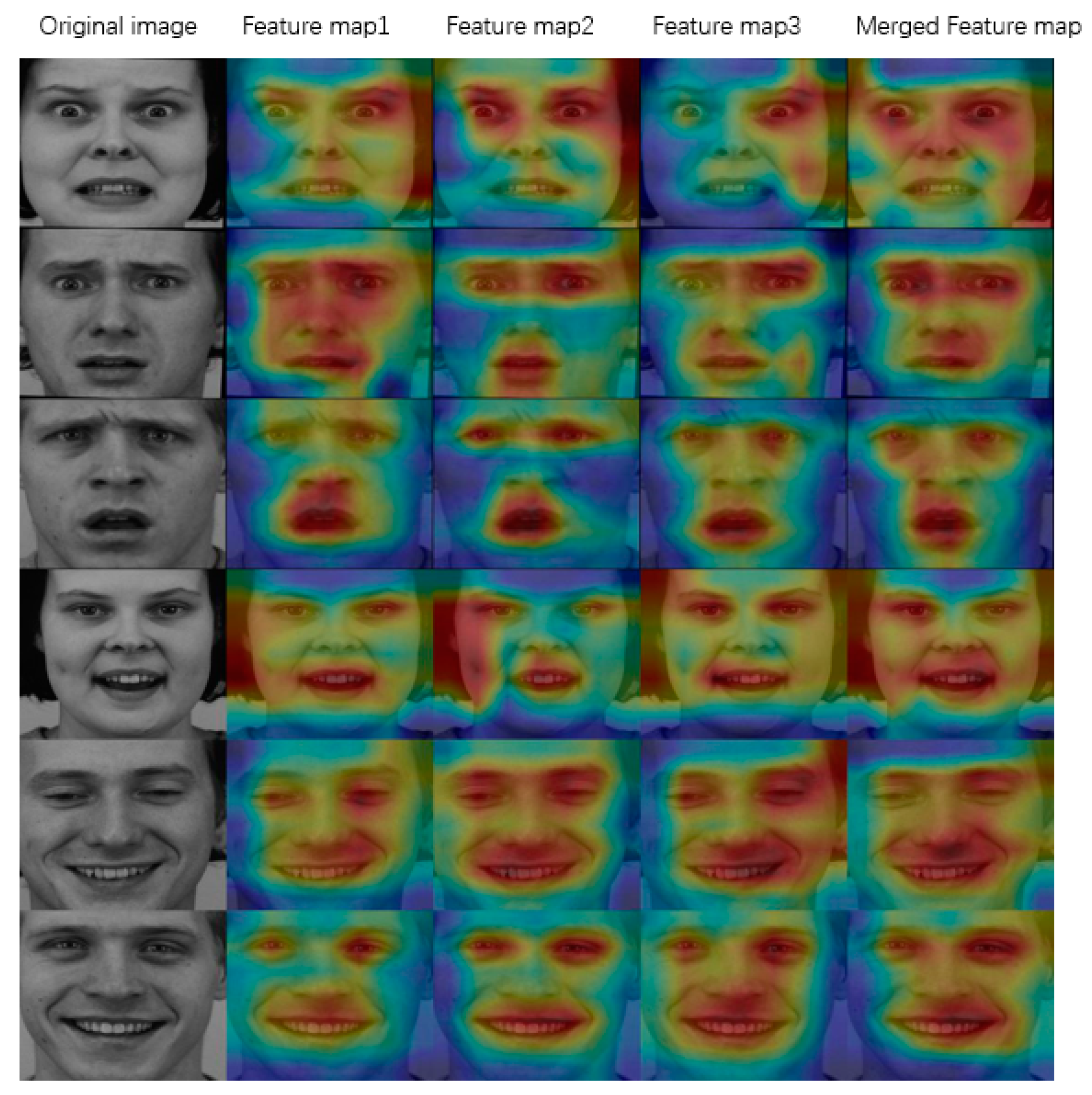
5. Visualization for the Triple-Structure Network Model
To further confirm the effectiveness of the proposed triple-structure network model, a class activation map visualization [
67] was performed on each branch of the model. A feature map formed by weighted overlapping of feature atlases can demonstrate the importance of each location to its classification. The first column in
Figure 20,
Figure 21 and
Figure 22 are the original images. The second column is the feature channel map (Feature map1) extracted by the global branch network (MobileNet). The third column is the feature channel map (Feature map2) extracted by MobileNet+SENet. The fourth column is the feature channel map (Feature map3) extracted by MobileNet+Div. Finally, the fifth column is the Merged Feature map extracted by our triple-structure network model.
The first three rows of
Figure 20 are angry, and the last three rows reflect happiness. The first three rows of
Figure 21 are fear, and the last three rows correspond to happiness. The first three rows of
Figure 22 are sad, and the last three rows reflect happiness. The second column of
Figure 20,
Figure 21 and
Figure 22 shows that the global branch network can learn globally about images. In the third column, attention mechanism learning is stressed. In addition, the key learning area of the image is enhanced. The fourth column emphasizes the diverse intra-class, which shows that the learning is performed for multiple regions of the image. The fifth column combines the above advantages for more in-depth learning. The first three rows and the last three rows of
Figure 20 are, respectively, angry and happiness, which belongs to an inter-class relationship. It can be observed from
Figure 20 that the learning focus on the two types of expressions is different. The key learning area of the angry expression image is around the eyes. The learning area of the expression image is concentrated on the mouth for happiness. This discovery emphasizes the concentration of learning different areas of inter-classes. As for
Figure 21, the focus on fear is the eyes and mouth, and the focus on happiness is around the mouth. As for
Figure 22, the focus on sad is the eyebrows and mouth, and the focus on happiness is around the mouth.
The expressions for the first three rows in
Figure 20,
Figure 21 and
Figure 22 are, respectively, angry, fear, and sad. The three are similar in that they focus more on the area around the eyes. Meanwhile, the fear learning has an additional learning towards the area around the mouth and sad has an additional learning towards the area around the eyebrows. The expressions for the last three rows of
Figure 20,
Figure 21 and
Figure 22 are happiness. This process is focused on the learning of intra-class features. In addition to the mouth, there is also learning around the eyes, which emphasizes the learning of the diversity of intra-class features.
6. Conclusions
We proposed a symmetric mode to extract the inter-class features and intra-class diversity features, and then put forward a triple-structure network model, which is trained by a new multi-branch loss function. Such a triple-structure network model comprises a global branch network, an attention mechanism branch network, and a diversified feature learning branch network. Our research consists of the below aspects:
- (1)
We slightly looked back at the previous related works about MobileNet V1 and SENet. Moreover, we highlighted their merits and achievements, which also favors our research idea.
- (2)
A triple-structure network model was presented. The global branch network focuses on learning global features, the attention branch network concentrates on learning inter-class features, and lastly the diverse feature learning branch network focuses on learning the diversity of intra-class features. Then, the judgment process of the network model comprehensively utilizes global features, inter-class features, and intra-class features. It not only can focus on the overall structure, but also can capture the diverse intra-class and the difference inter-class with a symmetric mode.
- (3)
Finally, experiments were performed on the KDEF, MMI, and CK+ datasets in which the classification accuracy reached 96.530%, 83.559%, and 99.042%, respectively. Through ablation experiments and visualization, the intrinsic mechanism of our triple-structure network model was proved to be very reasonable. Moreover, experiments on MMI, KDEF, and CK+ databases demonstrated that our proposed triple-structure network model performs better than dozens of state-of-the-art methods from [
10,
49], HE+DeepPCA+ELM [
11], QIBGSA [
12,
25], RCFN [
38,
54], FMN [
55], DLP+CNN [
56], DeRL [
57,
58], MF-MLP [
60], and HAAR+LDA+IBH-based ELM [
61,
62].
Based on the experimental results and analyses in
Section 4.3 and
Section 4.4, the proposed network is more competitive than other methods. However, there are still some limitations. For example, our network can only process images, not text and speech. With the development of modern society, the combination of video, voice, and text has been integrated into our world, which shows the limitations of our network.
Although our network applies multiple branches to learn with different focuses, the actual learning is to extract important features of the image to achieve a good recognition rate. However, multi-branch learning can achieve the learning of important features, and it also brings repeated learning and repeated iterations, which results in a waste of computing resources. A key direction we should study is how to propose a network to achieve focused learning of image features, thereby reducing the pressure on computing resources, and enabling better application in practice.
As a next step, we plan to propose a network to achieve focused learning of image features with a reduction on the pressure of computing resources. In the future, it is worthy to research how to construct an expression analysis model with more powerful generalization ability. In addition, we will consider utilizing orthogonal polynomials [
68] as a feature extraction tool for facial recognition, which may provide important help in improving the recognition rate.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





















