1. Introduction
Most control problems of interest in engineering and applied sciences concern positioning, path planning and obstacles avoidance. A noteworthy example is given by the need of commanding a spacecraft in such a way that it avoids bright objects yet maintaining communication with ground station, as discussed in [
1]. Further noteworthy examples are found in landing maneuvering of manned electric vehicles [
2], interception of mobile search vehicles [
3], and manual guidance of robotic manipulators [
4]. Virtual potentials prove effective in solving non-linear control problems as they appear to be versatile and widely applicable. In order to control a particular dynamical system, it is necessary to build a virtual potential field. Such construction may be effected within a number of mathematical frameworks. For instance, a virtual potential field may be constructed by the use of harmonic functions and Laplace’s equations [
5,
6], artificial gyroscopic forces [
7] and stream functions from fluid dynamics [
8].
The study of potential fields took originally its moves from physics, chemistry and biology [
9] although its versatility makes it advantageous in several different fields such as vehicle coordination [
10]. In fact, potential fields have been widely used to control different types of vehicles such as cylindrical robots [
11], helicopters [
12], road vehicles [
13] and unmanned ground vehicles [
14].
A special acknowledgment should be paid to Koditschek and Rimon who, in a series of papers, laid the foundation of the VARP theory. In particular, in the contribution [
15], the authors proposed “a methodology for exact robot motion planning and control that unifies the purely kinematic path planning problem with the lower level feedback controller design”. The innovative aspect of their work was to encode complete information about a freespace and goal in the form of a special virtual potential function, termed
navigation function. Such navigation function gives rise to a feedback controller for the robot that guarantees collision-free motion and convergence to the destination. The authors of [
15] developed a family of navigation functions that serve to guide a point-mass robot through a generalized sphere world. The simplest member of such family of navigation functions is obtained by puncturing a disk by an arbitrary number of smaller disjoint disks that represent obstacles. More complex spaces (and obstacles) are obtained from this model by suitable coordinate transformations. The study [
15] was essentially devoted to planar scenarios and appears as an application of more general results presented earlier in [
16], where the general problem of constructing navigation functions on arbitrary manifolds (not only those obtainable as deformations of sphere words) was dealt with.
Over the years, potential fields have been applied to constrained attitude control, as they enable to handle simultaneously a large number of forbidden and mandatory zones, while guaranteeing computational tractability and convergence [
17]. Potential fields have also been applied to slew maneuver of satellites; see, e.g., the paper [
18] that introduced a ‘Sun avoidance potential’. The manuscript [
19] introduced the notion of exponential repulsive potential whose gradient returns a protection control field to prevent aircraft accidents. The contribution [
20] utilizes virtual potential functions to generate trajectories to be used as initial guesses for a ‘general pseudospectral optimal control’ algorithm. The research work published in [
21] presents a real-time hybrid guidance method which fuses the flexibility and robustness of harmonic potential functions with a rapidly-expanding random-tree method; such research outcome allows to plan near-fuel-optimal trajectories on cluttered environments. The paper [
22] outlines a method based on the theory of virtual potential fields combined with sliding mode control for spacecraft maneuvers in the presence of obstacles; guidance and control algorithms devised in such manner were validated through a six degree-of-freedom omorbital simulator. Guidance algorithms based on artificial potential functions play an increasingly important role in hazard avoidance, although local minima might cause a spacecraft to be unable to reach the desired target landing point in complex terrains. In the paper [
23], a novel hazard avoidance guidance method was developed by improving the traditional virtual potential function structure.
Potential fields may also be utilized in conjunction with other control strategies. For example, Cao et al. [
24] suggested using potential fields in order to adjust the path planned by a neural network in such a way that an autonomous underwater vehicle avoids obstacles. Baxter et al. [
25] developed a control method based on the exchange of information regarding potential fields between robots belonging to the same local group of vehicles. Huang [
26] proposed a path and speed planning strategy based on the use of a potential field for a robot located in a dynamic environment where obstacles and targets are moving.
Potential function-based proportional-derivative as well as augmented-proportional-derivative control laws were developed in [
27] to govern the motion of an underactuated autonomous underwater vehicle in an obstacle-rich environment; for obstacle avoidance, a mathematical potential function was devised, which formulates the repulsive force between the vehicle and the solid obstacles intersecting a vehicle’s desired path. The guidance and control framework proposed in [
28] integrates offline optimal path planning with a safety distance constrained A* algorithm, and an online extended adaptively-weighted virtual potential field-based path following approach with dynamic collision avoidance, based on unmanned surface vehicles maneuvering response times. An adaptive potential function approach originally developed for ground robots was modified in [
29] and employed as a guidance law for a class of rotary-wing unmanned aerial vehicles that must also avoid obstacles located in a three-dimensional workspace.
The use of potential fields has been extensively studied and some alternatives have been proposed to overcome those difficulties that it might entail. An often encountered difficulty is that a local minimum in the potential field might trap a controlled vehicle and consequently prevent it from reaching the global minimum, which represents the actual goal. Lee et al. [
30] proposed a solution to such problem based on the placement of a virtual repulsive obstacle in a local minimum to keep a robot adequately distant from it. A further solution to the aforementioned problem is to invoke hybrid strategies based on virtual potentials and BUG algorithms [
31,
32,
33,
34,
35], as proposed by Wang et al. [
36]. A further common difficulty to be aware of in the use of potential fields is the oscillation of the controlled vehicle around obstacles and targets. Several proposals have been presented to address such problem. Ren et al. [
37] proposed the use of a modified Newton’s method (MNM) for robot navigation based on an approximation of a potential field function, which is often a complicated non-linear function, by a quadratic form. Li et al. [
38] presented a regression search method, based on an improved artificial potential field, capable of mitigating local minima as well as oscillations. Such solution consists in redefining potential functions in order to delete local minima and in utilizing virtual local targets for a robot to escape oscillations. Regression search was then used to optimize the path followed by a vehicle.
On the basis of the consistent literature accumulated on this subject, the authors of [
39] proposed a workable feedback control theory, termed VARP (that stands for virtual attractive-repulsive potentials) that they applied to drive a simple robotic platform (named ‘Kelly robot’). The control algorithm developed by the authors Nguyen, Chuang, Tung, Hsieh, Jin, Shi, Marthaler, Bertozzi and Murray was proven effective through experiments conducted at the Caltech University’s multi-vehicle wireless testbed facility. One of the main ideas developed in the paper [
39] was to endow each element in the environment, including the controlled robot as well as obstacles and targets, by both an attractive and a repulsive potential to improve maneuverability and control flexibility.
Since such VARP control theory was specifically designed to control a simple robotic platform with three degrees of freedom (two positional coordinates and an orientation angle), it cannot be extended directly to more complicated dynamical systems such as a six degree-of-freedom drone. The aim of the present paper is to design an artificial control field based on the virtual attractive-repulsive potentials to be applied to a wide class of dynamical systems. In fact, in the present paper, a VARP-based method will be developed to control different dynamical systems whose state-space equations insist on different mathematical spaces. In particular, manifold-type state spaces shall be dealt with, which present a high degree of symmetry, due to mutual non-linear constraints that single physical descriptive variables are subjected to. In order to formulate a VARP-on-manifold control theory, a special branch of mathematics will be accessed, namely
manifold calculus. In addition, in order to implement the devised VARP-on-manifold control theory on a computing platform, specific numerical algorithms have been developed, which are based on manifold calculus. As a reference on coordinate-free (embedded) manifold calculus in system theory and control, interested readers might consult the tutorial paper [
40].
The present document is organized as follows.
Section 2 describes the theory of virtual attractive-repulsive potentials as introduced in [
9,
39]. The aim of this section is to recall the main concepts related to the VARP theory and its main theoretical features.
Section 3 presents a description of a prototypical wheeled robot, used at the Caltech University for testing the devised VARP principle. This section also explains how to implement the VARP control method on a computation platform in order to evaluate numerically its effectiveness in controlling a small robot. In particular, in this section, results of numerical experiments obtained by varying the parameters of the VARP method will be presented and discussed, in order to illustrate its features. The numerical experiments were performed on purpose by a low-precision numerical scheme (the forward Euler method) to recap this method that will be extended to manifold in the following section. The analysis presented in this section is propaedeutic to the following development as the understanding of details concerning the application of the VARP control theory to drive a small robot will be beneficial in extending the VARP theory to control more complicated systems whose state evolves on smooth manifolds.
Section 4 recalls generalities of Riemannian manifolds and recaps the theory of second-order dynamical system whose state equations are formulated on the tangent bundle of a manifold. This section then illustrates how the VARP method can be extended in order to control a dynamical system whose state equations are formulated on a Riemannian manifold (M-VARP). As a case-study, the M-VARP method will be illustrated on the manifold
(a three-dimensional unit sphere). The numerical algorithms to implement such control scheme will be shown to arise from a specifically-tailored version of a forward Euler method on manifolds.
Section 5 completes the present document, focusing on conclusions and future works.
3. VARP Control Theory Applied to a Wheeled Robot Navigation on a Plane
In the present section, we shall recall how the VARP control theory was exploited to control a small self-driven wheeled vehicle termed ‘Kelly robot’. Full mathematical details are reported and commented, since these details are deemed interesting to understand the meaning of each terms in Equation (
3) in view of a successive extension of the plain VARP theory to Riemannian manifolds.
3.1. Kelly Robot Description and Mathematical Model
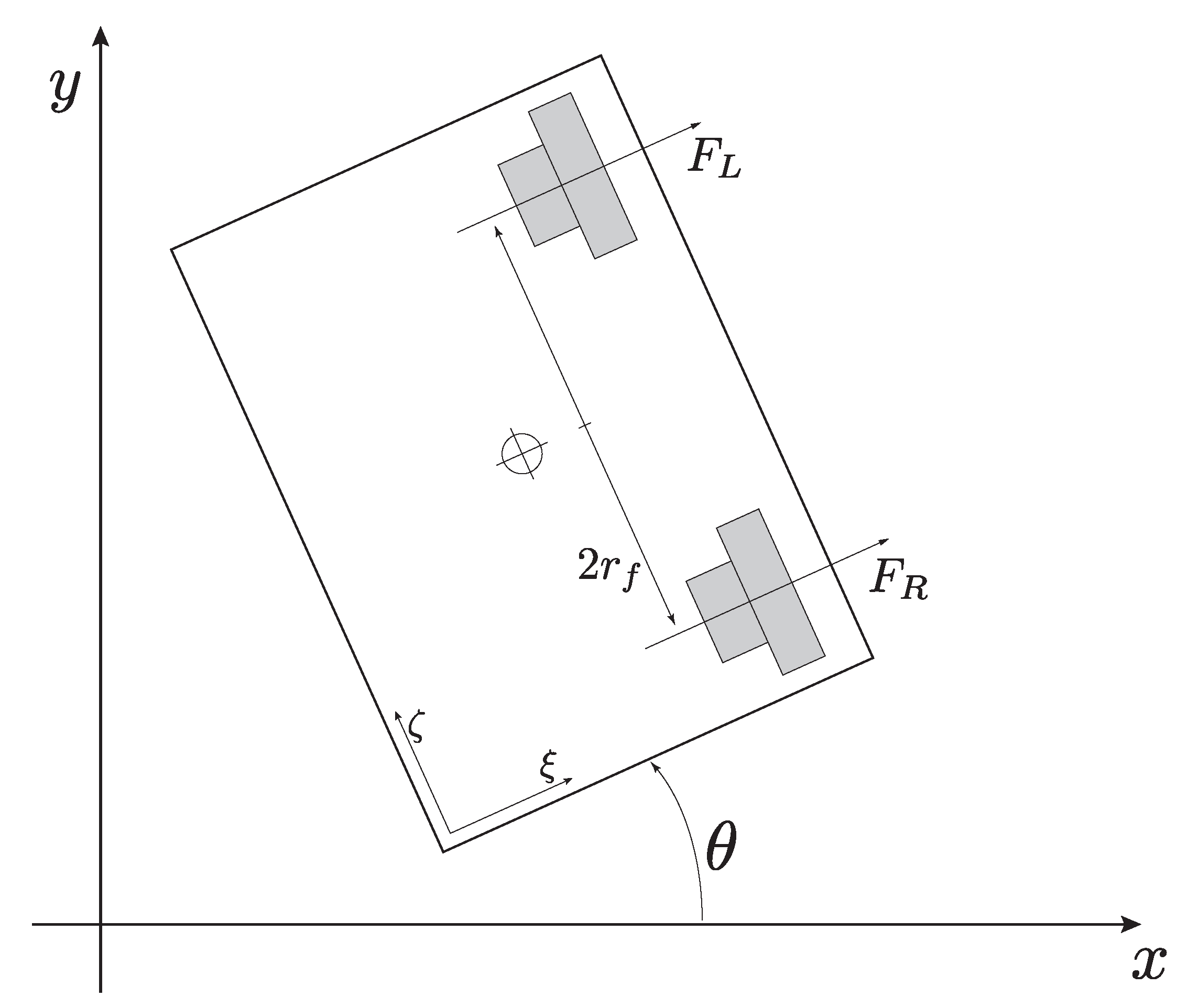
The Kelly robot was developed at the Caltech University and it was taken as a prototypical model for testing the VARP feedback control principle. Such robot was realized as a fiberglass structure that includes an onboard micro-controller (that implements the algorithm for movement control), onboard sensors and a 802.11b wireless card through which it may communicate. Further interesting characteristics are low-friction omnidirectional casters (which allow the Kelly robot to move over the floor) and two high-performance ducted fans, each capable of producing up to N of continuous thrust. Caltech tests have been conducted at the Multi-Vehicle Wireless Testbed (MVWT), which is a platform designed for validating theoretical advances in multiple-vehicle coordination and cooperative control. The MVWT is equipped by a wireless network, an arena for multi-vehicle operations, a lab positioning system based on overhead cameras, and a computer network. The smooth floor where the vehicles maneuver has dimensions of approximately 6.5 m × 7.0 m. Vehicles are marked with binary symbols on their hats, that the vision system uses to identify their location and orientation.
The Kelly robot is modeled by a nonlinear dynamical system described by the following equations:
where the symbols used take the following meanings:
the symbols
and
denote the magnitudes of the forces generated by, respectively, the ducted fans located at the right-hand side and the left-hand side of the robot’s rear end, which are separated by a distance
as shown in
Figure 1, where
m;
the constant m denotes the mass of the Kelly vehicle, whose value is kg;
the constant denotes the linear friction coefficient, whose value, in the case of the MVWT testbed, is kg/s;
the constant denotes an angular friction coefficient, whose value, in the case of the MVWT testbed, is kg m/s;
the variables and denote the components of the linear velocity of the vehicle, where and denote the positional coordinates of the vehicle;
the variable denotes the angular velocity with respect to the reference frame, expressed in rad/s, and the angle denotes the orientation of the vehicle (with respect to the same reference frame), expressed in radians;
the constant J denotes the moment of inertia of the vehicle and its value is kg m.
The quantities , , m, J and denote physical constants of the vehicle, while the variables u, v, and are the results of its dynamics and play the role of internal states of a vehicle’s model. The quantities and may be regarded as inputs of the system and are subjected to the action of a controlling algorithm, which may determine their amplitude according to a desired control strategy.
The aim of the VARP-based design is to determine expressions of the forces
and
in such a way that the mathematical model encoded by Equation (
5) transforms into the VARP Equation (
3). Such development is detailed in the next section.
3.2. VARP Control Theory Applied to the Kelly Robot
Combining Kelly robot’s equations of motion (
5) and the equations that describe the VARP theory (
3), it is possible to obtain a direct definition of the right-hand and left-hand fan forces, which represent input/control variables in the mathematical model (
5).
Plugging into the second equation of (
3) the explicit expressions of the potential functions leads to:
Applying the gradient to the sum we obtain:
The vehicle-fixed
reference frame is obtained by rotating the inertial
reference frame by an angle
. Namely, the two reference frames are related by:
Plugging Equation (
8) in Equation (
7) gives:
The forcing term (
9) may be decomposed in components along the
and
axes. From the scalar product between both sides of the relation (
9) and the unit vector
we obtain, in particular, the component of the forcing term
along the direction of motion:
The component of the force along the
direction, in turn, may be decomposed in two components, one along the
direction, and one along the
direction, which read, respectively:
In addition, from the scalar product between the force (
9) and the unit vector
, we obtain the component of the total forcing term perpendicular to the direction of motion, which reads:
The above component of the total force acting on one side of the body of the vehicle is responsible for the rotational motion of the vehicle which, in turn, determines its steering ability.
It is instructive to devise a physical interpretation of the above terms. From the
Figure 1, it is noticed that the velocity
is directed along the
direction while it is null along
. The perpendicular component
(projected into
) of the robot acceleration is related to its rotation about a perpendicular axis sticking off the floor.
It could be convenient to think of a inter-fan vector of length , with a direction consistent to the fact that is directed along . Multiplying by the robot’s mass, one obtains a force along the direction, which is responsible for Kelly robot’s spinning over the floor. Such force may be decomposed in two components, each of them taking half of its magnitude. Consequently the two virtual forces, with a moment arm , establish a torque that causes the rotation of the system.
Formally, since the force
is responsible for the change of the angular momentum of the vehicle, it is sensible to define the mechanical torque magnitude as:
The right-hand side of Equation (
14) is the magnitude of the mechanical torque acting on the vehicle’s body, which is computed as the product between the position vector of the force
and the component (
13) of the force perpendicular to Kelly robot’s direction.
Now, the VARP-based control equations for a Kelly robot may be derived by matching the above equations with Kelly robot’s equations of motion. In this way, one may obtain the sought control relationships between VARP features and Kelly robot’s inputs and parameters.
Specifically, by matching the first equation in (
5) to Equation (
11), we obtain:
The parameter
may be chosen arbitrarily, hence we shall impose
. Furthermore, deleting the factor
from both sides of the above equation, gives:
Then, comparing the third equation in (
5) with the relation (
14) and taking
, gives:
Notice that the constant
does not match with any parameter in the VARP equations, hence it must be assumed of zero value to retain consistency [
39], which, in practice, is equivalent to considering it of negligible value.
From Equations (
16) and (
17) we may obtain the right-hand fan thrust as well as the left-hand fan trust as:
Notice that the above expressions present a number of repeating terms. Collecting such repeating terms from the Equations (
18) and (
19), we may define:
Ultimately, we obtain two equations for the right-hand fan and the left-hand fan thrusts:
which are in full accordance with those presented in [
39].
In the present research work, we are mainly interested in the theoretical aspects that allow one to match the equations in the mathematical model of a vehicle to the structure of the general VARP control theory. In addition, we are especially interested in performing numerical experiments on the basis of the devised equations in order to gain a sufficient insight into the effects that the values of the parameters induce on the behavior of a vehicle. The numerical aspects of the present analysis are covered in the following section.
3.3. Numerical Scheme to Simulate a Controlled Dynamical System
The aim of the present subsection is to recall, from the specialized literature, a numerical scheme, namely the
forward Euler method, to approximately solve the differential equations that govern the motion of a Kelly robot. Although such method is standard in numerical calculus, we deemed it appropriate to recall it in some details to set up a common ground in view of its extension to manifolds in
Section 4.
The forward Euler method (hereafter denoted as fEul) is a numerical integration scheme used to approximate the solution of an ordinary differential equation starting from a known initial value, namely an
initial value problem (IVP). A first-order IVP may be expressed as:
The fEul method is based on two key ideas, namely, uniform time-discretization of the state-variable and approximation of its first-order derivative by means of an incremental ratio. To approximate the solution
to the IVP (
24), define a uniform succession of time-steps, separated by a reasonably short interval
termed
stepsize, which are denoted by
,
and so forth. According to the fEul method, for reasonably small values of
h, the first time-derivative
can be approximated by the incremental ratio:
Denoting by
an approximated value of the exact solution
at the
n-th step, the IVP (
24) for a generic time
may be approximated by the difference equation:
from which the iterative fEul method arises:
The fEul method will be employed to approximate the solutions to the differential Equation (
5) for simulation purposes. In the following mathematical steps, we will only show how to apply such method to the first equation of (
5), because for the remaining differential equations the procedure is similar.
For the sake of notation conciseness, hereafter we shall assume the presence of a single Kelly robot, so as to drop the index “i” from the equations of motion. The first of the differential Equation (
5) is a second-order equation in the variable
x. At time
, the Kelly robot presents an initial
x-coordinate denoted as
and an initial velocity
along the
x-axis. The IVP (
5) may be split into two IVPs:
For the second IVP, an application of the fEul method yields the iteration:
while for the first IVP, an application of the fEul method yields the iteration:
Likewise, for the second equation of the system (
5) we obtain:
and for the third differential equation in the system (
5) we obtain:
By applying fEul iteration, the values of the robot’s location and orientation may be approximated. The more the sampling step is small, the more such approximations will result accurate.
It is important to recall that the forward Euler method is poorly-performing in comparison to higher-order methods such as the 4th order Runge–Kutta method. Nevertheless, in the present paper we decided, in contrast to other papers on numerical methods on manifolds written by the third author, to invoke only the forward Euler method because usage of more accurate methods would have required a more extensive introduction on higher-order methods on manifolds that would have hindered the main flow of discussion, namely the extension of VARP method to smooth manifolds.
3.4. Simulations and Results of VARP Control Method
In the present subsection, results of numerical simulations will be discussed in order to illustrate how the VARP method was employed to control a Kelly robot and how the values of the VARP parameters, with special reference to constants , , and impact on control outcomes. The value of the chosen numerical stepsize in every simulation in this section is (s).
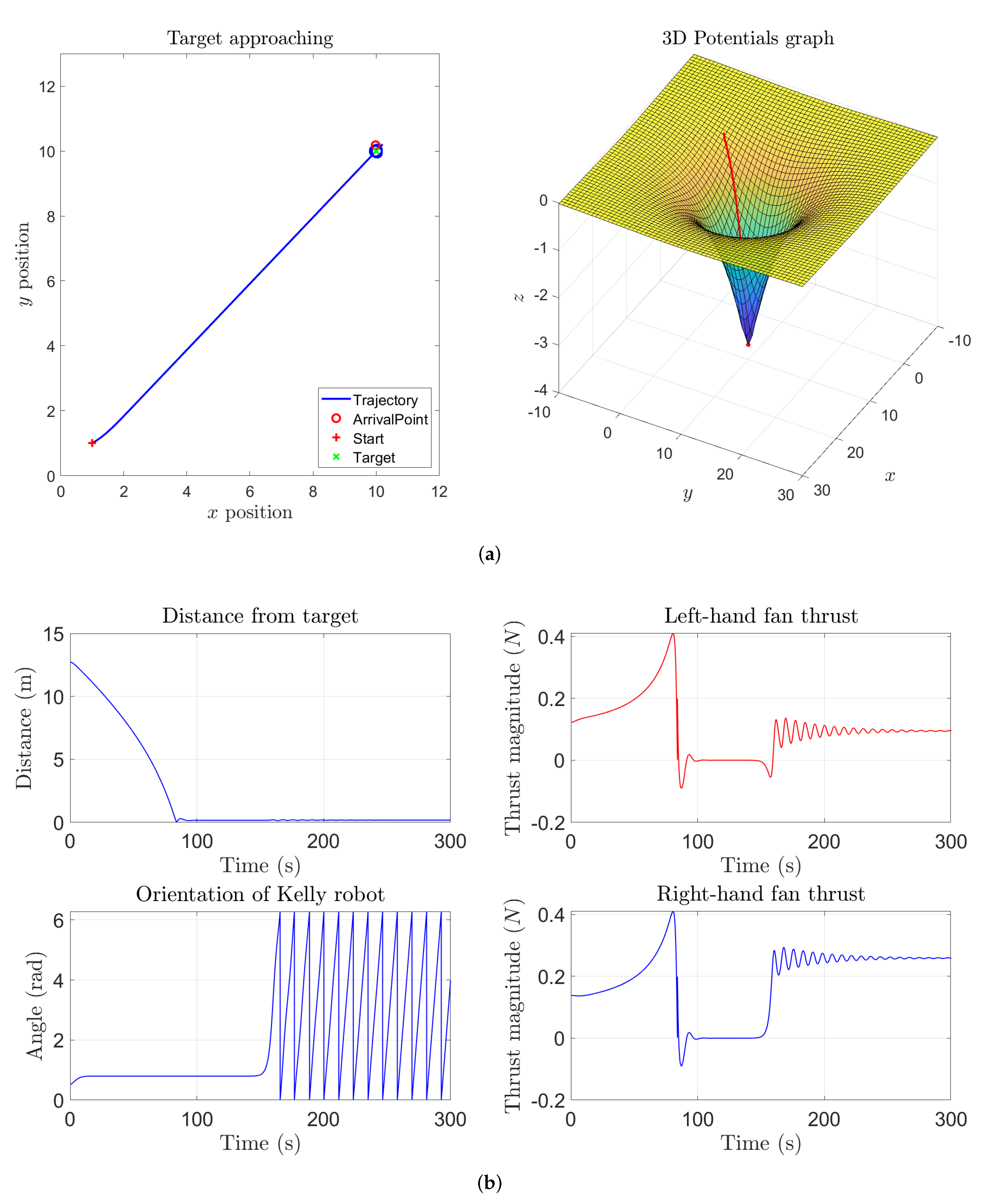
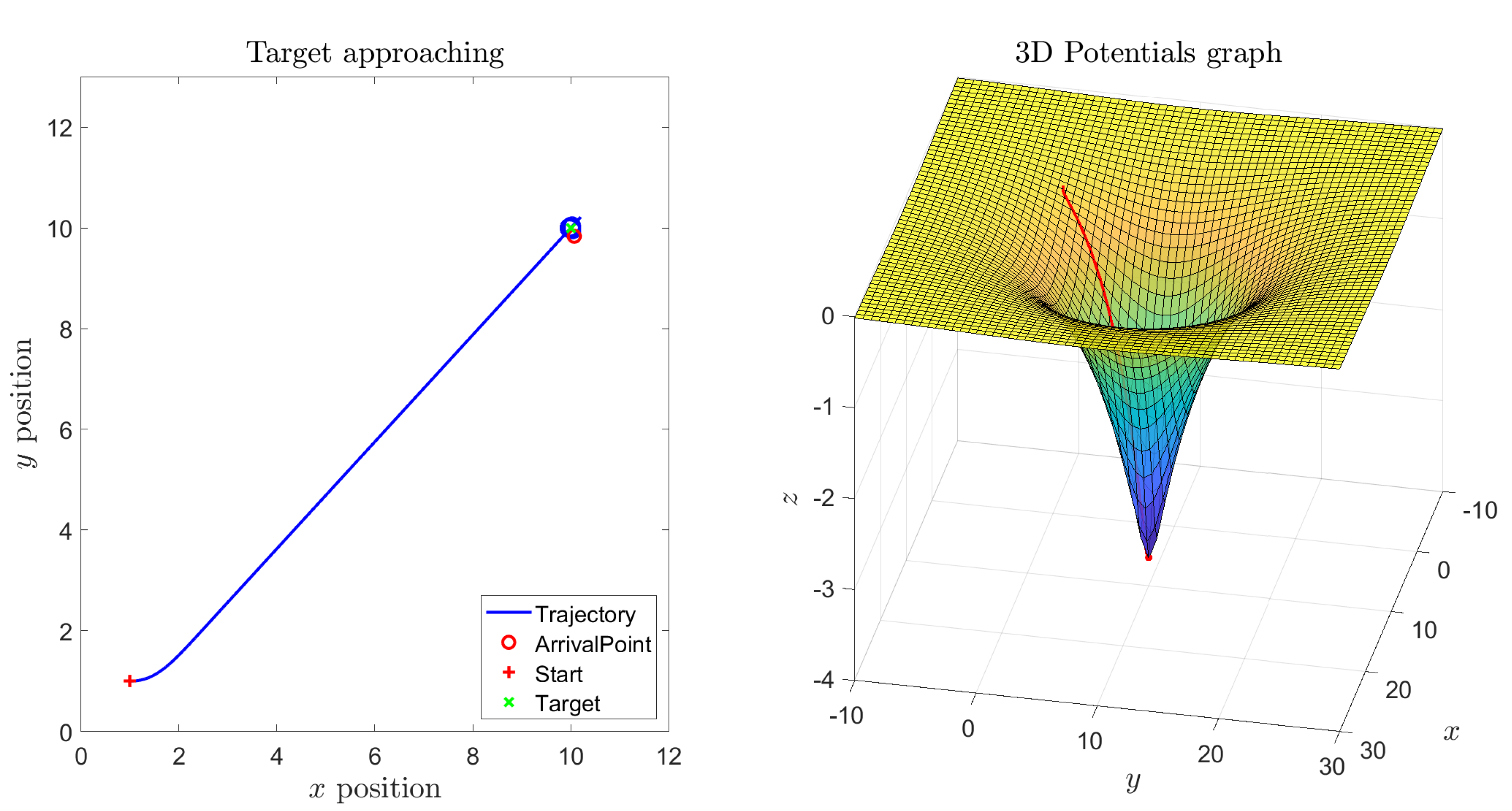
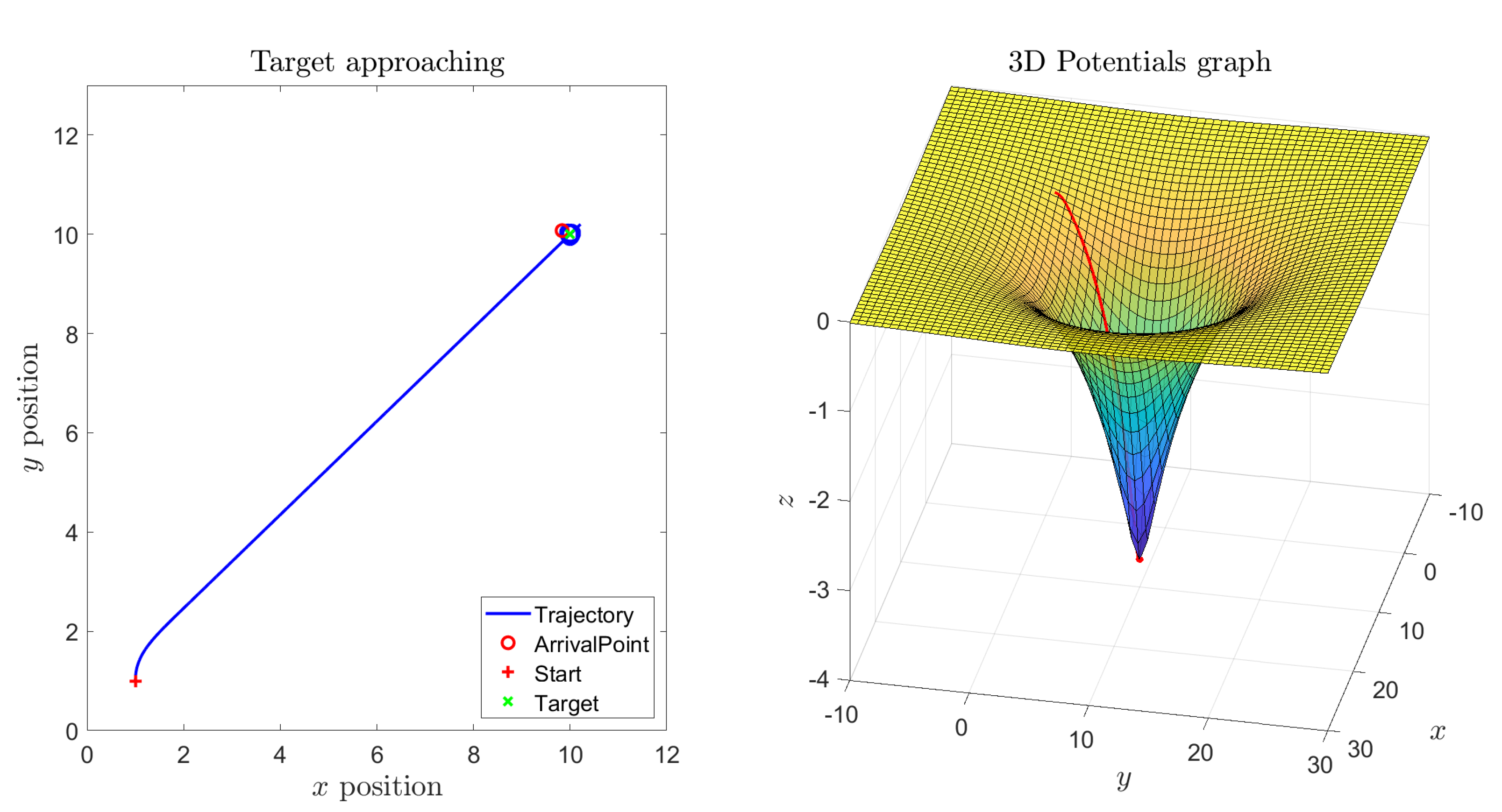
Figure 2 shows the result of a numerical simulation referred to a single target point and no obstacles. From the six panels of such figure it may be readily recognized that the robot traverses the state space from the initial point directly to the target. After the Kelly robot reaches the target, it keeps revolving around the way-point due to the action of the self-propelling term. During vehicle’s journey, the thrusts generated by the left-hand fan and by the right-hand fan look in sync, because the vehicle travels along a straight line, and the orientation of the vehicle keeps almost constant until it reaches the target.
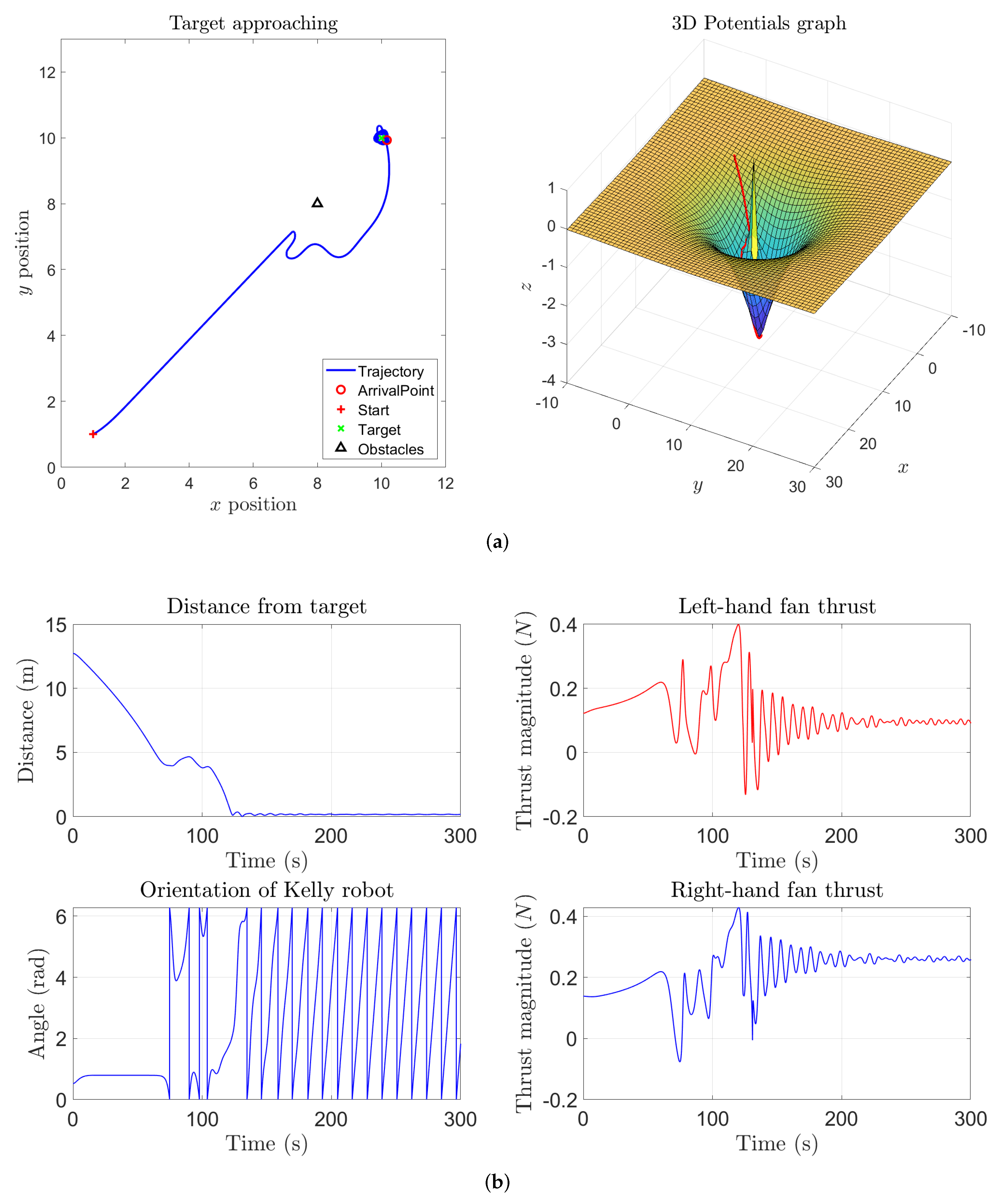
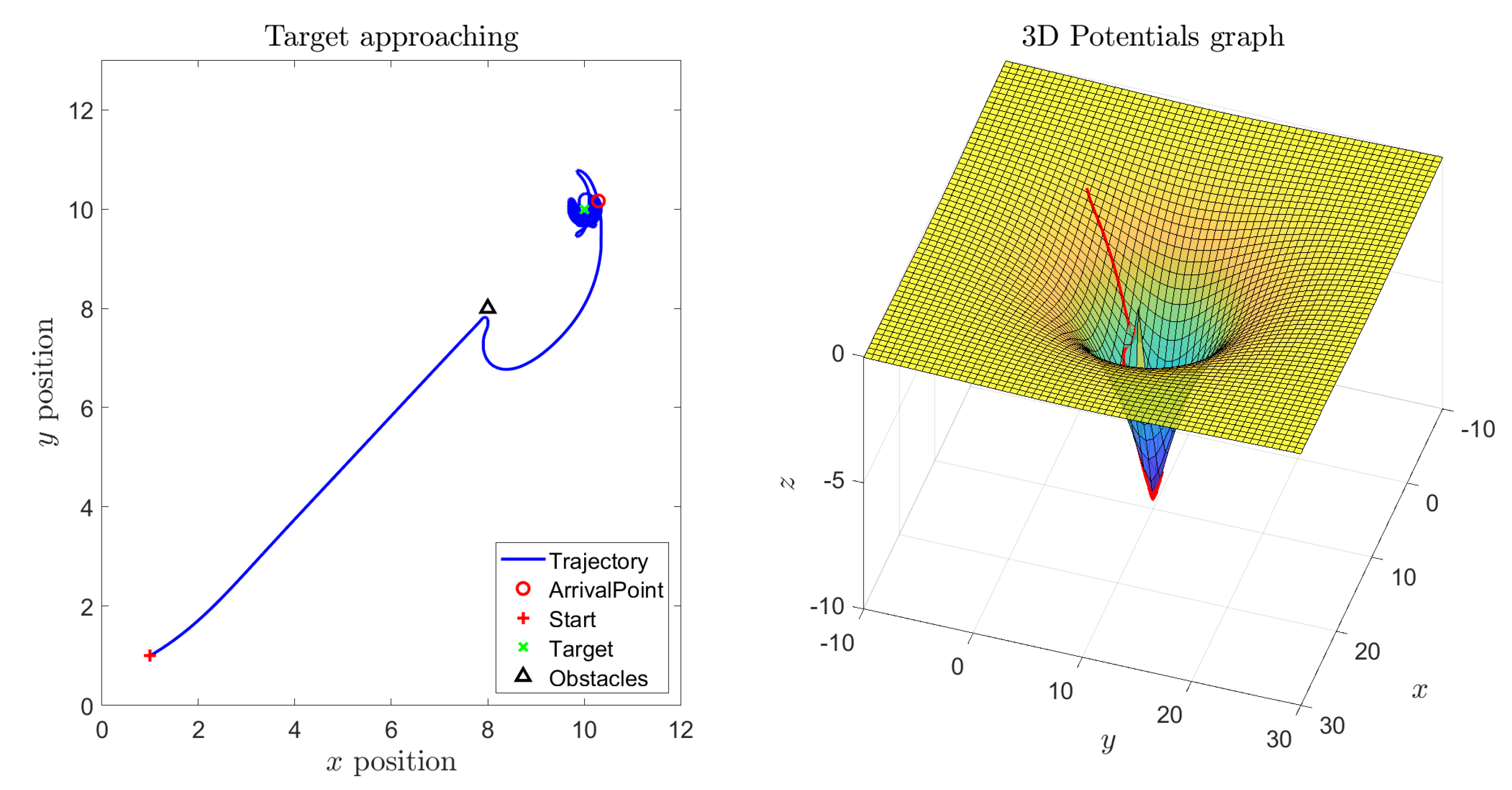
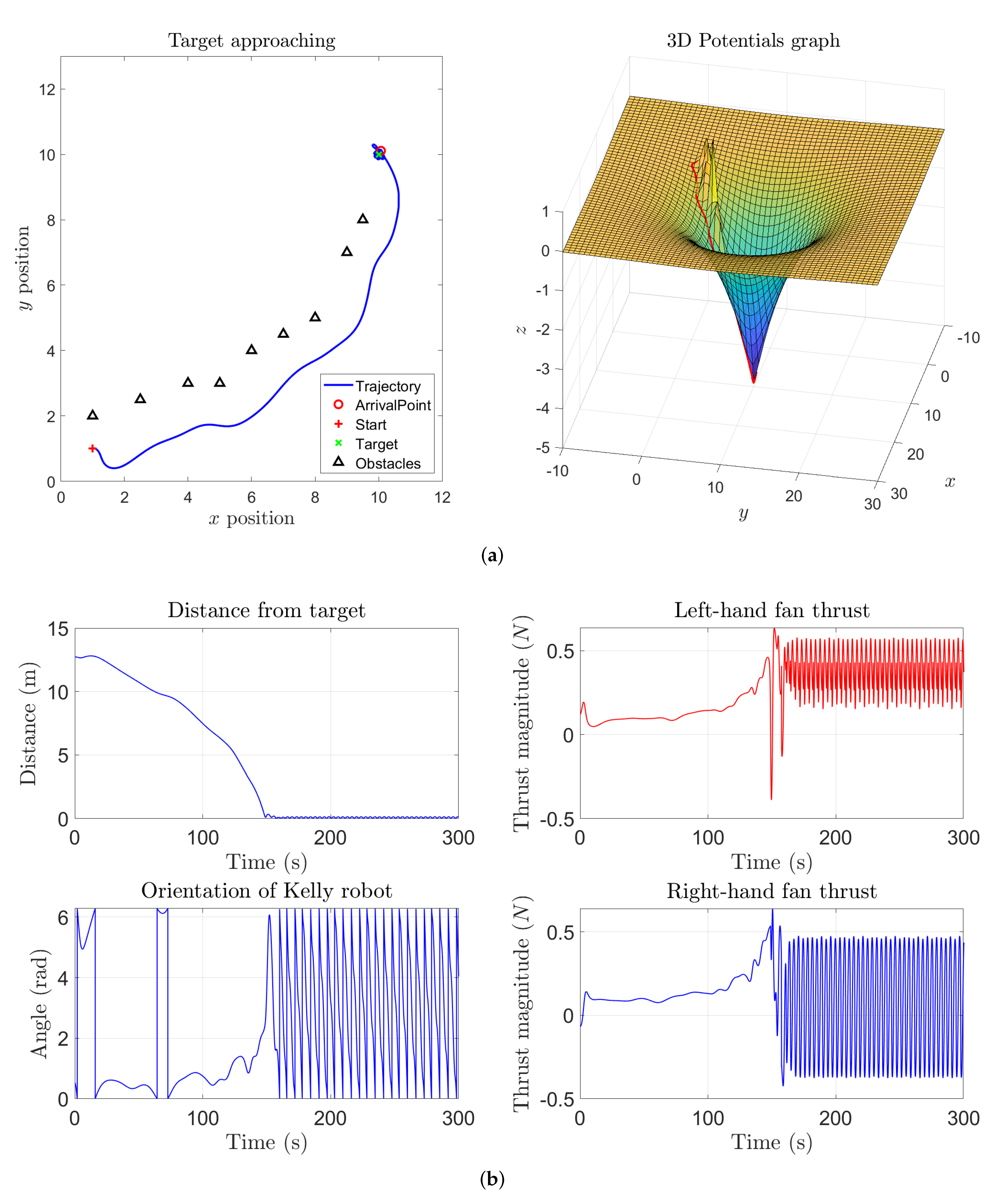
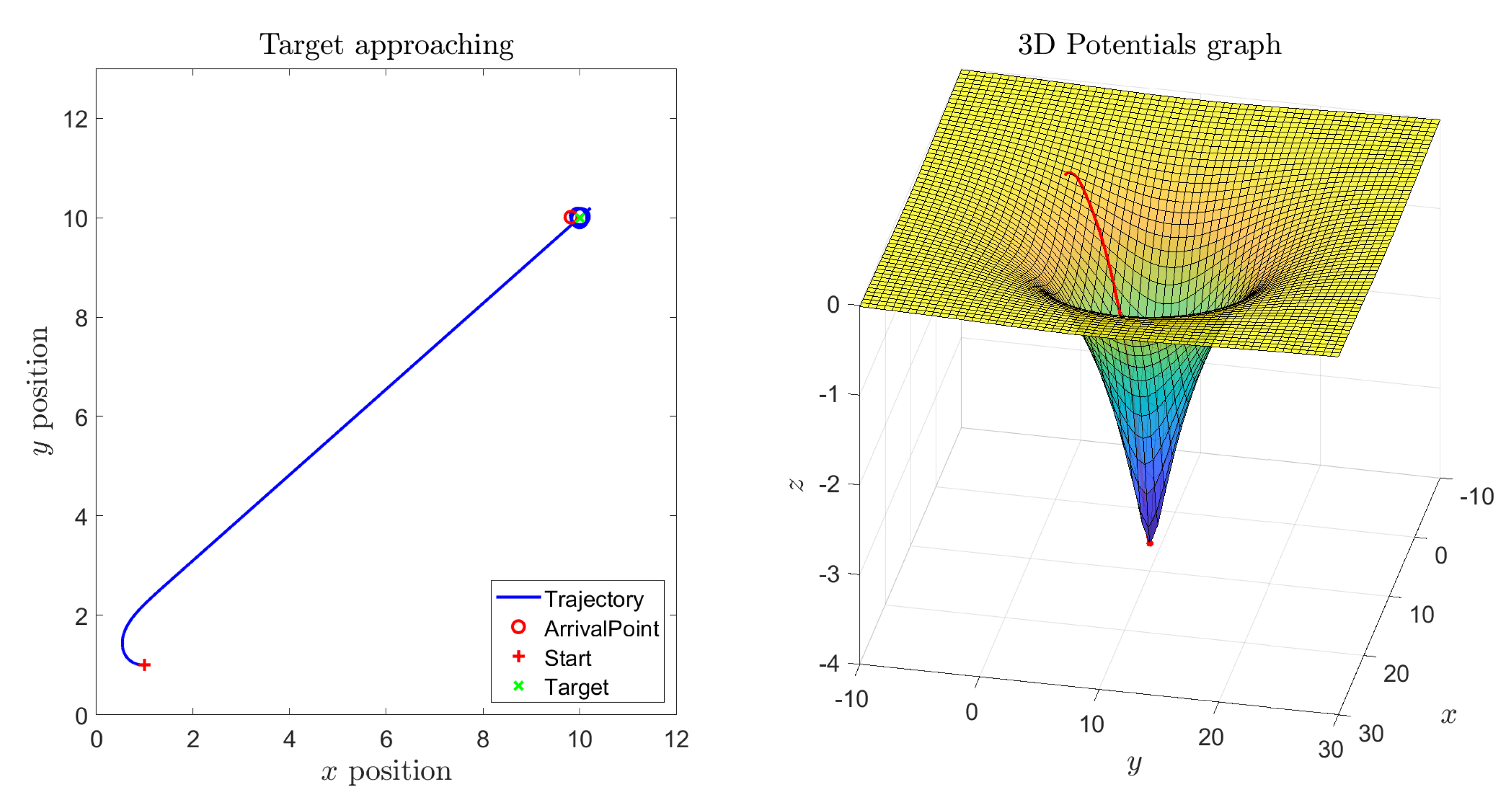
In the next two simulations, an obstacle between the initial location and the target location was added. From
Figure 3 it is readily observed how the robot could reach the target and managed to avoid the obstacle. In particular, while the vehicle is located sufficiently far away from the target to ignore its repulsive action, its trajectory resembles a straight line. As soon as the vehicle enters the sphere of influence of the obstacle, its trajectory bends to the left, which corresponds to a sudden increase of the thrust exerted by the right-hand fan around
s, to get around the obstacle. After reaching the target, both thrusts stabilize around a value giving rise to a forcing action necessary to counter-act the self-propelling term.
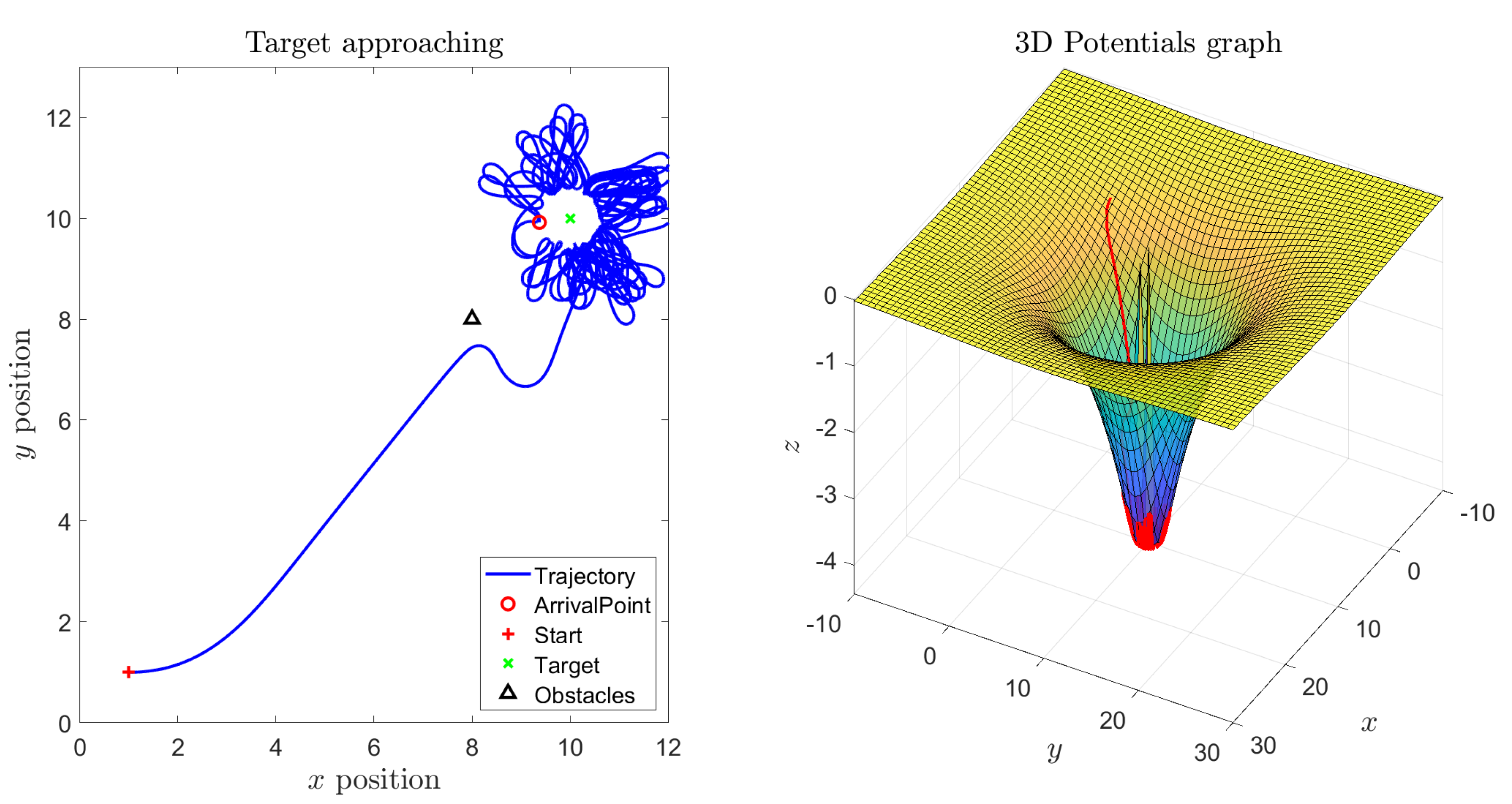
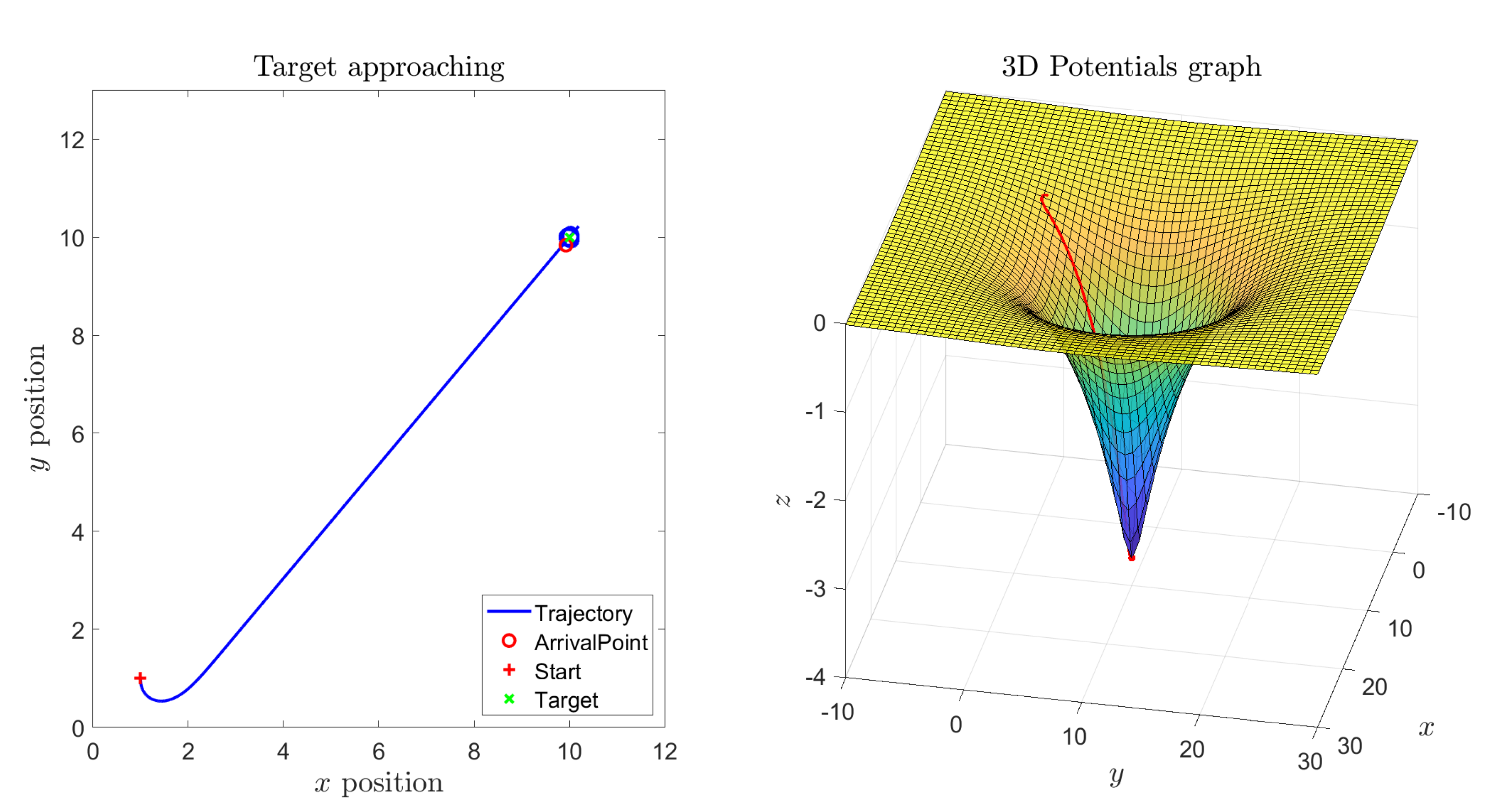
Figure 4 shows a result obtained under the same conditions of
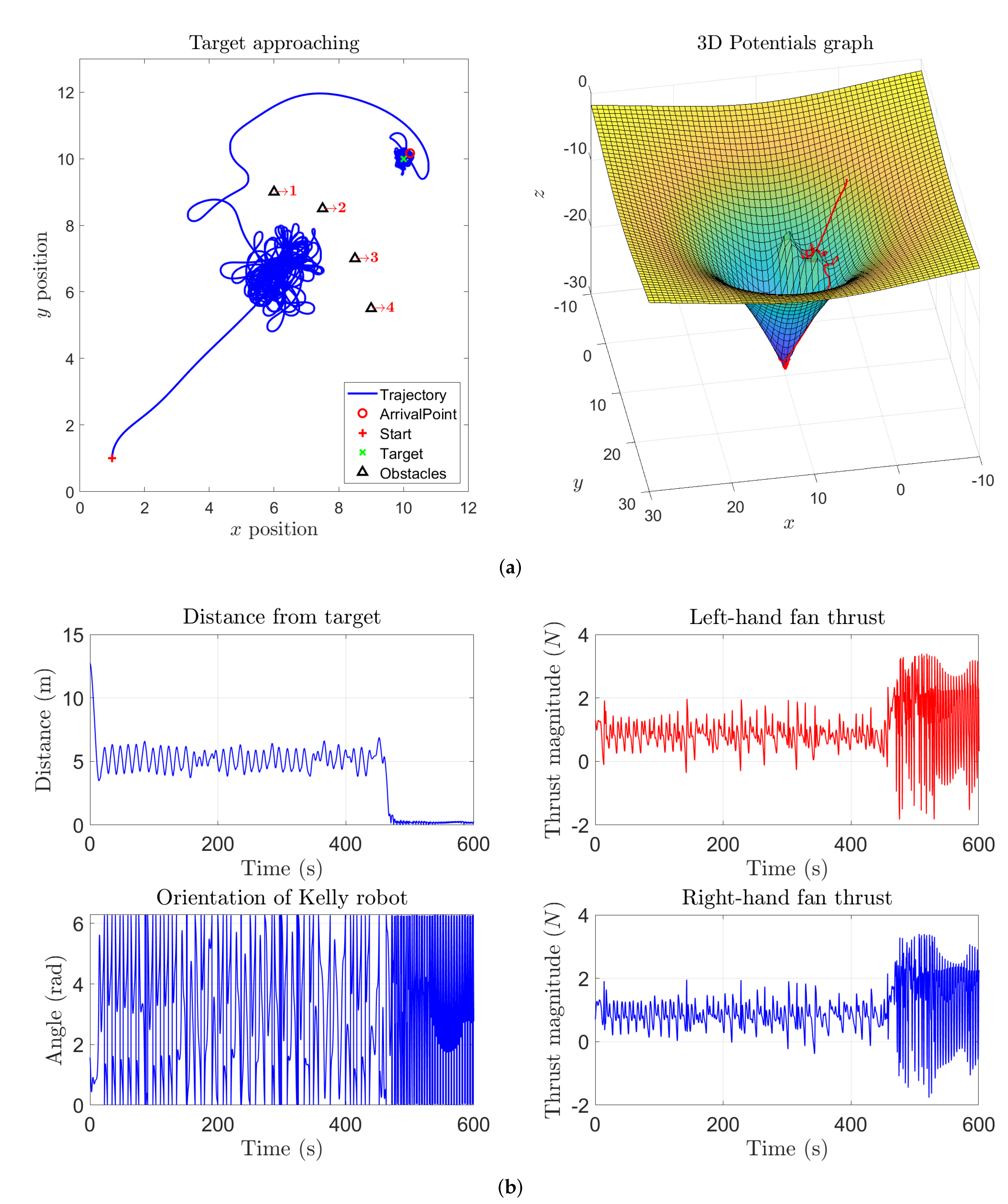
Figure 3 except that the magnitude of the self-propelling term was increased. In this case, the thrust is quite large, hence the vehicle approaches the target location quickly except then starting to revolve around the target in a pronounced way. Such effect is well visible because the self-propelling term prevails over the attraction pull of the target. Nevertheless, despite the overly irregular movement of the vehicles, the robot draws circular revolving trajectories around the target point.
The trajectory followed by a vehicle under the control action of a VARP-based algorithm may be smoothed out by increasing the attractive magnitude of the target to counteract the self-propelling term, as illustrated in
Figure 5. Although the robot appears to reach and then wander around the target point, with such a large value of the parameter
, it is necessary to consider carefully the irregular trend of the thrusts generated by the propellers. Experimental results show that the self-propelling term must range from
to
in order to induce a reasonable trajectory on the vehicle: the higher the value of the self-propelling amplitude
, the higher the average thrust required to the ducted fans.
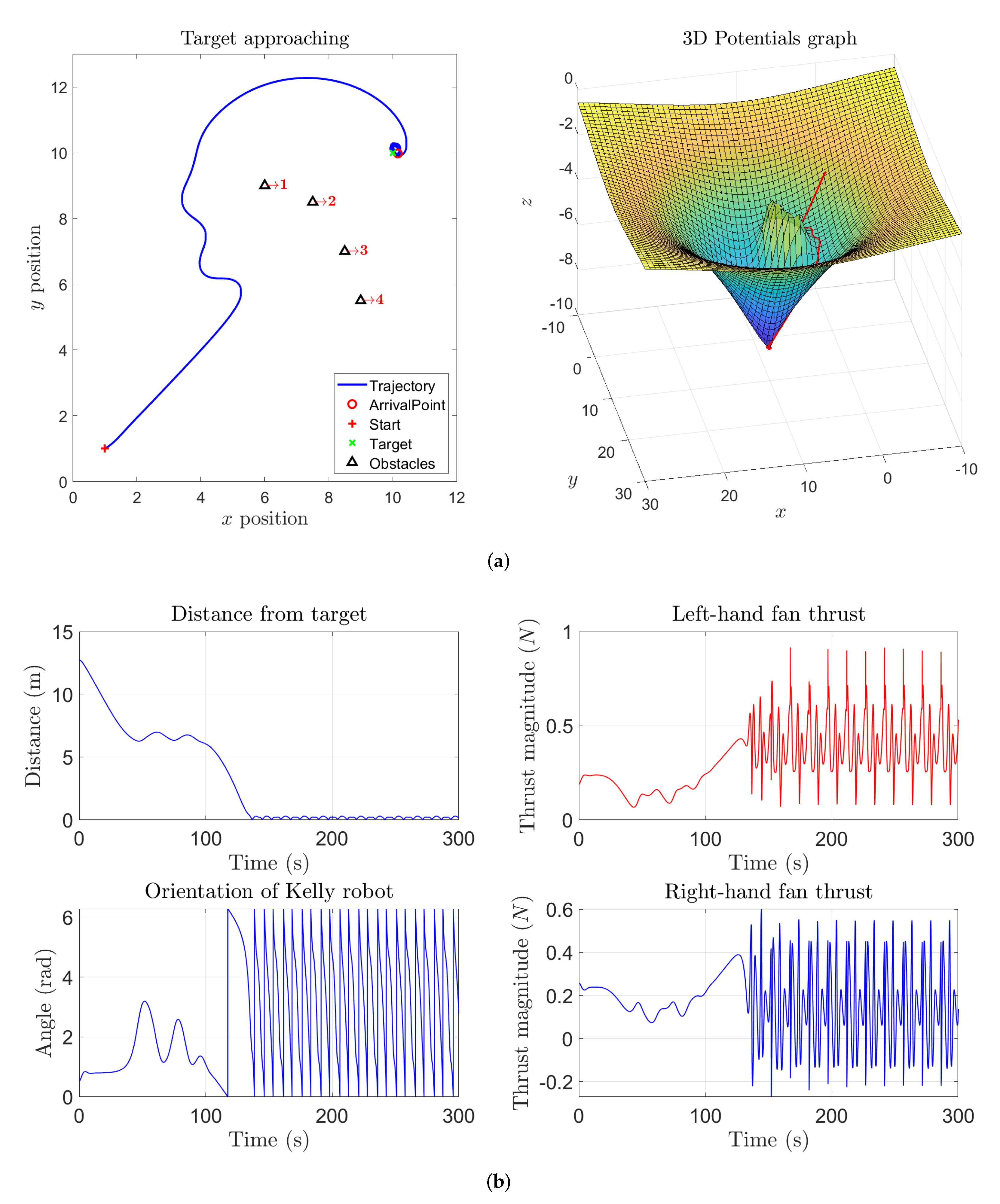
A further interesting experiment consisted in building a ‘barrier’ between the starting point and the target location. A barrier, in this context, is constructed by placing a number of obstacles represented by repulsive potentials.
Figure 6 shows the results of such numerical experiment. From the 3D potentials graph, it can be readily noticed a potential ‘bulge’ that represents the repulsive influence of the obstacles in the barrier. Even in such a case, a vehicle controlled by a VARP algorithm manages to reach the target location by getting around the barrier.
It can be noticed from
Figure 7 that, if a larger value of the parameter
is set, the Kelly robot tends to follow a wider trajectory since the obstacles result to be more cumbersome and their influence, in terms of repulsive potentials, is perceived farther by the robot’s control system. The 3D graph displayed in such figure shows how the virtual potential field influences the vehicle in every point of its state space. Indeed, the areas where the repulsive potentials are located correspond to a cumbersome ‘bulge’ in the 3D potentials graph. Compared to
Figure 6, the ‘bulge’ appears wider and taller since the repulsive range of obstacles takes a larger value. Instead, the attractive potential corresponding to the target location may be visualized as a depression/dip in the same 3D graph.
In general, the larger the value of the repulsive range, the wider the influence of the obstacles, which could be visualized as wider ‘bulges’ in the potential surface.
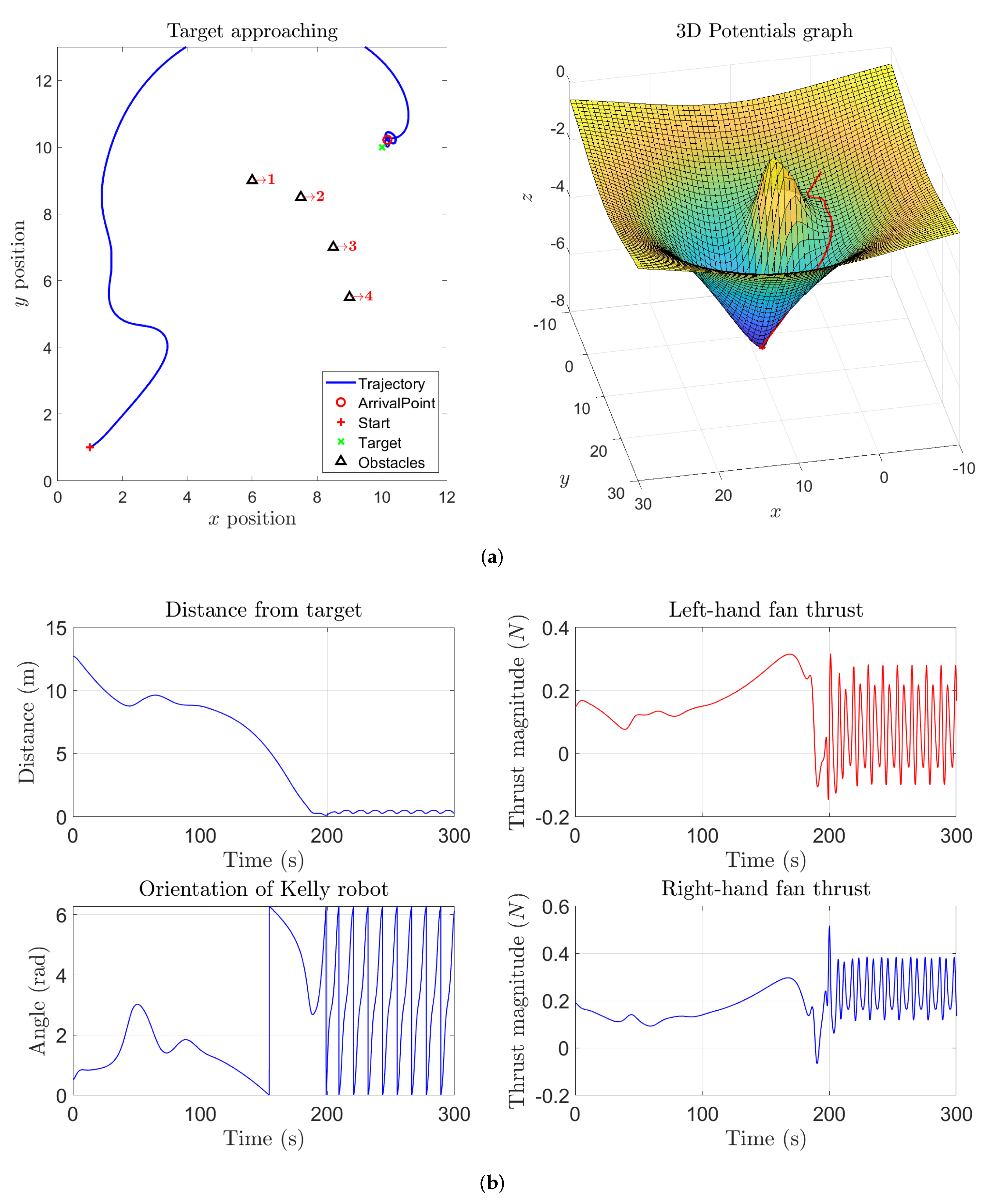
Upon choosing, instead, lower values for the repulsive range of the potentials describing the barrier obstacles, a vehicle tends to approach the barrier while, being attracted by the target and as well as being repelled from the obstacles, it might get trapped near the barrier as testified by the numerical experimental result illustrated in
Figure 8. It can be noticed from the 3D potentials graph that the vehicle is trapped behind the ‘bulge’ which appears to be less tall than in the previous experiments, since the repulsive range of obstacles takes a lower value. In this case, in order to make a robot be able to overcome the barrier, it is advisable to choose a large value of the self-propelling term coefficient as illustrated by the results displayed in
Figure 9.
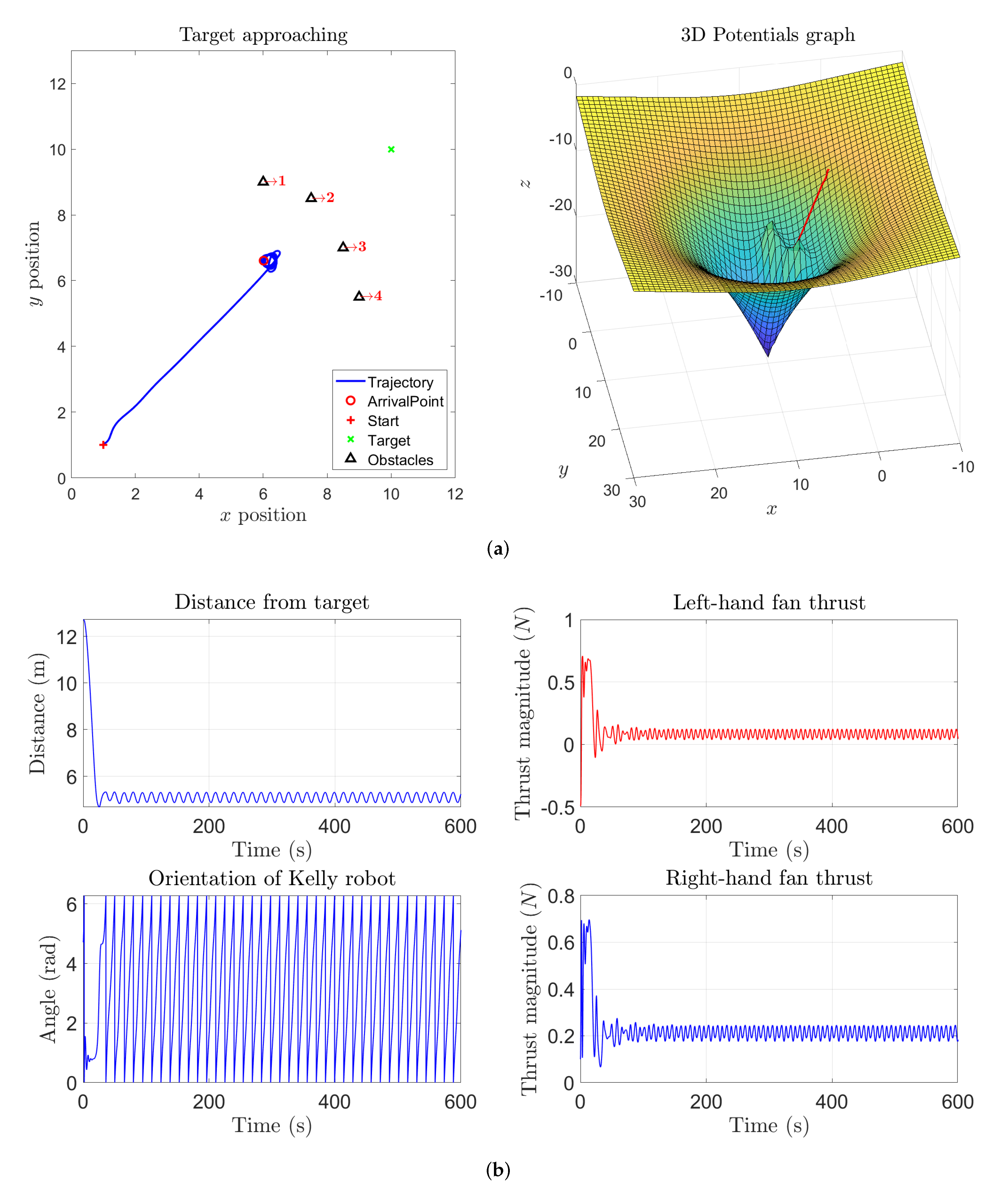
The previous simulations illustrated cases of study with a few obstacles and one target point. Building a more complex virtual potential field on the basis of more obstacles and/or more targets could lead to a more involved control algorithm yet to a more precise control action on a moving vehicle. As an instance,
Figure 10 illustrates how to make a vehicle follow a previously planned path. In such numerical experiment, a vehicle reaches the prescribed target by following a ‘guiding wall’ built through virtual potentials. It is remarkable how, in such simulated experiment, the thrusts exerted by the propellers on the vehicle’s body keep limited in amplitude until the vehicle reaches the target location.
Further simulations were performed by considering different initial orientations of a moving vehicle. Even in these cases, the control algorithm is able to steer the robot towards the prescribed target. Results of numerical simulations are illustrated in
Figure 11,
Figure 12,
Figure 13 and
Figure 14. From the results illustrated in
Figure 11, in particular, it may be noticed that the Kelly robot reaches the prescribed target without any difficulty and without any particular effort required to the propellers, as testified by the results shown in the panels about the thrusts exerted by the fans, which exhibit a rather regular course over time. In addition, the results displayed in
Figure 14 may be compared to the simulation results shown in
Figure 13; it is interesting to notice that, in this case, the Kelly robot will turn counterclockwise in order to steer towards the target. This aspect could also be noticed from the Kelly robot orientation graph where the plot reaches
and suddenly drops to 0.
The numerical simulations presented in this section are meaningful in view of an extension of the standard VARP control theory to state manifolds and serve as a guide in the development of illustrative numerical experiments concerning the next part of the paper. In fact, the large number of numerical results were designed to gain (and to guide readers through) a deeper understanding about the effects of the values of the parameters on the control outcomes.
As mentioned in the Introduction, the pursued extension of the VARP theory to state manifolds was partially inspired by the earlier work of Koditschek and Rimon [
16], which however considered simpler gradient systems and was more theoretical-oriented (in particular, the work [
16] is notable for the use of topological arguments to prove the existence of navigation functions on a large class of manifolds).
Notice that all the obstacles located in have been supposed to be stationary, although this is not a strict requirement for the devised theory to hold.
4. Extension of the VARP Control Theory to Riemannian Manifolds
The aim of the present section is to design a VARP-like principle to control second-order dynamical systems whose state space is a Riemannian manifold. This method will be referred to as M-VARP as it represents an extension of the original VARP control method to a generic Riemannian manifold.
A number of real-world dynamical systems may be framed as systems on manifolds. An example is a flying drone or an orbital gyrostat whose attitude is represented by a special orthogonal matrix belonging to a manifold denoted as SO(3) as illustrated, for example, in [
41,
42,
43].
Successively, the devised M-VARP principle will be implemented and simulated for the case of study where it controls an abstract dynamical system whose state space is the sphere
(which will be denoted as
-VARP). As in the previous experiments, we shall consider the presence of a single agent (as a matter of fact, in this paper we do not deal with ‘cooperative control’). As a general reference to manifold calculus, interested readers might want to refer to the Symmetry tutorial paper [
40].
4.1. Generalities on Riemannian Manifolds
Let denote a smooth manifold. At a point , the tangent space to the manifold is denoted as . The symbol denotes the tangent bundle associated to the manifold defined as .
A Riemannian manifold is endowed with a bilinear, positive-definite form that associates a scalar (or inner) product to each tangent space . A local metric also defines a local norm , for .
The Riemannian gradient of a scalar-valued function evaluated at a point is denoted as . The Riemannian gradient is associated to a specific metric.
A manifold exponential map maps a pair to a point on the manifold. The exponential map ‘shifts’ a point x along a geodesic curve in the direction of v to get to the point y. Its inverse ‘log’ is defined only locally and is termed manifold logarithm. Given points , a manifold logarithm computes a tangent vector such that .
Given two points
connectable by a geodesic arc, their
Riemannian distance is denoted by
. On a Riemannian manifold, the distance between two nearby points may be evaluated by:
A fundamental result of the calculus on manifolds states that the Riemannian gradient of a squared distance function reads:
wherever the logarithm is defined (for a proof, see, e.g., [
40]).
The covariant derivative, a generalization of directional derivative of calculus, of a vector field in the direction of a vector is denoted as . We assume to be endowed with a metric connection (namely, that the covariant derivative of the metric tensor is identically zero).
The parallel transport operator maps a tangent vector at a given point into a tangent vector at another given point , which is denoted as . Parallel transport moves the tangent vector v from to along the geodesic curve that connects the point x to the point y (if any) preserving its tangency along the geodesic arc and the angle formed to the tangent to the geodesic, in such a way to realize a conformal isometry.
Parallel transport and covariant derivation are closely related to one another, in particular, covariant derivation may be expressed in terms of parallel transport as follows:
where
denotes any smooth curve with prescribed foot-point and direction, namely such that
and
. For practical/computational purposes, such smooth curve is often taken as a geodesic arc. Such relationship leads to a numerical approximation of the covariant derivative at a point
x, as it will be pointed out in
Section 4.3.
4.2. Extension of the VARP Principle to Riemannian Manifolds
In order to extend the VARP principle to control dynamical systems whose state spaces are Riemannian manifolds, it is necessary to recall a fairly broad class of second-order dynamical systems. In the present context, it is sufficient to take into account a class of second-order dynamical systems whose state-transition equations are formulated on the tangent bundle of a manifold
, described by:
In such equations, the following notation has been used:
the function denotes the state of the dynamical system (it could be thought of as the position of a pointwise mass on the manifold at time t);
the function denotes the tangent vector to the trajectory at the time t (it could be thought of as the velocity of a pointwise mass on the manifold);
the vector field represents the covariant derivative of the vector field v with respect to itself (it could be thought of as the acceleration of the pointwise mass on the manifold); if the acceleration is zero, thus the pointwise mass will follow a uniform geodesic trajectory (which represents the counterpart, in the ordinary space, of a straight uniform motion);
the constant denotes a ‘viscous’ friction coefficient (therefore, the term could be thought of as a friction force which brakes the motion of a pointwise mass sliding over the manifold);
the function denotes a control action at time t (it could be thought of as a force whose purpose is to make a pointwise mass move on a manifold and deviate with respect to a purely geodesic trajectory); such control action is a vector field which is tangent to the manifold at the state .
On the basis of the above formulation of a dynamical system on manifold, it is viable to extend the VARP control principle recalled in
Section 2. In fact, an extension to manifold-type state-space systems of the type (
36) consists in setting the control action
u according to a manifold-consistent translation of the terms in the VARP principle (
3). The proposed extension is outlined in the following:
The terms appearing in the above equations may be explained as follows:
the term , with , represents a self-propelling term, where if otherwise ;
the function
denotes the total potential which depends on the state
x; the functions
and
denote, respectively, the repulsive and attractive components of the potential function, as they were already defined for Euclidean spaces in
Section 2.2; note that the components are indexed by the index
j: this indexing does not appear explicitly in [
39] while, in the present case, each obstacle and target has its own coefficient;
the N terms labeled represent obstacle-associated and target-associated locations on the manifold ;
the function denotes the squared Riemannian distance between two points on the state manifold ; notice that, in the equations, it appears squared because such choice, generally, simplifies the calculation of derivatives.
Combining together the Equations (
36) and (
37), it can be readily seen that the control field
u takes the expression:
Recalling the relationship (
34) for Riemannian manifolds leads to the expression:
where
and
.
Coherently with what was expected, the results show that .
In analogy to the VARP principle formulated on Euclidean spaces (see Equation (
4)), exponential-type attractive and repulsive potential functions have been chosen as:
where
and
denote the ‘magnitude of the potentials’,
and
their ‘characteristic lengths’ and
denotes a real positive variable. Their derivatives with respect to
take the expressions:
therefore the control field (
39) ultimately reads:
The M-VARP-controlled dynamical system (in analogy to a VARP-controlled Kelly robot described in
Section 3.2) is hence described by the following system of equations:
The first equation governs the evolution of the state x of the dynamical system on the basis of its (tangent) velocity v, while the second equation governs the evolution of the velocity on the basis of the chosen potentials, of the state and of the state-velocity itself. Notice that again all the obstacles located in have been supposed to be stationary, although this is not a strict requirement for the devised theory to hold.
4.3. Extended Euler Scheme for the Numerical Simulation of the M-VARP Control Method
In the preset subsection, we shall illustrate an extension of the previously-recalled forward Euler method to numerically simulate a controlled system on manifold.
The system (
43) to be simulated numerically may be recast in compact form as:
where
is the function on the right-hand side of the second equation in (
43) that maps a point
x and a tangent vector
into a tangent vector in
.
To solve numerically the system of differential Equation (
44), namely to simulate the controlled system (
43), we introduce three discrete-time sequences that arise from time discretization with a step size
:
the sequence , with , represents a time-discretized version of the state , namely denotes a numerical approximation of the exact state ;
the sequence , with , represents a time-discretized version of the velocity , namely denotes a numerical approximation of the exact state-velocity ;
the sequence
, with
, represents a time-discretized version of the control field
, namely
denotes a numerical approximation of
, that is:
Notice that the discrete-time index is denoted by a superscript (
) to avoid confusing it with the obstacle/target index which is denoted by subscript (
). Once a time discretization of the variables that describe the state of a dynamical system has been performed, an extension of the forward Euler method (fEul) to manifolds may be devised. To express such fEul-like method, the exponential map and the parallel transport operators recalled in
Section 4.1 shall be invoked.
As a further consideration that motivates the usage of a simple numerical scheme, such as the forward Euler one, when more precise schemes are available (such as the ones in the Runge–Kutta class), we notice that such higher-order schemes would require evaluating the control field in points of the trajectory that are not available within the numerical schemes, hence causing additional computational efforts and accumulation of additional numerical errors.
It is important to remind that the parallel transport operator is fundamental in the calculation of the covariant derivative. Let us denote by
a vector field on
(in each point
x of the manifold,
defines a tangent vector at
x) of which the covariant derivative is sought, and by
another vector field along which such covariant derivative needs to be calculated. The sought covariant derivative is then defined as:
Indeed, the covariant derivative represents the rate of change of the vector field w along the direction prescribed by the vector field v, namely, moving away from x toward a direction v.
Let us consider numerical resolution of the first equation in (
44) that is:
which is an IVP on the tangent bundle
. An algorithm that implements the numerical solution in a fEul-like fashion reads:
with
and
known from the initial conditions.
Let us consider now numerical resolution of the second equation of (
44), that is:
which represents a further IVP on the tangent bundle
.
The relation (
46), applied to the vector field
v with respect to itself, could be numerically approximated as:
(We notice that the above relationship is somewhat arbitrary, albeit natural. In fact, the quantities
and
are not related to the quantities
and
as much as in the exact relationship (
46) and, in particular, are not related to
h by a straighforward relationsip, hence the division by
h may appear somewhat arbitrary.) Therefore, an algorithm that implements the numerical solution of (
49) in a fEul-like fashion reads:
with
and
known from the initial conditions.
In summary, the numerical iteration that will be made use of in order to simulate a controlled second-order system on manifold reads:
with
and
known from the initial conditions.
In the following section, numerical results will illustrate a number of features of the devised control strategy on manifold, with reference to the unit hyper-sphere as exemplary case. Let us recall that, in the case of hyper-sphere (
), the canonical operators and the Riemannian distance required for the numerical implementation take the following expressions:
The expression given about the logarithmic map is continuous in
, in fact it is easily seen that:
In the expression of parallel transport, it is understood that points x and y need not be antipodal, namely .
4.4. Simulations Results about the -VARP Method
In the present subsection, results of numerical simulations will be reported in order to illustrate salient features of the M-VARP control method on the unitary sphere . The values of the parameters displayed in the figure captions were determined on the basis of a trial-and-error procedure, since the non-linear control algorithm is not prone to theoretical determination of optimal coefficients in any analytic way. Notice that in an abstract system the ‘temporal’ parameter t is immaterial, hence the duration of each numerical simulation is expressed in terms of computing steps. The value of the chosen numerical stepsize in every simulation in this section is (s).
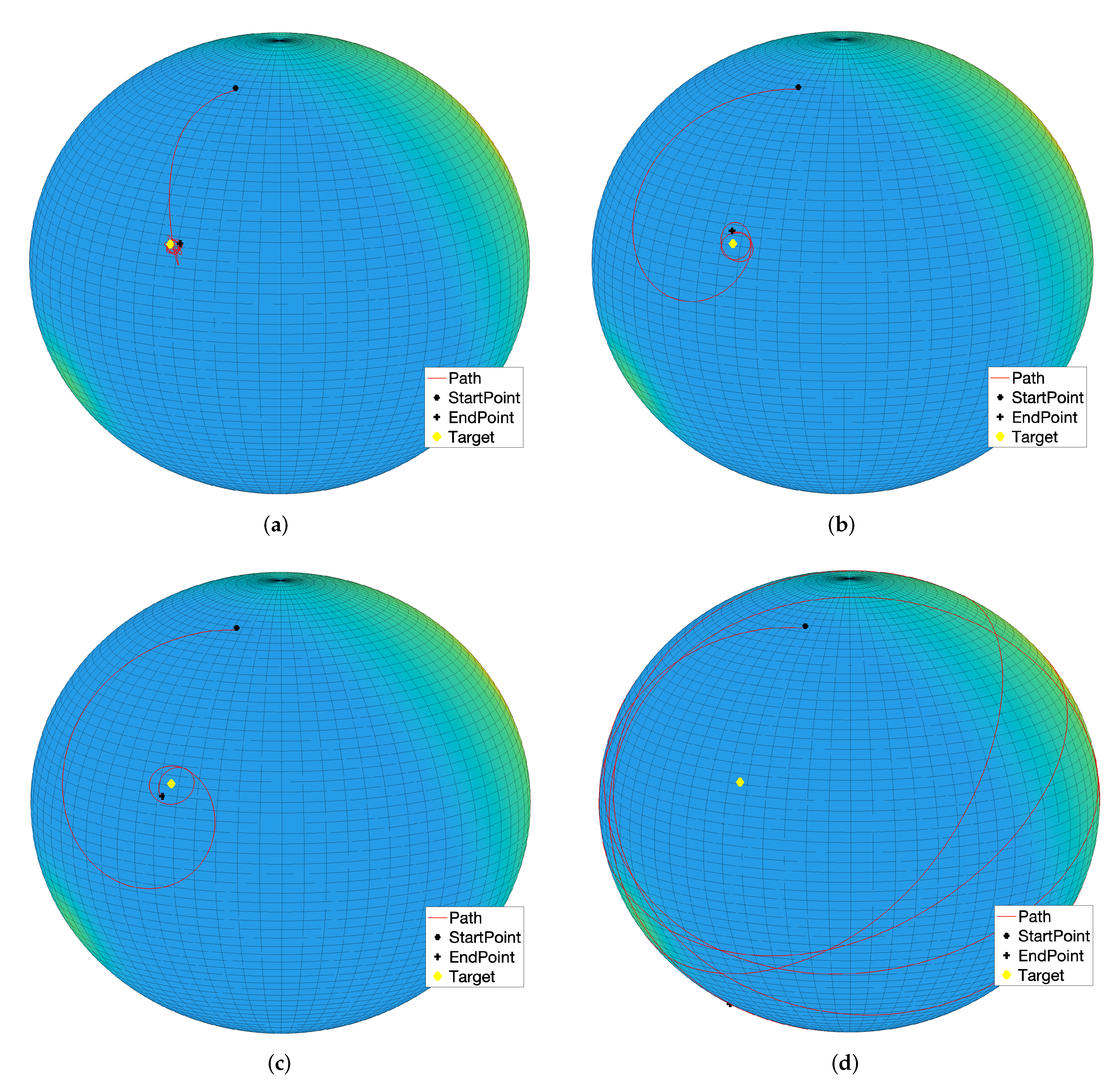
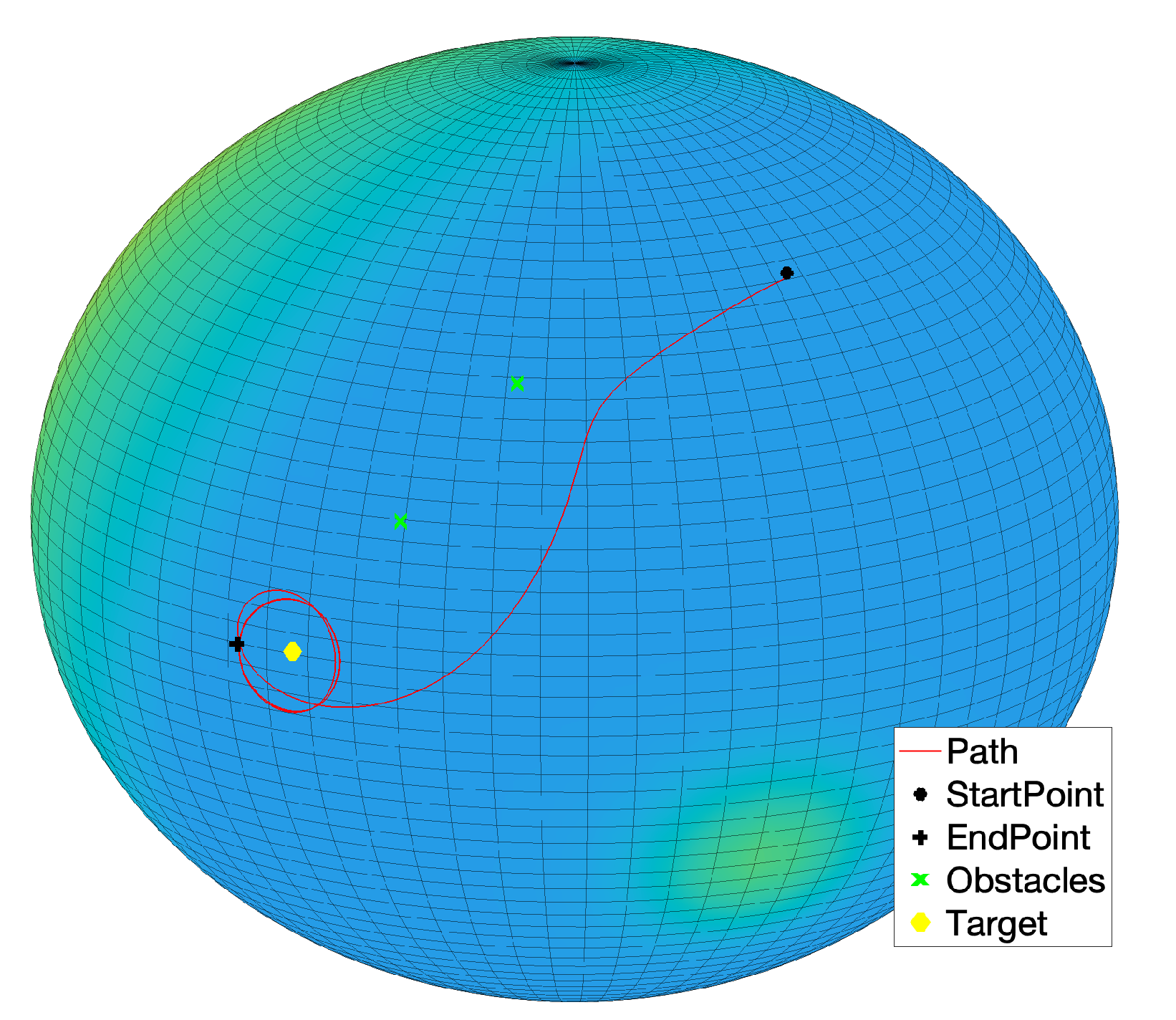
The first five numerical simulation results concern a case study where a single target is present while no obstacles were placed over the sphere.
Figure 15a shows the state trajectory followed by an abstract second-order dynamical system on the sphere and, as expected, the system state reaches the prescribed target. Across the following subfigures, the self-propelling coefficient was gradually increased, which explains why the system gradually follows a wider path, as illustrated in
Figure 15b,c. With an higher value of the coefficient
, self-propulsion is stronger than the attractive influence of the target, hence the system state will wander around the sphere without ever reaching the target, as displayed in
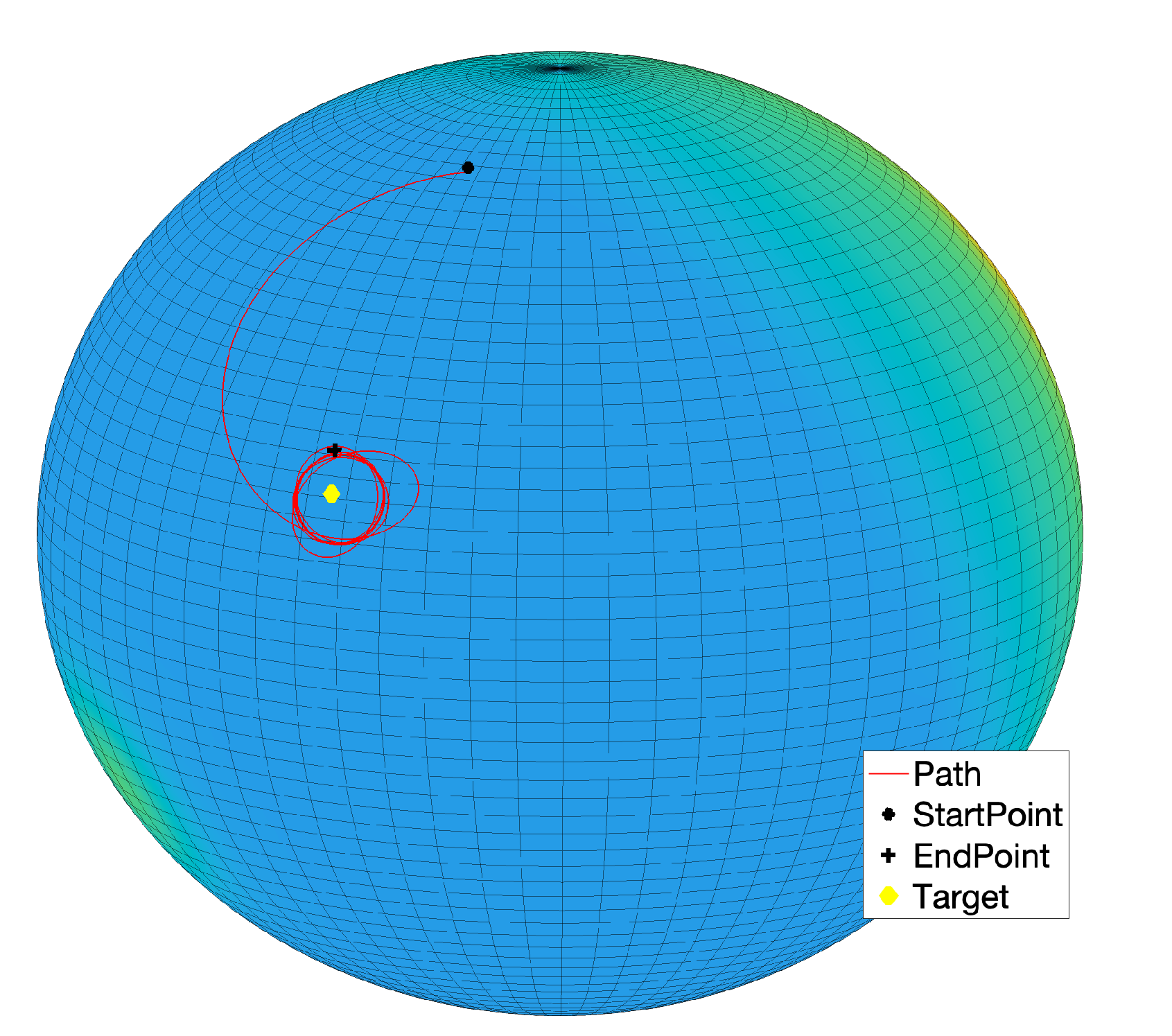
Figure 15d. However, by increasing the attractive magnitude of the target (
), the attractive potential is able to counteract the self-propelling term in order to make the system state reach the target again, as shown in
Figure 16.
A further set of experiments were designed that include one obstacle between the start location and the target location. The state trajectory of the system looks interesting, and aligned to the corresponding behavior seen in
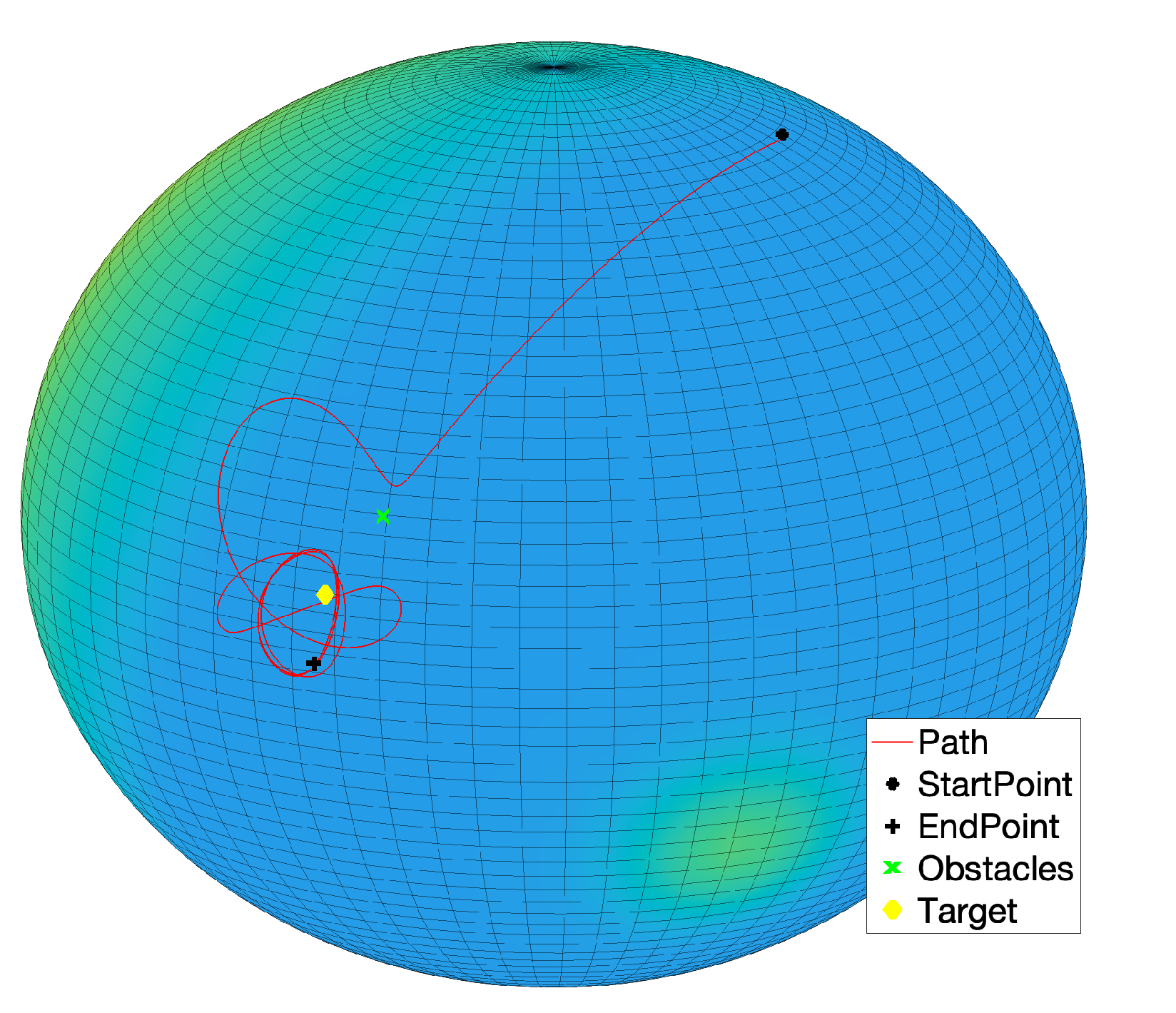
Section 3. In fact, the state trajectory of the system at the beginning of the simulation takes the shortest path to reach the target but, when the state gets close enough to the obstacle, it gets repelled and takes a detour to reach the target. As soon as the system approaches the target, its state trajectory reveals an interesting aspect of the VARP control method: since each location in the virtual potential field (that could represent an obstacle or a target) may be associated with both an attractive and a repulsive action, the system will not turn around the target since it is repelled by both the target and the obstacle, as illustrated in
Figure 17. Reducing the magnitude of the repulsive potential of the target and of the obstacle, the system state would keep go round the target as shown in
Figure 18. From such simulation, we can also notice that, before being repelled, the system state comes closer to the obstacle since its repulsive action was diminished.
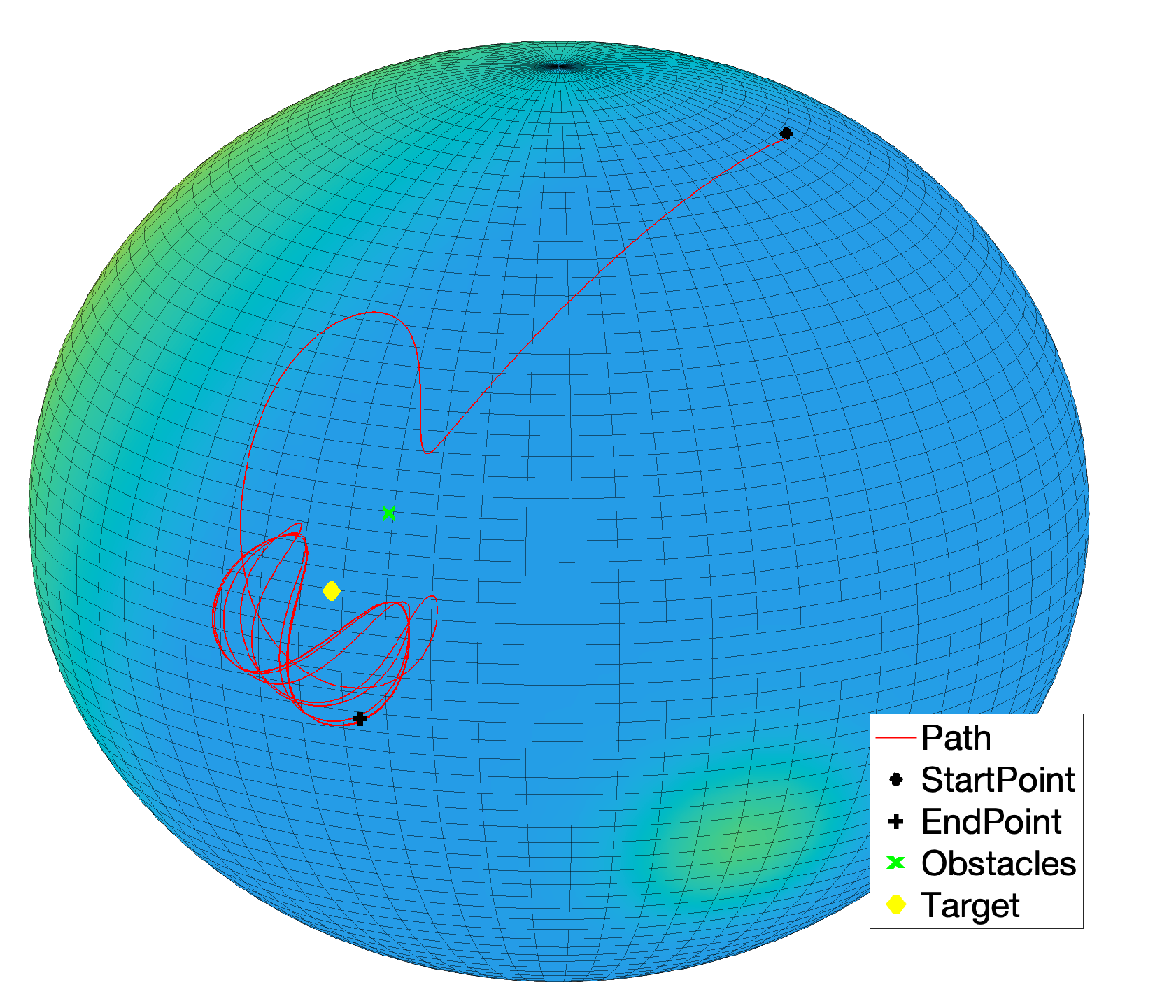
Setting suitable parameters values, the controlled system is able to reach the target also in the presence of two (or more) obstacles, by avoiding the virtual potential bump, as illustrated in
Figure 19.
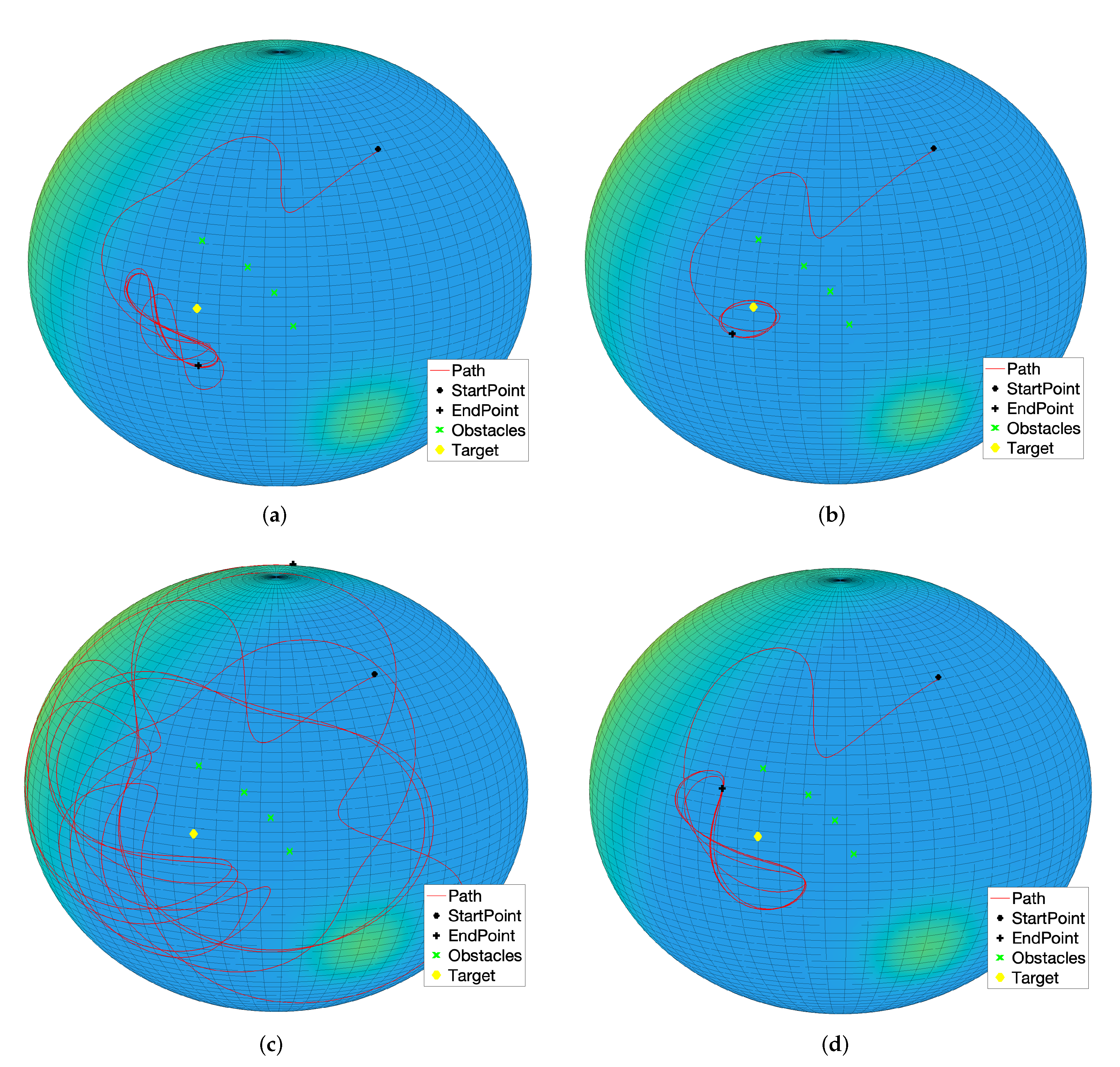
Even in the present set of experiments concerning the M-VARP control method, it is interesting to observe how the controlled system behaves when a barrier made of pointwise obstacles is placed between the starting location and the target.
Figure 20a illustrates how the controlled dynamical system is able to get around a barrier in order to reach the target. From this figure it is readily appreciated how the controlled agent is unable to get close to the target since the range of influence of the obstacles and their repulsive potentials exert a strong action. By setting lower values for both the repulsive range parameter and the repulsive magnitude of the obstacles makes the controlled system get closer and turn around the target, as illustrated in
Figure 20b.
By increasing both the repulsive strength of the obstacles and the self-propelling coefficient, the system will loose control and will start a rapid oscillatory behavior around the barrier and the target, as it can be observed from
Figure 20c. It is interesting to notice that, despite the system propulsion induced by the self-propelling term is way stronger than necessary and the system’s state wanders all over the sphere, yet the agent will never hit the barrier. To make the trajectory smoother and bound to the target, it pays to set a higher attractive magnitude for the target in order to counteract the self-propelling term. Such a conclusion may be drawn by observing the simulation result presented in the
Figure 20d.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



















