
Internal Similarity Network for Rejoining Oracle Bone Fragment Images


Abstract
:1. Introduction
2. Related Work
2.1. Rejoining Method Based on Local Edge Matching Algorithm
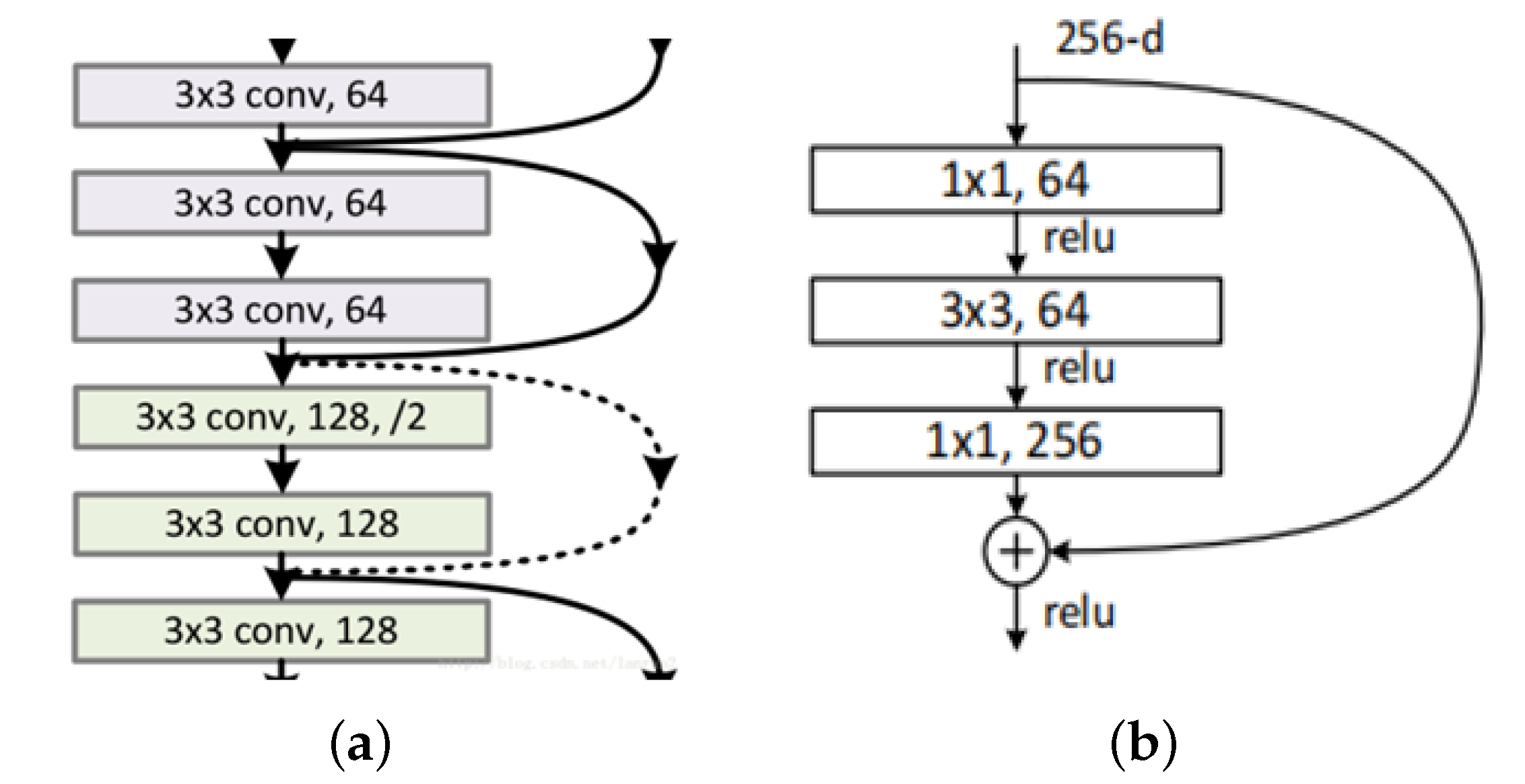
2.2. Residual Network Model
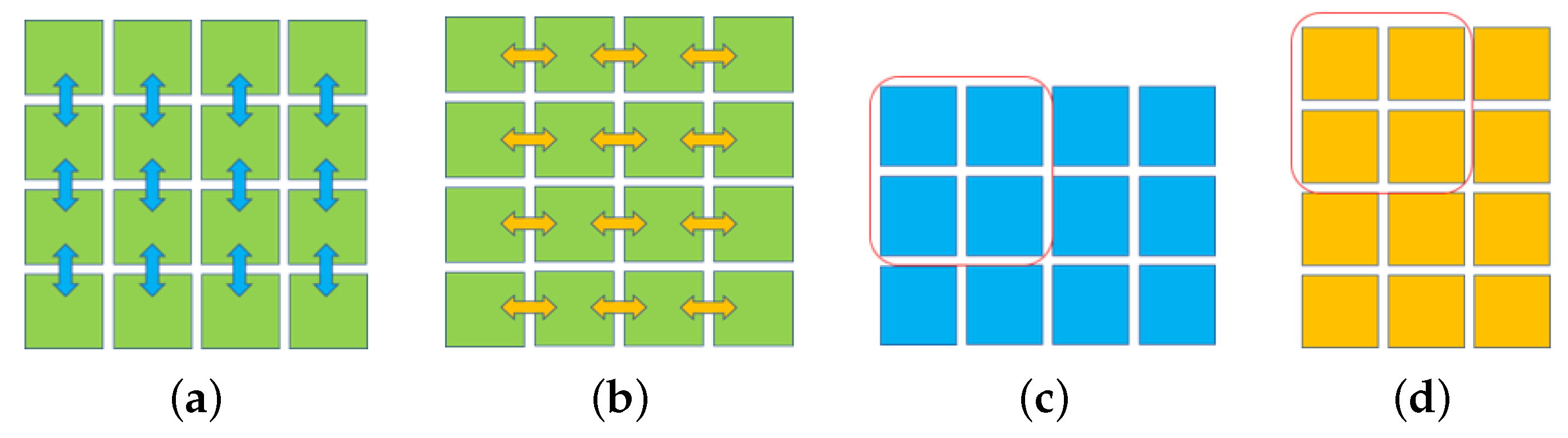
2.3. Image’S Internal Dissimilarity
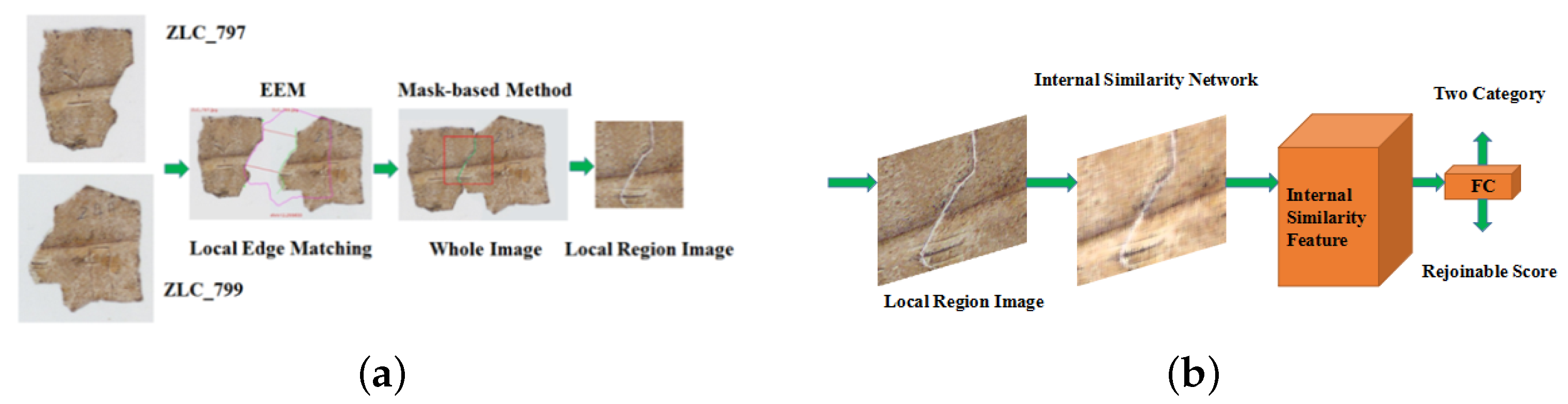
3. Methodology
- (1)
- Image edge equidistance matching (EEM) algorithm was applied to search matching edge segments in the oracle bone fragment image set.
- (2)
- Target-mask-based stitching method was proposed to put two images into a whole. The part of the whole image with matching edge segments, named the local region image (LRI), was cut from the whole image to extract the feature.
- (3)
- A convolution feature gradient map (CFGM) was designed to extract the texture feature of a local region image; it was embedded into a residual network to increase its stability.
- (4)
- An internal similarity pool (ISP) was given to compute the internal similarity of CFGM; after that, a full connection layer was used to give a score of the CFGM’s internal simialrity.
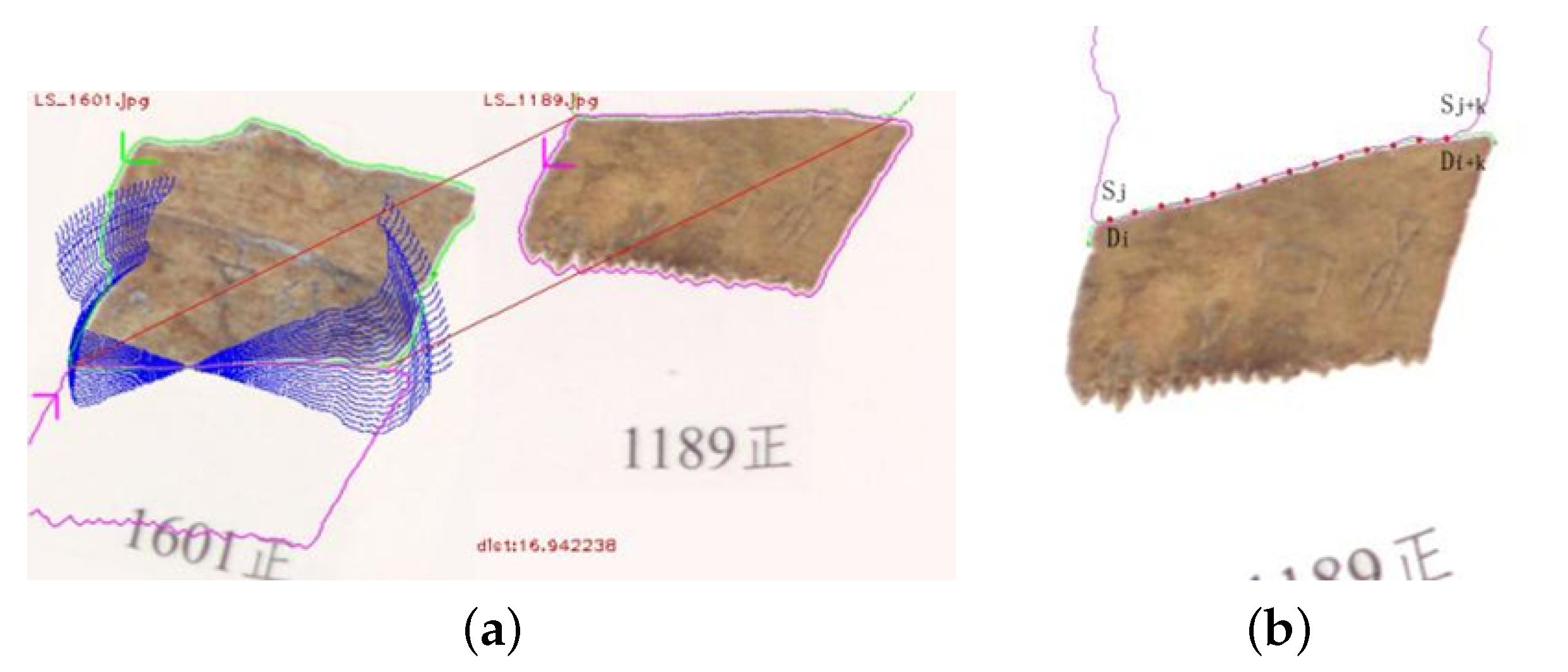
3.1. Local Edge Matching Algorithm
3.1.1. Image Preprocessing
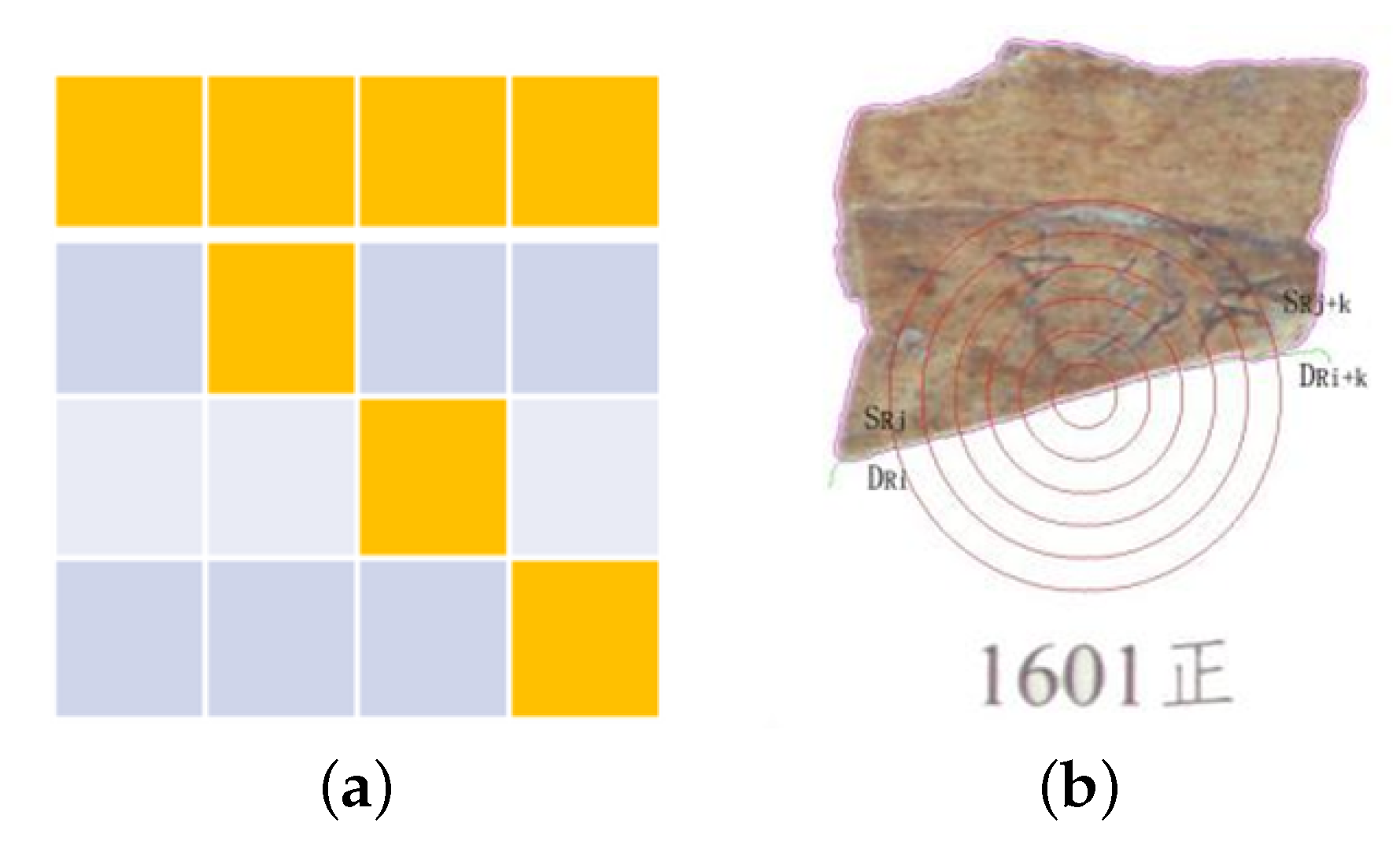
3.1.2. Image Edge Equal Pixel Matching Algorithm
3.1.3. Image Edge Equidistance Matching Algorithm
3.1.4. Image Rejoining Method
3.2. General Scheme
3.3. Internal Similarity Pooling
4. Experiment Verification
4.1. Experiment Platform and Dataset
4.2. Experimental Effect and Analysis
4.2.1. Performance of Edge Equidistance Matching
4.2.2. Convolution Feature Gradient Map Analysis
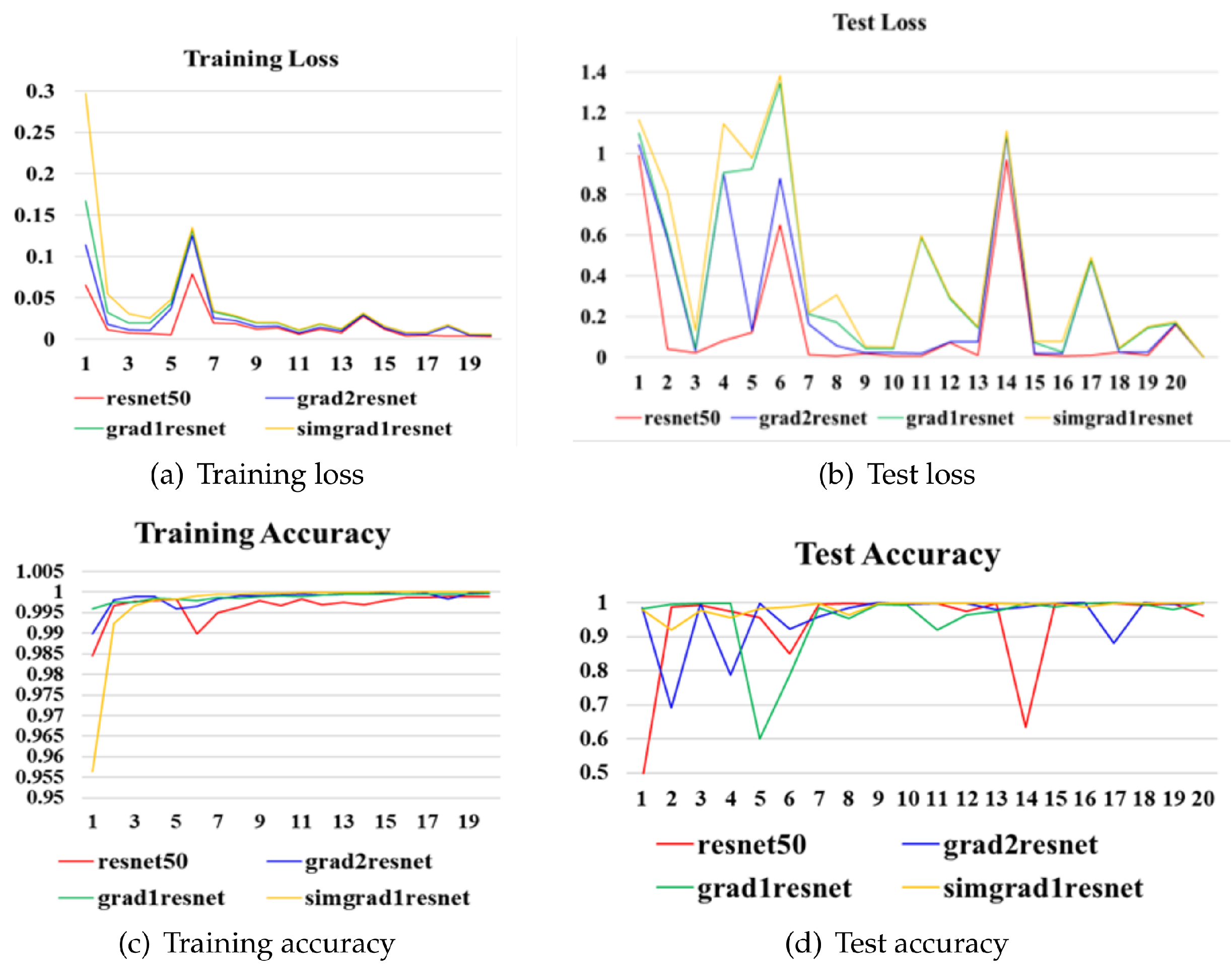
4.2.3. Performance of Different Models
4.3. Actual Rejoining Work
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Rejoinable Image Pairs Searched from LS Imageset

References
- Liu, Y.; Wang, T.; Wang, J. The Application of the Technique of 2D Fragments Stitching Based on Outline Feature in Rejoining Oracle Bones. In Proceedings of the International Conference on Multimedia Information Networking and Security, Nanjing, China, 4–6 November 2010; pp. 964–968. [Google Scholar]
- Alahi, A.; Ortiz, R.; Vandergheynst, P. FREAK: Fast retina keypoint. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 510–517. [Google Scholar]
- Kamran, H.; Zhang, K.; Li, M.; Li, X. An LCS-based 2D Fragmented Image Reassembly Algorithm. In Proceedings of the 13th International Conference on Computer Science and Education, Colombo, Sri Lanka, 8–11 August 2018; pp. 1–6. [Google Scholar]
- Zhang, Q.; Li, L.; Fang, R.; Xin, H. Reassembly of Two-Dimensional Irregular Fragments by Improved Polygon Feature Matching. In Proceedings of the IEEE 11th International Conference on Advanced Infocomm Technology, Jinan, China, 18–20 October 2019; pp. 82–85. [Google Scholar]
- Liu, W.; Wang, J.; Liu, K. Longitudinal Shredded Paper Stitching Method Based on Edge Matching. Comput. Mod. 2019, 2, 55–59. [Google Scholar]
- Zhang, M.; Chen, S.; Shu, Z.; Xin, S.; Zhao, J.; Jin, G.; Zhang, R.; Beyerer, J. Fast Algorithm for 2D Fragment Assembly Based on Partial EMD. Vis. Comput. 2016, 33, 1–12. [Google Scholar] [CrossRef]
- Paumard, M.; Picard, D.; Tabia, H. Deepzzle: Solving Visual Jigsaw Puzzles with Deep Learning and Shortest Path Optimization. Trans. Image Process. 2020, 29, 3569–3581. [Google Scholar] [CrossRef] [PubMed]
- Le, C.; Li, X. JigsawNet: Shredded Image Reassembly Using Convolutional Neural Network and Loop-Based Composition. IEEE Trans. Image Process. 2019, 28, 4000–4015. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ngo, T.; Nguyen, C.; Nakagawa, M. A Siamese Network-based Approach for Matching Various Sizes of Excavated Wooden Fragments. In Proceedings of the 17th International Conference on Frontiers in Handwriting Recognition, Dortmund, Germany, 8–10 September 2020; pp. 307–312. [Google Scholar]
- Cécilia, O.; Beurton, M. Matching Ostraca Fragments Using A Siamese Neural Network. Pattern Recognit. Lett. 2020, 131, 336–340. [Google Scholar]
- Cécilia, O.; Beurton-Aimar, M. Using Graph Neural Networks to Reconstruct Ancient Documents. In Proceedings of the 25th International Conference on Pattern Recognition, Milan, Italy, 13 November 2020. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception–V4, Inception–ResNet and the Impact of Residual Connections on Learning. In Proceedings of the 31st AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 23 February 2016; pp. 4278–4284. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Ruiz, L.; Gama, F.; Marques, A.G.; Ribeiro, A. Invariance-Preserving Localized Activation Functions for Graph Neural Networks. IEEE Trans. Signal Process. 2020, 68, 127–141. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Jian, S. Identity Mappings in Deep Residual Networks. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 630–645. [Google Scholar]
- Jegou, H.; Douze, M.; Schmid, C. Product Quantization for Nearest Neighbor Search. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 117–128. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, Z.; Yang, D. Internal and External Similarity Aggregation Stereo Matching Algorithm. In Proceedings of the 11th International Conference on Digital Image Processing, Guangzhou, China, 10–12 May 2019; p. 1117923. [Google Scholar]
- Felzenszwalb, P.F.; Huttenlocher, D.P. Efficient Graph-Based Image Segmentation. Int. J. Comput. Vis. 2004, 59, 167–181. [Google Scholar] [CrossRef]
- Mei, X.; Sun, X.; Dong, W.; Wang, H.; Zhang, X. Segment-tree based cost aggregation for stereo matching. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 313–320. [Google Scholar]
- Zhang, Z.; Wang, Y.T.; Li, B.; Guo, A.; Liu, C.L. Deep Rejoining Model for Oracle Bone Fragment Image. In Proceedings of the Asian Conference on Pattern Recognition, Jeju Island, Korea, 9–12 November 2021; Part II; pp. 3–15. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image Pair | Distance | Image Pair | Distance | Image Pair | Distance |
|---|---|---|---|---|---|
| ZLC_46 | 15.63 | ZLC_216 | 20.02 | ZLC_797 | 12.26 |
| ZLC_77 | ZLC_1398 | ZLC_799 | |||
| ZLC_1291 | 18.71 | ZLC_83 | 13.13 | ZLC_255 | 13.95 |
| ZLC_493 | ZLC_1244 | ZLC_257 | |||
| ZLC_1132 | 11.48 | ZLC_1641 | 16.96 | ZLC_1851 | 10.65 |
| ZLC_1144 | ZLC_1651 | ZLC_1878 | |||
| ZLC_1045 | 9.65 | ZLC_1230 | 9.71 | ZLC_1183 | 9.24 |
| ZLC_1111 | ZLC_1253 | ZLC_1207 |
| Methods | Accuracy | Loss | Time(s/Batch) |
|---|---|---|---|
| AlexNet | 83.39% | 0.4489 | 1.41 |
| VGG19 | 83.49% | 0.4480 | 15.37 |
| ResNet50 | 99.63% | 0.0126 | 13.46 |
| InceptionV3 | 99.68% | 0.0112 | 8.12 |
| MobileNet | 99.68% | 0.0108 | 6.78 |
| ISN | 99.98% | 0.0001 | 7.67 |
| Methods | Accuracy | Loss |
|---|---|---|
| AlexNet | 83.69% | 0.4447 |
| VGG19 | 83.38% | 0.4499 |
| ResNet50 | 95.66% | 3.2104 |
| InceptionV3 | 62.39% | 2.0513 |
| MobileNet | 90.90% | 0.1598 |
| ISN | 99.79% | 0.0089 |
| Methods | Pairs | Confidence | Probability |
|---|---|---|---|
| AlexNet | 11 | 83.76% | 91.67% |
| VGG19 | 11 | 83.34% | 91.67% |
| ResNet50 | 10 | 89.07% | 83.33% |
| InceptionV3 | 8 | 66.29% | 66.66% |
| MobileNet | 11 | 96.86% | 91.67% |
| ISN | 11 | 94.23% | 91.67% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Guo, A.; Li, B. Internal Similarity Network for Rejoining Oracle Bone Fragment Images. Symmetry 2022, 14, 1464. https://doi.org/10.3390/sym14071464
Zhang Z, Guo A, Li B. Internal Similarity Network for Rejoining Oracle Bone Fragment Images. Symmetry. 2022; 14(7):1464. https://doi.org/10.3390/sym14071464
Chicago/Turabian StyleZhang, Zhan, An Guo, and Bang Li. 2022. "Internal Similarity Network for Rejoining Oracle Bone Fragment Images" Symmetry 14, no. 7: 1464. https://doi.org/10.3390/sym14071464
APA StyleZhang, Z., Guo, A., & Li, B. (2022). Internal Similarity Network for Rejoining Oracle Bone Fragment Images. Symmetry, 14(7), 1464. https://doi.org/10.3390/sym14071464