1. Introduction
Surface defect detection is of great significance to product quality and has been widely used in many important industrial fields such as automobiles, railroad tracks, and aerospace engines. The traditional surface defect detection is performed by human eyes, which is time-consuming and low precision. In recent years, the deep learning methods have been widely used in the field of surface defect detection. However, due to the influence of high curvature or inconsistent surface reflection characteristics, there is uneven illumination on the surface defect image, which seriously affects the accuracy of the subsequent surface defect detection task.
To solve this problem, a simple preprocessing method based on the histogram transform is often used to correct uneven illumination, such as contrast limited adaptive histogram equalization (CLAHE) [
1], gamma correction (GC) [
2], logarithmic transformation, contrast stretching transformation, and normalization. The advantage of these methods is that they have low computational complexity and can directly improve the uneven grayscale distribution of the image. However, these methods can only alleviate the influence of uneven illumination on the defective image and may also introduce noise interference after preprocessing, which is not conducive to downstream defect detection tasks.
Recently, convolutional neural networks (CNNs) have been widely applied in image processing, including illumination correction [
3,
4]. Such models learn the relationship between image pairs with uneven and normal illumination via an end-to-end approach. Popular network structures, such as fully convolutional networks (FCNs) and encoder–decoder networks, have achieved good results when applied for uneven illumination correction. However, it is difficult to obtain uneven/normal illumination image pairs in an industrial context. Furthermore, deep-learning-based methods exhibit a strong dependence on the training dataset, and therefore, the difficulty of data acquisition has greatly restricted their application in complex scenarios.
The retinex model is the current mainstream illumination model [
5]. According to retinex theory, an image can be essentially regarded as the product of an illumination component and a reflection component. Finding the solution to this model is an ill-conditioned inverse problem, and prior knowledge of certain constraints needs to be introduced. Scholars have designed many physical priors about the illumination and reflection components to constrain the solution space of the retinex model, which can effectively realize uneven illumination image enhancement.
Notably, previous studies on retinex-based defect image enhancement methods still have the following disadvantages in industrial scenarios:
(1) The current methods cannot effectively retain important defect information while eliminating uneven background illumination.
(2) Existing methods require multiple iterations to complete the uneven illumination enhancement of images and consequently cannot meet industrial real-time requirements.
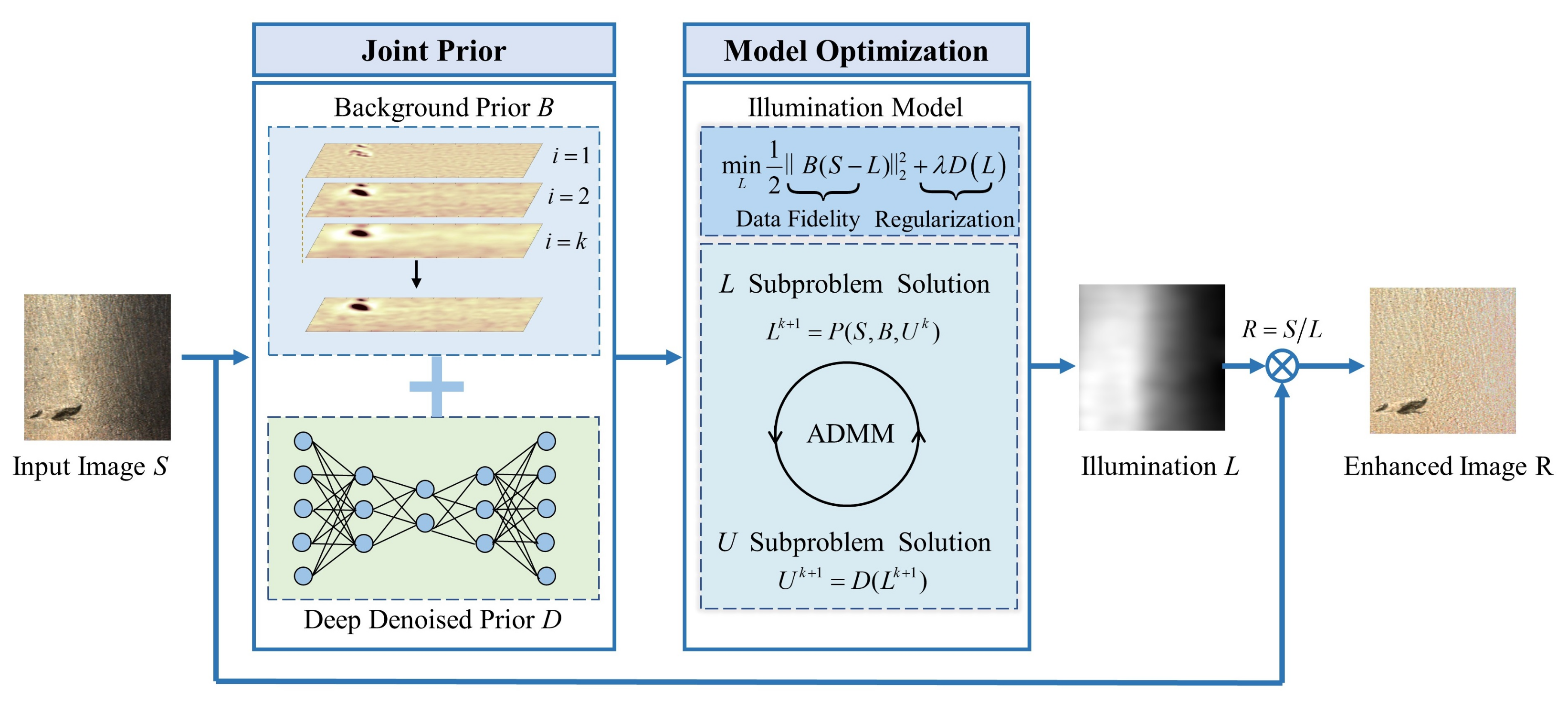
This paper proposes a joint-prior-based image enhancement algorithm for uneven illumination correction that can quickly and effectively realize the effective enhancement of images with uneven illumination. First, we design a simplified retinex semi-coupled model to transform the uneven illumination enhancement problem into an accurate estimation of illumination components. Then, a multiscale Gaussian difference-based background prior (BP) is proposed to avoid defect information loss by introducing semantic information. A deep denoising prior (DDP) is also designed to replace the physical prior knowledge in the existing model, such as the L2-norm, etc., to realize the efficient and fast solution of the retinex models. Finally, the effectiveness of the proposed algorithm is verified on public and private datasets. By comparing the defect images and enhanced results in a symmetric way, it can be found that our method is more conducive to downstream visual inspection tasks than state-of-the-art uneven illumination enhancement methods. In summary, our main contributions can be described as follows:
(1) We develop a novel joint prior retinex model to accurately remove uneven illumination in surface defect images. This method can effectively retain defect information while accurately eliminating uneven illumination.
(2) Considering the multiscale characteristics and low semantics of industrial defect images, we propose a formulation of background prior knowledge based on multiscale Gaussian differences to suppress the loss of defect information in the enhanced image.
(3) Taking full advantage of the powerful feature expression ability of deep learning, we propose an illumination constraint based on a depth prior to realize a fast iterative solution process for the illumination model.
(4) Experiments on public and private defect datasets demonstrate that our JPUIE method achieves better performance than previous competitive methods for uneven illumination enhancement.
The remainder of the article is organized as follows. The related work on the retinex model is discussed in
Section 2.
Section 3 describes the proposed method in detail.
Section 4 presents the experimental results in comparison with those of different start of-the-art methods. Finally, the conclusion and future work are summarized in
Section 5.
2. Related Works
The retinex model [
6] is mainly used to solve the problems of uneven illumination and color deviation in digital images. It is also widely used in image processing tasks such as haze images and underwater images to obtain high contrast images. The retinex model regards an image
as the product of an illumination component and a reflection component:
where
denotes the scene illumination component,
is the component representing the reflection from the surface of the imaged object, and ∘ denotes the elementwise multiplication. The uneven illumination image enhancement methods based on the retinex model can be divided into two categories: the model-driven methods and the data-driven methods.
The model-driven methods consider the local smoothness property of the illumination component and the piecewise constant property of the reflection component. Many prior-knowledge-guided uneven illumination enhancement algorithms have been proposed. Kimmel et al. [
7] proposed a pyramid-based retinex variational model using the L2-norm to constrain the illumination and reflection components and finally applied the alternating direction method of multipliers (ADMM) to optimize the solution. Subsequently, Fu et al. [
8] proposed the WVM, a probabilistic method for simultaneously estimating retinex models, by adding exponentially weighted coefficients to the regularization term to enhance the estimation of the illumination/reflection components in the logarithmic domain. To accelerate the solution of the model, Guo et al. [
9] proposed an illumination estimation model based on maximum illumination initialization. They used gradient descent as the approximation method to optimize the solution. The above methods focus on solving the retinex model in the logarithmic domain. However, Gu et al. [
10] believed that the estimation of the reflection component in the logarithmic domain would cause the loss of image details, so they proposed a retinex model solution method based on the image domain. Subsequently, the authors [
11] proposed a retinex model with a fractional-order regularization term, which allows the original details of the image to be preserved by optimizing either the traditional first-order regularization term or a second-order regularization term. On this basis, Dai et al. [
12] introduced illumination initialization constraints and added multiexposure image fusion technology to achieve detail preservation after illumination enhancement. Similarly, Yue et al. [
13] introduced a local smoothness constraint on the reflection component on the basis of the original model to achieve local contrast enhancement in the decomposed image. To further remove noise interference in the reflection component, Li et al. [
14] first proposed a retinex solution model with a structure of “illumination + reflection + noise”, which improved the effect of image decomposition through the addition of a noise constraint term. Ren et al. [
15] proposed a low-rank canonical retinex model named LR3M by incorporating the low-rank characteristics of the reflection component into the optimization model and proposed a corresponding optimization-based solution method.
The data-driven method mainly learns the complex relationship between high- and low-quality images, so as to enhance the low-quality images. Wei et al. [
16] proposed an illumination optimization network based on the retinex model for the first time. The network adopts a two-stage method to realize end-to-end image enhancement. Zhang et al. [
17] proposed a human–computer interactive illumination enhancement network, which is also inspired by the retinex model and consists of three modules: layer decomposition, reflectivity recovery, and illumination adjustment. Through training the images with different illumination levels, the characteristic information of low-quality images can be recovered. Then, Wang et al. [
18] proposed an underexposed image enhancement network, which is different from the previous methods. The network enhances the low light images by introducing intermediate illumination to correlate the input images and enhancement results.
4. Experiments and Analysis
To verify the effectiveness of the algorithm in this paper, a series of experiments is presented. First, the experiment details are introduced. Second, we compare the proposed method with seven state-of-the-art illumination correction methods on both public and private datasets. Third, an ablation study is carried out to investigate the effectiveness of the proposed method. All the experiments were conducted on a high-performance server, which was equipped with a dual NVIDIA Tesla P100 GPU, 40-core CPU 2.4 GHz, and 256 GB memory.
4.1. Experiment Details
We evaluated the performance of our proposed method on two surface defect datasets with uneven illumination, the Rail Surface Discrete Defect Dataset (RSDD) and the Motor Commutator Surface Defect Dataset (MCSD), and the details are as follows:
(1) RSDD: The RSDD Dataset is a public high-speed rail dataset. Due to the high curvature of rail surfaces, the grey distributions of rail images are uneven. We cropped the images in the original dataset to a size of 224 × 224 and adopted the data augmentation methods to increase the training samples. The dataset contains 1206 defect-free samples and 885 defective samples. We randomly divided the training set and the test set according to the ratio of 0.7:0.3.
(2) MCSD: The MCSD Dataset was collected on real production lines, as shown in
Figure 3. This dataset includes 1420 motor commutator images with a size of 256 × 256. To verify the segmentation accuracy, the corresponding ground-truth images were generated with the open-source annotation tool LabelMe. We divided the dataset into 994 training images and 426 test images.
We trained the proposed denoiser on the above defect image datasets with pytorch. In order to obtain the noisy/clean image pairs, we added Gaussian noise to the defect images. The noise deviation was empirically set to 50, which would obtain better performance. The proposed denoiser model was trained using the Adam optimizer with , , and the epoch and batch size were set to 300 and 24, respectively, while the learning rate was set to 10−3. We separately trained the denoiser model on the corresponding defect datasets. The parameter was used to balance the reconstruction loss and the total variation loss. Since the total loss was applied to train the denoised network, the weight of the reconstruction loss was more important than the total variation loss, so we set parameter to 0.1. The regularization parameter was used to balance the data fidelity term and the regularization term. When the value was large, the enhanced image could not guarantee the uniformity of the enhanced image. In this experiment, the parameter was set to 0.1.
4.2. Comparisons with State-of-the-Art Methods
We chose six popular algorithms for comparison, namely CLAHE, GC, GTV, LD, and STAR. For fairness, we tested the compared methods using the source code published by the authors and set the parameters to their default values.
4.2.1. Qualitative Analysis
Figure 4 and
Figure 5 show the enhancement results for images in the RSDD and MCSD Datasets, where
Figure 4a and
Figure 5a show the sample images and
Figure 4b–f and
Figure 5b–f show the results of the enhancement with the different methods. It can be seen that the compared methods cannot accurately eliminate uneven illumination or lose defect information. As for the CLAHE and GC methods, these methods aim to adjust the gray distribution to enhance the uneven illumination images and can partially alleviate the influence of uneven illumination. In particular, there are many artifacts in the CLAHE enhancement results, which interfere with the downstream defect detection tasks. JieP, GTV, LD, and STAR can effectively eliminate uneven illumination, because these methods are based on retinex theory. However, the results of LD still contain a certain degree of uneven illumination in the background. JieP, GTV, and STAR cause serious defect information loss after image enhancement, especially for large-area and high-contrast defect images. In comparison, our method generates the best image enhancement results, with the resulting images showing more consistent backgrounds and more defect information compared to the results of the other methods.
4.2.2. Quantitative Analysis
To evaluate the effectiveness of our image enhancement method on the downstream defect defection task, we employed two popular semantic segmentation models, UNet [
30] and PSPNet [
31], which are widely used in industrial scenarios for defect detection. The defect images with uneven illumination were directly fed into the segmentation models, serving as the baseline. For comparison, the original defect images were first enhanced by different enhancement methods, then the enhanced results were fed into the segmentation models. Due to space limitations, we show the defect detection results before and after image enhancement with the UNet model in
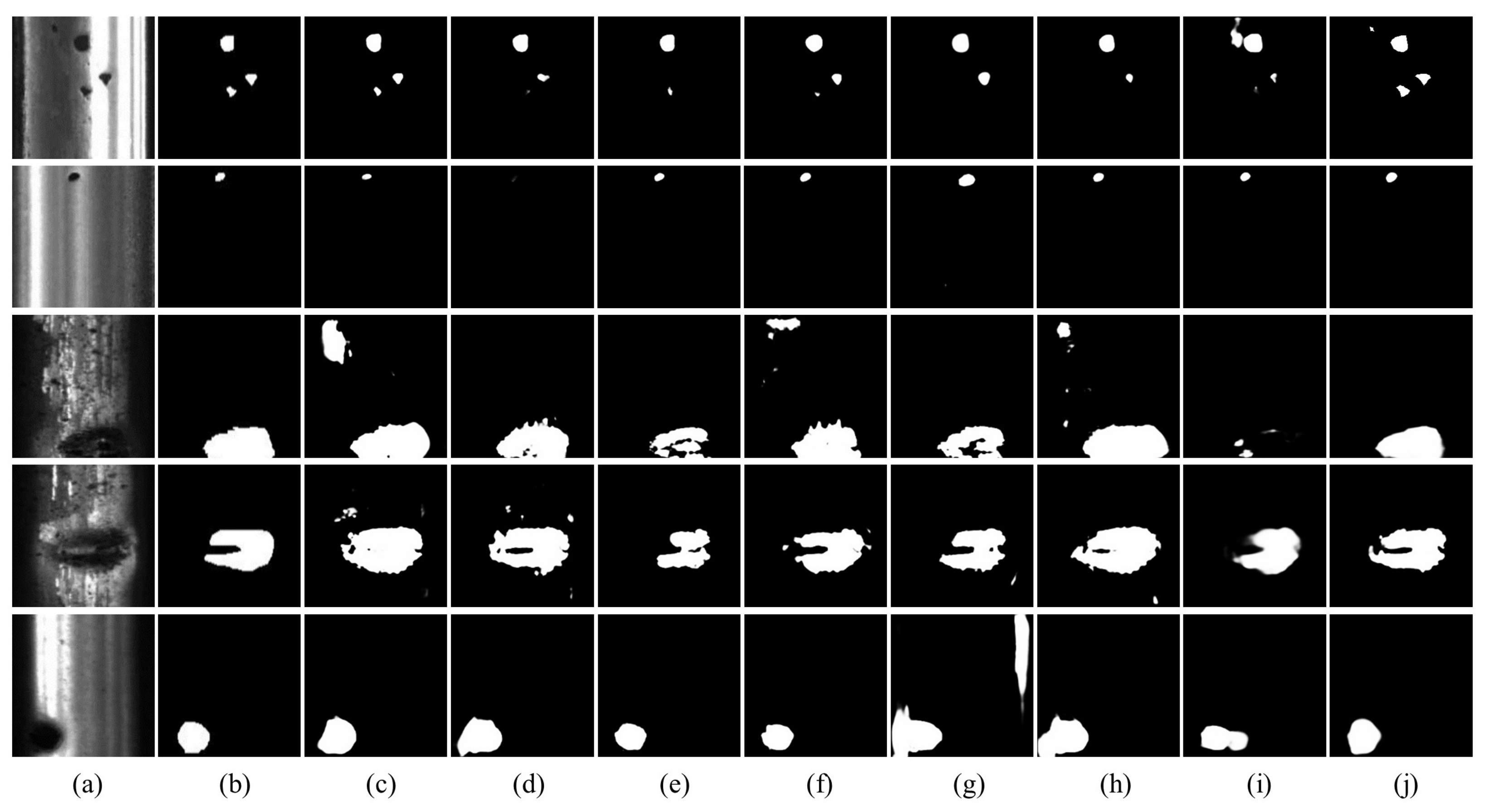
Figure 6 and
Figure 7. It can be seen that the defect images without the enhancement operation failed to obtain high performance. In contrast, the defect images enhanced by our method are more cognizable to achieve finer segmentation result.
In addition, to quantitatively analyze the segmentation performance, we employed the IOU metric to evaluate the defect detection accuracy [
32].
Table 2 summarizes the detection results. On the whole, our method achieved the best detection performance compared with the other enhancement methods. Specifically, on the RSDD Dataset, the IOU index of our method was 3.1% and 4.3% higher than the second best, respectively. On the MCSD Dataset, the IOU index of our method was 1.2% and 2.1% higher than the second best, respectively. There are two aspects worth noting. First, compared to the original defect images, the enhanced results by our methods had better detection performance, which proves that the proposed enhancement method is beneficial to the downstream defect detection task. Second, not all enhancement algorithms can improve the downstream image enhancement accuracy, because some methods cannot accurately eliminate the uneven illumination or lose important defect information during the enhancement process, which will hamper the defect detection performance.
4.2.3. Running Time
To verify the computational complexity of the proposed algorithm, we tested the inference time on the MCSD sample images of size 256 × 256. The average inference times of CLAHE, GC, JieP, GTV, LD, STAR, and the proposed method are shown in
Table 3. Although the inference time of the proposed method was not the shortest, compared with CLAHE and GC, it can reach 0.112 s per image, meeting the real-time requirements of industrial scenarios. Compared with other retinex-based image enhancement methods, the proposed method greatly shortens the time consumption. There are two main reasons for the runtime superiority of our method: (1) we adopted a semi-decoupled retinex model, which can shorten the algorithm time by nearly half, and (2) we used the deep denoised prior, which has a stronger regularization constraint effect, leading to faster iterative convergence.
4.3. Ablation Study
We performed several ablation studies on MCSD to demonstrate the effectiveness of the deep denoised prior and background prior in our method:
(1) The effect of the deep denoised prior: A deep denoised prior aims to efficiently and effectively realize the smoothness constraint of the estimated illumination images. To verify the effectiveness of the deep denoiser prior, we took the simplified semi-coupled retinex model with an L1-norm regularization term (SCR) as the baseline and then replaced the L1-norm regularization term with other denoiser priors, such as BM3D, Dncnn, and our deep denoiser prior DDP, respectively. The corresponding retinex decomposition results are shown in
Figure 8b–e. It can be seen that the illumination images obtained by the compared denoiser prior contained a large amount of texture information or artificial artifacts, which led to the loss of fine details in the estimated reflectance images. In contrast, our estimated illumination images were more piecewise smooth, and the detail information can be effectively preserved after image enhancement. The defect detection results of different denoising priors are displayed in
Table 4; we can find that the deep denoiser prior has better performance than the other denoiser priors. This phenomenon shows that the proposed deep denoiser prior is more suitable for uneven illumination image enhancement.
Further, we analyzed the convergence properties of different denoising priors. The iterative curve of the estimated illumination images are shown in
Figure 9; it can be seen that the iterative processes of different denoising priors are all monotonically convergent. The deep denoiser prior has the fastest convergence speed, which only needs six iterations to converge and obtain the decomposed results.
(2) The effect of the background prior: The background prior (BP) is used to prevent the loss of defect information after image enhancement.
Figure 8f shows the retinex decomposition results with background priors. It can be seen that there is no residual defect information in the estimated illumination image, which effectively retains the defect information in the reflectance image. As shown in
Table 4, after adding the background prior, the IoU also increased from 0.752 to 0.767. This proves that the background prior is conducive to subsequent defect detection tasks.
5. Conclusions
In this paper, we proposed a novel uneven illumination image enhancement method JPUIE for surface defect detection. In our JPUIE, we transformed the uneven illumination enhancement problem into a problem of accurate illumination estimation and established a simplified and effective semi-coupled retinex illumination model. Then, the semantic information was introduced to establish the background prior, so as to avoid the loss of defect information after image enhancement. The deep denoised prior is designed to improve the optimization efficiency of the proposed retinex model. Finally, we presented adequate quantitative and qualitative experiments to compare our method with state-of-the-art uneven illumination enhancement approaches. To verify the generalization of our method, all the experiments were carried out on a public defect image dataset RSDD and a real defect image dataset MCSD. The experimental results showed that the defect images enhanced by our method had the highest defect detection accuracy compared with other enhancement methods, and this proved that our method is superior to other methods in improving image quality.
In the future, we will consider a variety of image distortion types, such as defocus blur, noise, etc. and establish a unified image enhancement method to improve the image quality in complex industrial scenes.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}