

Toward Efficient Intrusion Detection System Using Hybrid Deep Learning Approach


Abstract
:1. Introduction
- The development of an innovative yet effective, robust, and proficient threat detection system, which implements IDS using a recurrent neural network based on gated recurrent units (GRUs) and improved long short-term memory (LSTM) through a computing unit.
- Clearly explains the purpose of time units in memory elements of LSTM and GRUs in attack detection, which is not present in similar studies, to the best of our knowledge.
- This system is applied to the optimum set of features of the latest CICIDS2018 dataset containing multiple types of cyber threats and attacks. This is to ensure the efficiency of the proposed IDS model in terms of accuracy and optimal complexity.
- Massive evaluation metrics are used for an exhaustive assessment of the proposed technique, including the precision, recall, detection accuracy, F1-score, true positive rate (TPR), true negative rate (TNR), and negative predictive value (NPV).
- The results are benchmarked with several prominent research studies to demonstrate the promising results of the proposed model.
- Finally, the proposed approach has recorded the highest accuracy and negligible FAR compared with many current studies.
2. Related Work
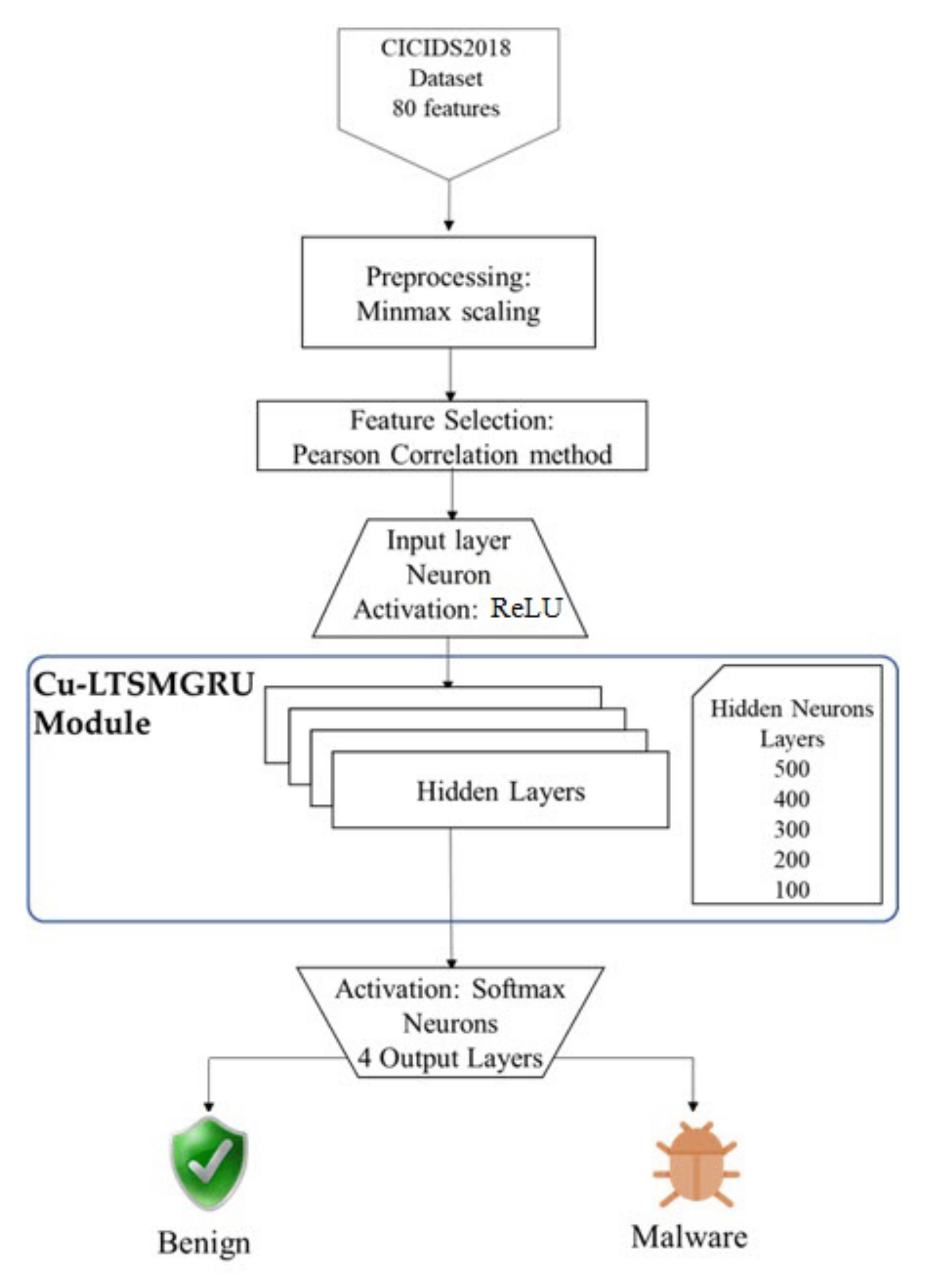
3. Methodology
3.1. Feature Selection
3.2. System Components
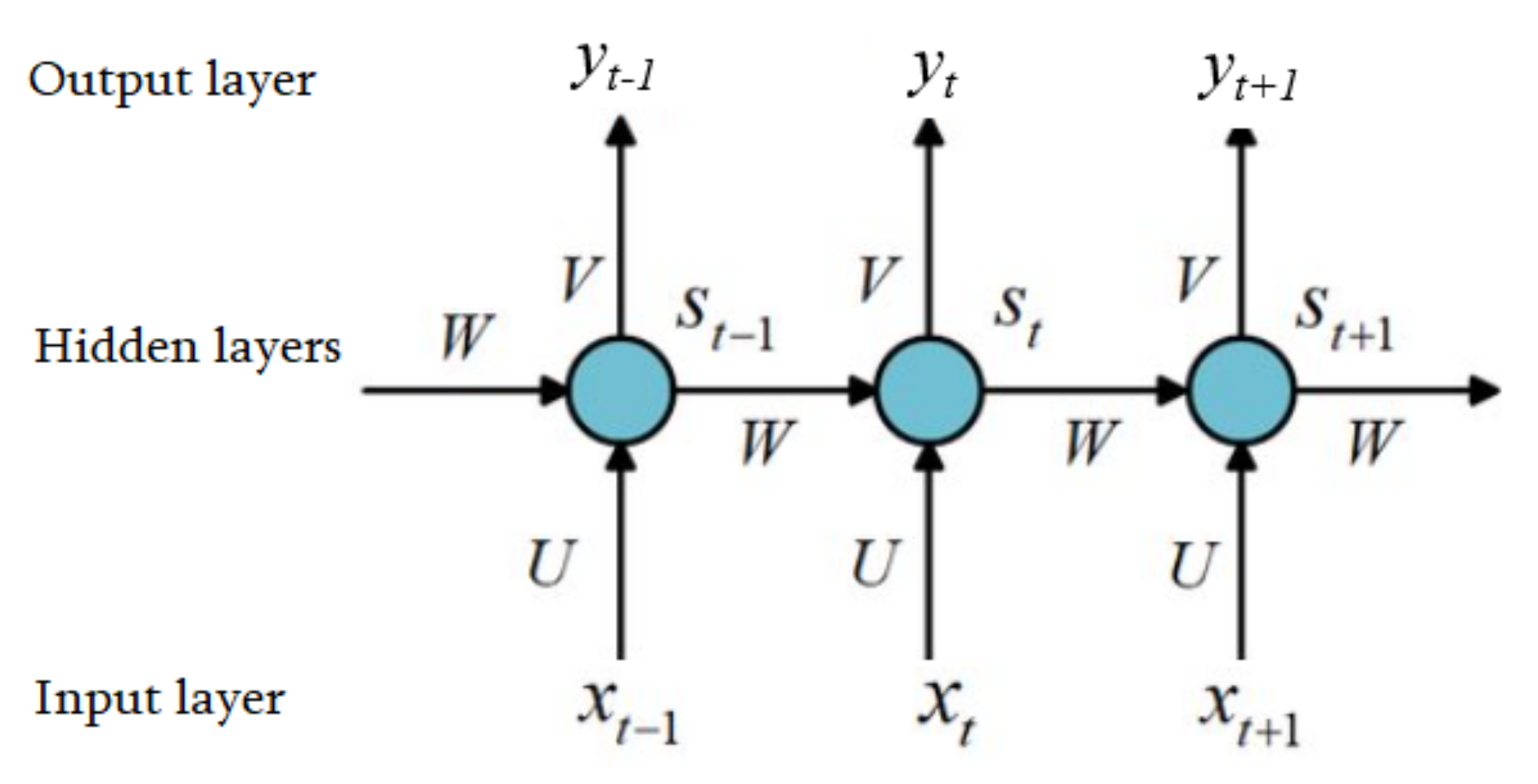
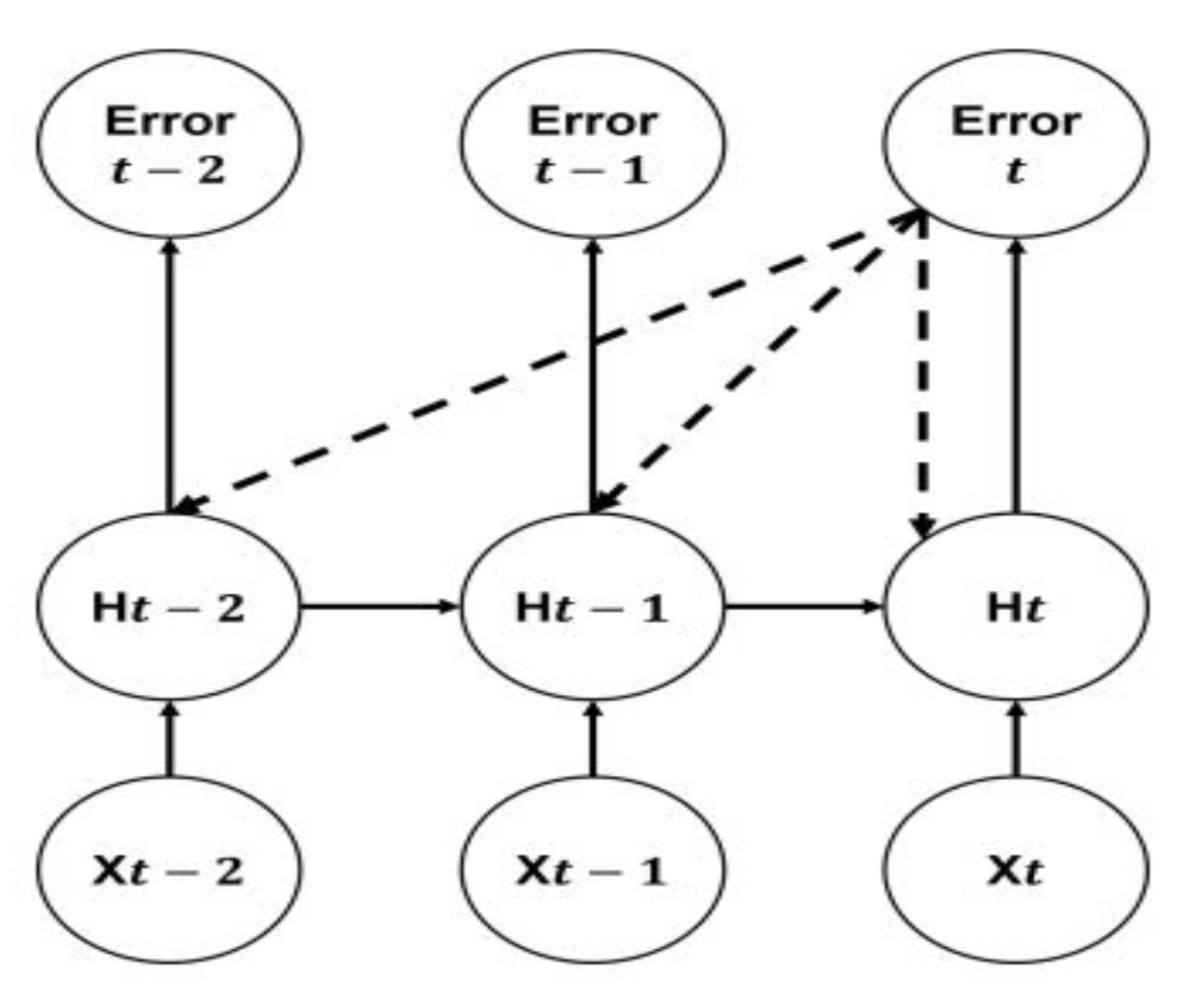
3.2.1. Recurrent Neural Network
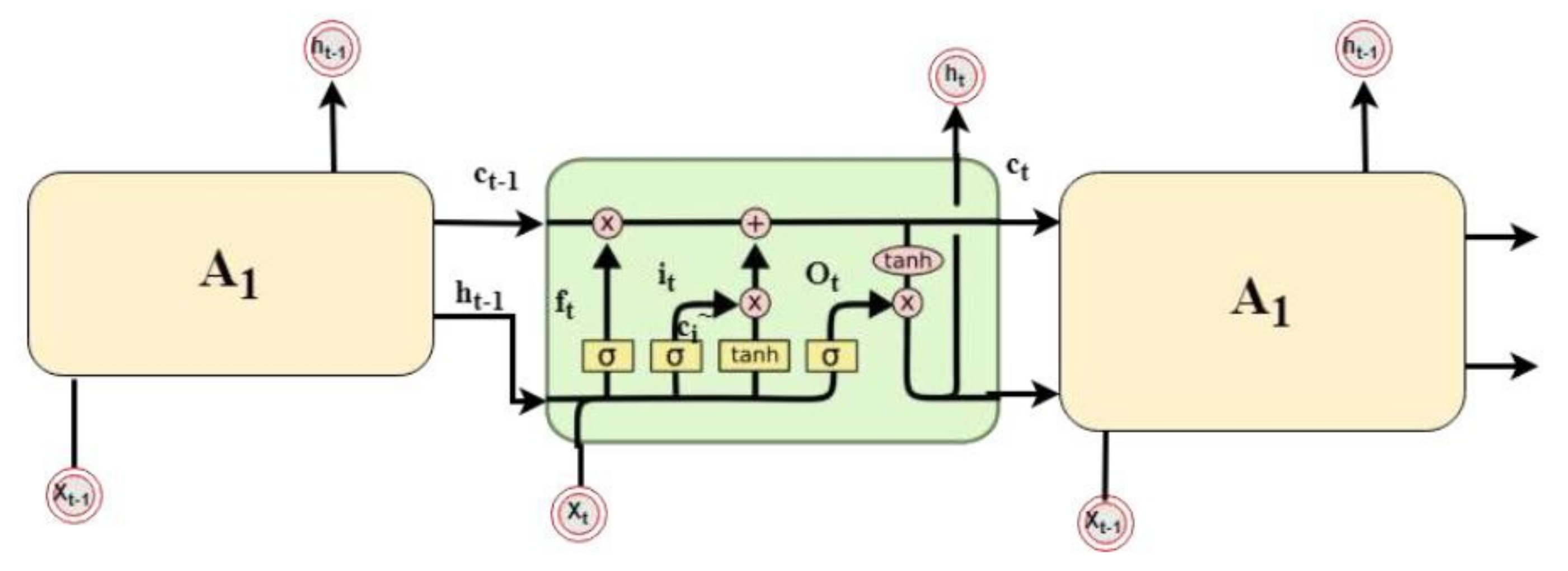
3.2.2. LSTM Neural Network
- LSTM has two types of activation functions: The first one is tanh, which is the most common one. Its output values range from −1 to 1. This function regulates the network data flow and avoids the exploding gradient phenomena. The function is defined as follows:The second type of activation function is the sigmoid activation functions. Its output values range from −1 to 1 to allow irrelevant information to be discarded by the neural network. The sigmoid activation function is defined as follows:
- Hidden state and cell state: The hidden state in the classical RNN architecture has two usages: it is used as a memory of the network and as an output of the hidden layer of the network. In addition to the hidden stats, the LSTM networks implement a cell state. The hidden state in RNN serves as a short-term working memory, while in LSTM, the cell state is used as a long-term memory to store important data from the past.
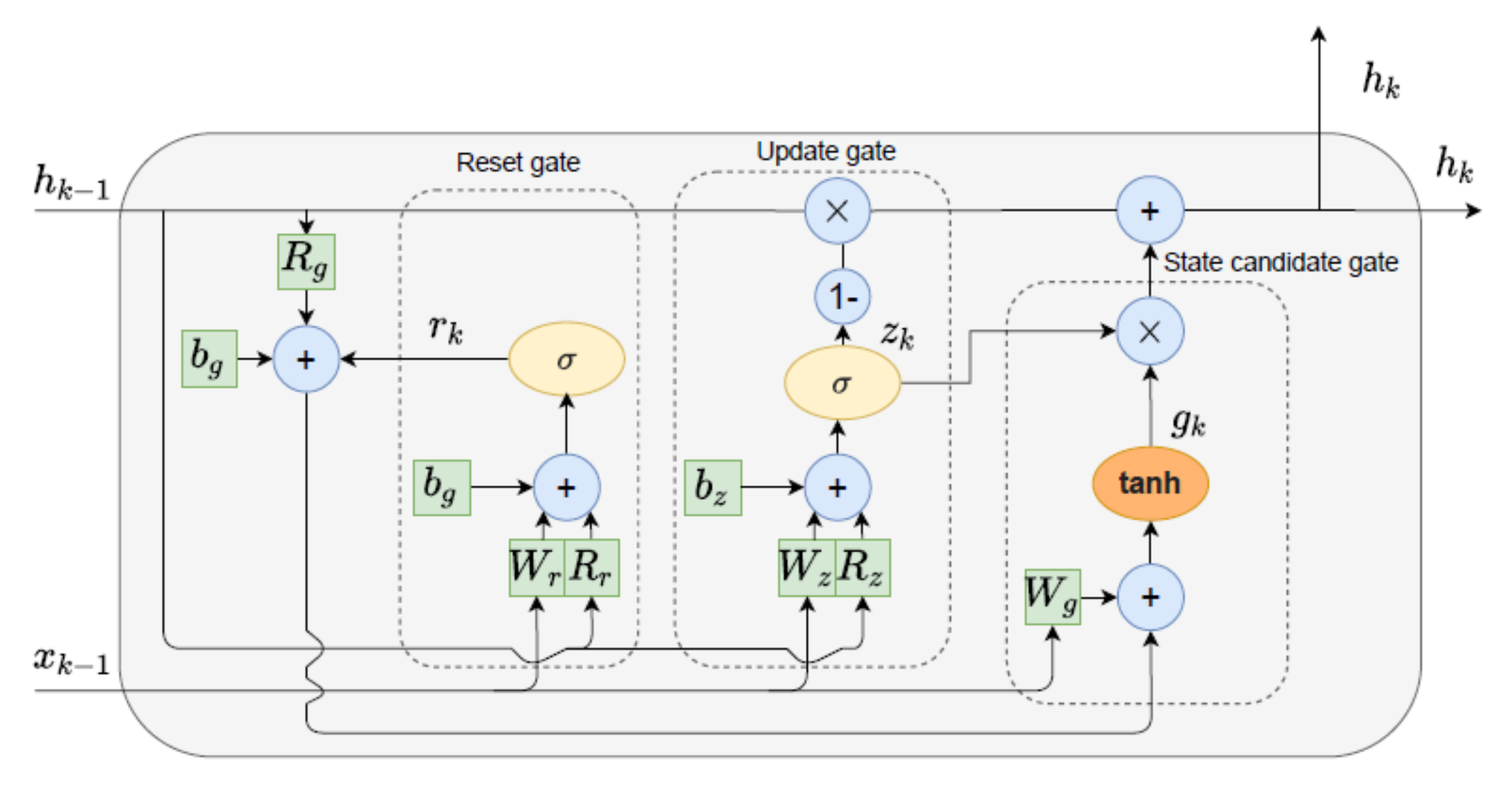
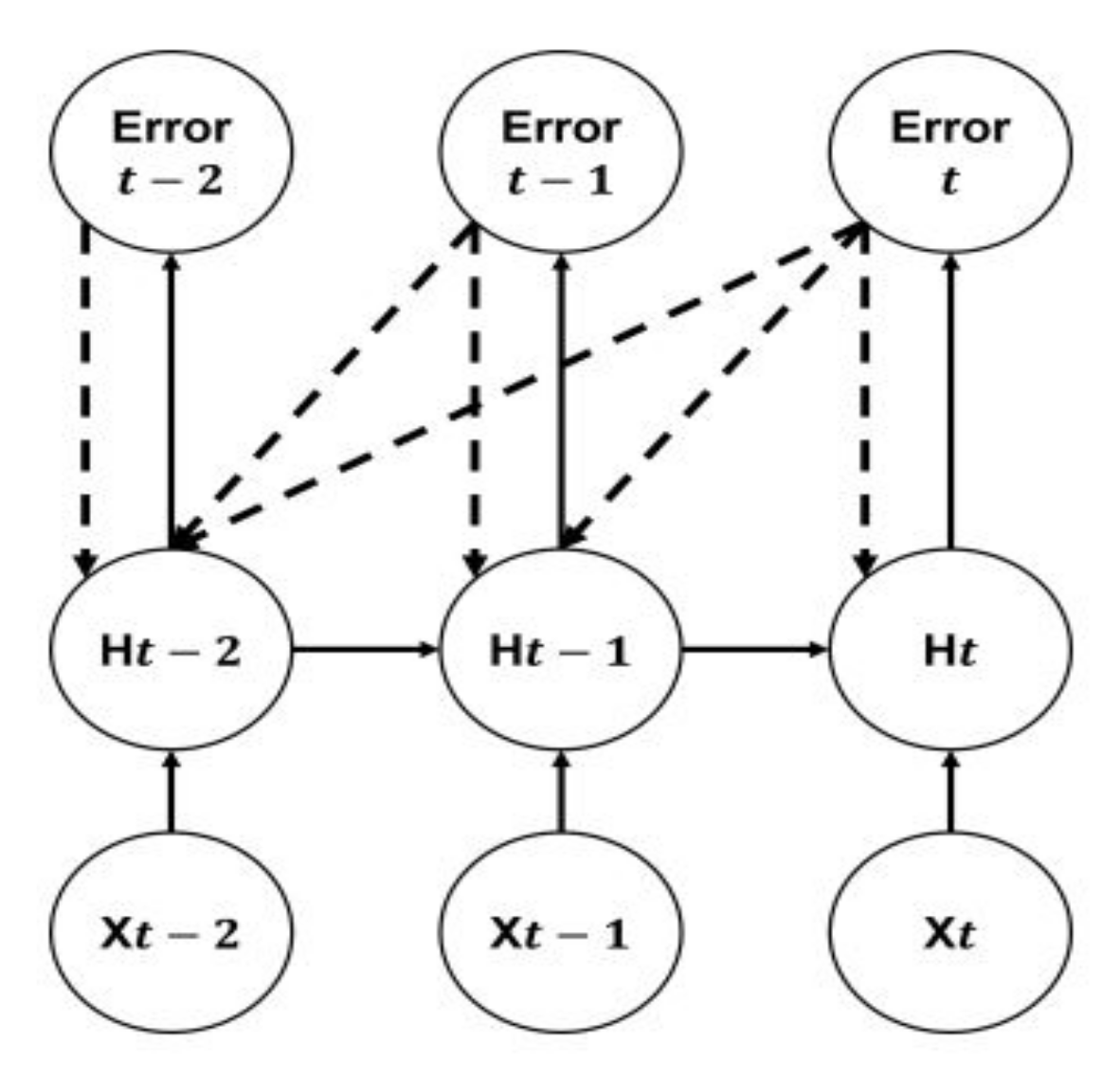
3.2.3. Gated Recurrent Unit
3.3. The Cu-Enabled LSTM + GRU (Cu-LTSMGRU)
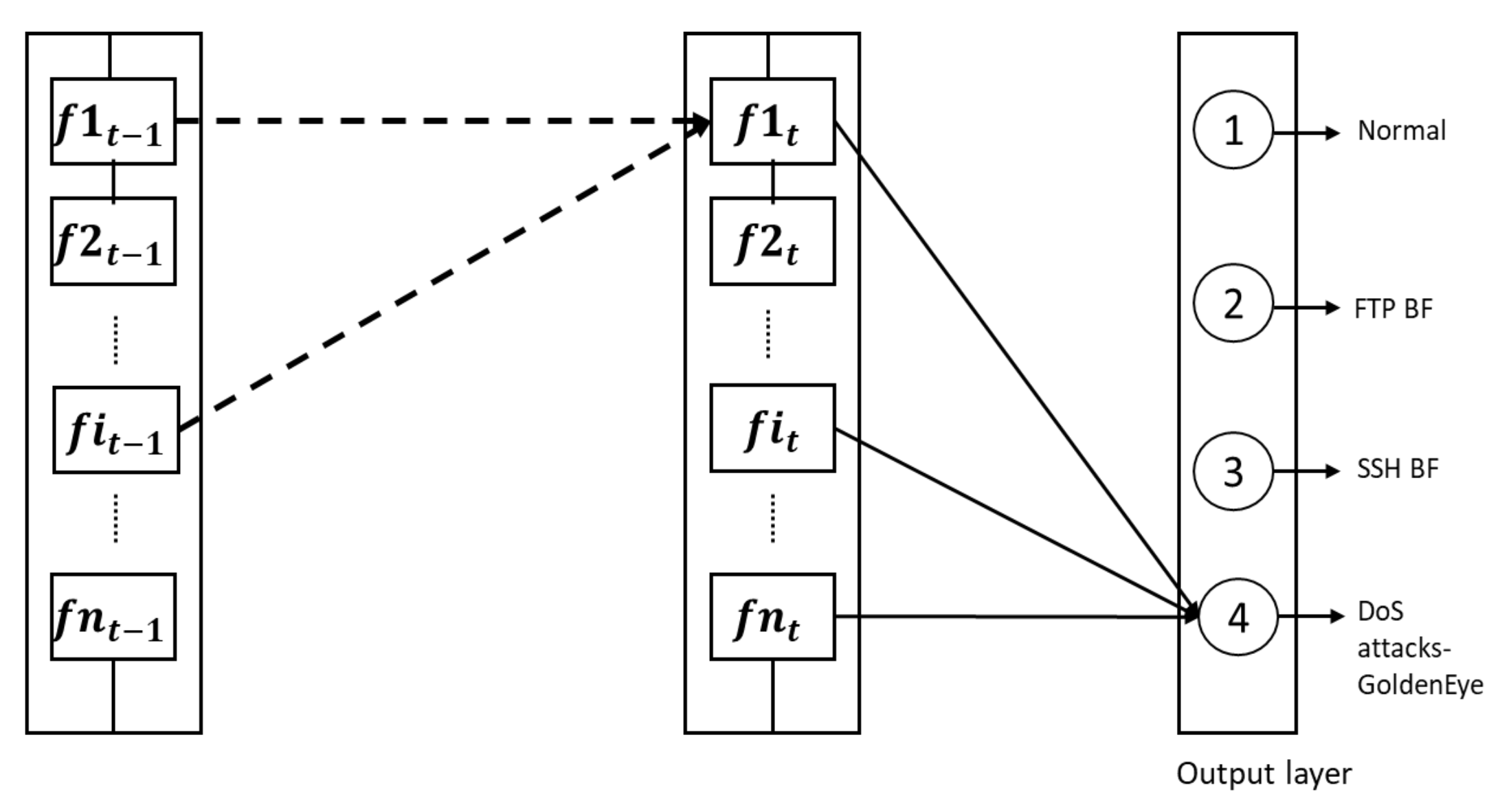
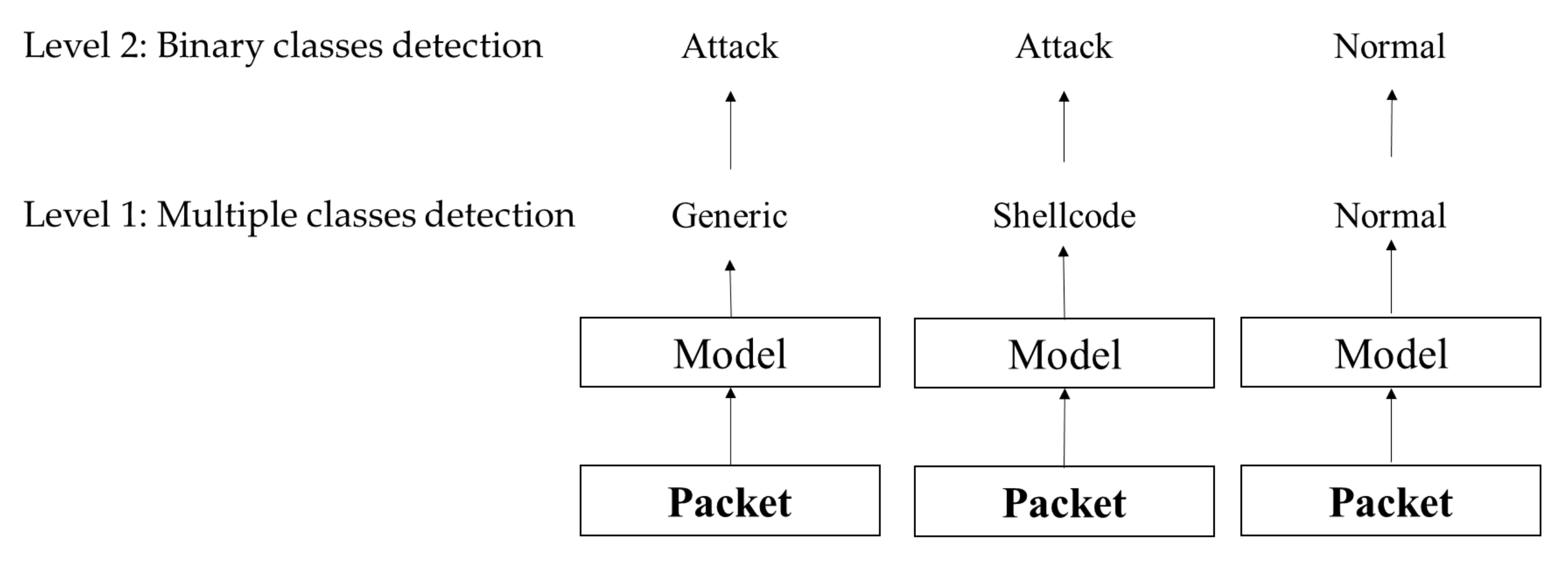
3.4. Multiple Classes and Binary Class Detection
4. Implementation
4.1. Dataset and Preprocessing
| Algorithm 1. Data preprocessing |
| 1. Begin |
| 2. Load data from 14 and 15 February 2018 |
| ## clean data |
| 3. Remove null values |
| 4. Remove infinite values |
| 5. Convert text into numerical format |
| a. Normalize data using Equation (10) |
| #Perform feature selection using Pearson correlation formula |
| 6. For I = 1 to N − 1 do ##N is the number of features in the dataset |
| a. |
| ## Fetch the features with high correlation that represent the upper left side of the correlation matrix |
| 7. Relevant Features] = Correlation [Correlation > 0.9] |
| 8. For all features fi |
| 9. If fi ∉ [Relevant Features] |
| 10. Drop fi |
| 11. End For |
| 12. Sample_dataset = Pick 10% of the normalized dataset |
| 13. Sample_dataset = SMOT (Sample_dataset) ##to avoid oversampling |
| 14. Sample_dataset = RandomUnderSampler (Sample_dataset) ##to avoid undersampling |
| 15. end |
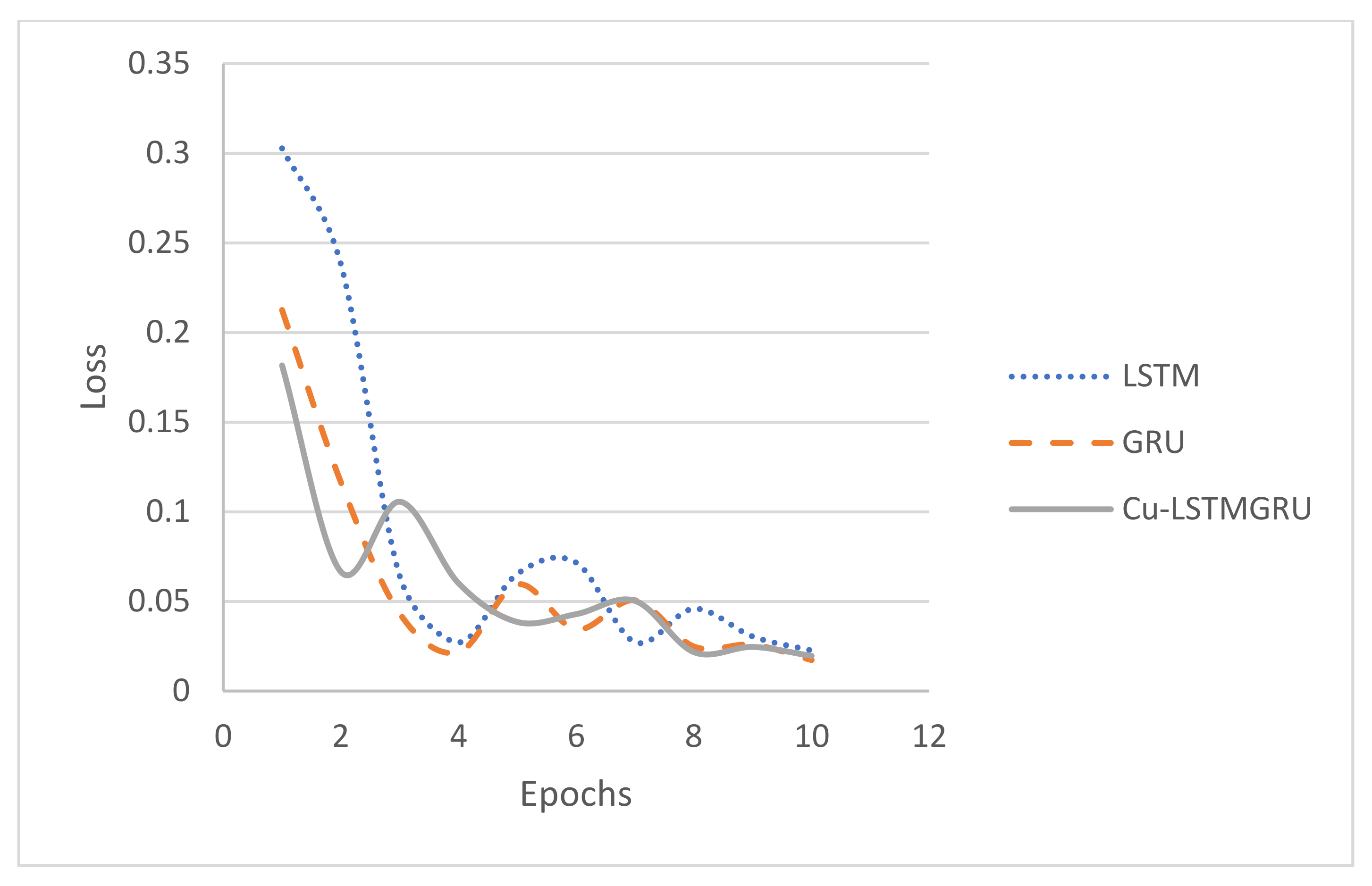
4.2. Experiment 1: LSTM Implementation and Predictions
4.3. Experiment 2: The GRU Implementation and Prediction
4.4. Experiment 3: The Cu-LSTMGRU Implementation and Prediction
5. Results and Analysis
5.1. Confusion Matrices
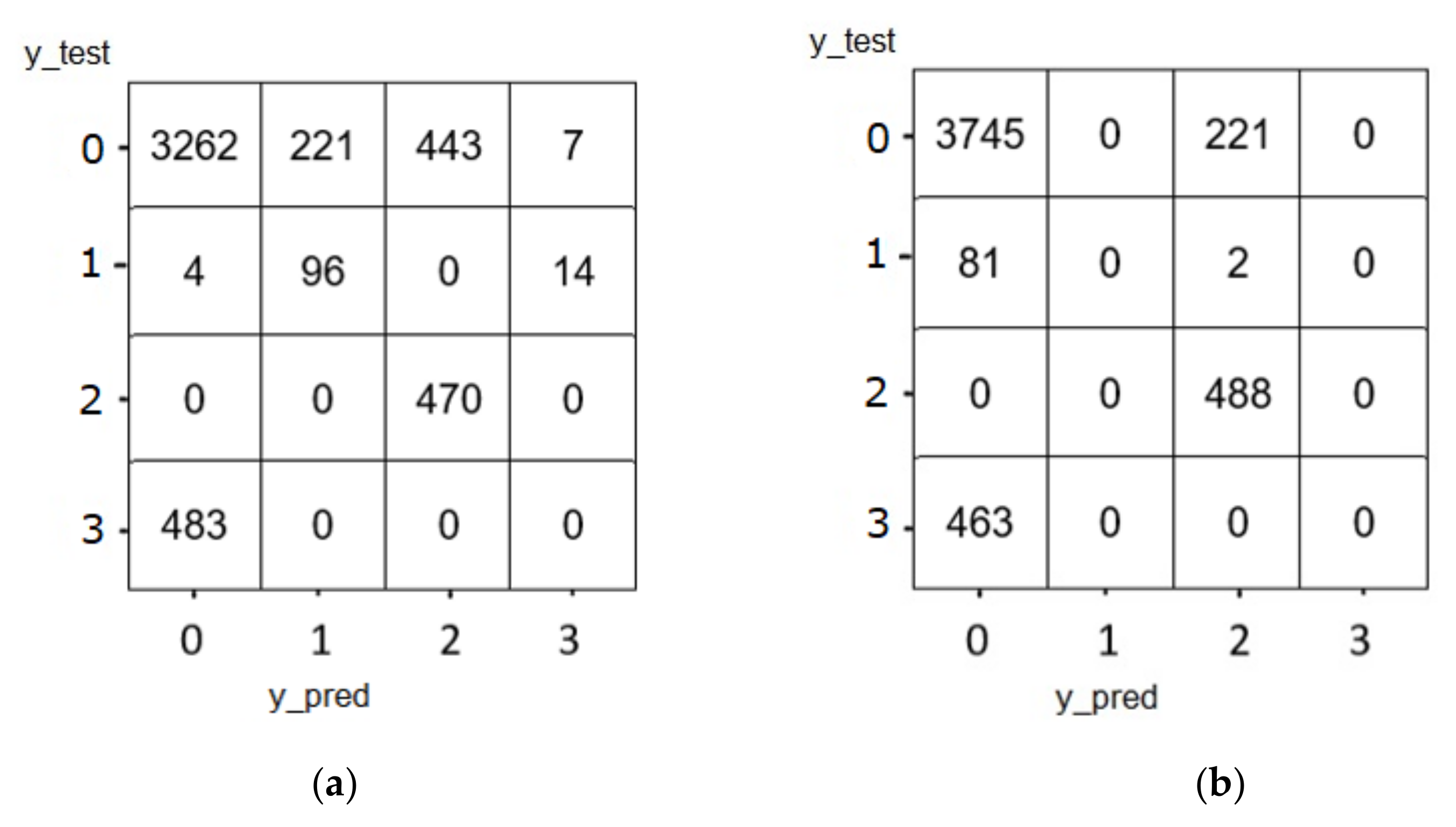
5.1.1. Confusion Matrix of LSTM
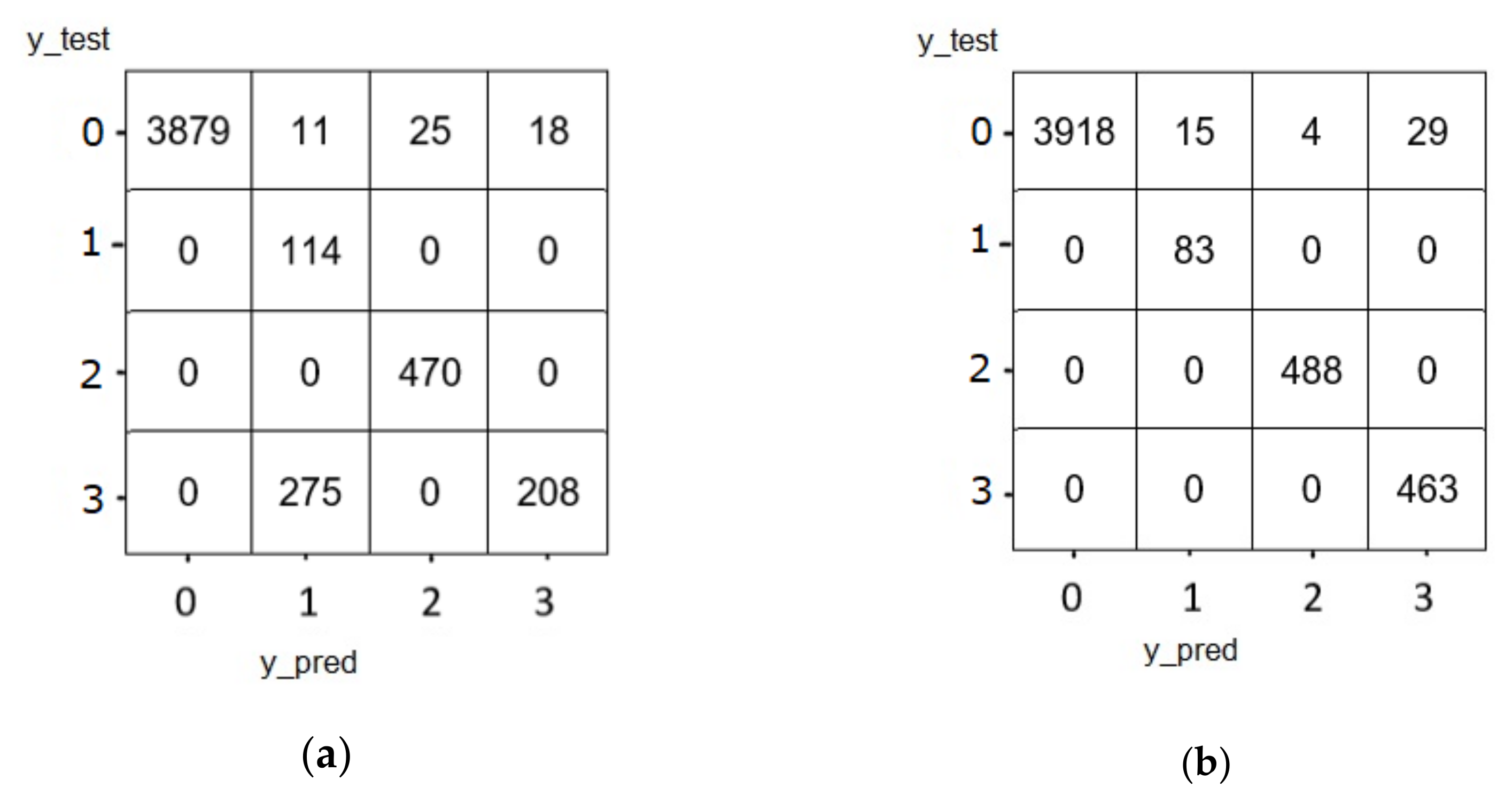
5.1.2. Confusion Matrix of GRU
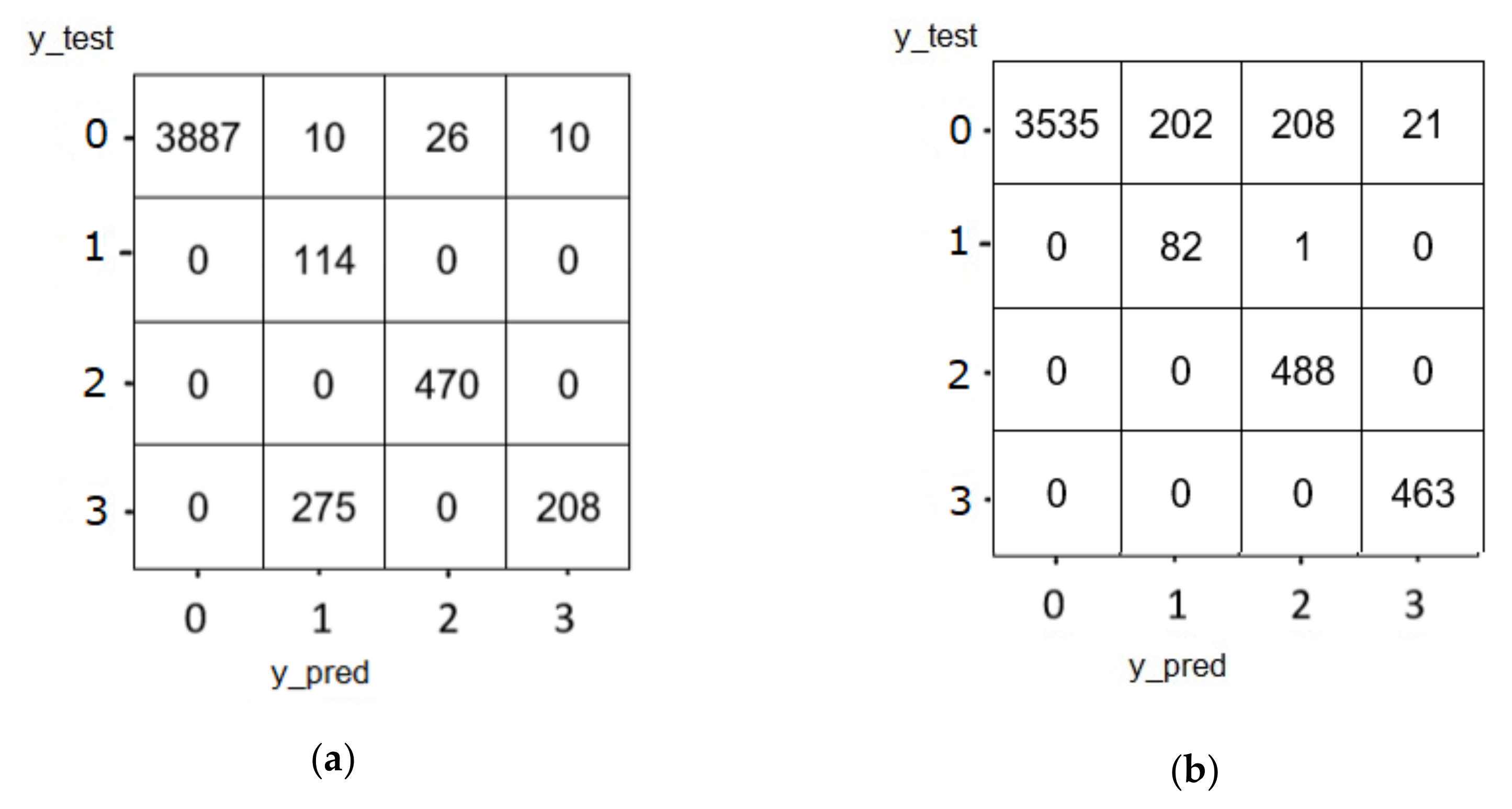
5.1.3. Confusion Matrix of Cu-LSTMGRU
5.2. Evaluation Metrics
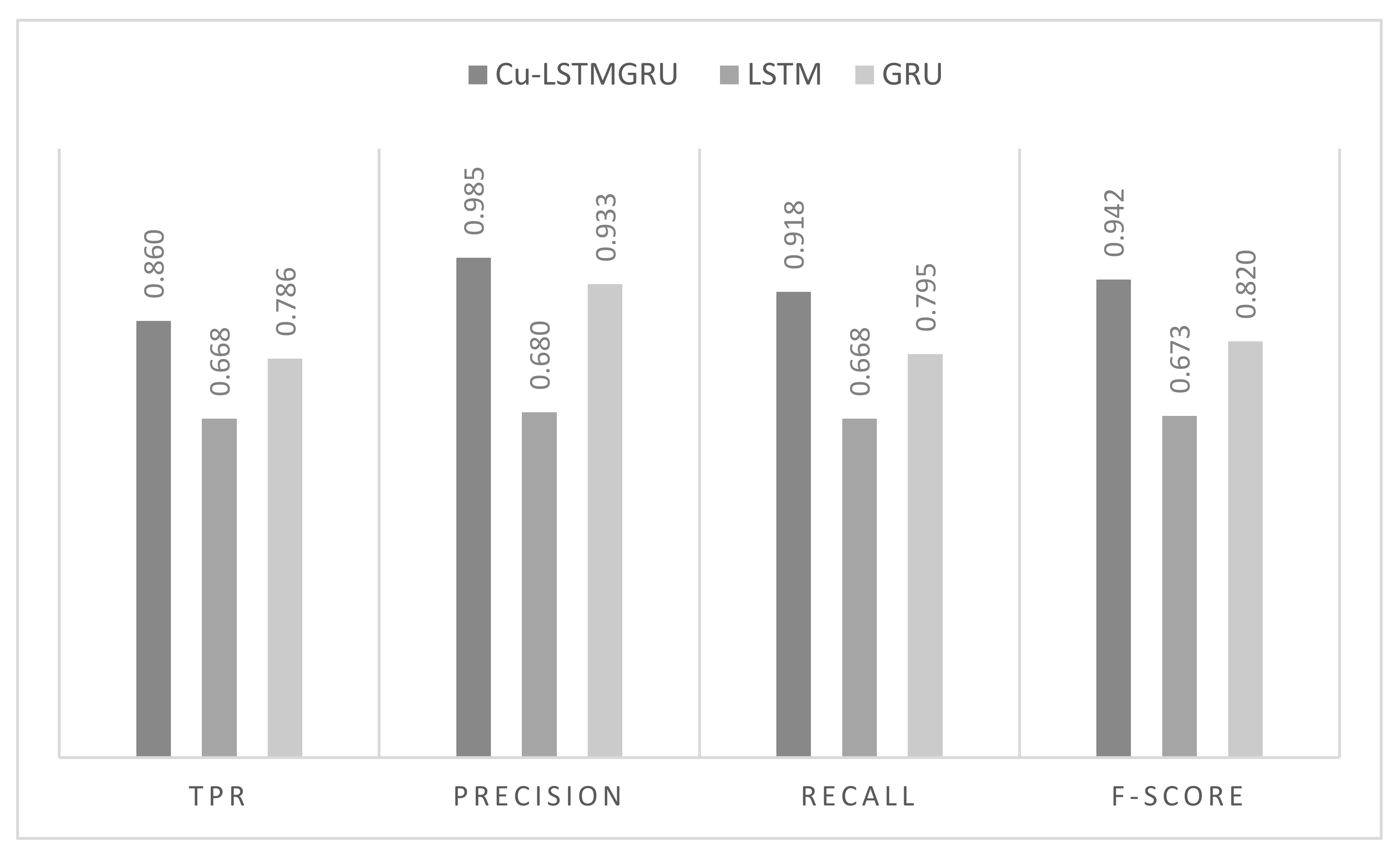
5.3. Comparison between the Proposed Cu-LSTMGRU Model, GRU, and LSTM
5.4. Benchmarking with State-of-the-Art Models
6. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Abusitta, A.; Bellaiche, M.; Dagenais, M.; Halabi, T. A deep learning approach for proactive multi-cloud cooperative intrusion detection system. Future Gener. Comput. Syst. 2019, 98, 308–318. [Google Scholar] [CrossRef]
- Xu, C.; Shen, J.; Du, X.; Zhang, F. An Intrusion Detection System Using a Deep Neural Network with Gated Recurrent Units. IEEE Access 2018, 6, 48697–48707. [Google Scholar] [CrossRef]
- Khan, M.A.; Ghazal, T.M.; Lee, S.-W.; Rehman, A. Data Fusion-Based Machine Learning Architecture for Intrusion Detection. Comput. Mater. Contin. 2021, 70, 3399–3413. [Google Scholar] [CrossRef]
- Peng, W.; Kong, X.; Peng, G.; Li, X.; Wang, Z. Network Intrusion Detection Based on Deep Learning. In Proceedings of the 2019 International Conference on Communications, Information System and Computer Engineering (CISCE), Haikou, China, 5–7 July 2019; pp. 431–435. [Google Scholar] [CrossRef]
- Tang, T.A.; Mhamdi, L.; McLernon, D.; Zaidi, S.A.R.; Ghogho, M. Deep Recurrent Neural Network for Intrusion Detection in SDN-based Networks. In Proceedings of the 2018 4th IEEE Conference on Network Softwarization and Workshops (NetSoft), Montreal, QC, Canada, 25–29 June 2018; pp. 202–206. [Google Scholar] [CrossRef]
- Elsherif, A. Automatic Intrusion Detection System Using Deep Recurrent Neural Network Paradigm. J. Inf. Secur. Cybercrimes Res. 2018, 1, 21–31. [Google Scholar] [CrossRef]
- Ambusaidi, M.A.; He, X.; Nanda, P.; Tan, Z. Building an intrusion detection system using a filter-based feature selection algorithm. IEEE Trans. Comput. 2016, 65, 2986–2998. [Google Scholar] [CrossRef]
- Riyaz, B.; Ganapathy, S. A deep learning approach for effective intrusion detection in wireless networks using CNN. Soft Comput. 2020, 24, 17265–17278. [Google Scholar] [CrossRef]
- Almiani, M.; AbuGhazleh, A.; Al-Rahayfeh, A.; Atiewi, S.; Razaque, A. Deep recurrent neural network for IoT intrusion detection system. Simul. Model. Pract. Theory 2020, 101, 102031. [Google Scholar] [CrossRef]
- Le, T.-T.-H.; Kim, Y.; Kim, H. Network Intrusion Detection Based on Novel Feature Selection Model and Various Recurrent Neural Networks. Appl. Sci. 2019, 9, 1392. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Xu, Y.; Liu, Z.; Hou, H.; Zheng, Y.; Xin, Y.; Zhao, Y.; Cui, L. Robust detection for network intrusion of industrial IoT based on multi-CNN fusion. Measurement 2020, 154, 107450. [Google Scholar] [CrossRef]
- Kim, A.; Park, M.; Lee, D.H. AI-IDS: Application of Deep Learning to Real-Time Web Intrusion Detection. IEEE Access 2020, 8, 70245–70261. [Google Scholar] [CrossRef]
- Amjad, A.; Khan, L.; Chang, H.-T. Semi-Natural and Spontaneous Speech Recognition Using Deep Neural Networks with Hybrid Features Unification. Processes 2021, 9, 2286. [Google Scholar] [CrossRef]
- Phyo, P.P.; Byun, Y.-C. Hybrid Ensemble Deep Learning-Based Approach for Time Series Energy Prediction. Symmetry 2021, 13, 1942. [Google Scholar] [CrossRef]
- Sahlol, A.; Elaziz, M.A.; Jamal, A.T.; Damaševičius, R.; Hassan, O.F. A Novel Method for Detection of Tuberculosis in Chest Radiographs Using Artificial Ecosystem-Based Optimisation of Deep Neural Network Features. Symmetry 2020, 12, 1146. [Google Scholar] [CrossRef]
- Amara, N.; Zhiqui, H.; Ali, A. Cloud Computing Security Threats and Attacks with Their Mitigation Techniques. In Proceedings of the 2017 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery (CyberC), Nanjing, China, 12–14 October 2017; pp. 244–251. [Google Scholar] [CrossRef]
- Maeda, S.; Kanai, A.; Tanimoto, S.; Hatashima, T.; Ohkubo, O. A Botnet Detection Method on SDN using Deep Learning. In Proceedings of the 2019 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 11–13 January 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Ashraf, N.; Ahmad, W.; Ashraf, R. A Comparative Study of Data Mining Algorithms for High Detection Rate in Intrusion Detection System. Ann. Emerg. Technol. Comput. 2018, 2, 49–57. [Google Scholar] [CrossRef]
- Sadaf, K.; Sultana, J. Intrusion Detection Based on Autoencoder and Isolation Forest in Fog Computing. IEEE Access 2020, 8, 167059–167068. [Google Scholar] [CrossRef]
- Louati, F.; Ktata, F.B. A deep learning-based multi-agent system for intrusion detection. SN Appl. Sci. 2020, 2, 675. [Google Scholar] [CrossRef] [Green Version]
- Mighan, S.N.; Kahani, M. A novel scalable intrusion detection system based on deep learning. Int. J. Inf. Secur. 2020, 20, 387–403. [Google Scholar] [CrossRef]
- Mayuranathan, M.; Murugan, M.; Dhanakoti, V. Best features based intrusion detection system by RBM model for detecting DDoS in cloud environment. J. Ambient. Intell. Humaniz. Comput. 2019, 2, 3609–3619. [Google Scholar]
- Masdari, M.; Khezri, H. Efficient VM migrations using forecasting techniques in cloud computing: A comprehensive review. Clust. Comput. 2020, 23, 2629–2658. [Google Scholar] [CrossRef]
- Yang, H.; Qin, G.; Ye, L. Combined Wireless Network Intrusion Detection Model Based on Deep Learning. IEEE Access 2019, 7, 82624–82632. [Google Scholar] [CrossRef]
- Wang, Z.; Zeng, Y.; Liu, Y.; Li, D. Deep Belief Network Integrating Improved Kernel-Based Extreme Learning Machine for Network Intrusion Detection. IEEE Access 2021, 9, 16062–16091. [Google Scholar] [CrossRef]
- Thamilarasu, G.; Chawla, S. Towards Deep-Learning-Driven Intrusion Detection for the Internet of Things. Sensors 2019, 19, 1977. [Google Scholar] [CrossRef]
- Zhang, J.; Li, F.; Zhang, H.; Li, R.; Li, Y. Intrusion detection system using deep learning for in-vehicle security. Ad Hoc Netw. 2019, 95, 101974. [Google Scholar] [CrossRef]
- Hu, Z.; Wang, L.; Qi, L.; Li, Y.; Yang, W. A Novel Wireless Network Intrusion Detection Method Based on Adaptive Synthetic Sampling and an Improved Convolutional Neural Network. IEEE Access 2020, 8, 195741–195751. [Google Scholar] [CrossRef]
- Elmasry, W.; Akbulut, A.; Zaim, A.H. Evolving deep learning architectures for network intrusion detection using a double PSO metaheuristic. Comput. Netw. 2020, 168, 107042. [Google Scholar] [CrossRef]
- Xu, X.; Li, J.; Yang, Y.; Shen, F. Towards Effective Intrusion Detection Using Log-Cosh Conditional Variational Autoencoder. IEEE Internet Things J. 2021, 8, 6187–6196. [Google Scholar] [CrossRef]
- Yang, L.; Li, J.; Yin, L.; Sun, Z.; Zhao, Y.; Li, Z. Real-Time Intrusion Detection in Wireless Network: A Deep Learning-Based Intelligent Mechanism. IEEE Access 2020, 8, 170128–170139. [Google Scholar] [CrossRef]
- Zhang, G.; Wang, X.; Li, R.; Song, Y.; He, J.; Lai, J. Network Intrusion Detection Based on Conditional Wasserstein Generative Adversarial Network and Cost-Sensitive Stacked Autoencoder. IEEE Access 2020, 8, 190431–190447. [Google Scholar] [CrossRef]
- Tang, T.A.; Mhamdi, L.; McLernon, D.; Zaidi, S.A.R.; Ghogho, M.; El Moussa, F. DeepIDS: Deep Learning Approach for Intrusion Detection in Software Defined Networking. Electronics 2020, 9, 1533. [Google Scholar] [CrossRef]
- Hara, K.; Shiomoto, K. Intrusion Detection System using Semi-Supervised Learning with Adversarial Auto-encoder. In Proceedings of the NOMS 2020-2020 IEEE/IFIP Network Operations and Management Symposium, Budapest, Hungary, 20–24 April 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, Y.; Zhang, N.; Xiao, M. A network intrusion detection method based on deep learning with higher accuracy. Procedia Comput. Sci. 2020, 174, 50–54. [Google Scholar] [CrossRef]
- Zhang, C.; Costa-P’erez, X.; Patras, P. Tiki-taka: Attacking and defending deep learning-based intrusion detection systems. In Proceedings of the 2020 ACM SIGSAC Conference on Cloud Computing Security Workshop, Virtual Event, USA, 9 November 2020; pp. 27–39. [Google Scholar]
- Azmin, S.; Islam, A.M.A.A. Network intrusion detection system based on conditional variational Laplace AutoEncoder. In Proceedings of the 7th International Conference on Networking, Systems and Security, Dhaka, Bangladesh, 22–24 December 2020; pp. 82–88. [Google Scholar] [CrossRef]
- Kumar, P.; Kumar, A.A.; Sahayakingsly, C.; Udayakumar, A. Analysis of intrusion detection in cyber attacks using DEEP learning neural networks. Peer-To-Peer Netw. Appl. 2021, 14, 2565–2584. [Google Scholar] [CrossRef]
- Ashiku, L.; Dagli, C. Network Intrusion Detection System using Deep Learning. Procedia Comput. Sci. 2021, 185, 239–247. [Google Scholar] [CrossRef]
- Fernandez, G.C.; Xu, S. A Case Study on using Deep Learning for Network Intrusion Detection. In Proceedings of the MILCOM 2019—2019 IEEE Military Communications Conference (MILCOM), Norfolk, VA, USA, 12–14 November 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Choraś, M.; Pawlicki, M. Intrusion detection approach based on optimised artificial neural network. Neurocomputing 2021, 452, 705–715. [Google Scholar] [CrossRef]
- Chen, L.; Kuang, X.; Xu, A.; Suo, S.; Yang, Y. A Novel Network Intrusion Detection System Based on CNN. In Proceedings of the 2020 Eighth International Conference on Advanced Cloud and Big Data (CBD), Taiyuan, China, 5–6 December 2020; pp. 243–247. [Google Scholar] [CrossRef]
- Nayyar, S.; Arora, S.; Singh, M. Recurrent Neural Network Based Intrusion Detection System. In Proceedings of the 2020 International Conference on Communication and Signal Processing (ICCSP), Chennai, India, 28–30 July 2020; pp. 0136–0140. [Google Scholar] [CrossRef]
- Bharati, M.P.; Tamane, S. NIDS-Network Intrusion Detection System Based on Deep and Machine Learning Frameworks with CICIDS2018 using Cloud Computing. In Proceedings of the 2020 International Conference on Smart Innovations in Design, Environment, Management, Planning and Computing (ICSIDEMPC), Aurangabad, India, 30–31 October 2020; pp. 27–30. [Google Scholar] [CrossRef]
- Meamarian, M.; Yazdani, N. A Robust, Lightweight Deep Learning Approach for Detection and Mitigation of DDoS Attacks in SDN. In Proceedings of the 2022 27th International Computer Conference, Computer Society of Iran (CSICC), Tehran, Iran, 23–24 February 2022; pp. 1–7. [Google Scholar] [CrossRef]
- Pendleton, M.; Garcia-Lebron, R.; Cho, J.-H.; Xu, S. A Survey on Systems Security Metrics. ACM Comput. Surv. 2017, 49, 62. [Google Scholar] [CrossRef]
- Catillo, M.; Rak, M.; Villano, U. 2L-ZED-IDS: A Two-Level Anomaly Detector for Multiple Attack Classes. In Web, Artificial Intelligence and Network Applications. WAINA 2020; Advances in Intelligent Systems and Computing; Barolli, L., Amato, F., Moscato, F., Enokido, T., Takizawa, M., Eds.; Springer: Cham, Switzerland, 2020; Volume 1150. [Google Scholar] [CrossRef]
- Cai, J.; Luo, J.; Wang, S.; Yang, S. Feature selection in machine learning: A new perspective. Neurocomputing 2018, 300, 70–79. [Google Scholar] [CrossRef]
- Jaw, E.; Wang, X. Feature Selection and Ensemble-Based Intrusion Detection System: An Efficient and Comprehensive Approach. Symmetry 2021, 13, 1764. [Google Scholar] [CrossRef]
- Alduailij, M.; Khan, Q.W.; Tahir, M.; Sardaraz, M.; Alduailij, M.; Malik, F. Machine-Learning-Based DDoS Attack Detection Using Mutual Information and Random Forest Feature Importance Method. Symmetry 2022, 14, 1095. [Google Scholar] [CrossRef]
- Shakya, V.; Makwana, R.R.S. Feature selection based intrusion detection system using the combination of DBSCAN, K-Mean++ and SMO algorithms. In Proceedings of the 2017 International Conference on Trends in Electronics and Informatics (ICEI), Tirunelveli, India, 11–12 May 2017; pp. 928–932. [Google Scholar] [CrossRef]
- Aldallal, A.; Alisa, F. Effective Intrusion Detection System to Secure Data in Cloud Using Machine Learning. Symmetry 2021, 13, 2306. [Google Scholar] [CrossRef]
- Moedjahedy, J.; Setyanto, A.; Alarfaj, F.K.; Alreshoodi, M. CCrFS: Combine Correlation Features Selection for Detecting Phishing Websites Using Machine Learning. Futur. Internet 2022, 14, 229. [Google Scholar] [CrossRef]
- Schober, P.; Boer, C.; Schwarte, L.A. Correlation coefficients: Appropriate use and interpretation. Anesth. Analg. 2018, 126, 1763–1768. [Google Scholar] [CrossRef]
- Mu, Y.; Liu, X.; Wang, L. A Pearson’s correlation coefficient based decision tree and its parallel implementation. Inf. Sci. 2018, 435, 40–58. [Google Scholar] [CrossRef]
- Rodriguez-Lujan, I.; Huerta, R.; Elkan, C.; Cruz, C.S. Quadratic programming feature selection. J. Mach. Learn. Res. 2010, 11, 1491–1516. [Google Scholar]
- Biesiada, J.; Duch, W. Feature Selection for High-Dimensional Data—A Pearson Redundancy Based Filter. In Computer Recognition Systems 2; Springer: Berlin/Heidelberg, Germany, 2007; pp. 242–249. [Google Scholar] [CrossRef]
- Fu, Z. Computer Network Intrusion Anomaly Detection with Recurrent Neural Network. Mob. Inf. Syst. 2022, 2022, 6576023. [Google Scholar] [CrossRef]
- Zarzycki, K.; Ławryńczuk, M. LSTM and GRU Neural Networks as Models of Dynamical Processes Used in Predictive Control: A Comparison of Models Developed for Two Chemical Reactors. Sensors 2021, 21, 5625. [Google Scholar] [CrossRef]
- A Realistic Cyber Defense Dataset (CSE-CIC-IDS2018). Available online: https://registry.opendata.aws/cse-cic-ids2018/ (accessed on 25 October 2021).
- Barranco-Chamorro, I.; Carrillo-García, R.M. Techniques to Deal with Off-Diagonal Elements in Confusion Matrices. Mathematics 2021, 9, 3233. [Google Scholar] [CrossRef]
- Bolboacă, S.D.; Jäntschi, L. Sensitivity, specificity, and accuracy of predictive models on phenols toxicity. J. Comput. Sci. 2014, 5, 345–350. [Google Scholar] [CrossRef]
- Saljoughi, S.; Mehrvarz, M.; Mirvaziri, H. Attacks and intrusion detection in cloud computing using neural networks and particle swarm optimization algorithms. Emerg. Sci. J. 2017, 1, 179–191. [Google Scholar] [CrossRef] [Green Version]
- Gupta, N.; Srivastava, K.; Sharma, A. Reducing False Positive in Intrusion Detection System: A Survey. Int. J. Comput. Sci. Inf. Technol. 2016, 7, 1600–1603. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Kernel/Neurons | Layers | AF | LF | Model Optimizer | Epochs | Batch Size |
|---|---|---|---|---|---|---|---|
| LSTM model structure | (600, 500, 400, 100, 400, 300, 200, 50) | Dense layers (9) | ReLU | Categorical cross entropy | Adam | 10 | 32 |
| - | Dropout layer | ||||||
| 4 | Output layer | SoftMax |
| Algorithm | Kernel/Neurons | Layers | AF | LF | Model Optimizer | Epochs | Batch Size |
|---|---|---|---|---|---|---|---|
| GRU model structure | (600, 500, 400, 100) | GRU layers (4) | ReLU | Categorical cross entropy | Adam | 10 | 32 |
| - | Dropout layer | ||||||
| (400, 300, 200, 50) | Dense layers (4) | ||||||
| 4 | Output layer | SoftMax |
| Algorithm | Kernel/Neurons | Layers | AF | LF | Model Optimizer | Epochs | Batch Size |
|---|---|---|---|---|---|---|---|
| Cu-DNNLSTMmodel structure | (700, 600, 500, 200) | CuLSTM layers (4) | ReLU | Categorical ross entropy | Adam | 10 | 32 |
| - | Dropout layer | ||||||
| (500, 400, 200, 50) | Dense layers (4) | ||||||
| 4 | Output layer | SoftMax |
| DL Models | TNR | PPV | NPV |
|---|---|---|---|
| Cu-LSTMGRU | 0.9962 | 0.9830 | 0.99930 |
| LSTM | 0.9954 | 0.6788 | 0.99885 |
| GRU | 0.9973 | 0.9320 | 0.99885 |
| DL Model | FPR | RNR | FDR |
|---|---|---|---|
| Cu-LSTMGRU | 0.0030 | 0.1400 | 0.01695 |
| LSTM | 0.0046 | 0.3319 | 0.07114 |
| GRU | 0.0032 | 0.2140 | 0.06740 |
| Authors | Dataset | Techniques | Accuracy | Precision | Recall (DR) | F1-Score | FAR (FPR) | Achieved Accuracy Improvement |
|---|---|---|---|---|---|---|---|---|
| Fernandez, 2019 [40] | CICIDS2017 | DNN | 98.9 | - | - | - | 0.99 | 0.83 |
| Chen, 2020 [42] | CICIDS2017 | CNN | 99.56 | - | - | - | - | 0.16 |
| Choras, 2021 [41] | CICIDS2017 | ANN | 99 | 98 | 98 | - | - | |
| Kim, 2020 [12] | CICIDS2017 | CNN-LSTM | 93 | 86.47 | 76.83 | 81.36 | - | 7.23 |
| Nayyar, 2020 [45] | CICIDS2017 | LSTM | 96.703 | - | - | - | - | 3.12 |
| Elmasry, 2020 [29] | CICIDS2017 | LSTM-RNN, GRN-RNN, | 89.09 93 | 99.64 99.77 | 87.58 92.05 | 93.22 95.75 | 1.9 2.4 | 0.78 |
| Proposed Model | CICIDS2018 | Cu-LSTMGRU | 99.76 | 99 | 99.6 | 99.3 | 0.003 | - |
| Catillo, 2020 [47] | CICIDS2018 | Two-level deep learning | 98.25 | 96.9 | 98.63 | - | 1.08 | 1.50 |
| Meamarian, 2022 [44] | CICIDS2018 | FGSM of a neural network | - | - | 98 | - | - | - |
| Bharati, 2020 [43] | CICIDS2018 | Multilayer perceptron (MLP) | 95 | - | - | - | - | 4.97 |
| Xu, 2018 [2] | KDD Cup 99 | BGRU + MLP + SoftMax | 99.84 | 99.42 | 0.5 | −0.12 | ||
| Tang, 2018 [5] | NSL-KDD | GRU-RNN | 89 | 12.05 | ||||
| Le, 2019 [10] | NSL-KDD | RNN | 89.6 | 11.30 | ||||
| LSTM | 92 | 8.39 | ||||||
| GRU | 91.8 | 8.63 | ||||||
| Fu, 2022 [58] | IADA, IADB | BiLSTM-DNN | 97.2 | 93.9 | 95.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aldallal, A. Toward Efficient Intrusion Detection System Using Hybrid Deep Learning Approach. Symmetry 2022, 14, 1916. https://doi.org/10.3390/sym14091916
Aldallal A. Toward Efficient Intrusion Detection System Using Hybrid Deep Learning Approach. Symmetry. 2022; 14(9):1916. https://doi.org/10.3390/sym14091916
Chicago/Turabian StyleAldallal, Ammar. 2022. "Toward Efficient Intrusion Detection System Using Hybrid Deep Learning Approach" Symmetry 14, no. 9: 1916. https://doi.org/10.3390/sym14091916
APA StyleAldallal, A. (2022). Toward Efficient Intrusion Detection System Using Hybrid Deep Learning Approach. Symmetry, 14(9), 1916. https://doi.org/10.3390/sym14091916