

Flexible Offloading and Task Scheduling for IoT Applications in Dynamic Multi-Access Edge Computing Environments

Abstract
:1. Introduction
- Taking into account the diversified requirements and time-dependent characteristics of multiple applications, we utilize the computation offloading decision and task scheduling priority to describe the offloading and scheduling solutions of multiple application tasks based on the multi-connectivity technology. The problem of computation offloading and task scheduling for applications that continuously arrive can be modeled as a multi-objective combinatorial optimization problem in an infinite time horizon, making it challenging to solve.
- To address this problem, we propose the FLOATS scheme to flexibly and adaptively coordinate and orchestrate the wireless and computing resources of dynamic networks among multiple application tasks. We divide the infinite time into numerous discrete time intervals named rolling horizon windows (RHW). By periodically updating the network and application information in each RHW, the rolling-horizon-based optimization and scheduling mechanism can decompose the dynamic intractable optimization problem into a series of static sub-problems that are easy to solve.
- For the static sub-problem in each RHW, a GA-based computation offloading and task scheduling algorithm is proposed to find the optimal solution. We utilize a two-layer chromosome construction to describe the offloading and scheduling solutions of the sub-problems. In order to enhance the searching efficiency, we adopt multiple methods to initialize the population chromosomes to avoid the GA algorithm falling into the local optimal solution prematurely. Furthermore, various crossover and mutation operations are applied to each layer of genes in the chromosomes to ensure the feasibility and validity of the chromosomes in each generation.
- Extensive simulation results validate the proposed optimization mechanism and algorithm performance. In comparison to other reference schemes, the proposed scheme demonstrates a significant reduction in network cost and enhances the efficiency in resource utilization.
2. Related Work
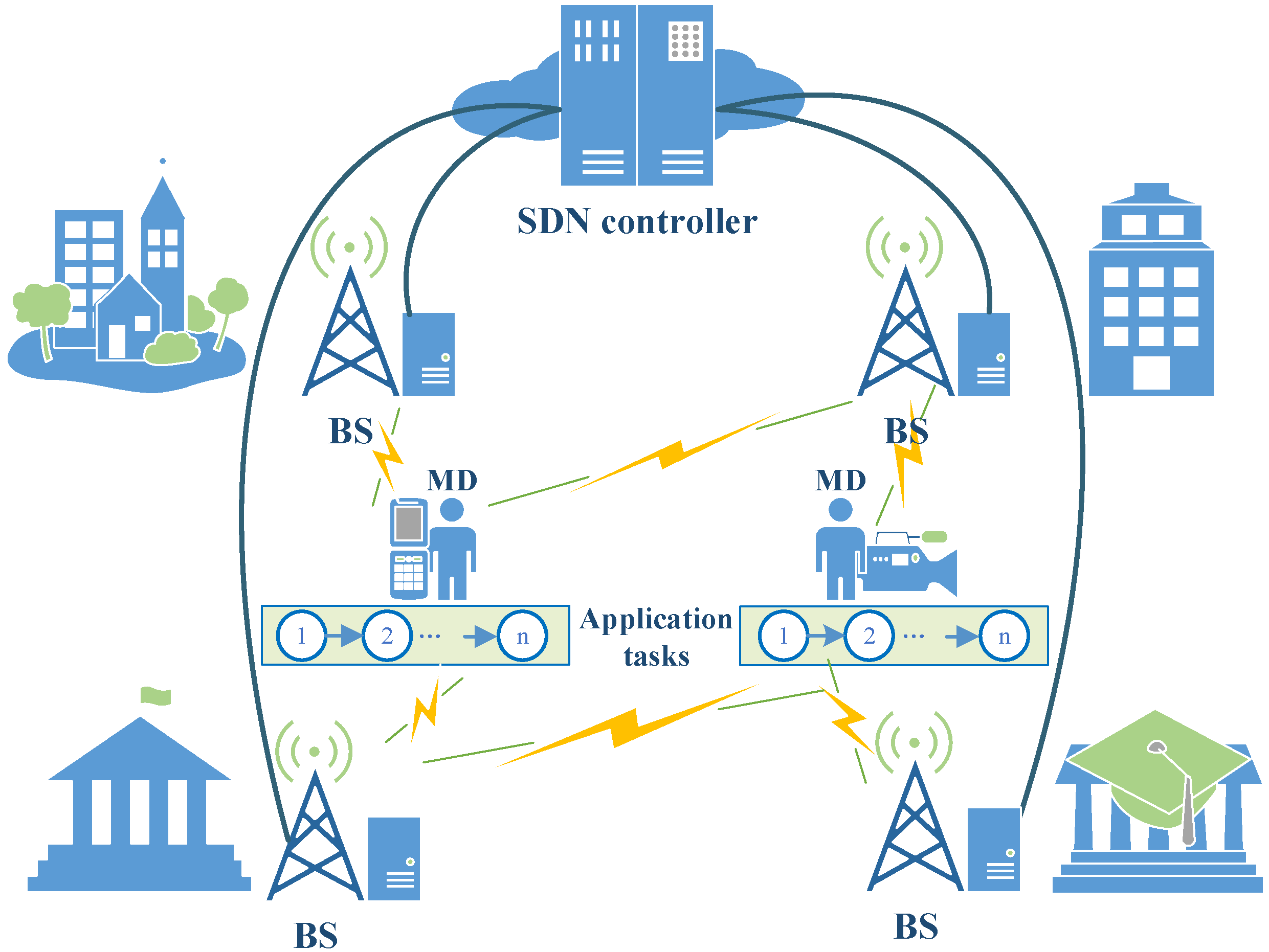
3. System Model
3.1. Network Model
3.2. Application Model
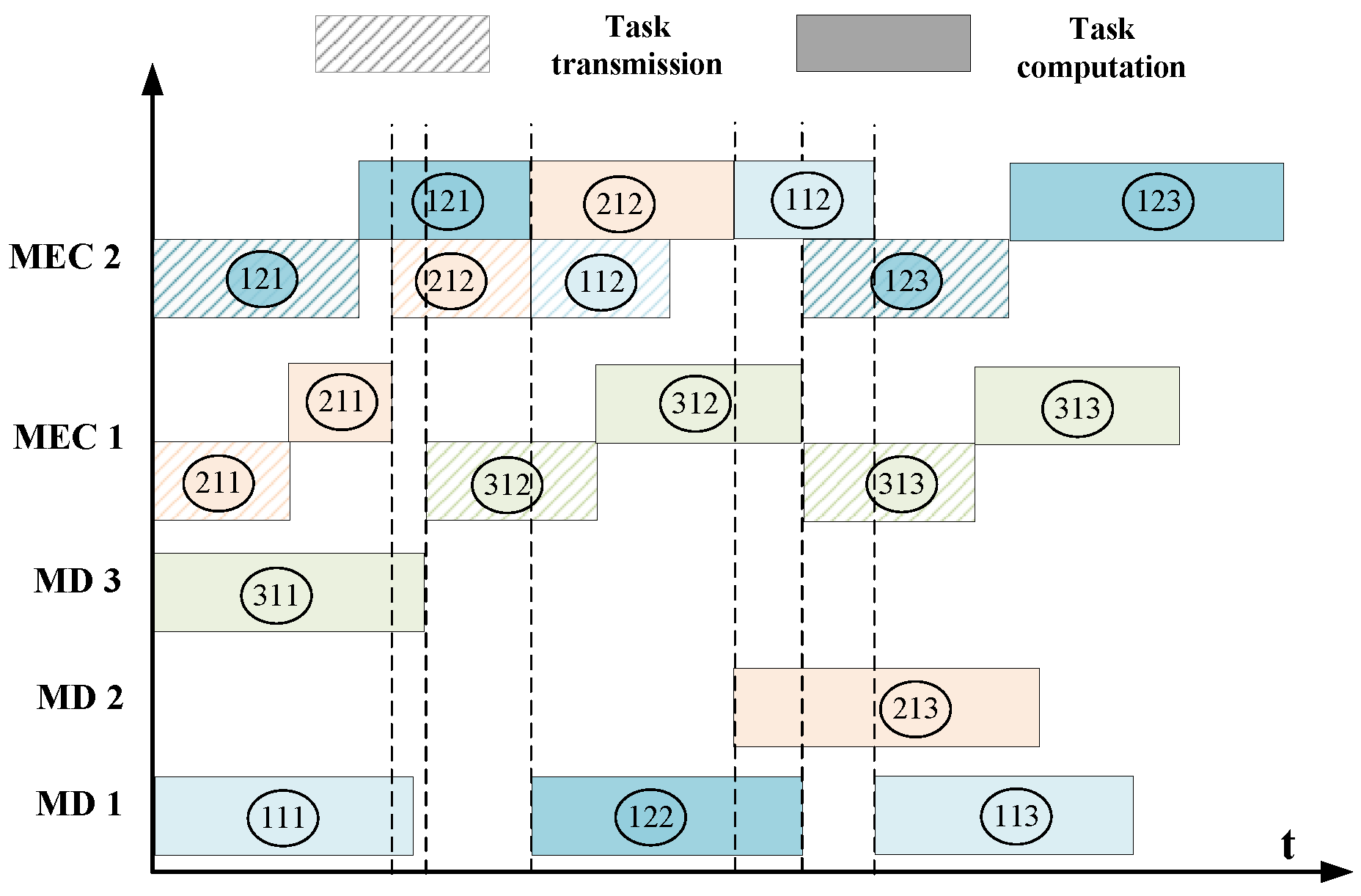
3.3. Task Offloading and Scheduling Model
- The order of the time-dependent tasks for each application is predefined, and the MEC network cannot start transmitting and processing the task until all its predecessor tasks have been processed.
- Each application can be coordinately processed by multiple BSs, but each task can be processed by only one of its candidate BSs.
- Each BS and MEC server can transmit and process at most one task at a time.
- The task is inseparable and non-preemptive; once it starts, the processing of the task cannot be stopped or paused until it is completed.
- If the task is processed locally ,
- If the task is offloaded to the MEC server ,
3.4. Latency Model
3.4.1. Local Computing Mode
3.4.2. MEC Offloading Mode
3.5. Energy Model
3.5.1. Local Computing Mode
3.5.2. MEC Offloading Mode
4. Problem Formulation
5. Flexible Offloading and Task Scheduling Optimization
Rolling-Horizon-Based Optimization and Scheduling Mechanism
6. GA-Based Computation Offloading and Task Scheduling Algorithm
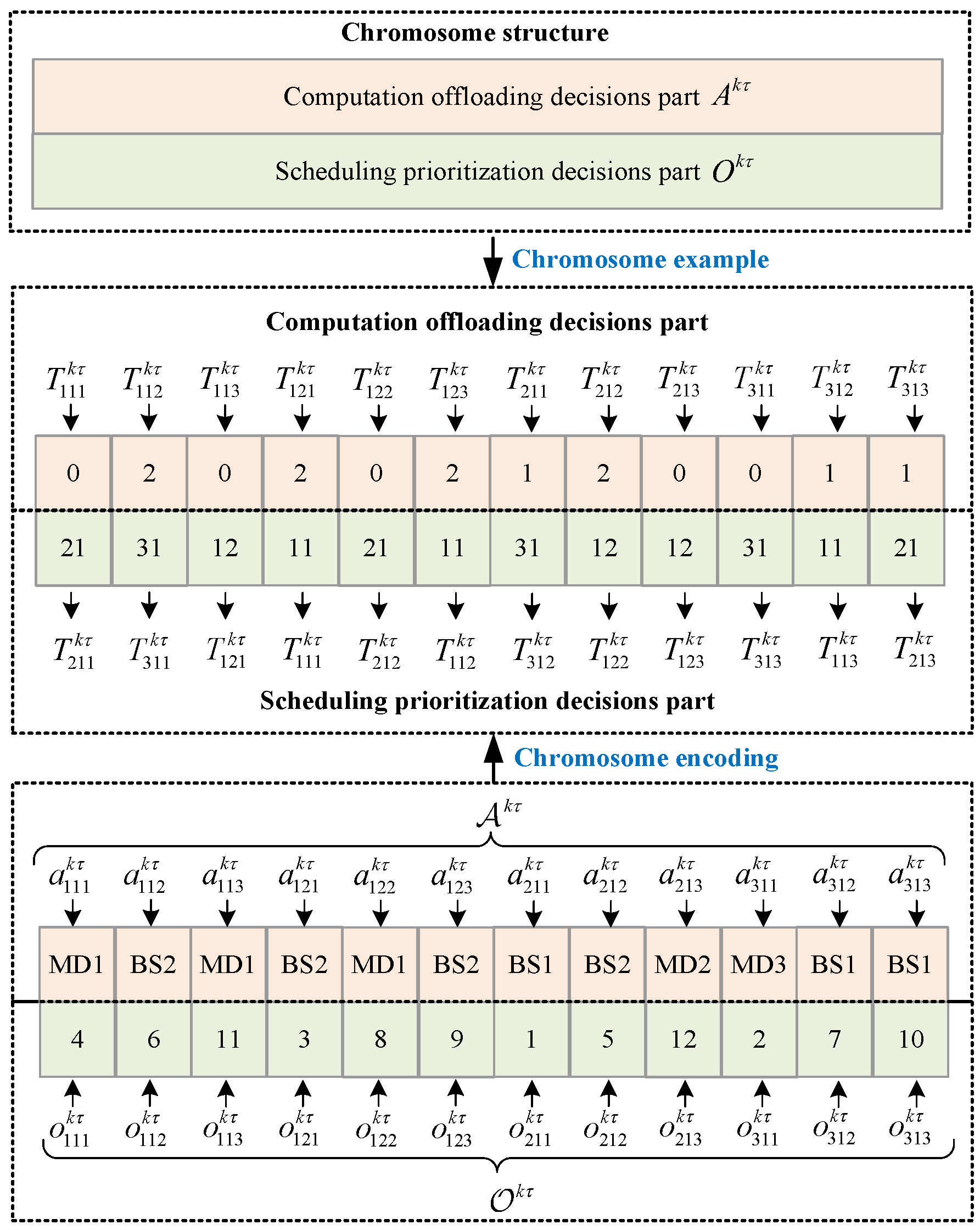
6.1. Two-Layer Modified Chromosome Construction and Encoding
6.2. Population Initialization
- Global heuristic generation method: We randomly generate the scheduling prioritization decisions for all tasks, and heuristically select the global optimal offloading decision for each task sequentially. The detailed steps are as follows:
- Randomly select an application number from the application set and fill it into , decode the selected task number according to Section 6.1.
- Calculate the network cost of the selected task based on the current network state, select the offloading decision with the lowest network cost and fill it into .
- Update and record the available time of the MDs and BSs in the current network. If the selected task is the last task of the application, remove the application from the application set.
- Repeat the first step until the application set is empty.
- Local heuristic generation method: We randomly generate the scheduling prioritization decisions for all tasks and heuristically select the offloading decisions with the lowest network cost for all tasks based on the initial network status. The detailed steps are as follows:
- Randomly select an application number from the application set and fill it into , decode the selected task number according to Section 6.1.
- Calculate the network cost of the selected task based on the initial network state, select the offloading decision with the lowest network cost and fill it into .
- If the selected task is the last task of the application, remove the application from the application set. Repeat the first step until the application set is empty.
- Random generation method: We randomly generate the scheduling prioritization decisions and the offloading decision vector for all tasks. The detailed steps are as follows:
- Randomly select an application number from the application set and fill it into , decode the selected task number according to Section 6.1.
- Randomly select an offloading decision for the selected task and fill it into .
- If the selected task is the last task of the application, remove the application from the application set. Repeat the first step until the application set is empty.
6.3. Fitness Evaluation and Chromosome Selection
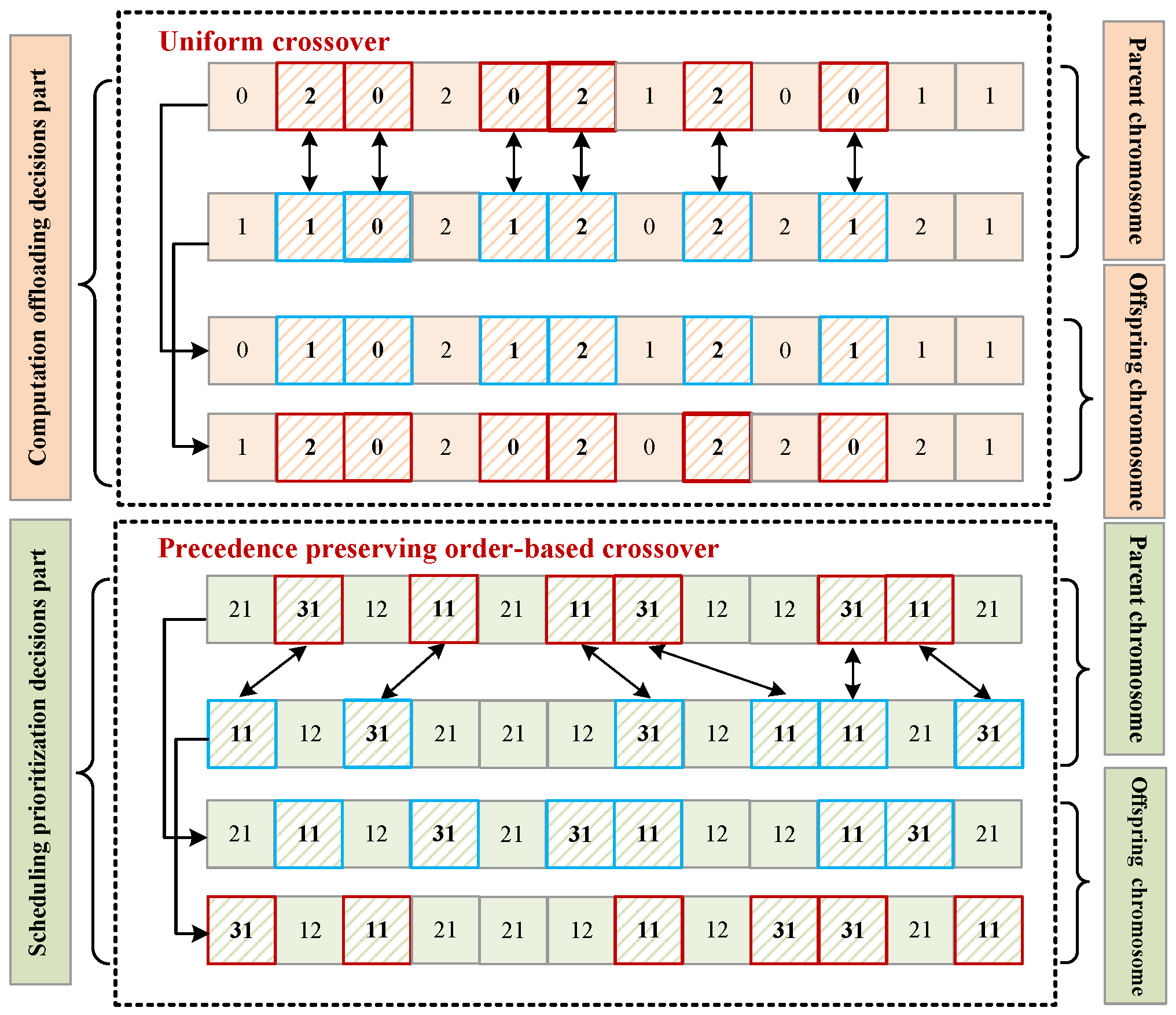
6.4. Crossover and Mutation
- Computation offloading decisions part: uniform crossover. We randomly select multiple crossover positions on and exchange corresponding genes from two parent chromosomes. The detailed steps are as follows:
- Randomly generate unequal integers between 1 and .
- According to the generated integers, exchange corresponding position genes from two parent chromosomes to generate the offspring chromosomes.
As shown in Figure 4, we randomly generate 6 positions, and exchange the genes at the 2nd, 3rd, 5th, 6th, 8th and 10th positions from the computation offloading decisions parts of parent chromosomes , to obtain the computation offloading decisions parts of offspring chromosome , . - Scheduling prioritization decisions part: precedence preserving order-based crossover. We randomly divide the application set into two subsets. For tasks of all applications in one subset, we extract and preserve the priority gene sequences on from two parent chromosomes, exchange the corresponding genes and sequentially fill them into the gene positions of the two chromosomes. The detailed steps are as follows:
- Randomly divide the application set into two subsets and .
- Search for the gene positions , and gene sequences , of tasks in from the scheduling prioritization decisions parts of the parent chromosomes and .
- Replace with and fill it into the gene positions in parent chromosome to obtain the offspring chromosome , and replace with and fill it into the gene positions in parent chromosome to obtain the offspring chromosome .
As shown in Figure 4, we randomly divide the application set into and . For the scheduling prioritization decisions parts of the parent chromosomes , , we exchange the gene sequences and and get the scheduling prioritization decisions parts of the offspring chromosomes , .
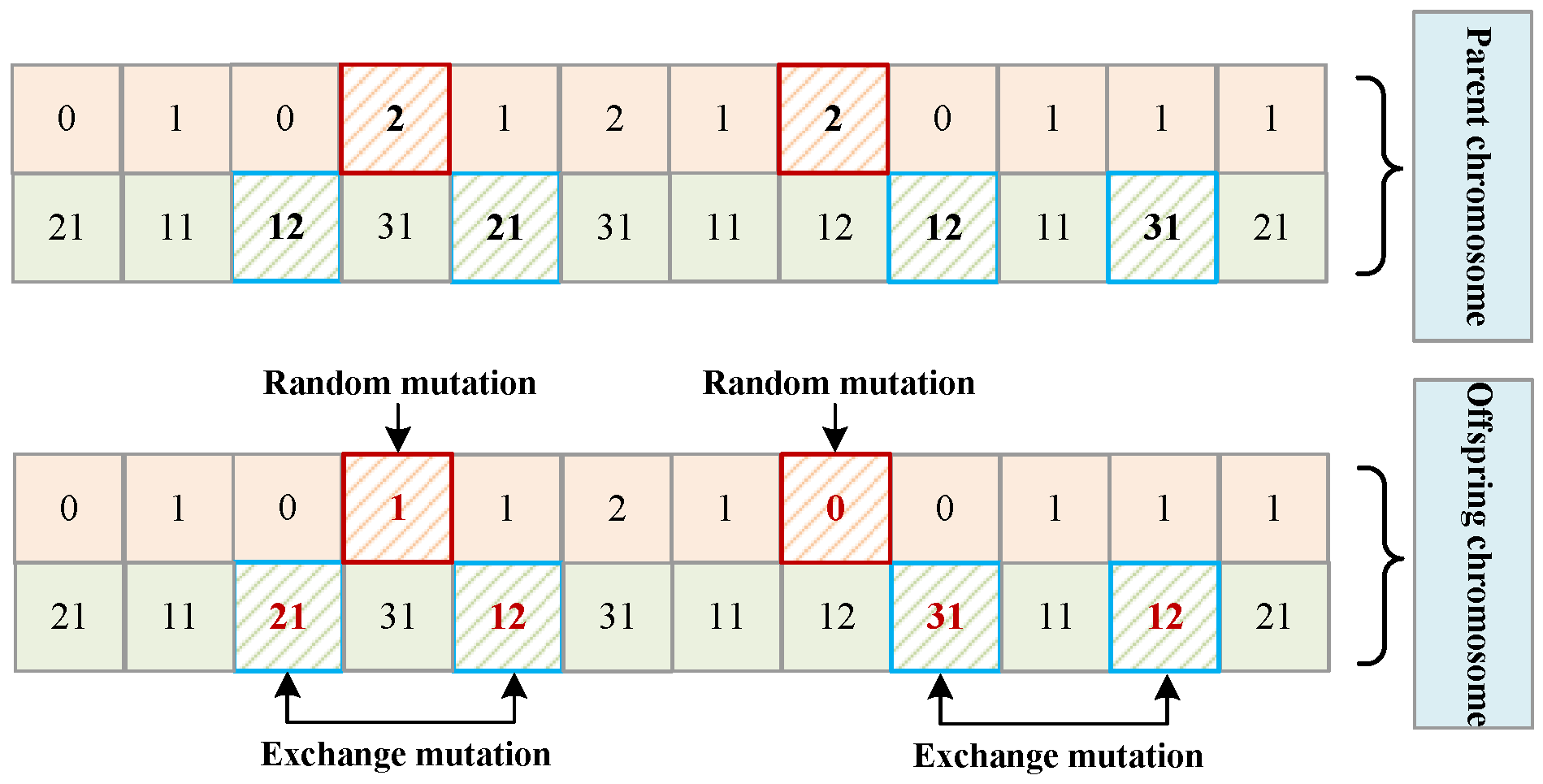
- Computation offloading decisions part: random mutation. For , we randomly mutate each gene within with the mutation probability of .
- Scheduling prioritization decisions part: exchange mutation. For , we randomly choose two genes for exchange with the mutation probability of to maintain the feasibility and validity of .
6.5. Generating New Population
| Algorithm 1 GA-based computation offloading and task scheduling algorithm |
|
6.6. Computation Time Complexity
7. Simulation and Performance Evaluation
7.1. Simulation Setup
- (1)
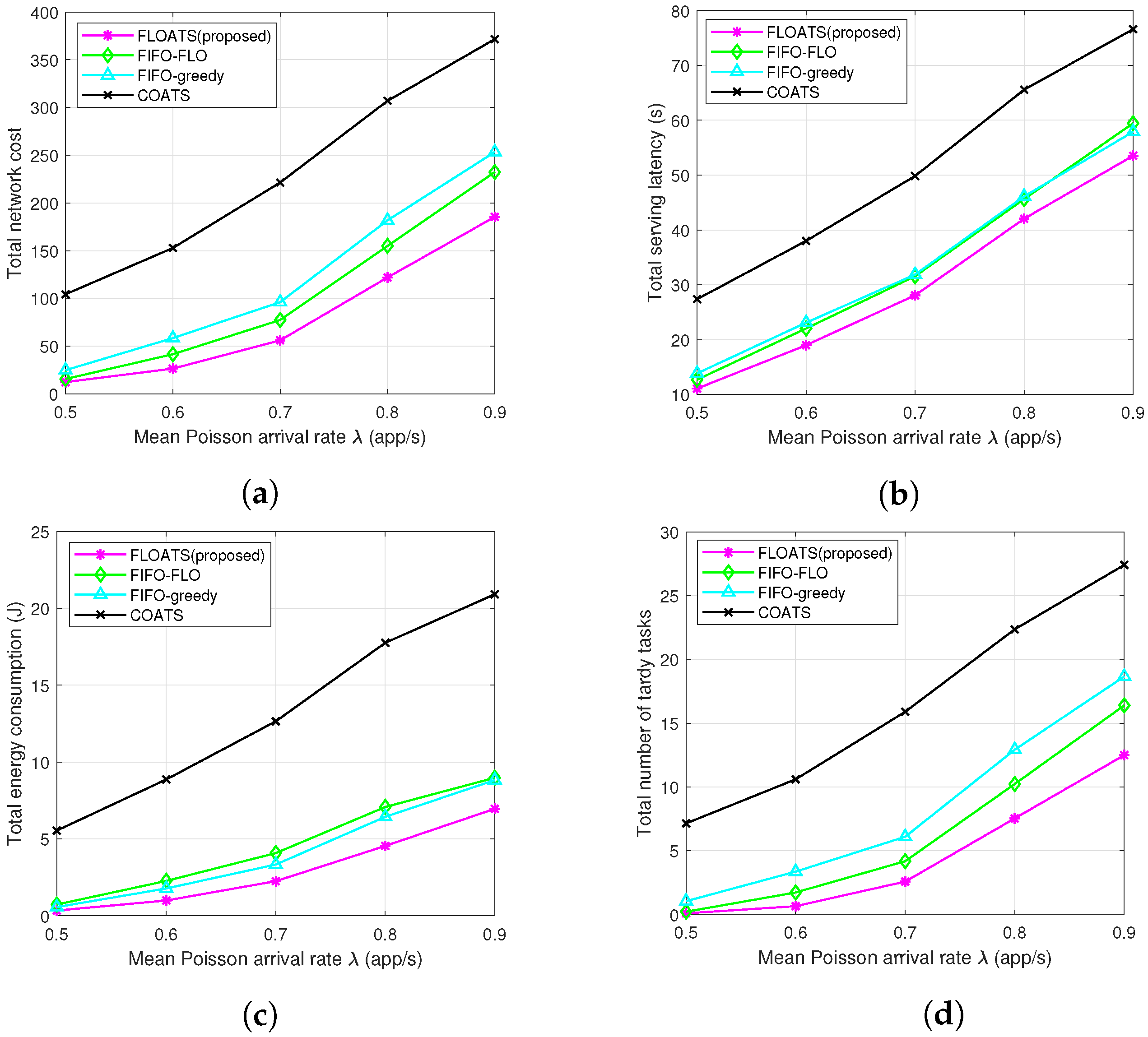
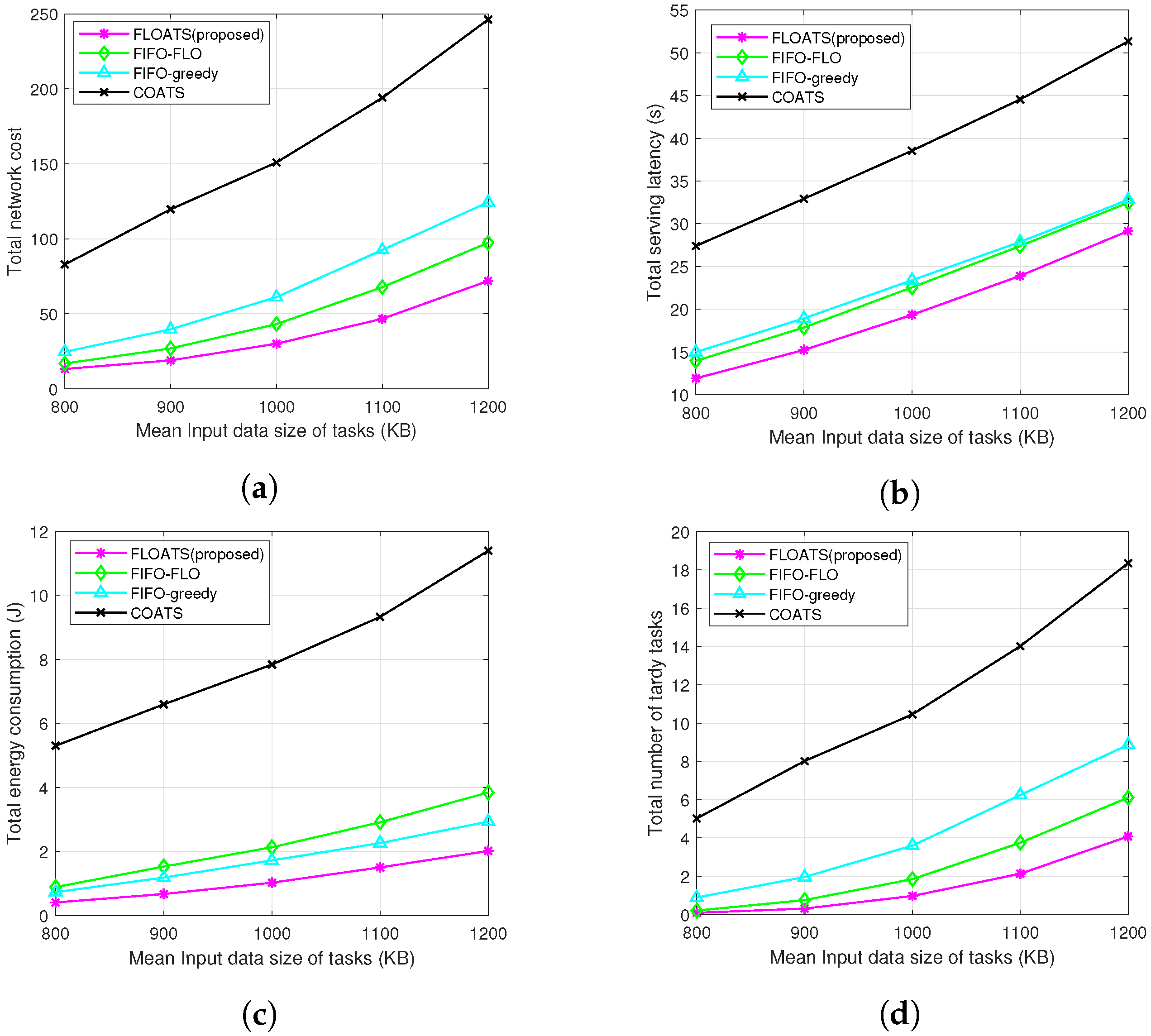
- FIFO-FLO: First-in-first-out prioritization-based flexible computation offloading algorithm, in which each task can be processed locally or flexibly offloaded to one of the multiple MEC servers and the computation offloading decisions are optimized by GA method.
- (2)
- FIFO-greedy: First-in-first-out prioritization-based computation offloading algorithm, in which each task can be processed locally or flexibly offloaded to one of the multiple MEC servers, and the computation offloading decisions are optimized by the greedy method.
- (3)
- COATS: Computation offloading and task scheduling algorithm with single-connectivity technology, in which each MD accesses the BS with the maximal received signal and all tasks of each MD can be processed locally or be processed by the MEC server equipped in associated BS.
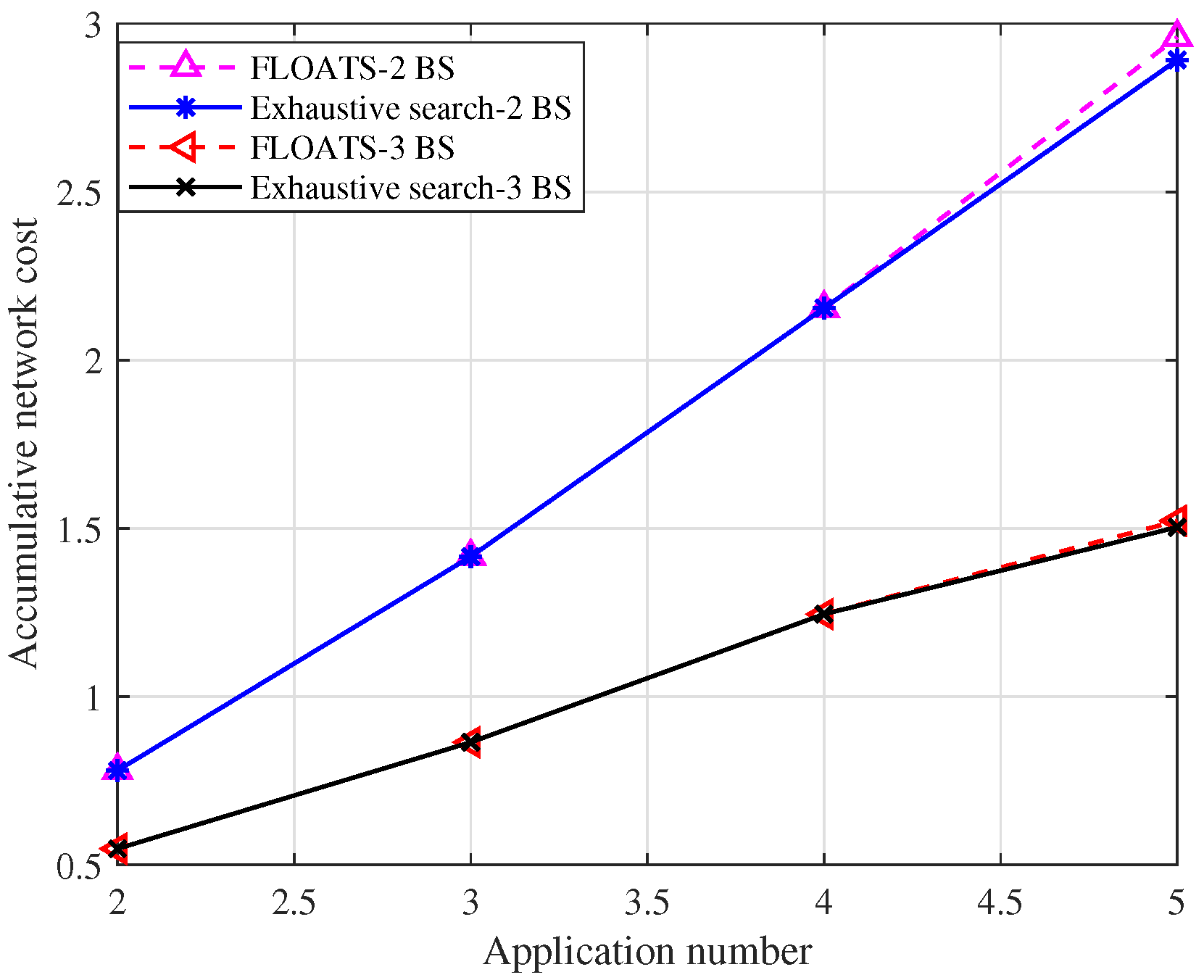
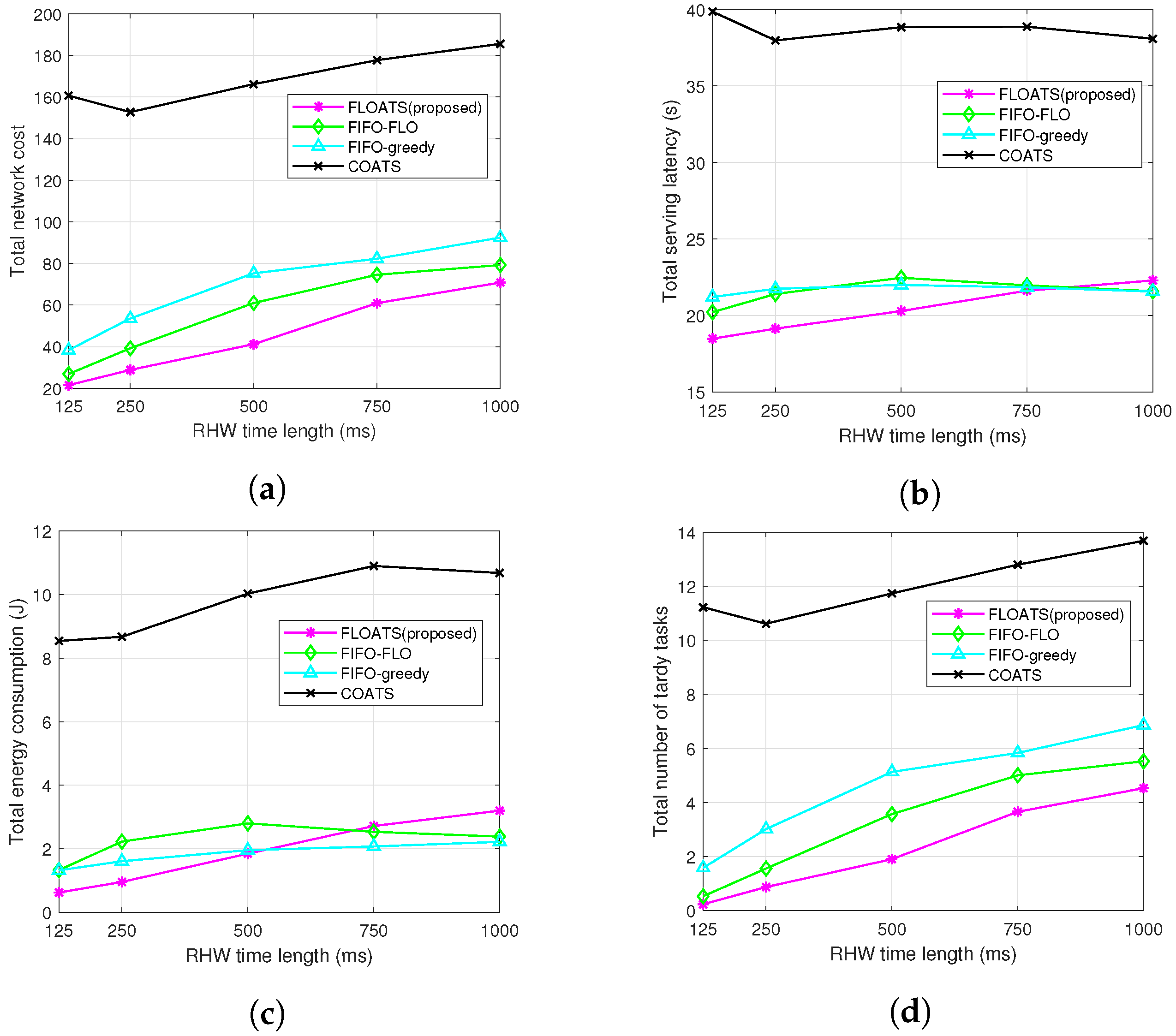
7.2. Performance Evaluation
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| IoT | Internet of things |
| QoS | Quality of service |
| MEC | Multi-access edge computing |
| RHW | Rolling-horizon window |
| DAG | Directed acyclic graph |
| BS | Base station |
| SDN | Software-defined network |
| GA | Genetic algorithm |
References
- Al-Fuqaha, A.; Guizani, M.; Mohammadi, M.; Aledhari, M.; Ayyash, M. Internet of Things: A Survey on Enabling Technologies, Protocols, and Applications. IEEE Commun. Surv. Tutor. 2015, 17, 2347–2376. [Google Scholar] [CrossRef]
- Zhong, A.; Li, Z.; Wu, D.; Tang, T.; Wang, R. Stochastic Peak Age of Information Guarantee for Cooperative Sensing in Internet of Everything. IEEE Internet Things J. 2023, 10, 15186–15196. [Google Scholar] [CrossRef]
- Tang, M.; Gao, L.; Huang, J. Communication, Computation, and Caching Resource Sharing for the Internet of Things. IEEE Commun. Mag. 2020, 58, 75–80. [Google Scholar] [CrossRef]
- Taleb, T.; Samdanis, K.; Mada, B.; Flinck, H.; Dutta, S.; Sabella, D. On Multi-Access Edge Computing: A Survey of the Emerging 5G Network Edge Cloud Architecture and Orchestration. IEEE Commun. Surv. Tutor. 2017, 19, 1657–1681. [Google Scholar] [CrossRef]
- Mach, P.; Becvar, Z. Mobile Edge Computing: A Survey on Architecture and Computation Offloading. IEEE Commun. Surv. Tutor. 2017, 19, 1628–1656. [Google Scholar] [CrossRef]
- Wu, Y.; Ni, K.; Zhang, C.; Qian, L.P.; Tsang, D.H.K. NOMA-Assisted Multi-Access Mobile Edge Computing: A Joint Optimization of Computation Offloading and Time Allocation. IEEE Trans. Veh. Technol. 2018, 67, 12244–12258. [Google Scholar] [CrossRef]
- Jeong, J.; Kim, I.M.; Hong, D. Deep Reinforcement Learning-based Task Offloading Decision in the Time Varying Channel. In Proceedings of the 2021 International Conference on Electronics, Information, and Communication (ICEIC), Jeju, Republic of Korea, 31 January–3 February 2021; pp. 1–4. [Google Scholar]
- Liu, C.F.; Bennis, M.; Debbah, M.; Poor, H.V. Dynamic Task Offloading and Resource Allocation for Ultra-Reliable Low-Latency Edge Computing. IEEE Trans. Commun. 2019, 67, 4132–4150. [Google Scholar] [CrossRef]
- Zhang, K.; Yang, J.; Lin, Z. Computation Offloading and Resource Allocation Based on Game Theory in Symmetric MEC-Enabled Vehicular Networks. Symmetry 2023, 15, 1241. [Google Scholar] [CrossRef]
- Tao, X.; Ota, K.; Dong, M.; Qi, H.; Li, K. Performance Guaranteed Computation Offloading for Mobile-Edge Cloud Computing. IEEE Wirel. Commun. Lett. 2017, 6, 774–777. [Google Scholar] [CrossRef]
- Huang, C.; Yan, Y.; Zhang, Y.; Sun, J. A Metaheuristic Algorithm for Mobility-Aware Task Offloading for Edge Computing Using Device-to-Device Cooperation. In Proceedings of the 2022 IEEE Smartworld, Ubiquitous Intelligence & Computing, Scalable Computing & Communications, Digital Twin, Privacy Computing, Metaverse, Autonomous & Trusted Vehicles, Haikou, China, 15–18 December 2022; pp. 656–663. [Google Scholar]
- Zhang, G.; Zhang, W.; Cao, Y.; Li, D.; Wang, L. Energy-Delay Tradeoff for Dynamic Offloading in Mobile-Edge Computing System With Energy Harvesting Devices. IEEE Trans. Ind. Inform. 2018, 14, 4642–4655. [Google Scholar] [CrossRef]
- Long, S.; Zhang, Y.; Deng, Q.; Pei, T.; Ouyang, J.; Xia, Z. An Efficient Task Offloading Approach Based on Multi-Objective Evolutionary Algorithm in Cloud-Edge Collaborative Environment. IEEE Trans. Netw. Sci. Eng. 2023, 10, 645–657. [Google Scholar] [CrossRef]
- Bai, W.; Wang, Y. Jointly Optimize Partial Computation Offloading and Resource Allocation in Cloud-Fog Cooperative Networks. Electronics 2023, 12, 3224. [Google Scholar] [CrossRef]
- Li, D.; Jin, Y.; Liu, H. Resource Allocation Strategy of Edge Systems Based on Task Priority and an Optimal Integer Linear Programming Algorithm. Symmetry 2020, 12, 972. [Google Scholar] [CrossRef]
- Cai, W.; Duan, F. Task Scheduling for Federated Learning in Edge Cloud Computing Environments by Using Adaptive-Greedy Dingo Optimization Algorithm and Binary Salp Swarm Algorithm. Future Internet 2023, 15, 357. [Google Scholar] [CrossRef]
- Chen, L.; Wu, J.; Zhang, J.; Dai, H.N.; Long, X.; Yao, M. Dependency-Aware Computation Offloading for Mobile Edge Computing with Edge-Cloud Cooperation. IEEE Trans. Cloud Comput. 2020, 10, 2451–2468. [Google Scholar] [CrossRef]
- Fu, X.; Tang, B.; Guo, F.; Kang, L. Priority and Dependency-Based DAG Tasks Offloading in Fog/Edge Collaborative Environment. In Proceedings of the 2021 IEEE 24th International Conference on Computer Supported Cooperative Work in Design (CSCWD), Dalian, China, 5–7 May 2021; pp. 440–445. [Google Scholar]
- Mahmoodi, S.E.; Subbalakshmi, K.P.S. A Time-Adaptive Heuristic for Cognitive Cloud Offloading in Multi-RAT Enabled Wireless Devices. IEEE Trans. Cogn. Commun. Netw. 2016, 2, 194–207. [Google Scholar] [CrossRef]
- Al-Habob, A.A.; Dobre, O.A.; Armada, A.G.; Muhaidat, S. Task Scheduling for Mobile Edge Computing Using Genetic Algorithm and Conflict Graphs. IEEE Trans. Veh. Technol. 2020, 69, 8805–8819. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, Q. Code-Partitioning Offloading Schemes in Mobile Edge Computing for Augmented Reality. IEEE Access 2019, 7, 11222–11236. [Google Scholar] [CrossRef]
- Yan, J.; Bi, S.; Zhang, Y.J.A. Offloading and Resource Allocation with General Task Graph in Mobile Edge Computing: A Deep Reinforcement Learning Approach. IEEE Trans. Wirel. Commun. 2020, 19, 5404–5419. [Google Scholar] [CrossRef]
- Fang, J.; Qu, D.; Chen, H.; Liu, Y. Dependency-Aware Dynamic Task Offloading Based on Deep Reinforcement Learning in Mobile Edge Computing. IEEE Trans. Netw. Serv. Manag. 2023. [Google Scholar] [CrossRef]
- Fang, C.; Zhang, T.; Huang, J.; Xu, H.; Hu, Z.; Yang, Y.; Wang, Z.; Zhou, Z.; Luo, X. A DRL-Driven Intelligent Optimization Strategy for Resource Allocation in Cloud-Edge-End Cooperation Environments. Symmetry 2022, 14, 2120. [Google Scholar] [CrossRef]
- Sastry, K.D.E.G.; Kendall, G. Genetic Algorithms; Springer: Boston, MA, USA, 2014. [Google Scholar]
- Fu, Y.; Wang, H.; Huang, M.; Ding, J.; Tian, G. Multiobjective flow shop deteriorating scheduling problem via an adaptive multipopulation genetic algorithm. Proc. Inst. Mech. Eng. Part B J. Eng. Manuf. 2018, 232, 2641–2650. [Google Scholar] [CrossRef]
- Fu, Y.; Jiang, G.; Tian, G.; Wang, Z. Job scheduling and resource allocation in parallel-machine system via a hybrid nested partition method. IEEJ Trans. Electr. Electron. Eng. 2019, 14, 597–604. [Google Scholar] [CrossRef]
- Fazli, M.; Fathollahi-Fard, A.M.; Tian, G. Addressing a Coordinated Quay Crane Scheduling and Assignment Problem by Red Deer Algorithm. Mater. Energy Res. Cent. 2019, 32, 1186–1191. [Google Scholar]
- Fathollahi-Fard, A.M.; Woodward, L.; Akhrif, O. Sustainable distributed permutation flow-shop scheduling model based on a triple bottom line concept. J. Ind. Inf. Integr. 2021, 24, 100233. [Google Scholar] [CrossRef]
- Shi, Y.; Chu, J.; Ji, C.; Li, J.; Ning, S. A Fuzzy-Based Mobile Edge Architecture for Latency-Sensitive and Heavy-Task Applications. Symmetry 2022, 14, 1667. [Google Scholar] [CrossRef]
- Liu, F.; Huang, J.; Wang, X. Joint Task Offloading and Resource Allocation for Device-Edge-Cloud Collaboration with Subtask Dependencies. IEEE Trans. Cloud Comput. 2023, 11, 3027–3039. [Google Scholar] [CrossRef]
- Peng, B.; Li, T.; Chen, Y. DRL-Based Dependent Task Offloading Strategies with Multi-Server Collaboration in Multi-Access Edge Computing. Appl. Sci. 2023, 13, 191. [Google Scholar] [CrossRef]
- Xu, B.; Hu, Y.; Hu, M.; Liu, F.; Peng, K.; Liu, L. Iterative Dynamic Critical Path Scheduling: An Efficient Technique for Offloading Task Graphs in Mobile Edge Computing. Appl. Sci. 2022, 12, 3189. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Elements of information theory. Publ. Am. Stat. Assoc. 1991, 103, 429. [Google Scholar]
- Li, Z.; Zhu, N.; Wu, D.; Wang, H.; Wang, R. Energy-Efficient Mobile Edge Computing under Delay Constraints. IEEE Trans. Green Commun. Netw. 2022, 6, 776–786. [Google Scholar] [CrossRef]
- Le, K.D.; Day, J.T. Rolling Horizon Method: A New Optimization Technique for Generation Expansion Studies. IEEE Trans. Power Appar. Syst. 1982, PAS-101, 3112–3116. [Google Scholar] [CrossRef]
- Ren, Y.; Zhang, C.; Zhao, F.; Xiao, H.; Tian, G. An asynchronous parallel disassembly planning based on genetic algorithm. Eur. J. Oper. Res. 2018, 269, 647–660. [Google Scholar] [CrossRef]
- Moghadam, A.M.; Wong, K.Y.; Piroozfard, H. An efficient genetic algorithm for flexible job-shop scheduling problem. In Proceedings of the 2014 IEEE International Conference on Industrial Engineering and Engineering Management, Selangor, Malaysia, 9–12 December 2014; pp. 1409–1413. [Google Scholar]
- Sesia, S.; Toufik, I.; Baker, M. LTE, The UMTS Long Term Evolution: From Theory to Practice; Wiley Publishing: Hoboken, NJ, USA, 2009. [Google Scholar]
- Yang, S.; Guohui, Z.; Liang, G.; Kun, Y. A novel initialization method for solving Flexible Job-shop Scheduling Problem. In Proceedings of the 2009 International Conference on Computers & Industrial Engineering, Troyes, France, 6–9 July 2009; pp. 68–73. [Google Scholar]
- Yi, C.; Cai, J.; Su, Z. A Multi-User Mobile Computation Offloading and Transmission Scheduling Mechanism for Delay-Sensitive Applications. IEEE Trans. Mob. Comput. 2020, 19, 29–43. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Task | MD | Server | Scenario | Objective | Algorithm |
|---|---|---|---|---|---|---|
| [6] | Independent | Multiple | Multiple | Static | Delay | Linear-search-based algorithm |
| [7] | Independent | Single | Single | Dynamic | Delay | Deep reinforcement learning algorithm |
| [8] | Independent | Multiple | Multiple | Dynamic | Delay | Lyapunov optimization and matching theory |
| [10] | Independent | Multiple | Multiple | Static | Energy | Convex algorithm |
| [11] | Independent | Multiple | Single | Dynamic | Energy | Metaheuristic algorithm |
| [24] | Independent | Multiple | Multiple | Dynamic | Offloaded traffic | Deep reinforcement learning algorithm |
| [12] | Independent | Single | Single | Dynamic | Delay and energy | Lyapunov algorithm |
| [13] | Independent | Multiple | Multiple | Static | Delay, energy and load variance | Multi-objective evolutionary algorithm |
| [14] | Independent | Multiple | Multiple | Static | Delay, energy and cloud rental cost | Convex algorithm |
| [33] | Dependent | Single | Multiple | Static | Delay | Heuristic algorithm |
| [17] | Dependent | Single | Multiple | Static | Delay and offloading failure probability | Heuristic algorithm |
| [20] | Dependent | Single | Multiple | Static | Service failure probability | Genetic algorithm |
| [21] | Dependent | Single | Multiple | Static | Delay and energy | Integer particle swarm algorithm |
| [22] | Dependent | Single | Single | Static | Delay and energy | Deep reinforcement learning algorithm |
| [30] | Dependent | Multiple | Multiple | Static | Delay | Fuzzy logic |
| [18] | Dependent | Multiple | Multiple | Static | Delay and energy | Heuristic algorithm |
| [31] | Dependent | Multiple | Multiple | Static | Delay and energy | Convex algorithm |
| [19] | Dependent | Single | Multiple | Dynamic | Delay and energy | Heuristic algorithm |
| System parameters | Values |
|---|---|
| MD number U | 20 |
| BS number M | 4 |
| Channel bandwidth B | 10 MHz |
| Local computation capacity | 1 GHz |
| Computation capacity of MEC server | GHz |
| Input data size of task | KB |
| Demanded CPU cycles per bit | cycles/bit |
| Recommended maximum serving delay | ms |
| Maximal uplink transmit power | 23 dBm |
| Pathloss | |
| White noise | dBm/Hz |
| Time length of RHW | 250 ms |
| Chromosome | 2000 |
| Crossover probability | 0.8 |
| Mutation probability | 0.01 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Y.; Bian, Y.; Li, H.; Tan, F.; Liu, L. Flexible Offloading and Task Scheduling for IoT Applications in Dynamic Multi-Access Edge Computing Environments. Symmetry 2023, 15, 2196. https://doi.org/10.3390/sym15122196
Sun Y, Bian Y, Li H, Tan F, Liu L. Flexible Offloading and Task Scheduling for IoT Applications in Dynamic Multi-Access Edge Computing Environments. Symmetry. 2023; 15(12):2196. https://doi.org/10.3390/sym15122196
Chicago/Turabian StyleSun, Yang, Yuwei Bian, Huixin Li, Fangqing Tan, and Lihan Liu. 2023. "Flexible Offloading and Task Scheduling for IoT Applications in Dynamic Multi-Access Edge Computing Environments" Symmetry 15, no. 12: 2196. https://doi.org/10.3390/sym15122196
APA StyleSun, Y., Bian, Y., Li, H., Tan, F., & Liu, L. (2023). Flexible Offloading and Task Scheduling for IoT Applications in Dynamic Multi-Access Edge Computing Environments. Symmetry, 15(12), 2196. https://doi.org/10.3390/sym15122196