

Cross-Correlation Fusion Graph Convolution-Based Object Tracking

Abstract
:1. Introduction
- We propose an end-to-end graph convolutional tracking framework combining traditional cross-correlation operations which has a symmetrical structure. To the best of our knowledge, this is the first work to combine them directly without complex operations or other strategies.
- We propose a graph attention fusion (GAF) method to realize both part-to-part matching and global matching for information embedding. Compared with traditional graph attention trackers, which ignore the integrity of the object, our tracker can greatly improve the anti-interference and accuracy.
- Extensive experiments on several challenging benchmarks, including the VOT2016, GOT-10k, and LaSOT datasets, show that our proposed model achieves leading performance compared to state-of-the-art trackers, which means our CFGC is accurate and robust.
2. Related Work
2.1. Object Tracking and Siamese Networks
2.2. Graph Neural Networks
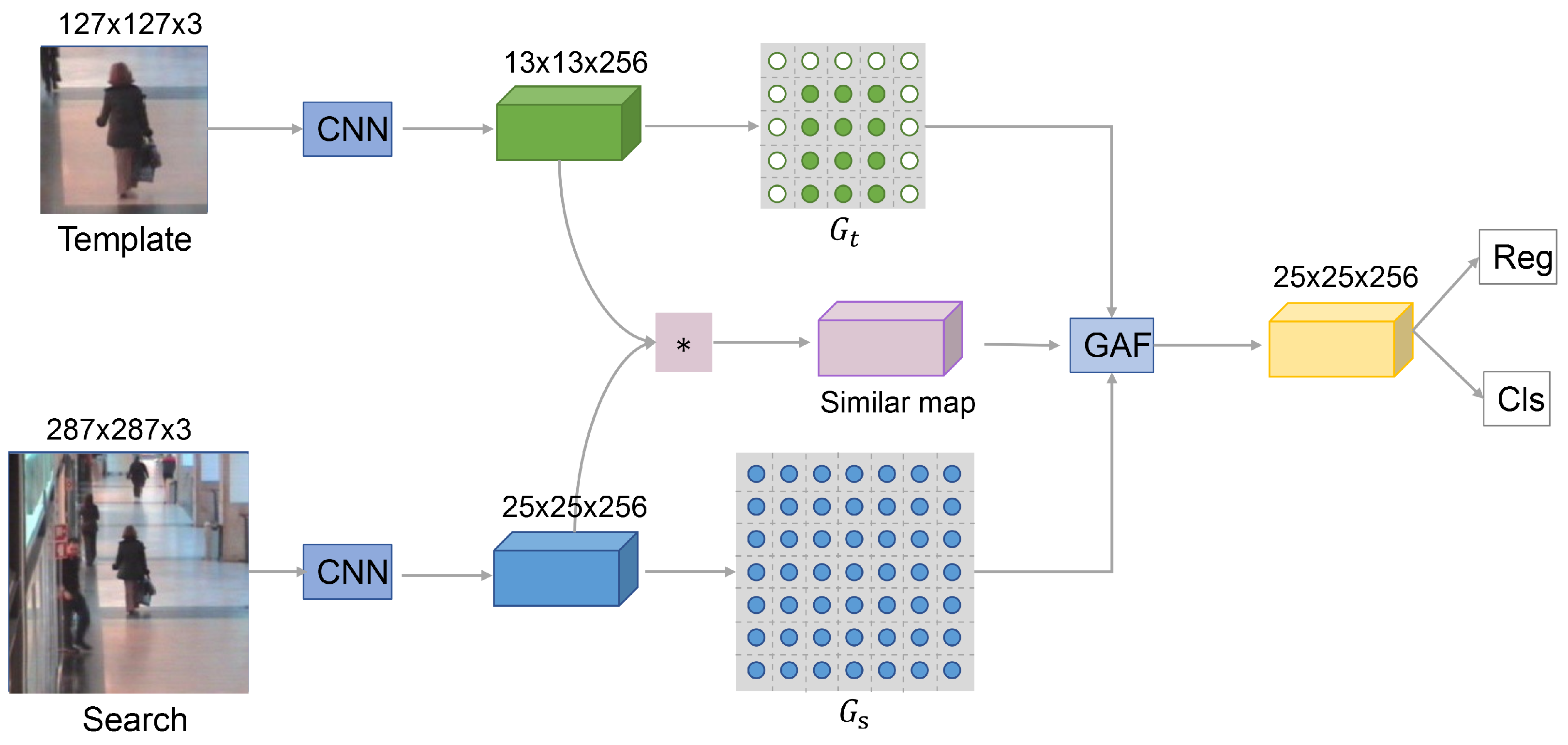
3. Method
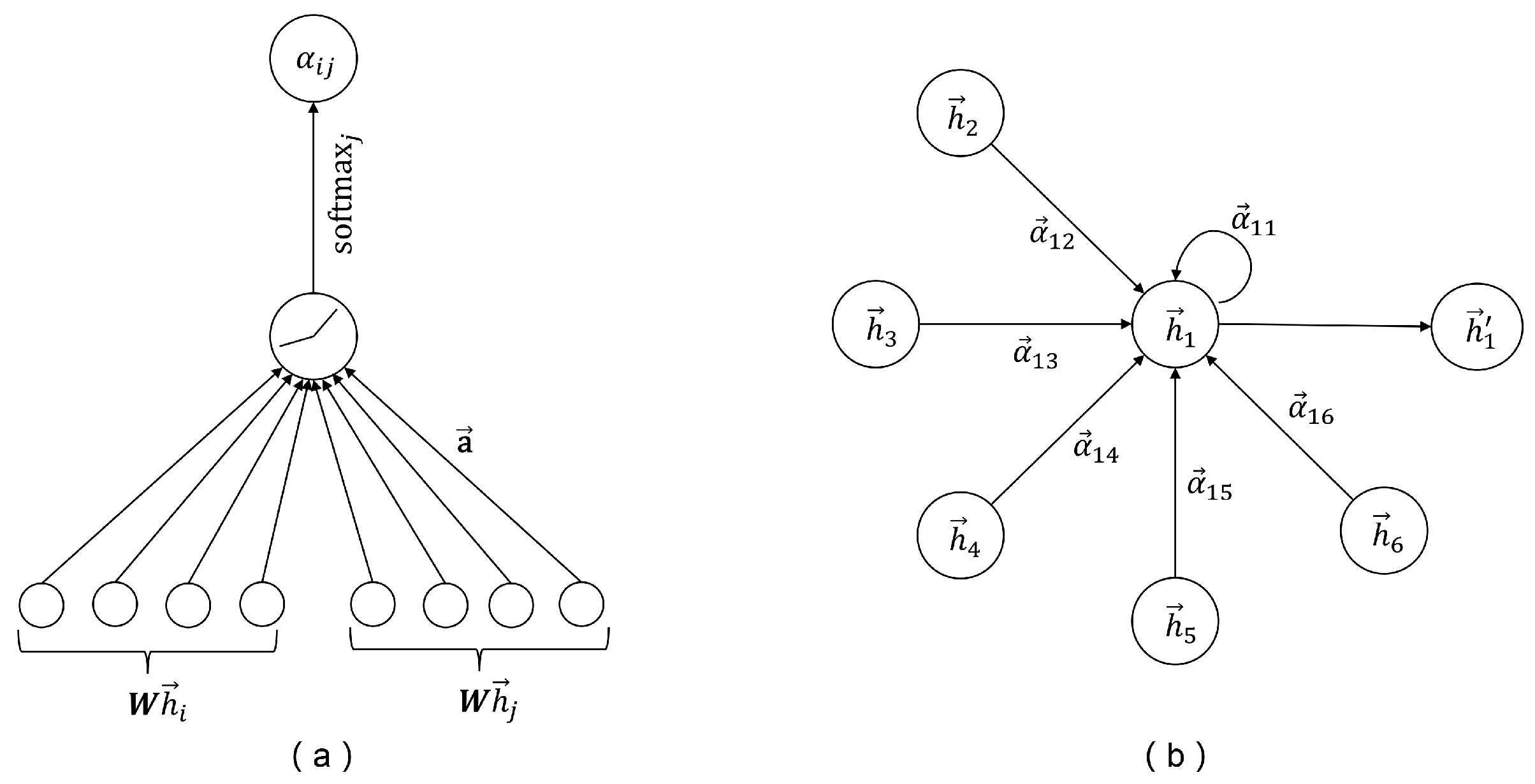
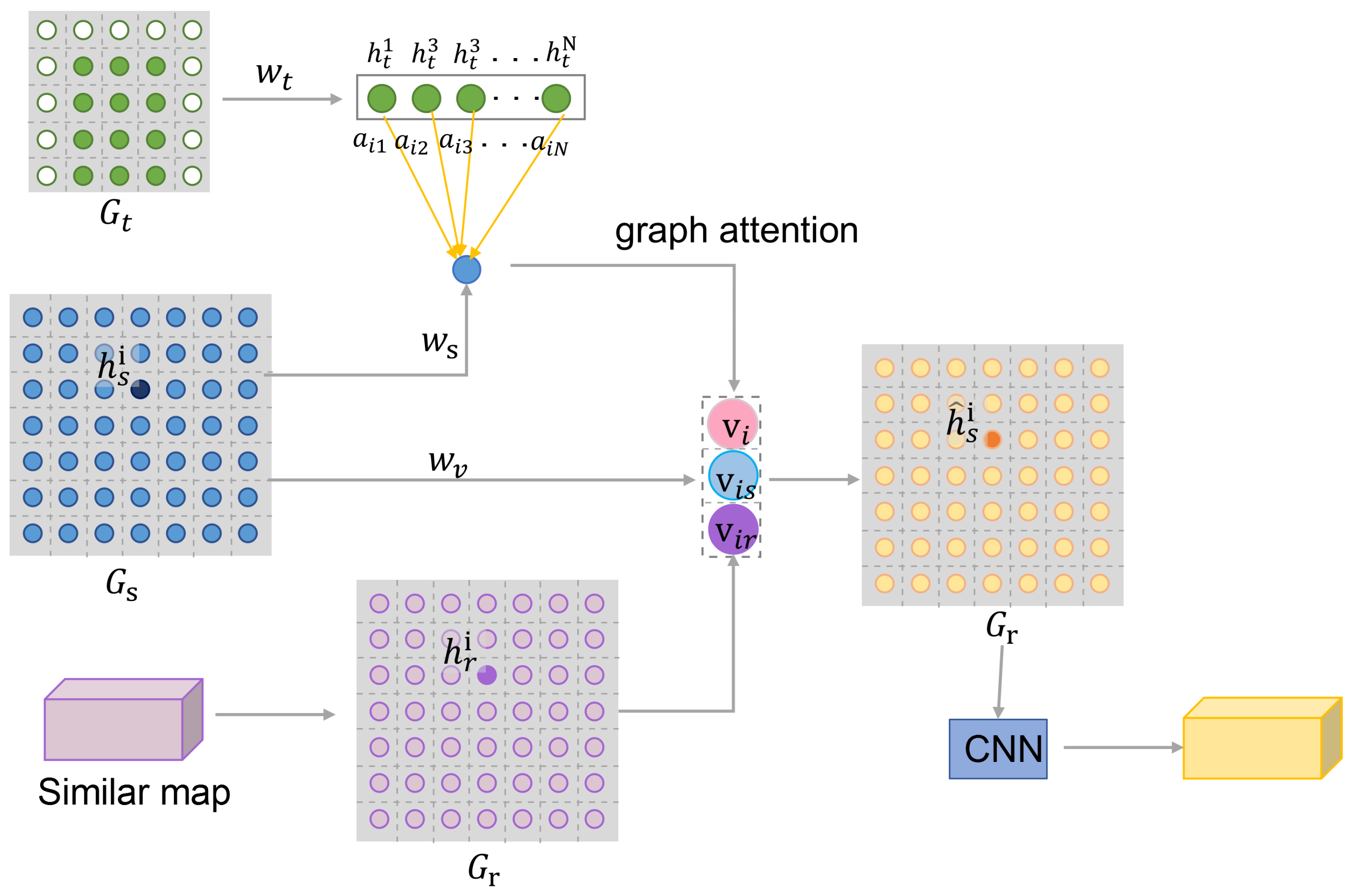
3.1. Cross-Graph Attention Convolution
3.2. Cross-Correlation Features and Feature Fusion
4. Experiments
4.1. Implementation Details
4.2. Ablation Study
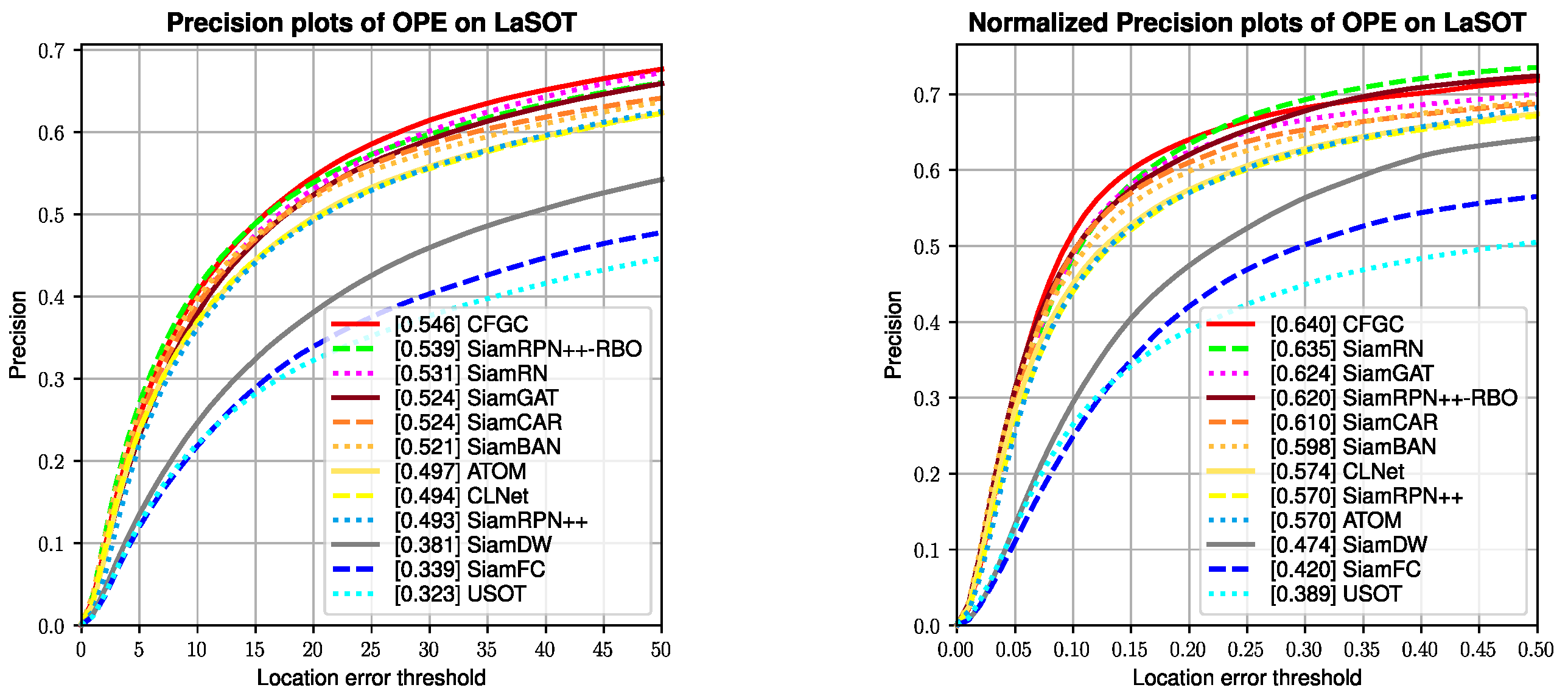
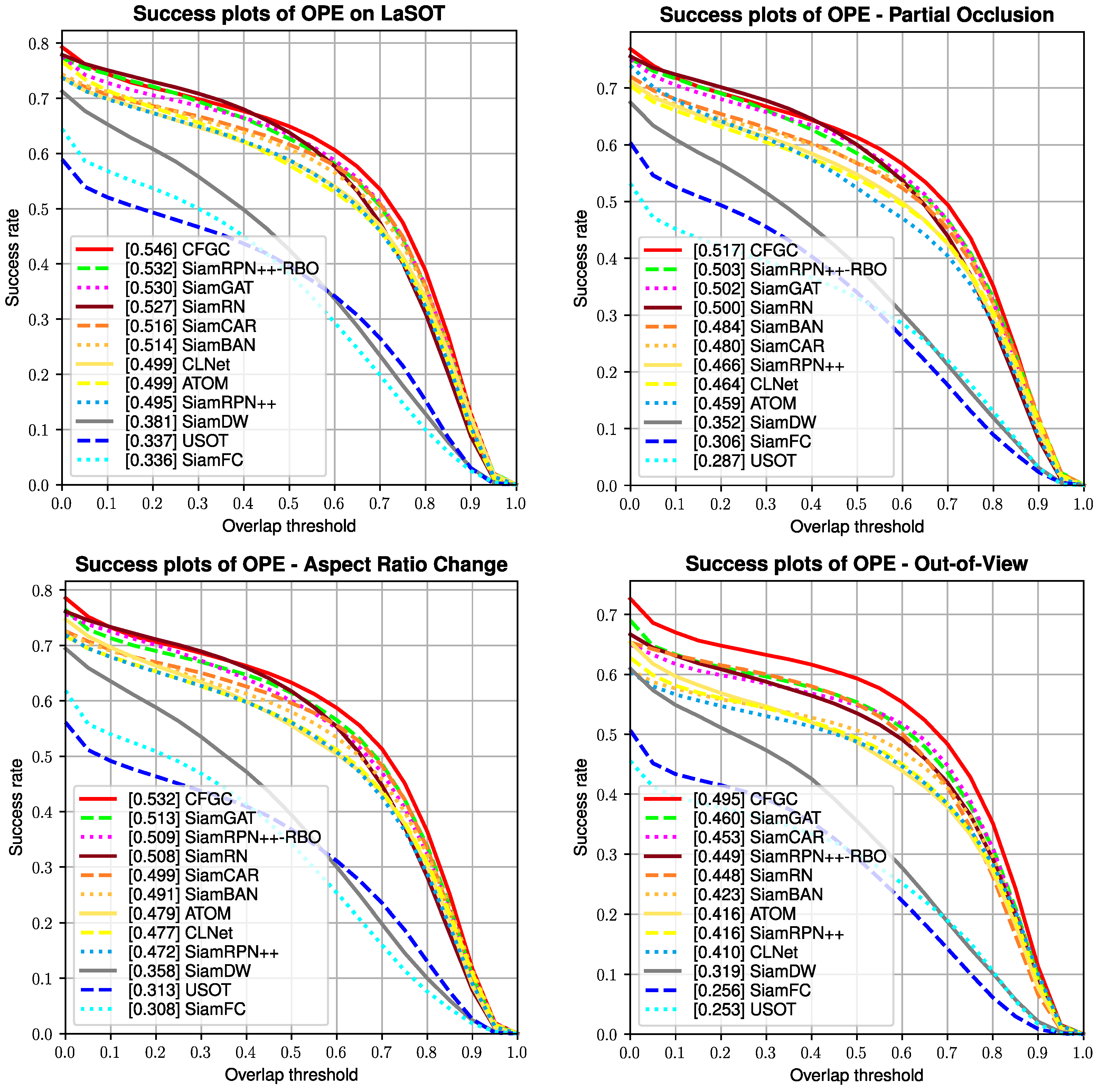
4.3. Experiments on LaSOT
4.4. Evaluation on GOT-10k
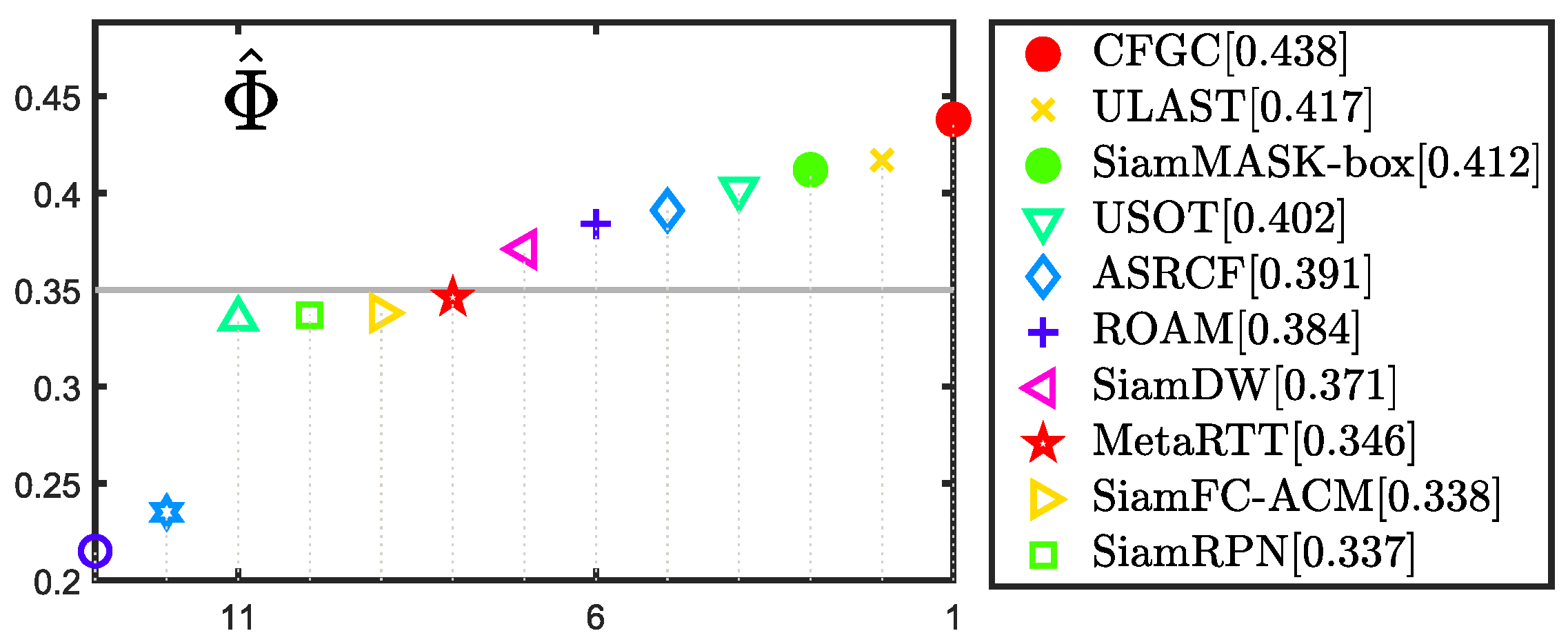
4.5. Evaluation on VOT2016
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Suljagic, H.; Bayraktar, E.; Celebi, N. Similarity based person re-identification for multi-object tracking using deep siamese network. Neural Comput. Appl. 2022, 34, 18171–18182. [Google Scholar] [CrossRef]
- Bayraktar, E.; Wang, Y.; DelBue, A. Fast re-obj: Real-time object re-identification in rigid scenes. Mach. Vis. Appl. 2022, 33, 97. [Google Scholar] [CrossRef]
- Cen, M.; Jung, C. Fully convolutional siamese fusion networks for object tracking. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018. [Google Scholar]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High performance visual tracking with siamese region proposal network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Zhu, Z.; Wang, Q.; Li, B.; Wu, W.; Yan, J.; Hu, W. Distractor-aware siamese networks for visual object tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. Siamrpn++: Evolution of siamese visual tracking with very deep networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Xu, Y.; Wang, Z.; Li, Z.; Yuan, Y.; Yu, G. Siamfc++: Towards robust and accurate visual tracking with target estimation guidelines. In Proceedings of the AAAI Conference on Artificial Intelligence (AIII), New York, NY, USA, 10 February 2020. [Google Scholar]
- Chen, Z.; Zhong, B.; Li, G.; Zhang, S.; Ji, R. Siamese box adaptive network for visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Guo, D.; Wang, J.; Cui, Y.; Wang, Z.; Chen, S. Siamcar: Siamese fully convolutional classification and regression for visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The graph neural network model. IEEE Trans. Neural Net. 2008, 20, 61–80. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, S.; Tong, H.; Xu, J.; Maciejewski, R. Graph convolutional networks: A comprehensive review. Comput. Soc. Net. 2019, 6, 1–23. [Google Scholar] [CrossRef] [Green Version]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. Stat 2018, 1050, 4. [Google Scholar]
- Gao, J.; Zhang, T.; Xu, C. Graph convolutional tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Guo, D.; Shao, Y.; Cui, Y.; Wang, Z.; Zhang, L.; Shen, C. Graph attention tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Kristan, J.M.M.; Leonardis, A.; Felsberg, M. The visual object tracking vot2016 challenge results. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 November 2016. [Google Scholar]
- Huang, L.; Zhao, X.; Huang, K. Got-10k: A large high-diversity benchmark for generic object tracking in the wild. IEEE Trans. Pattern Anal. Mach. Intell. (Tpami) 2019, 43, 1562–1577. [Google Scholar] [CrossRef] [Green Version]
- Fan, H.; Lin, L.; Yang, F.; Chu, P.; Deng, G.; Yu, S.; Bai, H.; Xu, Y.; Liao, C.; Ling, H. Lasot: A high-quality benchmark for large-scale single object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Cheng, S.; Zhong, B.; Li, G.; Liu, X.; Tang, Z.; Li, X.; Wang, J. Learning to filter: Siamese relation network for robust tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Peng, J.; Jiang, Z.; Gu, Y.; Wu, Y.; Wang, Y.; Tai, Y.; Wang, C.; Lin, W. Siamrcr: Reciprocal classification and regression for visual object tracking. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), Montréal, QC, Canada, 19–20 August 2021. [Google Scholar]
- Tang, F.; Ling, Q. Ranking-based siamese visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Danelljan, M.; Bhat, G.; Khan, F.S.; Felsberg, M. Atom: Accurate tracking by overlap maximization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Bhat, G.; Danelljan, M.; Gool, L.V.; Timofte, R. Learning discriminative model prediction for tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Wang, Y.; Kitani, K.; Weng, X. Joint object detection and multi-object tracking with graph neural networks. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021. [Google Scholar]
- Cao, P.; Zhu, Z.; Wang, Z.; Zhu, Y.; Niu, Q. Applications of graph convolutional networks in computer vision. Neural Comput. Appl. 2022, 34, 13387–13405. [Google Scholar] [CrossRef]
- Dai, P.; Weng, R.; Choi, W.; Zhang, C.; He, Z.; Ding, W. Learning a proposal classifier for multiple object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Wang, R.; Yan, J.; Yang, X. Learning combinatorial embedding networks for deep graph matching. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Lin, T.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Real, E.; Shlens, J.; Mazzocchi, S.; Pan, X.; Vanhoucke, V. Youtube-boundingboxes: A large high-precision human-annotated data set for object detection in video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–27 July 2017. [Google Scholar]
- Zhang, Z.; Peng, H. Deeper and wider siamese networks for real-time visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zheng, Z.; Wan, Y.; Zhang, Y.; Xiang, S.; Peng, D.; Zhang, B. Clnet: Cross-layer convolutional neural network for change detection in optical remote sensing imagery. ISPRS J. Photogramm. Remote. Sens. (JPRS) 2021, 175, 247–267. [Google Scholar] [CrossRef]
- Zheng, J.; Ma, C.; Peng, H.; Yang, X. Learning to track objects from unlabeled videos. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Zhang, Z.; Peng, H.; Fu, J.; Li, B.; Hu, W. Ocean: Object-aware anchor-free tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Lukezic, A.; Matas, J.; Kristan, M. D3s-a discriminative single shot segmentation tracker. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Ko, K.; Lee, J.-T.; Kim, C.-S. Pac-net: Pairwise aesthetic comparison network for image aesthetic assessment. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018. [Google Scholar]
- Zhou, Z.; Pei, W.; Li, X.; Wang, H.; Zheng, F.; He, Z. Saliency-associated object tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Yan, B.; Peng, H.; Wu, K.; Wang, D.; Fu, J.; Lu, H. Lighttrack: Finding lightweight neural networks for object tracking via one-shot architecture search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Yan, B.; Peng, H.; Fu, J.; Wang, D.; Lu, H. Learning spatio-temporal transformer for visual tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Nardo, E.D.; Ciaramella, A. Tracking vision transformer with class and regression tokens. Inf. Sci. 2023, 619, 276–287. [Google Scholar] [CrossRef]
- Dai, K.; Wang, D.; Lu, H.; Sun, C.; Li, J. Visual tracking via adaptive spatially-regularized correlation filters. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Yang, T.; Xu, P.; Hu, R.; Chai, H.; Chan, A.B. Roam: Recurrently optimizing tracking model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Shen, Q.; Qiao, L.; Guo, J.; Li, P.; Li, X.; Li, B.; Feng, W.; Gan, W.; Wu, W.; Ouyang, W. Unsupervised learning of accurate siamese tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Sio, C.H.; Ma, Y.; Shuai, H.; Chen, J.; Cheng, W. S2siamfc: Self-supervised fully convolutional siamese network for visual tracking. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020. [Google Scholar]
- Wang, Q.; Zhang, L.; Bertinetto, L.; Hu, W.; Torr, P.H.S. Fast online object tracking and segmentation: A unifying approach. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zhao, W.; Deng, M.; Cheng, C.; Zhang, D. Real-time object tracking algorithm based on siamese network. Appl. Sci. 2022, 12, 7338. [Google Scholar] [CrossRef]
- Han, W.; Dong, X.; Khan, F.S.; Shao, L.; Shen, J. Learning to fuse asymmetric feature maps in siamese trackers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Jung, I.; You, K.; Noh, H.; Cho, M.; Han, B. Real-time object tracking via meta-learning: Efficient model adaptation and one-shot channel pruning. In Proceedings of the AAAI Conference on Artificial Intelligence (AIII), New York, NY, USA, 7–12 February 2020; pp. 11205–11212. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Cross-Graph Attention | Cross-Correlation | Success | Precision |
|---|---|---|---|---|
| ✘ | ✔ | 0.516 | 0.524 | |
| LaSOT | ✔ | ✘ | 0.530 | 0.524 |
| ✔ | ✔ | 0.546 | 0.546 |
| Tracker | AO (%) | (%) | (%) |
|---|---|---|---|
| ATOM | 55.6 | 63.4 | 40.2 |
| SiamCAR | 56.9 | 67 | 41.5 |
| PACNet | 58.2 | 68.5 | 44.3 |
| SiamFC++ | 59.5 | 69.5 | 47.9 |
| D3S | 59.7 | 67.6 | 47.2 |
| SiamRPN++-RBO | 60.2 | 71.8 | 44.6 |
| Ocean-online | 61.1 | 72.1 | 47.3 |
| DiMP-50 | 61.1 | 71.7 | 49.2 |
| LightTrack | 62.3 | 72.6 | - |
| SiamRCR | 62.3 | 75.2 | 46 |
| SiamGAT | 62.7 | 74.4 | 48.8 |
| STARK | 67.2 | 76.1 | 61.2 |
| ViTCRT | 65.6 | 75.0 | 59.8 |
| CFGC | 64.0 | 75.6 | 50.7 |
| Tracker | Speed (fps) | FLOPs (G) | Params (M) |
|---|---|---|---|
| STARK | 31.7 | 20.4 | 47.2 |
| SiamGAT | 37.5 | 19.57 | 14.23 |
| CFGC | 37.03 | 19.61 | 14.29 |
| Tracker | EAO (%) ↑ | Acc (%) ↑ | Rob (%) ↓ |
|---|---|---|---|
| S2SiamFC | 21.5 | 49.3 | 63.9 |
| SiamFC | 23.5 | 53.2 | 46.1 |
| SiamFP | 33.5 | 53.7 | 38.1 |
| SiamRPN | 33.7 | 57.8 | 31.2 |
| SiamFC-ACM | 33.8 | 53.5 | 29.4 |
| MetaRTT | 34.6 | - | - |
| SiamDW | 37.1 | 58.0 | 24.0 |
| ROAM | 38.4 | 55.6 | 13.8 |
| ASRCF | 39.1 | 56.0 | 18.7 |
| USOT | 40.2 | 60.0 | 23.3 |
| SiamMASK-box | 41.2 | 62.3 | 23.3 |
| ULAST | 41.7 | 60.3 | 21.4 |
| CFGC | 43.8 | 64.6 | 19.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, L.; Chen, W.; Jiang, X. Cross-Correlation Fusion Graph Convolution-Based Object Tracking. Symmetry 2023, 15, 771. https://doi.org/10.3390/sym15030771
Fan L, Chen W, Jiang X. Cross-Correlation Fusion Graph Convolution-Based Object Tracking. Symmetry. 2023; 15(3):771. https://doi.org/10.3390/sym15030771
Chicago/Turabian StyleFan, Liuyi, Wei Chen, and Xiaoyan Jiang. 2023. "Cross-Correlation Fusion Graph Convolution-Based Object Tracking" Symmetry 15, no. 3: 771. https://doi.org/10.3390/sym15030771
APA StyleFan, L., Chen, W., & Jiang, X. (2023). Cross-Correlation Fusion Graph Convolution-Based Object Tracking. Symmetry, 15(3), 771. https://doi.org/10.3390/sym15030771