1. Introduction
In the era of big data, a large number of personal information data are generated every day, such as social information [
1], physiological signals collected by intelligent wearable devices [
2], and data auctions in the internet of things [
3]. Information digitization technology enables various institutions to easily collect a large amount of information and data, publish statistical results in various forms, and conduct data analysis and research. Although the analysis and mining results of these data can help people to analyze and study things, there will also be the problem that the private information contained will be stolen in the actual process of publishing information. Histograms, as a common method to intuitively display the characteristics of data distribution, are often used to publish statistical data. In this method, the published data is divided into disjoint buckets according to some attributes, and then the bucket count is used to represent the data characteristics. However, if we directly publish the statistical histogram without privacy protection in the process of publishing the information, an attacker can infer the user data by combining the background knowledge and the real count of the histogram bucket, resulting in the problem of user privacy disclosure.
For example,
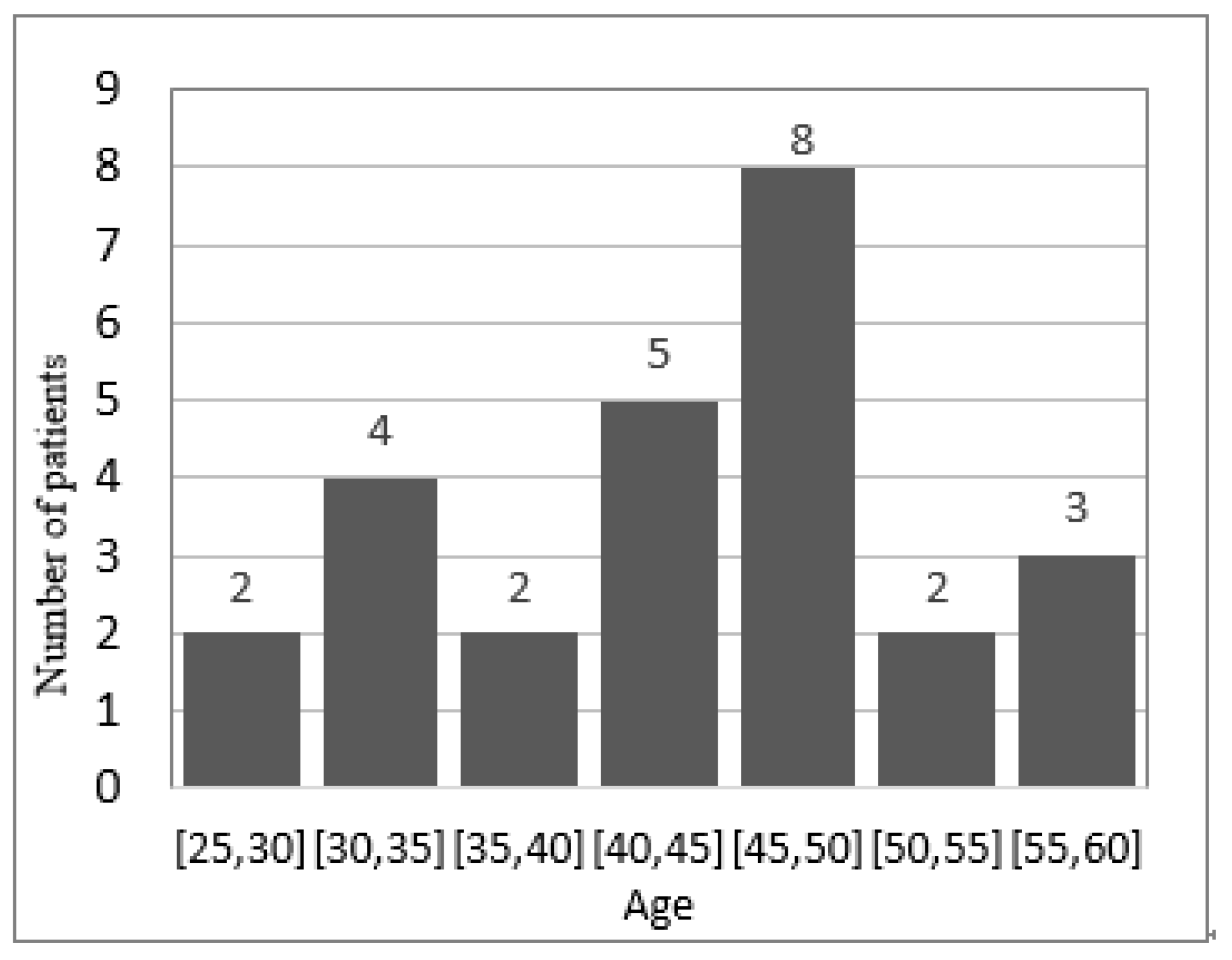
Table 1 shows some sensitive data records of whether a group of patients are infected with HIV, and
Figure 1 shows the statistical histogram of HIV+ distribution in
Table 1 after taking the values according to their age attributes. If the attacker already knows that Ava is 29 years old, and if the attacker obtains the disease information of three people in the bucket [20, 30] except Ava by some means, it can be accurately inferred that AVA is infected with HIV.
In order to prevent the disclosure of users’ privacy, it is necessary to protect the privacy of data before publishing. The existing privacy protection models include k-anonymity [
4,
5] and a series of extended models [
6,
7,
8], such as l-diversity, t-closeness, and so on. However, these typical privacy protection models limit the attacker’s background knowledge when they are defined, and are only effective for specific attack models. In practice, the attacker has much more background knowledge than this hypothesis. Dwork proposed a new privacy definition, differential privacy [
9], in 2006 to solve the problem of database privacy disclosure. Compared with the traditional protection model, the differential privacy model has two significant advantages: (1) it does not depend on the background knowledge of the attacker; (2) it has a rigorous statistical model and can provide quantifiable privacy assurance. Therefore, differential privacy is widely used as the main technology of data privacy publishing. The main idea of differential privacy is to add enough noise to each histogram count, so that the attacker cannot use the information of the specific record owner to generate the histogram before processing. However, the increased noise for higher privacy requirements usually greatly reduces the accuracy of the published histogram. In order to solve this problem, this paper does not consider directly adding noise to the histogram count, but uses the reconstruction method to reduce the data sensitivity to reduce the noise amplitude. In this process, the reconstruction error and noise error are balanced at the same time, which greatly improves the availability of data when the histogram meets the privacy.
Although the current histogram publishing method based on grouping can ensure the privacy and security of the published histogram, it cannot improve the accuracy of the published histogram, resulting in low availability. The existing methods mainly have the following problems:
The local grouping method only considers the similar bucket count of the nearest neighbor, but cannot measure the buckets with similar counts in the global range, so that there is a large reconstruction error in grouping.
The global grouping method obtains the optimal error balance global grouping of the original histogram through fixed length grouping or greedy clustering grouping, which may fall into local optimization and cannot better balance the reconstruction error and Laplace error [
10], resulting in the reduction in the availability of the published histogram.
In view of the above problems, this paper realizes the satisfaction -differential privacy histogram publishing method DPHR. Firstly, an approximate ranking algorithm based on an exponential mechanism is proposed, which considers the relationship between the difference between bucket counts and the outlier length , the exponential mechanism is used to sort the bucket count of the original histogram globally. Based on the sorting results, combined with the dynamic programming algorithm based on the global minimum error, the optimal grouping strategy is obtained. On the basis of meeting the requirements of differential privacy, this method balances the reconstruction error (RE) generated by the group mean and the Laplace error (LE) generated by adding Laplace noise in the grouping, and effectively reduces the reconstruction error (RE) in the sorting results, which not only ensures the privacy of the published histogram, but also improves the availability of the data.
The main contributions of this paper are as follows:
Aiming at addressing the problem of low data availability of the existing grouping histogram publishing algorithm, an approximate sorting algorithm based on an exponential mechanism is adopted, which is based on the relationship between the difference between bucket counts and the length of outliers . The exponential mechanism is used to sort the bucket count of the original histogram globally, so as to improve the accuracy of the grouping.
A dynamic programming algorithm based on the global minimum error is proposed, to realize the global grouping with the best error balance on the sorting histogram, balance the reconstruction error and Laplace error, and reduce the overall difference between the published histogram and the original histogram.
2. Related Work
Ref. [
11] proposed the Laplacian mechanism (LPA), which publishes the differential privacy histogram by adding independent and identically distributed Laplacian noise to each bucket of the histogram, which lays a theoretical foundation for later research results. However, due to the addition of noise, the cumulative noise error of this method in the face of a long-range counting query is too large, which affects the accuracy of the data. In view of the above shortcomings, many scholars have put forward improved methods. The grouping method reconstructs the histogram grouping structure, uses the group mean to approximate the original histogram count, and then reduces the added Laplace noise error in the fixed privacy budget. Such methods use the group mean and Laplacian mechanism to protect privacy, which inevitably produces reconstruction errors caused by reconstruction and Laplacian errors caused by adding Laplacian noise. Ref. [
12] proposed the Noisefirst and StructureFirst algorithms. The Noisefirst algorithm performs dynamic programming on the histogram after the addition of noise and divides the optimal grouping. Because too much noise is added first, the privacy cost is high. The StructureFirst algorithm uses an exponential mechanism to divide the optimal grouping of the histogram, and adds Laplace noise to the group mean. However, this method needs to specify the number of groups K, and does not take into account the balance between the reconstruction error and noise error caused by the groups. Ref. [
13] proposed the P-HPartition algorithm, which uses an exponential mechanism combined with the greedy bisection strategy to continuously divide and group, so as to obtain the division scheme with the minimum error value. Both P-HPartition and StructureFirst are based on the idea of local grouping. They only consider the numerical nearest neighbor relationship of buckets in the local range, cannot measure the nearest neighbor relationship of global count, and cannot well balance the reconstruction error and Laplace error.
Aiming at the shortcomings of local grouping, here a histogram publishing method based on global grouping is developed. Ref. [
14] proposed obtaining an ordered histogram by row sampling or column sampling, and divide the ordered histogram by equal width. However, a fixed length packet cannot effectively balance the reconstruction error and noise error, which affects the availability of data. The APH [
15] method uses the threshold mechanism to count the buckets within the threshold without adding noise, and then obtains the grouping through greedy clustering. Although this method reduces the Laplace error, it leads to an imbalance between the reconstruction error and Laplace error when the privacy budget is small. Ref. [
16] and others proposed using sampling technology to obtain an approximate correct ranking, and then greedy clustering to obtain global grouping. The IHP [
17] method uses an exponential mechanism to continuously divide and group, so as to obtain the balance of the Laplace error and reconstruction error. Ref. [
18] introduced a quantitative mechanism of associated privacy disclosure evaluation in the literature to evaluate the loss in privacy disclosure in the process of histogram publishing. Ref. [
19] proposed an algorithm to publish a node strength histogram based on node differential privacy. Firstly, the “sequence edge” is used to reduce the query sensitivity and make the distribution of the node strength more dense. Then, the histogram is divided into groups by a clustering method, and finally, the node strength histogram is published. However, the algorithm also has the problem that it cannot balance the publishing errors of the two histograms.
4. Method
4.1. Symmetry Differential Privacy Histogram Released Algorithm
Aiming at the problems existing in the existing methods, this paper realizes the satisfaction symmetry
-differential privacy histogram publishing method DPHR. The specific implementation details are shown in Algorithm 1.
| Algorithm 1 DPHR |
- Input:
original histogram , privacy budget ; - Output:
histogram satisfying differential privacy; - 1:
, - 2:
; /* Approximate sorting of H*/ - 3:
; /* H is optimally grouped based on global error */ - 4:
for do - 5:
; /* Calculate the mean value of each group after grouping*/ - 6:
end for - 7:
for do - 8:
; /* Add Laplace noise to the mean of each group*/ - 9:
end for - 10:
return ;
|
Correct sorting and grouping are the key to this algorithm. Given the privacy budget, the is divided into two parts: and , which are used for sorting and denoising. Given the original histogram H and privacy budget , the approximate ranking (line 2) is obtained by using the exponential mechanism. After sorting, the histogram is optimized for grouping (row 3) in order to reduce the global error of each group. Finally, the privacy budget is used to add Laplace noise to the mean of each group (lines 4–9).
4.2. Approximate_Sort algorithm
When reconstructing the original histogram, if only the bucket counts of the nearest neighbors are combined, it will bring huge errors in the grouping. Therefore, we consider the relationship between the difference between bucket counts and the discrete length , using the exponential mechanism to approximate sort the bucket count of the original histogram, and the correct sorting of histogram H is approximately obtained. Here, we give the following definitions.
Definition 6 (Discrete length). If the vertex set in an undirected graph is , for point , the discrete length δ is .
This method uses the exponential mechanism to approximate the correct ranking under the condition of differential privacy. If the histogram method is sorted directly, it will make its output different from the count sorting of adjacent histograms, which does not meet the definition requirements of differential privacy. Therefore, we use the exponential mechanism to select the nearest neighbor buckets and select the buckets with similar counts, and the result has a certain randomness. The definition of a nearest neighbor bucket is as follows.
We use the outlier length as the distance threshold, and define the nearest neighbor bucket set of base bucket
Taking bucket as the base bucket, each bucket of the nearest neighbor bucket set can be scored according to the bucket count difference and bucket order: , where is the absolute value of the count difference between and , and is the absolute value of the sequence difference between and . According to Definition 5, the exponential mechanism allocates the probability of output results according to the level of the scoring function. The larger the scoring function value, the greater the possibility of output. Therefore, the exponential mechanism can be used to continuously select the bucket whose count is most similar to that of the previous base bucket from the nearest neighbor bucket set to form an ordered histogram .
The detailed implementation process of the Approximate_Sort algorithm is as follows (Algorithm 2):
| Algorithm 2 Approximate_Sort algorithm |
![Symmetry 15 01099 i001]() |
The histogram
is shown in
Figure 1, first, select
as the base bucket for sorting, and the outlier length
of bucket
, obtain the nearest neighbor bucket set
of bucket
, then,
,
,
,
, select bucket
according to the exponential mechanism and put it into the sorting queue. If the next benchmark bucket is
,
,
,
, put bucket
into the sorting queue. The next benchmark bucket is
. Continuously calculate the set of adjacent buckets, and use the exponential mechanism to select buckets with similar counts and put them into the sorting queue. The final sorting result is
.
4.3. Optimized_Cluster algorithm
After using the exponential mechanism to obtain the ordered histogram, in order to adaptively obtain the ideal grouping scheme, we use dynamic programming technology to solve the grouping problem. The problem is described as follows: given the histogram bucket count sequence
H, find several segmentation points, and find the best histogram group
that minimizes the error evaluation function among all possible histograms with exactly
K groups. The error evaluation function used in traditional methods such as the StructureFirst method is
, which is the sum of the squares of errors between the group mean and the original value of the combined partial histogram sequence
. The corresponding dynamic programming recurrence formula is as follows:
However, only taking the reconstruction error as the error evaluation function for dynamic programming, the grouping obtained may not be the grouping scheme with the smallest total error, and cannot effectively balance the reconstruction error and noise error. Therefore, we propose the calculation formula of the global error, and take the global error as the error evaluation function to obtain the global grouping scheme with the smallest total error.
Theorem 3. For any group , it has a global error , where is the mean of group , is the reconstruction error RE, and is the Laplace error, LE.
Proof. According to the reconstruction error and noise error released by the histogram grouping, we can know that the average value of the group count is
, and the size of the Laplace noise added to
is
, then the expectation of
can be expressed as
Therefore, the new dynamic programming recurrence formula is as follows:
represents the minimum global error in covering histogram and dividing it into k groups, and represents the global error in merging subsequences of partial histograms as a group. □
The Optimized_Cluster algorithm is presented in Algorithm 3:
| Algorithm 3 Optimized_Cluster algorithm |
![Symmetry 15 01099 i002]() |
Using the data in
Figure 1 for an example analysis. The specific analysis process is as follows. The privacy budget is taken as
= 1, the number of groups
:
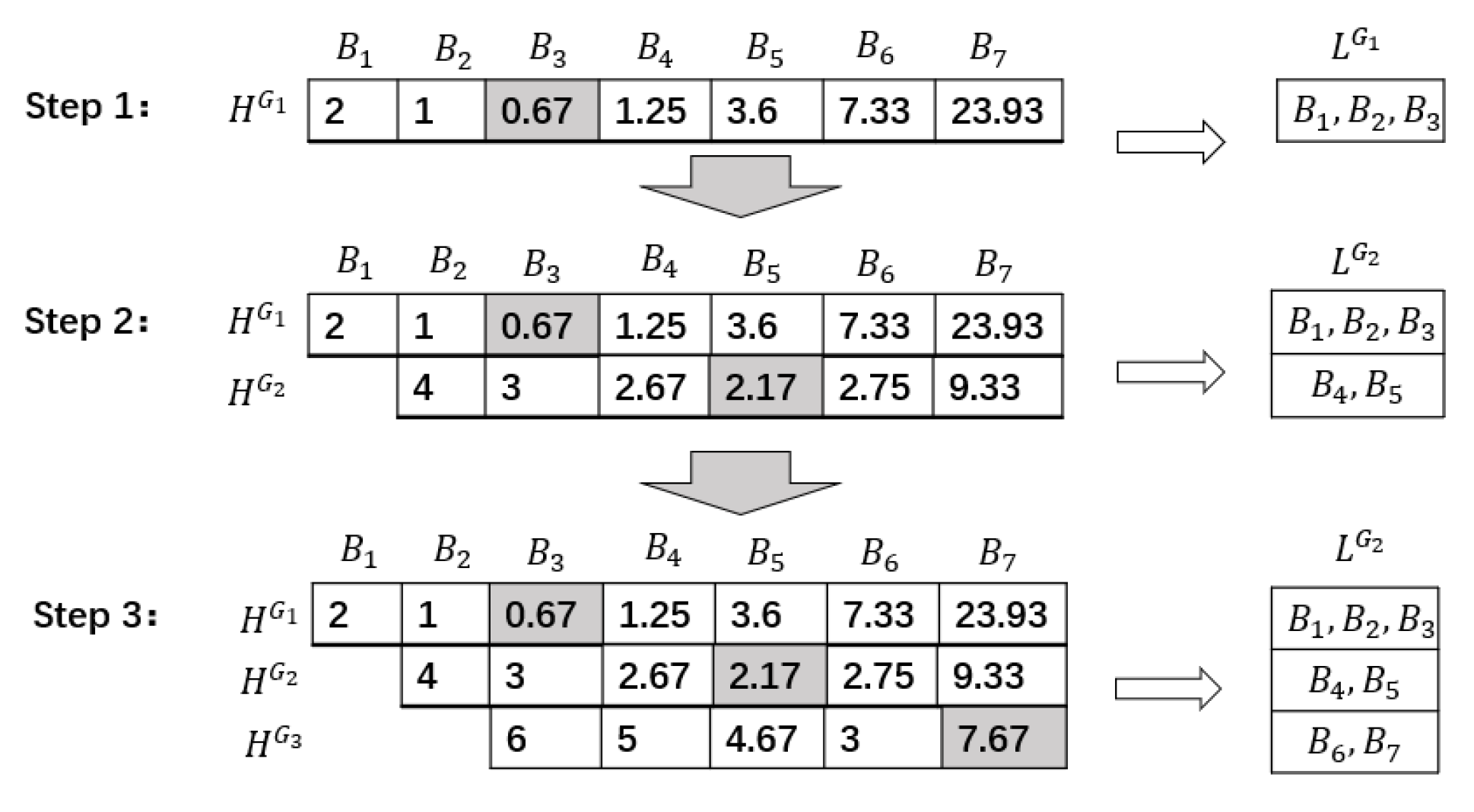
Steps 1–3 in
Figure 2 describe the results of each cycle of the optimized grouping algorithm. In each step, the algorithm can obtain the optimal grouping structure under the current number of groups. The two-dimensional table
on the left-hand side of
Figure 2 stores the intermediate result of the dynamic programming, which represents the minimum global error
of each grouping structure recorded by dividing the grouping of n buckets in
into one group, two groups, …, to
k groups. The j-th row and i-th column in the two-dimensional table
are used to store the minimum error caused by dividing the first i buckets into j packets. The outer layer circularly uses the grouping structure
from
to
, and the inner layer circularly uses the bucket
from
to
.
T is calculated successively through the recursive Formula (7), and the backtracking method is used to traverse the two-dimensional table to determine its grouping structure. Finally, the grouping structure
with the lowest
and the optimal number of packets
k are selected. Shaded
cells represent the optimal histogram grouping division under the current number of groups. The list on the right-hand side of
Figure 2 is
, which represents the current optimal grouping structure stored under different groups, which is determined according to the minimum global error
in the two-dimensional table.
7. Conclusions
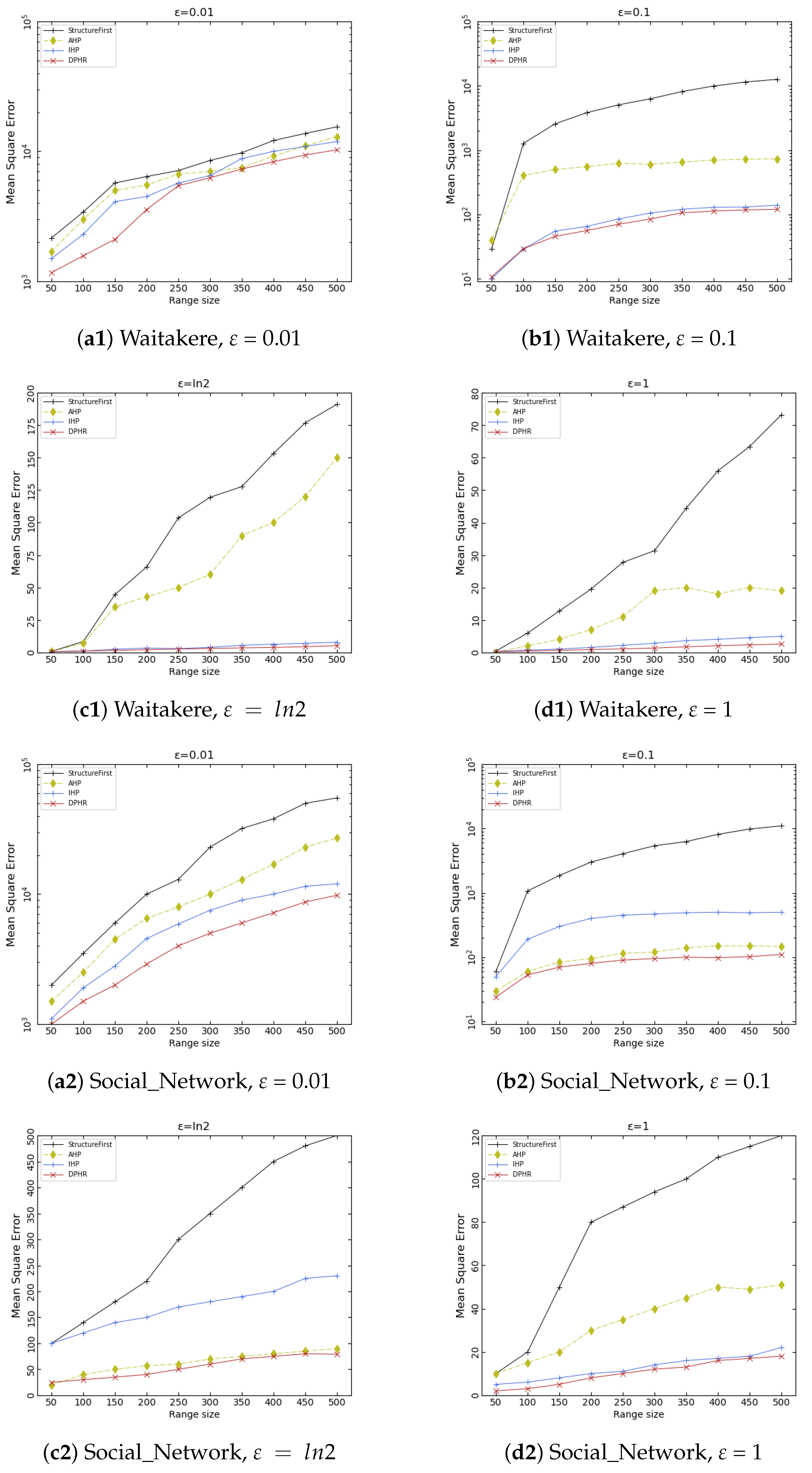
Aiming at the differential privacy histogram publishing method, this paper proposes a histogram publishing DPHR method based on sorting and grouping. Aiming at addressing the problem that the existing methods cannot balance the reconstruction error caused by grouping and the noise error caused by noise, this method puts forward a solution. The DPHR algorithm includes two important algorithms: Approximate_Sort algorithm and Optimized_Cluster algorithm. Among them, the Approximate_Sort algorithm is mainly based on the idea of smooth grouping, which uses approximate sorting on the original histogram to prepare for reducing the error in the grouping reconstruction. The Optimized_Cluster algorithm mainly carries out adaptive grouping according to the optimized dynamic programming recursive formula, to obtain the grouping scheme with the minimum global error, and balance the reconstruction error and Laplace noise error, so as to improve the accuracy of the final published histogram. The privacy analysis of DPHR shows that this method can better protect the privacy of published histogram data, and the experimental tests show that the usability of this method is better than other methods.
The Optimized_Cluster algorithm mainly carries out adaptive grouping according to the optimized dynamic programming recursive formula to obtain the grouping scheme with the minimum global error, and balance the reconstruction error and Laplace noise error, so as to improve the accuracy of the final published histogram. The privacy analysis of DPHR shows that this method can better protect the privacy of published histogram data, and the experimental test shows that the usability of this method is better than other methods.
The research perspective of the differential privacy histogram publishing method in this paper is not comprehensive enough. The data published by the differential privacy publishing algorithm studied in this paper is a static dataset. Future research work can also study the privacy protection of continuous data in real time.









{kind=link}
{kind=link}
{kind=link}