
A Novel Image Similarity Measure Based on Greatest and Smallest Eigen Fuzzy Sets



Abstract
:1. Introduction
- -
- It is computationally faster to calculate the iterative algorithm to compute SEFS and GEFS as it converges quickly;
- -
- It provides a very efficient image similarity measure as it improves the image similarity of PSNR and SSIM-based indices; moreover, it is more robust to image noise than PSNR and SSIM-based similarity measures;
- -
- Unlike other image quality measures, it does not depend on specific parameters that must be set beforehand and does not need massive learning image datasets to run.
2. Preliminaries
| Algorithm 1: Find the GEFS of R with respect to the max–min composition |
|
|
| Algorithm 2: Find the SEFS of R with respect to the min–max composition |
|
|
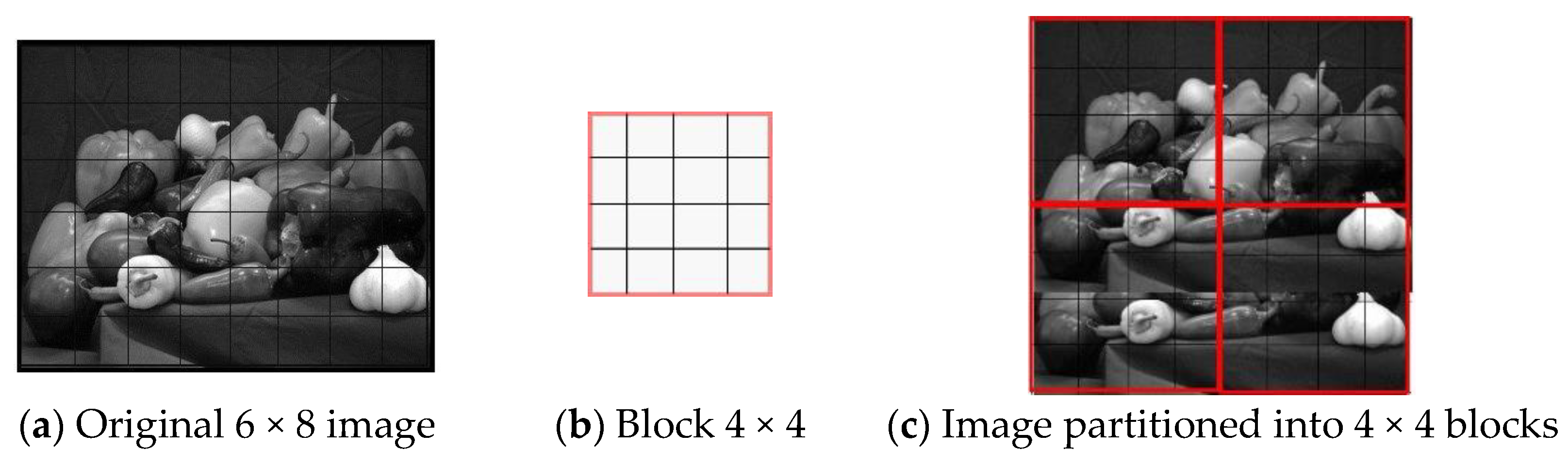
3. The GEFS–SEFS Image Similarity Measure
| Algorithm 3: GEFS–SEFS image similarities |
| Input: N × M images I1 and I2 |
| Sizes of the blocks n |
| Output: Similarity S between the two images I1 and I2 |
|
|
4. Discussion and Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, Z.; Bovik, A.C. Modern Image Quality Assessment. Synth. Lect. Image Video Multimed. Process. 2006, 2, 1–156. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Simoncelli, E.P.; Bovik, A.C. Multiscale structural similarity for image quality assessment. In Proceedings of the Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, Pacific Grove, CA, USA, 9–12 November 2003. [Google Scholar] [CrossRef]
- Li, C.; Bovik, A.C. Three-component weighted structural similarity index. IS&T/SPIE Electron. Imaging 2009, 7242, 72420Q. [Google Scholar]
- Liu, Z.; Laganière, R. Phase congruence measurement for image similarity assessment. Pattern Recognit. Lett. 2006, 28, 166–172. [Google Scholar] [CrossRef]
- Kovesi, P. Phase congruency: A low-level image invariant. Psychol. Res. 2000, 64, 136–148. [Google Scholar] [CrossRef] [PubMed]
- Chen, G.H.; Yang, C.L.; Xie, S.L. Gradient-based structural similarity for image quality assessment. In Proceedings of the 2006 International Conference on Image Processing, Atlanta, GA, USA, 8–11 October 2006; pp. 2929–2932. [Google Scholar] [CrossRef]
- Han, H.-S.; Kim, D.-O.; Park, R.-H. Gradient information-based image quality metric. IEEE Trans. Consum. Electron. 2010, 56, 361–362. [Google Scholar] [CrossRef]
- Liu, A.; Lin, W.; Narwaria, M. Image Quality Assessment Based on Gradient Similarity. IEEE Trans. Image Process. 2011, 21, 1500–1512. [Google Scholar] [CrossRef] [PubMed]
- Xue, W.; Zhang, L.; Mou, X.; Bovik, A.C. Gradient Magnitude Similarity Deviation: A Highly Efficient Perceptual Image Quality Index. IEEE Trans. Image Process. 2013, 23, 684–695. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Zhang, L.; Mou, X.; Zhang, D. FSIM: A Feature Similarity Index for Image Quality Assessment. IEEE Trans. Image Process. 2011, 20, 2378–2386. [Google Scholar] [CrossRef] [PubMed]
- Sampat, M.P.; Wang, Z.; Gupta, S.; Bovik, A.C.; Markey, M.K. Complex Wavelet Structural Similarity: A New Image Similarity Index. IEEE Trans. Image Process. 2009, 18, 2385–2401. [Google Scholar] [CrossRef] [PubMed]
- Babenko, A.; Slesarev, A.; Chigorin, A.; Lempitsky, V. Neural codes for image retrieval. In Proceedings of the ECCV 2014—13th European Conference, Zurich, Switzerland, 6–12 September 2014. 16 p. [Google Scholar] [CrossRef]
- Melekhov, I.; Kannala, J.; Rahtu, E. Siamese network features for image matching. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 378–383. [Google Scholar] [CrossRef]
- Appalaraju, S.; Chaoji, V. Image similarity using Deep CNN and Curriculum Learning. arXiv 2017, arXiv:1709.08761. [Google Scholar] [CrossRef]
- Yuan, X.; Liu, Q.; Long, J.; Hu, L.; Wang, Y. Deep Image Similarity Measurement Based on the Improved Triplet Network with Spatial Pyramid Pooling. Information 2019, 10, 129. [Google Scholar] [CrossRef]
- Ding, K.; Ma, K.; Wang, S.; Simoncelli, E.P. Image Quality Assessment: Unifying Structure and Texture Similarity. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 2567–2581. [Google Scholar] [CrossRef] [PubMed]
- Shanmugamani, R. Deep Learning for Computer Vision: Expert Techniques to Train Advanced Neural Networks Using Ten-sorFlow and Keras; Packt Publishing Ltd.: Birmingham, UK, 2018; 3010 p, ISBN 978-1-78829-562-8. [Google Scholar]
- Felix, R.; Kretzberg, T.; Wehner, M. Image Analysis based on Fuzzy Similarities. In Fuzzy-Systems in Computer Science; Springer: Berlin/Heidelberg, Germany, 1994; pp. 109–116. [Google Scholar] [CrossRef]
- Nachtegael, M.; Schulte, S.; De Witte, V.; Mélange, T.; Kerre, E.E. Image Similarity—From Fuzzy Sets to Color Image Applications. In Advances in Visual Information Systems: 9th International Conference, VISUAL 2007 Shanghai, China, June 28–29, 2007 Revised Selected Papers 9; Springer: Berlin/Heidelberg, Germany, 2007; Volume 4781, pp. 26–37. [Google Scholar] [CrossRef]
- Di Martino, F.; Sessa, S. Comparison between images via bilinear fuzzy relation equations. J. Ambient. Intell. Humaniz. Comput. 2017, 9, 1517–1525. [Google Scholar] [CrossRef]
- Sanchez, E. Resolution of Eigen fuzzy sets equations. Fuzzy Sets Syst. 1978, 1, 69–74. [Google Scholar] [CrossRef]
- Sanchez, E. Eigen fuzzy sets and fuzzy relations. J. Math. Anal. Appl. 1981, 81, 399–421. [Google Scholar] [CrossRef]
- Bourke, M.M.; Fisher, D. Convergence, eigen fuzzy sets and stability analysis of relational matrices. Fuzzy Sets Syst. 1996, 81, 227–234. [Google Scholar] [CrossRef]
- Nobuhara, H.; Hirota, K. A solution for eigen fuzzy sets of adjoint max-min composition and its application to image analysis. In Proceedings of the IEEE International Symposium on Intelligent Signal Processing, Budapest, Hungary, 6 September 2003. [Google Scholar] [CrossRef]
- Di Martino, F.; Nobuhara, H.; Sessa, S. Eigen fuzzy sets and image information retrieval. In Proceedings of the 2004 IEEE International Conference on Fuzzy Systems, Budapest, Hungary, 25–29 July 2004; pp. 1285–1390. [Google Scholar] [CrossRef]
- Di Martino, F.; Sessa, S.; Nobuhara, H. Eigen fuzzy sets and image information retrieval. In Handbook of Granular Computing; Pedrycz, W., Skowron, A., Kreinovich, V., Eds.; Wiley: New York, NY, USA, 2008; pp. 863–872. [Google Scholar] [CrossRef]
- Nobuhara, H.; Bede, B.; Hirota, K. On various eigen fuzzy sets and their application to image reconstruction. Inf. Sci. 2006, 176, 2988–3010. [Google Scholar] [CrossRef]
- Di Martino, F.; Sessa, S. A Genetic Algorithm Based on Eigen Fuzzy Sets for Image Reconstruction. In Applications of Fuzzy Sets Theory: 7th International Workshop on Fuzzy Logic and Applications, WILF 2007, Camogli, Italy, July 7–10, 2007. Proceedings 7; Springer: Berlin/Heidelberg, Germany, 2007; Volume 4578, pp. 342–348. [Google Scholar]
- Rakus-Andersson, E. The greatest and the least eigen fuzzy sets in evaluation of the drug effectiveness levels. In Artificial Intelligence and Soft Computing—ICAISC 2006; Lecture Notes in Computer Science; Rutkowski, L., Tadeusiewicz, R., Zadeh, L.A., Żurada, J.M., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; Volume 402. [Google Scholar]
- Di Martino, F.; Sessa, S. Eigen Fuzzy Sets and their Application to Evaluate the Effectiveness of Actions in Decision Problems. Mathematics 2020, 8, 1999. [Google Scholar] [CrossRef]
- Di Martino, F.; Sessa, S. Image Matching by Using Fuzzy Transforms. Adv. Fuzzy Syst. 2013, 2013, 760704. [Google Scholar] [CrossRef]









{kind=link}
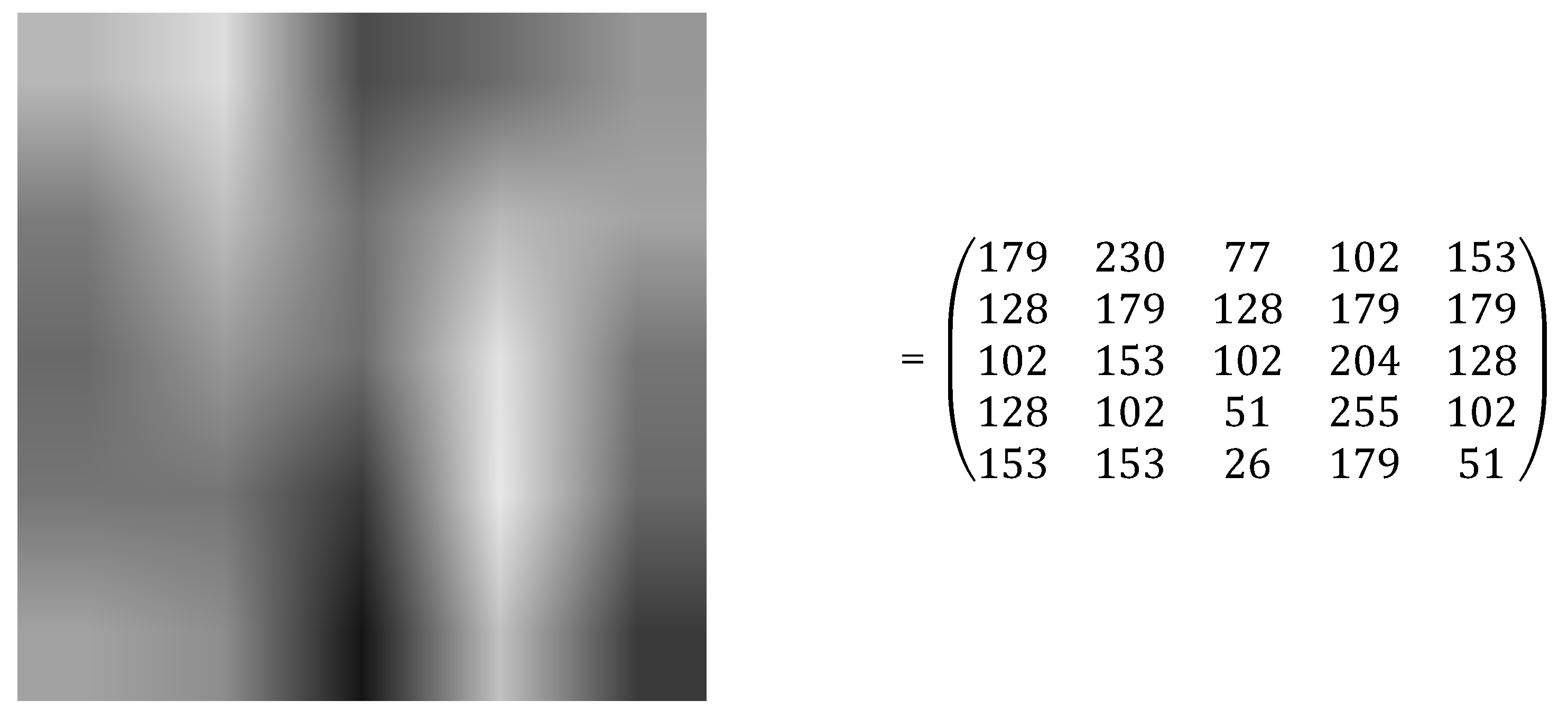{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
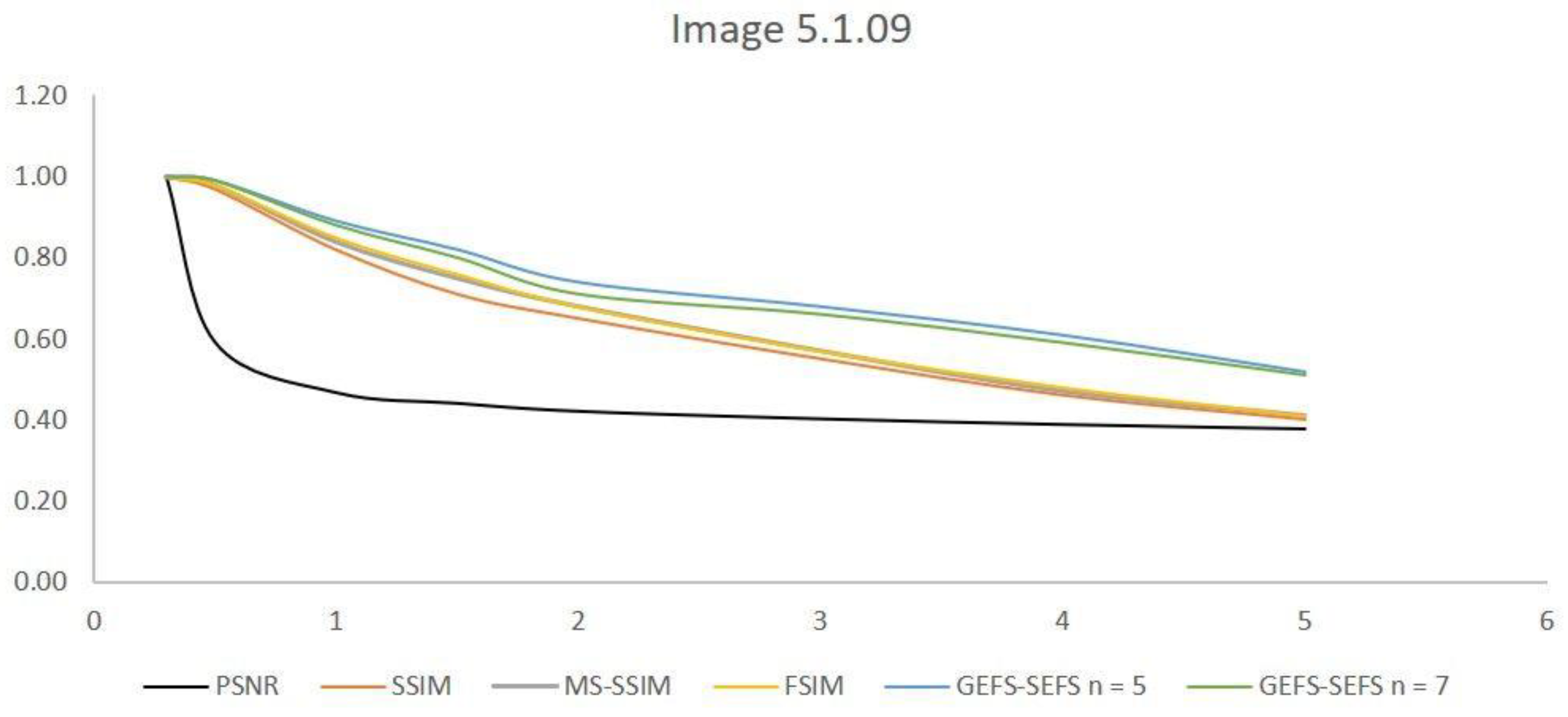
| σ | PSNR | PSNR Normalized | SSIM | MS-SSIM | FSIM | GEFS-SEFS n = 5 | GEFS–SEFS n = 7 |
|---|---|---|---|---|---|---|---|
| 0.3 | 68.85 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| 0.5 | 40.81 | 0.59 | 0.97 | 0.98 | 0.98 | 0.99 | 0.99 |
| 1.0 | 32.26 | 0.47 | 0.82 | 0.84 | 0.85 | 0.89 | 0.88 |
| 1.5 | 30.45 | 0.44 | 0.71 | 0.75 | 0.76 | 0.82 | 0.80 |
| 2.0 | 29.10 | 0.42 | 0.65 | 0.68 | 0.68 | 0.74 | 0.71 |
| 3.0 | 27.81 | 0.40 | 0.55 | 0.57 | 0.57 | 0.68 | 0.66 |
| 4.0 | 26.85 | 0.39 | 0.46 | 0.47 | 0.48 | 0.61 | 0.60 |
| 5.0 | 26.11 | 0.38 | 0.40 | 0.41 | 0.41 | 0.52 | 0.51 |
| σ | PSNR | PSNR Normalized | SSIM | MS-SSIM | FSIM | GEFS-SEFS n = 5 | GEFS–SEFS n = 7 |
|---|---|---|---|---|---|---|---|
| 0.3 | 68.41 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| 0.5 | 40.01 | 0.58 | 0.98 | 0.98 | 0.98 | 0.99 | 0.99 |
| 1.0 | 31.89 | 0.47 | 0.82 | 0.83 | 0.83 | 0.88 | 0.88 |
| 1.5 | 29.35 | 0.43 | 0.70 | 0.72 | 0.73 | 0.79 | 0.78 |
| 2.0 | 28.26 | 0.41 | 0.58 | 0.58 | 0.60 | 0.69 | 0.68 |
| 3.0 | 26.67 | 0.39 | 0.43 | 0.45 | 0.46 | 0.57 | 0.56 |
| 4.0 | 25.71 | 0.38 | 0.33 | 0.36 | 0.37 | 0.49 | 0.48 |
| 5.0 | 25.10 | 0.37 | 0.26 | 0.28 | 0.29 | 0.41 | 0.41 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Di Martino, F.; Sessa, S. A Novel Image Similarity Measure Based on Greatest and Smallest Eigen Fuzzy Sets. Symmetry 2023, 15, 1104. https://doi.org/10.3390/sym15051104
Di Martino F, Sessa S. A Novel Image Similarity Measure Based on Greatest and Smallest Eigen Fuzzy Sets. Symmetry. 2023; 15(5):1104. https://doi.org/10.3390/sym15051104
Chicago/Turabian StyleDi Martino, Ferdinando, and Salvatore Sessa. 2023. "A Novel Image Similarity Measure Based on Greatest and Smallest Eigen Fuzzy Sets" Symmetry 15, no. 5: 1104. https://doi.org/10.3390/sym15051104
APA StyleDi Martino, F., & Sessa, S. (2023). A Novel Image Similarity Measure Based on Greatest and Smallest Eigen Fuzzy Sets. Symmetry, 15(5), 1104. https://doi.org/10.3390/sym15051104