

Controlling of Unmanned Underwater Vehicles Using the Dynamic Planning of Symmetric Trajectory Based on Machine Learning for Marine Resources Exploration


Abstract
:1. Introduction
- Introduction of deep learning methods: This study applied deep learning methods to the field of dynamic path planning for underwater unmanned vehicles (UUVs). Traditional dynamic programming approaches face challenges in complex environments, while deep learning methods have the ability to handle complex data and learn environmental patterns. By introducing the LSTM-RNN network structure, this research combined deep learning with path planning, enabling UUVs to learn and apply dynamic planning patterns for autonomous obstacle avoidance in unknown environments.
- Design without models or perception devices: Unlike traditional methods, this research did not rely on complex environment models or cumbersome perception devices to support the decision-making process. By training the deep learning network, UUVs can directly learn environmental patterns from actual observation data and autonomously plan obstacle avoidance in real-time environments. This model-free, perception-device-free design is significant for improving the practicality and reliability of the system and is innovative in its application in underwater environments.
- Applicability to unknown environments: Another scientific novelty of this research lies in its applicability to unknown environments. Traditional approaches often require prior knowledge of environmental characteristics and parameters, while in practical applications, environmental changes and uncertainties are common. By training the deep learning network to learn planning patterns in unknown environments, UUVs can autonomously plan obstacle avoidance in real-time environments, whether the environment has been previously explored or modeled. This capability is important for expanding the application domains of UUVs and enhancing their adaptability.
- Application of LSTM-RNN networks in dynamic path planning for UUVs: We verified the effectiveness of the LSTM-RNN network structure in the task of dynamic path planning for UUVs. By training the network, we enabled UUVs to learn and infer patterns in the environment, and make path planning and obstacle avoidance decisions based on the learned patterns.
- Model-free, perception-device-free autonomous obstacle avoidance method: We developed a deep-learning-based method that achieved autonomous obstacle avoidance for UUVs in unknown environments without the need for prior environment modeling or reliance on perception devices. This approach simplified the complexity of the system and improved its practicality.
- Performance validation in practical scenarios: Through experimental results, we validated the performance of the method in real-world applications of UUVs. The experimental results demonstrated that using LSTM-RNN networks can effectively learn planning patterns in unknown environments and achieve autonomous obstacle avoidance in practical applications, providing strong support for the actual application of UUVs in complex environments.
2. Materials and Methods
- Using ant colony algorithm for static planning:
- System dynamic programming strategy design:
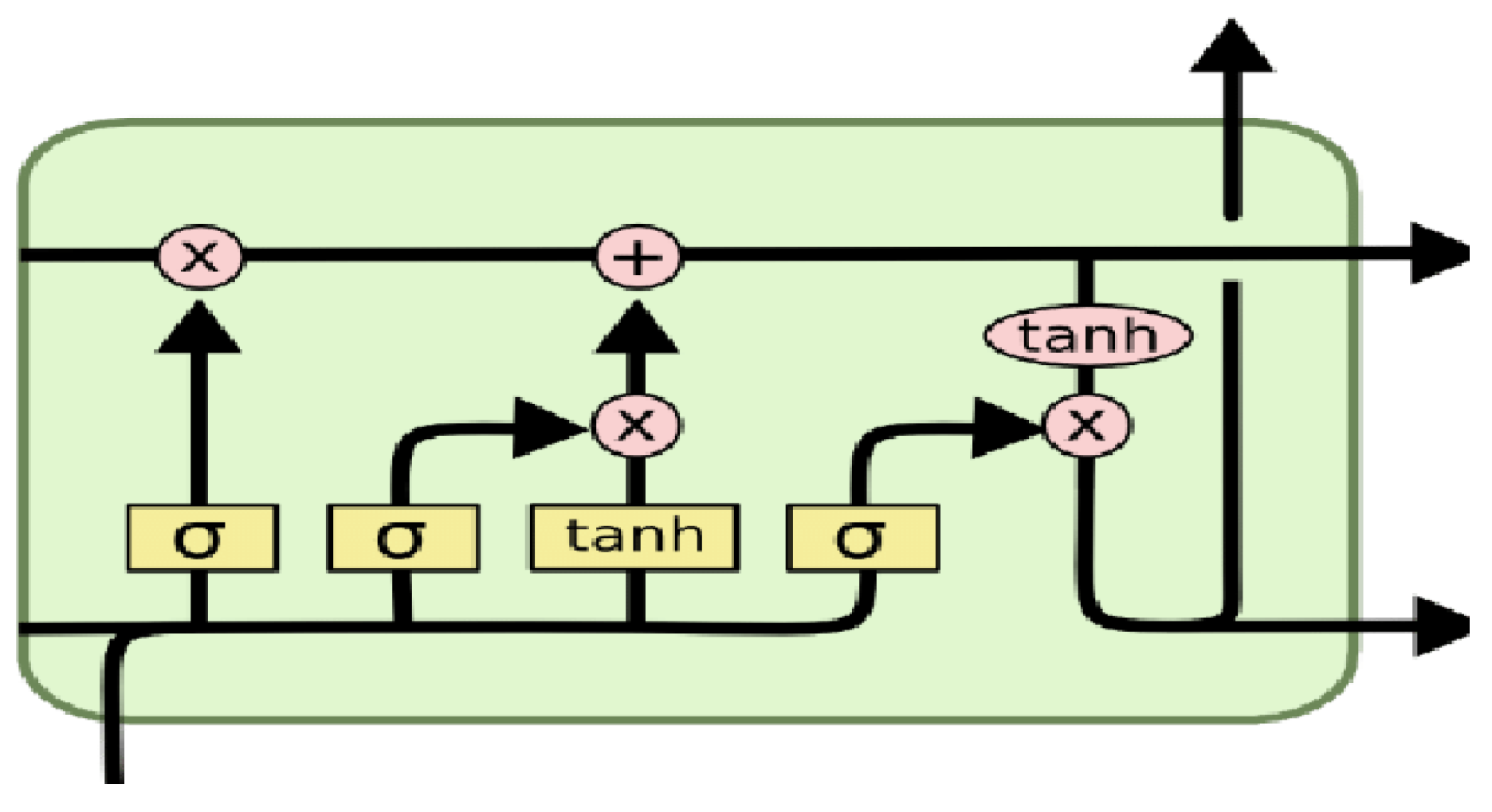
- Design of UUV Dynamic Programming based on LSTM-RNN:
3. Results
3.1. UUV Dynamic Planning LSTM-RNN Training
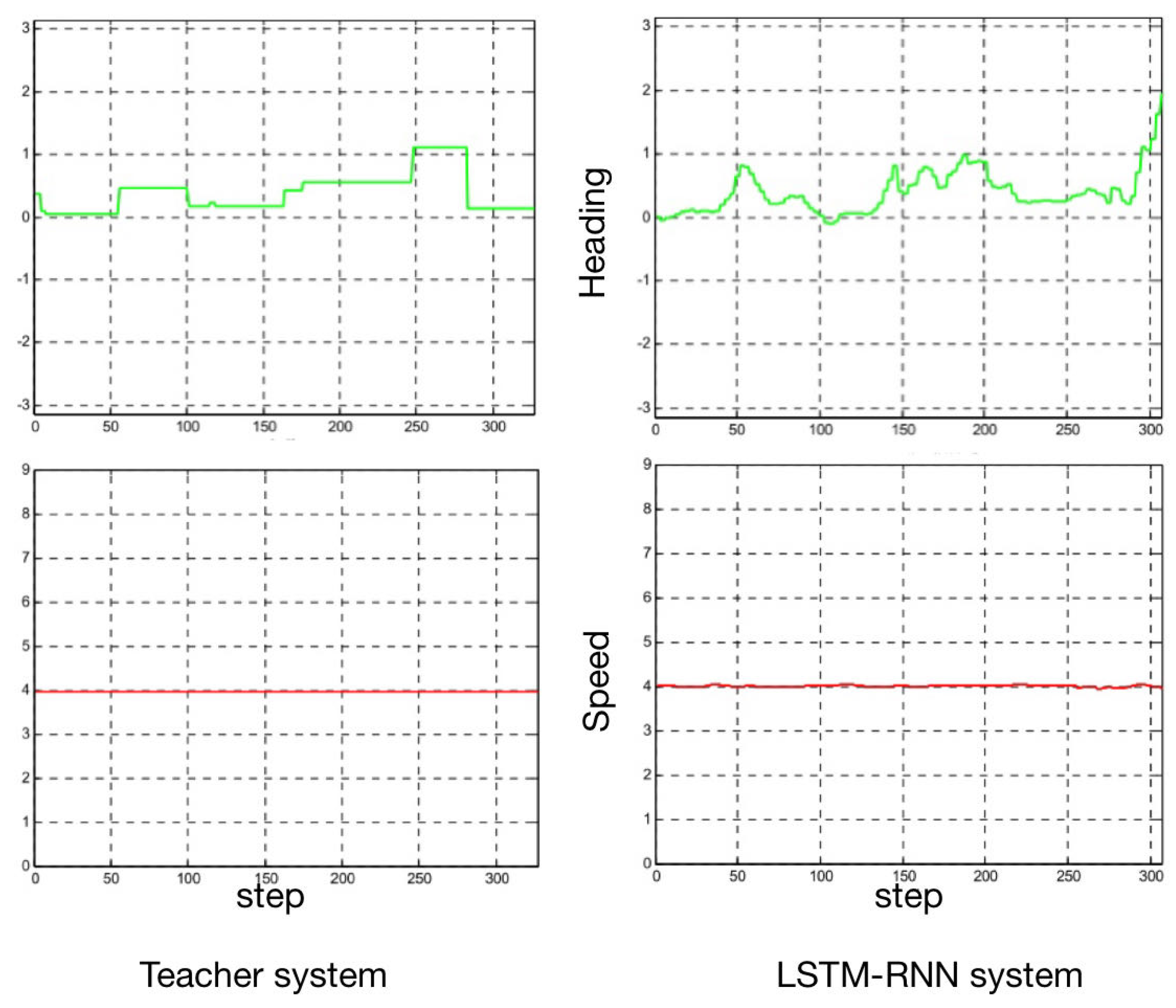
3.2. Simulation Verification of System Dynamic Planning
- Data collection and labeling: Obtaining sufficient training data and labeling can be a challenge. Large-scale, high-quality data sets are essential for training LSTM-RNN models. In addition, labeling data may require professional domain knowledge and time costs.
- Network design and tuning: Designing and optimizing the LSTM-RNN network structure for optimal performance may require a lot of experimentation and tuning. Choosing the appropriate network architecture, number of layers, number of neurons, and activation function is a complex task.
- Computational resource and time cost: The LSTM-RNN method usually requires large computational resources and time to train the model. The complexity of the model and the size of the training data set may lead to increased demand for computing resources, and the training time may be longer.
- Real-time requirements: In practical applications, the LSTM-RNN method may need to meet the real-time requirements, that is, to generate obstacle avoidance strategies within a limited period of time. Real-time requirements may require further optimization and acceleration of the algorithm.
- Environmental complexity: The complexity and dynamic changes of the actual marine environment may have an impact on the performance of the LSTM-RNN method. Dealing with complex terrain, ocean currents, multiple moving obstacles, etc., may require higher model robustness and generalization capabilities.
4. Discussion and Future Work
- System improvement. The system designed in this paper performed well in terms of real-time and planning effectiveness, but the planned path was not smoothed, and when it is in a complex multi-motion obstacle environment, strategy conflicts may occur, leading to slow or oscillatory UUV movement [36,37,38,39].
- Data cleaning. During the sampling process, there may be a small number of erroneous samples due to system defects, and the entire dataset is concatenated from sampling data in many different random environments, resulting in a large number of sequence discontinuities. Therefore, in the case of sufficient resources, it is advisable to create independent sequence-label sample pairs instead of randomly selecting sequences from the training dataset. This approach can eliminate erroneous samples and avoid the issue of sequence discontinuity.
- Training on a larger dataset. Due to equipment limitations, the dataset used in this paper was relatively small, and a larger dataset will undoubtedly lead to better performance.
- Using deep reinforcement learning. This approach can enable the system to automatically try and learn from errors without the need for sampling, achieving true intelligence implementation
- Enhanced autonomy and safety: By utilizing the LSTM-RNN network to learn dynamic planning patterns, UUVs can autonomously navigate through complex and unknown underwater environments. This capability reduces the reliance on human operators for real-time decision-making, increasing the autonomy of UUVs and improving their overall safety during underwater missions.
- Efficient resource exploration: UUVs are widely used in marine resource exploration, and accurate path planning is crucial for maximizing the efficiency of these missions. The proposed approach enabled UUVs to dynamically plan their paths in unknown environments without the need for extensive environment modeling or cumbersome perception devices. This not only saves time and resources but also enhances the efficiency and effectiveness of resource exploration activities.
- Applications in marine science and research: UUVs play a significant role in marine scientific research, enabling data collection and analysis in remote and inaccessible marine environments. The research findings contribute to the development of intelligent UUV systems that can adapt to unknown environments and autonomously avoid obstacles. This opens up new possibilities for conducting in-depth studies in marine biology, geology, oceanography, and other scientific fields.
- Enhanced operational capabilities: The ability of UUVs to autonomously plan paths and avoid obstacles in challenging environments expands their operational capabilities. They can perform tasks such as underwater inspection, maintenance, and surveillance with greater efficiency and accuracy. This has practical implications for applications such as underwater infrastructure inspection, offshore oil and gas operations, and marine security.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| MDPI | Multidisciplinary Digital Publishing Institute |
| UUV | Unmanned Underwater Vehicles |
| LSTM | Long Short-Term Memory |
| RNN | Recurrent Neural Network |
| ACO | Ant Colony Optimization |
| DL | Deep Learning |
| NN | Neural Network |
References
- Wang, J.; Yang, Y.; Mao, J.; Huang, Z.; Huang, C.; Xu, W. CNN-RNN: A Unified Framework for Multi-label Image Classification. arXiv 2016, arXiv:1604.04573. [Google Scholar]
- Yu, H.; Wang, J.; Huang, Z.; Yang, Y.; Xu, W. Video paragraph captioning using hierarchical recurrent neural networks. arXiv 2015, arXiv:1510.07712. [Google Scholar]
- Wang, J.X.; Kurth-Nelson, Z.; Tirumala, D.; Soyer, H.; Leibo, J.Z.; Munos, R.; Blundell, C.; Kumaran, D.; Botvinick, M. Learning to reinforcement learn. arXiv 2016, arXiv:1611.05763. [Google Scholar]
- Gupta, O.; Raskar, R. Distributed learning of deep neural network over multiple agents. J. Netw. Comput. Appl. 2018, 116, 1–8. [Google Scholar] [CrossRef]
- Osband, I.; Blundell, C.; Pritzel, A.; Van Roy, B. Deep Exploration via Bootstrapped DQN. arXiv 2016, arXiv:1602.04621. [Google Scholar]
- Foerster, J.; Assael, I.A.; De Freitas, N.; Whiteson, S. Learning to Communicate with Deep Multi-Agent Reinforcement Learning. arXiv 2016, arXiv:1605.06676. [Google Scholar]
- Dai, Z.; Li, L.; Xu, W. CFO: Conditional Focused Neural Question Answering with Large-scale Knowledge Bases. arXiv 2016, arXiv:1606.01994. [Google Scholar]
- Carta, S.; Ferreira, A.; Podda, A.S.; Recupero, D.R.; Sanna, A. Multi-DQN: An ensemble of deep Q-Learning agents for stock market forecasting. Expert Syst. Appl. 2021, 164, 113820. [Google Scholar] [CrossRef]
- Li, Y.; Fan, C.; Li, Y.; Wu, Q.; Ming, Y. Improving Deep Neural Network with Multiple Parametric Exponential Linear Units. arXiv 2016, arXiv:1606.00305. [Google Scholar] [CrossRef]
- Lutonin, A.; Shklyarskiy, J. Topology and control algorithms for a permanent magnet synchronous motor as a part of a vehicle with in-wheel motors. In Proceedings of the E3S Web of Conferences, Khabarovsk, Russia, 7–9 September 2021; EDP Sciences: Ulysses, France, 2021; Volume 266, p. 04001. [Google Scholar]
- Brigadnov, I.; Lutonin, A.; Bogdanova, K. Error State Extended Kalman Filter Localization for Underground Mining Environments. Symmetry 2023, 15, 344. [Google Scholar] [CrossRef]
- Yapar, C.; Levie, R.; Kutyniok, G.; Caire, G. Real-time outdoor localization using radio maps: A deep learning approach. arXiv 2021, arXiv:2106.12556. [Google Scholar] [CrossRef]
- Xu, W.; Cai, Y.; He, D.; Lin, J.; Zhang, F. Fast-lio2: Fast direct lidar-inertial odometry. IEEE Trans. Robot. 2022, 38, 2053–2073. [Google Scholar] [CrossRef]
- Kakani, V.; Nguyen, V.H.; Kumar, B.P.; Kim, H.; Pasupuleti, V.R. A critical review on computer vision and artificial intelligence in food industry. J. Agric. Food Res. 2020, 2, 100033. [Google Scholar] [CrossRef]
- Sankowski, D.; Nowakowski, J. Computer Vision in Robotics and Industrial Applications; World Scientific: Singapore, 2014; Volume 3. [Google Scholar]
- Tian, H.; Wang, T.; Liu, Y.; Qiao, X.; Li, Y. Computer vision technology in agricultural automation—A review. Inf. Process. Agric. 2020, 7, 1–19. [Google Scholar] [CrossRef]
- Bertolini, M.; Mezzogori, D.; Neroni, M.; Zammori, F. Machine Learning for industrial applications: A comprehensive literature review. Expert Syst. Appl. 2021, 175, 114820. [Google Scholar] [CrossRef]
- Kashyap, P.; Kashyap, P. Industrial applications of machine learning. In Machine Learning for Decision Makers: Cognitive Computing Fundamentals for Better Decision Making; Apress: Bangalore, India, 2017; pp. 189–233. [Google Scholar]
- Abiodun, O.I.; Jantan, A.; Omolara, A.E.; Dada, K.V.; Mohamed, N.A.; Arshad, H. State-of-the-art in artificial neural network applications: A survey. Heliyon 2018, 4, e00938. [Google Scholar] [CrossRef] [PubMed]
- Zhou, H.; Zhao, H.; Zhang, Y. Nonlinear system modeling using self-organizing fuzzy neural networks for industrial applications. Appl. Intell. 2020, 50, 1657–1672. [Google Scholar] [CrossRef]
- Chen, F.; Wang, M.Y. Design optimization of soft robots: A review of the state of the art. IEEE Robot. Autom. Mag. 2020, 27, 27–43. [Google Scholar] [CrossRef]
- Takishima, Y.; Yoshida, K.; Khosla, A.; Kawakami, M.; Furukawa, H. Fully 3D-printed hydrogel actuator for jellyfish soft robots. ECS J. Solid State Sci. Technol. 2021, 10, 037002. [Google Scholar] [CrossRef]
- Runciman, M.; Darzi, A.; Mylonas, G.P. Soft robotics in minimally invasive surgery. Soft Robot. 2019, 6, 423–443. [Google Scholar] [CrossRef]
- Zakharov, L.A.; Martyushev, D.A.; Ponomareva, I.N. Predicting dynamic formation pressure using artificial intelligence methods. J. Min. Inst. 2022, 253, 23–32. [Google Scholar] [CrossRef]
- Zhukovskiy, Y.L.; Kovalchuk, M.S.; Batueva, D.E.; Senchilo, N.D. Development of an Algorithm for Regulating the Load Schedule of Educational Institutions Based on the Forecast of Electric Consumption within the Framework of Application of the Demand Response. Sustainability 2021, 13, 13801. [Google Scholar] [CrossRef]
- Yakovleva, T.A.; Romashev, A.O.; Mashevsky, G.N. Digital technologies for optimizing the dosing of flotation reagents during flotation of non-ferrous metal ores. Min. Inf. Anal. Bull. 2022, 6, 175–188. [Google Scholar] [CrossRef]
- Zemenkova, M.Y.; Chizhevskaya, E.L.; Zemenkov, Y.D. Intelligent monitoring of the condition of hydrocarbon pipeline transport facilities using neural network technologies. J. Min. Inst. 2022, 258, 933–944. [Google Scholar] [CrossRef]
- Alanazi, A.K.; Alizadeh, S.M.; Nurgalieva, K.S.; Nesic, S.; Grimaldo Guerrero, J.W.; Abo-Dief, H.M.; Eftekhari-Zadeh, E.; Nazemi, E.; Narozhnyy, I.M. Application of Neural Network and Time-Domain Feature Extraction Techniques for Determining Volumetric Percentages and the Type of Two Phase Flow Regimes Independent of Scale Layer Thickness. Appl. Sci. 2022, 12, 1336. [Google Scholar] [CrossRef]
- Ushakov, E.; Aleksandrova, T.; Romashev, A. Neural network modeling methods in the analysis of the processing plant’s indicators. In International Scientific Conference Energy Management of Municipal Facilities and Sustainable Energy Technologies EMMFT 2019; Springer: Berlin/Heidelberg, Germany, 2021; Volume 2, pp. 36–45. [Google Scholar]
- Filippov, E.V.; Zaharov, L.A.; Martyushev, D.A.; Ponomareva, I.N. Reproduction of reservoir pressure by machine learning methods and study of its influence on the cracks formation process in hydraulic fracturing. J. Min. Inst. 2022, 258, 924–932. [Google Scholar] [CrossRef]
- Islamov, S.; Grigoriev, A.; Beloglazov, I.; Savchenkov, S.; Gudmestad, O.T. Research Risk Factors in Monitoring Well Drilling—A. Case Study Using Machine Learning Methods. Symmetry 2021, 13, 1293. [Google Scholar] [CrossRef]
- Montiel, J.; Halford, M.; Mastelini, S.M.; Bolmier, G.; Sourty, R.; Vaysse, R.; Zouitine, A.; Gomes, H.M.; Read, J.; Abdessalem, T.; et al. River: Machine learning for streaming data in python. J. Mach. Learn. Res. 2021, 22, 4945–4952. [Google Scholar]
- Vasilev, I.; Slater, D.; Spacagna, G.; Roelants, P.; Zocca, V. Python Deep Learning: Exploring Deep Learning Techniques and Neural Network Architectures with Pytorch, Keras, and TensorFlow; Packt Publishing Ltd.: Birmingham, UK, 2019. [Google Scholar]
- Sun, W.; Akashi, N.; Kuniyoshi, Y.; Nakajima, K. Physics-informed recurrent neural networks for soft pneumatic actuators. IEEE Robot. Autom. Lett. 2022, 7, 6862–6869. [Google Scholar] [CrossRef]
- Sultanbekov, R.; Beloglazov, I.; Islamov, S.; Ong, M.C. Exploring of the Incompatibility of Marine Residual Fuel: A Case Study Using Machine Learning Methods. Energies 2021, 14, 8422. [Google Scholar] [CrossRef]
- Romashev, A.O.; Nikolaeva, N.V.; Gatiatullin, B.L. Adaptive approach formation using machine vision technology to determine the parameters of enrichment products deposition. J. Min. Inst. 2022, 256, 677–685. [Google Scholar] [CrossRef]
- Chen, A.; Yin, R.; Cao, L.; Yuan, C.; Ding, H.; Zhang, W. Soft robotics: Definition and research issues. In Proceedings of the 24th International Conference on Mechatronics and Machine Vision in Practice (M2VIP), Auckland, New Zealand, 21–23 November 2017; pp. 366–370. [Google Scholar]
- Makhovikov, A.B.; Kryltsov, S.B.; Matrokhina, K.V.; Trofimets, V.Y. Secured communication system for a metallurgical company. Tsvetnye Met. 2023, 4, 5–13. [Google Scholar] [CrossRef]
- Matrokhina, K.V.; Trofimets, V.Y.; Mazakov, E.B.; Makhovikov, A.B.; Khaykin, M.M. Development of methodology for scenario analysis of investment projects of enterprises of the mineral resource complex. J. Min. Inst. 2023, 259, 112–124. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Times | 1,000,000 | 2,000,000 | 3,000,000 | 4,000,000 |
|---|---|---|---|---|
| Heading error | 0.28 rad | 0.24 rad | 0.21 rad | 0.19 rad |
| Speed error | 1.2 kn | 1.0 kn | 0.85 kn | 0.81 kn |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kozhubaev, Y.; Belyaev, V.; Murashov, Y.; Prokofev, O. Controlling of Unmanned Underwater Vehicles Using the Dynamic Planning of Symmetric Trajectory Based on Machine Learning for Marine Resources Exploration. Symmetry 2023, 15, 1783. https://doi.org/10.3390/sym15091783
Kozhubaev Y, Belyaev V, Murashov Y, Prokofev O. Controlling of Unmanned Underwater Vehicles Using the Dynamic Planning of Symmetric Trajectory Based on Machine Learning for Marine Resources Exploration. Symmetry. 2023; 15(9):1783. https://doi.org/10.3390/sym15091783
Chicago/Turabian StyleKozhubaev, Yuriy, Victor Belyaev, Yuriy Murashov, and Oleg Prokofev. 2023. "Controlling of Unmanned Underwater Vehicles Using the Dynamic Planning of Symmetric Trajectory Based on Machine Learning for Marine Resources Exploration" Symmetry 15, no. 9: 1783. https://doi.org/10.3390/sym15091783
APA StyleKozhubaev, Y., Belyaev, V., Murashov, Y., & Prokofev, O. (2023). Controlling of Unmanned Underwater Vehicles Using the Dynamic Planning of Symmetric Trajectory Based on Machine Learning for Marine Resources Exploration. Symmetry, 15(9), 1783. https://doi.org/10.3390/sym15091783