

Adaptive Multi-Channel Deep Graph Neural Networks


Abstract
:1. Introduction
- We propose a new deep GNN model that creates a unique receptive field for each node by combining adaptive receptive fields at different granularities. The unique receptive field ensures node embedding remains different for a deep model.
- With decoupling transformation and propagation, the original features are retained and the parameters and training time are reduced, which ensures the robustness of the model in deep layers.
- We conducted extensive experiments on four real datasets and compared them with state-of-the-art models. The experimental results demonstrate the effectiveness of the proposed model.
2. Related Works
3. Preliminary
3.1. Semi-Supervised Node Classification
3.2. Graph Neural Networks
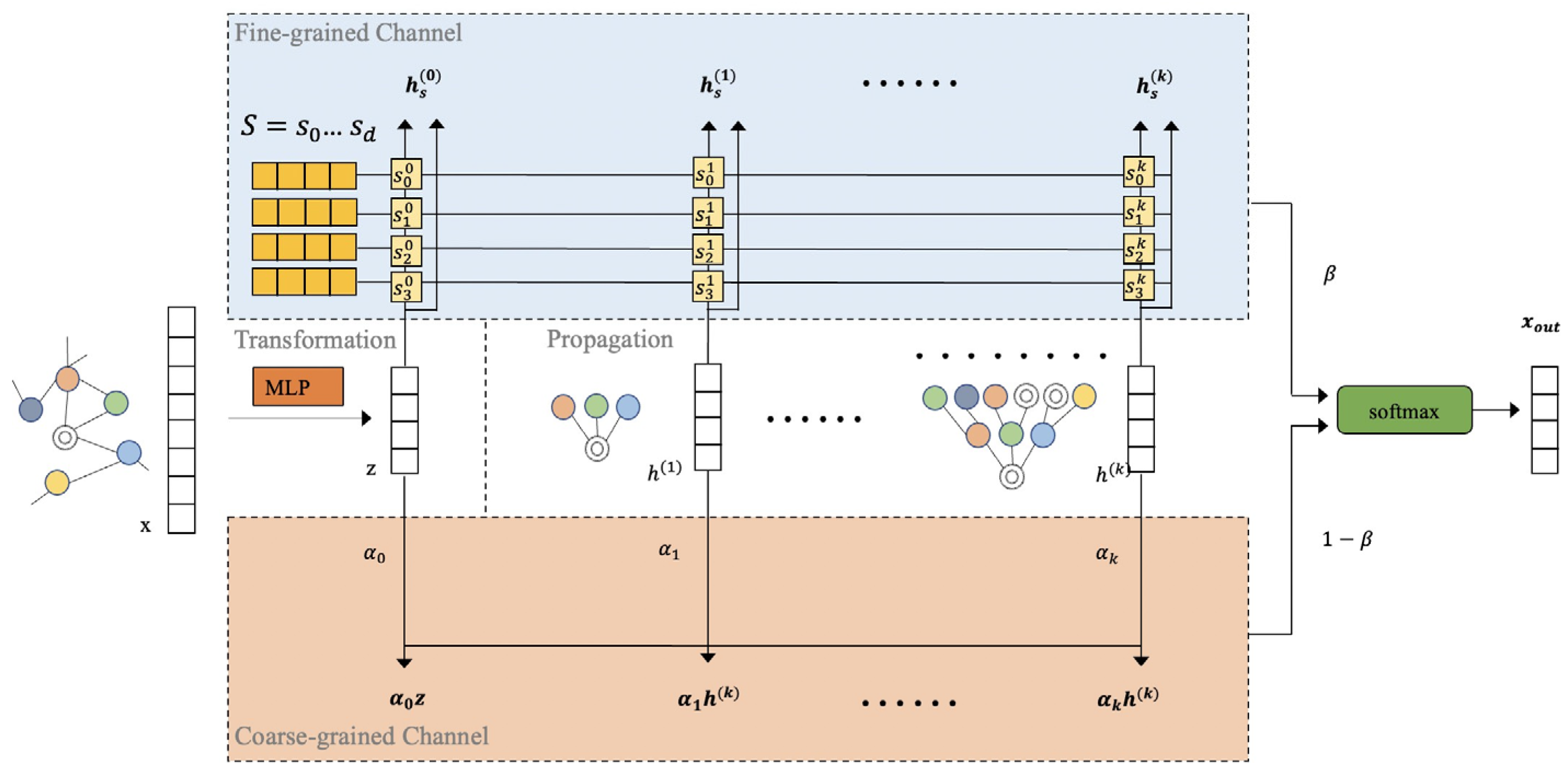
4. AMD-GNN Model
5. Experiments
5.1. Experimental Setup
5.2. Analysis of the Deep Architecture
5.3. Ablation Study
5.4. Model Depth Study
5.5. Convergence Speed Analysis
5.6. Analysis of the Heterophily Graphs
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jin, D.; Yu, Z.; Jiao, P.; Pan, S.; He, D.; Wu, J.; Philip, S.Y.; Zhang, W. A survey of community detection approaches: From statistical modeling to deep learning. IEEE Trans. Knowl. Data Eng. 2021, 35, 1149–1170. [Google Scholar] [CrossRef]
- He, D.; Wang, T.; Zhai, L.; Jin, D.; Yang, L.; Huang, Y.; Feng, Z.; Philip, S.Y. Adversarial representation mechanism learning for network embedding. IEEE Trans. Knowl. Data Eng. 2021, 35, 1200–1213. [Google Scholar] [CrossRef]
- Chen, M.; Wei, Z.; Huang, Z.; Ding, B.; Li, Y. Simple and deep graph convolutional networks. In Proceedings of the International Conference on Machine Learning, Virtual Event, 13–18 July 2020; pp. 1725–1735. [Google Scholar]
- Gao, H.; Wang, Z.; Ji, S. Large-scale learnable graph convolutional networks. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1416–1424. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Cui, G.; Zhou, J.; Yang, C.; Liu, Z. Adaptive graph encoder for attributed graph embedding. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, 23–27 August 2020; pp. 976–985. [Google Scholar]
- Kipf, T.N.; Welling, M. Variational graph auto-encoders. arXiv 2016, arXiv:1611.07308. [Google Scholar]
- Pan, S.; Hu, R.; Long, G.; Jiang, J.; Yao, L.; Zhang, C. Adversarially regularized graph autoencoder for graph embedding. arXiv 2018, arXiv:1802.04407. [Google Scholar]
- Wang, C.; Pan, S.; Long, G.; Zhu, X.; Jiang, J. Mgae: Marginalized graph autoencoder for graph clustering. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 889–898. [Google Scholar]
- Cai, L.; Ji, S. A multi-scale approach for graph link prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7 February 2020; pp. 3308–3315. [Google Scholar]
- Zhang, M.; Chen, Y. Weisfeiler-lehman neural machine for link prediction. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 575–583. [Google Scholar]
- Zhang, M.; Chen, Y. Link prediction based on graph neural networks. In Proceedings of the Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, Montréal, QC, Canada, 3–8 December 2018; pp. 5171–5181. [Google Scholar]
- Gao, H.; Ji, S. Graph u-nets. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 4948–4960. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.; Lee, I.; Kang, J. Self-attention graph pooling. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 3734–3743. [Google Scholar]
- Ma, Y.; Wang, S.; Aggarwal, C.C.; Tang, J. Graph convolutional networks with eigenpooling. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchoage, AK, USA, 4–8 August 2019; pp. 723–731. [Google Scholar]
- Ying, Z.; You, J.; Morris, C.; Ren, X.; Hamilton, W.; Leskovec, J. Hierarchical graph representation learning with differentiable pooling. In Proceedings of the Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, Montréal, QC, Canada, 3–8 December 2018; pp. 4805–4815. [Google Scholar]
- Frasconi, P.; Gori, M.; Sperduti, A. A general framework for adaptive processing of data structures. IEEE Trans. Neural Netw. 1998, 9, 768–786. [Google Scholar] [CrossRef] [PubMed]
- Zador, A.; Escola, S.; Richards, B.; Ölveczky, B.; Bengio, Y.; Boahen, K.; Botvinick, M.; Chklovskii, D.; Churchland, A.; Clopath, C.; et al. Catalyzing next-generation artificial intelligence through neuroai. Nat. Commun. 2023, 14, 1597. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Li, Q.; Han, Z.; Wu, X.M. Deeper insights into graph convolutional networks for semi-supervised learning. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 3538–3545. [Google Scholar]
- Oono, K.; Suzuki, T. Graph neural networks exponentially lose expressive power for node classification. arXiv 2019, arXiv:1905.10947. [Google Scholar]
- Cong, W.; Ramezani, M.; Mahdavi, M. On provable benefits of depth in training graph convolutional networks. Adv. Neural Inf. Process. Syst. 2021, 34, 9936–9949. [Google Scholar]
- Klicpera, J.; Bojchevski, A.; Günnemann, S. Predict then propagate: Graph neural networks meet personalized pagerank. In Proceedings of the 7th International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Rong, Y.; Huang, W.; Xu, T.; Huang, J. Dropedge: Towards deep graph convolutional networks on node classification. arXiv 2019, arXiv:1907.10903. [Google Scholar]
- Xu, K.; Li, C.; Tian, Y.; Sonobe, T.; Kawarabayashi, K.i.; Jegelka, S. Representation learning on graphs with jumping knowledge networks. In Proceedings of the International Conference on Machine Learning, Stockholmsmässan, Stockholm, Sweden, 10–15 July 2018; pp. 5453–5462. [Google Scholar]
- Zhao, L.; Akoglu, L. Pairnorm: Tackling oversmoothing in gnns. arXiv 2019, arXiv:1909.12223. [Google Scholar]
- Zhou, K.; Huang, X.; Zha, D.; Chen, R.; Li, L.; Choi, S.H.; Hu, X. Dirichlet energy constrained learning for deep graph neural networks. Adv. Neural Inf. Process. Syst. 2021, 34, 21834–21846. [Google Scholar]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 1024–1034. [Google Scholar]
- Xu, K.; Hu, W.; Leskovec, J.; Jegelka, S. How powerful are graph neural networks? arXiv 2018, arXiv:1810.00826. [Google Scholar]
- Wu, F.; Souza, A.; Zhang, T.; Fifty, C.; Yu, T.; Weinberger, K. Simplifying graph convolutional networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6861–6871. [Google Scholar]
- Wang, X.; Zhu, M.; Bo, D.; Cui, P.; Shi, C.; Pei, J. Am-gcn: Adaptive multi-channel graph convolutional networks. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Virtual Event, 23–27 August 2020; pp. 1243–1253. [Google Scholar]
- Liu, M.; Gao, H.; Ji, S. Towards deeper graph neural networks. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, 23–27 August 2020; pp. 338–348. [Google Scholar]
- Sen, P.; Namata, G.; Bilgic, M.; Getoor, L.; Galligher, B.; Eliassi-Rad, T. Collective classification in network data. AI Mag. 2008, 29, 93. [Google Scholar] [CrossRef]
- Pei, H.; Wei, B.; Chang, K.C.C.; Lei, Y.; Yang, B. Geom-gcn: Geometric graph convolutional networks. arXiv 2020, arXiv:2002.05287. [Google Scholar]
- Jin, D.; Wang, R.; Ge, M.; He, D.; Li, X.; Lin, W.; Zhang, W. Raw-gnn: Random walk aggregation based graph neural network. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, Vienna, Austria, 23–29 July 2022; pp. 2108–2114. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Liu, Z.; Chen, C.; Li, L.; Zhou, J.; Li, X.; Song, L.; Qi, Y. Geniepath: Graph neural networks with adaptive receptive paths. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 4424–4431. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Classes | Nodes | Edges | Features |
|---|---|---|---|---|
| Cora | 7 | 2708 | 5429 | 1433 |
| Citeseer | 6 | 3327 | 4732 | 3703 |
| Pubmed | 3 | 19,717 | 44,338 | 500 |
| Cornell | 5 | 183 | 295 | 1703 |
| Dataset | Hyperparameters |
|---|---|
| Cora | hidden units: 64, lr: 0.01, dropout: 0.5, |
| Citeseer | hidden units: 64, lr: 0.01, dropout: 0.5, |
| Pubmed | hidden units: 64, lr: 0.01, dropout: 0.5, |
| Cornell | hidden units: 64, lr: 0.01, dropout: 0.5, |
| Dataset | Method | Layers | |||||
|---|---|---|---|---|---|---|---|
| 2 | 4 | 8 | 16 | 32 | 64 | ||
| Cora | GCN | 86.29 | 84.53 | 55.47 | 29.56 | 29.46 | 29.54 |
| GAT | 82.9 | 82.9 | 21.15 | 16.38 | OOM | OOM | |
| Jknet | – | 82.73 | 83.84 | 83.18 | 84.5 | 73 | |
| APPNP | 14.37 | 57.1 | 84.72 | 86.11 | 85.65 | 85.63 | |
| GCN + DropEdge | 81.49 | 83.1 | 29.54 | 29.54 | 29.54 | 29.54 | |
| Incep + DropEdge | – | 85.92 | 85.61 | 84.37 | 84.29 | 84.41 | |
| DAGNN | 86.12 | 86.94 | 87.05 | 86.62 | 85.86 | 85.15 | |
| AMD-GNN | 87.73 | 88.79 | 88.83 | 88.29 | 88.01 | 86.88 | |
| Citeseer | GCN | 74.67 | 71.27 | 54.53 | 20.17 | 20.64 | 20.5 |
| GAT | 74.53 | 47.71 | 19.93 | OOM | OOM | OOM | |
| Jknet | – | 70.93 | 70.55 | 69.48 | 69.74 | 64.61 | |
| APPNP | 5.99 | 52.62 | 72.54 | 72.82 | 73.01 | 73.45 | |
| GCN + DropEdge | 71.32 | 69.27 | 33.3 | 21.72 | 19.67 | 18.77 | |
| Incep + DropEdge | – | 74.1 | 74.15 | 73.66 | 72.15 | 53.67 | |
| DAGNN | 74.73 | 75.63 | 75.45 | 74.39 | 73.02 | 72.43 | |
| AMD-GNN | 76.7 | 76.96 | 76.86 | 76.11 | 75.09 | 74.65 | |
| Pubmed | GCN | 86.05 | 85.11 | 39.94 | 40.16 | 40.04 | 39.48 |
| GAT | 79.46 | 80.65 | OOM | OOM | OOM | OOM | |
| Jknet | – | 80.44 | 80.2 | 76.08 | 76.23 | 77.37 | |
| APPNP | 21.04 | 74.25 | 84.18 | 84.36 | 84.82 | 82.94 | |
| GCN + DropEdge | 68.84 | 60.95 | 56.64 | 67.99 | 49.48 | 41 | |
| Incep + DropEdge | – | 87.89 | 86.6 | 84.28 | OOM | OOM | |
| DAGNN | 87.47 | 87.88 | 87.16 | 86.12 | 84.91 | 83.75 | |
| AMD-GNN | 87.34 | 87.7 | 87.22 | 86.07 | 85.07 | 83.85 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, R.; Li, F.; Liu, S.; Li, W.; Chen, S.; Feng, B.; Jin, D. Adaptive Multi-Channel Deep Graph Neural Networks. Symmetry 2024, 16, 406. https://doi.org/10.3390/sym16040406
Wang R, Li F, Liu S, Li W, Chen S, Feng B, Jin D. Adaptive Multi-Channel Deep Graph Neural Networks. Symmetry. 2024; 16(4):406. https://doi.org/10.3390/sym16040406
Chicago/Turabian StyleWang, Renbiao, Fengtai Li, Shuwei Liu, Weihao Li, Shizhan Chen, Bin Feng, and Di Jin. 2024. "Adaptive Multi-Channel Deep Graph Neural Networks" Symmetry 16, no. 4: 406. https://doi.org/10.3390/sym16040406
APA StyleWang, R., Li, F., Liu, S., Li, W., Chen, S., Feng, B., & Jin, D. (2024). Adaptive Multi-Channel Deep Graph Neural Networks. Symmetry, 16(4), 406. https://doi.org/10.3390/sym16040406