
The Expansion Methods of Inception and Its Application


Abstract
:1. Introduction
1.1. The Models of the Inception Series
1.2. Lightweight CNNs
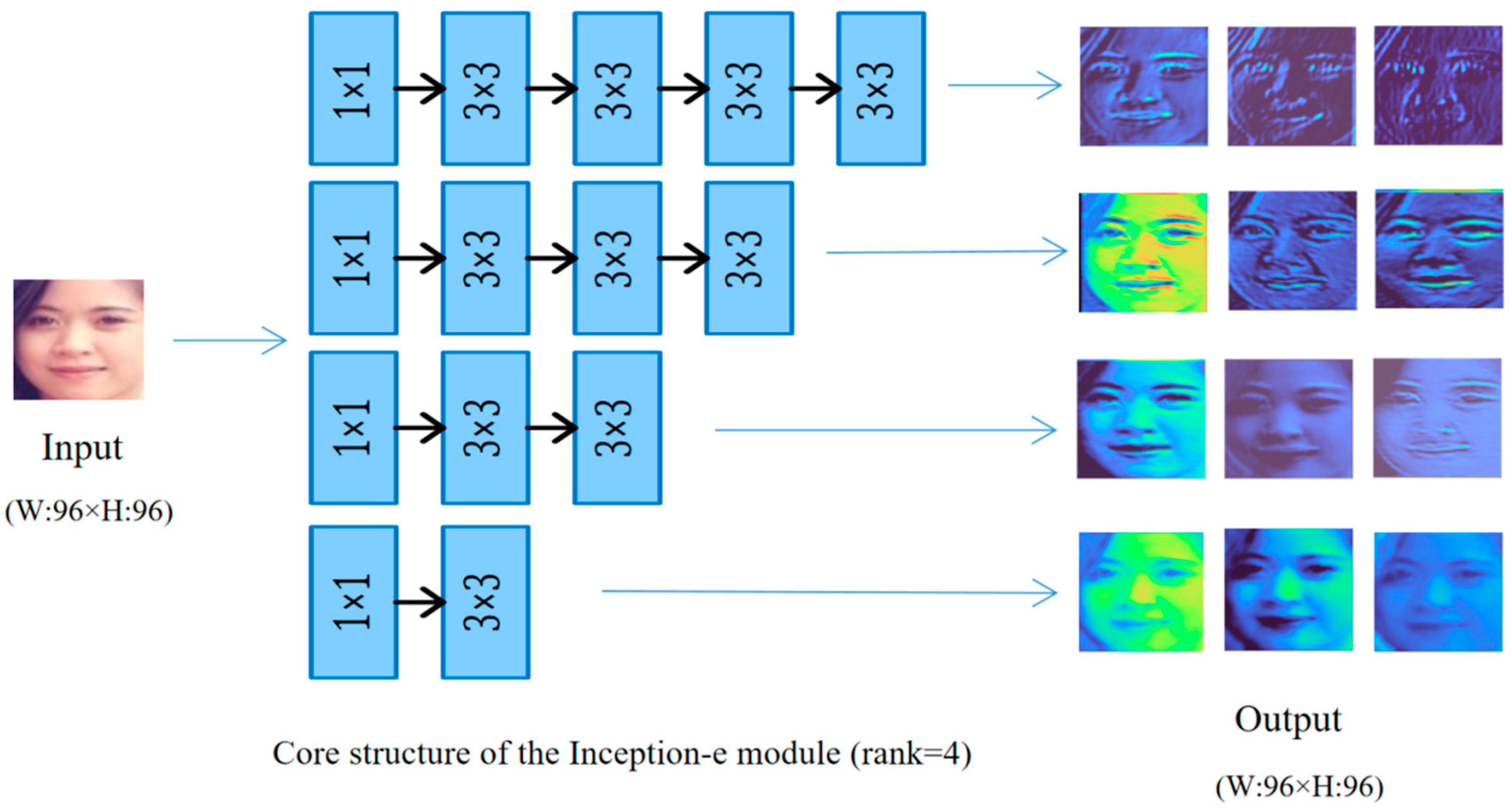
- A basic extension method, the Inception-e module, is proposed by us. Based on the Inception module A, firstly, the basic expansion method is raised, and the experimental results prove that increasing the depth and width of the Inception module A is beneficial to the improvement of the classification accuracy of the model, but the method is accompanied by a huge number of parameters.
- To solve the problem of increasing the number of parameters due to extension, an equivalent extension method, the Eception module, is proposed by us, which has comparable perceptual field and feature extraction abilities to Inception-e. The Eception module improves the classification accuracy of the model while saving on the number of parameters.
- A lightweight expansion method, Lception module, is proposed. On the basis of Eception module, inspired by the idea of a lightweight convolutional neural network, by cross-replacing the ordinary convolutional layers of the Eception module with depthwise convolutional layers, the weights of these layers are sparser, and thus reduce the number of parameters. The experimental results show that the Lception module can effectively improve the classification accuracy of the network with almost the same number of parameters.
2. Methods
2.1. Basic Expansion Method—Inception-e
2.2. Equivalent Expansion Method—Eception
2.3. Lightweight Expansion Method—Lception
3. Experiments and Analysis
3.1. Experimental Datasets
3.2. The Network Models and Experimental Conditions
- Optimizer: SGD [41]
- Training batch: 32
- Momentum: 0.9
- Regularization: L2 regularization of the weights of all convolutional layers.
3.3. Validation of the Three Expansion Methods
3.4. Grad-CAM Visual Analysis
3.5. Comparison with More Methods
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Meena, G.; Mohbey, K.K.; Indian, A.; Khan, M.Z.; Kumar, S. Identifying emotions from facial expressions using a deep convolutional neural network-based approach. Multimed. Tools Appl. 2024, 83, 15711–15732. [Google Scholar] [CrossRef]
- Febrian, R.; Halim, B.M.; Christina, M.; Ramdhan, D.; Chowanda, A. Facial expression recognition using bidirectional LSTM-CNN. Procedia Comput. Sci. 2023, 216, 39–47. [Google Scholar] [CrossRef]
- Sajjad, M.; Ullah, F.U.; Ullah, M.; Christodoulou, G.; Cheikh, F.A.; Hijji, M.; Muhammad, K.; Rodrigues, J.J. A comprehensive survey on deep facial expression recognition: Challenges, applications, and future guidelines. Alex. Eng. J. 2023, 68, 817–840. [Google Scholar] [CrossRef]
- Adyapady, R.R.; Annappa, B. A comprehensive review of facial expression recognition techniques. Multimed. Syst. 2023, 29, 73–103. [Google Scholar] [CrossRef]
- Fouladi, S.; Safaei, A.A.; Mammone, N.; Ghaderi, F.; Ebadi, M.J. Efficient deep neural networks for classification of Alzheimer’s disease and mild cognitive impairment from scalp EEG recordings. Cogn. Comput. 2022, 14, 1247–1268. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, New York, NY, USA, 4–9 February 2017; pp. 4278–4284. [Google Scholar]
- Zhang, X.; Huang, S.; Zhang, X.; Wang, W.; Wang, Q.; Yang, D. Residual Inception: A New Module Combining Modified Residual with Inception to Improve Network Performance. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 3039–3043. [Google Scholar] [CrossRef]
- Alom, M.Z.; Hasan, M.; Yakopcic, C.; Taha, T.M. Inception recurrent convolutional neural network for object recognition. arXiv 2017, arXiv:1704.07709. [Google Scholar] [CrossRef]
- Xie, L.; Huang, C. A Residual Network of Water Scene Recognition Based on Optimized Inception Module and Convolutional Block Attention Module. In Proceedings of the 2019 6th International Conference on Systems and Informatics (ICSAI), Shanghai, China, 2–4 November 2019; pp. 1174–1178. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV 2018), Munich, Germany, 8–14 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–19. [Google Scholar]
- Chen, F.; Wei, J.; Xue, B.; Zhang, M. Feature fusion and kernel selective in Inception-v4 network. Appl. Soft Comput. 2022, 119, 108582. [Google Scholar] [CrossRef]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 510–519. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More Features From Cheap Operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1577–1586. [Google Scholar] [CrossRef]
- Zhou, D.; Hou, Q.; Chen, Y.; Feng, J.; Yan, S. Rethinking bottleneck structure for efficient mobile network design. In Proceedings of the European Conference Computer Vision (ECCV 2020), Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 680–697. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted residuals and linear bottlenecks. arXiv 2019, arXiv:1801.04381. [Google Scholar] [CrossRef]
- Ma, N.; Zhang, X.; Huang, J.; Sun, J. Weightnet: Revisiting the design space of weight networks. In Proceedings of the European Conference on Computer Vision (ECCV 2020), Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 776–792. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the 36th International Conference on Machine Learning, PMLR, Los Angeles, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Munir, M.; Avery, W.; Marculescu, R. Mobilevig: Graph-based sparse attention for mobile vision applications. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 2211–2219. [Google Scholar]
- Vasu, P.K.; Gabriel, J.; Zhu, J.; Tuzel, O.; Ranjan, A. FastViT: A fast hybrid vision transformer using structural reparameterization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 5785–5795. [Google Scholar]
- Shaker, A.; Maaz, M.; Rasheed, H.; Khan, S.; Yang, M.H.; Khan, F.S. SwiftFormer: Efficient additive attention for transformer-based real-time mobile vision applications. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 17425–17436. [Google Scholar]
- Li, Y.; Yuan, G.; Wen, Y.; Hu, J.; Evangelidis, G.; Tulyakov, S.; Wang, Y.; Ren, J. Efficientformer: Vision transformers at mobilenet speed. Adv. Neural Inf. Process. Syst. 2022, 35, 12934–12949. [Google Scholar]
- Li, Y.; Hu, J.; Wen, Y.; Evangelidis, G.; Salahi, K.; Wang, Y.; Tulyakov, S.; Ren, J. Rethinking vision transformers for mobilenet size and speed. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 16889–16900. [Google Scholar]
- Yu, W.; Luo, M.; Zhou, P.; Si, C.; Zhou, Y.; Wang, X.; Feng, J.; Yan, S. Metaformer is actually what you need for vision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 10819–10829. [Google Scholar]
- Wang, A.; Chen, H.; Lin, Z.; Pu, H.; Ding, G. Repvit: Revisiting mobile cnn from vit perspective. arXiv 2023, arXiv:2307.09283. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, South Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Li, S.; Deng, W. Reliable crowdsourcing and deep locality-preserving learning for unconstrained facial expression recognition. IEEE Trans. Image Process. 2019, 28, 356–370. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.J.; Erhan, D.; Carrier, P.L.; Courville, A.; Mirza, M.; Hamner, B.; Cukierski, W.; Tang, Y.; Thaler, D.; Lee, D.-H.; et al. Challenges in representation learning: A report on three machine learning contests. In Proceedings of the International Conference on Neural Information Processing, Daegu, Korea, 3–7 November 2013; pp. 117–124. [Google Scholar]
- Barsoum, E.; Zhang, C.; Ferrer, C.C.; Zhang, Z. Training deep networks for facial expression recognition with crowd-sourced label distribution. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, Tokyo, Japan, 25–29 October 2016; pp. 279–283. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Bottou, L. Stochastic gradient descent tricks. In Proceedings of the Neural Networks: Tricks of the Trade; Montavon, G., Orr, G.B., Müller, K.R., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 421–436. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual explanations from deep networks via gradient-based localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar] [CrossRef]
- Zhao, G.; Yang, H.; Yu, M. Expression recognition method based on a lightweight convolutional neural network. IEEE Access 2020, 8, 38528–38537. [Google Scholar] [CrossRef]
- Siqueira, H.; Magg, S.; Wermter, S. Efficient facial feature learning with wide ensemble-based convolutional neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 3 April 2020; No. 4. Volume 34, pp. 5800–5809. [Google Scholar] [CrossRef]
- Miao, S.; Xu, H.; Han, Z.; Zhu, Y. Recognizing facial expressions using a shallow convolutional neural network. IEEE Access 2019, 7, 78000–78011. [Google Scholar] [CrossRef]
- Li, M.; Xu, H.; Huang, X.; Song, Z.; Li, X.; Li, X. Facial expression recognition with identity and emotion joint learning. IEEE Trans. Affect. Comput. 2018, 12, 544–550. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar] [CrossRef]
- Ma, N.; Zhang, X.; Zheng, H.-T.; Sun, J. ShuffleNet V2: Practical guidelines for efficient cnn architecture design. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; Volume 11218, pp. 122–138. [Google Scholar] [CrossRef]
- Shengtao, G.; Chao, X.; Bo, F. Facial expression recognition based on global and local feature fusion with CNNs. In Proceedings of the International Conference on Signal Processing, Communications and Computing (ICSPCC), Dalian, China, 20–23 September 2019; pp. 1–5. [Google Scholar]
- Pham, T.T.D.; Kim, S.; Lu, Y.; Jung, S.-W.; Won, C.-S. Facial action units-based image retrieval for facial expression recognition. IEEE Access 2019, 7, 5200–5207. [Google Scholar] [CrossRef]
- Arriaga, O.; Valdenegro-Toro, M.; Plöger, P. Real-time convolutional neural networks for emotion and gender classification. arXiv 2017, arXiv:1710.07557. [Google Scholar] [CrossRef]
- Liu, K.; Zhang, M.; Pan, Z. Facial expression recognition with CNN ensemble. In Proceedings of the International Conference on Cyberworlds (CW), Chongqing, China, 28–30 September 2016; pp. 163–166. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Rank | |||
|---|---|---|---|
| 2 | 1.00 | ||
| 3 | 0.83 | ||
| 4 | 0.70 | ||
| 5 | 0.60 | ||
| … | … | … | |
| Experimental Structure in Cifar10 | Output Size | ||
|---|---|---|---|
| Input | 96 × 96 | ||
| Inception-e module | Eception module | Lception module | 96 × 96 |
| channel = 32 | channel = 32 | channel = 32 | |
| 1/2 MaxPool | 48 × 48 | ||
| Inception-e module | Eception module | Lception module | 48 × 48 |
| channel = 64 | channel = 64 | channel = 64 | |
| 1/2 MaxPool | 24 × 24 | ||
| Inception-e module | Eception module | Lception module | 24 × 24 |
| channel = 96 | channel = 96 | channel = 96 | |
| 1/2 MaxPool | 12 × 12 | ||
| Inception-e module | Eception module | Lception module | 12 × 12 |
| channel = 128 | channel = 128 | channel = 128 | |
| 1/2 MaxPool | 6 × 6 | ||
| Inception-e module | Eception module | Lception module | 6 × 6 |
| channel = 160 | channel = 160 | channel = 160 | |
| 1/2 MaxPool | 3 × 3 | ||
| Global Average Pool | 1 × 1 | ||
| Dropout (0.2) | |||
| Fully-concatenate, softmax | 10 | ||
| FER+ | ||
|---|---|---|
| Parameters | OA | |
| Lception module (rank = 4) ours | 1.3 M | 86.9 |
| Eception module (rank = 4) ours | 2.3 M | 87.3 |
| Eception module (rank = 8) ours | 4.8 M | 87.6 |
| Original Inception module * | 1.4 M | 85.2 |
| Inception module A * | 1.2 M | 86.3 |
| VGG-11-GAP * | 2.4 M | 86.5 |
| VGG-13-GAP * | 3.5 M | 85.0 |
| VGG-13 [43] | 9.4 M | 84.4 |
| VGG-19 [43] | 20.0 M | 84.4 |
| ResNet18 [43] | 11.2 M | 84.8 |
| MobilNet v1 [43] | 1.1 M | 83.5 |
| MobilNet v2 [43] | 2.2 M | 81.4 |
| ShuffleNet v1 [43] | 0.9 M | 84.1 |
| ShuffleNet v2 [43] | 1.3 M | 80.4 |
| ESRs [44] | - | 87.2 |
| SHCNN [45] | - | 86.5 |
| LER [43] | - | 85.7 |
| TFE-JL [46] | - | 84.3 |
| FER2013 | |
|---|---|
| OA | |
| Lception module (rank = 4) ours | 68.4 |
| Eception module (rank = 4) ours | 68.5 |
| Eception module (rank = 8) ours | 67.9 |
| Alexnet [49] | 66.7 |
| GoogLenet [50] | 64.6 |
| GoogLenet + MLP [50] | 65.8 |
| mini-Xception [51] | 66.0 |
| Subnet3 [52] | 62.4 |
| Subnet Ensemble [52] | 65.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, C.; Liu, Z.; Qu, J.; Deng, Y. The Expansion Methods of Inception and Its Application. Symmetry 2024, 16, 494. https://doi.org/10.3390/sym16040494
Shi C, Liu Z, Qu J, Deng Y. The Expansion Methods of Inception and Its Application. Symmetry. 2024; 16(4):494. https://doi.org/10.3390/sym16040494
Chicago/Turabian StyleShi, Cuiping, Zhenquan Liu, Jiageng Qu, and Yuxin Deng. 2024. "The Expansion Methods of Inception and Its Application" Symmetry 16, no. 4: 494. https://doi.org/10.3390/sym16040494
APA StyleShi, C., Liu, Z., Qu, J., & Deng, Y. (2024). The Expansion Methods of Inception and Its Application. Symmetry, 16(4), 494. https://doi.org/10.3390/sym16040494