1. Introduction
As part of our work on constructing simulation models for grinding machines, to be used for process design in programs such as ModSim [
1], we undertook a review of the literature on tower mills. The most complete study useful for our purpose was the work done by Duffy [
2] on a pilot-scale tower mill at the Mount Isa Mines in Australia, using an ore sample from the mine. The work contains nine tests on this ore, run as batch grinding tests. Since Duffy provided no data analysis from a kinetic point of view, his results are re-examined here using the concepts of grinding kinetics [
3].
One important and recurrent discussion that arises from the mill modeling work is related to the number of parameters that are required to describe the breakage and selection functions. More parameters tend to produce better fits but at a cost, which is the lack of meaning of the calculated parameters resulting from the large flat-model response that is generated from increasing the number of degrees of freedom. Fewer parameters are desirable because they are easier to determine and tend to have a simpler, clear graphical representation (slopes and intercepts). However, fewer parameters will also produce lower quality fits (larger values for the objective function, deviation from measured data, etc.). It is reasonable to say that having fewer parameters is the more attractive alternative, mostly because it is easier to implement solutions for fewer parameters (such as the Solver™ supplement in Excel™). In favorable scenarios at least two parameters are required for the breakage function (as in a truncated Gaudin–Schuhmann model) and two parameters for the selection function (given we are not in the abnormal breakage region), giving a minimum number of four model parameters to describe the grinding action in a perfectly mixed region of a mill. Further reduction of parameters in the classical size-mass balance model is not possible. The simple model, however, contains only two model parameters, and this, at the very least, means that it is much easier to implement and to determine parameter values, making this alternative more attractive. The simple model was first proposed by Gaudin and Meloy [
4]. The idea driving it is quite logical, and it is possible to determine the rate of production of particles smaller than any given size if the grinding rate of all particles larger than the size is known.
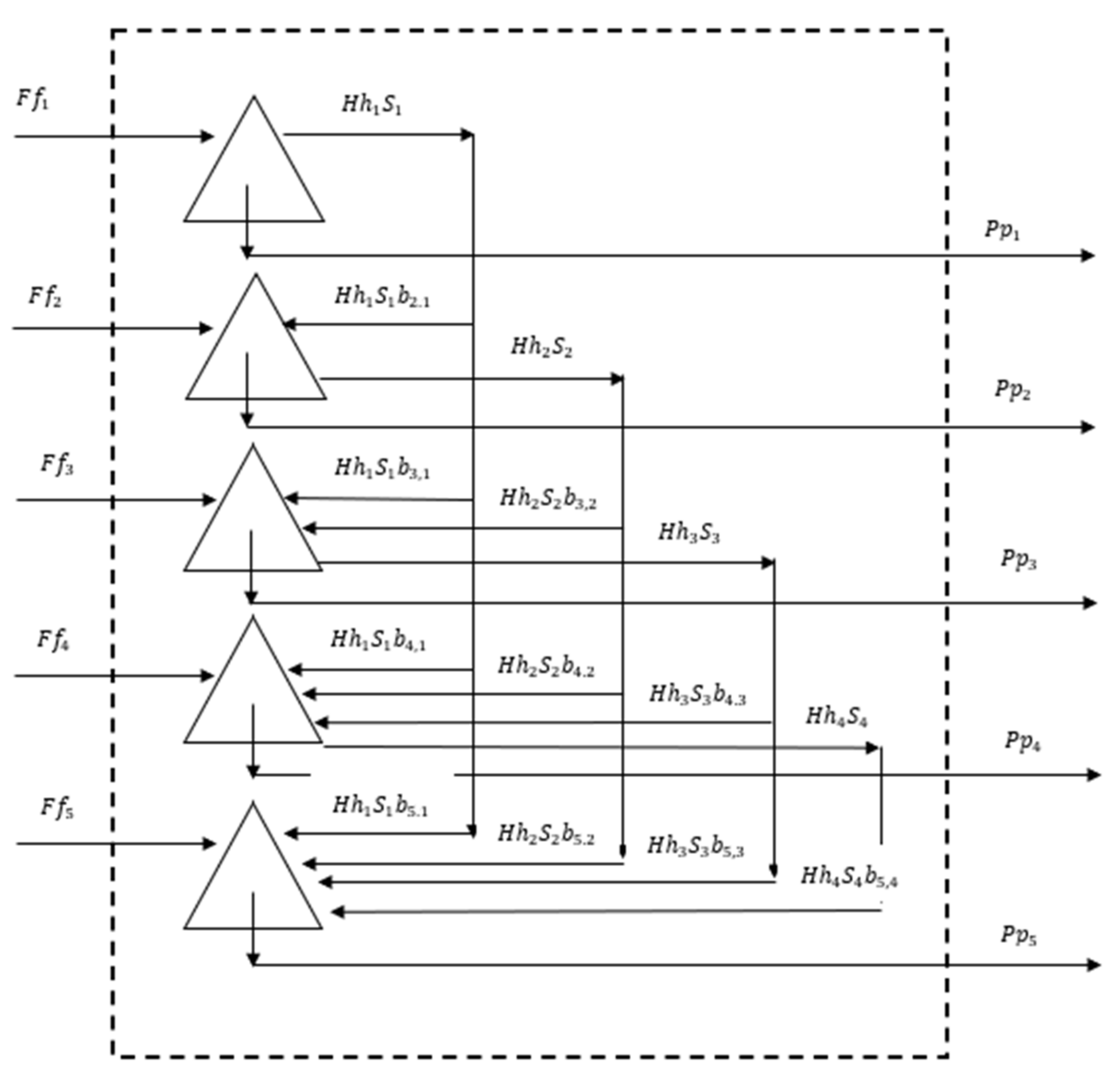
It is important to understand the difference between the classic size-mass balance model and the simple model. The classic size-mass balance model is illustrated in the diagram in
Figure 1.
The perfectly mixed mill region represented in
Figure 1 is being fed
F t/h of coarse particles and producing
P t/h of finer particles. Each triangle represents a particle size range in the perfectly mixed region. There is no special location associated with each size range, but, in the diagram, the coarsest particles are represented by the top triangle. The lower the position of the triangle in the sketch, the finer the particle size range it represents.
For the fourth size class, accounting for all particles leaving the size class in the left side of the equation and all particles entering the class in the right side of the equation:
At steady state,
F =
P. Furthermore, for a perfectly mixed region,
hi =
pi. Equation (1) can be rewritten as:
Dividing both sides by
F, and rewriting the sum within parenthesis using sigma notation:
The ratio
H/
F is equal to τ, the average residence time in the perfectly mixed region. Solving for
p4:
It can be readily seen that this expression can be written in a general form for any size class
i within the perfectly mixed region:
Equation (2) represents the population balance model solution for a continuous, perfectly mixed mill region. It is in fact a size-mass balance with all distributions as mass-weighed distributions rather than the number-weighed distributions that are used in formal population balance models. Equation (2) can be solved recursively starting with size i = 1.
The solution in Equation (2) can be easily expanded to a series of perfect mixers in series, with each mixer fed with the product of the previous one.
Classification effects can be incorporated as well, and this is required in overflow ball mills that are operated with relatively lower slurry viscosities, in which case overflow classification becomes important, and in grate discharge mills, such as ball mills, ROM mills and SAG mills.
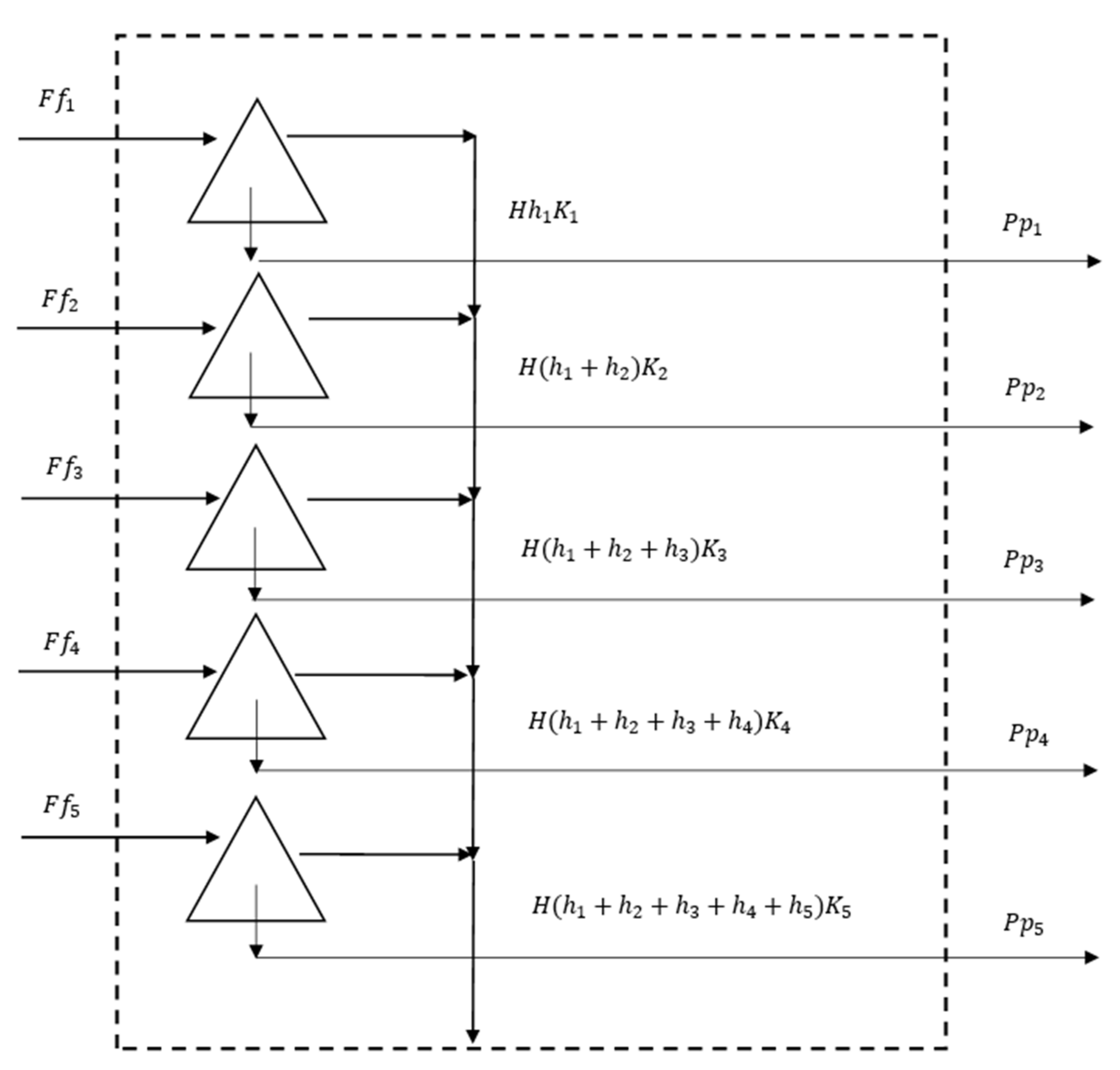
For the simple model it is not necessary (nor desirable) to be concerned with the destinations of all breakage products (the breakage function). All that we are concerned with is the rate of breakage of all particles larger than a given size. A diagram could be envisaged for this model in the same fashion as the diagram for the classic model. This is shown in
Figure 2.
For the simple model, the same definitions as in the classic model in
Figure 1 are used, except that here the rates of breakage of each size class
Si are replaced by cumulative rates
Ki as we are only interested in the rate of production of particles smaller than size
i from all particles larger than size
i. It is worth pointing out that
K1 =
S1 and
Ki ≠
Si for
i > 1.
Similarly, a balance for the fourth size class can be written as:
Again, at steady state,
F =
P. Furthermore, for a perfectly mixed region,
hi =
pi. Equation (1) can be rewritten as:
Using the definition of the cumulative distribution for the sum within the parenthesis:
and for any size
i, Equation (4) can be generalized to:
This is the simple model for a perfectly mixed region of a continuous grinding mill, as proposed by Gaudin and Meloy [
4]. More recently, the simple model was revisited to make estimates of the charge in a SAG pilot mill [
5]. In that work the cumulative rates were assumed to be constant or highly independent of the hold-up size distribution, and this apparently worked well for predicting the charge level under distinct grinding conditions, with power draw as the driving charge level regulator.
3. Mill Conditions
The measured conditions in the mill for each of the nine tests are given in
Table 1.
For a mill of this size, it is convenient to work in units of kg and liter, with densities expressed as kg/L (=g/cm3 = specific gravity). Let the ball diameter be d (mm), the load of balls be BL (kg), the slurry (often called pulp) concentration be s (weight % solids or weight fraction of solids) and the charge of slurry (ore and water) be pulp weight (kg). The density of the steel balls is given as 7.9 kg/L and the ore as ρore = 3.82 kg/L.
These values can be expressed as derived values using definitions similar to those used in tumbling ball mills [
6]. Let
W be the weight of ore in the charge (referred to as the hold up),
J be the fraction of the mill volume filled by a bed of balls at rest with a formal porosity of 40% and
U be the fraction of this bed porosity that is filled by the ore particles as a bed, also with a formal porosity of 40%. Let the active volume of the mill be defined as
V = the combined volume of slurry and balls (liters). Then:
pulp density = 1/[(s/ρore) + (1 − s)]
pulp volume = pulp weight/pulp density
volume of balls = ball load/ball density
total volume = pulp volume + ball volume
hold up W = pulp weight × slurry concentration as weight fraction of ore
J = (ball volume/0.6)/total volume
U = (W/ore density)/ball volume
The measured values obtained by Duffy produce the data given in
Table 2.
It can be seen that expressing the mill conditions in a form similar to that used for tumbling ball mills gives values very similar to the conditions used in ball mills to get optimum performance, especially U being close to 1 for most of the runs. The mean active mill volume determined from the amount of slurry and balls necessary to fill the mill to overflow is 96.4 L, which is consistent with the physical dimensions of the mill, and the variation of values from the mean is believed to be consistent with the expected variation in experimental determination of the inputs.
Furthermore, considering the pumped flow rates of overflow back to the mill, each liter of flow contains:
Thus, knowing the volume flow rate of slurry, the weight flow rate of solids can be calculated. The mean residence time of solids in the mill is defined by
τ =
W/(weight flow rate of solids) and these results are also shown in
Table 1 for those tests where flow rates are available in Duffy’s thesis.
The values of the volume flow rate are somewhat variable with the test time, but the estimates of mean residence time show that the solids being ground circulate at least once per minute. Since the first test time is 15 min this seems an adequate justification for a fully mixed mill.
All tests were carried out with the same stirrer speed of 100 rpm.
4. Preliminary Analysis of the Kinetics of Size Reduction
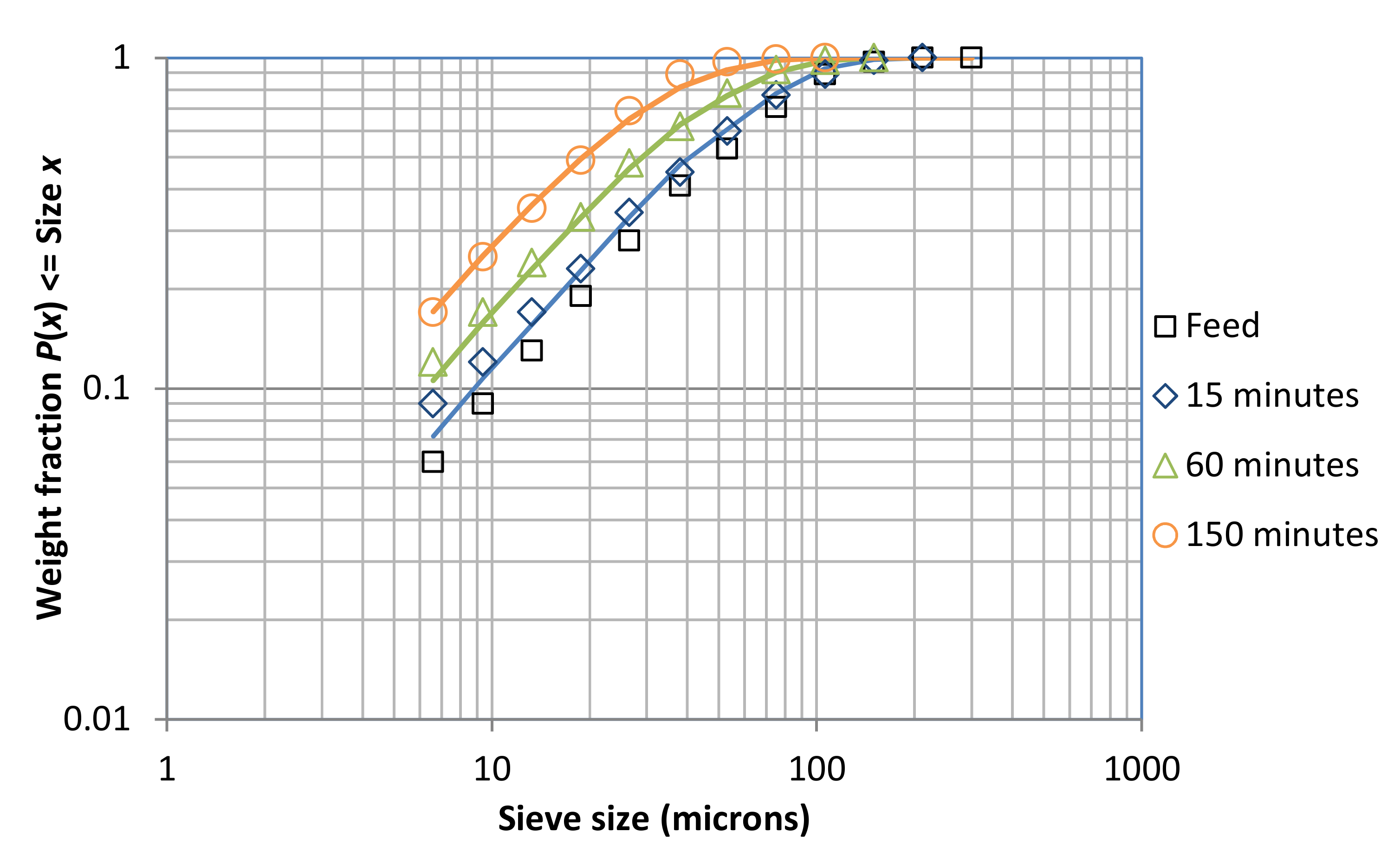
The kinetics of size reduction is determined from the rate at which the particle size distribution of the feed is reduced to smaller particle sizes. The symbolism to describe the size distributions is as follows. Let the particle size distribution of the material (being ground) in the mill at zero grinding time (the feed) be described by the cumulative fraction by weight Fi less than size xi, where x is a sieve size (or equivalent) in microns and i is an integer indexing a 1/√2 size interval with the upper size of xi, with i ranging from 1 for the largest size to n, where n is the number of size intervals. Thus, the nth interval is size xn to 0 (known as the sink interval). Similarly, let the product size distributions Pi,k be defined for a series of grinding times t in minutes indexed by the integer k, starting with 1, i.e., t1, t2, …tk.
Table 3 shows the results for Run 1:
Examination of these data indicated that the results fitted the “simple” model of batch grinding kinetics [
4,
7]. This model results from a compensation condition where larger particle sizes break more quickly than smaller sizes but the fraction of their breakage products that is smaller than a chosen size
x (less than the breaking sizes) is lower, to the extent that the rate of production of material smaller than size
x depends on the amount of material larger than size
x but NOT on the size distribution of the larger sizes. The normal batch grinding equation then becomes:
rate of increase of mass of particles less than size xi = sum of all contributions from breakage of larger sizes
wj is the fraction of the hold up W that has particle sizes in the size interval indexed by j.
Bi,j is the primary cumulative breakage distribution function (i.e., the mass fraction of products broken from the size interval indexed by j that have sizes less than or equal to particle size xi).
Sj is the specific rate of breakage of particles in the size range of interval j, j < i. Since the compensation condition states that Bi,j Sj is a function of xi only, Bi,j Sj can be replaced by S(xi). This now has the meaning of the specific rate of breakage of all sizes larger than xi.
Since
S(
xi) is a constant for a chosen
xi it can be taken out of the summation, while
W cancels and the sum of
wj is the fraction of the particle mass that is greater than or equal to size
xi; i.e., 1 −
P(
xi,
t). Separating and integrating Equation (6) from
t = 0 to
t =
τ with these changes and using the initial condition of 1 −
P(
xi,0) = 1 −
F(
xi) gives the simple model equation for batch grinding:
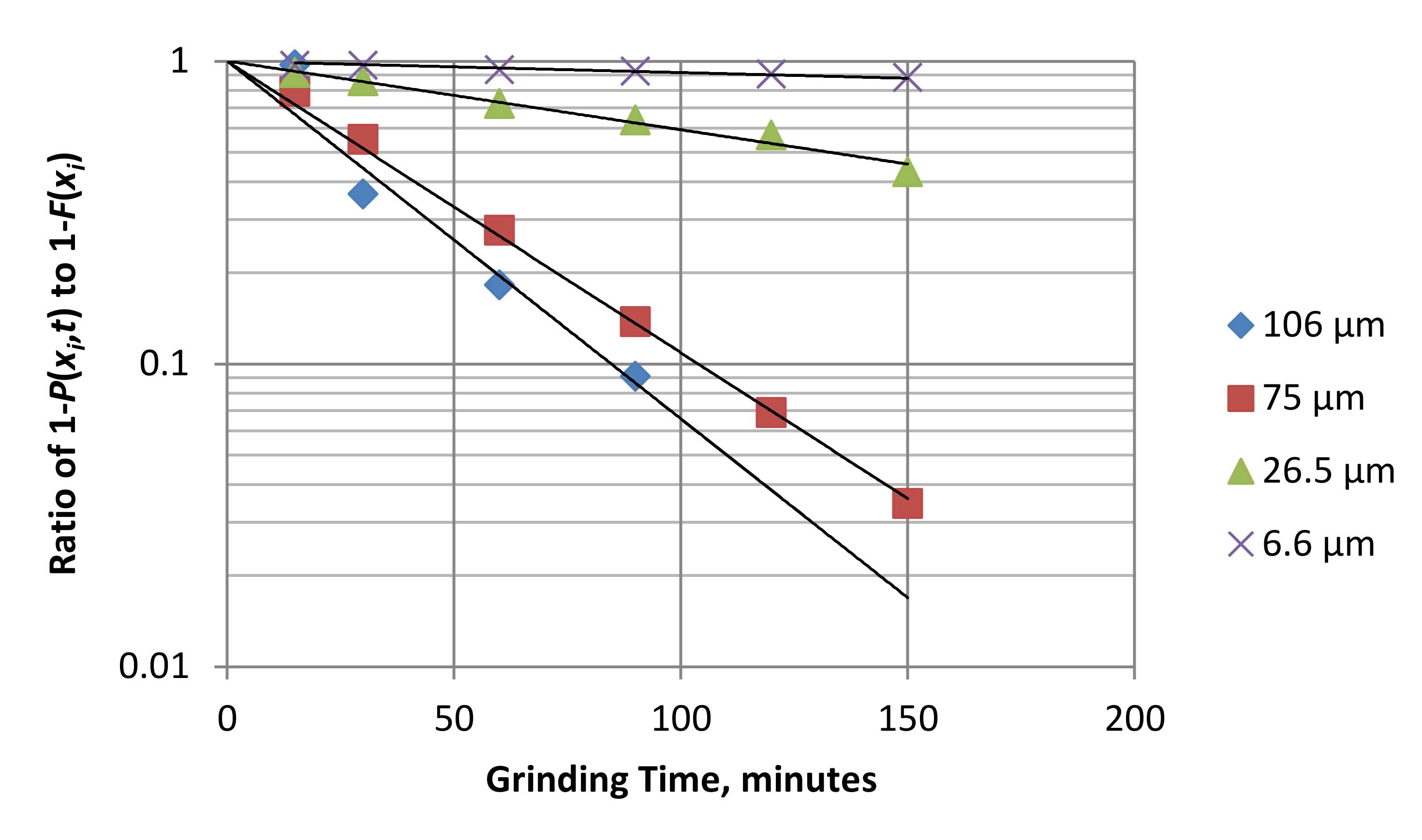
The applicability of this equation to the data can be tested by plotting (1 −
P)/(1 −
F) for chosen particle sizes, on a log scale, versus
τ on a linear scale, as shown in
Figure 4. There is scatter in some of the results, but the general pattern is that the model describes the data with reasonable precision. Note that
Pi depends on
Si−1 not
Si, as
P2 clearly depends on
S1. Furthermore, Equation (7) is continuous in grinding time
t but discrete in size
x.
The simple solution for batch grinding for time
t is:
This can be plotted as the fraction 1 −
P(
xi,
t)/(1 −
Fi) versus grinding time t. It is algebraically convenient to denote the ratio 1 −
P(
xi,
t)/(1 −
Fi) as
Y(
i,
t):
where
t is a suitable range of time values. Therefore, a plot of
Y(
i,
t) versus
t on a log-linear scale will give a straight line. Similarly,
Xi,k is defined as the matrix of experimental values of (1 −
Pi,k)/(1 −
Fi), with
k indexing the (discontinuous) values of experimental grinding times.
Si is adjusted to match the experimental values for a chosen
i (i.e., a chosen
xi). This is repeated for different sizes. A good fit to the experimental values of
Xi,k will show if the simple model applies and the vector of
Si values can be obtained.
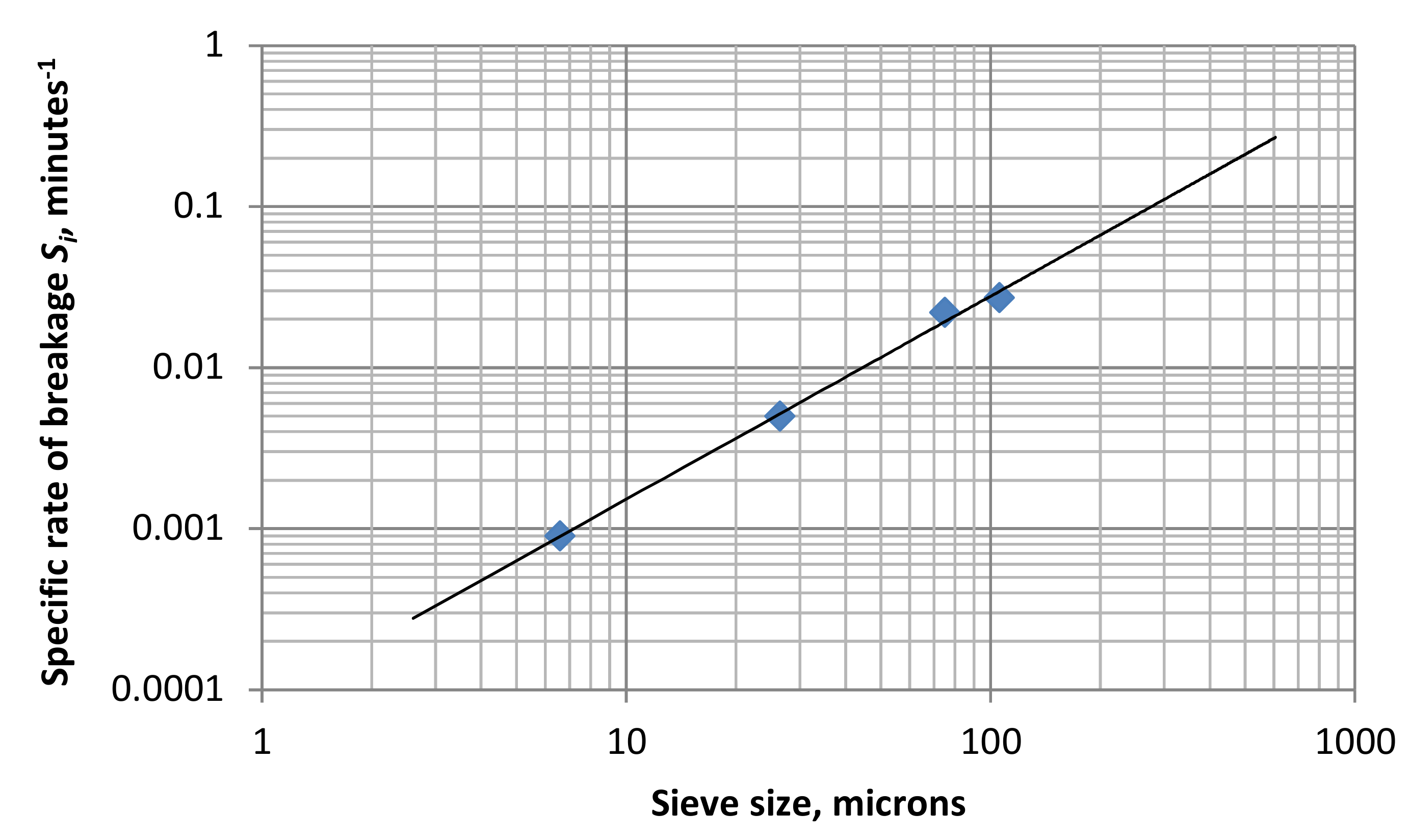
Figure 5 shows that the relation can be expressed as:
It should be understood that xs is a standard size, 1 micron in this case, so x/xs is dimensionless and a has units of fraction per minute; i.e., min−1. It is common to leave out xs as its value is one, but its inherent presence must be remembered to avoid confusion with units.
In the simple model of grinding kinetics,
S(
x) has the meaning of the specific rate of breakage (fraction per unit time) of all particles greater than size
x to sizes less than or equal to size
x. Thus,
a and
α are characteristic parameters that vary with mill conditions and the material being ground. The cumulative primary breakage distribution
B is dimensionally normalized and is:
Equation (12) is the compensation condition that is necessary for the simple model to be valid [
7]; i.e.,
SB is a function of
x but not of larger size
y. Equation (10) can be expressed as:
Equation (7) gives:
where
PC is the computed model value.
In addition to the methods of determining
a and
α given above, the values can be found by assuming the model to apply (as indicated here) and choosing values for
a and
α that give the best fit between the computed and experimental values of the product size distributions, as is shown in
Figure 6. The criterion chosen here is unweighted least squares of error (as described in the Statistical Analysis in
Section 6):
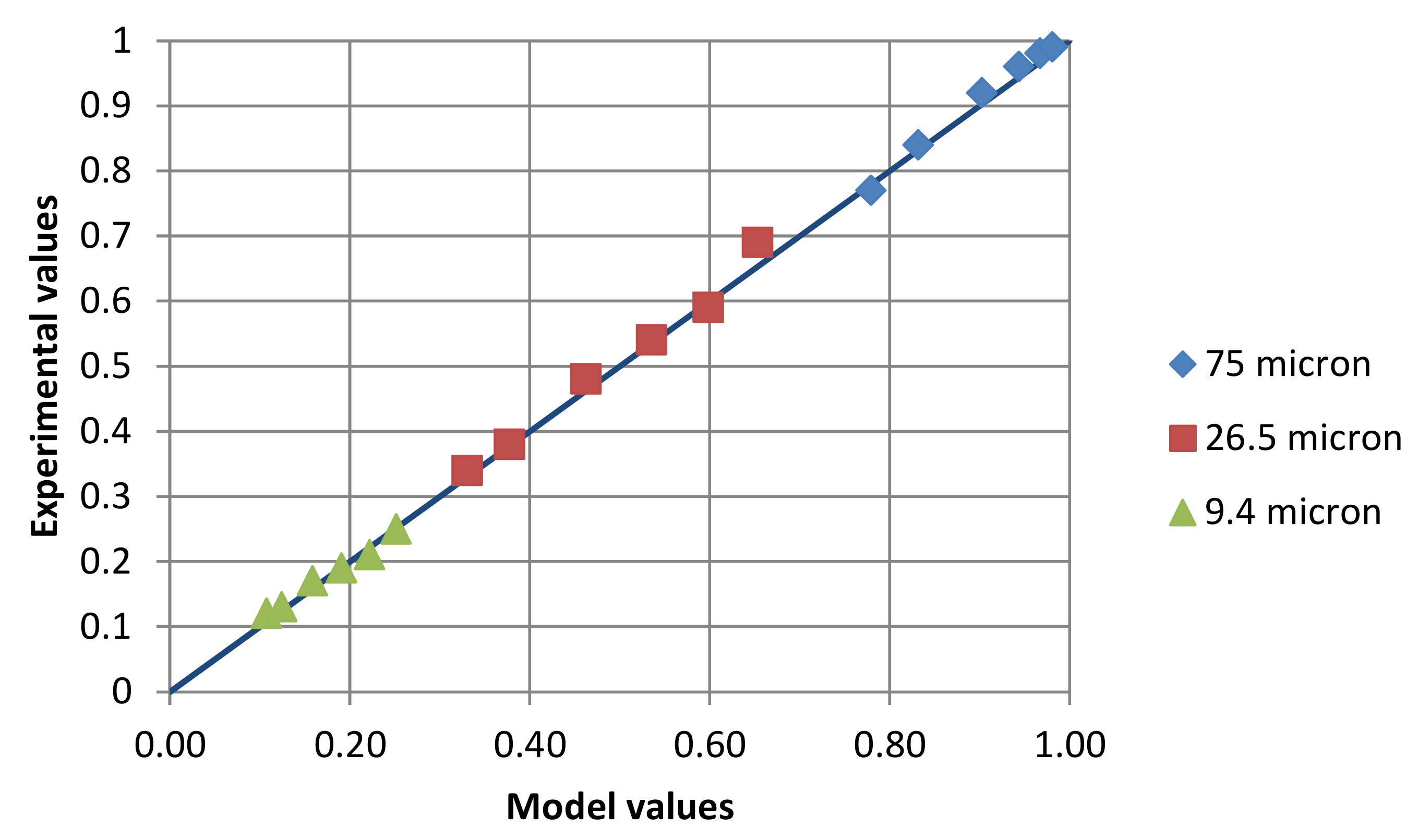
The adequacy of the fit with the simple model can also be demonstrated by comparing measured and calculated % < size for selected sizes for all grinding times. This is shown in
Figure 7. The slope of the straight line in this figure is 1, passing through 0, and there is very little scatter for the selected particle sieve sizes.
5. Results for All Runs
Table 4 gives the results for
a and
α plus the
SSQ criterion value for each run.
It can be seen that Run 7 has an
SSQ several times higher than the other values. There was nothing unusual about the test conditions, but Duffy reported that the mill appeared to be blocking during this run. Consequently, Run 7 was ignored in further analysis of the results. It can be observed that the values of
α are 1.5 plus or minus about 0.3. It is expected that the
a values should vary with slurry density (see below) but there is no physical reason why changes in slurry density would make smaller particles break slower or faster with respect to larger particles, so the value of
α should be constant. In addition, it has been shown [
8] that determination of parameters in the presence of variability in the data can give ranges of the parameter values that are equally valid. A discussion in detail of the application of statistics to the determination of kinetic breakage parameters is given in Austin, Klimpel and Luckie, [
9].
Consequently, the data for Run 1 were re-examined to see if the use of α = 1.5 would give a statistically significant worse result than α = 1.27. For any value of α the value of a that gives the minimum SSQ is found by a search, and α is also searched to get the optimum minimum.
Trial values of a and α for Run 1 are:
SSQ = 0.019 for α = 1.27, a = 7.9 × 10−5;
SSQ = 0.014(5) for α = 1.4, a = 5.2 × 10−5;
SSQ = 0.016 for α = 1.5, a = 3.7 × 10−5;
SSQ = 0.027 for α = 1.6, a = 2.5 × 10−5.
It can be seen that there is a range of a, α pairs that give little change in SSQ values. The optimum minimum was for α = 1.45, a = 4.4 × 10−5, giving SSQ = 0.014(5).
6. Statistical Analysis
In order to see if the value of
α = 1.5 was valid, a statistical analysis [
9] was adapted to apply to the simple model. Since this model considers a kinetic mass-time balance for breakage of material greater than sieve size
x to product less than size
x, the correct definition of error is
Pi −
PCi. In this model there are only two parameters,
a and
α. An investigation was made of weighting factors as follows.
Values of error could have had a bias of becoming larger error values at higher 1 −
PC values. However, the error values were so variable that it was not possible to decide on the weighting relation with a graphical examination, so a least squares search was undertaken. The objective was to minimize the sum of squares of error taken over all the data points with a suitable weighting factor.
The value of γ was varied from 0 to 2, giving: γ = 0, SSQW = 0.014; γ = 1/2, SSQW = 0.032; γ = 1, SSQW = 0.097; γ = 1.5, SSQW = 0.56; and γ = 2, SSQW = 9.9. The results suggest that there is no weighting factor; that is, γ = 0 and the sum of squares is of “absolute error squared”; γ = 2 would give “relative error squared”.
The values of
a and
α that give the minimum
SSQ are called “optimal” and the corresponding
SSQ is the optimal value. Then, the
F factor is defined as
In this equation,
n is the number of data points and
N is the number of parameters being searched. Each test had 12 data points and 6 times, so
n = 72.
N is 2 for
a and
α, but when
α is set (at 1.5 in this case) then
SSQ has
N replaced by
N − 1. Examination of a table of
F values [
10] as a function of
Q(
F|ν1,ν2) where ν1 =
n −
N, ν2 =
n −
N + 1 and
Q is the probability that
SSQ >
SSQopt, will show if the
SSQ error from forcing alpha to be 1.5 is significantly greater than
SSQopt, according to where
F is placed in the table.
For the case considered here, the value of
F < 1.5 (95% confidence level) implies that
SSQ is not significantly greater than
SSQopt.
Table 5 gives the results of applying Equation (19) to all tests (except Run 7).
It is seen that the F value is less than 1.5, a requisite to conclude that there is no significant error introduced by using α as 1.5 with the corresponding a values, except in Run 9. Thus, it was decided to choose α as 1.5 for all runs and therefore to use only the values of a to correlate the effects of test conditions on specific rates of breakage.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}