
Prediction of Prospecting Target Based on Selective Transfer Network

Abstract
:1. Introduction
- (1)
- Methods based on ensemble learning combine multiple supervised learning algorithms for prospecting target prediction. For example, the authors in [11] determined the hyperparameters of the random forest by simulating the natural evolution process, which were used to improve the accuracy of the model in predicting the prospecting target area. The authors in [12] used the isolation forest algorithm to predict outliers to determine the prospecting target area. The authors in [13] proposed the use of metric learning in the random forest to project the sample features into the feature space, separating the background and mining targets, so as to improve the prediction accuracy of the model.
- (2)
- Methods based on the support vector machine (SVM) divide mining samples and other samples through a hyperplane. For example, the authors in [14] separated the “mines” samples from “non-mines” samples through the optimal hyperplane and determined three prospecting target areas on both sides of the hyperplane. The authors in [15] used a genetic algorithm to optimize the hyperparameters of SVM to reduce its influence on prospecting target prediction.
- (3)
- Methods based on depth neural networks project the geoscience data into the same depth neural network space and extract effective features through multiple nonlinear transformations for prospecting target prediction. For example, the authors in [16] used three-layer convolution to extract the features of a Zn-element concentration distribution map to predict the prospecting target area. The authors in [17] used AlexNet to extract the features of multiple ore-forming factor maps to determine four prospecting target areas.
- (1)
- Methods based on data augmentation increase the diversity of geological samples by cropping, changing the chromatic aberration and size, and distorting features. For example, the authors in [18] added random noises into geological data to predict a prospecting target by a deep convolutional network. The authors in [19] first oversampled the samples with mines and then used the random forest to determine the prospecting target areas. The authors in [20] proposed recombining pixel pairs of geological samples to assist in prospecting target prediction. These methods increase the number of geological samples but cannot cope with the irregular features of the mining areas.
- (2)
- Methods based on multiscale feature transformation acquire mining area features of different scales through irregular sampling for training [21,22]. For example, the authors in [23] proposed to extract irregular features of different scales using multigroup convolution or a pooling operation and fused them for prospecting target prediction. The authors in [24] used four convolution operations with different sizes to extract and fuse irregular features of geological data to improve the prediction accuracy. However, these methods do not consider the small number of samples in the prospecting target area.
- 1.
- A deep learning framework for prospecting target prediction is proposed, which provides a new way for prospecting target prediction.
- 2.
- A novel selective knowledge transfer mechanism is designed, which selectively transfers knowledge from the source network to target networks, which increases the performance of the target networks in prospecting target prediction during testing without adding additional computational cost.
- 3.
- For the first time, a soft mask strategy is proposed to maintain the consistency of related mineral elements. Its purpose is to utilize the metallogenic indicative significance of the main mineral elements and associated mineral elements to complete the prospecting target prediction task.
2. Study Area and Data
2.1. Study Area
2.2. Data Processing
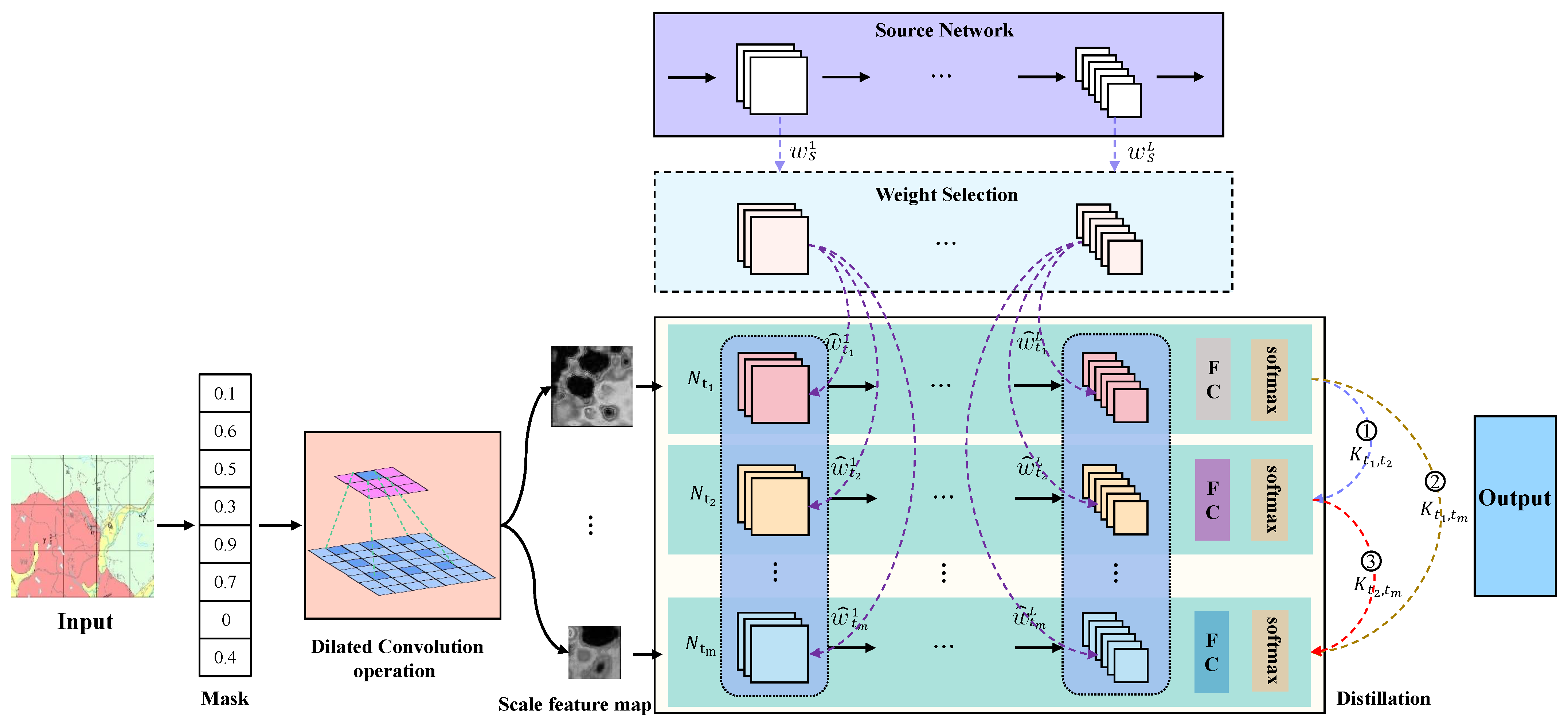
3. Methodology
3.1. Problem Formulation
3.2. Congruence of Related Mineral Elements
3.3. Selective Knowledge Transfer
3.4. Self-Distillation
3.5. Objective Function
4. Experiments
4.1. Experimental Settings
4.2. Experimental Results and Analysis
4.3. Correlation Analysis Experiment
4.3.1. Ablation Experiments
- 1.
- The soft mask makes the corresponding weight of the associated mineral elements as consistent as possible with that of the main mineral elements. Dilated convolution deals with the irregular features of the mining areas through different receptive fields. Selective knowledge transfer improves the model generalization performance to solve the problem of a small number of samples. Self-distillation mines the hidden knowledge between the feature maps of different scales. All of the aforementioned methods can improve the Accuracy, Recall, and F1-score of the prospecting prediction.
- 2.
- The contributions of these methods to SKT are different. According to the contribution from large to small, they are ranked as follows: dilated convolution, selective knowledge transfer, soft mask, and self-distillation.
4.3.2. Parameter Analysis Experiments
4.4. Visualization
5. Conclusions
- (1)
- In view of problems such as the small number of geological samples and the irregular features of mining areas in the research of prospecting prediction, the deep learning framework (SKT) for prospecting target prediction based on selective knowledge transfer has greatly improved the prediction of the samples with mines, which is obviously superior to other methods.
- (2)
- Soft mask makes the corresponding weight of associated mineral elements consistent with that of the main mineral elements as much as possible; dilation convolution enriches irregular features of the mining areas through capturing features at different scales; selective knowledge transfer improves the generalization performance of the model and solves the problem of a small number of samples; and self-distillation mines the hidden knowledge between different scale feature maps.
- (3)
- Parameter analysis experiments show that dilation convolution, selective knowledge transfer, soft mask, and self-distillation can improve the accuracy of SKT prediction, but their contribution to SKT gradually weakens.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Scharf, T.; Kirkland, C.; Daggitt, M.; Barham, M.; Puzyrev, V. AnalyZr: A Python application for zircon grain image segmentation and shape analysis. Comput. Geosci. 2022, 162, 105057. [Google Scholar] [CrossRef]
- Middya, A.I.; Nag, B.; Roy, S. Deep learning based multimodal emotion recognition using model-level fusion of audio–visual modalities. Knowl.-Based Syst. 2022, 244, 108580. [Google Scholar] [CrossRef]
- Cui, S.; Ma, A.; Zhang, L.; Xu, M.; Zhong, Y. MAP-Net: SAR and Optical Image Matching via Image-Based Convolutional Network With Attention Mechanism and Spatial Pyramid Aggregated Pooling. IEEE Trans. Geosci. Remote. Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Elashmawy, M.; Alatawi, I. Atmospheric water harvesting from low-humid regions of Hail City in Saudi Arabia. Nat. Resour. Res. 2020, 29, 3689–3700. [Google Scholar] [CrossRef]
- Eppelbaum, L.; Eppelbaum, V.; Ben-Avraham, Z. Formalization and Estimation of Integrated Geological Investigations: An Informational Approach. Geoinformatics 2003, 14, 233–240. [Google Scholar] [CrossRef]
- Siebels, K.; Goïta, K.; Germain, M. Estimation of Mineral Abundance From Hyperspectral Data Using a New Supervised Neighbor-Band Ratio Unmixing Approach. IEEE Trans. Geosci. Remote. Sens. 2020, 58, 6754–6766. [Google Scholar] [CrossRef]
- Li, S.; Chen, J.; Liu, C. Overview on the Development of Intelligent Methods for Mineral Resource Prediction under the Background of Geological Big Data. Minerals 2022, 12, 616. [Google Scholar] [CrossRef]
- Jooshaki, M.; Nad, A.; Michaux, S. A systematic review on the application of machine learning in exploiting mineralogical data in mining and mineral industry. Minerals 2021, 11, 816. [Google Scholar] [CrossRef]
- Duda, R.O.; Hart, P.E. Pattern Classification and Scene Analysis; Wiley: New York, NY, USA, 1973; Volume 3. [Google Scholar]
- Zekri, H.; Cohen, D.R.; Mokhtari, A.R.; Esmaeili, A. Geochemical prospectivity mapping through a feature extraction–selection classification scheme. Nat. Resour. Res. 2019, 28, 849–865. [Google Scholar] [CrossRef]
- Daviran, M.; Maghsoudi, A.; Ghezelbash, R.; Pradhan, B. A new strategy for spatial predictive mapping of mineral prospectivity: Automated hyperparameter tuning of random forest approach. Comput. Geosci. 2021, 148, 104688. [Google Scholar] [CrossRef]
- Zhang, S.; Carranza, E.J.M.; Xiao, K.; Wei, H.; Yang, F.; Chen, Z.; Li, N.; Xiang, J. Mineral Prospectivity Mapping based on Isolation Forest and Random Forest: Implication for the Existence of Spatial Signature of Mineralization in Outliers. Nat. Resour. Res. 2021, 1–19. [Google Scholar] [CrossRef]
- Wang, Z.; Zuo, R.; Dong, Y. Mapping of Himalaya Leucogranites Based on ASTER and Sentinel-2A Datasets Using a Hybrid Method of Metric Learning and Random Forest. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2020, 13, 1925–1936. [Google Scholar] [CrossRef]
- Wang, Y.; Zhou, Y.; Xiao, F.; Wang, J.; Wang, K.; Yu, X. Numerical Metallogenic Modelling and Support Vector Machine Methods Applied to Predict Deep Mineralization:A Case Study from the Fankou Pb-An ore Deposit in Northem Guangdong. Geotecton. Metallog. 2020, 44, 9. [Google Scholar] [CrossRef]
- Mandana, T.; Behnam, B.; Saeed, D. Intelligent geochemical exploration modeling using multiclass support vector machine and integration it with continuous genetic algorithm in Gonabad region, Khorasan Razavi, Iran. Arab. J. Geosci. 2021, 14, 1–15. [Google Scholar] [CrossRef]
- Liu, Y.; Zhu, L.; Zhou, Y. Experimental Research on Big Data Mining and Intelligent Prediction of Prospecting Target Area Application of Convolutional Neural Network Model. Geotecton. Metallog. 2020, 44, 1–11. [Google Scholar] [CrossRef]
- Li, S.; Chen, J.; Xiang, J. Applications of deep convolutional neural networks in prospecting prediction based on two-dimensional geological big data. Neural Comput. Appl. 2020, 32, 2037–2053. [Google Scholar] [CrossRef]
- Li, T.; Zuo, R.; Xiong, Y.; Peng, Y. Random-Drop Data Augmentation of Deep Convolutional Neural Network for Mineral Prospectivity Mapping. Nat. Resour. Res. 2020, 30, 27–38. [Google Scholar] [CrossRef]
- Li, T.; Xia, Q.; Zhao, M.; Gui, Z.; Leng, S. Prospectivity Mapping for Tungsten Polymetallic Mineral Resources, Nanling Metallogenic Belt, South China: Use of Random Forest Algorithm from a Perspective of Data Imbalance. Nat. Resour. Res. 2020, 29, 203–227. [Google Scholar] [CrossRef]
- Zhang, C.; Zuo, R.; Xiong, Y. Detection of the multivariate geochemical anomalies associated with mineralization using a deep convolutional neural network and a pixel-pair feature method. Appl. Geochem. 2021, 130, 104994. [Google Scholar] [CrossRef]
- Li, D.; Yao, A.; Chen, Q. Learning to learn parameterized classification networks for scalable input images. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 19–35. [Google Scholar]
- Yang, T.; Zhu, S.; Chen, C.; Yan, S.; Zhang, M.; Willis, A. Mutualnet: Adaptive convnet via mutual learning from network width and resolution. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 299–315. [Google Scholar]
- Yang, N.; Zhang, Z.; Yang, J.; Hong, Z.; Shi, J. A Convolutional Neural Network of GoogLeNet Applied in Mineral Prospectivity Prediction Based on Multi-source Geoinformation. Nat. Resour. Res. 2021, 30, 3905–3923. [Google Scholar] [CrossRef]
- Wang, X. Metallogenic Pattern and Mineral Prospectivity Modeling of the Dashui Gold Concentration District. Ph.D. Thesis, China University of Geosciences, Beijing, China, 2020. [Google Scholar]
- Xiao, F.; Wang, K.; Hou, W.; Erten, O. Identifying geochemical anomaly through spatially anisotropic singularity mapping: A case study from silver-gold deposit in Pangxidong district, SE China. J. Geochem. Explor. 2020, 210, 106453. [Google Scholar] [CrossRef]
- Zhou, Y.; Li, X.; Zhen, Y.; Shen, W.; He, J.; Yu, P.; Niu, J.; Zeng, C. Geological settings and metallogenesis of Qinzhou Bay-Hangzhou Bay orogenic juncture belt, South China. Acta Petrol. Sin. 2017, 33, 667–681. [Google Scholar]
- Lin, Z.; Zhou, Y.; Qin, Y.; Zheng, Y.; Liang, Z.; Zou, H.; Niu, J. Ore-controlling structure analysis of Panxidong-Jinshan silver-gold orefield, southern Qin-Hang belt: Implications for furthern exploration. Miner. Depos. 2017, 36, 866–878. [Google Scholar]
- Lobo, J.M.; Jiménez-Valverde, A.; Real, R. AUC: A misleading measure of the performance of predictive distribution models. Glob. Ecol. Biogeogr. 2008, 17, 145–151. [Google Scholar] [CrossRef]
- Zhang, S. Deep Learning for Mineral Prospecitivity Mapping of Lala-Type Copper Deposit in the Huili Region, Sichuan. Ph.D. Thesis, China University of Geosciences, Beijing, China, 2020. [Google Scholar]
- Zhang, Y.; Zhou, Y.Z.; Wang, L.F.; Wang, Z.H.; He, J.G.; An, Y.F.; Li, H.Z.; Zeng, C.Y.; Liang, J.; Lü, W.C.; et al. Mineralization-related geochemical anomalies derived from stream sediment geochemical data using multifractal analysis in Pangxidong area of Qinzhou-Hangzhou tectonic joint belt, Guangdong Province, China. J. Cent. South Univ. 2013, 20, 184–192. [Google Scholar] [CrossRef]
- Zeyu, Z.; Qingying, Z.; Shixian, L. Comparison of two machine learning algorithms for geochemical anomaly detection. Glob. Geol. 2018, 37, 1288–1294. [Google Scholar]
- Kumar, V.; Gupta, P. Importance of statistical measures in digital image processing. Int. J. Emerg. Technol. Adv. Eng. 2012, 2, 56–62. [Google Scholar]
- Jia, M.; Dong, M. Analysis and comparison of Gaussian noise denoising algorithms. J. Phys. Conf. Ser. 2021, 1846, 012069. [Google Scholar] [CrossRef]
- Zuo, R.; Peng, Y.; Li, T.; Xiong, Y. Challenges of geological prospecting big data mining and integration using deep learning algorithms. Earth Sci. 2021, 46, 350–358. [Google Scholar]
- Zuo, R.; Wang, J.; Xiong, Y.; WANG, Z. Progresses of researches on geochemical exploration data processing during 2011–2020. Bull. Mineral. Petrol. Geochem. 2021, 40, 81–93. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Lyu, P.; He, L.; He, Z.; Liu, Y.; Deng, H.; Qu, R.; Wang, J.; Zhao, Y.; Wei, Y. Research on remote sensing prospecting technology based on multi-source data fusion in deep-cutting areas. Ore Geol. Rev. 2021, 138, 104359. [Google Scholar] [CrossRef]
- Chen, Y.; Zhao, Q.; Lu, L. Combining the outputs of various k-nearest neighbor anomaly detectors to form a robust ensemble model for high-dimensional geochemical anomaly detection. J. Geochem. Explor. 2021, 231, 106875. [Google Scholar] [CrossRef]
- Wang, C.; Pan, Y.; Chen, J.; Ouyang, Y.; Rao, J.; Jiang, Q. Indicator element selection and geochemical anomaly mapping using recursive feature elimination and random forest methods in the Jingdezhen region of Jiangxi Province, South China. Appl. Geochem. 2020, 122, 104760. [Google Scholar] [CrossRef]
- Dai, L.M.; Chen, Y.L.; Zhou, Y.G.; Liu, B.; Lou, D. A decision tree model for mineral potential mapping. Prog. Geophys. 2009, 24, 1081–1087. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Tan, M.; Chen, B.; Pang, R.; Vasudevan, V.; Sandler, M.; Howard, A.; Le, Q.V. Mnasnet: Platform-aware neural architecture search for mobile. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2820–2828. [Google Scholar]
- Liu, J.J.; Hou, Q.; Cheng, M.M.; Wang, C.; Feng, J. Improving convolutional networks with self-calibrated convolutions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10096–10105. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Yuan, L.; Chen, Y.; Wang, T.; Yu, W.; Shi, Y.; Jiang, Z.H.; Tay, F.E.; Feng, J.; Yan, S. Tokens-to-token vit: Training vision transformers from scratch on imagenet. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 558–567. [Google Scholar]
- Zhu, L.; She, Q.; Li, D.; Lu, Y.; Kang, X.; Hu, J.; Wang, C. Unifying Nonlocal Blocks for Neural Networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 12292–12301. [Google Scholar]
- Amaral, T.G.; Pires, V.F.; Pires, A.J. Fault detection in PV tracking systems using an image processing algorithm based on PCA. Energies 2021, 14, 7278. [Google Scholar] [CrossRef]
- Zhou, S.G.; Zhou, K.F.; Wang, J.L. Geochemical metallogenic potential based on cluster analysis: A new method to extract valuable information for mineral exploration from geochemical data. Appl. Geochem. 2020, 122, 104748. [Google Scholar] [CrossRef]
- Ayari, J.; Barbieri, M.; Barhoumi, A.; Belkhiria, W.; Braham, A.; Dhaha, F.; Charef, A. A regional-scale geochemical survey of stream sediment samples in Nappe zone, northern Tunisia: Implications for mineral exploration. J. Geochem. Explor. 2022, 235, 106956. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| X | Y | Au | B | Sn | Cu | Ag | Ba | Mn | Pb | Zn | As | Sb | Bi | Hg | Mo | W | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 422.24 | 2418.80 | 0.9 | 3 | 8.7 | 4 | 0.025 | 33 | 147 | 27 | 26 | 1.17 | 0.31 | 0.23 | 0.04 | 2.67 | 0.79 | 212 |
| 421.37 | 2418.80 | 0.54 | 4 | 2.56 | 7 | 0.078 | 88 | 209 | 12 | 23 | 0.9 | 0.29 | 0.13 | 0.04 | 0.82 | 1.16 | 204 |
| 419.76 | 2418.25 | 0.81 | 3 | 1.52 | 5 | 0.043 | 1111 | 423 | 42 | 14 | 0.51 | 0.35 | 0.06 | 0.07 | 0.59 | 0.38 | 101 |
| 420.12 | 2418.40 | 0.37 | 2 | 1.65 | 6 | 0.046 | 941 | 498 | 38 | 17 | 0.53 | 0.31 | 0.1 | 0.02 | 0.57 | 0.33 | 111 |
| 420.55 | 2418.60 | 1.09 | 4 | 1.53 | 8 | 0.033 | 427 | 338 | 37 | 29 | 0.74 | 0.28 | 0.09 | 0.07 | 1.68 | 0.73 | 186 |
| 433.81 | 2397.92 | 2.31 | 121 | 2.2 | 4 | 0.075 | 365 | 239 | 16 | 18 | 4.31 | 0.96 | 0.43 | 0.066 | 0.77 | 3.01 | 186 |
| 424.17 | 2415.02 | 0.43 | 5 | 2.18 | 4 | 0.069 | 42 | 250 | 13 | 14 | 1.21 | 0.33 | 0.4 | 0.031 | 1.04 | 1.53 | 201 |
| 423.74 | 2415.31 | 0.51 | 5 | 4.85 | 7 | 0.004 | 30 | 242 | 47 | 31 | 0.5 | 0.26 | 0.32 | 0.016 | 1.02 | 3.07 | 210 |
| 425.14 | 2414.87 | 0.46 | 6 | 2.08 | 7 | 0.061 | 28 | 298 | 15 | 25 | 1.49 | 0.35 | 0.24 | 0.075 | 1.75 | 1.3 | 217 |
| 425.14 | 2415.15 | 0.47 | 6 | 1.95 | 7 | 0.055 | 54 | 420 | 9 | 18 | 1.07 | 0.37 | 0.14 | 0.042 | 1.08 | 0.85 | 108 |
| 424.86 | 2414.76 | 0.5 | 5 | 1.46 | 4 | 0.036 | 21 | 355 | 6 | 11 | 1.1 | 0.33 | 0.17 | 0.022 | 0.98 | 1.14 | 130 |
| 424.47 | 2414.47 | 0.59 | 6 | 2.6 | 4 | 0.038 | 29 | 170 | 6 | 21 | 1.01 | 0.33 | 0.2 | 0.039 | 1.32 | 2.02 | 192 |
| 424.82 | 2414.37 | 0.43 | 11 | 2.26 | 2 | 0.027 | 22 | 210 | 6 | 19 | 1.19 | 0.31 | 0.2 | 0.03 | 1.5 | 1.76 | 177 |
| 425.22 | 2414.46 | 1.05 | 45 | 4.2 | 3 | 0.065 | 39 | 125 | 6 | 25 | 1.94 | 0.39 | 0.54 | 0.046 | 2.17 | 3.04 | 396 |
| 424.41 | 2414.11 | 0.4 | 6 | 1.84 | 3 | 0.054 | 16 | 231 | 6 | 10 | 0.77 | 0.28 | 0.11 | 0.016 | 0.83 | 0.91 | 93 |
| 424.72 | 2413.83 | 0.9 | 7 | 3.87 | 9 | 0.094 | 135 | 231 | 48 | 45 | 2.15 | 0.41 | 0.73 | 0.069 | 1.82 | 2.54 | 327 |
| 424.35 | 2413.78 | 0.68 | 6 | 2.68 | 3 | 0.059 | 26 | 130 | 5 | 25 | 2.32 | 0.34 | 0.37 | 0.045 | 1.09 | 1.69 | 201 |
| 431.88 | 2411.24 | 0.81 | 4 | 3.58 | 15 | 0.053 | 140 | 143 | 83 | 34 | 2.76 | 0.36 | 2 | 0.052 | 2.05 | 8.94 | 241 |
| 432.90 | 2411.89 | 0.39 | 3 | 3.4 | 10 | 0.077 | 121 | 133 | 93 | 33 | 1.73 | 0.34 | 4.24 | 0.061 | 2.33 | 6.41 | 230 |
| 433.60 | 2410.63 | 0.42 | 5 | 2.62 | 1 | 0.042 | 81 | 152 | 12 | 21 | 1.55 | 0.31 | 0.3 | 0.054 | 0.77 | 0.94 | 135 |
| 433.91 | 2411.37 | 0.8 | 4 | 3.49 | 2 | 0.025 | 120 | 88 | 31 | 33 | 3.17 | 0.33 | 0.72 | 0.062 | 0.85 | 1.48 | 231 |
| 434.07 | 2410.91 | 0.42 | 6 | 2.99 | 4 | 0.057 | 109 | 117 | 12 | 22 | 2.38 | 0.32 | 0.27 | 0.048 | 0.63 | 2.19 | 210 |
| 434.73 | 2410.27 | 0.37 | 4 | 3.11 | 9 | 0.045 | 171 | 132 | 12 | 21 | 1.93 | 0.31 | 0.12 | 0.042 | 0.69 | 1.98 | 180 |
| 434.09 | 2409.69 | 0.36 | 5 | 2.92 | 6 | 0.044 | 135 | 123 | 5 | 21 | 1.76 | 0.29 | 0.09 | 0.046 | 0.71 | 0.6 | 156 |
| 432.45 | 2414.37 | 1.86 | 46 | 1.82 | 11 | 0.059 | 96 | 278 | 13 | 22 | 11.58 | 0.42 | 0.35 | 0.017 | 0.78 | 3.05 | 150 |
| 432.29 | 2414.59 | 3.76 | 65 | 6.04 | 4 | 0.036 | 41 | 164 | 67 | 20 | 9.37 | 0.79 | 0.67 | 0.047 | 2.42 | 7.75 | 486 |
| 432.60 | 2414.75 | 2.63 | 83 | 2.09 | 22 | 0.049 | 112 | 208 | 30 | 17 | 26.06 | 0.54 | 0.64 | 0.033 | 1.18 | 3.09 | 201 |
| Element | AUC | Element | AUC | ||
|---|---|---|---|---|---|
| Au | 0.6024 | 2.8395 | B | 0.5901 | 2.4839 |
| Sn | 0.6065 | 2.9595 | Cu | 0.6311 | 3.6977 |
| Ag | 0.6762 | 5.1563 | Ba | 0.6147 | 3.2020 |
| Mn | 0.5573 | 1.5617 | Pb | 0.5778 | 2.1341 |
| Zn | 0.5450 | 1.2232 | As | 0.5655 | 1.7893 |
| Sb | 0.5942 | 2.6017 | Bi | 0.5901 | 2.4839 |
| Hg | 0.6393 | 3.9516 | Mo | 0.5983 | 2.7203 |
| W | 0.5778 | 2.1341 | F | 0.5696 | 1.9037 |
| Methods | Accuracy | Recall | F1-Score |
|---|---|---|---|
| SVM | 49.51 | 17.64 | 43.73 |
| KNN | 51.45 | 35.29 | 50.09 |
| RandomForest | 59.70 | 25.49 | 54.27 |
| Decisiontree | 58.73 | 39.21 | 57.03 |
| ResNet-18 | 56.79 | 24.50 | 53.21 |
| ShufflenetV2 | 57.45 | 17.64 | 48.24 |
| GoogLeNet | 61.81 | 31.09 | 56.51 |
| MobilenetV2 | 55.82 | 16.66 | 47.74 |
| Mnasnet | 59.22 | 17.64 | 50.61 |
| SCnet | 58.73 | 30.39 | 55.05 |
| Efficientnet-b0 | 57.28 | 23.52 | 51.70 |
| T2T-vit-14 | 57.76 | 39.21 | 56.19 |
| SNL | 59.70 | 35.29 | 57.07 |
| Ours | 69.09 | 40.33 | 65.00 |
| Target Network | Accuracy | Recall | F1-Score |
|---|---|---|---|
| 57.45 | 31.93 | 53.30 | |
| 65.45 | 41.17 | 62.08 | |
| 61.45 | 35.29 | 57.38 | |
| 70.18 | 47.05 | 67.34 | |
| 64.72 | 37.81 | 60.70 | |
| Voting | 69.09 | 40.33 | 65.00 |
| Methods | Accuracy | Recall | F1-Score |
|---|---|---|---|
| R-S-Mask | 64.72 | 29.41 | 55.43 |
| R-D-Convolution | 61.09 | 29.41 | 58.29 |
| R-Sk-Transfer | 62.54 | 30.25 | 56.83 |
| R-S-Distillation | 65.81 | 31.09 | 59.72 |
| Ours | 69.09 | 40.33 | 65.00 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Y.; Feng, Q.; Zhang, W.; Zhang, L.; Gao, L. Prediction of Prospecting Target Based on Selective Transfer Network. Minerals 2022, 12, 1112. https://doi.org/10.3390/min12091112
Huang Y, Feng Q, Zhang W, Zhang L, Gao L. Prediction of Prospecting Target Based on Selective Transfer Network. Minerals. 2022; 12(9):1112. https://doi.org/10.3390/min12091112
Chicago/Turabian StyleHuang, Yongjie, Quan Feng, Wanting Zhang, Li Zhang, and Le Gao. 2022. "Prediction of Prospecting Target Based on Selective Transfer Network" Minerals 12, no. 9: 1112. https://doi.org/10.3390/min12091112
APA StyleHuang, Y., Feng, Q., Zhang, W., Zhang, L., & Gao, L. (2022). Prediction of Prospecting Target Based on Selective Transfer Network. Minerals, 12(9), 1112. https://doi.org/10.3390/min12091112