Exploratory Analysis of Provenance Data Using R and the Provenance Package


Abstract
:1. Introduction



- Chemical data such as major and trace element concentrations are known as compositional data. Section 2 and Section 3 show that the statistical analysis of this class of data is fraught with difficulties. Fortunately, these are easily overcome by means of ‘Aitchison’s logratio transformation’. This transformation is a prerequisite to further statistical treatment, including Principal Component Analysis and compositional biplots of multi-sample datasets (Section 2 and Section 3).
- Categorical data such as bulk petrography and heavy mineral compositions are known as point-counting data. These are closely related to, but are fundamentally different from, compositional data. Compositional data consist of strictly positive real numbers that are subject to a constant-sum constraint and whose analytical precision can generally be ignored. In contrast, point-counting data contain integer values that may be greater than or equal to zero, and whose multinomial uncertainty is significant compared to the underlying compositional dispersion. Section 4 shows that both of these differences can be captured by a combination of logistic normal and multinomial statistics.
2. Ratio Data
- Create two vectors A and B, each containing 100 random numbers between 0 and 1:
![Minerals 09 00193 i004]() Intuitively, given that and , we would expect the same to be true for their means and . However, when we define two new variables for the (inverse) of the (reciprocal) mean ratios:
Intuitively, given that and , we would expect the same to be true for their means and . However, when we define two new variables for the (inverse) of the (reciprocal) mean ratios:![Minerals 09 00193 i005]() then we find that AB.mean≠inv.BA.mean. So and ! This is a counterintuitive and clearly wrong result.
then we find that AB.mean≠inv.BA.mean. So and ! This is a counterintuitive and clearly wrong result. - Calculate the standard deviation of and multiply this by two to obtain a ‘2-sigma’ confidence interval for the data:
![Minerals 09 00193 i006]() then we find that , which is nonsensical since A and B are both strictly positive numbers and their ratio is therefore not allowed to take negative values either. Herein lies the root of the problem. The sampling distribution of A/B is positively skewed, whereas the normal distribution is symmetric with tails ranging from to . Geologists frequently encounter strictly positive numbers. Time, for example, is a strictly positive quantity, expressed by geochronologists as ‘years before present’, where ‘present’ is equivalent to zero.
then we find that , which is nonsensical since A and B are both strictly positive numbers and their ratio is therefore not allowed to take negative values either. Herein lies the root of the problem. The sampling distribution of A/B is positively skewed, whereas the normal distribution is symmetric with tails ranging from to . Geologists frequently encounter strictly positive numbers. Time, for example, is a strictly positive quantity, expressed by geochronologists as ‘years before present’, where ‘present’ is equivalent to zero. - The problems caused by applying normal theory to strictly positive data can often be solved by simply taking logarithms [15]. The transformed data are then free to take on any value, including negative values, and this often allows normal theory to be applied with no problems. For example, when we calculate the (geometric) mean after taking the logarithm of the ratio data:
![Minerals 09 00193 i007]() then we find that AB.gmean = inv.BA.gmean, which is a far more sensible result.
then we find that AB.gmean = inv.BA.gmean, which is a far more sensible result. - Calculating the 2-sigma interval for the log-transformed data:
![Minerals 09 00193 i008]() also produces strictly positive values, as expected.
also produces strictly positive values, as expected.





3. Compositional Data
- Read a compositional dataset containing the Al2O3 – (CaO+Na2O) – K2O composition of a number of synthetic samples:
![Minerals 09 00193 i009]() where row.names=1 indicates that the sample names are contained in the first column; and the header=TRUE and check.names=FALSE arguments indicate that the first column of the input table contains the column headers, one of which contains a special character (‘+’).
where row.names=1 indicates that the sample names are contained in the first column; and the header=TRUE and check.names=FALSE arguments indicate that the first column of the input table contains the column headers, one of which contains a special character (‘+’). - Calculate the arithmetic mean composition and 95% confidence limits for each column of the dataset:
![Minerals 09 00193 i010]() and construct the 2-sigma confidence confidence bounds:
and construct the 2-sigma confidence confidence bounds:![Minerals 09 00193 i011]()
- In order to plot the compositional data on a ternary diagram, we will need to first load the provenance package into memory:
![Minerals 09 00193 i012]() Now plot the Al2O3, (CaO + Na2O) and K2O compositions on a ternary diagram alongside the arithmetic mean composition:
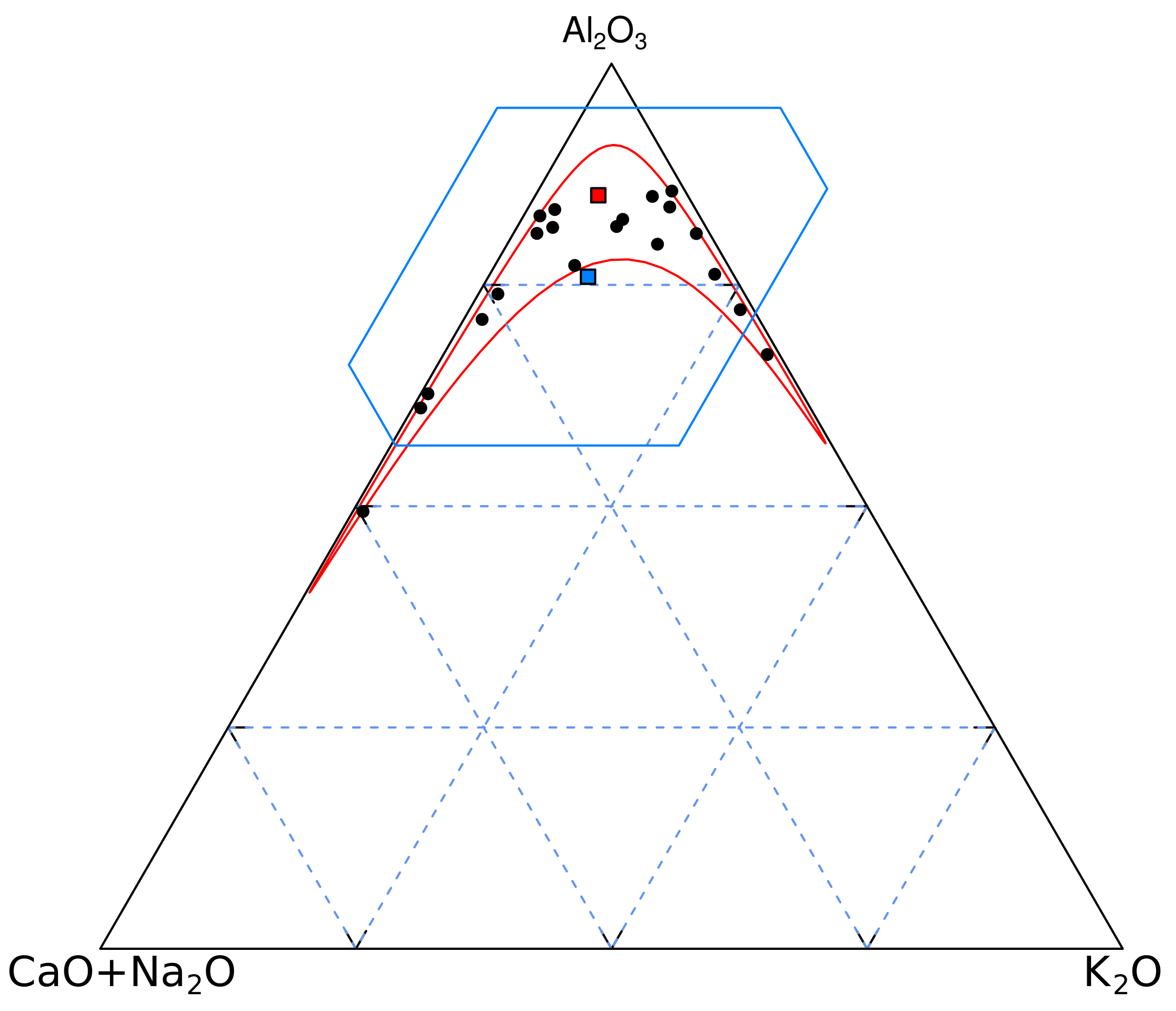
Now plot the Al2O3, (CaO + Na2O) and K2O compositions on a ternary diagram alongside the arithmetic mean composition:![Minerals 09 00193 i013]() where ternary(x) creates a ternary data ‘object’ from a variable x, and pch = 20 and pch = 22 produce filled circles and squares, respectively. Notice how the arithmetic mean plots outside the data cloud, and therefore fails to represent the compositional dataset (Figure 1).
where ternary(x) creates a ternary data ‘object’ from a variable x, and pch = 20 and pch = 22 produce filled circles and squares, respectively. Notice how the arithmetic mean plots outside the data cloud, and therefore fails to represent the compositional dataset (Figure 1). - Add a 2-sigma confidence polygon to this figure using the ternary.polygon() function that is provided in the auxiliary helper.R script (see Online Supplement):
![Minerals 09 00193 i014]() Note that the polygon partly plots outside the ternary diagram, into physically impossible negative data space. This nonsensical result is diagnostic of the dangers of applying ‘normal’ statistics to compositional data. It is similar to the negative limits for the ratio data in Section 2.
Note that the polygon partly plots outside the ternary diagram, into physically impossible negative data space. This nonsensical result is diagnostic of the dangers of applying ‘normal’ statistics to compositional data. It is similar to the negative limits for the ratio data in Section 2.






- 5.
- Compute the logratio mean composition and add it to the existing ternary diagram as a red square:
![Minerals 09 00193 i015]() This red square falls right inside the data cloud, an altogether more satisfying result than the arithmetic mean shown in blue (Figure 1).
This red square falls right inside the data cloud, an altogether more satisfying result than the arithmetic mean shown in blue (Figure 1). - 6.
- To add a compositional confidence contour, we must re-read ACNK.csv into memory using the read.compositional() function. This will tell the provenance package to treat the resulting variable as compositional data in subsequent operations:
![Minerals 09 00193 i016]() Adding the 95% confidence contour using provenance’s ternary.ellipse() function:
Adding the 95% confidence contour using provenance’s ternary.ellipse() function:![Minerals 09 00193 i017]() creates a 95% confidence ellipse in logratio space, and maps this back to the ternary diagram. This results in a ‘boomerang’-shaped contour that tightly hugs the compositional data whilst staying inside the boundaries of the ternary diagram (Figure 1).
creates a 95% confidence ellipse in logratio space, and maps this back to the ternary diagram. This results in a ‘boomerang’-shaped contour that tightly hugs the compositional data whilst staying inside the boundaries of the ternary diagram (Figure 1).



4. Point-Counting Data
- Download the auxiliary data file HM.csv from the Online Supplement. This file contains a heavy mineral dataset from the Namib Sand Sea [13]. It consists of 16 rows (one for each sample) and 15 columns (one for each mineral). Read these data into memory and tell provenance to treat it as point-counting data in all future operations:
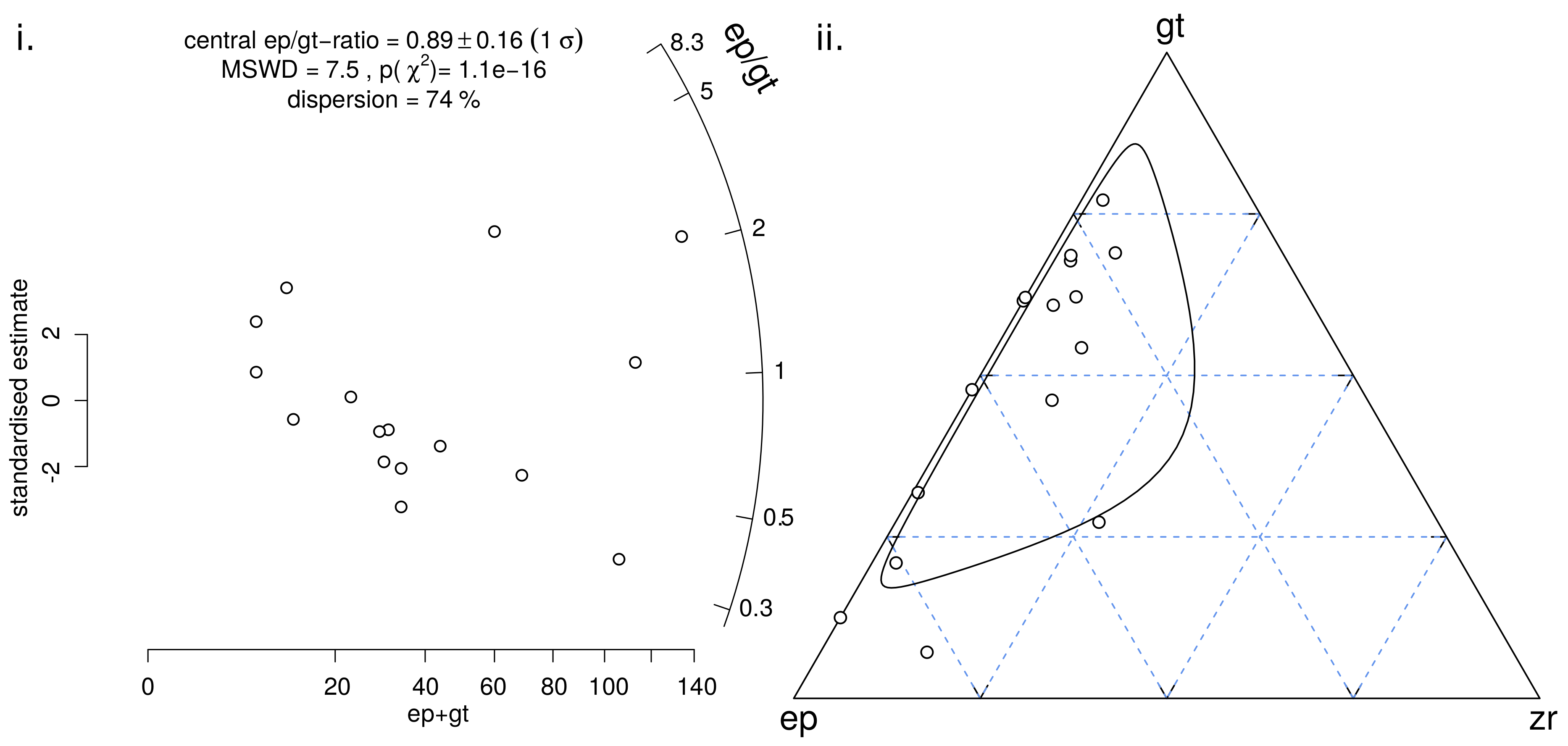
![Minerals 09 00193 i018]() Galbraith [28]’s radial plot is an effective way to visually assess the degree to which the random counting uncertainties account for the observed scatter of binary point-counting data. Applying this to the epidote/garnet-ratio of the heavy mineral data (Figure 2):
Galbraith [28]’s radial plot is an effective way to visually assess the degree to which the random counting uncertainties account for the observed scatter of binary point-counting data. Applying this to the epidote/garnet-ratio of the heavy mineral data (Figure 2):![Minerals 09 00193 i019]() Each circle on the resulting scatter plot represents a single sample in the HM dataset. Its epidote/garnet-ratio can be obtained by projecting the circle onto the circular scale. Thus, low and high ratios are found at negative and positive angles to the origin, respectively. The horizontal distance of each point from the origin is proportional to the total number of counts in each sample and, hence, to its precision. An (asymmetric) 95% confidence interval for the ep/gt-ratio of each sample can be obtained by projecting both ends of a 2-sigma confidence bar onto the circular scale.
Each circle on the resulting scatter plot represents a single sample in the HM dataset. Its epidote/garnet-ratio can be obtained by projecting the circle onto the circular scale. Thus, low and high ratios are found at negative and positive angles to the origin, respectively. The horizontal distance of each point from the origin is proportional to the total number of counts in each sample and, hence, to its precision. An (asymmetric) 95% confidence interval for the ep/gt-ratio of each sample can be obtained by projecting both ends of a 2-sigma confidence bar onto the circular scale.


- 2.
- The continuous mixtures from the previous section can be generalised from two to three or more dimensions. The following code snippet uses it to construct a 95% confidence contour for the ternary subcomposition of garnet, epidote and zircon (Figure 2ii). Note that this dataset contains four zero values, which would have rendered the logratio approach of Figure 1 unusable.
![Minerals 09 00193 i020]()
- 3.
- For datasets comprising more than three variables, the central composition can be simply obtained as follows:
![Minerals 09 00193 i021]() This produces a matrix with the proportions of each component; its standard error; the dispersion of the binary subcomposition formed by the component and the amalgamation of all remaining components; and the outcome of a chi-square test for homogeneity.
This produces a matrix with the proportions of each component; its standard error; the dispersion of the binary subcomposition formed by the component and the amalgamation of all remaining components; and the outcome of a chi-square test for homogeneity.


5. Distributional Data
- Download auxiliary data file DZ.csv from the Online Supplement. This file contains a detrital zircon U-Pb dataset from Namibia. It consists of 16 columns—one for each sample—each containing the single grain U-Pb ages of their respective sample. Let us load this file into memory using provenance’s read.distributional() function:
![Minerals 09 00193 i022]() DZ now contains an object of class distributional containing the zircon U-Pb ages of 16 Namibian sand samples. To view the names of these samples:
DZ now contains an object of class distributional containing the zircon U-Pb ages of 16 Namibian sand samples. To view the names of these samples:![Minerals 09 00193 i023]()
- One way to visualise the U-Pb age distributions is as Kernel Density Estimates. A KDE is defined as:where is the ‘kernel’ and is the ‘bandwidth’ [32,33]. The kernel can be any unimodal and symmetric shape (such as a box or a triangle), but is most often taken to be Gaussian (where is the mean and the standard deviation). The bandwidth can either be set manually, or selected automatically based on the number of data points and the distance between them. provenance implements the automatic bandwidth selection algorithm of Botev et al. [34] but a plethora of alternatives are available in the statistics literature. To plot all the samples as KDEs:
![Minerals 09 00193 i024]() where ncol specifies the number of columns over which the KDEs are divided.
where ncol specifies the number of columns over which the KDEs are divided. - Alternatively, the Cumulative Age Distribution (CAD) is a second way to show the data [35]. A CAD is a step function that sets out the rank order of the dates against their numerical value:where if * is true and if * is false. The main advantages of CADs over KDEs are that (i) they do not require any smoothing (i.e., there is no ‘bandwidth’ to choose), and (ii) they can superimpose multiple samples on the same plot. Plotting samples N1, N2 and N4 of the Namib dataset:
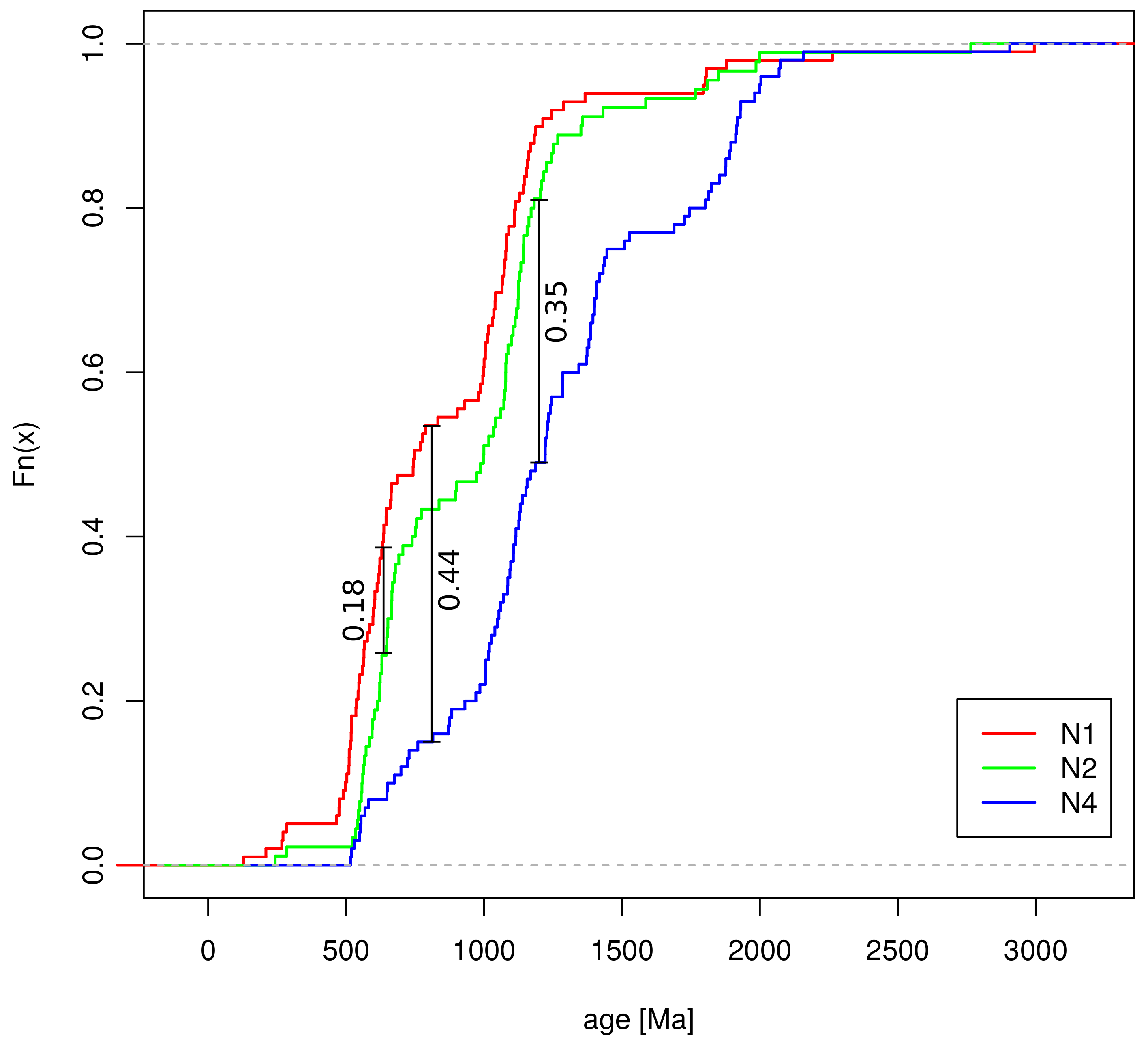
![Minerals 09 00193 i025]() we can see that (1) the CADs of samples N1 and N2 plot close together with steepest sections at 500 Ma and 1000 Ma, reflecting the prominence of those age components; (2) sample N4 is quite different from N1 and N2.
we can see that (1) the CADs of samples N1 and N2 plot close together with steepest sections at 500 Ma and 1000 Ma, reflecting the prominence of those age components; (2) sample N4 is quite different from N1 and N2. - We can quantify this difference using the Kolmogorov–Smirnov (KS) statistic [36,37,38], which represents the maximum vertical difference between two CADs:
![Minerals 09 00193 i026]() This shows that the KS-statistic between N1 and N2 is KS(N1,N2) = 0.18, whereas KS(N1,N4) = 0.44, and KS(N2,N4) = 0.35 (Figure 3). The KS statistic is a non-negative value that takes on values between zero (perfect overlap between two distributions) and one (no overlap between two distributions). It is symmetric because the KS statistic between any sample x and another sample y equals that between y and x. For example, KS(N1,N2) = 0.18 = KS(N2,N1). Finally, the KS-statistic obeys the triangle equality, which means that the dissimilarity between any two samples is always smaller than or equal to the sum of the dissimilarities between those two samples and a third. For example, KS(N1,N2) = 0.18 < KS(N1,N4) + KS(N2,N4) = 0.44 + 0.35 = 0.79. These three characteristics qualify the KS statistics as a metric, which makes it particularly suitable for Multidimensional Scaling (MDS) analysis (see Section 7). The KS statistic is just one of many dissimilarity measures for distributional data. However, not all these alternatives to the KS statistic fulfil the triangle inequality [38].
This shows that the KS-statistic between N1 and N2 is KS(N1,N2) = 0.18, whereas KS(N1,N4) = 0.44, and KS(N2,N4) = 0.35 (Figure 3). The KS statistic is a non-negative value that takes on values between zero (perfect overlap between two distributions) and one (no overlap between two distributions). It is symmetric because the KS statistic between any sample x and another sample y equals that between y and x. For example, KS(N1,N2) = 0.18 = KS(N2,N1). Finally, the KS-statistic obeys the triangle equality, which means that the dissimilarity between any two samples is always smaller than or equal to the sum of the dissimilarities between those two samples and a third. For example, KS(N1,N2) = 0.18 < KS(N1,N4) + KS(N2,N4) = 0.44 + 0.35 = 0.79. These three characteristics qualify the KS statistics as a metric, which makes it particularly suitable for Multidimensional Scaling (MDS) analysis (see Section 7). The KS statistic is just one of many dissimilarity measures for distributional data. However, not all these alternatives to the KS statistic fulfil the triangle inequality [38].





6. Principal Component Analysis (PCA)
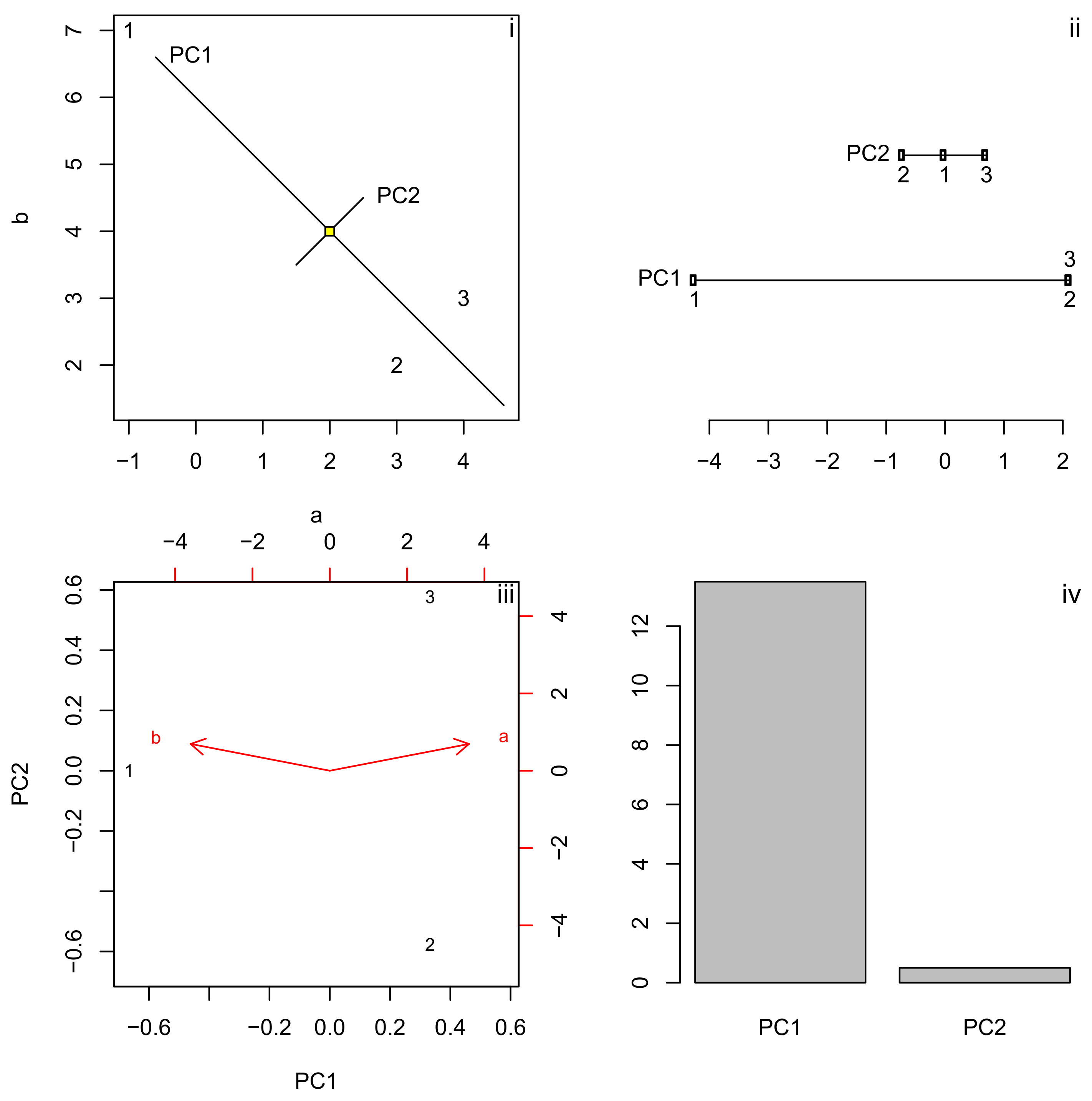
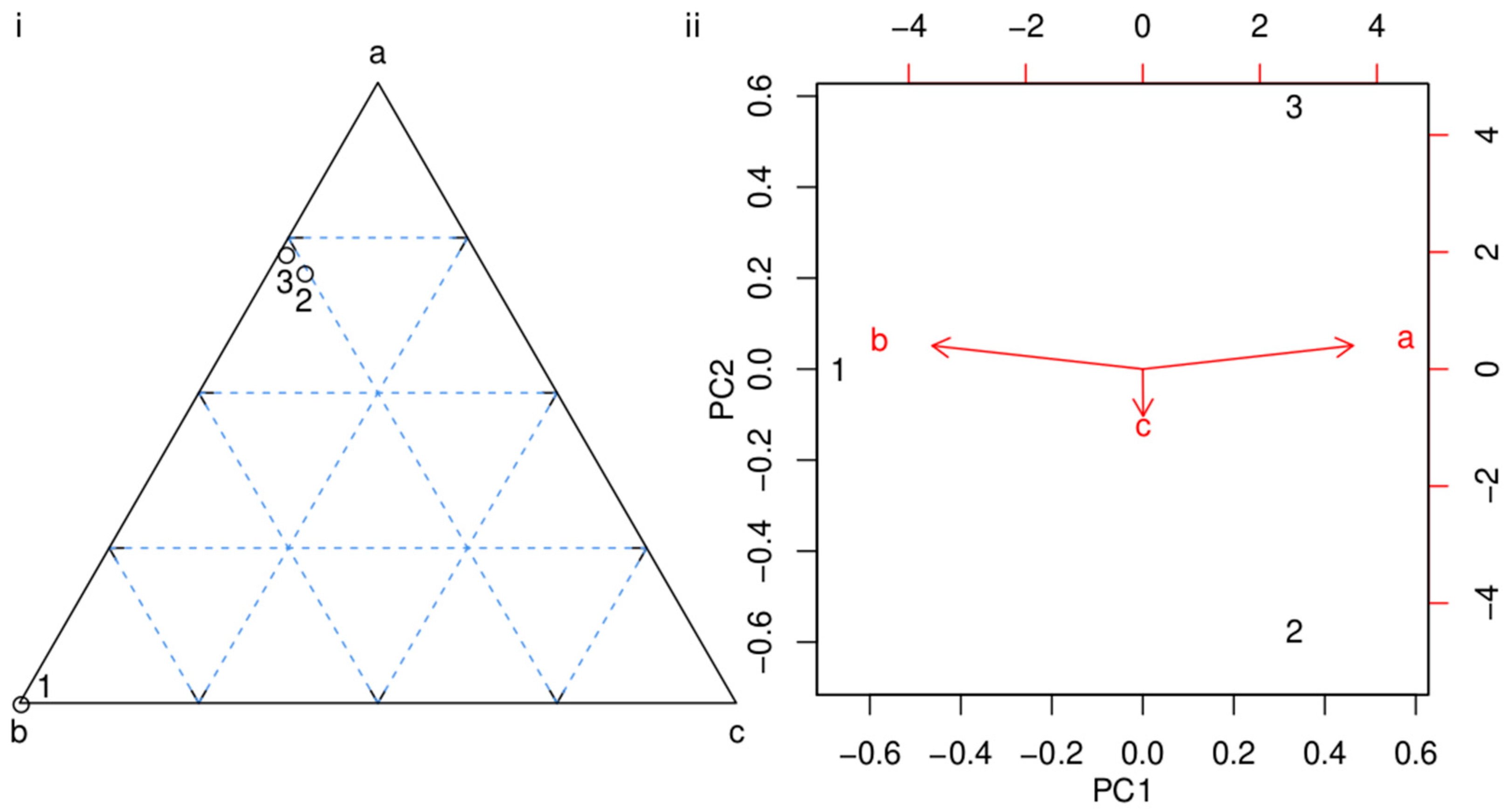
- Consider the following bivariate (a and b) dataset of three (1, 2 and 3) samples:Generating and plotting X in R:
![Minerals 09 00193 i027]() yields a diagram in which two of the three data points plot close together while the third one plots further away.
yields a diagram in which two of the three data points plot close together while the third one plots further away. - Imagine that you live in a one-dimensional world and cannot see the spatial distribution of the three points represented by X. Principal Component Analysis (PCA) is a statistical technique invented by Pearson [39] to represent multi- (e.g., two-) dimensional data in a lower- (e.g., one-) dimensional space whilst preserving the maximum amount of information (i.e., variance). This can be achieved by decomposing X into four matrices (C, S, V and D):where C is the centre (arithmetic mean) of the two data columns; S are the normalised scores; the diagonals of V correspond to the standard deviations of the two principal components; and D is a rotation matrix (the principal directions). S, V and D can be recombined to define two more matrices:where P is a matrix of transformed coordinates (the principal components or scores) and L contains the scaled eigenvectors or loadings. Figure 4i shows X as numbers on a scatterplot, C as a yellow square, and as a cross. Thus, the first principal direction (running from the upper left to the lower right) has been stretched by a factor of with respect to the second principal component, which runs perpendicular to it. The two principal components are shown separately as Figure 4ii, and their relative contribution to the total variance of the data as Figure 4iv. Figure 4 can be reproduced with the following R-code:
![Minerals 09 00193 i028]()
- Although the two-dimensional example is useful for illustrative purposes, the true value of PCA obviously lies in higher dimensional situations. As a second example, let us consider one of R’s built-in datasets. USArrests contains statistics (in arrests per 100,000 residents) for assault, murder, and rape in each of the 50 US states in 1973. Also given is the percentage of the population living in urban areas. Thus, USArrests is a four-column table that cannot readily be visualised on a two-dimensional surface. Applying PCA yields four principal components, the first two of which represent 62% and 25% of the total variance, respectively. Because the four columns of the input data are expressed in different units (arrests per 100,000 or percentage), it is necessary to scale the data to have unit variance before the analysis takes place:
![Minerals 09 00193 i029]() The resulting biplot shows that the loading vectors for Murder, Assault and Rape are all pointing in approximately the same direction (dominating the first principal component), perpendicular to UrbanPop (which dominates the second principal component). This tells us that crime and degree of urbanisation are not correlated in the United States.
The resulting biplot shows that the loading vectors for Murder, Assault and Rape are all pointing in approximately the same direction (dominating the first principal component), perpendicular to UrbanPop (which dominates the second principal component). This tells us that crime and degree of urbanisation are not correlated in the United States.



7. Multidimensional Scaling
- Multidimensional Scaling (MDS [40,41,42,43]) is a dimension-reducing technique that aims to extract two- (or higher) dimensional ‘maps’ from tables of pairwise distances between objects. This method is most easily illustrated with a geographical example. Consider, for example, the eurodist dataset that is built into R, and which gives the road distances (in km) between 21 cities in Europe (see ?eurodist for further details):
![Minerals 09 00193 i030]()
- The MDS configuration can be obtained by R’s built-in cmdscale() function
![Minerals 09 00193 i031]() Set up an empty plot with a 1:1 aspect ratio, and then label the MDS configuration with the city names:
Set up an empty plot with a 1:1 aspect ratio, and then label the MDS configuration with the city names:![Minerals 09 00193 i032]() Note that the map may be turned ‘upside down’. This reflects the rotation invariance of MDS configurations.
Note that the map may be turned ‘upside down’. This reflects the rotation invariance of MDS configurations. - R’s cmdscale() function implements so-called ‘classical’ MDS, which aims to fit the actual distances [42,43]. If these distances are Euclidean, then it can be shown that MDS is equivalent to PCA [44,45,46]. To demonstrate this equivalence, let us apply MDS to the data in Equation (7). First, run the first two lines of code from part 1 in Section 6. Calculating the Euclidean distances between the three samples produces a dissimilarity matrix d. For example, the distance between points 1 and 2 is . This value is stored in d[1,2]. In R:
![Minerals 09 00193 i033]() which produces:
which produces:
- Next, calculate the MDS configuration:
![Minerals 09 00193 i034]() Finally, plot the MDS configuration as a scatterplot of text labels:
Finally, plot the MDS configuration as a scatterplot of text labels:![Minerals 09 00193 i035]() which is identical to the PCA configuration of Figure 4iii apart from an arbitrary rotation or reflection.
which is identical to the PCA configuration of Figure 4iii apart from an arbitrary rotation or reflection. - An alternative implementation of MDS loosens the Euclidean distance assumption by fitting the relative distances between objects [40,41]. Let us apply this to the dataset of European city distances using the isoMDS function of the ‘Modern Applied Statistics with S’ (MASS) package [47]:
![Minerals 09 00193 i036]() To compute and plot the non-metric MDS configuration:
To compute and plot the non-metric MDS configuration: ![Minerals 09 00193 i037]() where conf3 is a list with two items: stress, which expresses the goodness-of-fit of the MDS configuration; and points, which contains the configuration. The ‘$’ operator is used to access any of these items.
where conf3 is a list with two items: stress, which expresses the goodness-of-fit of the MDS configuration; and points, which contains the configuration. The ‘$’ operator is used to access any of these items.








8. PCA of Compositional Data
- The following script applies compositional PCA to a dataset of major element compositions from Namibia (see Online Supplement) using base R:
![Minerals 09 00193 i038]()
- Alternatively, we can also do this more easily in provenance:
![Minerals 09 00193 i039]() where the read.compositional function reads the .csv file into an object of class compositional, thus ensuring that logratio statistics are used in all provenance functions (such as PCA) that accept compositional data as input. Also note that the provenance package overloads the plot function to generate a compositional biplot when applied to the output of the PCA function.
where the read.compositional function reads the .csv file into an object of class compositional, thus ensuring that logratio statistics are used in all provenance functions (such as PCA) that accept compositional data as input. Also note that the provenance package overloads the plot function to generate a compositional biplot when applied to the output of the PCA function.


9. Correspondence Analysis

10. MDS Analysis of Distributional Data

11. ‘Big’ Data
- The full Namib Sand Sea study that we have used as a test case for this tutorial comprises five datasets (see Online Supplement):
- (a)
- Major element concentrations (Major.csv, compositional data)
- (b)
- Trace element concentrations (Trace.csv, compositional data)
- (c)
- Bulk petrography (PT.csv, point-counting data)
- (d)
- Heavy mineral compositions (HM.csv, point-counting data)
- (e)
- Detrital zircon U-Pb data (DZ.csv, distributional data)
All these datasets can be visualised together in a single summary plot:![Minerals 09 00193 i042]() where Major, Trace, QFL and HM are shown as pie charts (the latter two with a different colour map than the former), and DZ as KDEs. Adding DZ instead of KDEs(DZ) would plot the U-Pb age distributions as histograms.
where Major, Trace, QFL and HM are shown as pie charts (the latter two with a different colour map than the former), and DZ as KDEs. Adding DZ instead of KDEs(DZ) would plot the U-Pb age distributions as histograms. - The entire Namib dataset comprises 16,125 measurements spanning five dimensions worth of compositional, distributional and point-counting information. This complex dataset, which may be rightfully described by the internet-era term of ‘Big Data’, is extremely difficult to interpret by mere visual inspection of the pie charts and KDEs. Applying MDS/PCA to each of the five individual datasets helps but presents the analyst with a multi-plot comparison problem. provenance implements two methods to address this issue [13]. The first of these is called ‘Procrustes Analysis’ [54]. Given a number of MDS configurations, this technique uses a combination of transformations (translation, rotation, scaling and reflection) to extract a ‘consensus view’ for all the data considered together:
![Minerals 09 00193 i043]()
- Alternatively, ‘3-way MDS’ is an extension of ‘ordinary’ (2-way) MDS that accepts 3-dimensional dissimilarity matrices as input. provenance includes the most common implementation of this class of algorithms, which is known as ‘INdividual Difference SCALing’ or INDSCAL [55,56]:
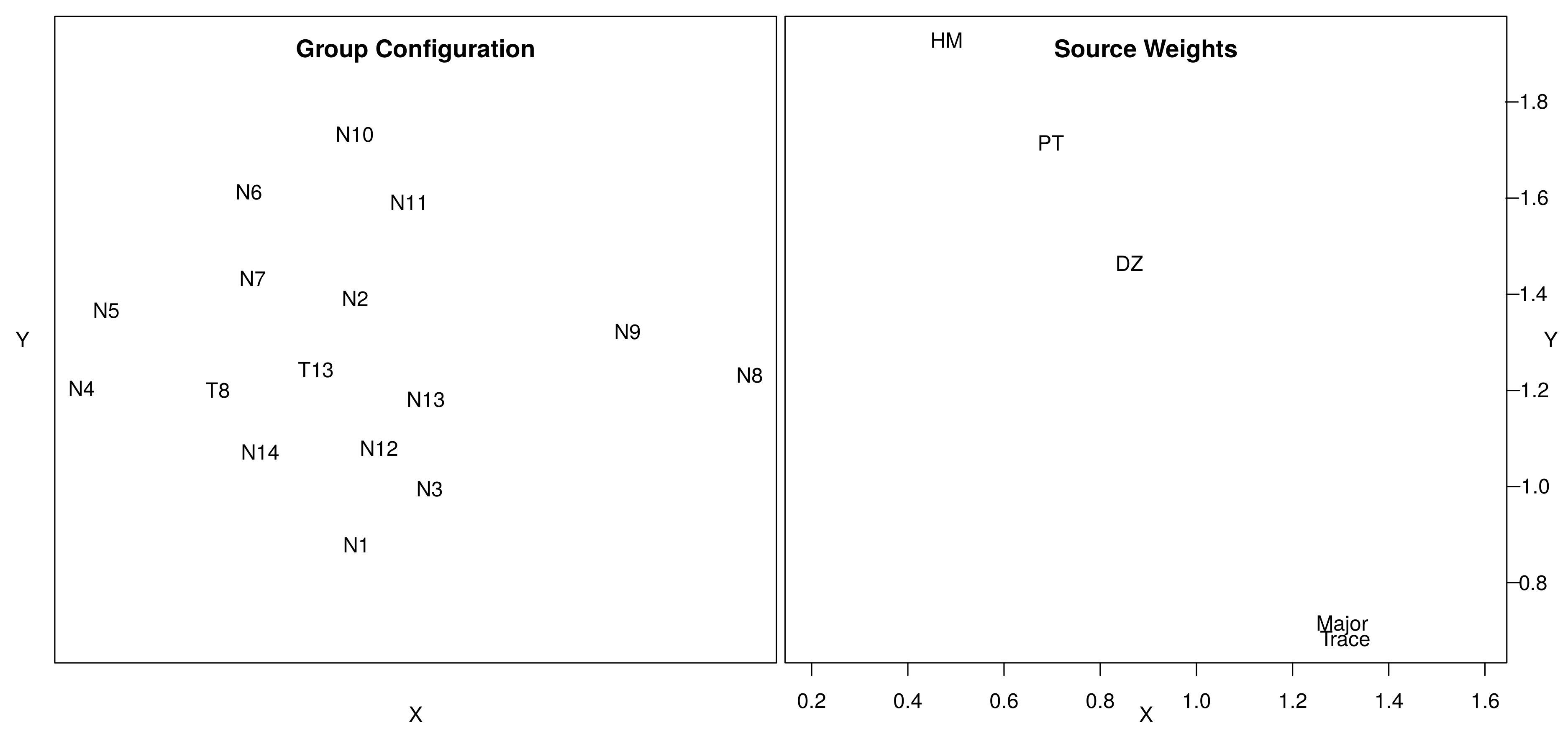
![Minerals 09 00193 i044]() This code produces two pieces of graphical output (Figure 6). The ‘group configuration’ represents the consensus view of all provenance proxies considered together. This looks very similar to the Procrustes configuration created by the previous code snippet. The second piece of graphical information displays not the samples but the provenance proxies. It shows the weights that each of the proxies attach to the horizontal and vertical axis of the group configuration.For example, the heavy mineral compositions of the Namib desert sands can be (approximately) described by stretching the group configuration vertically by a factor of 1.9, whilst shrinking it horizontally by a factor of 0.4. In contrast, the configurations of the major and trace element compositions for the same samples are obtained by shrinking the group configuration vertically by a factor 0.8, and stretching it horizontally by a factor of 1.3. Thus, by combining these weights with the group configuration yields five ‘private spaces’ that aim to fit each of the individual datasets.INDSCAL group configurations are not rotation-invariant, in contrast with the 2-way MDS configurations of Section 7. This gives geological meaning to the horizontal and vertical axes of the plot. For example, samples N1 and N10 plot along a vertical line on the group configuration, indicating that they have different heavy mineral compositions, but similar major and trace element compositions. On the other hand, samples N4 and N8 plot along a horizontal line, indicating that they have similar major and trace element compositions but contrasting heavy mineral compositions.Closer inspection of the weights reveals that the datasets obtained from fractions of specific densities (HM, PT and DZ) attach stronger weights to the vertical axis, whereas those that are determined on bulk sediment (Major and Trace) dominate the horizontal direction. Provenance proxies that use bulk sediment are more sensitive to winnowing effects than those that are based on density separates. This leads to the interpretation that the horizontal axis separates samples that have been affected by different degrees of hydraulic sorting, whereas the vertical direction separates samples that have different provenance.
This code produces two pieces of graphical output (Figure 6). The ‘group configuration’ represents the consensus view of all provenance proxies considered together. This looks very similar to the Procrustes configuration created by the previous code snippet. The second piece of graphical information displays not the samples but the provenance proxies. It shows the weights that each of the proxies attach to the horizontal and vertical axis of the group configuration.For example, the heavy mineral compositions of the Namib desert sands can be (approximately) described by stretching the group configuration vertically by a factor of 1.9, whilst shrinking it horizontally by a factor of 0.4. In contrast, the configurations of the major and trace element compositions for the same samples are obtained by shrinking the group configuration vertically by a factor 0.8, and stretching it horizontally by a factor of 1.3. Thus, by combining these weights with the group configuration yields five ‘private spaces’ that aim to fit each of the individual datasets.INDSCAL group configurations are not rotation-invariant, in contrast with the 2-way MDS configurations of Section 7. This gives geological meaning to the horizontal and vertical axes of the plot. For example, samples N1 and N10 plot along a vertical line on the group configuration, indicating that they have different heavy mineral compositions, but similar major and trace element compositions. On the other hand, samples N4 and N8 plot along a horizontal line, indicating that they have similar major and trace element compositions but contrasting heavy mineral compositions.Closer inspection of the weights reveals that the datasets obtained from fractions of specific densities (HM, PT and DZ) attach stronger weights to the vertical axis, whereas those that are determined on bulk sediment (Major and Trace) dominate the horizontal direction. Provenance proxies that use bulk sediment are more sensitive to winnowing effects than those that are based on density separates. This leads to the interpretation that the horizontal axis separates samples that have been affected by different degrees of hydraulic sorting, whereas the vertical direction separates samples that have different provenance.



12. Summary, Conclusions and Outlook
Supplementary Materials
Funding
Acknowledgments
Conflicts of Interest
Appendix A. An Introduction to R
- First, do some arithmetic:
![Minerals 09 00193 i045]() where the ‘>’ symbol marks the command prompt.
where the ‘>’ symbol marks the command prompt. - You can use the arrow to assign a value to a variable. Note that the arrow can point both ways:
![Minerals 09 00193 i046]()
- Create a sequence of values:
![Minerals 09 00193 i047]() Query the third value of the vector:
Query the third value of the vector:![Minerals 09 00193 i048]() Change the third value of the vector:
Change the third value of the vector:![Minerals 09 00193 i049]() Change the second and the third value of the vector:
Change the second and the third value of the vector:![Minerals 09 00193 i050]() Create a vector of 1, 2, 3, …, 10:
Create a vector of 1, 2, 3, …, 10:![Minerals 09 00193 i051]() Equivalently:
Equivalently:![Minerals 09 00193 i052]() Create a 10-element vector of twos:
Create a 10-element vector of twos:![Minerals 09 00193 i053]()
- Create a 2 × 4 matrix of ones:
![Minerals 09 00193 i054]() Change the third value in the first column of mymat to 3:
Change the third value in the first column of mymat to 3:![Minerals 09 00193 i055]() Change the entire second column of mymat to 2:
Change the entire second column of mymat to 2:![Minerals 09 00193 i056]() The transpose of mymat:
The transpose of mymat:![Minerals 09 00193 i057]() Element-wise multiplication (*) vs. matrix multiplication (%*%):
Element-wise multiplication (*) vs. matrix multiplication (%*%):![Minerals 09 00193 i058]()
- Lists are used to store more complex data objects:
![Minerals 09 00193 i059]()
- Plot the first against the second row of mymat:
![Minerals 09 00193 i060]() Draw lines between the points shown on the existing plot:
Draw lines between the points shown on the existing plot:![Minerals 09 00193 i061]() Create a new plot with red lines but no points:
Create a new plot with red lines but no points:![Minerals 09 00193 i062]() Use a 1:1 aspect ratio for the X- and Y-axis:
Use a 1:1 aspect ratio for the X- and Y-axis:![Minerals 09 00193 i063]()
- Save the currently active plot as a vector-editable .pdf file:
![Minerals 09 00193 i064]()
- To learn more about a function, type ‘help’ or ‘?’:
![Minerals 09 00193 i065]()
- It is also possible to define one’s own functions:
![Minerals 09 00193 i066]() Using the newly created function:
Using the newly created function:![Minerals 09 00193 i067]()
- Create some random (uniform) numbers:
![Minerals 09 00193 i068]()
- List all the variables in the current workspace:
![Minerals 09 00193 i069]() Remove all the variables in the current workspace:
Remove all the variables in the current workspace:![Minerals 09 00193 i070]() To get and set the working directory:
To get and set the working directory:![Minerals 09 00193 i071]()
- Collect the following commands in a file called ‘myscript.R’. Note that this text does not contain any ‘>’-symbols because it is not entered at the command prompt but in a separate text editor:
![Minerals 09 00193 i072]() This code can be run by going back to the command prompt (hence the ‘>’ in the next box) and typing:
This code can be run by going back to the command prompt (hence the ‘>’ in the next box) and typing:![Minerals 09 00193 i073]() This should result in the number being printed to the console. Note that everything that follows the ‘#’-symbol was ignored by R.
This should result in the number being printed to the console. Note that everything that follows the ‘#’-symbol was ignored by R. - Conditional statements. Add the following function to myscript.R:
![Minerals 09 00193 i074]() Save and run at the command prompt:
Save and run at the command prompt:![Minerals 09 00193 i075]()
- Loops. Add the following function to myscript.R:
![Minerals 09 00193 i076]() Save and run at the command prompt to calculate the first 20 numbers in the Fibonnaci series:
Save and run at the command prompt to calculate the first 20 numbers in the Fibonnaci series:![Minerals 09 00193 i077]()
- Arguably the greatest power of R is the availability of 10,000 packages that provide additional functionality. For example, the compositions package implements a number of statistical tools for compositional data analysis [21,22]. To install this package:
![Minerals 09 00193 i078]() Use the newly installed package to plot the built-in SkyeAFM dataset, which contains the Al2O3—FeO—MgO compositions of 23 aphyric lavas from the isle of Skye.
Use the newly installed package to plot the built-in SkyeAFM dataset, which contains the Al2O3—FeO—MgO compositions of 23 aphyric lavas from the isle of Skye.![Minerals 09 00193 i079]() Note that the plot() function has been overloaded for compositional data.
Note that the plot() function has been overloaded for compositional data.



































References
- Gerdes, A.; Zeh, A. Combined U–Pb and Hf isotope LA-(MC-) ICP-MS analyses of detrital zircons: Comparison with SHRIMP and new constraints for the provenance and age of an Armorican metasediment in Central Germany. Earth Planet. Sci. Lett. 2006, 249, 47–61. [Google Scholar] [CrossRef]
- Mazumder, R. Sediment provenance. In Sediment Provenance: Influence on Compositional Change From Source to Sink; Mazumder, R., Ed.; Elsevier: Amsterdam, The Netherlands, 2017; pp. 1–4. [Google Scholar]
- Morton, A.C. Geochemical studies of detrital heavy minerals and their application to provenance research. In Developments in Sedimentary Provenance Studies; Morton, A., Todd, S., Haughton, P.D.W., Eds.; Geological Society of London: London, UK, 1991; Volume 57, pp. 31–45. [Google Scholar]
- Rittner, M.; Vermeesch, P.; Carter, A.; Bird, A.; Stevens, T.; Garzanti, E.; Andò, S.; Vezzoli, G.; Dutt, R.; Xu, Z.; et al. The provenance of Taklamakan desert sand. Earth Planet. Sci. Lett. 2016, 437, 127–137. [Google Scholar] [CrossRef]
- Weltje, G.J.; von Eynatten, H. Quantitative provenance analysis of sediments: Review and outlook. Sediment. Geol. 2004, 171, 1–11. [Google Scholar] [CrossRef]
- DuToit, S.H.; Steyn, A.G.W.; Stumpf, R.H. Graphical Exploratory Data Analysis; Springer Science & Business Media: Berlin, Germany, 1986. [Google Scholar]
- Kenkel, N. On selecting an appropriate multivariate analysis. Can. J. Plant Sci. 2006, 86, 663–676. [Google Scholar] [CrossRef]
- Martinez, W.L.; Martinez, A.R.; Solka, J. Exploratory Data Analysis with MATLAB; Chapman and Hall/CRC: Boca Raton, FL, USA, 2017; ISBN 9781498776066. [Google Scholar]
- Tukey, J.W. Exploratory Data Analysis; Addison-Wesley: Boston, MA, USA, 1977; Volume 2, ISBN 978-0-201-07616-5. [Google Scholar]
- Bhatia, M.R. Plate tectonics and geochemical composition of sandstones. J. Geol. 1983, 91, 611–627. [Google Scholar] [CrossRef]
- Bhatia, M.R.; Crook, K.A. Trace element characteristics of graywackes and tectonic setting discrimination of sedimentary basins. Contrib. Mineral. Petrol. 1986, 92, 181–193. [Google Scholar] [CrossRef]
- Vermeesch, P.; Resentini, A.; Garzanti, E. An R package for statistical provenance analysis. Sediment. Geol. 2016, 336, 14–25. [Google Scholar] [CrossRef]
- Vermeesch, P.; Garzanti, E. Making geological sense of ‘Big Data’ in sedimentary provenance analysis. Chem. Geol. 2015, 409, 20–27. [Google Scholar] [CrossRef]
- Morton, A.C.; Hallsworth, C.R. Processes controlling the composition of heavy mineral assemblages in sandstones. Sediment. Geol. 1999, 124, 3–29. [Google Scholar] [CrossRef]
- Aitchison, J.; Brown, J.A. The Lognormal Distribution; Cambridge University Press: Cambridge, MA, USA, 1957; ISBN 0521040116. [Google Scholar]
- Garzanti, E. Petrographic classification of sand and sandstone. Earth-Sci. Rev. 2019. [Google Scholar] [CrossRef]
- Nesbitt, H.; Young, G.M. Formation and diagenesis of weathering profiles. J. Geol. 1989, 97, 129–147. [Google Scholar] [CrossRef]
- LeMaitre, R.W.; Streckeisen, A.; Zanettin, B.; LeBas, M.; Bonin, B.; Bateman, P. Igneous Rocks: A Classification and Glossary of Terms: Recommendations of the International Union of Geological Sciences Subcommission on the Systematics of Igneous Rocks; Cambridge University Press: Cambridge, MA, USA, 2002; ISBN 9780511535581. [Google Scholar]
- Aitchison, J. The Statistical Analysis of Compositional Data; Chapman and Hall: London, UK, 1986. [Google Scholar]
- Pawlowsky-Glahn, V.; Egozcue, J.J.; Tolosana-Delgado, R. Modeling and Analysis of Compositional Data; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Van den Boogaart, K.G.; Tolosana-Delgado, R. “Compositions”: A unified R package to analyze compositional data. Comput. Geosci. 2008, 34, 320–338. [Google Scholar] [CrossRef]
- Van den Boogaart, K.G.; Tolosana-Delgado, R. Analyzing Compositional Data with R; Springer: Berlin, Germany, 2013; Volume 122. [Google Scholar]
- Van der Plas, L.; Tobi, A. A chart for judging the reliability of point counting results. Am. J. Sci. 1965, 263, 87–90. [Google Scholar] [CrossRef]
- Weltje, G. Quantitative analysis of detrital modes: Statistically rigorous confidence regions in ternary diagrams and their use in sedimentary petrology. Earth-Sci. Rev. 2002, 57, 211–253. [Google Scholar] [CrossRef]
- Vermeesch, P. Statistical models for point-counting data. Earth Planet. Sci. Lett. 2018, 501, 1–7. [Google Scholar] [CrossRef]
- Bloemsma, M.R.; Weltje, G.J. Reduced-rank approximations to spectroscopic and compositional data: A universal framework based on log-ratios and counting statistics. Chemom. Intell. Lab. Syst. 2015, 142, 206–218. [Google Scholar] [CrossRef]
- Martín-Fernández, J.A.; Barceló-Vidal, C.; Pawlowsky-Glahn, V. Dealing with zeros and missing values in compositional data sets using nonparametric imputation. Math. Geol. 2003, 35, 253–278. [Google Scholar] [CrossRef]
- Galbraith, R. Graphical display of estimates having differing standard errors. Technometrics 1988, 30, 271–281. [Google Scholar] [CrossRef]
- Galbraith, R.F. The radial plot: Graphical assessment of spread in ages. Nuclear Tracks Radiat. Meas. 1990, 17, 207–214. [Google Scholar] [CrossRef]
- Fedo, C.; Sircombe, K.; Rainbird, R. Detrital zircon analysis of the sedimentary record. Rev. Mineral. Geochem. 2003, 53, 277–303. [Google Scholar] [CrossRef]
- Gehrels, G. Detrital zircon U-Pb geochronology: Current methods and new opportunities. In Tectonics of Sedimentary Basins: Recent Advances; Busby, C., Azor, A., Eds.; Wiley Online Library: Hoboken, NJ, USA, 2011; Chapter 2; pp. 45–62. [Google Scholar]
- Silverman, B. Density Estimation for Statistics and Data Analysis; Chapman and Hall: London, UK, 1986. [Google Scholar]
- Vermeesch, P. On the visualisation of detrital age distributions. Chem. Geol. 2012, 312–313, 190–194. [Google Scholar] [CrossRef]
- Botev, Z.I.; Grotowski, J.F.; Kroese, D.P. Kernel density estimation via diffusion. Ann. Stat. 2010, 38, 2916–2957. [Google Scholar] [CrossRef]
- Vermeesch, P. Quantitative geomorphology of the White Mountains (California) using detrital apatite fission track thermochronology. J. Geophys. Res. (Earth Surf.) 2007, 112, 3004. [Google Scholar] [CrossRef]
- DeGraaff-Surpless, K.; Mahoney, J.; Wooden, J.; McWilliams, M. Lithofacies control in detrital zircon provenance studies: Insights from the Cretaceous Methow basin, southern Canadian Cordillera. Geol. Soc. Am. Bull. 2003, 115, 899–915. [Google Scholar] [CrossRef]
- Feller, W. On the Kolmogorov-Smirnov limit theorems for empirical distributions. Ann. Math. Stat. 1948, 19, 177–189. [Google Scholar] [CrossRef]
- Vermeesch, P. Dissimilarity measures in detrital geochronology. Earth-Sci. Rev. 2018, 178, 310–321. [Google Scholar] [CrossRef]
- Pearson, K. On lines and planes of closest fit to systems of points in space. Lond. Edinburgh Dublin Philos. Mag. J. Sci. 1901, 2, 559–572. [Google Scholar] [CrossRef]
- Kruskal, J.B.; Wish, M. Multidimensional Scaling; Sage University Paper series on Quantitative Application in the Social Sciences; Sage Publications: Beverly Hills, CA, USA; London, UK, 1978; Volume 7–11. [Google Scholar]
- Shepard, R.N. The analysis of proximities: Multidimensional scaling with an unknown distance function. I. Psychometrika 1962, 27, 125–140. [Google Scholar] [CrossRef]
- Torgerson, W.S. Multidimensional scaling: I. Theory and method. Psychometrika 1952, 17, 401–419. [Google Scholar] [CrossRef]
- Young, G.; Householder, A.S. Discussion of a set of points in terms of their mutual distances. Psychometrika 1938, 3, 19–22. [Google Scholar] [CrossRef]
- Aitchison, J. Principal component analysis of compositional data. Biometrika 1983, 70, 57–65. [Google Scholar] [CrossRef]
- Cox, T.F.; Cox, M.A. Multidimensional Scaling; CRC Press: Boca Raton, FL, USA, 2000. [Google Scholar]
- Kenkel, N.C.; Orlóci, L. Applying metric and nonmetric multidimensional scaling to ecological studies: Some new results. Ecology 1986, 67, 919–928. [Google Scholar] [CrossRef]
- Ripley, B. Modern applied statistics with S. In Statistics and Computing, 4th ed.; Springer: New York, NY, USA, 2002. [Google Scholar]
- Vermeesch, P. Multi-sample comparison of detrital age distributions. Chem. Geol. 2013, 341, 140–146. [Google Scholar] [CrossRef]
- Greenacre, M.J. Theory and Applications of Correspondence Analysis; Academic Press: Cambridge, MA, USA, 1984. [Google Scholar]
- Stephan, T.; Kroner, U.; Romer, R.L. The pre-orogenic detrital zircon record of the peri-gondwanan crust. Geol. Mag. 2018, 156, 1–27. [Google Scholar] [CrossRef]
- Garzanti, E.; Andò, S. Heavy-mineral concentration in modern sands: Implications for provenance interpretation. In Heavy Minerals in Use, Developments in Sedimentology Series 58; Mange, M., Wright, D., Eds.; Elsevier: Amsterdam, The Netherlands, 2007; pp. 517–545. [Google Scholar]
- Malusà, M.G.; Garzanti, E. The sedimentology of detrital thermochronology. In Fission-Track Thermochronology and its Application to Geology; Springer: Berlin, Germany, 2019; pp. 123–143. [Google Scholar]
- Malusà, M.G.; Resentini, A.; Garzanti, E. Hydraulic sorting and mineral fertility bias in detrital geochronology. Gondwana Res. 2016, 31, 1–19. [Google Scholar] [CrossRef]
- Gower, J.C. Generalized procrustes analysis. Psychometrika 1975, 40, 33–51. [Google Scholar] [CrossRef]
- Carroll, J.D.; Chang, J.-J. Analysis of individual differences in multidimensional scaling via an N-way generalization of ‘Eckart-Young’ decomposition. Psychometrika 1970, 35, 283–319. [Google Scholar] [CrossRef]
- DeLeeuw, J.; Mair, P. Multidimensional scaling using majorization: The R package smacof. J. Stat. Softw. 2009, 31, 1–30. [Google Scholar]
- Chayes, F. On ratio correlation in petrography. J. Geol. 1949, 57, 239–254. [Google Scholar] [CrossRef]
- Chayes, F. On correlation between variables of constant sum. J. Geophys. Res. 1960, 65, 4185–4193. [Google Scholar] [CrossRef]
- Armstrong-Altrin, J.; Verma, S.P. Critical evaluation of six tectonic setting discrimination diagrams using geochemical data of Neogene sediments from known tectonic settings. Sediment. Geol. 2005, 177, 115–129. [Google Scholar] [CrossRef]
- Tolosana-Delgado, R.; von Eynatten, H.; Krippner, A.; Meinhold, G. A multivariate discrimination scheme of detrital garnet chemistry for use in sedimentary provenance analysis. Sediment. Geol. 2018, 375, 14–26. [Google Scholar] [CrossRef]
- Weltje, G.J. Quantitative models of sediment generation and provenance: State of the art and future developments. Sediment. Geol. 2012, 280, 4–20. [Google Scholar] [CrossRef]
- Allen, P.A. From landscapes into geological history. Nature 2008, 451, 274. [Google Scholar] [CrossRef]
- Garzanti, E.; Dinis, P.; Vermeesch, P.; Andò, S.; Hahn, A.; Huvi, J.; Limonta, M.; Padoan, M.; Resentini, A.; Rittner, M.; et al. Sedimentary processes controlling ultralong cells of littoral transport: Placer formation and termination of the Orange sand highway in southern Angola. Sedimentology 2018, 65, 431–460. [Google Scholar] [CrossRef]
- Garzanti, E.; Andò, S.; Vezzoli, G. Grain-size dependence of sediment composition and environmental bias in provenance studies. Earth Planet. Sci. Lett. 2009, 277, 422–432. [Google Scholar] [CrossRef]
- Malusà, M.G.; Carter, A.; Limoncelli, M.; Villa, I.M.; Garzanti, E. Bias in detrital zircon geochronology and thermochronometry. Chem. Geol. 2013, 359, 90–107. [Google Scholar] [CrossRef]
- Resentini, A.; Malusà, M.G.; Garzanti, E. MinSORTING: An Excel® worksheet for modelling mineral grain-size distribution in sediments, with application to detrital geochronology and provenance studies. Comput. Geosci. 2013, 59, 90–97. [Google Scholar] [CrossRef]
- Bloemsma, M.; Zabel, M.; Stuut, J.; Tjallingii, R.; Collins, J.; Weltje, G.J. Modelling the joint variability of grain size and chemical composition in sediments. Sediment. Geol. 2012, 280, 135–148. [Google Scholar] [CrossRef]
- Paatero, P.; Tapper, U. Positive matrix factorization: A non-negative factor model with optimal utilization of error estimates of data values. Environmetrics 1994, 5, 111–126. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Type | Dissimilarity Measure | Ordination Technique |
|---|---|---|
| compositional | Aitchison | Principal Component Analysis |
| point-counting | Chi-square | Correspondence Analysis |
| distributional | Kolmogorov–Smirnov | Multidimensional Scaling |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vermeesch, P. Exploratory Analysis of Provenance Data Using R and the Provenance Package. Minerals 2019, 9, 193. https://doi.org/10.3390/min9030193
Vermeesch P. Exploratory Analysis of Provenance Data Using R and the Provenance Package. Minerals. 2019; 9(3):193. https://doi.org/10.3390/min9030193
Chicago/Turabian StyleVermeesch, Pieter. 2019. "Exploratory Analysis of Provenance Data Using R and the Provenance Package" Minerals 9, no. 3: 193. https://doi.org/10.3390/min9030193
APA StyleVermeesch, P. (2019). Exploratory Analysis of Provenance Data Using R and the Provenance Package. Minerals, 9(3), 193. https://doi.org/10.3390/min9030193