1. Introduction
According to the relevant survey, the worldwide industrial sector will consume more than half of the total energy through 2040 [
1]. Against the background of the deteriorating ecological environment, environmental protection has become a serious issue for global manufacturing industries. Both economic benefits and environmental factors compel manufacturing managers to introduce some promising techniques to control energy consumption. In recent years, energy-saving scheduling has become a new research direction in the manufacturing field [
2]. In this problem, an optimal scheduling scheme is drawn up to reduce energy consumption from the production management perspective. With a slight extra financial burden on enterprises, the energy-saving scheduling attracts more attention in comparison with some traditional methods, such as purchasing energy-efficient equipment and designing new products, especially for some small-scale enterprises [
3].
In recent decades, the flexible job shop scheduling problem (FJSP) has attracted great attention from researchers due to its wide application and high complexity [
4]. Along with the promotion of green manufacturing, the energy-saving FJSP has gradually become a research hotspot in recent years [
5,
6,
7,
8,
9,
10,
11,
12,
13]. Like the classical FJSP, the previous work on the energy-saving FJSP assumes that operations in each job of the workshop must be processed following a predefined sequential precedence constraint, while jobs are independent from each other. However, for real-life complex products in many machining-assembly manufacturing systems, such as automobile engines, bicycles, etc., they are made up of multiple and multilevel jobs and characterized by Bills-Of-Materials (BOMs). This means that not only do sequential operation precedence constraints exist in each job, but hierarchical precedence constraints between different jobs also need to be considered simultaneously [
14]. In general, the variant of FJSP with hierarchical job precedence constraints is named the assembly job shop scheduling problem (AJSP). In the existing literature, AJSP can be classified into two types: two-stage AJSP and hybrid AJSP. In the two-stage AJSP, the machining and assembly operations are handled in the machining and assembly stages, respectively. The traditional FJSP is contained in the machining stage, which deals with the sequential precedence relationships between operations in each job. The assembly stage is attached to the machining stage to carry out the assembly operations once all jobs of the same BOM are completed or available after the machining stage [
15,
16,
17,
18,
19,
20]. This means that the line-structure operation precedence constraints and the tree-structure job precedence constraints are considered separately [
14], which leads to the splitting of the inherent parallel relationship between machining and assembly operations. Compared with the two-stage AJSP, the hybrid AJSP mixes machining operations and assembly operations. The mixture of hierarchical and sequential precedence constraints significantly increases the complexity and makes the hybrid AJSP problem quite challenging to solve. Zhu and Zhou [
14] proposed a multi-objective grey wolf optimization algorithm to solve the FJSP with job precedence constraints to minimize the makespan, the maximum machine workload, and the total machine workload simultaneously. Pathumnakul and Egbelu [
21] considered the AJSP problem in just-in-time manufacturing with the objective of optimizing the weighted earliness cost. A heuristic algorithm was developed by decomposing the problem into several single machine scheduling problems. Chen et al. [
22] studied a FJSP with hierarchical job precedence constraints. An actual weapons manufacturing factory was used as a case study to test the performance of the proposed dispatching rules. Na and Park [
23] considered a FJSP with multi-level job structures. A hybrid genetic algorithm was proposed to minimize the total tardiness of jobs. Jiang and Wang [
24] studied the AJSP in an aircraft-engine assembly workshop and proposed a genetic algorithm to solve the problem. Zou et al. [
25] proposed a level-based evolutionary algorithm to deal with the AJSP.
In the previous work about AJSP, researchers only concentrated on improving production efficiency, such as makespan, earliness, tardiness, workload, etc. In the current context of green manufacturing, some ecological metrics should be addressed in the energy-saving AJSP to meet the needs of sustainable development, such as energy consumption, noise pollution, CO2 emission, and carbon footprint. To the best of our knowledge, there is little literature focusing on the energy-saving AJSP. Ren et al. [
26] developed a mathematical model with the objective of improving production efficiency and minimizing energy consumption. Then, a heuristic PSO-GA algorithm was proposed to solve the problem. However, the considered scheduling problem is a two-stage AJSP rather than a hybrid AJSP. In addition, the transportation operations of jobs between machines are neglected to simplify the problem. In fact, production and transportation operations strongly interact with each other. On one hand, the machine selection of two successive operations in a job determines the transportation time. On the other hand, the transportation time can affect the waiting times of machines in terms of different operation sequences [
3]. Furthermore, a certain amount of energy will be generated in the transportation process. Thus, the job transportation times should also be considered to narrow the gap between the scheduling problem and the practical production.
Since the considered energy-saving AJSP is the extended version of the classical FJSP, the problem has the nature of NP-hard. It is well-known that it is difficult to obtain the optimal solutions to production scheduling problems using exact methods, even for small-scale problems. Therefore, intelligence algorithms are an effective alternative method due to the advantage of finding satisfactory solutions in an affordable time. In recent years, various intelligence algorithms have been successfully applied for solving the energy-saving scheduling problems, such as African buffalo optimization (ABO) [
2], genetic algorithm (GA) [
3,
5,
6], interior search algorithm (ISA) [
7], cat swarm optimization (CSO) [
8], imperialist competitive algorithm (ICA) [
9], pigeon-inspired optimization (PIO) [
10], bat algorithm (BA) [
11], particle swarm optimization (PSO) [
26], etc. However, the No Free Lunch (NFL) theorem [
27] implies that no algorithm performs best for all optimization problems, which means that a particular intelligence algorithm may attain promising solutions on a set of problems, but it may show poor performance on a different set of problems. This motivates researchers to explore new meta-heuristics for coping with various optimization problems. Thus, it is worthwhile to develop a fresh optimization algorithm for the energy-saving assembly job shop scheduling problem.
Inspired by the social behaviors of elephants in nature, elephant herding optimization (EHO) a novel swarm intelligence algorithm. Due to the impressive advantages of EHO, including easy implementation and good convergence, it has been successfully implemented for various optimization problems [
28,
29,
30,
31]. The primary difference with most of the existing meta-heuristics is that EHO employs a multi-population technique in the evolutionary process. In this technique, the elephant population is split into several sub-populations, based on which differentiated search strategies can be easily adopted among sub-populations and the collaboration and communication between sub-populations can be easily implemented. Therefore, the disadvantages of the premature convergence and the loss of population diversity can be well overcome, which are suffered by most of the existing meta-heuristic algorithms. This is the main reason to choose the EHO for solving the considered problem. Furthermore, the basic EHO algorithm was originally presented for continuous optimization problems. Thus, some problem-oriented modifications need to be carried out to make it suitable for the discrete scheduling problem. These reasons motivate the systematic investigation of the EHO for the considered energy-saving assembly job shop scheduling problem. The main works of this paper are summarized as follows: (1) A mathematical model is established for the energy-saving assembly job shop scheduling problem with transportation times; (2) a two-segment string is adopted to represent scheduling solutions, and an energy-saving decoding method is proposed to obtain active scheduling solutions; (3) a population initialization is utilized to obtain initial solutions with a certain quality and diversity; (4) two searching operators, namely the clan updating operator and separating operator, are designed to implement the improved elephant herding optimization algorithm (IEHO) following the characteristics of the problem.
The remainder of this paper is structured in the following manner.
Section 2 formulates the considered scheduling problem.
Section 3 shows the proposed IEHO algorithm in detail, including the encoding/decoding approach, population initialization, and discrete search operators.
Section 4 conducts extensive experiments to verify the performance of the proposed algorithm.
Section 5 reports the conclusion and future work.
2. Problem Description and Mathematical Model
2.1. Problem Description
The energy-saving AJSP can be described as follows: In a workshop, there are products to be manufactured by machines . Each product is composed of jobs corresponding to a tree-structure BOM. Each job is consisted by operations with a line-structure precedence relationship. For each operation , it must be processed on a machine chosen from its eligible machine set. The processing time of depends on the processing capacity of the selected machine. In addition, an operation consumes a different amount of energy when it is assigned to different machines. When a job is finished on a machine, it will be immediately conveyed to the next machine for machining or assembly. The transportation times between different machines are assumed to be known. The transfer also consumes an amount of energy during the transportation time. This problem attempts to assign operations to an appropriate machine and sequence them on each machine. The objective is to optimize the total energy consumption, which is composed by four types: processing energy consumption (PEC), idle energy consumption (IEC), transportation energy consumption (TEC), and auxiliary energy consumption (AEC). Some assumptions are considered as follows:
- (1)
All jobs are released and all machines are available at time zero.
- (2)
Each machine can perform one operation simultaneously.
- (3)
Each job can only be processed by one machine at a time.
- (4)
The processing of each operation cannot be interrupted.
- (5)
Each machine cannot be turned off until all jobs on it are completed.
- (6)
There are enough transfers for transportation operations between machines.
- (7)
The last operation of each product does not need to be transported after it is finished.
- (8)
Machine breakdown is negligible and setup times of machines are ignored.
2.2. Mathematical Model
Before describing the problem, some necessary symbols are shown as below.
: The index of products, ;
: The index of jobs, ;
: The index of operations, ;
: The index of machines, ;
: The th operation of job in product ;
: The immediate successor operation of ;
: The processing time of when it is processed on machine ;
: The objective function;
: Total energy consumption;
: Processing energy consumption coefficient of when it is processed on machine ;
: Idle energy consumption coefficient of machine when it is idle;
: Auxiliary energy consumption coefficient;
: Transportation energy consumption coefficient;
: Completion time of machine ;
: Start time of machine ;
: Workload of machine , the sum of the processing times of jobs on machine ;
: The final completion time (makespan);
: The transportation time between machine and machine for and ;
: Starting time of ;
: Completion time of ;
: A positive number big enough for Constraints (8) and (9);
: A binary variable, if is processed on machine , = 1; otherwise, =0;
: A binary variable, if
is processed before
adjacently on machine
,
= 1; otherwise,
= 0.
Equation (1) denotes the optimization objective of the problem. Constraint (2) denotes the processing energy consumption, which originates from the processing of operations on machines. Constraint (3) represents the idle energy consumed by machines when waiting for processing tasks. Constraint (4) gives the transportation energy consumption, which is generated by transfers for transporting jobs between machines. Constraint (5) defines the energy consumed by auxiliary equipment, such as lighting and air conditioning. Constraint (6) means that preemption is not allowed. Constraint (7) gives the precedence relationships between operations. Constraints (8) and (9) guarantee that each machine cannot process more than one operation at a time. When = 1, is processed before on machine . Accordingly, Constraint (8) holds. is set to ensure that Constraint (9) also holds. When = 0, is processed behind on machine . Accordingly, Constraint (9) holds. is used to let Constraint (8) also be met; Constraint (10) ensures that any operation can only choose one machine for its processing; Constraint (11) calculates the machine workload; Constraints (12) and (13) give the completion time and starting time of each machine; Constraint (14) represents that the start time of each operation is greater than zero; Constraints (15) and (16) state two 0–1 variables.
3. Overview of the Basic EHO Algorithm
The elephant herding optimization (EHO) algorithm was proposed by Wang et al. [
28] according to the herding behavior of elephants. In the EHO, two operators are used to formulate the herding behavior of elephants, i.e., the clan updating operator and separating operator. A brief introduction of the basic EHO algorithm is presented as follows.
3.1. Clan Updating Operator
In each clan, each elephant updates its position under the guidance of the fittest elephant corresponding to the natural matriarch. For the elephant
in clan
, the updating operation can be formulated by Equation (17).
where
is the current generation;
is the position of individual
in clan
;
is a scale factor which reflects the influence of the matriarch on
;
represents the matriarch’s position in clan
.
is a random number with the uniform distribution in
. In addition, for the matriarch, its position is updated by Equation (18).
where
is a scale factor in
;
is the center of the clan, which can be calculated by Equation (19);
is the number of elephants in clan
;
and
are the
th dimension of
and
, respectively.
3.2. Separating Operator
The separating operator simulates the leaving of the mature male elephants from their groups. This operator is conducted to the individual elephants with the worst fitness value, as shown in Equation (20).
where
and
are the lower and upper bounds of the elephant’s position.
represents the worst individual in clan
.
is a random number with a uniform distribution in
.
3.3. Elitism Strategy
Like some other intelligence algorithms, the elitism strategy is adopted to avoid the best individuals from being ruined during the evolutionary process. In the beginning of each generation, the best elephant individuals are saved, which are used to replace the worst elephant individuals at the end of every search process. This strategy guarantees that the later elephant population is not worse than the former one.
3.4. Steps of the Basic EHO
The detailed steps of the basic EHO algorithm are shown as below.
Step 1. Create the initial population at random, and determine the parameters of the algorithm, such as the population size , the number of saved best elephants , the maximum generation , the scale factors and , the number of clans , and the number of elephants in the th clan.
Step 2. Evaluate the fitness of each elephant.
Step 3. Sort all the elephants in the population according to the fitness values, save the best elephants, and then divide the population into clans.
Step 4. Conduct the clan updating operator following Equations (17) and (18).
Step 5. Conduct the separating operator following Equation (20).
Step 6. Combine the clans into one population, and evaluate the fitness of all new individuals.
Step 7. Conduct the elitism strategy to replace the worst individuals with the saved ones.
Step 8. Judge whether the maximum generation is met. If yes, go to Step 9, otherwise, go to Step 3.
Step 9. Output the results.
4. Implementation of the IEHO
4.1. Encoding Approach
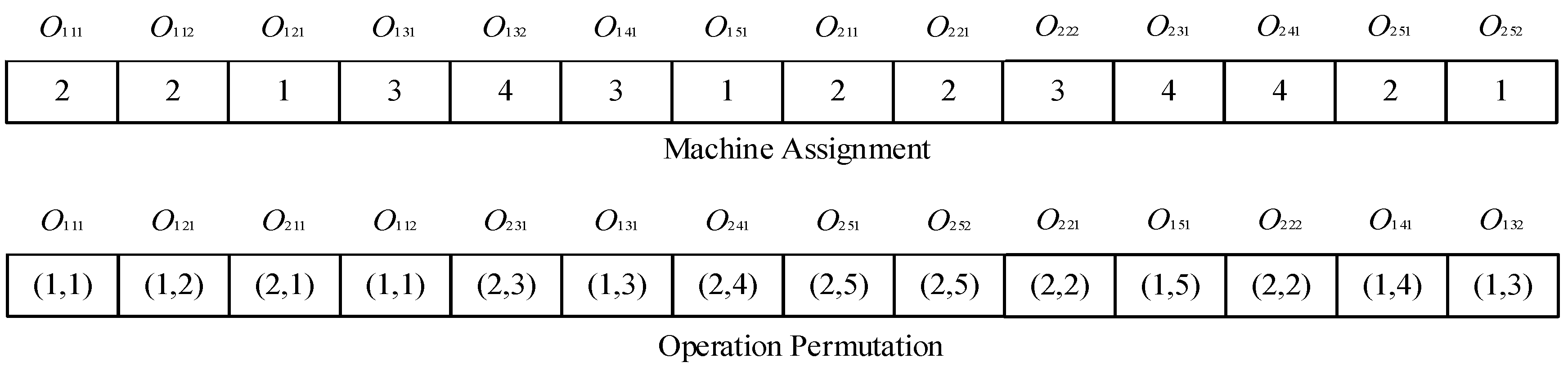
To implement the IEHO, the first step is to devise an encoding approach to represent the solution to the problem. Here, a two-segment string is applied to express each scheduling solution. The first segment stores the information of machine assignment (MA) for each operation, and the second gives the information of operation permutation (OP) on each assigned machine. The length of the MA segment is equal to that of the OP segment, which equals the total number of operations in the workshop, i.e., .
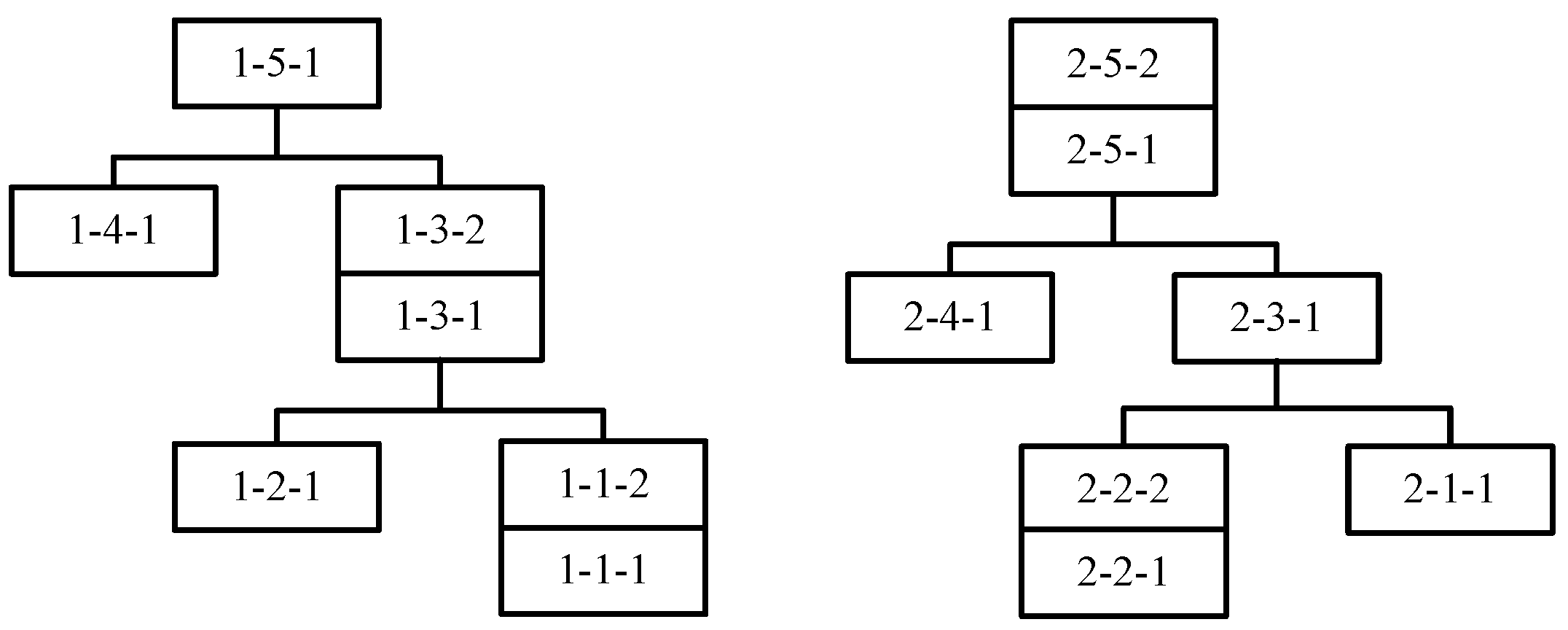
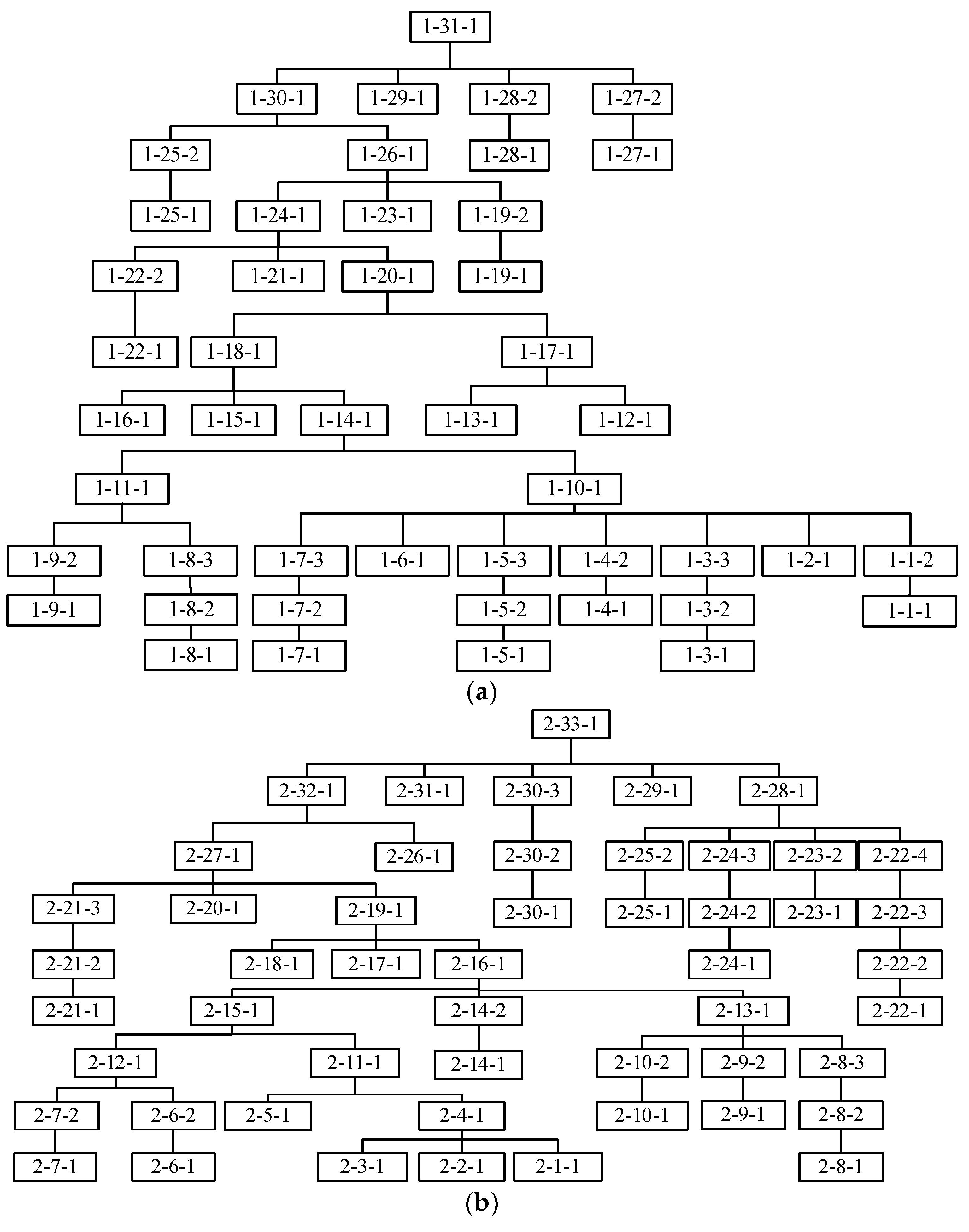
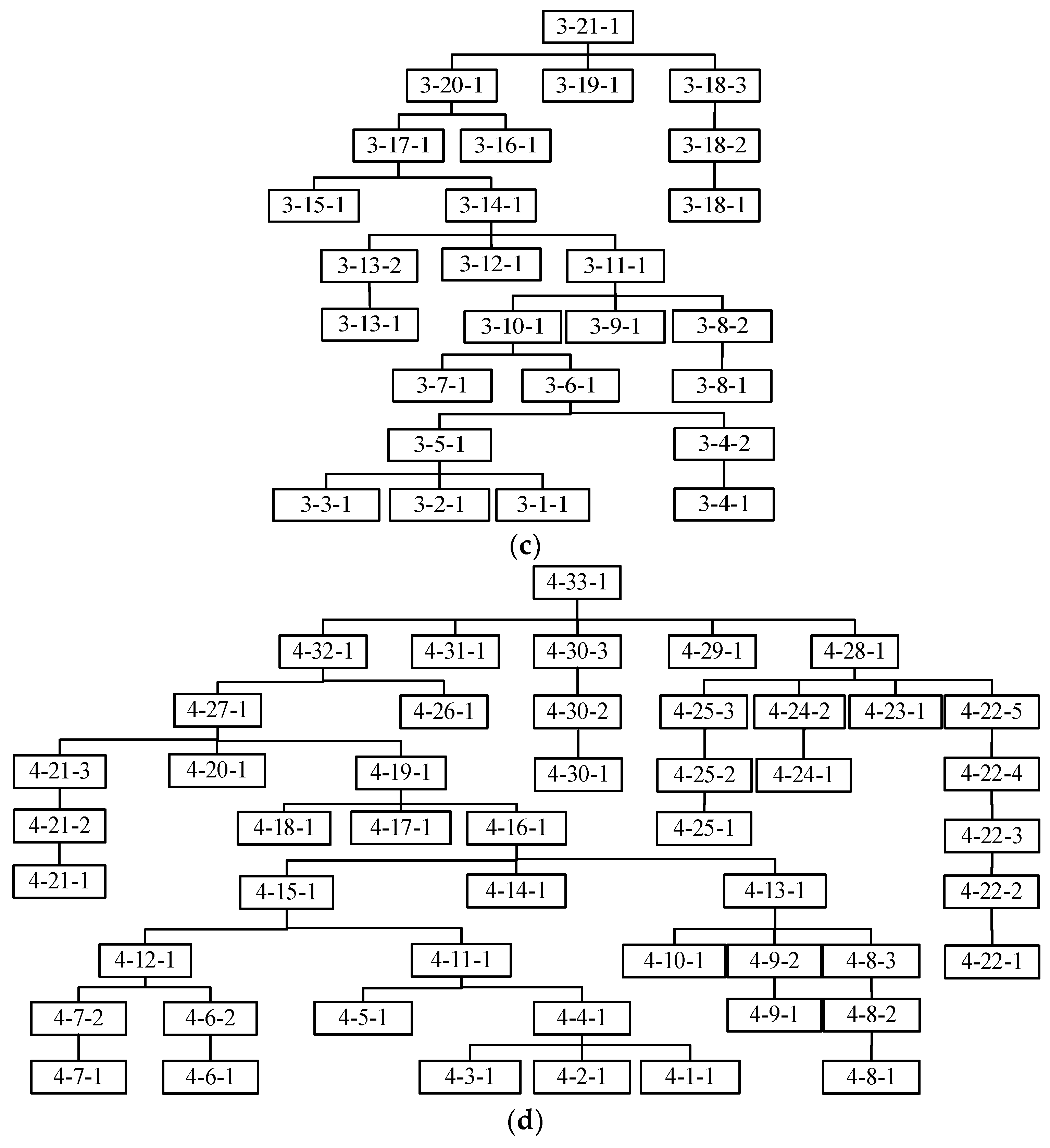
An example of two products is provided to describe this encoding scheme. The processing times and the tree-like structure of the two products are respectively presented in
Table 1 and
Figure 1. In
Table 1,
represents the
th product,
defines the
th job of the
th product, and
is the
th operation of the
th job in the
th product. In addition, ‘-’ means that the machine is unavailable for the operation. In
Figure 1, the numerical representation in each rectangle,
i-j-q, denotes the
qth operation of job
j in product
i. Based on the above information,
Figure 2 illustrates the encoding scheme of a scheduling solution. The MA segment stores the machine index following a fixed sequence of operations. Each machine is selected from the eligible machine set of the corresponding operation. The OP segment contains the codes of products and jobs. The elements with the same values belong to the same job of the product. The
th occurrence of the value refers to the
th operation of the job in the product. For example, the second ‘(1,3)’ represents the second operation of job 3 in product 1, and the first ‘(2,5)’ denotes the first operation of job 5 in product 2.
According to the encoding scheme, the elements in the first segment are always selected from the eligible machine set, which can ensure the feasibility of the machine assignment. However, the second segment is most likely unfeasible due to the existence of hierarchical job precedence constraints. For example,
and
is processed before
, which does not meet the job precedence constraints of
in
Figure 1. Here, a job precedence repair mechanism is devised to obtain a feasible operation permutation. The repair mechanism can be described below.
Step 1. Scan the OP segment of the candidate individual from left to right.
Step 2. For each operation, judge whether the current operation has precedent operations in product tree. If yes, pick out the current operation and all its precedent operations from the OP segment, keeping the positions of others unchanged.
Step 3. Relocate the current operation behind its precedent operations, and then place these elements back the OP segment following the new sequence.
After performing the repair mechanism, a feasible operation permutation is shown in
Figure 3.
4.2. Energy-Saving Decoding Approach
Due to job/operation precedence constraints and transportation times between machines, there exists some idle time slots between the adjacent operations on each machine. Hence, we propose an energy-saving decoding approach under the principle of the left-shift rule, which considers the makespan and energy consumption simultaneously. The left-shift rule states that if an operation can be inserted into one of the left idle time slots on the assigned machine as compactly as possible without violating the precedence constraints, the slot is first preferred. Based on this rule, the idle times of each machine are compacted, which leads to the reduction in the idle energy consumption. Meanwhile, the makespan may also be shortened, resulting in the reduction in auxiliary energy consumption. When executing the decoding approach, the OP segment of the candidate individual is traversed from left to right, and the left-shift rule is repeated for each operation until all operations in the current individual have been scheduled. For each operation, the detailed steps of the left-shift rule are shown below.
Step 1. Find out the assigned machine in the MA segment, and obtain the processing time of the current operation .
Step 2. Find out all the idle time slots in machine . For each slot, it can be represented by [,], where and are the start time and the end time of the slot, respectively.
Step 3. Traverse all the slots on machine from left to right, and try to insert the current operation into one slot as early as possible. When is met, the time slot is available for . If has precedent operations, , is the precedent operation set of , otherwise, .
Step 4. If all slots on machine are unavailable for , append it at the rear of machine .
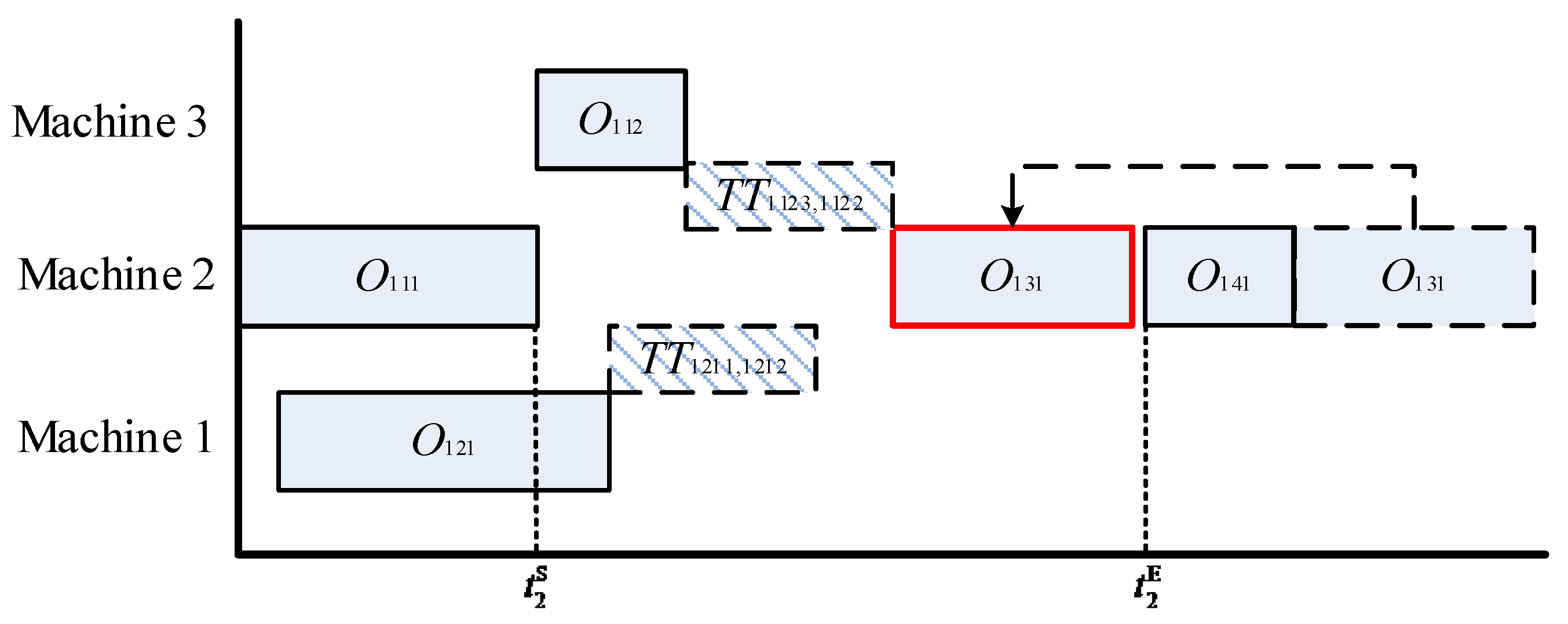
Figure 4 illustrates the left-shift rule, where four operations have been scheduled, i.e.,
. It is assumed that
is assigned to Machine 2 for processing. If the idle time slots are not considered,
will be placed behind
. When the condition
is met,
can be shifted to the left of
, by which the idle time slot can be compacted. This mechanism provides an opportunity for decreasing the makespan and the total energy consumption.
4.3. Population Initialization and Splitting
In order to obtain initial solutions with a certain quality and diversity, a population initialization approach is proposed to construct the MA and OP segments, which is described as below.
For the MA segment, the two assignment rules proposed by Pezzella et al. [
32], named
AssignmentRule1 and
AssignmentRule2, are used to select an appropriate machine for each operation. In these two rules, a matrix with the size of
is created to record the workload of each machine. For each operation, the machine assignment procedure includes finding the machine with the minimum workload, fixing that assignment, and then updating the workload of the selected machine by adding the processing time of the operation to all the entries in the columns where the selected machine resides. In this paper, by considering the optimization objective, the matrix is modified to record the processing energy of each machine. In addition, the random assignment rule (RAR) is also used to select a machine from the eligible machine set of each operation at random. Here, 10% of the initial population is generated by RAR, 10% by
AssignmentRule1, and 80% by
AssignmentRule2.
For the OP segment, we present three dispatching rules to generate the operation sequence on each machine, i.e., LLC + MWR, LLC + MOR, RSR. RSR denotes the random sequencing rule, by which the operations are randomly sequenced on each machine. The operation’s lowest level (LLC) means that the operation located on the lowest level of product three has the highest priority to be scheduled. For example, in
Figure 1,
are located on the lowest level of the product tree, which have the highest priority among all the operations,
have higher priority than
, etc. Most Work Remaining (MWR) defines that the operation belonging to the job with the most remaining processing time has higher priority to be selected. Most Operations Remaining (MOR) represents that the operation belonging to the job with the most remaining operations has a higher priority to be selected. LLC + MWR means that the LLC rule is first used to selected the operations with the lowest level, and the MWR rule is adopted to break a tie if more than one operation has the lowest level. LLC + MOR means that the LLC rule is first used to selected the operations with the lowest level, and the MOR rule is employed to break a tie. If one operation has been scheduled, the operation will be deleted from the product tree to update the current lowest level. Here, 40% operation sequences are generated by the LLC + MWR rule, 40% by the LLC + MOR rule, and 20% by the RSR rule.
In EHO, before undertaking the evolutionary process, the population is first split into a fixed number of clans, which can also be viewed as sub-populations. The existing research reported that the multi-population method is one of the most effective methods to maintain population diversity, by which solutions are scattered over the search space rather than focusing on a specific area [
33,
34]. The procedure of the population splitting is as follows: First, all solutions are sorted in descending order based on their fitness values. Then, the first elephant is assigned to the first clan, the second elephant is assigned to the second clan, the
th elephant goes to the
th clan, the
th elephant goes to the first clan, the
th elephant goes to the second clan, etc.
4.4. Clan Updating Operator
It is obvious that Equations (17) and (18) are not suitable for the discrete scheduling problem. Therefore, in this paper, the original clan updating operator is discretized based on the crossover operation. Before performing the crossover operation, a random number is generated with a uniform distribution in [0, 1]. If is smaller than the crossover rate , the crossover operator will be performed to obtain a new individual.
For the candidate individual in clan , the crossover operator is first performed between and . If the new individual is better than , is replaced by . Otherwise, the crossover operator is then performed between and the global best individual in the whole population to obtain . If is superior to , is replaced by , else is unchanged.
For the matriarch in each clan, the crossover operator is first performed between and to generate a new individual . Here, is the elephant individual whose fitness value is closest to the mean fitness of the clan . If the new individual is better than , . Otherwise, the crossover operator is then performed between and to obtain . If is superior to , is replaced by , else is unchanged.
In this work, two different crossover operations are adopted for operation permutation and machine assignment, respectively. For the machine assignment, the multi-point crossover (MPX) [
25] can be directly adopted. For the operation permutation, an operation is first randomly selected, which has precedent operations in product tree. For example, in
Figure 5,
is selected from the operation permutation. Then the precedent operations of
are
. When performing the crossover operation, all the precedent operations
of the selected operation in the two parent individuals are swapped to obtain two child individuals. The better one is selected as the new individual of the clan updating operator.
4.5. Separating Operator
In the basic EHO algorithm, the worst elephant in each clan will be randomly replaced, as expressed in Equation (20). However, the original separation operator ignores the evaluation of the newborn calf, by which an inferior solution might join the clan. Therefore, a new separation method proposed by Li et al. [
35] is employed in this section. In this method, if it is better than the original one, it can be accepted. Otherwise, a probability value
is employed to determine whether the original elephant should be replaced. To this end, a random number
is randomly generated. If
is greater than
, the original elephant will be replaced.
To implement the separating strategy, two types of neighborhood structures are proposed for the operation permutation and the machine assignment, respectively. When performing the separating operator, a neighborhood structure is randomly selected from each of Type 1 and Type 2 to acquire a new individual.
Type 1: Neighborhood structures for machine assignment
NMS1: Randomly select an operation, and then a different machine is randomly selected from the eligible machine set of the selected operation to replace the original one.
NMS2: Randomly select an operation, and then the machine with the shortest processing time is selected from the eligible machine set of the selected operation to replace the original one.
NMS3: Randomly select an operation, and then the machine with the smallest processing energy consumption coefficient is selected from the eligible machine set of the selected operation to replace the original one.
Type 2: Neighborhood structures for operation permutation
NOP1: Randomly select two elements with different values in the OP segment, and then swap the positions of the selected elements. Perform the repair mechanism to ensure the feasibility of the scheduling solution.
NOP2: Randomly select two elements with different values in the OP segment, and then insert the second element to the front of the first one. Perform the repair mechanism to ensure the feasibility of the scheduling solution.
NOP3: Randomly select two elements with different values in the OP segment, and then invert the original order of the elements between the selected two elements. Perform the repair mechanism to ensure the feasibility of the scheduling solution.
4.6. Steps of the IEHO
The steps of the IEHO algorithm can be summarized as below.
Step 1. Generate the initial population following the method in
Section 3.4, and set some related parameters, such as the population size
, the number of clans
, the number of the saved elephants
, the maximum generation
, the crossover rate
and the acceptance probability
.
Step 2. Evaluate the fitness of each elephant individual.
Step 3. Sort all the individuals in the population according to the fitness, save the best elephants, and then split the population into clans with the same size.
Step 4. Perform the clan updating operation in
Section 4.4.
Step 5. Perform the separating operation based on the neighborhood structure in
Section 4.5.
Step 6. Merge the individuals of each clan into the population, and evaluate the fitness of all individuals.
Step 7. Perform the elitism strategy to replace the worst individuals with the saved ones.
Step 8. Judge whether the maximum iteration number is met. If yes, go to Step 9, otherwise, go to Step 3.
Step 9. Terminate the algorithm.
4.7. Time Complexity
The time complexity of the IEHO algorithm is analyzed following the above steps. Obviously, evaluate the fitness of each elephant individual in Step 2 with time complexity . Sort all the individuals in the population in Step 3 with time complexity . In Step 4, execute the clan-updating operator for all clans with time complexity . In Step 5, perform the separating operator for all clans with time complexity . In Step 6, evaluate the fitness of all individuals with time complexity . Perform the elitism strategy to replace the worst individuals in Step 7 with time complexity . After omitting the low-order terms, the total time complexity of the IEHO algorithm is , which is only related to , , and . is the total number of operations in the workshop.
6. Conclusions and Future Work
Energy-saving scheduling has attracted more and more attention in recent years and has become a hotspot in the manufacturing area. In this paper, an energy-saving assembly job shop scheduling problem with transportation times is investigated in a manner that is close to actual production. A mathematical model is established with the criteria to minimize the total energy consumption of the workshop. An improved elephant herding optimization algorithm, named IEHO, is developed according to the characteristics of the problem. A number of experiments are conducted to test the performance of the IEHO algorithm. The comparison results demonstrate that IEHO is very competitive in solving the energy-saving assembly job shop scheduling problem with transportation times.
In this paper, only single-objective static scheduling is investigated, thereby restricting the implementation of IEHO for multi-objective dynamic scheduling problems. In the next work, some more practical factors will be considered, such as multi-objective optimization, dynamic/uncertain manufacturing environments, transportation constraints, worker flexibility, deterioration/learning effect, time-of-use electricity policy, and renewable resources. Moreover, the left-shift decoding method in IEHO concentrates more on the improvement in the solution quality, which leads to an increase in the computational time. Therefore, we will further develop more efficient search strategies, improve the computational efficiency of the algorithm, and implement an effective combination of EHO with other algorithms.













{kind=link}
{kind=link}
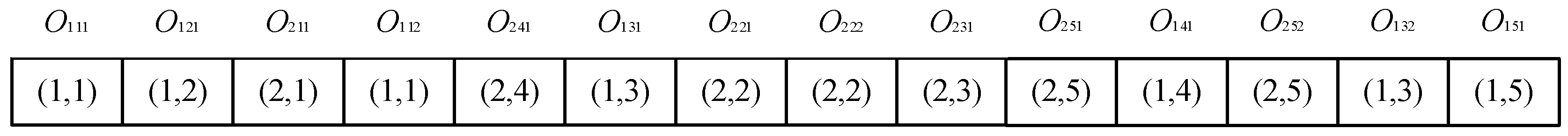{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}