
Estimation of Uncertainty for Technology Evaluation Factors via Bayesian Neural Networks


Abstract
:1. Introduction
- Technology evaluation that can predict technology excellence is a bridge that connects various types of IP-R&D and firms.
- The technology value may fluctuate depending on the time of evaluation.
- The uncertainty of technology value can be actively reflected in the management and investment of firms.
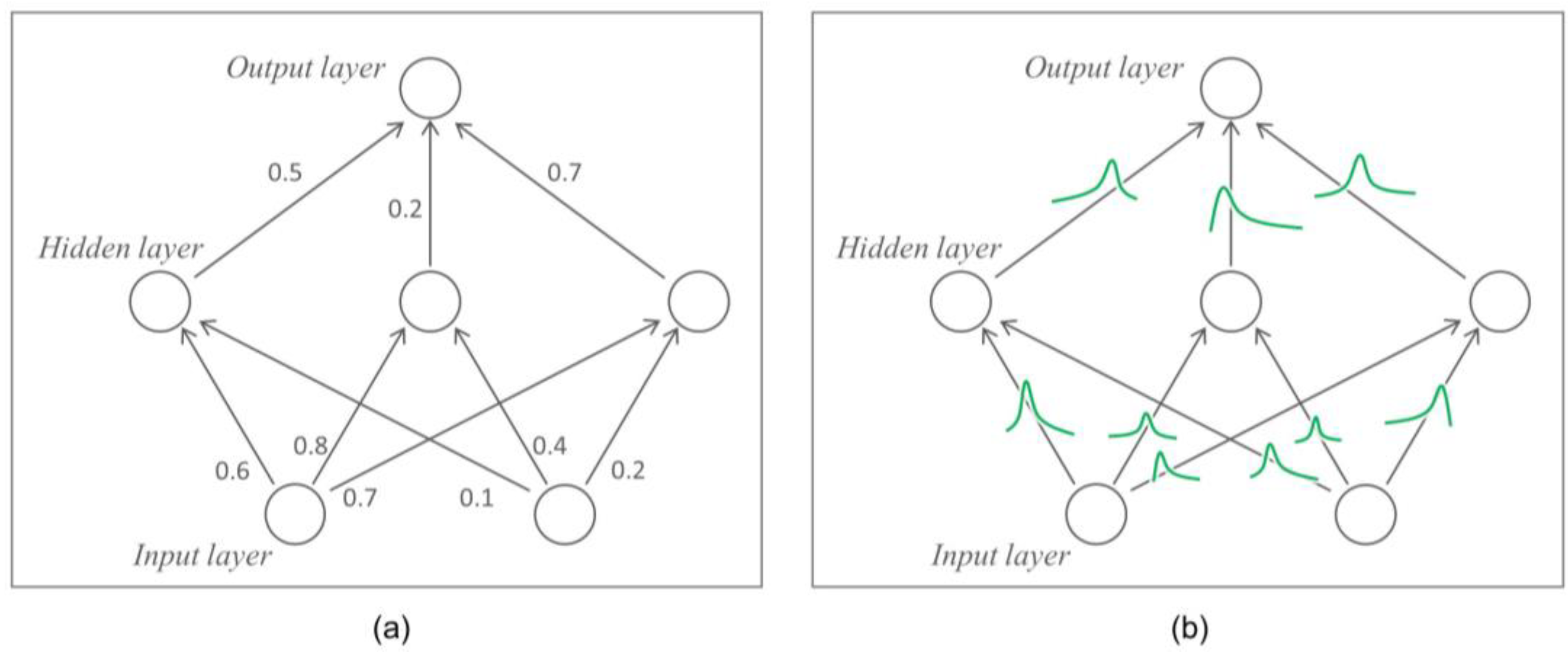
- Jun (2022) and Uhm and Jun (2022) pointed out the intractable limitations of the Bayesian approach as the volume of big data gradually increased [22,23]. To improve these limitations, we applied Flipout as a tractable and appropriate approach to big data. Flipout helped BNN learn each layer independently.
- Lee and Park (2022) emphasized that identifying factors influencing IP-R&D can prevent the absence of validity in patent analysis [24]. Thus, we measured the influence on the technology value for each evaluation factor. To this end, the difference between the mean and variance of the value according to the factor was statistically tested.
- Choi et al. (2023) argued that for sustainable growth in an uncertain business environment, it is necessary to cope with the rapidly changing flow of technology [25]. Therefore, we measured the uncertainty of technology evaluation over time. In addition, we verified the trend and presented empirical evidence for the timeliness and objectivity of technology evaluation.
2. Related Works
3. Background
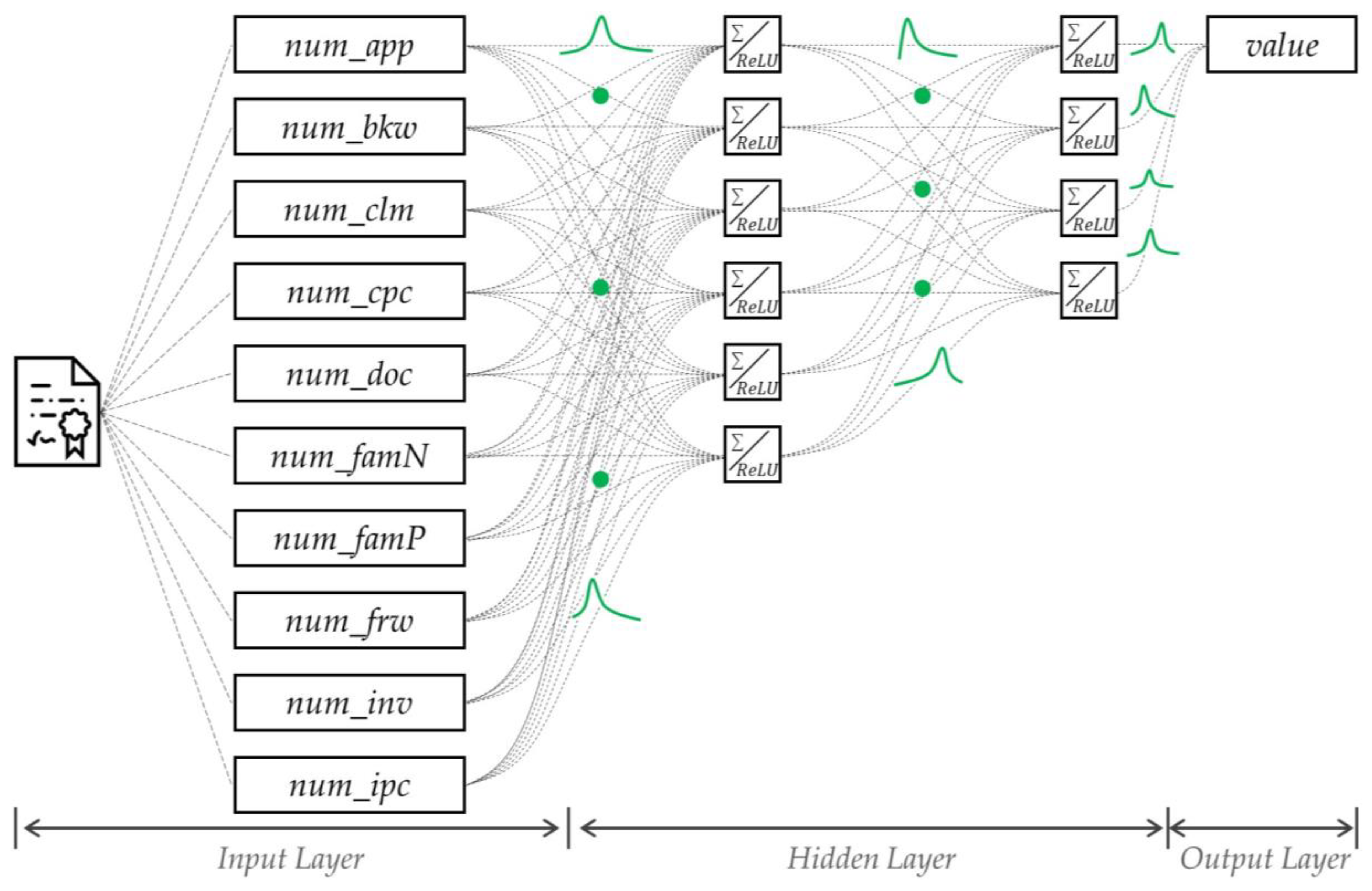
4. Proposed Method
5. Experimental Results
5.1. Experimental Setup
5.2. Statistical Test for Research Hypothesis
5.2.1. Statistical Test for Hypothesis 1
5.2.2. Statistical Test for Hypothesis 2
5.2.3. Statistical Test for Hypothesis 3
5.2.4. Statistical Test for Hypothesis 4
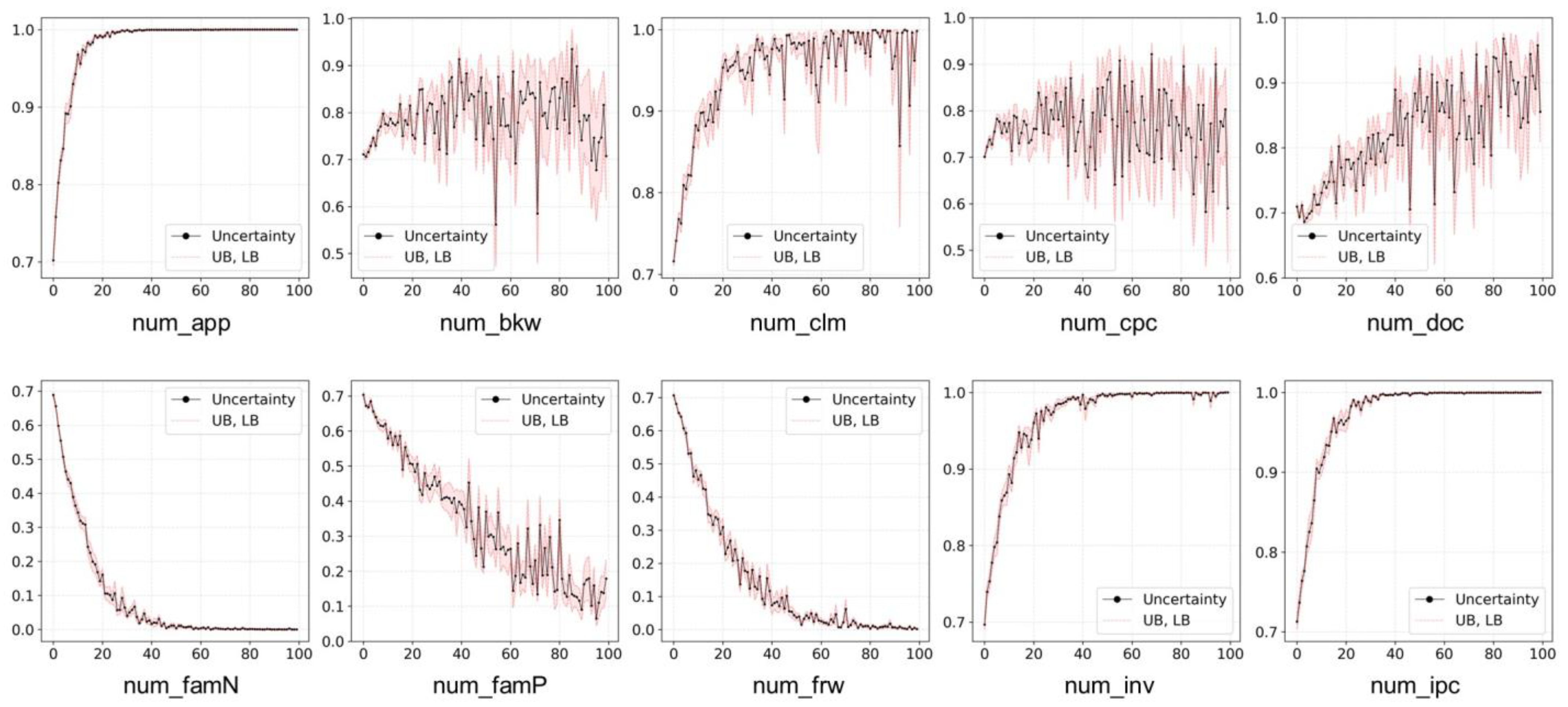
5.3. Factor Ablation Trial
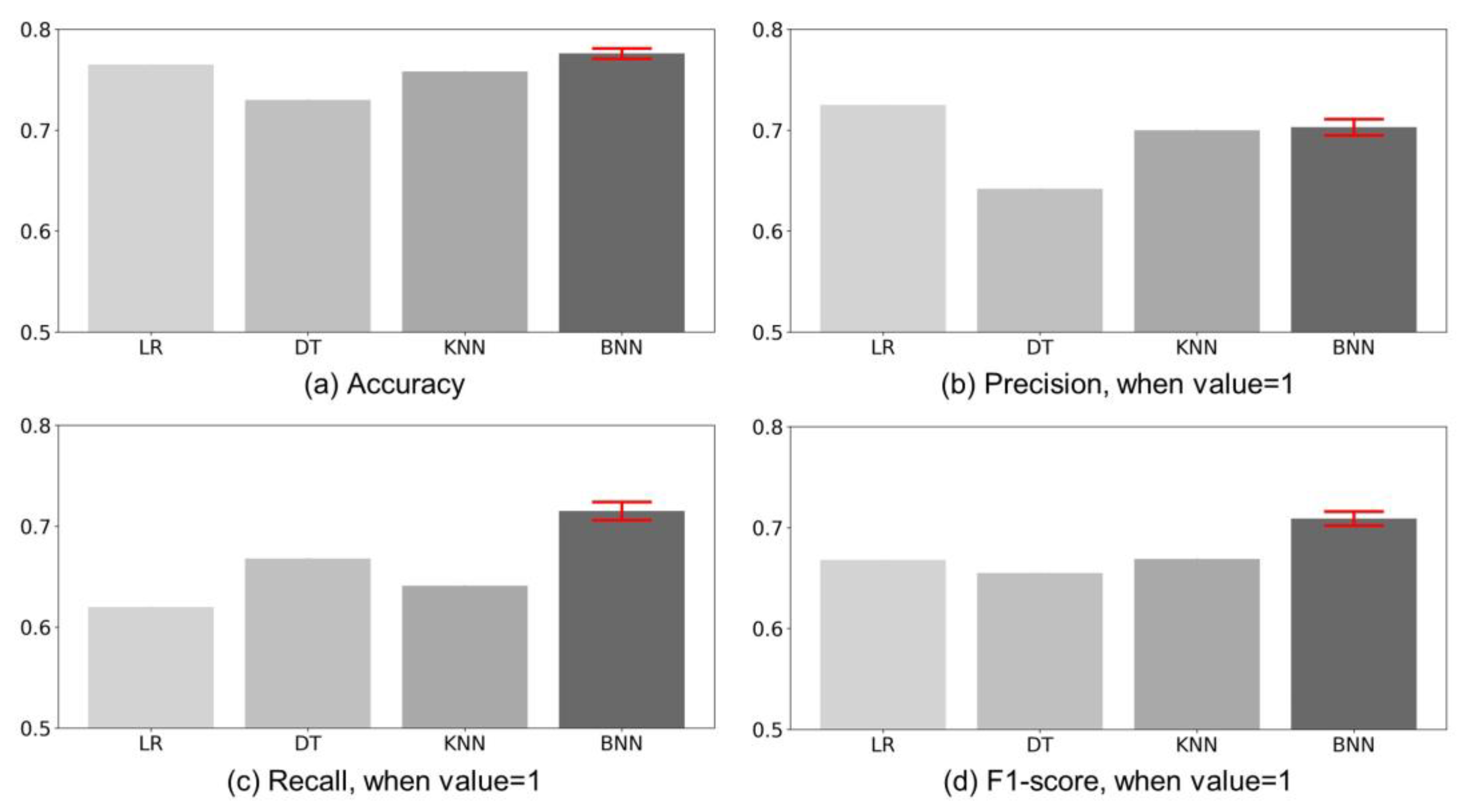
- As a result, BNN had the highest F1-score, followed by KNN, LR, and DT. This means that the performance has improved by up to 109.31% compared to the previous one. Since the range of fluctuation of BNN performance is very small, the proposed method can make stable predictions.
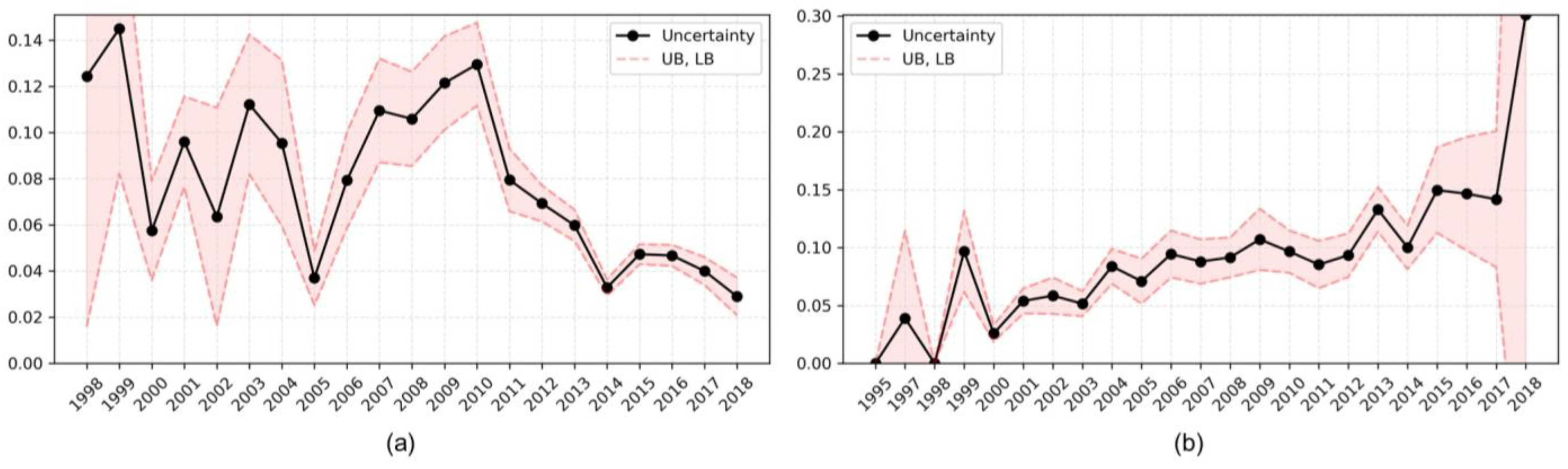
- We found a trend in uncertainty over time. This means that when researchers build IP-R&D strategies, they must consider the period when the value of the technology was evaluated.
- Through the feature ablation trial, we found that the uncertainty of evaluation decreased as num_famN, num_famP, and num_frw among the factors increased. In addition, we found that num_app, num_clm, num_doc, num_inv, and num_ipc are proportional to the uncertainty of evaluation.
6. Discussion
- Technology value is determined by originality, marketability, and the scope of rights.
- The causal relationship of technology value with the number of applicants who own patent rights, the number of inventors, and the number of IPC codes should be carefully interpreted.
- Nonetheless, the evaluation of technology, which is higher in the number of countries for family patents, the number of forward citations, and the number of family patents, can be trusted more than that of other cases.
7. Conclusions
- Patents are documents that describe the technology. However, we did not use patent texts.
- We predicted patent value through BNN. We also compared the performance with that of other classifiers. However, although our model was the best, it was not good enough to be applied to the real world.
- More recently, various layers have been proposed as deep learning advances. However, this was not considered.
- In recent years, the study field of natural language processing has rapidly grown. Thus, it is necessary to consider the patent text when estimating technology value in future studies.
- Prediction performance needs to be further improved. Reliable prediction performance helps discover new technology opportunities beyond technology evaluation in various fields.
- We need to compare the estimation of uncertainty according to various layers in future studies. This is because the attention-based layer suitable for the patent document helps the model understand the technical terms of the patent [57].
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

References
- Kaufmann, A.; Tödtling, F. Science–Industry Interaction in the Process of Innovation: The Importance of Boundary-Crossing between Systems. Res. Policy 2001, 30, 791–804. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.; Lee, C.Y.; Cho, Y. Technological Diversification, Core-Technology Competence, and Firm Growth. Res. Policy 2016, 45, 113–124. [Google Scholar] [CrossRef]
- Chen, Y.F.; Wu, T.C. An Empirical Analysis of Core Competence for High-Tech Firms and Traditional Manufacturers. J. Manag. Dev. 2007, 26, 159–168. [Google Scholar] [CrossRef]
- Lin, B.-W.; Chen, C.-J.; Wu, H.-L. Patent Portfolio Diversity, Technology Strategy, and Firm Value. IEEE Trans. Eng. Manag. 2006, 53, 17–26. [Google Scholar] [CrossRef]
- Appio, F.P.; De Luca, L.M.; Morgan, R.; Martini, A. Patent Portfolio Diversity and Firm Profitability: A Question of Specialization or Diversification? J. Bus. Res. 2019, 101, 255–267. [Google Scholar] [CrossRef]
- Ha, S.H.; Liu, W.; Cho, H.; Kim, S.H. Technological Advances in the Fuel Cell Vehicle: Patent Portfolio Management. Technol. Forecast. Soc. Chang. 2015, 100, 277–289. [Google Scholar] [CrossRef]
- Shi, X.; Cai, L.; Song, H. Discovering Potential Technology Opportunities for Fuel Cell Vehicle Firms: A Multi-Level Patent Portfolio-Based Approach. Sustainability 2019, 11, 6381. [Google Scholar] [CrossRef] [Green Version]
- Chang, S. Bin Using Patent Analysis to Establish Technological Position: Two Different Strategic Approaches. Technol. Forecast. Soc. Chang. 2012, 79, 3–15. [Google Scholar] [CrossRef]
- Kim, G.; Bae, J. A Novel Approach to Forecast Promising Technology through Patent Analysis. Technol. Forecast. Soc. Chang. 2017, 117, 228–237. [Google Scholar] [CrossRef]
- Aristodemou, L.; Tietze, F. Citations as a Measure of Technological Impact: A Review of Forward Citation-Based Measures. World Pat. Inf. 2018, 53, 39–44. [Google Scholar] [CrossRef]
- Falk, N.; Train, K. Patent Valuation with Forecasts of Forward Citations. J. Bus. Valuat. Econ. Loss Anal. 2017, 12, 101–121. [Google Scholar] [CrossRef]
- Lanjouw, J.O.; Schankerman, M. Patent Quality and Research Productivity: Measuring Innovation with Multiple Indicators. Econ. J. 2004, 114, 441–465. [Google Scholar] [CrossRef]
- Han, E.J.; Sohn, S.Y. Patent Valuation Based on Text Mining and Survival Analysis. J. Technol. Transf. 2015, 40, 821–839. [Google Scholar] [CrossRef]
- Moore, K.A. Worthless Patents. Berkeley Technol. Law J. 2005, 20, 1521. [Google Scholar] [CrossRef]
- Liu, K.; Arthurs, J.; Cullen, J.; Alexander, R. Internal Sequential Innovations: How Does Interrelatedness Affect Patent Renewal? Res. Policy 2008, 37, 946–953. [Google Scholar] [CrossRef]
- Bozeman, B. Technology Transfer and Public Policy: A Review of Research and Theory. Res. Policy 2000, 29, 627–655. [Google Scholar] [CrossRef]
- Cunningham, J.A.; Menter, M.; Young, C. A Review of Qualitative Case Methods Trends and Themes Used in Technology Transfer Research. J. Technol. Transf. 2016, 42, 923–956. [Google Scholar] [CrossRef]
- Yoon, B.; Park, I.; Yun, D.; Park, G. Exploring Promising Vacant Technology Areas in a Technology-Oriented Company Based on Bibliometric Analysis and Visualisation. Technol. Anal. Strateg. Manag. 2019, 31, 388–405. [Google Scholar] [CrossRef]
- Rotolo, D.; Hicks, D.; Martin, B.R. What Is an Emerging Technology? Res. Policy 2015, 44, 1827–1843. [Google Scholar] [CrossRef] [Green Version]
- Noh, H.; Seo, J.H.; Sun Yoo, H.; Lee, S. How to Improve a Technology Evaluation Model: A Data-Driven Approach. Technovation 2018, 72–73, 1–12. [Google Scholar] [CrossRef]
- Lee, J.; Kang, J.; Park, S.; Jang, D.; Lee, J. A Multi-Class Classification Model for Technology Evaluation. Sustainability 2020, 12, 6153. [Google Scholar] [CrossRef]
- Jun, S. Text Data Analysis Using Generalized Linear Mixed Model and Bayesian Visualization. Axioms 2022, 11, 674. [Google Scholar] [CrossRef]
- Uhm, D.; Jun, S. Zero-Inflated Patent Data Analysis Using Generating Synthetic Samples. Futur. Internet 2022, 14, 211. [Google Scholar] [CrossRef]
- Lee, J.; Park, S. A Study on the Calibrated Confidence of Text Classification Using a Variational Bayes. Appl. Sci. 2022, 12, 9007. [Google Scholar] [CrossRef]
- Choi, J.; Lee, C.; Yoon, J. Exploring a Technology Ecology for Technology Opportunity Discovery: A Link Prediction Approach Using Heterogeneous Knowledge Graphs. Technol. Forecast. Soc. Chang. 2023, 186, 122161. [Google Scholar] [CrossRef]
- Woudenberg, F. An Evaluation of Delphi. Technol. Forecast. Soc. Chang. 1991, 40, 131–150. [Google Scholar] [CrossRef]
- Kharat, M.G.; Raut, R.D.; Kamble, S.S.; Kamble, S.J. The Application of Delphi and AHP Method in Environmentally Conscious Solid Waste Treatment and Disposal Technology Selection. Manag. Environ. Qual. 2016, 27, 427–440. [Google Scholar] [CrossRef]
- Galbraith, C.S.; Ehrlich, S.B.; DeNoble, A.F. Predicting Technology Success: Identifying Key Predictors and Assessing Expert Evaluation for Advanced Technologies. J. Technol. Transf. 2006, 31, 673–684. [Google Scholar] [CrossRef] [Green Version]
- Akoka, J.; Comyn-Wattiau, I. A Method for Emerging Technology Evaluation. Application to Blockchain and Smart Data Discovery. In Conceptual Modeling Perspectives; Springer: Cham, Switzerland, 2017; pp. 247–258. [Google Scholar]
- Sá, E.; Carvalho, A.; Silva, J.; Rezazadeh, A. A Delphi Study of Business Models for Cycling Urban Mobility Platforms. Res. Transp. Bus. Manag. 2022, 45, 100907. [Google Scholar] [CrossRef]
- Woo Kim, H.; Kim, J.; Lee, J.; Park, S.; Jang, D. A Novel Methodology for Extracting Core Technology and Patents by IP Mining. J. Korean Inst. Intell. Syst. 2015, 25, 392–397. [Google Scholar] [CrossRef]
- Choi, J.; Jang, D.; Jun, S.; Park, S. A Predictive Model of Technology Transfer Using Patent Analysis. Sustainability 2015, 7, 16175–16195. [Google Scholar] [CrossRef] [Green Version]
- Kumari, R.; Jeong, J.Y.; Lee, B.-H.; Choi, K.-N.; Choi, K. Topic Modelling and Social Network Analysis of Publications and Patents in Humanoid Robot Technology. J. Inf. Sci. 2021, 47, 658–676. [Google Scholar] [CrossRef]
- Lai, K.-K.; Chen, Y.-L.; Kumar, V.; Daim, T.; Verma, P.; Kao, F.-C.; Liu, R. Mapping Technological Trajectories and Exploring Knowledge Sources: A Case Study of E-Payment Technologies. Technol. Forecast. Soc. Chang. 2023, 186, 122173. [Google Scholar] [CrossRef]
- Yang, D.S.-C.G. Some Methods Determining Reasonable Royalty Rates for Patent Valuation—An Infringement Damages Model. J. Korea Technol. Innov. Soc. 2012, 15, 700–721. [Google Scholar]
- Trappey, A.J.C.; Trappey, C.V.; Wu, C.-Y.; Lin, C.-W. A Patent Quality Analysis for Innovative Technology and Product Development. Adv. Eng. Inform. 2012, 26, 26–34. [Google Scholar] [CrossRef]
- Ko, N.; Jeong, B.; Seo, W.; Yoon, J. A Transferability Evaluation Model for Intellectual Property. Comput. Ind. Eng. 2019, 131, 344–355. [Google Scholar] [CrossRef]
- Trappey, A.J.C.; Trappey, C.V.; Govindarajan, U.H.; Sun, J.J.H. Patent Value Analysis Using Deep Learning Models—The Case of IoT Technology Mining for the Manufacturing Industry. IEEE Trans. Eng. Manag. 2021, 68, 1334–1346. [Google Scholar] [CrossRef]
- Chung, P.; Sohn, S.Y. Early Detection of Valuable Patents Using a Deep Learning Model: Case of Semiconductor Industry. Technol. Forecast. Soc. Chang. 2020, 158, 120146. [Google Scholar] [CrossRef]
- Lee, C.-W.; Tao, F.; Ma, Y.-Y.; Lin, H.-L. Development of Patent Technology Prediction Model Based on Machine Learning. Axioms 2022, 11, 253. [Google Scholar] [CrossRef]
- Huang, Z.; Li, J.; Yue, H. Study on Comprehensive Evaluation Based on AHP-MADM Model for Patent Value of Balanced Vehicle. Axioms 2022, 11, 481. [Google Scholar] [CrossRef]
- Lecun, Y. A Theoretical Framework for Back-Propagation. In Proceedings of the 1988 Connectionist Models Summer School; Morgan Kaufmann: San Mateo, CA, USA, 1988; pp. 21–28. [Google Scholar]
- Nair, V.; Hinton, G. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the ICML’10: 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Gal, Y.; Ghahramani, Z. A Theoretically Grounded Application of Dropout in Recurrent Neural Networks. Adv. Neural Inf. Process. Syst. 2016, 29, 1–9. [Google Scholar]
- Blundell, C.; Cornebise, J.; Kavukcuoglu, K.; Com, W. Weight Uncertainty in Neural Networks. In Proceedings of the ICML’15: 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1613–1622. [Google Scholar]
- Liu, Q.; Wang, D. Stein Variational Gradient Descent: A General Purpose Bayesian Inference Algorithm. Adv. Neural Inf. Process. Syst. 2016, 29, 1–9. [Google Scholar]
- Graves, A. Practical Variational Inference for Neural Networks. Adv. Neural Inf. Process. Syst. 2011, 24, 1–9. [Google Scholar]
- Wan, L.; Zeiler, M.; Zhang, S.; Cun, Y.L.; Fergus, R. Regularization of Neural Networks Using DropConnect. PMLR 2013, 28, 1058–1066. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2013. [Google Scholar] [CrossRef]
- Kingma, D.P.; Salimans, T.; Welling, M. Variational Dropout and the Local Reparameterization Trick. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar]
- Wen, Y.; Vicol, P.; Ba, J.; Tran, D.; Grosse, R. Flipout: Efficient Pseudo-Independent Weight Perturbations on Mini-Batches. arXiv 2018. [Google Scholar] [CrossRef]
- Esteva, A.; Robicquet, A.; Ramsundar, B.; Kuleshov, V.; DePristo, M.; Chou, K.; Cui, C.; Corrado, G.; Thrun, S.; Dean, J. A Guide to Deep Learning in Healthcare. Nat. Med. 2019, 25, 24–29. [Google Scholar] [CrossRef]
- Ding, X.; Nassehi, D.; Larson, E.C. Measuring Oxygen Saturation With Smartphone Cameras Using Convolutional Neural Networks. IEEE J. Biomed. Health Inform. 2019, 23, 2603–2610. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.; Ren, Z.; Cao, K.; Li, M.M.; Wang, K.; Zhou, Y. CancerVar: An Artificial Intelligence–Empowered Platform for Clinical Interpretation of Somatic Mutations in Cancer. Sci. Adv. 2022, 8, 1624. [Google Scholar] [CrossRef] [PubMed]
- Shapiro, S.S.; Wilk, M.B. Biometrika Trust An Analysis of Variance Test for Normality (Complete Samples). Biometrika 1965, 52, 591–611. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. arXiv 2017. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approaches | Related Works | Objectivity | Prediction | Uncertainty |
|---|---|---|---|---|
| Expert- based | [26,27,28,29,30] | – | – | – |
| SNA- Based 1 | [31,32,33,34] | √ | – | – |
| ML and DL Based 2 | [35,36,37,38,39,40,41] | √ | √ | – |
| BNN- based | Our method | √ | √ | √ |
| Factors | Description |
|---|---|
| num_app | Number of applicants who own patent rights |
| num_bkw | Number of backward citations |
| num_clm | Number of claims |
| num_cpc | Number of Cooperative Patent Classification (CPC) codes |
| num_doc | Number of cited non-patent documents |
| num_famN | Number of countries for family patents |
| num_famP | Number of family patents |
| num_frw | Number of forward citations |
| num_inv | Number of Inventors |
| num_ipc | Number of International Patent Classification (IPC) codes |
| Value | High (or 1) if the value of the patent is high, and Low (or 0) otherwise |
| Dataset | High | Low | Total | Ratio |
|---|---|---|---|---|
| Raw dataset | 2335 | 1446 | 3781 | 100% |
| Training dataset | 1307 | 809 | 2116 | 56% |
| Validation dataset | 327 | 203 | 530 | 14% |
| Test dataset | 701 | 434 | 1135 | 30% |
| Variables | Levene * | T-Test * | Wilcoxon * | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Statistics | p-Value | Statistics | p-Value | Statistics | p-Value | |||||
| num_app | 1.156 | 1.196 | 0.549 | 0.671 | 4.093 | 0.043 | −1.931 | 0.027 | −1.157 | 0.124 |
| num_bkw | 34.435 | 79.099 | 86.937 | 259.065 | 49.834 | <0.001 | −6.337 | <0.001 | −13.678 | <0.001 |
| num_clm | 17.839 | 21.694 | 9.391 | 13.818 | 55.854 | <0.001 | −9.352 | <0.001 | −8.824 | <0.001 |
| num_cpc | 8.686 | 13.376 | 7.676 | 16.573 | 154.033 | <0.001 | −10.107 | <0.001 | −6.720 | <0.001 |
| num_doc | 7.737 | 18.119 | 32.677 | 52.314 | 52.232 | <0.001 | −6.770 | <0.001 | −11.455 | <0.001 |
| num_famN | 2.652 | 5.535 | 2.277 | 4.022 | 354.661 | <0.001 | −24.888 | <0.001 | −25.482 | <0.001 |
| num_famP | 14.008 | 87.576 | 47.859 | 287.619 | 131.161 | <0.001 | −9.641 | <0.001 | −26.605 | <0.001 |
| num_frw | 14.728 | 74.661 | 24.087 | 115.006 | 398.873 | <0.001 | −19.546 | <0.001 | −33.123 | <0.001 |
| num_inv | 2.215 | 2.094 | 1.931 | 2.269 | 34.145 | <0.001 | 1.690 | > 0.500 | 4.631 | >0.500 |
| num_ipc | 4.060 | 4.416 | 3.231 | 5.785 | 49.939 | <0.001 | −2.146 | 0.016 | 6.442 | >0.500 |
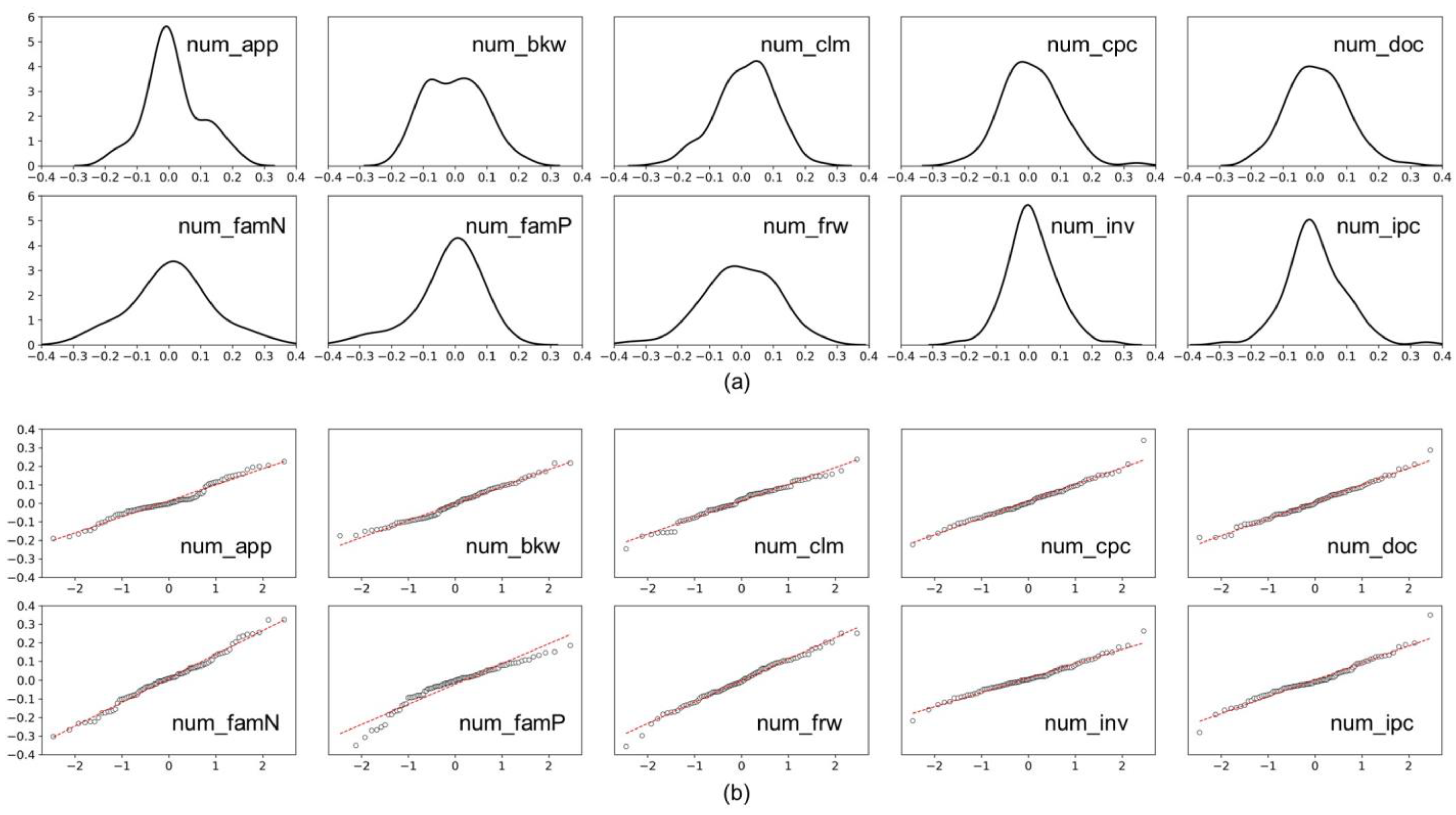
| Variables | Avg | Std | Skewness | Kurtosis | Shapiro-Wilk * | |
|---|---|---|---|---|---|---|
| Statistics | p-Value | |||||
| num_app | 0.013 | 0.086 | 0.278 | 0.081 | 0.965 | 0.010 |
| num_bkw | −0.002 | 0.090 | 0.208 | −0.676 | 0.980 | 0.133 |
| num_clm | 0.013 | 0.089 | −0.333 | 0.032 | 0.985 | 0.316 |
| num_cpc | 0.010 | 0.090 | 0.389 | 0.985 | 0.986 | 0.369 |
| num_doc | 0.007 | 0.090 | 0.262 | 0.160 | 0.990 | 0.688 |
| num_famN | 0.009 | 0.126 | 0.045 | 0.112 | 0.988 | 0.519 |
| num_famP | −0.022 | 0.112 | −1.410 | 3.056 | 0.905 | 0.000 |
| num_frw | −0.003 | 0.113 | −0.286 | 0.212 | 0.991 | 0.722 |
| num_inv | 0.010 | 0.076 | 0.238 | 0.980 | 0.987 | 0.416 |
| num_ipc | 0.001 | 0.090 | 0.411 | 1.849 | 0.970 | 0.024 |
| Statistical Test | Spearman * | Kendall * | ||
|---|---|---|---|---|
| Statistics | p-Value | Statistics | p-Value | |
| −0.594 | 0.005 | −0.448 | 0.004 | |
| 0.872 | <0.001 | 0.737 | <0.001 | |
| Variables | Spearman * | Kendall * | ||
|---|---|---|---|---|
| Statistics | p-Value | Statistics | p-Value | |
| num_app | 0.981 | <0.001 | 0.897 | <0.001 |
| num_bkw | 0.143 | 0.077 | 0.116 | 0.044 |
| num_clm | 0.728 | <0.001 | 0.588 | <0.001 |
| num_cpc | −0.047 | 0.321 | −0.016 | 0.408 |
| num_doc | 0.788 | <0.001 | 0.611 | <0.001 |
| num_famN | −0.973 | <0.001 | −0.887 | <0.001 |
| num_famP | −0.949 | <0.001 | −0.826 | <0.001 |
| num_frw | −0.972 | <0.001 | −0.878 | <0.001 |
| num_inv | 0.916 | <0.001 | 0.804 | <0.001 |
| num_ipc | 0.972 | <0.001 | 0.872 | <0.001 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J.; Park, S.; Lee, J. Estimation of Uncertainty for Technology Evaluation Factors via Bayesian Neural Networks. Axioms 2023, 12, 145. https://doi.org/10.3390/axioms12020145
Lee J, Park S, Lee J. Estimation of Uncertainty for Technology Evaluation Factors via Bayesian Neural Networks. Axioms. 2023; 12(2):145. https://doi.org/10.3390/axioms12020145
Chicago/Turabian StyleLee, Juhyun, Sangsung Park, and Junseok Lee. 2023. "Estimation of Uncertainty for Technology Evaluation Factors via Bayesian Neural Networks" Axioms 12, no. 2: 145. https://doi.org/10.3390/axioms12020145
APA StyleLee, J., Park, S., & Lee, J. (2023). Estimation of Uncertainty for Technology Evaluation Factors via Bayesian Neural Networks. Axioms, 12(2), 145. https://doi.org/10.3390/axioms12020145