
A CNN-Based Method for Counting Grains within a Panicle


Abstract
:1. Introduction
2. Samples Generation
2.1. Image Acquisition Instrument
2.2. Image Annotation and Preprocessing
3. Design of Neural Network
4. Training Process
5. Result
6. Analysis
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, Q.F. Strategies for developing green super rice. Proc. Natl. Acad. Sci. USA 2007, 104, 16402–16409. [Google Scholar] [CrossRef] [Green Version]
- Han, B. Genome-Wide Assocation Studies (GWAS) in Crops. In Proceedings of the Plant and Animal Genome Conference (PAG XXIV), San Diego, CA, USA, 10–15 January 2014. [Google Scholar]
- Zhu, Z.H.; Zhang, F.; Hu, H.; Bakshi, A.; Robinson, M.R.; Powell, J.E.; Montgomery, G.W.; Goddard, M.E.; Wray, N.R.; Visscher, P.M.; et al. Integration of summary data from GWAS and eQTL studies predicts complex trait gene targets. Nat. Genet. 2016, 48, 481–487. [Google Scholar] [CrossRef] [PubMed]
- Xing, Y.Z.; Zhang, Q.F. Genetic and Molecular Bases of Rice Yield. Annu. Rev. Plant Biol. 2010, 61, 421–442. [Google Scholar] [CrossRef] [PubMed]
- Mochida, K.; Koda, S.; Inoue, K.; Hirayama, T.; Tanaka, S.; Nishii, R.; Melgani, F. Computer vision-based phenotyping for improvement of plant productivity: A machine learning perspective. Gigascience 2019, 8, giy153. [Google Scholar] [CrossRef] [Green Version]
- Reuzeau, C. TraitMill (TM): A high throughput functional genomics platform for the phenotypic analysis of cereals. In Vitro Cell. Dev. Biol. Anim. 2007, 43, S4. [Google Scholar]
- Neumann, K. Using Automated High-Throughput Phenotyping using the LemnaTec Imaging Platform to Visualize and Quantify Stress Influence in Barley. In Proceedings of the International Plant & Animal Genome Conference XXI, San Diego, CA, USA, 12–16 January 2013. [Google Scholar]
- Golzarian, M.R.; Frick, R.A.; Rajendran, K.; Berger, B.; Roy, S.; Tester, M.; Lun, D.S. Accurate inference of shoot biomass from high-throughput images of cereal plants. Plant Methods 2011, 7, 2. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hao, H.; Chun-bao, H. Research on Image Segmentation Based on OTSU Algorithm and GA. J. Liaoning Univ. Technol. 2016, 36, 99–102. [Google Scholar]
- Huang, P.; Zhu, L.; Zhang, Z.; Yang, C. Row End Detection and Headland Turning Control for an Autonomous Banana-Picking Robot. Machines 2021, 9, 103. [Google Scholar] [CrossRef]
- Cao, X.; Yan, H.; Huang, Z.; Ai, S.; Xu, Y.; Fu, R.; Zou, X. A Multi-Objective Particle Swarm Optimization for Trajectory Planning of Fruit Picking Manipulator. Agronomy 2021, 11, 2286. [Google Scholar] [CrossRef]
- Wu, F.; Duan, J.; Chen, S.; Ye, Y.; Ai, P.; Yang, Z. Multi-Target Recognition of Bananas and Automatic Positioning for the Inflorescence Axis Cutting Point. Front. Plant Sci. 2021, 12, 705021. [Google Scholar] [CrossRef] [PubMed]
- Greenspan, H.; Ginneken, B.v.; Summers, R.M. Guest Editorial Deep Learning in Medical Imaging: Overview and Future Promise of an Exciting New Technique. IEEE Trans. Med. Imaging 2016, 35, 1153–1159. [Google Scholar] [CrossRef]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep Learning for Computer Vision: A Brief Review. Comput. Intell. Neurosci. 2018. [Google Scholar] [CrossRef]
- He, K.M.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (Cvpr), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (Cvpr), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Wu, H.; Zhang, J.; Huang, K.; Liang, K.; Yu, Y. FastFCN: Rethinking Dilated Convolution in the Backbone for Semantic Segmentation. arXiv 2019, arXiv:1903.11816. [Google Scholar]
- Gupta, H.; Jin, K.H.; Nguyen, H.Q.; McCann, M.T.; Unser, M. CNN-Based Projected Gradient Descent for Consistent CT Image Reconstruction. IEEE Trans. Med. Imaging 2018, 37, 1440–1453. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, L.; Wang, S.; Fan, W.; Sun, J.; Naoi, S. Beyond Human Recognition: A CNN-Based Framework for Handwritten Character Recognition. In Proceedings of the 3rd Iapr Asian Conference on Pattern Recognition Acpr, Kuala Lumpur, Malaysia, 3–6 November 2015; pp. 695–699. [Google Scholar]
- Jingying, Q.; Xian, S.; Xin, G. Remote sensing image target recognition based on CNN. Foreign Electron. Meas. Technol. 2016, 8, 45–50. [Google Scholar]
- Yunju, J.; Ansari, I.; Shim, J.; Lee, J. A Car Plate Area Detection System Using Deep Convolution Neural Network. J. Korea Multimed. Soc. 2017, 20, 1166–1174. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (Iccv), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.Q.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.M.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (Iccv), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Dumoulin, V.; Visin, F. A guide to convolution arithmetic for deep learning. arXiv 2016, arXiv:1603.07285. [Google Scholar]
- Scherer, D.; Muller, A.; Behnke, S. Evaluation of Pooling Operations in Convolutional Architectures for Object Recognition. Artif. Neural Netw. 2010, 6354 Pt III, 92–101. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. Med. Image Comput. Comput. Assist. Interv. 2015, 9351, 234–241. [Google Scholar]
- Rad, R.M.; Saeedi, P.; Au, J.; Havelock, J. Blastomere Cell Counting and Centroid Localization in Microscopic Images of Human Embryo. In Proceedings of the 2018 IEEE 20th International Workshop on Multimedia Signal Processing (MMSP), Vancouver, BC, Canada, 29–31 August 2018. [Google Scholar]
- Chen, J.; Fan, Y.; Wang, T.; Zhang, C.; Qiu, Z.; He, Y. Automatic Segmentation and Counting of Aphid Nymphs on Leaves Using Convolutional Neural Networks. Agronomy 2018, 8, 129. [Google Scholar] [CrossRef] [Green Version]
- Falk, T.; Mai, D.; Bensch, R.; Çiçek, Ö.; Abdulkadir, A.; Marrakchi, Y.; Böhm, A.; Deubner, J.; Jäckel, Z.; Seiwald, K.; et al. U-Net: Deep learning for cell counting, detection, and morphometry. Nat. Methods 2019, 16, 67–70. [Google Scholar] [CrossRef]
- Luo, J.; Oore, S.; Hollensen, P.; Fine, A.; Trappenberg, T. Self-training for Cell Segmentation and Counting. Adv. Artif. Intell. 2019, 11489, 406–412. [Google Scholar]
- Guo, Y.; Stein, J.; Wu, G.; Krishnamurthy, A. SAU-Net: A Universal Deep Network for Cell Counting. In Proceedings of the 10th ACM International Conference on Bioinformatics, Computational Biology and Health Informatics, Niagara Falls, NY, USA, 7–10 September 2019; ACM: New York, NY, USA, 2019; pp. 299–306. [Google Scholar]
- Ghosal, S.; Zheng, B.; Chapman, S.C.; Potgieter, A.B.; Jordan, D.R.; Wang, X.; Singh, A.K.; Singh, A.; Hirafuji, M.; Ninomiya, S.; et al. A Weakly Supervised Deep Learning Framework for Sorghum Head Detection and Counting. Plant Phenomics 2019, 2019, 14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- Gong, L.; Lin, K.; Wang, T.; Liu, C.; Yuan, Z.; Zhang, D.; Hong, J. Image-based on-panicle rice [Oryza sativa L.] grain counting with a prior edge wavelet correction model. Agronomy 2018, 8, 91. [Google Scholar] [CrossRef] [Green Version]
- Faroq, A.T.; Adam, H.; Dos Anjos, A.; Lorieux, M.; Larmande, P.; Ghesquière, A.; Jouannic, S.; Shahbazkia, H.R. P-TRAP: A panicle trait phenotyping tool. BMC Plant Biol. 2013, 13, 122. [Google Scholar]











{kind=link}
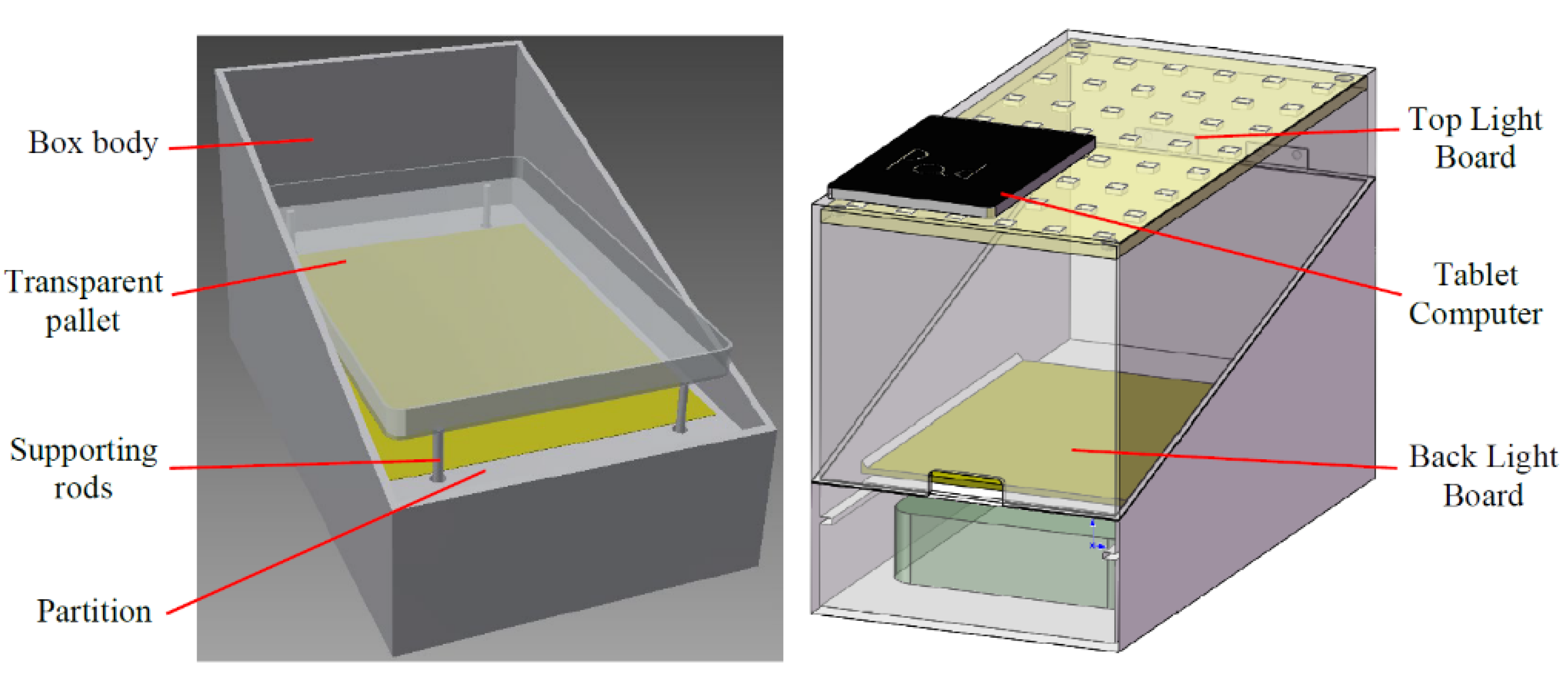{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
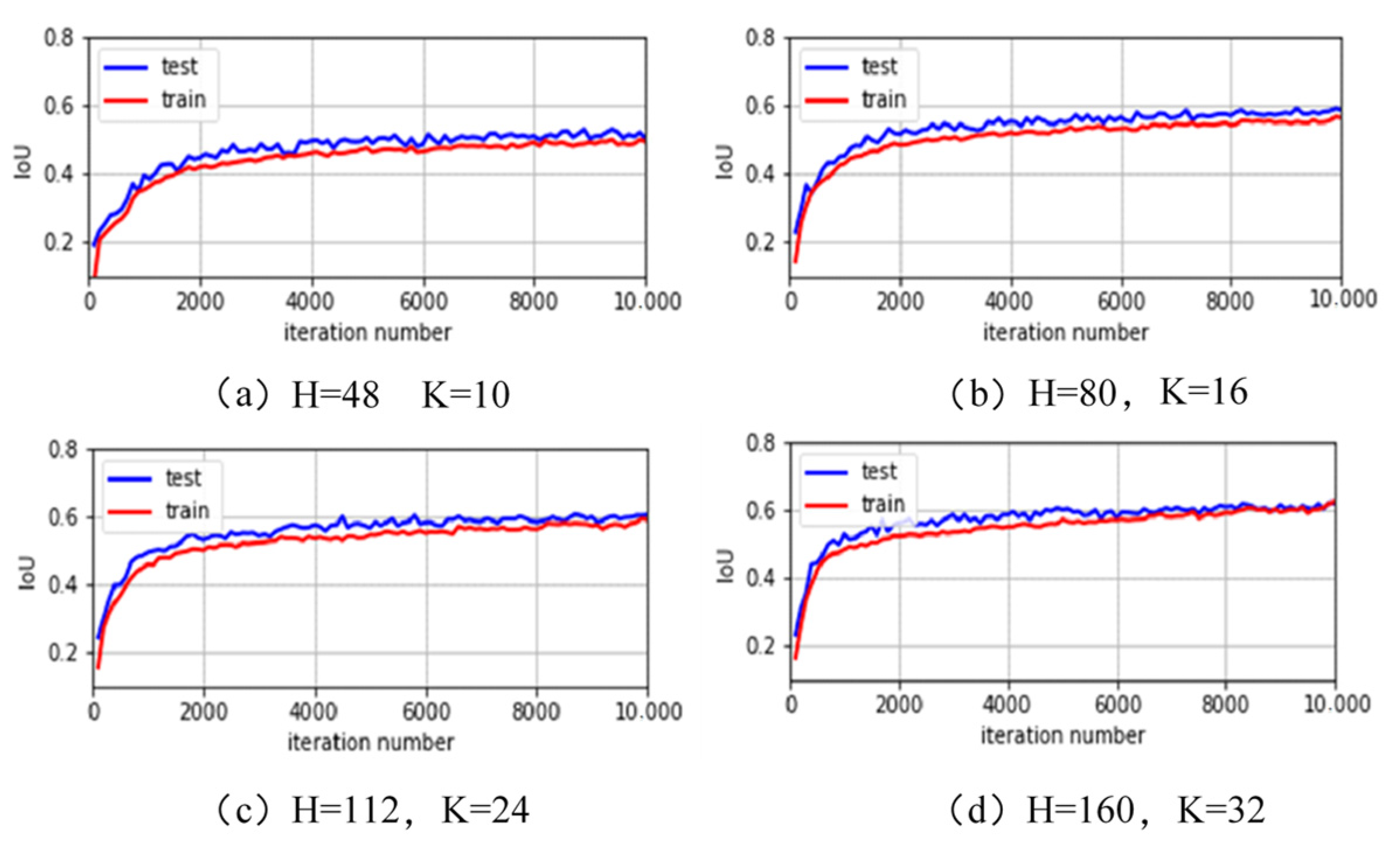{kind=link}
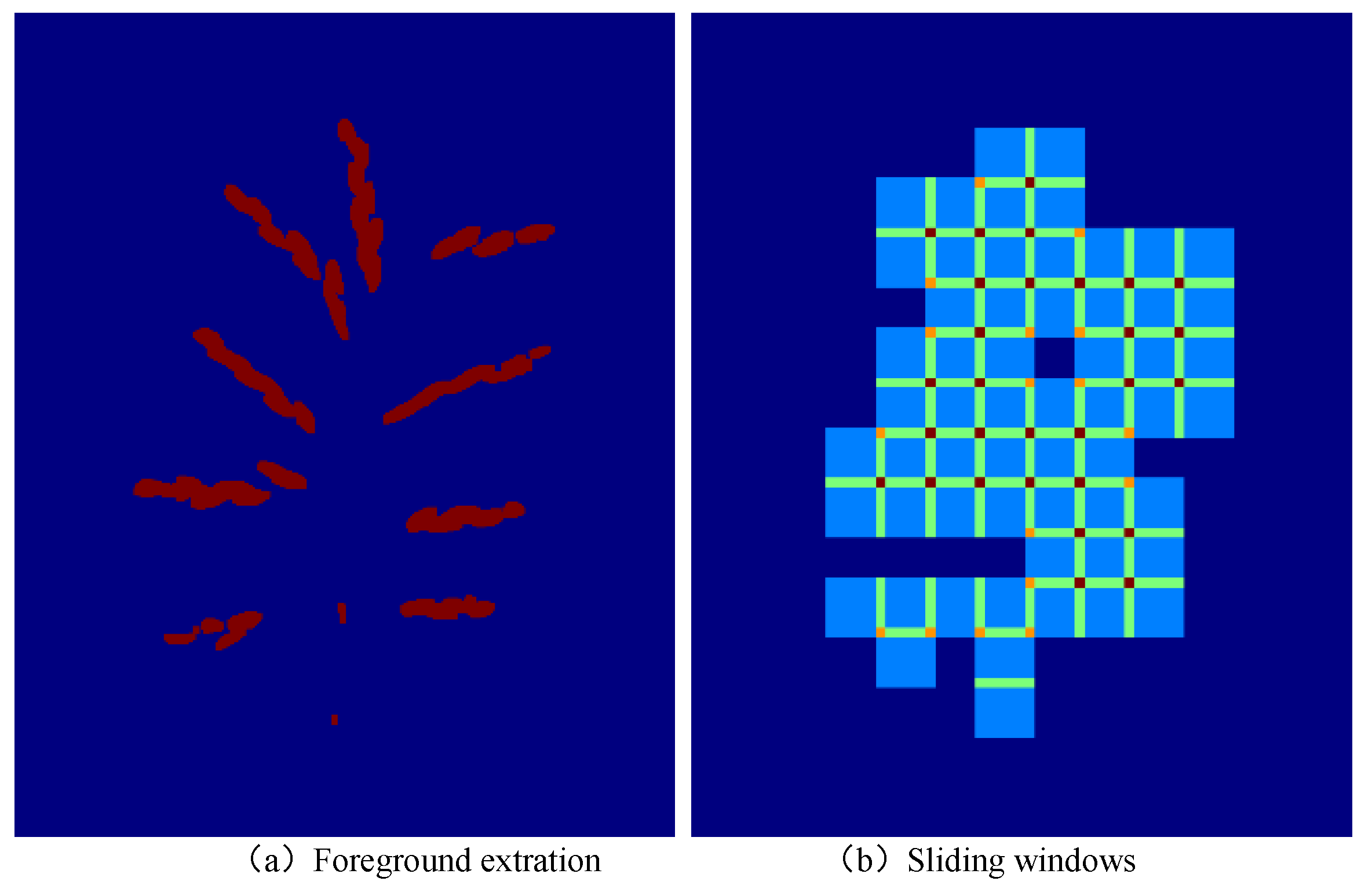{kind=link}
{kind=link}
{kind=link}
| Index | Size | Activation Function |
|---|---|---|
| Input | H, H, 3 | - |
| C1 | H, H, K | ReLU |
| C2 | H/2, H/2, 2 K | ReLU |
| C3 | H/4, H/4, 4 K | ReLU |
| C4 | H/8, H/8, 8 K | ReLU |
| C5 | H/16, H/16, 16 K | ReLU |
| C6 | H/8, H/8, 8 K | ReLU |
| C7 | H/4, H/4, 4 K | ReLU |
| C8 | H/2, H/2, 2 K | ReLU |
| C9 | H, H, K | ReLU |
| Output | H, H, 1 | Sigmoid |
| Index | Parameters | Model Size (MB) |
|---|---|---|
| 1 | H = 48, K = 10 | 8.8 |
| 2 | H = 80, K = 16 | 22.5 |
| 3 | H = 112, K = 24 | 50.5 |
| 4 | H = 160, K = 32 | 89.8 |
| Index | Parameters | Cutting Amount | Sub | Step |
|---|---|---|---|---|
| 1 | H = 48, K = 10 | u, v = 4, 6 | 40 | 34 |
| 2 | H = 80, K = 16 | u, v = 6, 8 | 68 | 60 |
| 3 | H = 112, K = 24 | u, v = 8, 12 | 96 | 84 |
| 4 | H = 160, K = 32 | u, v = 10, 16 | 140 | 124 |
| Index | Model Description | MAE | MSE | MRE | Processing Time (ms) |
|---|---|---|---|---|---|
| 1 | H = 48, K = 10 | 5.00 | 8.41 | 4.05 | 6.40 |
| 2 | H = 80, K = 16 | 4.75 | 7.78 | 4.05 | 27.30 |
| 3 | H = 112, K = 24 | 4.38 | 7.31 | 3.66 | 88.90 |
| 4 | H = 160, K = 32 | 3.75 | 4.63 | 3.47 | 264.90 |
| 5 | Wavelet Model [36] | 5.68 | 6.96 | 6.08 | 140.40 |
| 6 | P-trap [37] | 13.76 | 17.68 | 14.07 | ~2000.00 * |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gong, L.; Fan, S. A CNN-Based Method for Counting Grains within a Panicle. Machines 2022, 10, 30. https://doi.org/10.3390/machines10010030
Gong L, Fan S. A CNN-Based Method for Counting Grains within a Panicle. Machines. 2022; 10(1):30. https://doi.org/10.3390/machines10010030
Chicago/Turabian StyleGong, Liang, and Shengzhe Fan. 2022. "A CNN-Based Method for Counting Grains within a Panicle" Machines 10, no. 1: 30. https://doi.org/10.3390/machines10010030
APA StyleGong, L., & Fan, S. (2022). A CNN-Based Method for Counting Grains within a Panicle. Machines, 10(1), 30. https://doi.org/10.3390/machines10010030