
Tracking and Counting of Tomato at Different Growth Period Using an Improving YOLO-Deepsort Network for Inspection Robot



Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Processing
2.1.1. Data Acquisition and Experimental Environment
2.1.2. Data Augmentation
- The color gamut change is to generate a new image by randomly adjusting the original image’s color saturation, brightness, and contrast. The random adjustment of the input image color is vital for improving the robustness of the network and enhancing the model’s performance in complex greenhouse scenes. The image data’s HSV (Hue, Saturation, Value) describes the image’s color gamut distortion. The values of these three parameters are, respectively, Hue (h) is 0.015, Saturation (s) is 0.6, and the brightness (v) is 0.4.
- Flip the image from left to right in the horizontal direction, and each image has a 50% probability of flipping. This data enhancement method can also effectively expand the data volume of training samples.
- To enhance the network’s ability to detect tomato flowers, we use mosaic enhancement technology and stitch the four images processed by steps 1 and 2 above by random scaling, random cropping, and random distribution. There are 4 different images are mixed, while CutMix mixes only 2 images [32]. This method effectively increases the diversity of images for the training process to improve the model’s ability to detect the flowers. And this method also effectively increases the number of images. Not only that, by splicing four images to form one, the batch size is increased in disguise, which reduces the GPU memory requirements for model training.
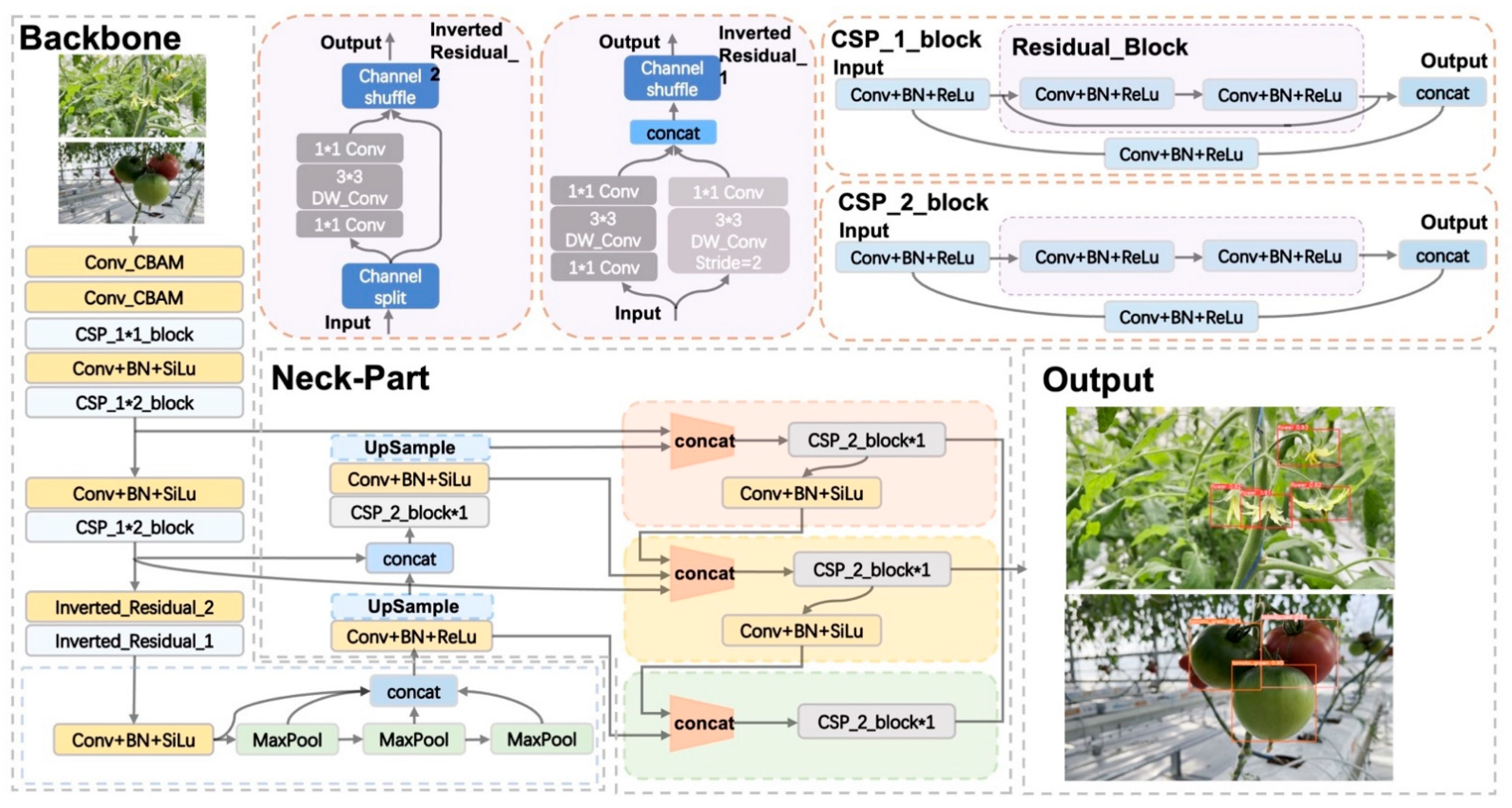
2.2. YOLO-Deepsort Model
2.2.1. Object Detection Model
- 4.
- Inherited from the CSP-1-block of the original YOLOv5’s backbone, this hierarchical feature fusion mechanism of the CSP structure effectively strengthens the learning ability of the convolutional neural network. It reduces the number of parameters of the network. Using the CSP structure can effectively alleviate the problem of gradient disappearance. In addition, the CSP structure is nested by multiple residual structures [35]. The basic module in the residual structure is CBL (convolution, batch normalization, SiLu).
- 5.
- The SPPF structure is used to replace the SPP (spatial pyramid pooling) structure as the output of the last layer of the backbone [36]. The feature map level fusion of local and global features is achieved through the SPPF module. In addition, the SPPF structure dramatically improves the speed of network operations and the feature information-carrying capacity of feature maps.
- 6.
- The feature vector extracted by the shallow network often contains rich location information, such as contours and texture information. In contrast, the feature vectors extracted by deep feature extraction networks often contain rich semantic information and less location information. The location information determines the prediction accuracy of the target location, and the semantic information determines the accuracy of the target category prediction. Our model uses BiFPN [34] as the Neck-Part of the network to maximize the use of the feature information.
- 7.
- The Head Part is used for the final detection part, applying anchor boxes on the feature map and generating regression parameters with class probability, target probability score, and bounding box [15]. YOLO-deepsort has a total of three heads. The scales of these heads are (80 × 80 × 21) (40 × 40 × 21) (20 × 20 × 21), each head has a total of (classes + confidence + coordinate offsets (dx, dy, dw, dh)) × 3 anchor boxes, a total of 21 channels.
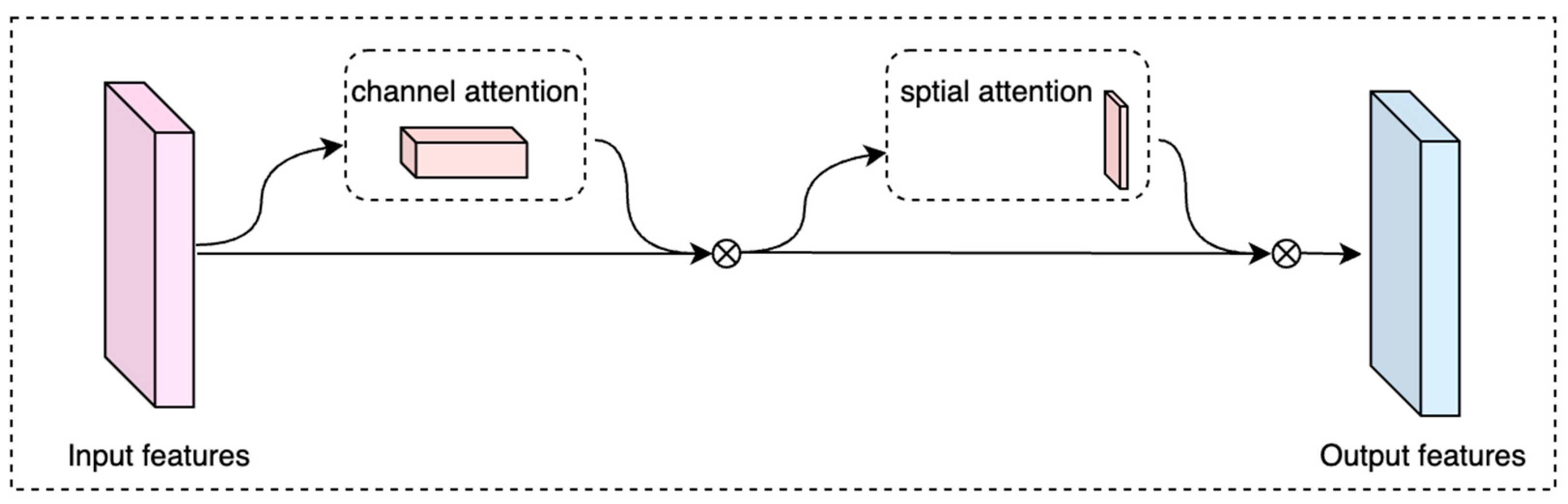
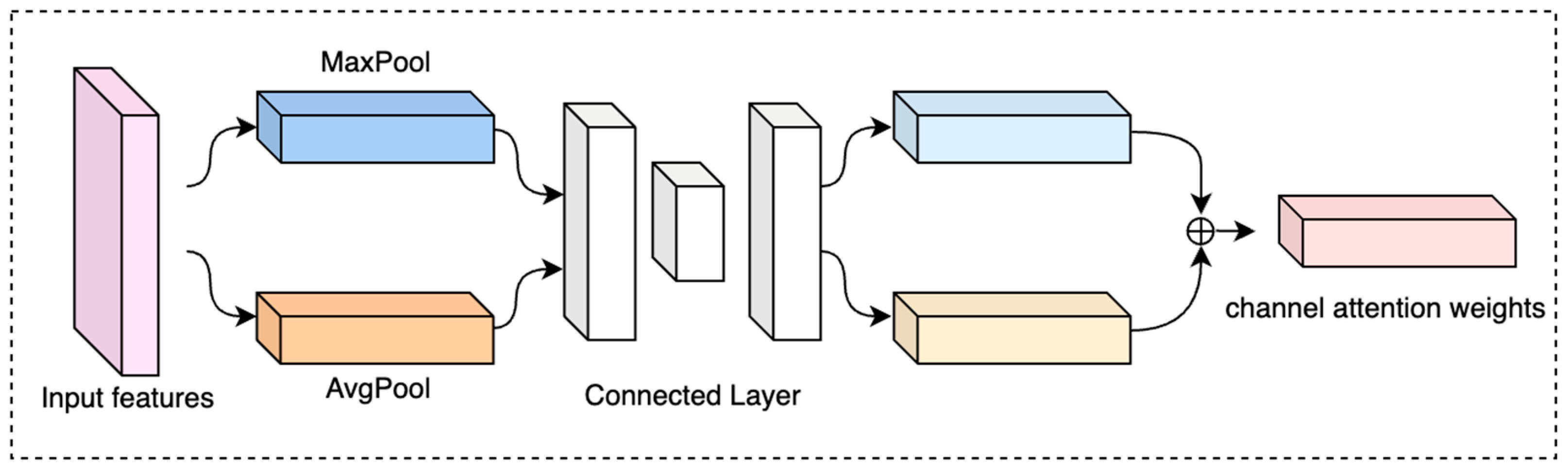
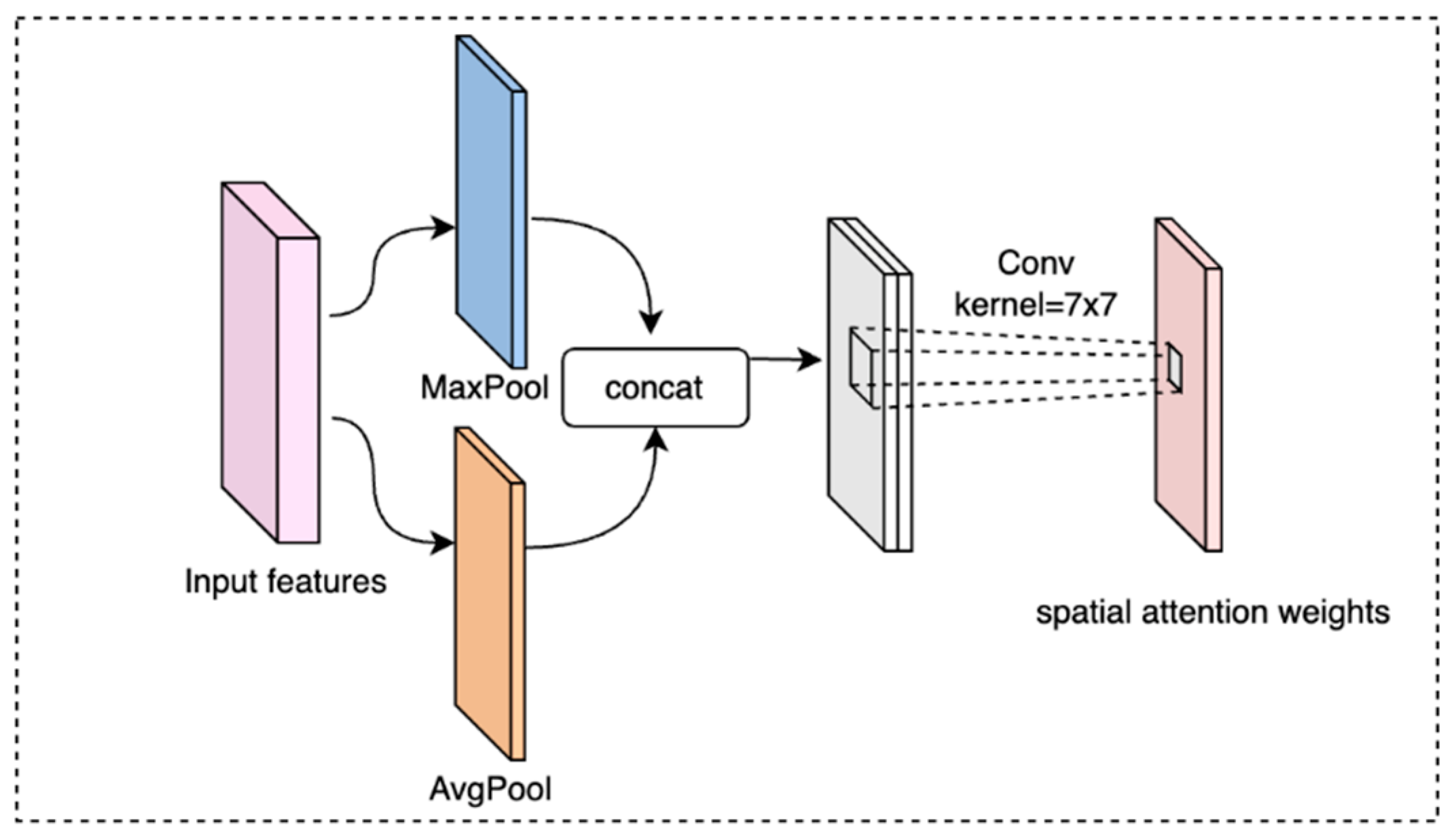
2.2.2. Attention Module
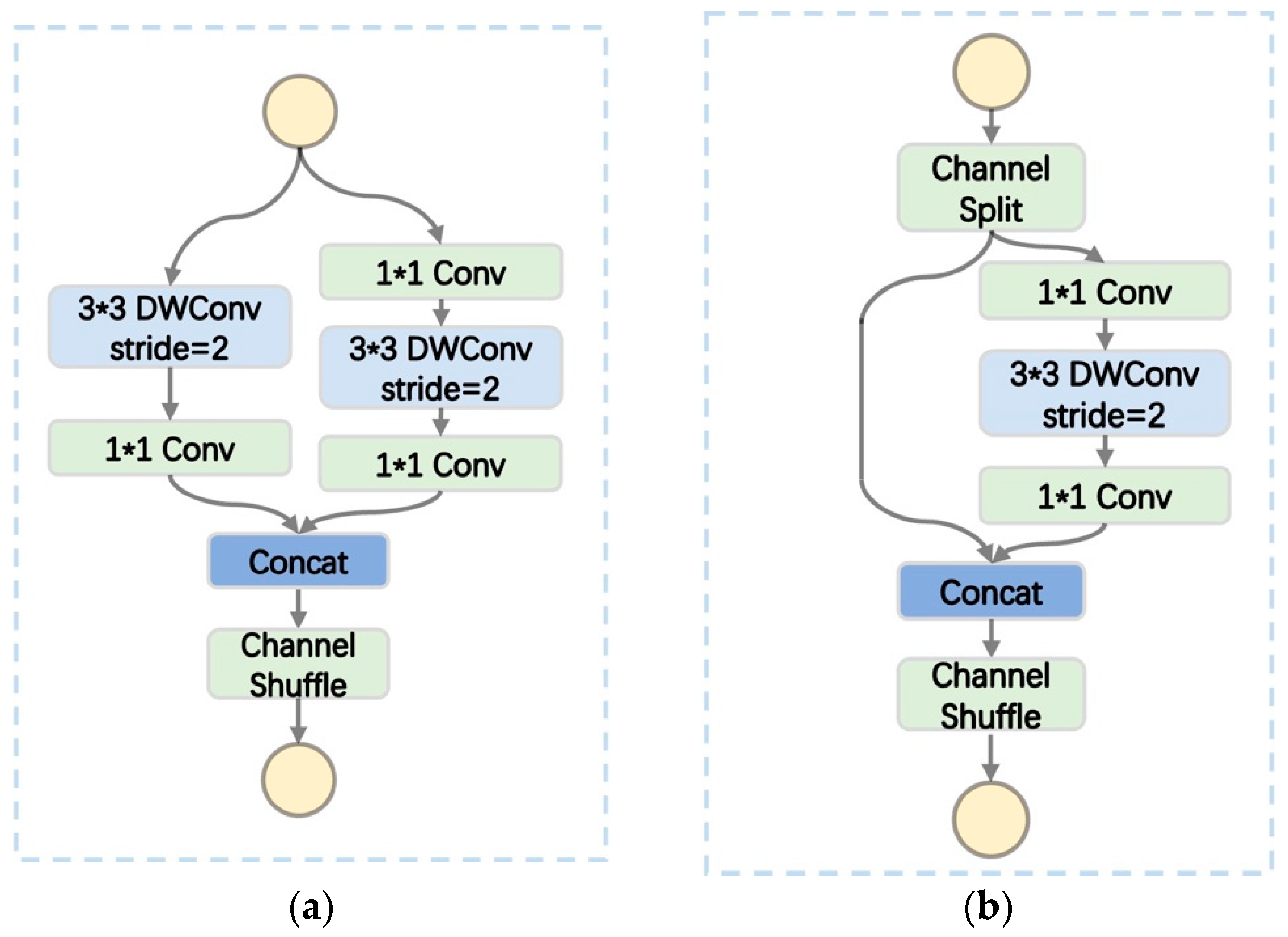
2.2.3. Lightweight Module
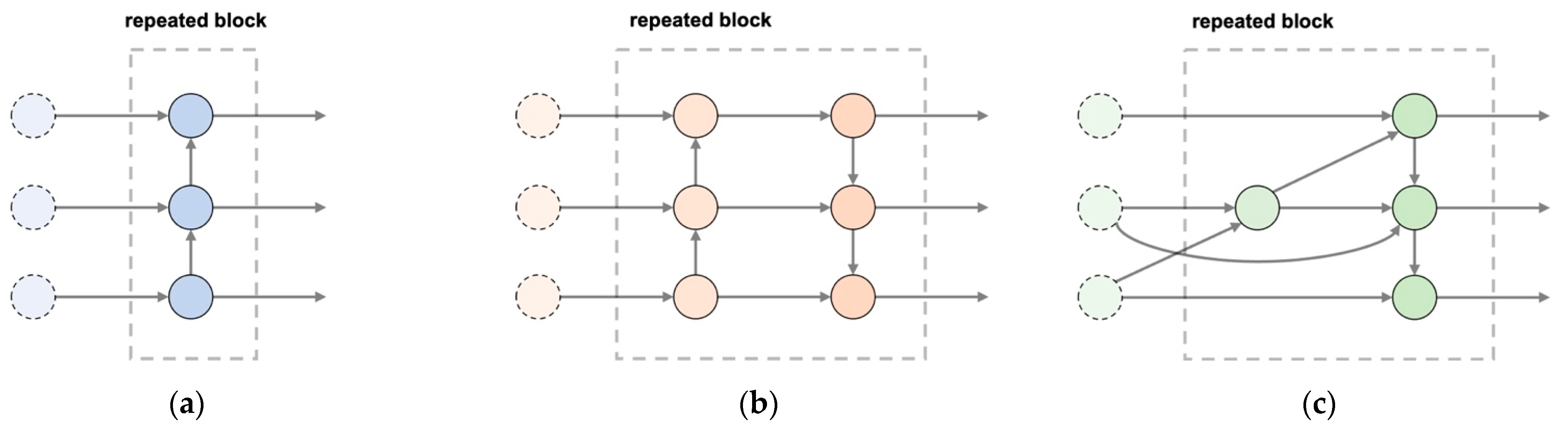
2.2.4. BiFPN Module
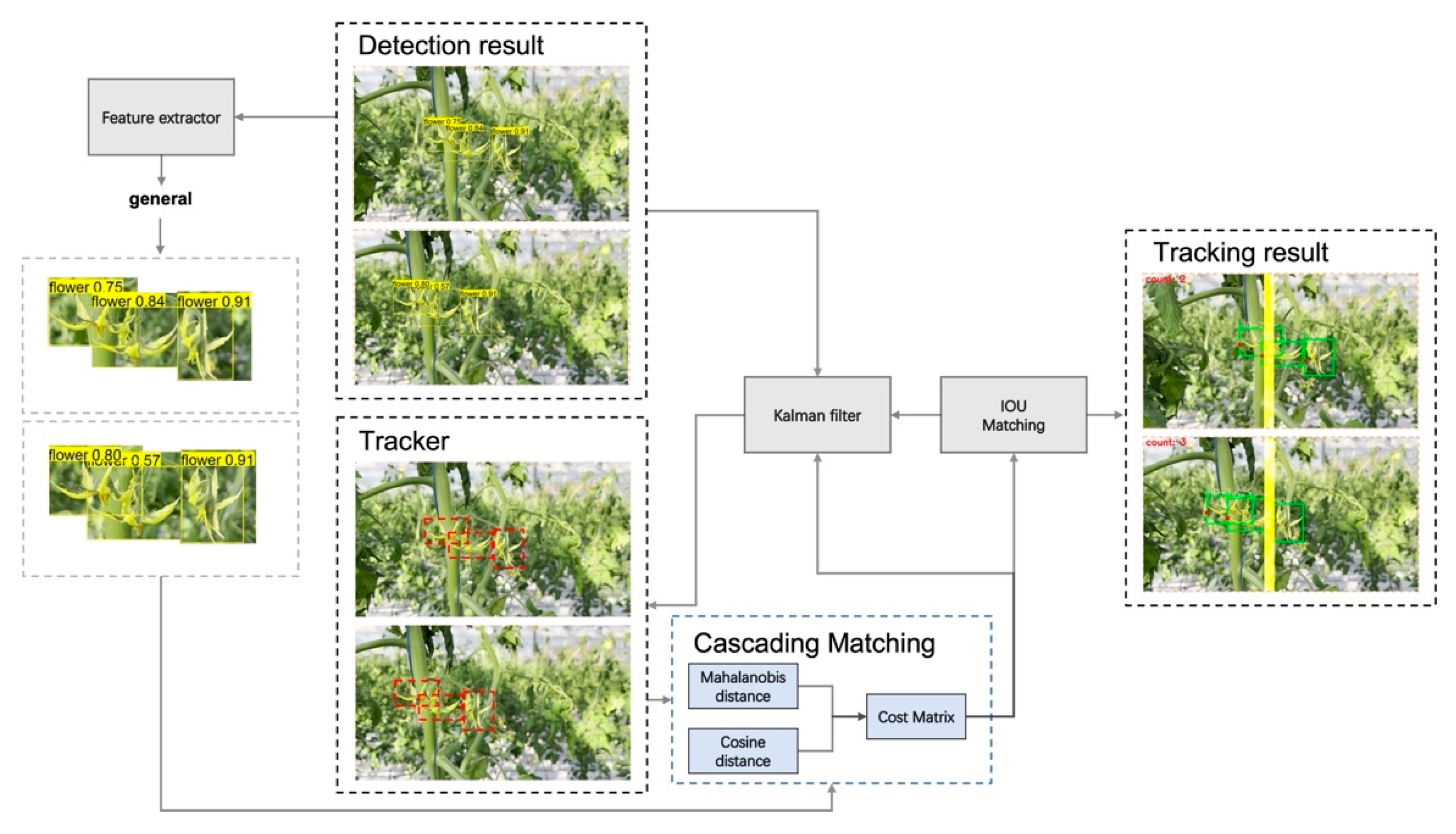
2.2.5. DeepSort Model
- 8.
- Prediction: When the target passes through a building, parameters such as the target frame position and speed of the current frame are predicted through parameters such as the target frame and speed of the previous frame.
- 9.
- Update: The predicted and observed values, the two states of the normal distribution, are linearly weighted to obtain the state predicted by the current system.
2.3. Evaluation of Model Performance
- TP(True Positive): the prediction result and ground truth are positive samples
- FP(False Positive): the detection result is negative, but the prediction result is true
- TN(True Negative): the prediction result and ground truth are both negative samples
- FN(False Negative): the detection result is positive instead of negative
3. Results
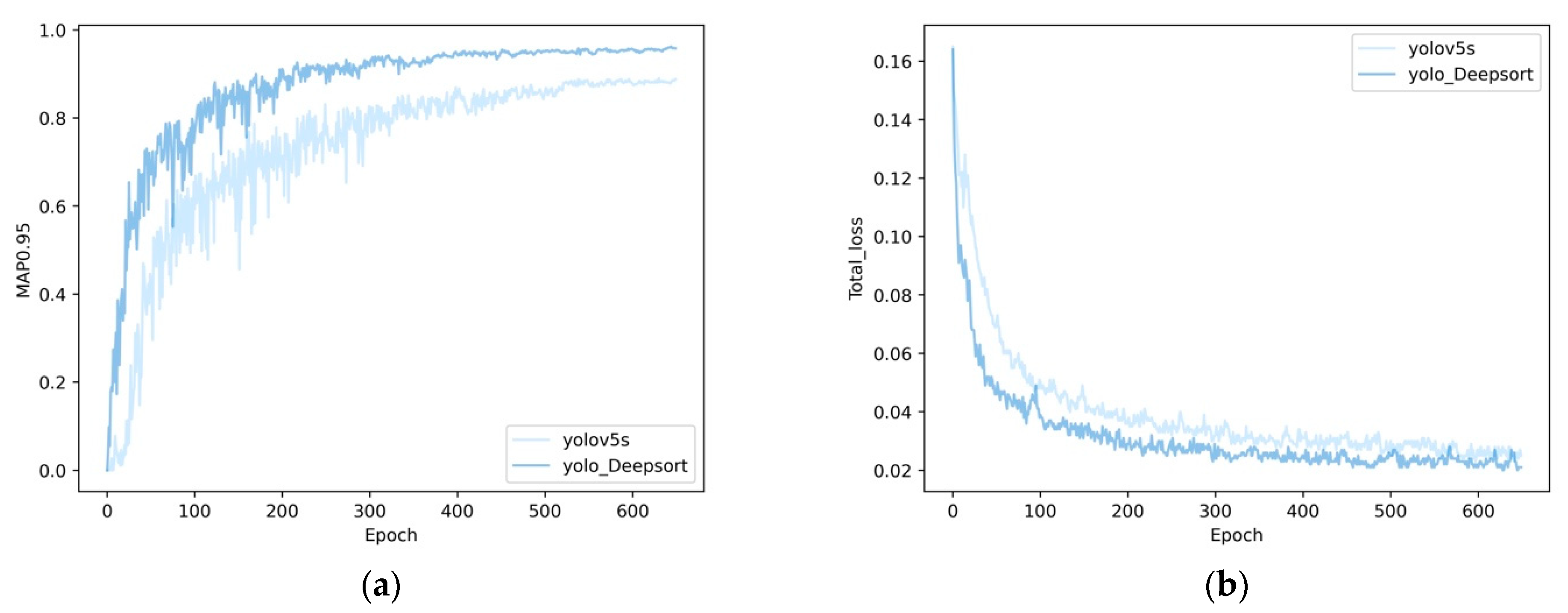
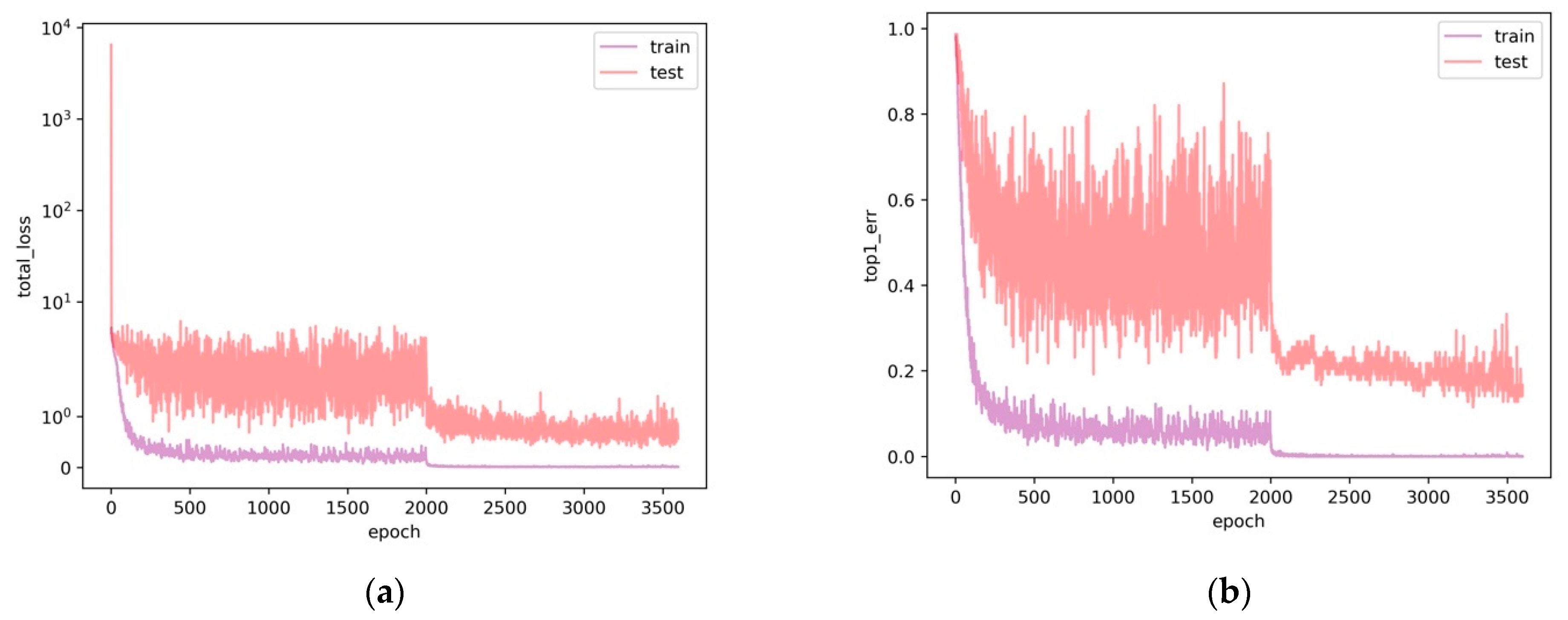
3.1. Object Detection Part Training
3.2. Object Detection Part Result
3.3. Object Tracking Part
4. Discussion
4.1. Comparison with Other Object Detection Methods
4.2. Comparison with Other Object Lightweight Methods
4.3. Performance of Object Tracking and Counting
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhou, L.; Song, L.; Xie, C.; Zhang, J. Applications of Internet of Things in the Facility Agriculture. In Computer and Computing Technologies in Agriculture VI. CCTA 2012. IFIP Advances in Information and Communication Technology; Li, D., Chen, Y., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; Volume 392. [Google Scholar] [CrossRef] [Green Version]
- Jin, X.-B.; Yu, X.-H.; Wang, X.-Y.; Bai, Y.-T.; Su, T.-L.; Kong, J.-L. Deep Learning Predictor for Sustainable Precision Agriculture Based on Internet of Things System. Sustainability 2020, 12, 1433. [Google Scholar] [CrossRef] [Green Version]
- Yin, H.; Chai, Y.; Yang, S.X.; Mittal, G.S. Ripe Tomato Recognition and Localization for a Tomato Harvesting Robotic System. In Proceedings of the 2009 International Conference of Soft Computing and Pattern Recognition, Washington, DC, USA, 4–7 December 2009; pp. 557–562. [Google Scholar] [CrossRef]
- Suykens, J.; Vandewalle, J. Least Squares Support Vector Machine Classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Liu, G.; Mao, S.; Kim, J.H. A Mature-Tomato Detection Algorithm Using Machine Learning and Color Analysis. Sensors 2019, 19, 2023. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Amarante, M.A.; Ang, A.; Garcia, R.; Garcia, R.G.; Martin, E.M.; Valiente, L.F.; Valiente, L., Jr.; Vigila, S. Determination of Ripening Stages and Nutritional Content of Tomatoes Using Color Space Conversion Algorithm, Processed Through Raspberry Pi. In Proceedings of the International Conference on Biomedical Engineering and Technology, Tokyo, Japan, 15–18 September 2020. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. 2022, 44, 154–180. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ko, K.; Jang, I.; Choi, J.H.; Lim, J.H.; Lee, D.U. Stochastic Decision Fusion of Convolutional Neural Networks for Tomato Ripeness Detection in Agricultural Sorting Systems. Sensors 2021, 21, 917. [Google Scholar] [CrossRef]
- Seo, D.; Cho, B.-H.; Kim, K.-C. Development of Monitoring Robot System for Tomato Fruits in Hydroponic Greenhouses. Agronomy 2021, 11, 2211. [Google Scholar] [CrossRef]
- Liu, G.; Nouaze, J.C.; Touko Mbouembe, P.L.; Kim, J.H. YOLO-Tomato: A Robust Algorithm for Tomato Detection Based on YOLOv3. Sensors 2020, 20, 2145. [Google Scholar] [CrossRef] [Green Version]
- Magalhães, S.A.; Castro, L.; Moreira, G.; dos Santos, F.N.; Cunha, M.; Dias, J.; Moreira, A.P. Evaluating the Single-Shot MultiBox Detector and YOLO Deep Learning Models for the Detection of Tomatoes in a Greenhouse. Sensors 2021, 21, 3569. [Google Scholar] [CrossRef]
- Sun, J.; He, X.; Ge, X.; Wu, X.; Shen, J.; Song, Y. Detection of Key Organs in Tomato Based on Deep Migration Learning in a Complex Background. Agriculture 2018, 8, 196. [Google Scholar] [CrossRef] [Green Version]
- Dzmitry, B.; Kyunghyun, C.; Yoshua, B. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2015, arXiv:1409.0473. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Chen, Z.; Wu, R.; Lin, Y.; Li, C.; Chen, S.; Yuan, Z.; Chen, S.; Zou, X. Plant Disease Recognition Model Based on Improved YOLOv5. Agronomy 2022, 12, 365. [Google Scholar] [CrossRef]
- Yang, B.; Gao, Z.; Gao, Y.; Zhu, Y. Rapid Detection and Counting of Wheat Ears in the Field Using YOLOv4 with Attention Module. Agronomy 2021, 11, 1202. [Google Scholar] [CrossRef]
- Lu, S.; Song, Z.; Chen, W.; Qian, T.; Zhang, Y.; Chen, M.; Li, G. Counting Dense Leaves under Natural Environments via an Improved Deep-Learning-Based Object Detection Algorithm. Agriculture 2021, 11, 1003. [Google Scholar] [CrossRef]
- Xia, X.; Chai, X.; Zhang, N.; Zhang, Z.; Sun, Q.; Sun, T. Culling Double Counting in Sequence Images for Fruit Yield Estimation. Agronomy 2022, 12, 440. [Google Scholar] [CrossRef]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar] [CrossRef] [Green Version]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar] [CrossRef] [Green Version]
- Buslaev, A.; Parinov, A.; Khvedchenya, E.; Iglovikov, V.I.; Kalinin, A.A. Albumentations: Fast and flexible image augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef] [Green Version]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 6023–6032. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Wang, C.Y.; Liao, H.-Y.M.; Wu, Y.; Chen, P.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 1571–1580. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An extremely efficient convolutional neural network for mobile devices. arXiv 2017, arXiv:1707.01083v2. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Kalman, R.E. A new approach to linear filtering and prediction problems. J. Fluids Eng. 1960, 82, 35–45. [Google Scholar] [CrossRef] [Green Version]
- De Maesschalck, R.; Delphine, J.-R.; Massart, D.L. The mahalanobis distance. Chemom. Intell. Lab. Syst. 2000, 50, 1–18. [Google Scholar] [CrossRef]
- Wright, M.B. Speeding up the Hungarian algorithm. Comput. Oper. Res. 1990, 17, 95–96. [Google Scholar] [CrossRef]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Flower | Tomato_Red | Tomato_Green | Total |
|---|---|---|---|---|
| Train set | 1640 | 669 | 1138 | 3447 |
| Test set | 164 | 68 | 139 | 371 |
| From | n | Params | Module | Arguments | |
|---|---|---|---|---|---|
| 0 | −1 | 1 | 3746 | Conv_CBAM | [3, 32, 6, 2, 2] |
| 1 | −1 | 1 | 19,170 | Conv_CBAM | [32, 64, 3, 2] |
| 2 | −1 | 1 | 18,816 | CSP_1*1_block | [64, 64, 1] |
| 3 | −1 | 1 | 73,984 | Conv + BN + SiLu | [64, 128, 3, 2] |
| 4 | −1 | 2 | 115,712 | CSP_1*1_block | [128, 128, 2] |
| 5 | −1 | 1 | 295,424 | Conv + BN + SiLu | [128, 256, 3, 2] |
| 6 | −1 | 3 | 625,152 | CSP_1*1_block | [256, 256, 3] |
| 7 | −1 | 1 | 203,776 | Inverted_Residual_2 | [256, 512, 2] |
| 8 | −1 | 1 | 134,912 | Inverted_Residual_1 | [512, 512, 1] |
| 9 | −1 | 1 | 656,896 | SPPF | [512, 512, 5] |
| 10 | −1 | 1 | 131,584 | Conv + BN + SiLu | [512, 256, 1, 1] |
| 11 | −1 | 1 | 0 | Upsample | |
| 12 | [−1, 6] | 1 | 0 | Concat | [1] |
| 13 | −1 | 1 | 361,984 | CSP_2*1_block | [512, 256, 1] |
| 14 | −1 | 1 | 33,024 | Conv + BN + SiLu | [256, 128, 1, 1] |
| 15 | −1 | 1 | 0 | Upsample | |
| 16 | [−1, 6, 14] | 1 | 0 | Concat | [1] |
| 17 | −1 | 1 | 90,880 | CSP_2*1_block | [256, 128, 1] |
| 18 | −1 | 1 | 147,712 | Conv + BN + SiLu | [128, 128, 3, 2] |
| 19 | [−1, 6, 14] | 1 | 0 | Concat | [1] |
| 20 | −1 | 1 | 361,984 | CSP_2*1_block | [512, 256, 1] |
| 21 | −1 | 1 | 590,336 | Conv + BN + SiLu | [256, 256, 3, 2] |
| 22 | [−1, 10] | 1 | 0 | Concat | [1] |
| 23 | −1 | 1 | 1,182,720 | CSP_2*1_block | [512, 512, 1] |
| 24 | [17, 20, 23] | 1 | 21,576 | Detect |
| Hyperparameter | Selection | Notice |
|---|---|---|
| learning rate | SGD [43] | If the learning rate is too high or too low, the optimization of the model will fail. |
| momentum | 0.937 | Speed up convergence, jump out of the extreme point and avoid falling into the local optimal solution |
| weight_decay | 0.0005 | Constrain the number of parameters, prevent model overfitting |
| batch size | 8 | Updating the weight every 8 images per iteration |
| box | 0.05 | In most cases, the loss function hyperparameters may affect the optimization. Inappropriate hyperparameters will make it challenging to optimize the model even if the loss function is very suitable for the target optimization. |
| cls | 0.5 | |
| cls_pw | 1.0 | |
| obj | 1.0 | |
| obj_pw | 1.0 | |
| Iou_t | 0.2 | |
| anchor_t | 4.0 |
| Model | Precision | Recall | F1-Score | mAP (0.5:0.95) | Parameters |
|---|---|---|---|---|---|
| YOLOv5 s | 99.5% | 90.6% | 94.8% | 88.7% | 7,018,216 |
| YOLOv5 m | 99.5% | 95.3% | 97.4% | 91.6% | 13,354,682 |
| YOLOv5 l | 99.5% | 94.1% | 96.7% | 91.6% | 46,119,048 |
| YOLO-deepsort | 99.5% | 98.4% | 98.9% | 95.8% | 5,072,848 |
| Model | Input_Size | Params | Size(M) | Percision | mAP(0.5:0.95) |
|---|---|---|---|---|---|
| YOLO_nano | 416 × 416 | - | 34.8 | 30.5% | 15.4% |
| YOLOv3-tiny | 416 × 416 | 8.67 M | 17.4 | 95.7% | 86.7% |
| YOLOv5 n | 640 × 640 | 1.76 M | 3.8 | 96.7% | 85.4% |
| YOLOv5_Lite | 640 × 640 | 5.39 M | 10.9 | 99.2% | 91.3% |
| YOLO-deepsort | 640 × 640 | 5.07 M | 10.5 | 99.5% | 95.8% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ge, Y.; Lin, S.; Zhang, Y.; Li, Z.; Cheng, H.; Dong, J.; Shao, S.; Zhang, J.; Qi, X.; Wu, Z. Tracking and Counting of Tomato at Different Growth Period Using an Improving YOLO-Deepsort Network for Inspection Robot. Machines 2022, 10, 489. https://doi.org/10.3390/machines10060489
Ge Y, Lin S, Zhang Y, Li Z, Cheng H, Dong J, Shao S, Zhang J, Qi X, Wu Z. Tracking and Counting of Tomato at Different Growth Period Using an Improving YOLO-Deepsort Network for Inspection Robot. Machines. 2022; 10(6):489. https://doi.org/10.3390/machines10060489
Chicago/Turabian StyleGe, Yuhao, Sen Lin, Yunhe Zhang, Zuolin Li, Hongtai Cheng, Jing Dong, Shanshan Shao, Jin Zhang, Xiangyu Qi, and Zedong Wu. 2022. "Tracking and Counting of Tomato at Different Growth Period Using an Improving YOLO-Deepsort Network for Inspection Robot" Machines 10, no. 6: 489. https://doi.org/10.3390/machines10060489
APA StyleGe, Y., Lin, S., Zhang, Y., Li, Z., Cheng, H., Dong, J., Shao, S., Zhang, J., Qi, X., & Wu, Z. (2022). Tracking and Counting of Tomato at Different Growth Period Using an Improving YOLO-Deepsort Network for Inspection Robot. Machines, 10(6), 489. https://doi.org/10.3390/machines10060489