
Fault Detection for High-Speed Trains Using CCA and Just-in-Time Learning



Abstract
:1. Introduction
2. Preliminaries
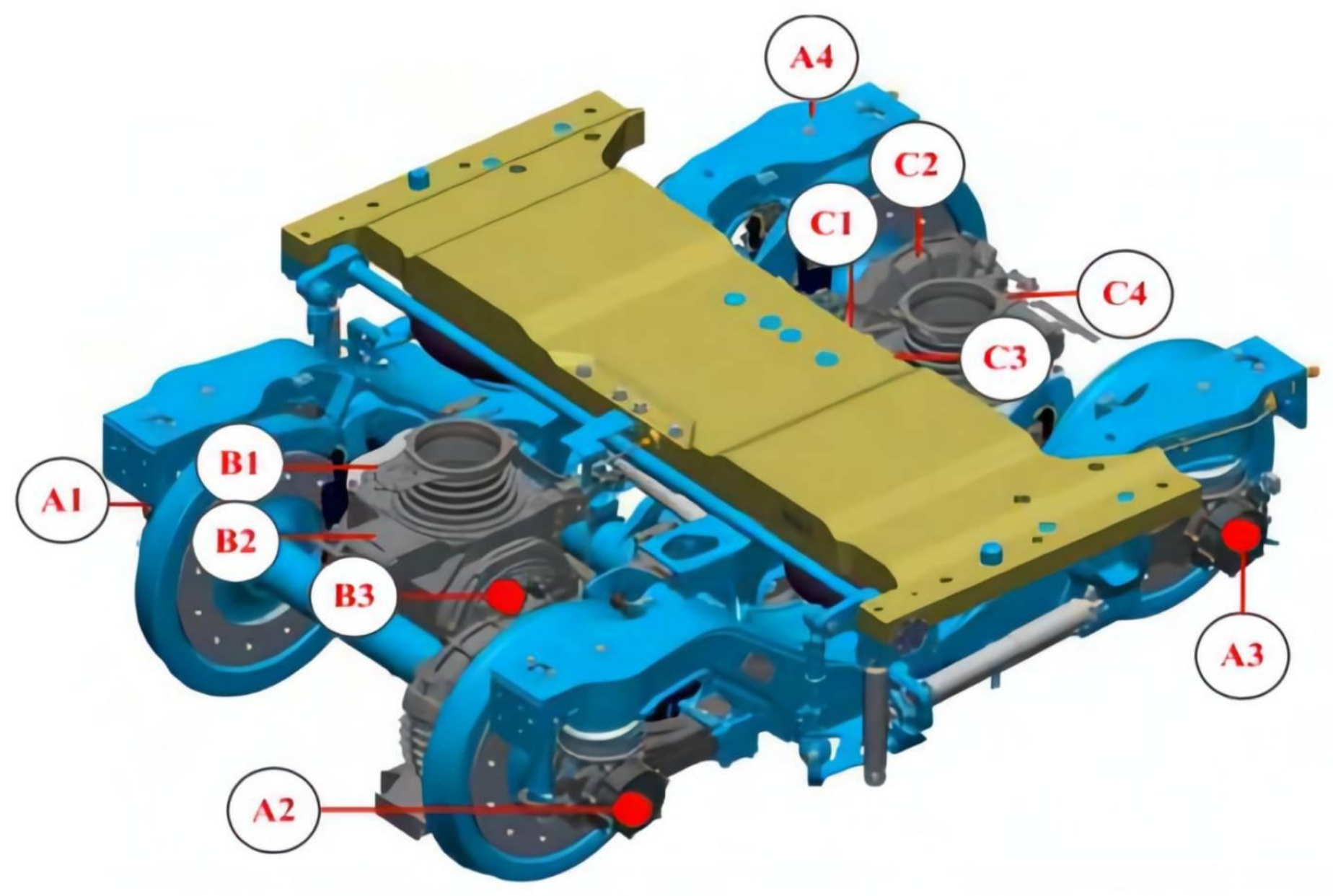
2.1. Introduction of a Running Gears System of a High-Speed Train
2.2. Fault Description
2.3. Objective and Design Issues
- Investigate effective data processing techniques, and maintain the original trend of the data.
- Design a series of statistical tests for model evaluation.
- Design a use case and apply the proposed method.
2.4. System Design
3. Methodology
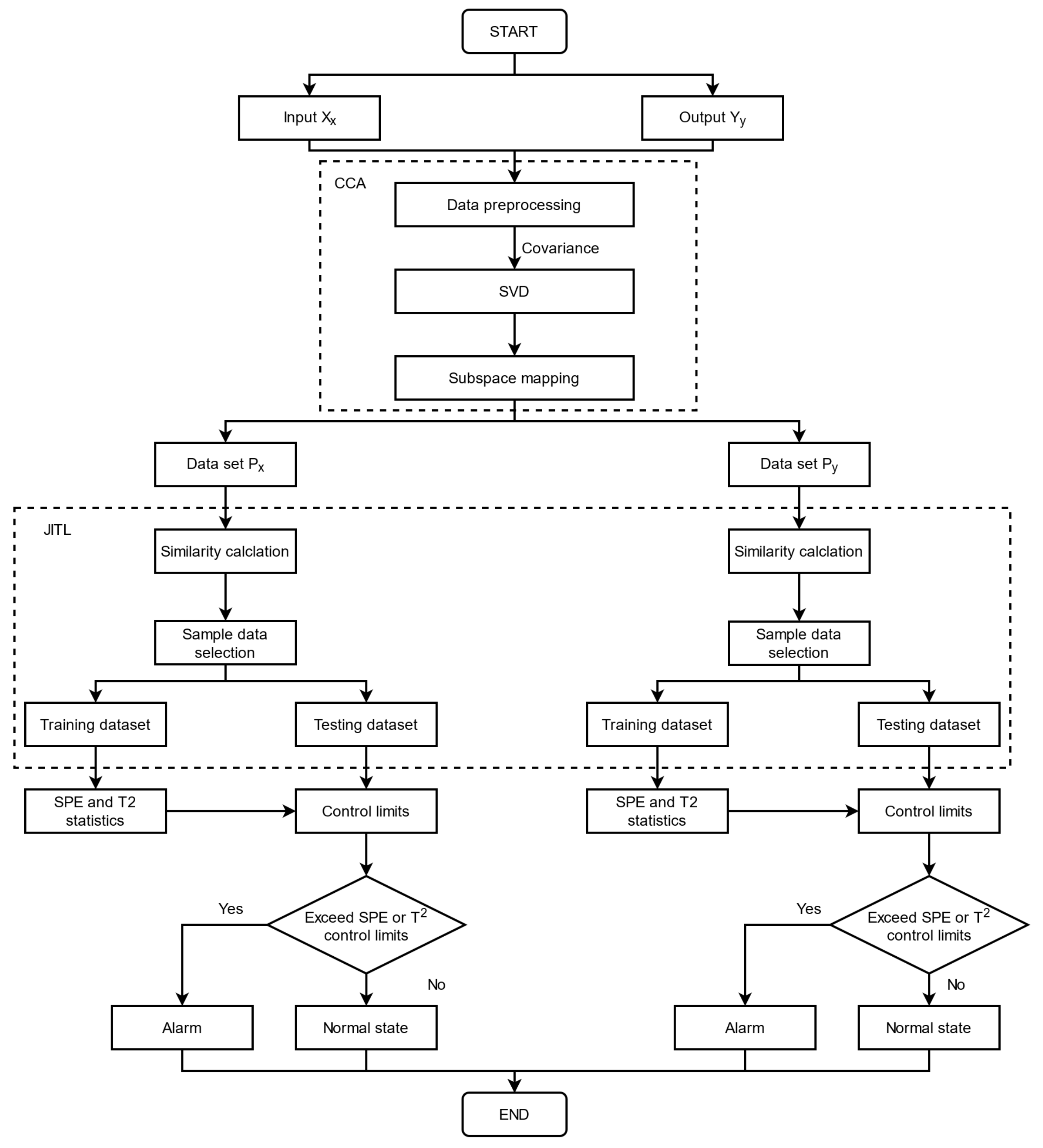
3.1. Canonical Correlation Analysis and Just-in-Time Learning Methods
3.2. Monitoring Statistics of FD Models
3.3. Offline Training and Online Detection Algorithms
| Algorithm 1 Offline training |
1: Normalize the measurement data. 2: The data is divided into two data matrices via CCA model. 3: The JITL model is used to improve accuracy of data fitting. 4: Find the thresholds and associated with the data matrix , and the thresholds and associated with the data matrix . |
| Algorithm 2 Online detection |
1: The collected fault data is normalized. 2: Find the two data matrices. 3: The JITL model is used to improve accuracy of data fitting. 4: Calculate SPE and via (11) and (12). 5: Determine whether a fault occurs comparing the test statistic with the thresholds. |
3.4. System Evaluation Methodology
4. Experimental Results and Discussion
4.1. Experimental Verification
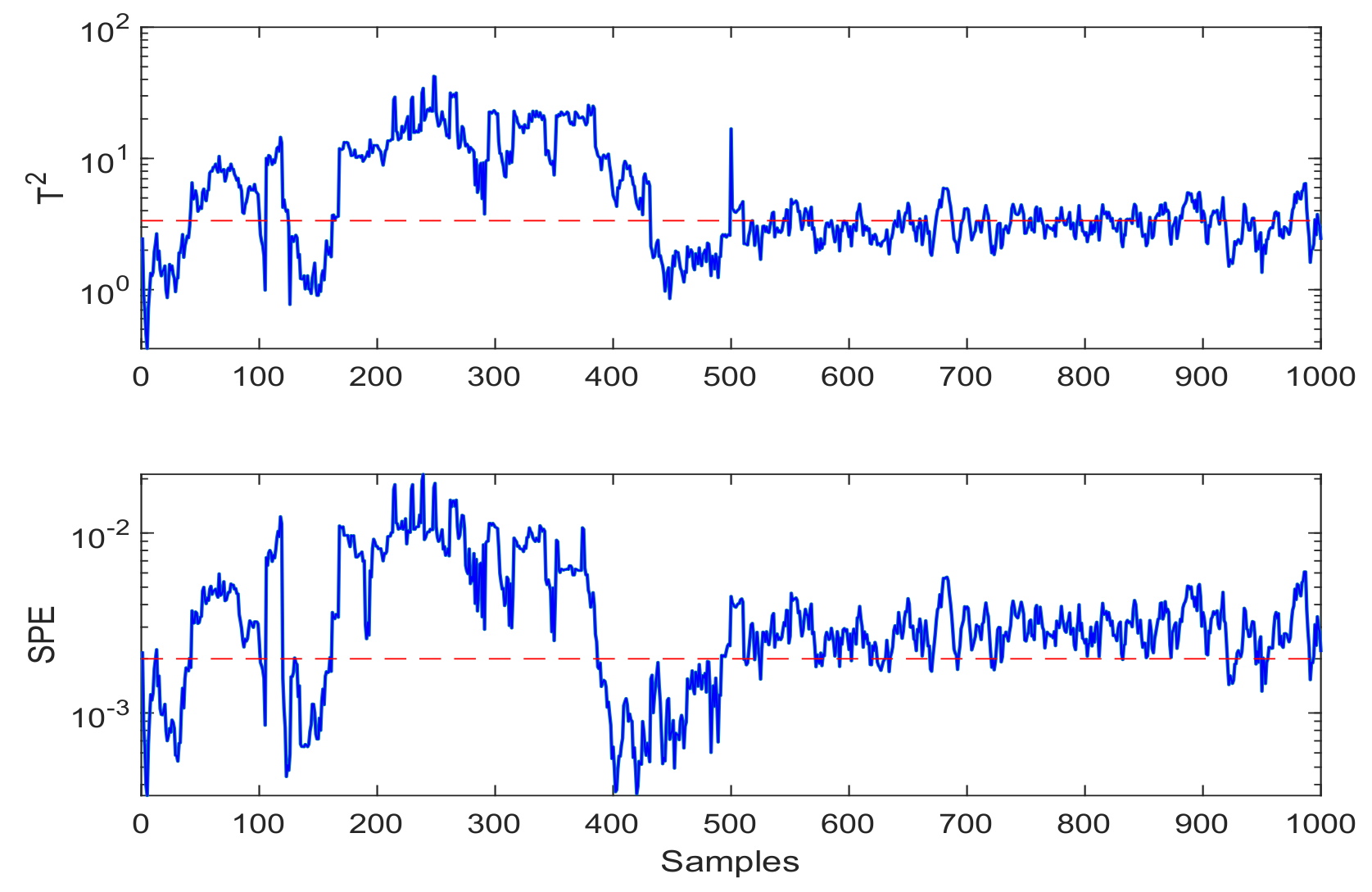
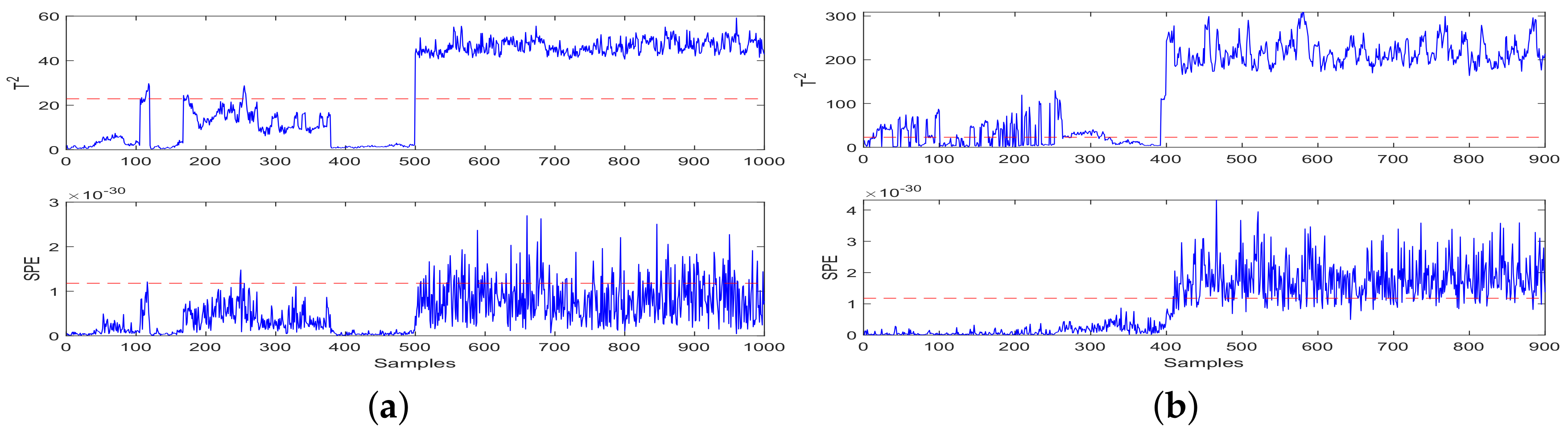
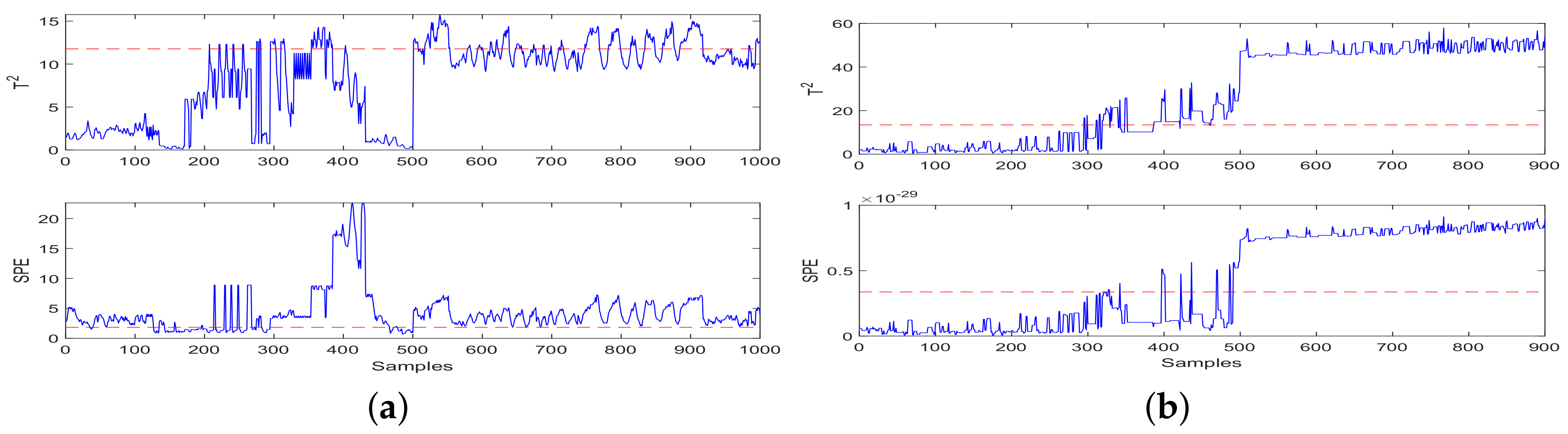
- Fault Injection: Under the given speed 1000 r/min of high-speed trains, 1000 × 8 samples under health and fault conditions are collected from eight sensors as data sets. Fault data was injected from the 500th data points of the sample test dataset.
- Fault Detection: Fault detection results of CCA-JITL are shown in Figure 4 where red dashed lines are thresholds and blue sold lines are test statistics.
4.2. Discussions
5. Conclusions and Future Studies
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, H.; Jiang, B. A Review of Fault Detection and Diagnosis for the Traction System in High-Speed Trains. IEEE Trans. Intell. Transp. Syst. 2020, 21, 450–465. [Google Scholar] [CrossRef]
- Gao, S.; Hou, Y.; Dong, H.; Stichel, S.; Ning, B. High-speed trains automatic operation with protection constraints: A resilient nonlinear gain-based feedback control approach. IEEE/CAA J. Autom. Sin. 2019, 6, 992–999. [Google Scholar] [CrossRef]
- Chen, L.; Hu, X.; Tian, W.; Wang, H.; Cao, D.; Wang, F.Y. Parallel planning: A new motion planning framework for autonomous driving. IEEE/CAA J. Autom. Sin. 2019, 6, 236–246. [Google Scholar] [CrossRef]
- Chen, H.; Jiang, B.; Ding, S.X.; Huang, B. Data-Driven Fault Diagnosis for Traction Systems in High-Speed Trains: A Survey, Challenges, and Perspectives. IEEE Trans. Intell. Transp. Syst. 2022, 23, 1700–1716. [Google Scholar] [CrossRef]
- Ran, G.; Liu, J.; Li, C.; Lam, H.K.; Li, D.; Chen, H. Fuzzy-Model-Based Asynchronous Fault Detection for Markov Jump Systems with Partially Unknown Transition Probabilities: An Adaptive Event-Triggered Approach. IEEE Trans. Fuzzy Syst. 2022, 1. [Google Scholar] [CrossRef]
- Chen, H.; Chen, Z.; Chai, Z.; Jiang, B.; Huang, B. A Single-Side Neural Network-Aided Canonical Correlation Analysis With Applications to Fault Diagnosis. IEEE Trans. Cybern. 2021, 1–13. [Google Scholar] [CrossRef]
- Raveendran, R.; Kodamana, H.; Huang, B. Process monitoring using a generalized probabilistic linear latent variable model. Automatica 2018, 96, 73–83. [Google Scholar] [CrossRef]
- Ge, Z.; Song, Z.; Ding, S.X.; Huang, B. Data Mining and Analytics in the Process Industry: The Role of Machine Learning. IEEE Access 2017, 5, 20590–20616. [Google Scholar] [CrossRef]
- Li, X.; Yang, Y.; Pan, H.; Cheng, J.; Cheng, J. A novel deep stacking least squares support vector machine for rolling bearing fault diagnosis. Comput. Ind. 2019, 110, 36–47. [Google Scholar] [CrossRef]
- Zhu, Q.; Qin, S.J. Supervised Diagnosis of Quality and Process Faults with Canonical Correlation Analysis. Ind. Eng. Chem. Res. 2019, 58, 11213–11223. [Google Scholar] [CrossRef]
- Jiang, Q.; Yan, X. Learning Deep Correlated Representations for Nonlinear Process Monitoring. IEEE Trans. Ind. Inform. 2019, 15, 6200–6209. [Google Scholar] [CrossRef]
- Chen, Z.; Ding, S.X.; Peng, T.; Yang, C.; Gui, W. Fault Detection for Non-Gaussian Processes Using Generalized Canonical Correlation Analysis and Randomized Algorithms. IEEE Trans. Ind. Electron. 2018, 65, 1559–1567. [Google Scholar] [CrossRef]
- Peng, X.; Ding, S.X.; Du, W.; Zhong, W.; Qian, F. Distributed process monitoring based on canonical correlation analysis with partly-connected topology. Control Eng. Pract. 2020, 101, 104500. [Google Scholar] [CrossRef]
- Chen, H.; Li, L.; Shang, C.; Huang, B. Fault Detection for Nonlinear Dynamic Systems With Consideration of Modeling Errors: A Data-Driven Approach. IEEE Trans. Cybern. 2022, 1–11. [Google Scholar] [CrossRef]
- Garramiola, F.; Poza, J.; Madina, P.; del Olmo, J.; Ugalde, G. A Hybrid Sensor Fault Diagnosis for Maintenance in Railway Traction Drives. Sensors 2020, 20, 962. [Google Scholar] [CrossRef] [Green Version]
- Kou, L.; Qin, Y.; Zhao, X.; Chen, X. A Multi-Dimension End-to-End CNN Model for Rotating Devices Fault Diagnosis on High-Speed Train Bogie. IEEE Trans. Veh. Technol. 2020, 69, 2513–2524. [Google Scholar] [CrossRef]
- Zhao, R.; Yan, R.; Chen, Z.; Mao, K.; Wang, P.; Gao, R.X. Deep learning and its applications to machine health monitoring. Mech. Syst. Signal Process. 2019, 115, 213–237. [Google Scholar] [CrossRef]
- Niu, G.; Xiong, L.; Qin, X.; Pecht, M. Fault detection isolation and diagnosis of multi-axle speed sensors for high-speed trains. Mech. Syst. Signal Process. 2019, 131, 183–198. [Google Scholar] [CrossRef]
- Fu, Y.; Huang, D.; Qin, N.; Liang, K.; Yang, Y. High-Speed Railway Bogie Fault Diagnosis Using LSTM Neural Network. In Proceedings of the 2018 37th Chinese Control Conference (CCC), Wuhan, China, 25–27 July 2018; pp. 5848–5852. [Google Scholar] [CrossRef]
- Cheng, C.; Guo, Y.; Wang, J.h.; Chen, H.; Shao, J. A Unified BRB-based Framework for Real-Time Health Status Prediction in High-Speed Trains. IEEE Trans. Veh. Technol. 2022, 1. [Google Scholar] [CrossRef]
- Guan, S.; Huang, D.; Guo, S.; Zhao, L.; Chen, H. An Improved Fault Diagnosis Approach Using LSSVM for Complex Industrial Systems. Machines 2022, 10, 443. [Google Scholar] [CrossRef]
- Sayyad, S.; Kumar, S.; Bongale, A.; Kamat, P.; Patil, S.; Kotecha, K. Data-Driven Remaining Useful Life Estimation for Milling Process: Sensors, Algorithms, Datasets, and Future Directions. IEEE Access 2021, 9, 110255–110286. [Google Scholar] [CrossRef]
- Capriglione, D.; Carratù, M.; Pietrosanto, A.; Sommella, P. Online Fault Detection of Rear Stroke Suspension Sensor in Motorcycle. IEEE Trans. Instrum. Meas. 2019, 68, 1362–1372. [Google Scholar] [CrossRef]
- Shabanian, M.; Montazeri, M. A neuro-fuzzy online fault detection and diagnosis algorithm for nonlinear and dynamic systems. Int. J. Control. Autom. Syst. 2011, 9, 665–670. [Google Scholar] [CrossRef]
- Yan, B.; Yu, F.; Huang, B. Generalization and comparative studies of similarity measures for Just-in-Time modeling. IFAC-PapersOnLine 2019, 52, 760–765. [Google Scholar] [CrossRef]
- Cheng, C.; Chiu, M.S. Nonlinear process monitoring using JITL-PCA. Chemom. Intell. Lab. Syst. 2005, 76, 1–13. [Google Scholar] [CrossRef]
- Bittanti, S.; Picci, G. Identification, Adaptation, Learning: The Science of Learning Models from Data; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1996; Volume 153. [Google Scholar]
- Yu, H.; Yin, S.; Luo, H. Robust Just-in-time Learning Approach and Its Application on Fault Detection. IFAC-PapersOnLine 2017, 50, 15277–15282. [Google Scholar] [CrossRef]
- Chen, H.; Chai, Z.; Jiang, B.; Huang, B. Data-Driven Fault Detection for Dynamic Systems with Performance Degradation: A Unified Transfer Learning Framework. IEEE Trans. Instrum. Meas. 2021, 70, 1–12. [Google Scholar] [CrossRef]
- Ran, G.; Li, C.; Lam, H.K.; Li, D.; Han, C. Event-Based Dissipative Control of Interval Type-2 Fuzzy Markov Jump Systems Under Sensor Saturation and Actuator Nonlinearity. IEEE Trans. Fuzzy Syst. 2022, 30, 714–727. [Google Scholar] [CrossRef]
- Cheng, C.; Qiao, X.; Luo, H.; Teng, W.; Gao, M.; Zhang, B.; Yin, X. A Semi-Quantitative Information Based Fault Diagnosis Method for the Running Gears System of High-Speed Trains. IEEE Access 2019, 7, 38168–38178. [Google Scholar] [CrossRef]
- Cheng, C.; Wang, J.; Teng, W.; Gao, M.; Zhang, B.; Yin, X.; Luo, H. Health Status Prediction Based on Belief Rule Base for High-Speed Train Running Gear System. IEEE Access 2019, 7, 4145–4159. [Google Scholar] [CrossRef]
- Chen, H.; Chai, Z.; Dogru, O.; Jiang, B.; Huang, B. Data-Driven Designs of Fault Detection Systems via Neural Network-Aided Learning. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–12. [Google Scholar] [CrossRef]
- Kresta, J.V.; Macgregor, J.F.; Marlin, T.E. Multivariate statistical monitoring of process operating performance. Can. J. Chem. Eng. 1991, 69, 35–47. [Google Scholar] [CrossRef]
- Wise, B.M.; Gallagher, N.B. The process chemometrics approach to process monitoring and fault detection. J. Process. Control 1996, 6, 329–348. [Google Scholar] [CrossRef]
- Chiang, L.H.; Russell, E.L.; Braatz, R.D. Fault Detection and Diagnosis in Industrial Systems; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2000. [Google Scholar]
- Kumar, D.; Ding, X.; Du, W.; Cerpa, A. Building sensor fault detection and diagnostic system. In Proceedings of the 8th ACM International Conference on Systems for Energy-Efficient Buildings, Cities, and Transportation, Coimbra, Portugal, 17–18 November 2021; pp. 357–360. [Google Scholar]
- Li, G.; Zheng, Y.; Liu, J.; Zhou, Z.; Xu, C.; Fang, X.; Yao, Q. An improved stacking ensemble learning-based sensor fault detection method for building energy systems using fault-discrimination information. J. Build. Eng. 2021, 43, 102812. [Google Scholar] [CrossRef]
- Kumar, S.; Kolekar, T.; Patil, S.; Bongale, A.; Kotecha, K.; Zaguia, A.; Prakash, C. A Low-Cost Multi-Sensor Data Acquisition System for Fault Detection in Fused Deposition Modelling. Sensors 2022, 22, 517. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
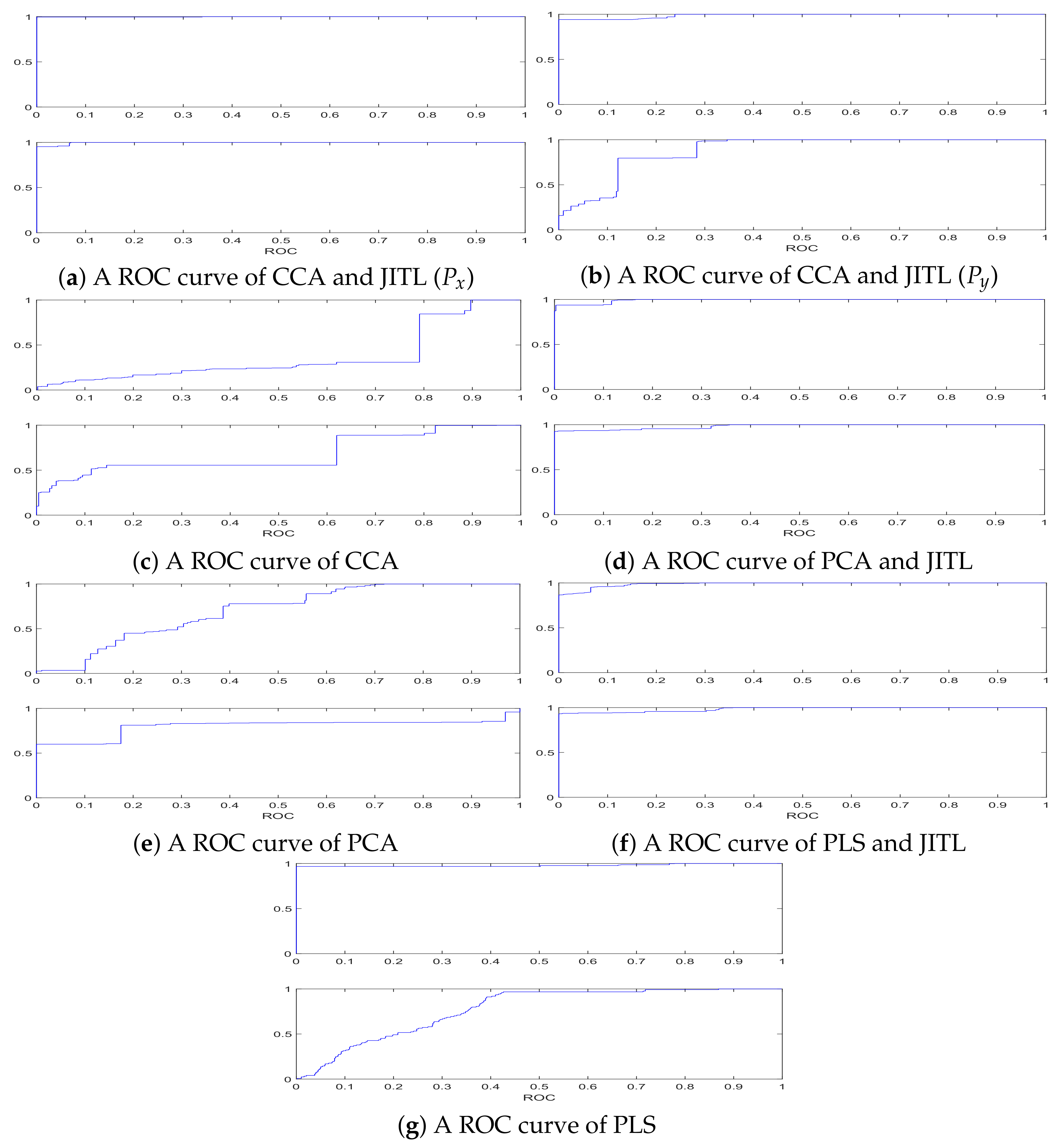
| Methods | FAR | FDR | AUC | |||
|---|---|---|---|---|---|---|
| SPE | SPE | SPE | ||||
| PLS | 8.81% | 45.69% | 100% | 17.61% | 0.9802 | 0.7729 |
| PLS and JITL | 44.75% | 0% | 100% | 82% | 0.8430 | 0.9261 |
| PCA | 14.75% | 83.5% | 41.6% | 100% | 0.5612 | 0.7708 |
| PCA and JITL | 28.26% | 7.41% | 100% | 100% | 0.9887 | 0.9798 |
| CCA | 69.8% | 62.2% | 38% | 90% | 0.3601 | 0.6775 |
| CCA and JITL () | 2.5% | 6.5% | 100% | 100% | 0.9961 | 0.9943 |
| CCA and JITL () | 7.75% | 29.5% | 100% | 92.2% | 0.9847 | 0.8778 |
| CCA and JITL (average value) | 5.125% | 18% | 100% | 96.1% | 0.9904 | 0.9361 |
| Methods | FAR | FDR | AUC | |||
|---|---|---|---|---|---|---|
| SPE | SPE | SPE | ||||
| PLS | 4.6% | 0.6% | 80% | 78% | 0.7851 | 0.7861 |
| PLS and JITL | 44.5% | 0.5% | 100% | 66.8% | 0.9384 | 0.8506 |
| PCA | 13% | 66.8% | 76.4% | 79.6% | 0.7370 | 0.3738 |
| PCA and JITL | 0% | 2.75% | 98.6% | 98.2% | 0.9975 | 0.9868 |
| CCA | 83.2% | 54.2% | 16.2% | 62% | 0.2158 | 0.7730 |
| CCA and JITL () | 13.25% | 19% | 100% | 100% | 0.9587 | 0.9874 |
| CCA and JITL () | 34.25% | 67.5% | 99% | 100% | 0.8081 | 0.8291 |
| CCA and JITL (average value) | 23.75% | 43.25% | 99.5% | 100% | 0.8834 | 0.9083 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, H.; Zhu, K.; Cheng, C.; Fu, Z. Fault Detection for High-Speed Trains Using CCA and Just-in-Time Learning. Machines 2022, 10, 526. https://doi.org/10.3390/machines10070526
Zheng H, Zhu K, Cheng C, Fu Z. Fault Detection for High-Speed Trains Using CCA and Just-in-Time Learning. Machines. 2022; 10(7):526. https://doi.org/10.3390/machines10070526
Chicago/Turabian StyleZheng, Hong, Keyuan Zhu, Chao Cheng, and Zhaowang Fu. 2022. "Fault Detection for High-Speed Trains Using CCA and Just-in-Time Learning" Machines 10, no. 7: 526. https://doi.org/10.3390/machines10070526
APA StyleZheng, H., Zhu, K., Cheng, C., & Fu, Z. (2022). Fault Detection for High-Speed Trains Using CCA and Just-in-Time Learning. Machines, 10(7), 526. https://doi.org/10.3390/machines10070526