
Intelligent Control of Swarm Robotics Employing Biomimetic Deep Learning


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
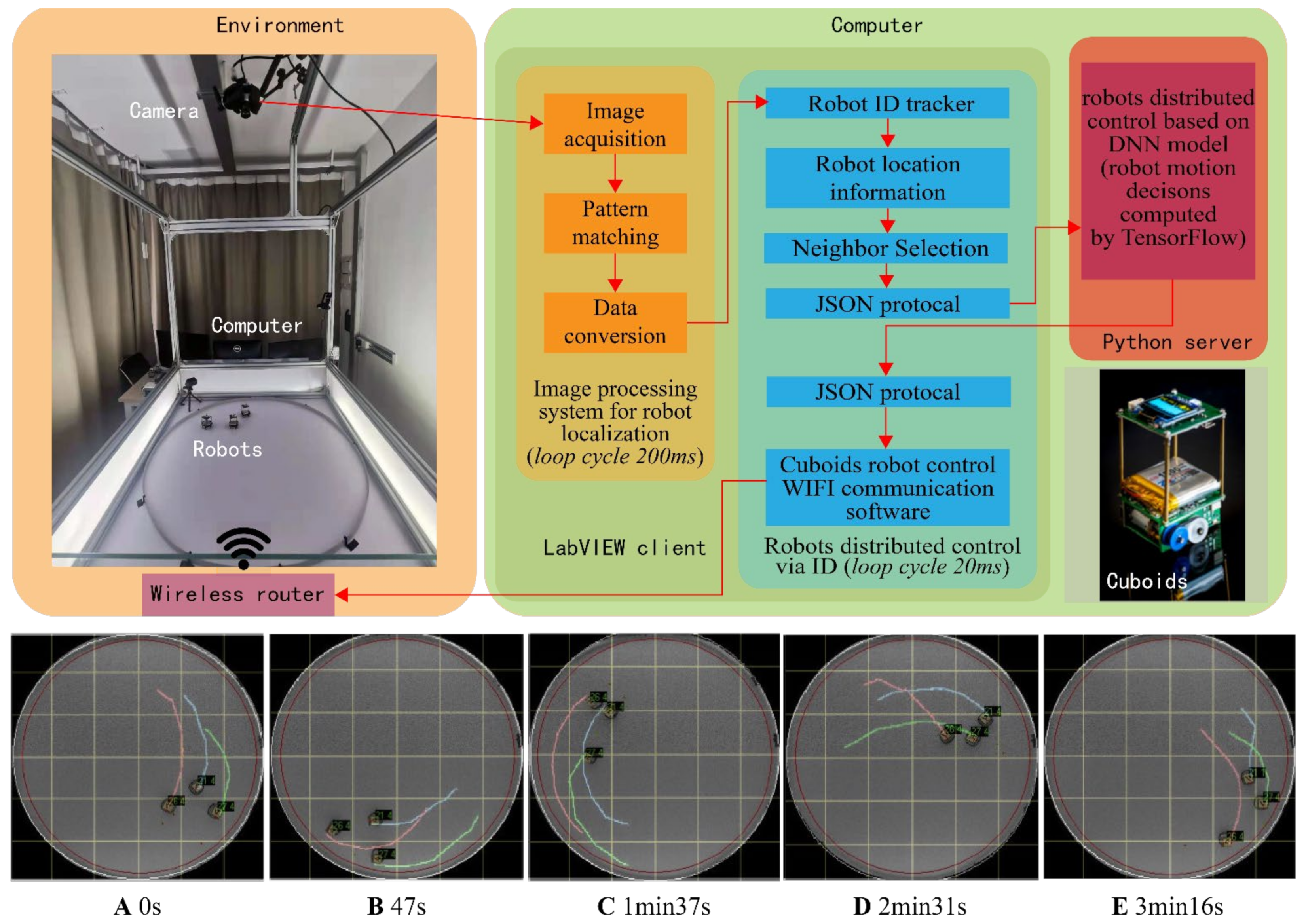
2. Materials and Methods
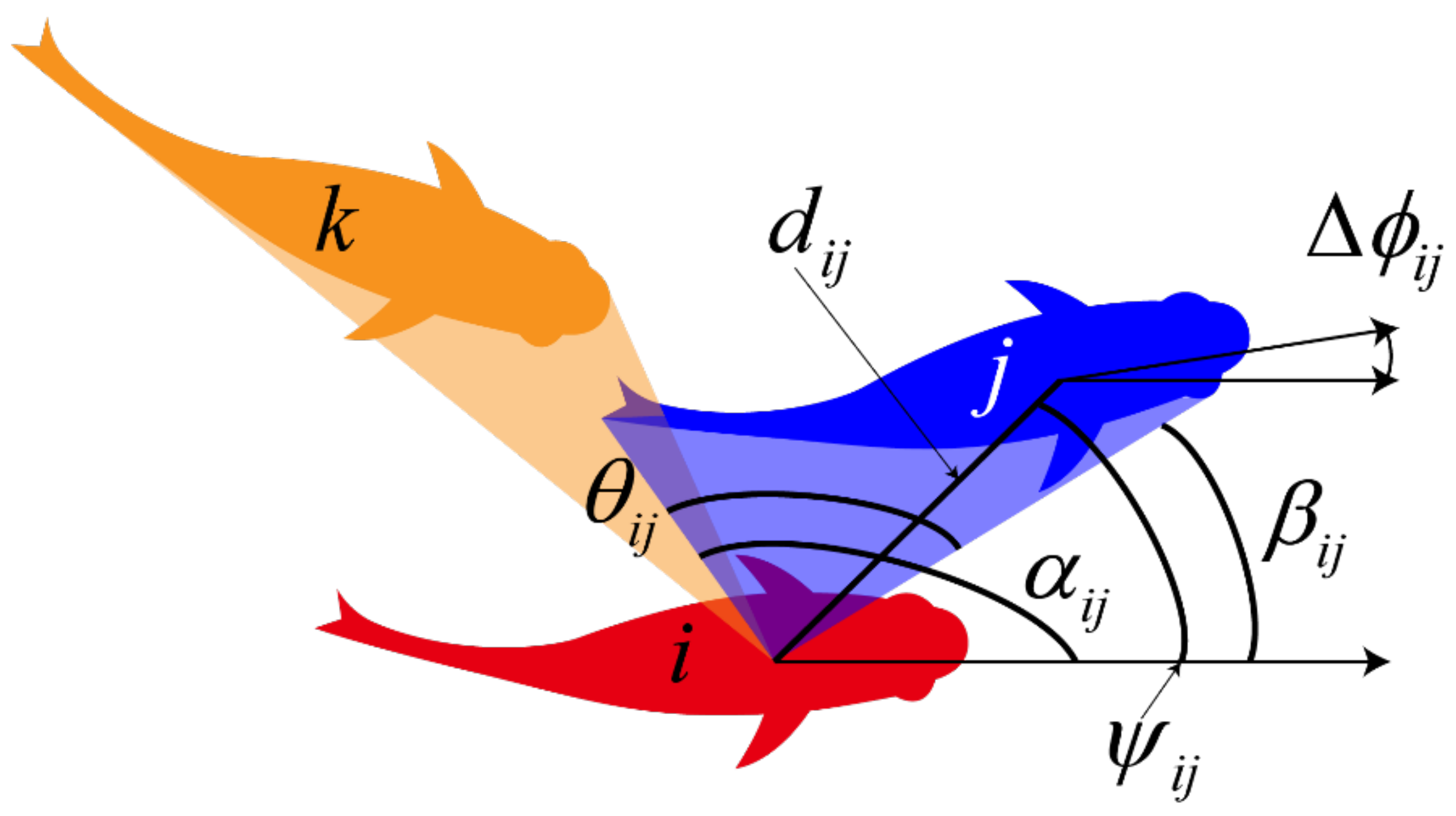
2.1. Experimental Data
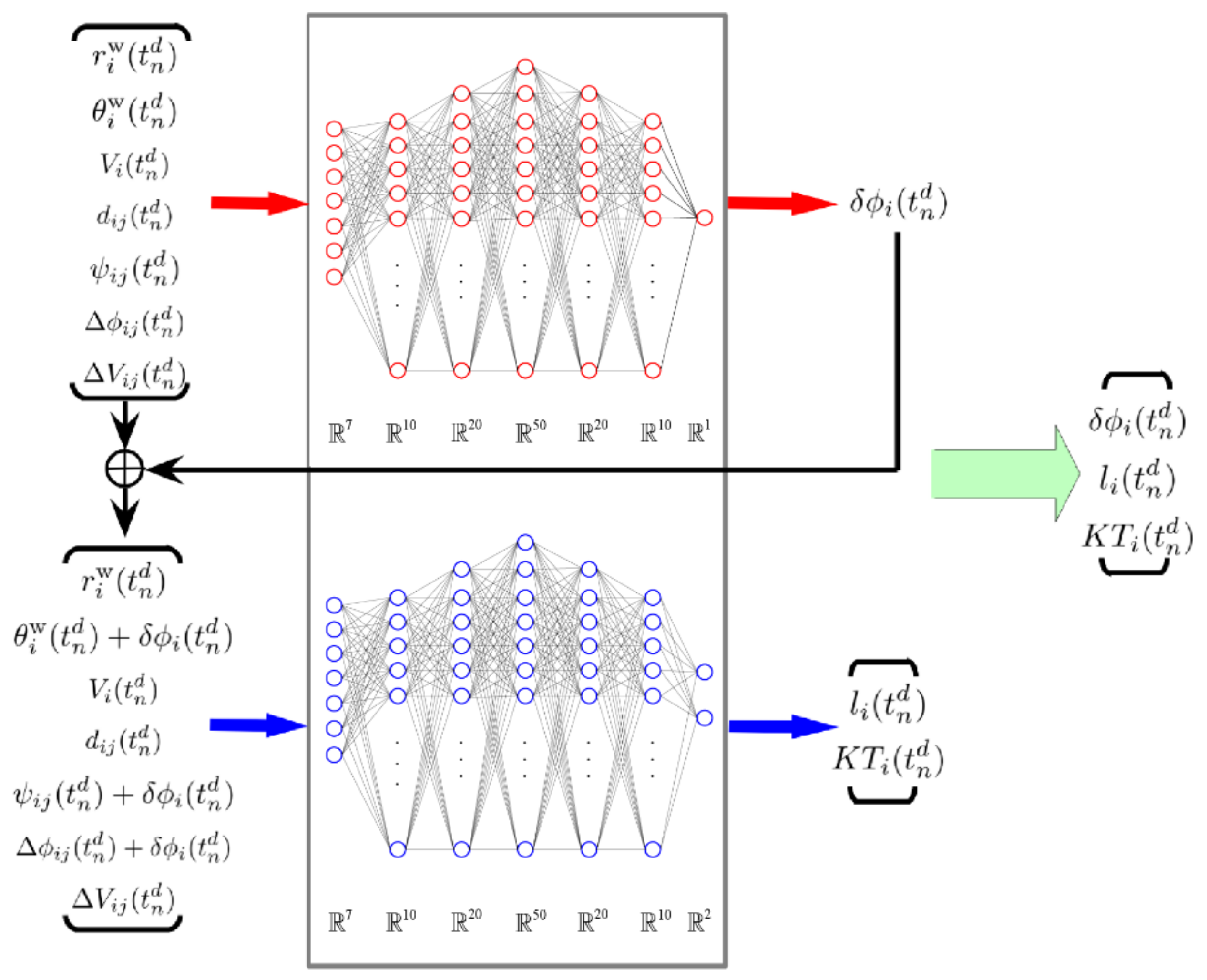
2.2. Deep Neural Network (DNN) Model
2.3. The Fusion Method of Pairwise Interaction for the Multi-Agents
2.4. Software Configuration of the Simulation Platform
| Algorithm 1. States Update Rules for Agent |
| Input: decision results, old statesand the timer value. Output: new statesand new timer value If is less than or equal to 0 \\ there exists a new decision from the Python server = Else \\ agent straight motion = =+ =+ If BL \\ safety mechanism of the motion simulation \\ ask the Python Server for a new decision |
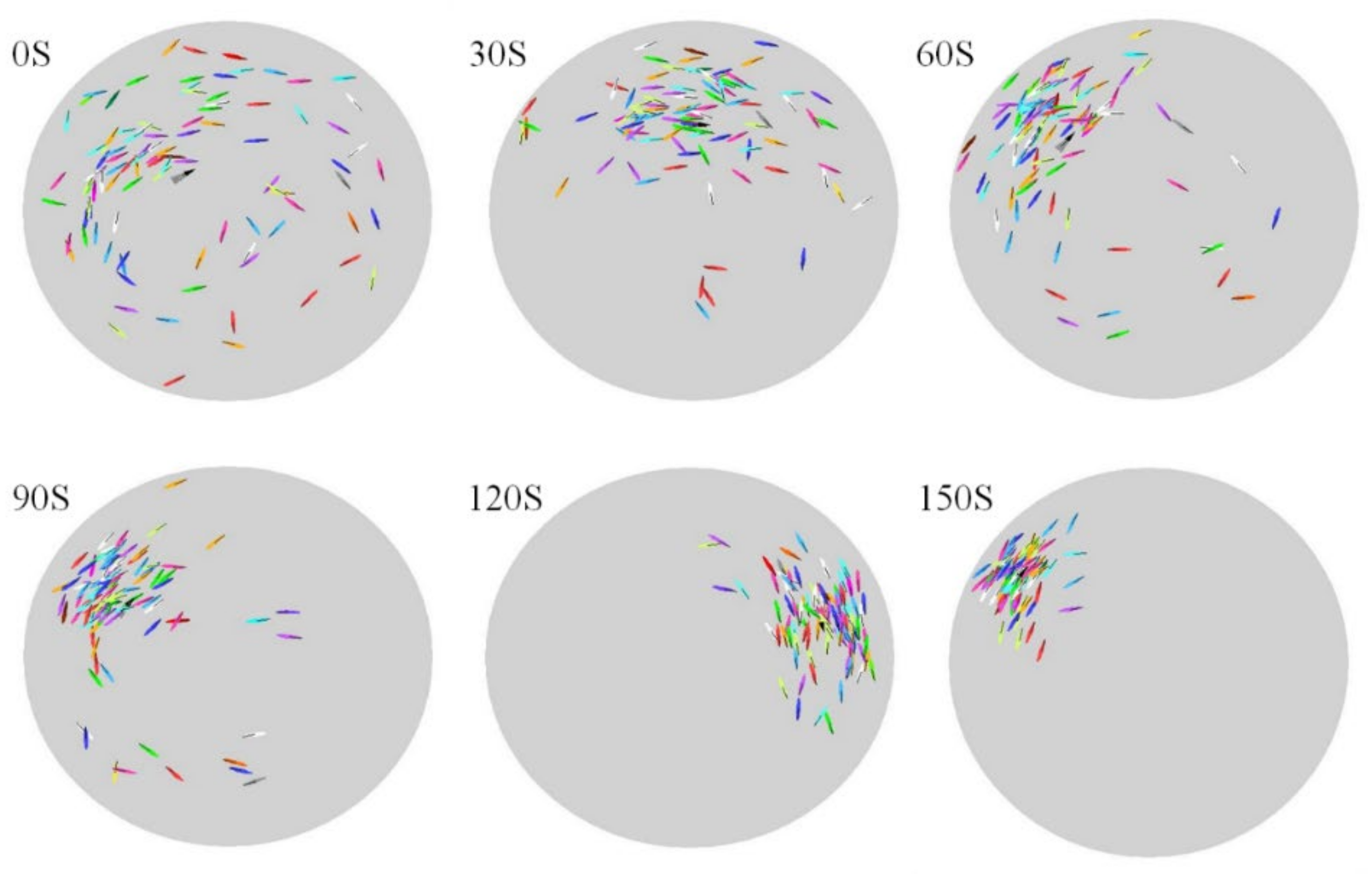
2.5. Statistical Properties of Collective Motion
- The distance from all fish (agents) to the wall: ;
- The angle to the wall of all fish (agents): .
- 3.
- Polarization of the group: :where is the unit vector for representing the direction of the fish . When the value , all the fish (agents) have the same orientation, while when this value is close to 0, all the fish are in different directions.
- 4.
- Group size: :where is the distance from to . When the group is compact, is low, and vice versa.
- 5.
- Counter-milling index :where is the relative speed angle between the relative position vector and the relative speed vector , represents the sign function, and means all fish (agents) move counterclockwise. Contrarily, if this value is less than zero, all fish move clockwise. When the direction of all fish moving around the center of the experimental space is different from the direction of each fish rotating around the barycenter, we call the group counter-milling swimming (i.e., ). On the contrary, if the two directions of rotation are the same, then the group shows a super-milling behavior (i.e., ).
- 6.
- The relative speed to the barycenter of all fish may be described as follows:
3. Results
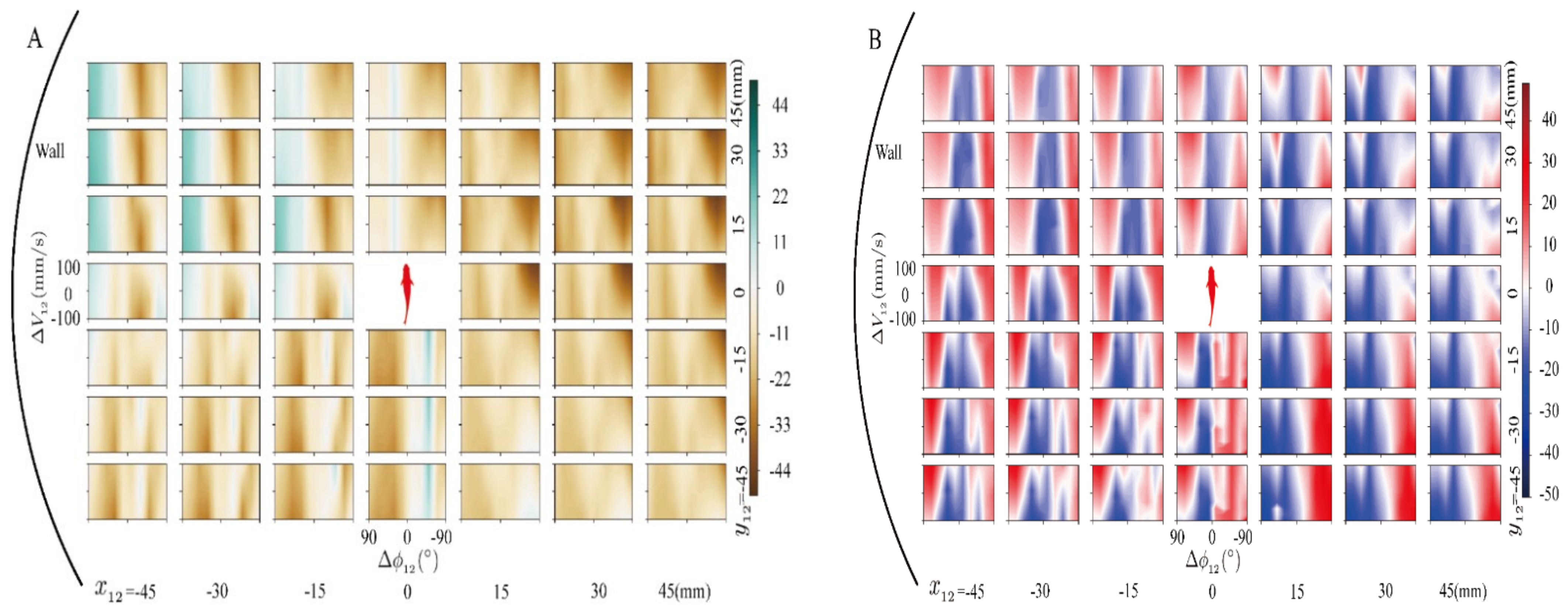
3.1. The Effect of Model Pairwise Interaction
3.2. The Analysis of the Multi-Fusion Method of Pairwise Interaction
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Buhl, J.; Sumpter, D.J.T.; Couzin, I.D. From disorder to order in marching locusts. Science 2006, 284, 1402–1406. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cavagna, A.; Cimareli, A.; Giardina, I. Scale-free corelations in starling flocks. Proc. Natl. Acad. Sci. USA 2010, 107, 11865–11870. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Altshuler, E.; Ramos, O.; Nunez, Y. Symmetry breaking in escaping ants. Am. Nat. 2005, 166, 643–649. [Google Scholar] [CrossRef] [PubMed]
- Helbing, D.; Farkas, I.; Vicsek, T. Simulating dynamical features of escape panic. Nature 2000, 407, 487–490. [Google Scholar] [CrossRef] [Green Version]
- Camazine, S.; Franks, N.R.; Sneyd, J. Self-organization in biological systems. Anim. Behav. 2003, 64, 829–830. [Google Scholar]
- Couzin, I.D.; Krause, J. Self-organization and collective behavior in vertebrates. Adv. Stud. Behav. 2003, 32, 1–75. [Google Scholar]
- Jia, Y.; Vicsek, T. Modelling Hierarchical Flocking. New J. Phys. 2019, 21, 093048. [Google Scholar] [CrossRef]
- Zafeiris, A.; Vicsek, T. Why We Live in Hierarchies? A Quantitative Treatise; Springer: Berlin, Germany, 2018. [Google Scholar]
- Zafeiris, A.; Vicsek, T. Group performance is maximized by hierarchical competence distribution. Nat. Commun. 2013. [Google Scholar] [CrossRef] [Green Version]
- Couzin, I.D.; Krause, J.; Franks, N.R.; Levin, S.A. Effective. Leadership and decision making in animal groups on the move. Nature 2005, 433, 513–516. [Google Scholar] [CrossRef] [Green Version]
- Calovi, D.S.; Litchinko, A.; Lecheval, V. Disentangling and modeling interactions in fish with burst and coast swimming reveal distinct alignment and attraction behaviors. PLoS Comput. Biol. 2018, 14, e1005933. [Google Scholar] [CrossRef] [Green Version]
- Vicsek, T.; Zafeiris, A. Collective motion. Phys. Rep. 2012, 517, 71–140. [Google Scholar] [CrossRef] [Green Version]
- Mao, S.; Rajan, D.; Tien, C.L. Deep Residual Pooling Network for Texture Recognition. Pattern Recogn 2021, 112, 107817. [Google Scholar] [CrossRef]
- Paixo, T.M.; Berriel, R.F.; Boeres, M. Self-supervised Deep Reconstruction of Mixed Strip-shredded Text Documents. Pattern Recogn 2020, 107, 107535. [Google Scholar] [CrossRef]
- Tayyab, S.M.; Chatterton, S.; Pennacchi, P. Fault Detection and Severity Level Identification of Spiral Bevel Gears under Different Operating Conditions Using Artificial Intelligence Techniques. Machines 2021, 9, 173. [Google Scholar] [CrossRef]
- Sinha, A.K.; Hati, A.S.; Benbouzid, M.; Chakrabarti, P. ANN-Based Pattern Recognition for Induction Motor Broken Rotor Bar Monitoring under Supply Frequency Regulation. Machines 2021, 9, 87. [Google Scholar] [CrossRef]
- Moreira, L.; Figueiredo, J.; Vilas-Boas, J.P.; Santos, C.P. Kinematics, Speed, and Anthropometry-Based Ankle Joint Torque Estimation: A Deep Learning Regression Approach. Machines 2021, 9, 154. [Google Scholar] [CrossRef]
- Qureshi, A.S.; Khan, A.; Zameer, A. Wind power prediction using deep neural network based meta regression and transfer learning. Appl. Soft Comput. 2017, 58, 742–755. [Google Scholar] [CrossRef]
- Mavrogiannis, C.I.; Blukis, V.; Knepper, R.A. Socially competent navigation planning by deep learning of multi-agent path topologies. IROS 2017. [Google Scholar] [CrossRef]
- Li, J.; Tan, Y. A Two-Stage Imitation Learning Framework for the Multi-Target Search Problem in Swarm Robotics. Neurocomputing 2019, 334, 249–264. [Google Scholar] [CrossRef]
- Mi, H.C.; Lee, E.J.; Son, M. A magnetic switch for the control of cell death signalling in in vitro and in vivo systems. Nat. Mater. 2012, 11, 1038–1043. [Google Scholar]
- Yu, J.; Wang, B.; Du, X. Ultra-extensible ribbon-like magnetic microswarm. Nat. Commun. 2018, 9, 3260. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Li, X.; Luo, T. Development of a magnetic microrobot for carrying and delivering targeted cells. Sci. Robot 2018, 3, eaat8829. [Google Scholar] [CrossRef] [Green Version]
- Kaiser, A.; Snezhko, A.; Aranson, I.S. Flocking ferromagnetic colloids. Sci. Adv. 2017, 3, e1601469. [Google Scholar] [CrossRef] [Green Version]
- Dong, X.W.; Zhou, Y.; Ren, Z. Time-Varying Formation Tracking for Second-Order Multi-Agent Systems Subjected to Switching Topologies With Application to Quadrotor Formation Flying. IEEE Trans. Ind. Electron. 2017, 64, 5014–5024. [Google Scholar] [CrossRef]
- Pietro, D.L.; Edoardo, C.; Arrigo, C. Model-Based Feedback Control of Live Zebrafish Behavior via Interaction With a Robotic Replica. IEEE Trans. Robot 2019, 36, 28–41. [Google Scholar]
- Scholz, C.; Engel, M.; Poschel, T. Rotating robots move collectively and self-organize. Nat. Commun. 2018, 9, 931. [Google Scholar] [CrossRef] [PubMed]
- Berlinger, F.; Gauci, M.; Nagpal, R. Implicit coordination for 3D underwater collective behaviors in a fish-inspired robot swarm. Sci. Robot 2021, 6, eabd8668. [Google Scholar] [CrossRef]
- Ozkan-Aydin, Y.; Goldman, D.I. Self-reconfigurable multilegged robot swarms collectively accomplish challenging terradynamic tasks. Sci. Robot 2021, 6, eabf1628. [Google Scholar] [CrossRef] [PubMed]
- Elamvazhuthi, K.; Kakish, Z.; Shirsat, A. Controllability and Stabilization for Herding a Robotic Swarm Using a Leader: A Mean-Field Approach. IEEE Trans. Robot 2020, 37, 418–432. [Google Scholar] [CrossRef]
- Vasarhelyi, G.; Viragh, C.; Somorjai, G. Optimized flocking of autonomous drones in confined environments. Sci. Robot 2018, 3, eaat3536. [Google Scholar] [CrossRef] [Green Version]
- Lei, L.; Escobedo, R.; Sire, C.; Theraulaz, G. Computational and robotic modeling reveal parsimonious combinations of interactions between individuals in schooling fish. PLoS Comput. Biol. 2020, 16, e1007194. [Google Scholar] [CrossRef] [Green Version]
- Parrish, J.K.; Grünbaum, V.D. Self-organized fish schools: An examination of emergent properties. Bio Bull. 2002, 202, 296–305. [Google Scholar] [CrossRef] [Green Version]
- Aoki, I. A Simulation Study on the Schooling Mechanism in Fish. Bull. Jpn. Soc. Sci. Fish 1982, 48, 1081–1088. [Google Scholar] [CrossRef] [Green Version]
- Couzin, I.D.; Krause, J.; James, R. Collective memory and spatial sorting in animal groups. J. Theor. Biol. 2002, 218, 1–11. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vicsek, T.; Czirók, A.; Ben-Jacob, E. Novel Type of Phase Transition in a System of Self-Driven Particles. Phys. Rev. Lett. 1995, 75, 1226. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ballerini, M.; Cabibbo, N.; Candelier, R.; Cavagna, A.; Cisbani, E.; Giardina, I.; Lecomte, V.; Orlandi, A.; Parisi, G.; Procaccini, A.; et al. Interaction Ruling Animal Collective Behavior Depends on Topological Rather than Metric Distance: Evidence from a Field Study. Proc. Natl. Acad. Sci. USA 2008, 105, 1232–1237. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Camperi, M.; Cavagna, A.; Giardina, I. Spatially balanced topological interaction grants optimal cohesion in flocking models. Interface Focus 2012, 2, 715–725. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.P. Collective motion and density fluctuations in bacterial colonies. Proc. Natl. Acad. Sci. USA 2010, 107, 13626–13630. [Google Scholar] [CrossRef] [Green Version]
- Strandburg-Peshkin, A.; Farine, D.R.; Couzin, I.D. Shared decision-making drives collective movement in wild baboons. Sciences 2015, 348, 1358–1361. [Google Scholar] [CrossRef] [Green Version]
- Pérez-Escudero, A.; Vicente-Page, J.; Hinz, R.C. idTracker: Tracking individuals in a group by automatic identification of unmarked animals. Nat. Methods 2014, 11, 743–748. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980v9. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mac. Learn Res. 2014, 15, 1929–1958. [Google Scholar]
- Rosenthal, S.B.; Twomey, C.R.; Hartnett, A.T. Revealing the hidden networks of interaction in mobile animal groups allows prediction of complex behavioral contagion. Proc. Natl. Acad. Sci. USA 2015, 112, 4690–4695. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lanchester, B.S.; Mark, R.F. Pursuit and prediction in the tracking of moving food by a teleost fish (Acanthaluteres spilomelanurus). Indian J. Exp. Biol. 1975, 63, 627–645. [Google Scholar] [CrossRef]
- Heras, F.J.H.; Romero-Ferrero, F.; Hinz, R.C. Deep attention networks reveal the rules of collective motion in zebrafish. PLoS Comput. Biol. 2019, 15, e1007354. [Google Scholar] [CrossRef] [Green Version]
- Wang, M.; Zeng, B.; Wang, Q. Research on Motion Planning Based on Flocking Control and Reinforcement Learning for Multi-Robot Systems. Machines 2021, 9, 77. [Google Scholar] [CrossRef]
- Chen, G.; Xu, W.; Li, Z.; Liu, Y.; Liu, X. Research on the Multi-Robot Cooperative Pursuit Strategy Based on the Zero-Sum Game and Surrounding Points Adjustment. Machines 2021, 9, 187. [Google Scholar] [CrossRef]











Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Liu, L. Intelligent Control of Swarm Robotics Employing Biomimetic Deep Learning. Machines 2021, 9, 236. https://doi.org/10.3390/machines9100236
Zhang H, Liu L. Intelligent Control of Swarm Robotics Employing Biomimetic Deep Learning. Machines. 2021; 9(10):236. https://doi.org/10.3390/machines9100236
Chicago/Turabian StyleZhang, Haoxiang, and Lei Liu. 2021. "Intelligent Control of Swarm Robotics Employing Biomimetic Deep Learning" Machines 9, no. 10: 236. https://doi.org/10.3390/machines9100236
APA StyleZhang, H., & Liu, L. (2021). Intelligent Control of Swarm Robotics Employing Biomimetic Deep Learning. Machines, 9(10), 236. https://doi.org/10.3390/machines9100236