
Design and Comparison of Reinforcement-Learning-Based Time-Varying PID Controllers with Gain-Scheduled Actions



Abstract
:1. Introduction
2. Preliminaries and System Modeling
2.1. The Markov Property
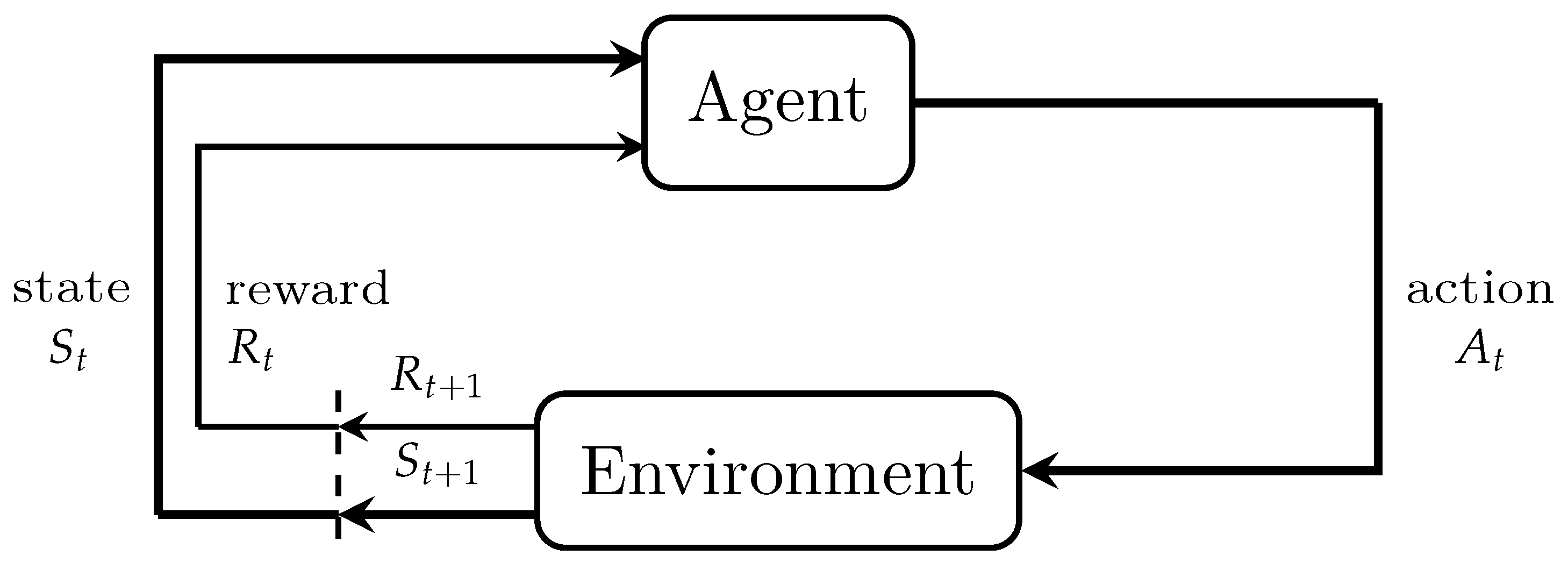
2.2. Reinforcement Learning
2.3. Q-Learning
| Algorithm 1 Q-learning: Off-policy TD control algorithm. |
|
2.4. Sarsa
| Algorithm 2 Sarsa: On-policy TD control algorithm. |
|
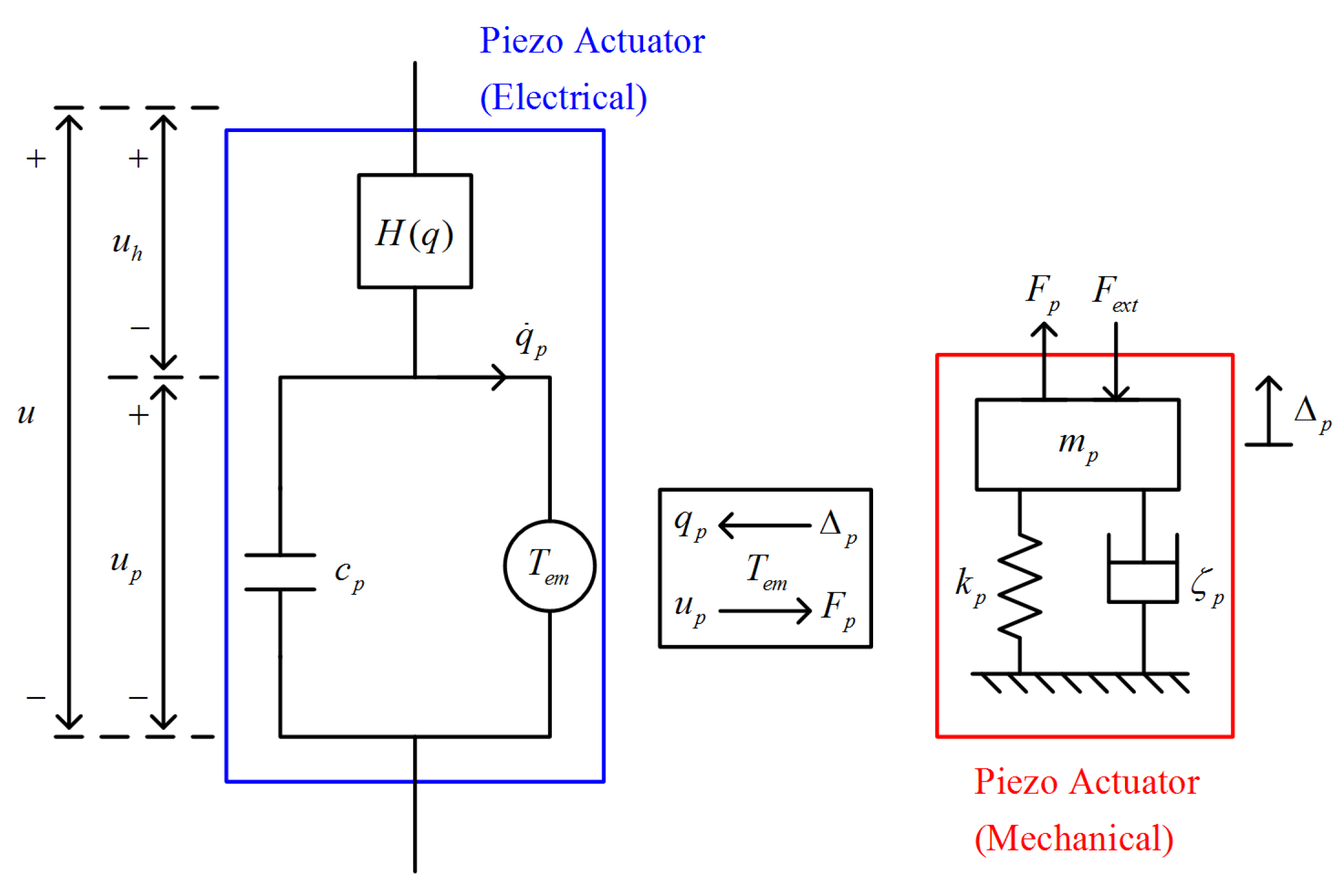
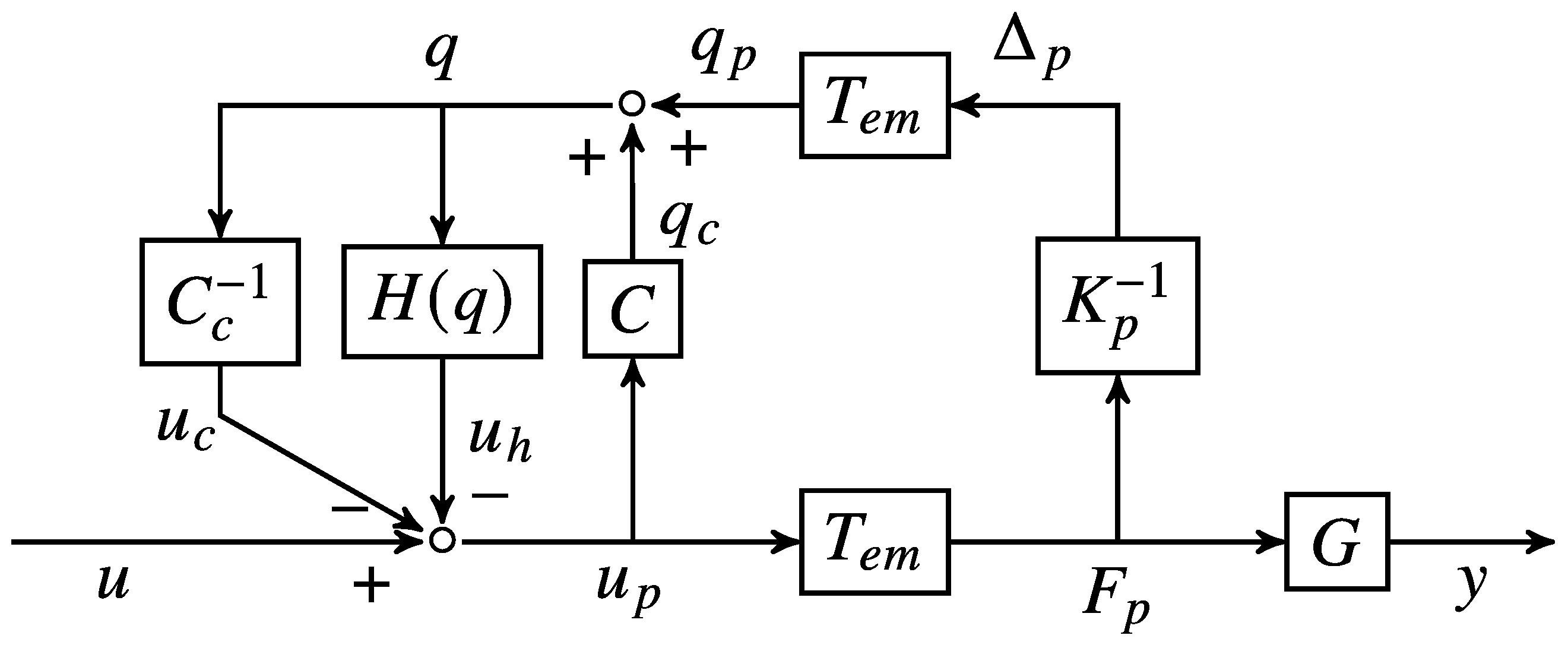
2.5. System Modeling of Piezo-Actuated Stage
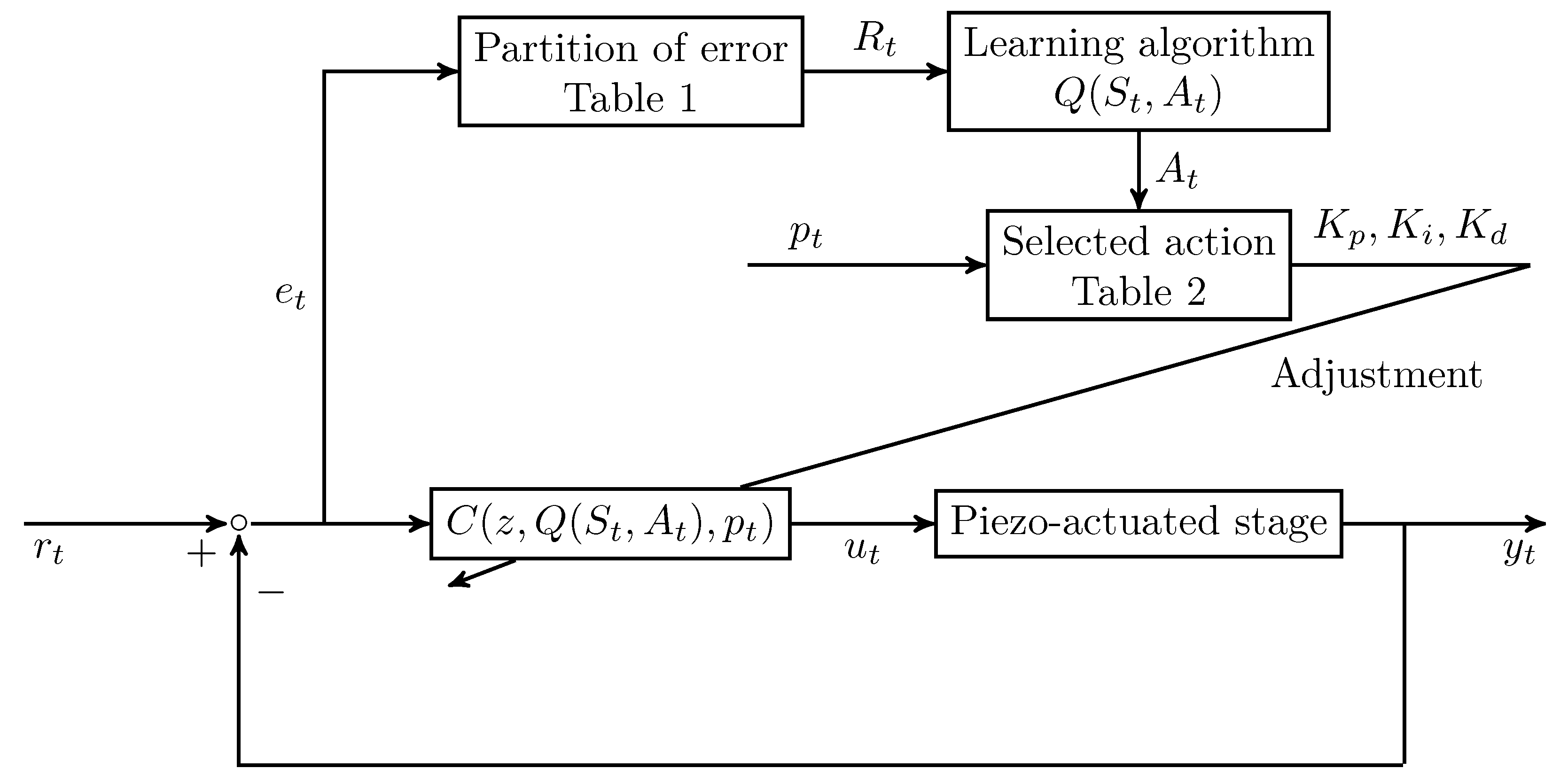
3. Controller Design
4. Experimental Results
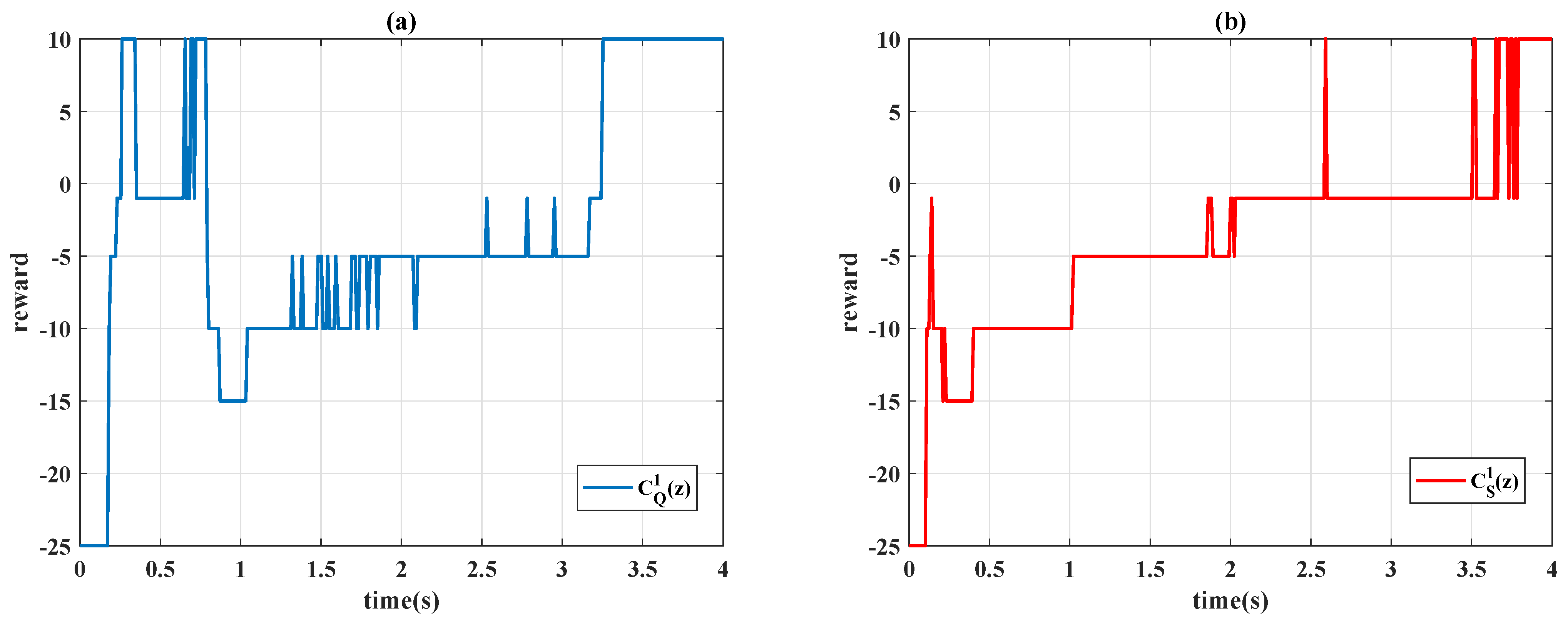
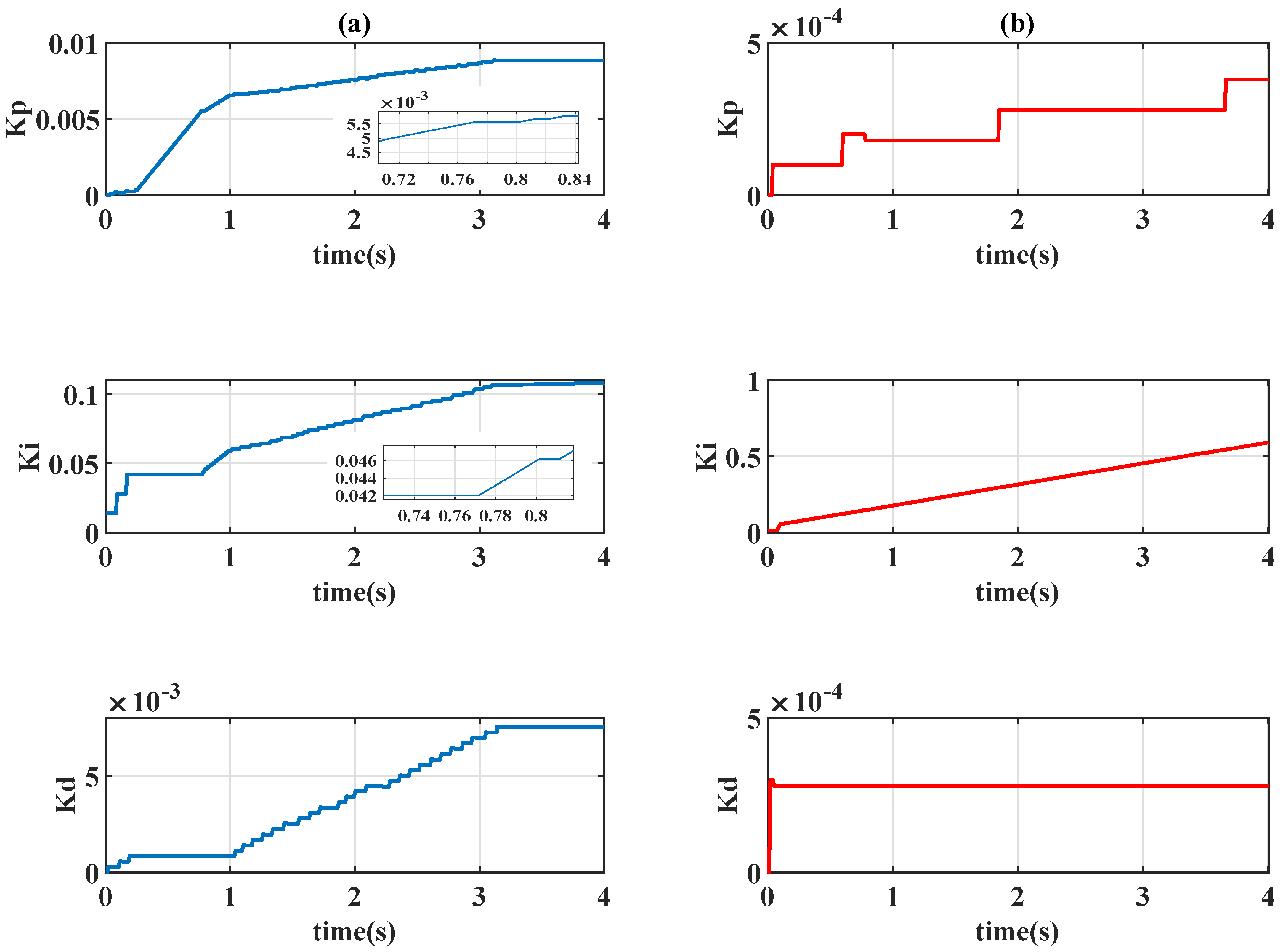
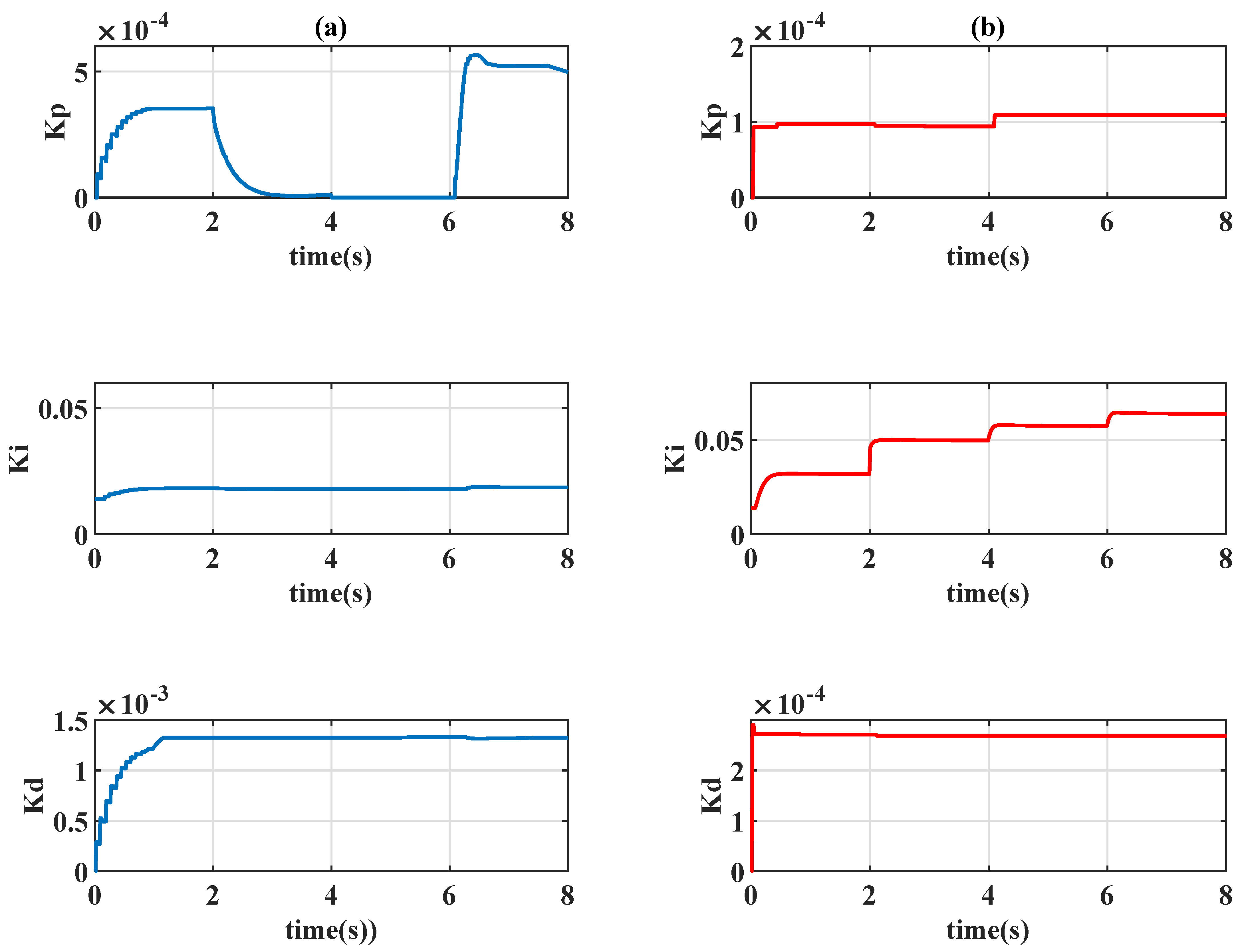
4.1. Gain-Scheduled Actions
4.1.1.
4.1.2.
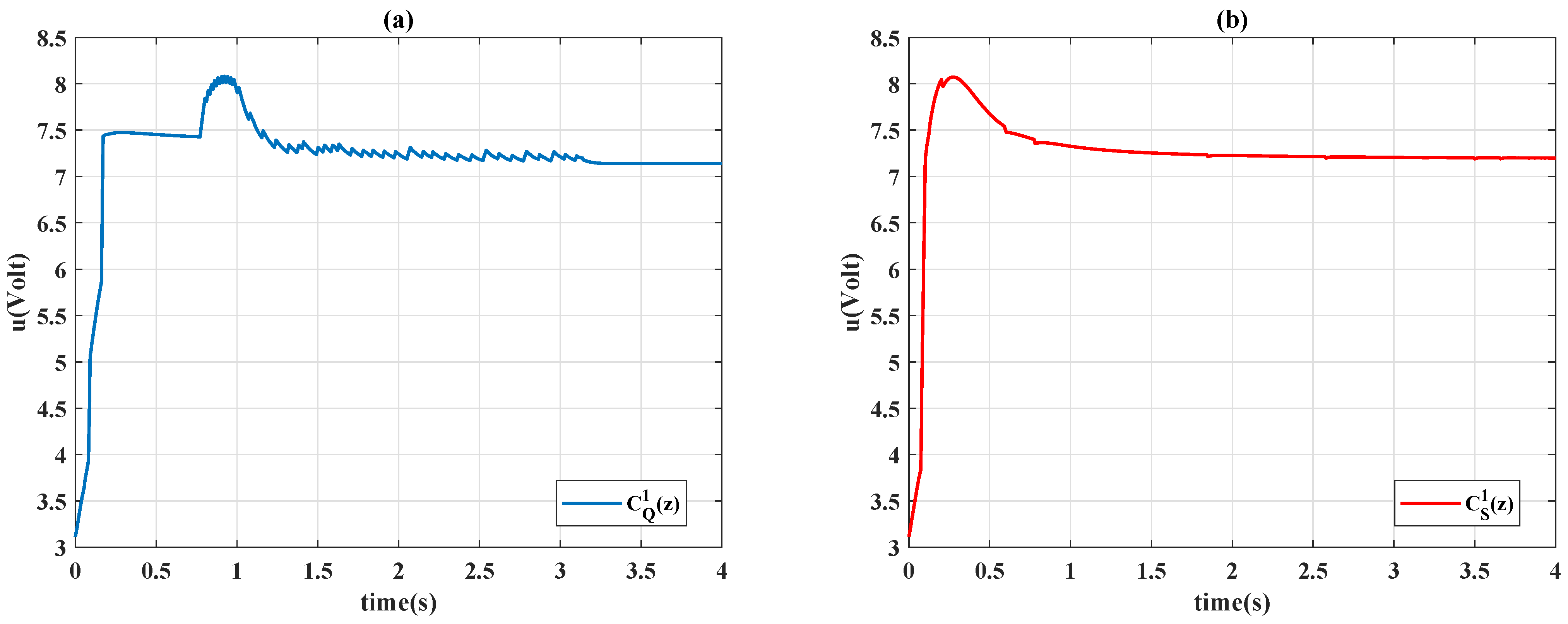
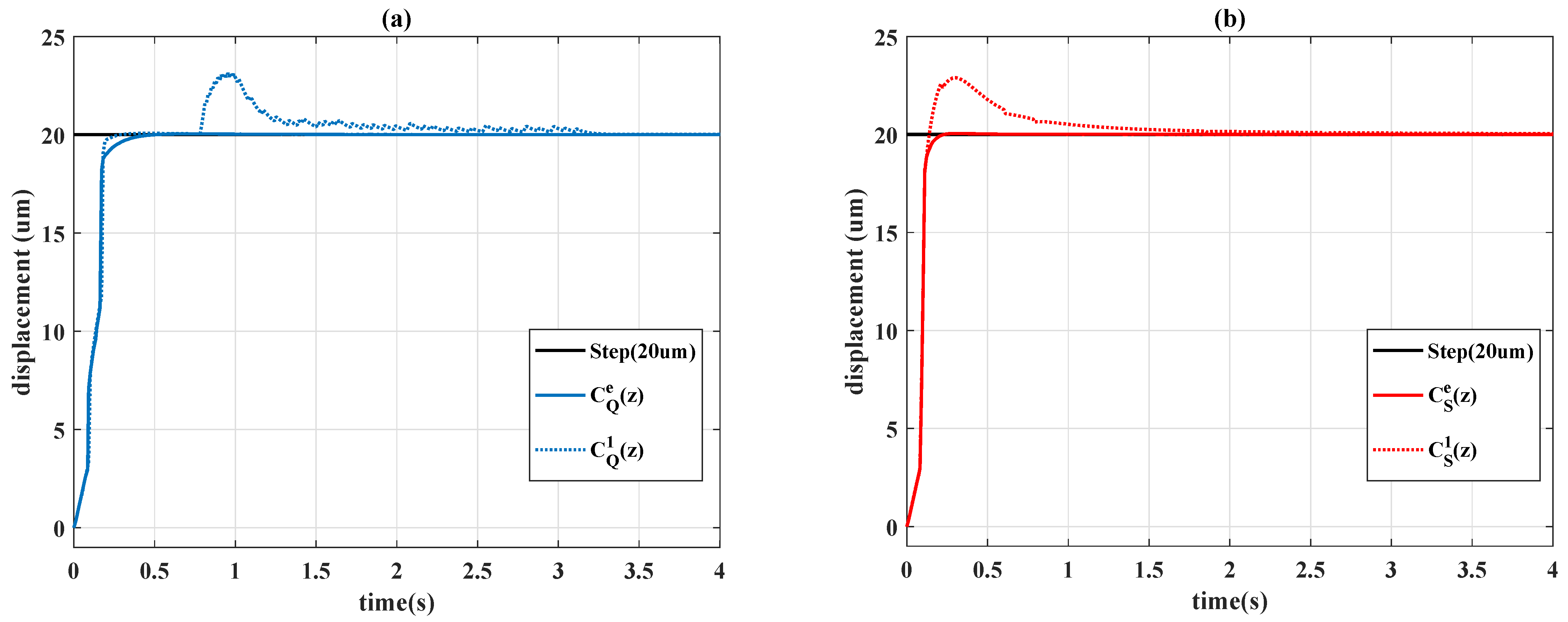
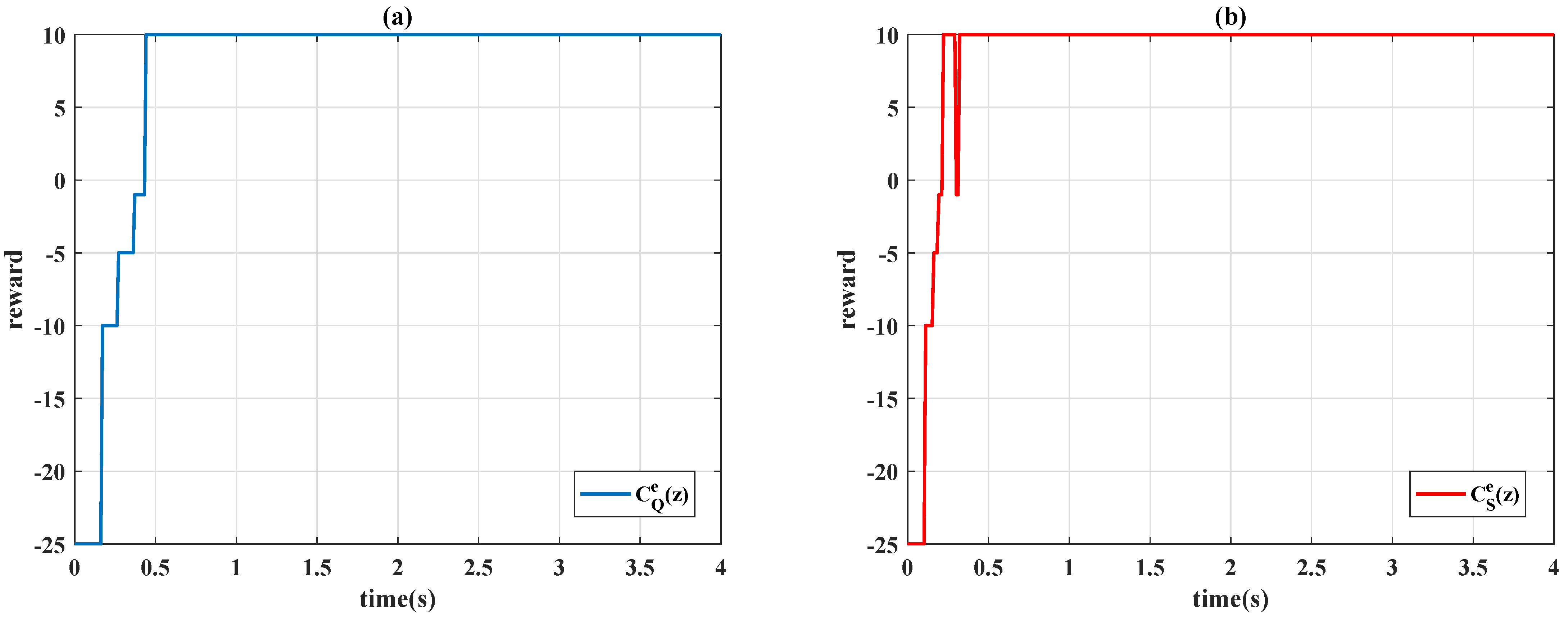
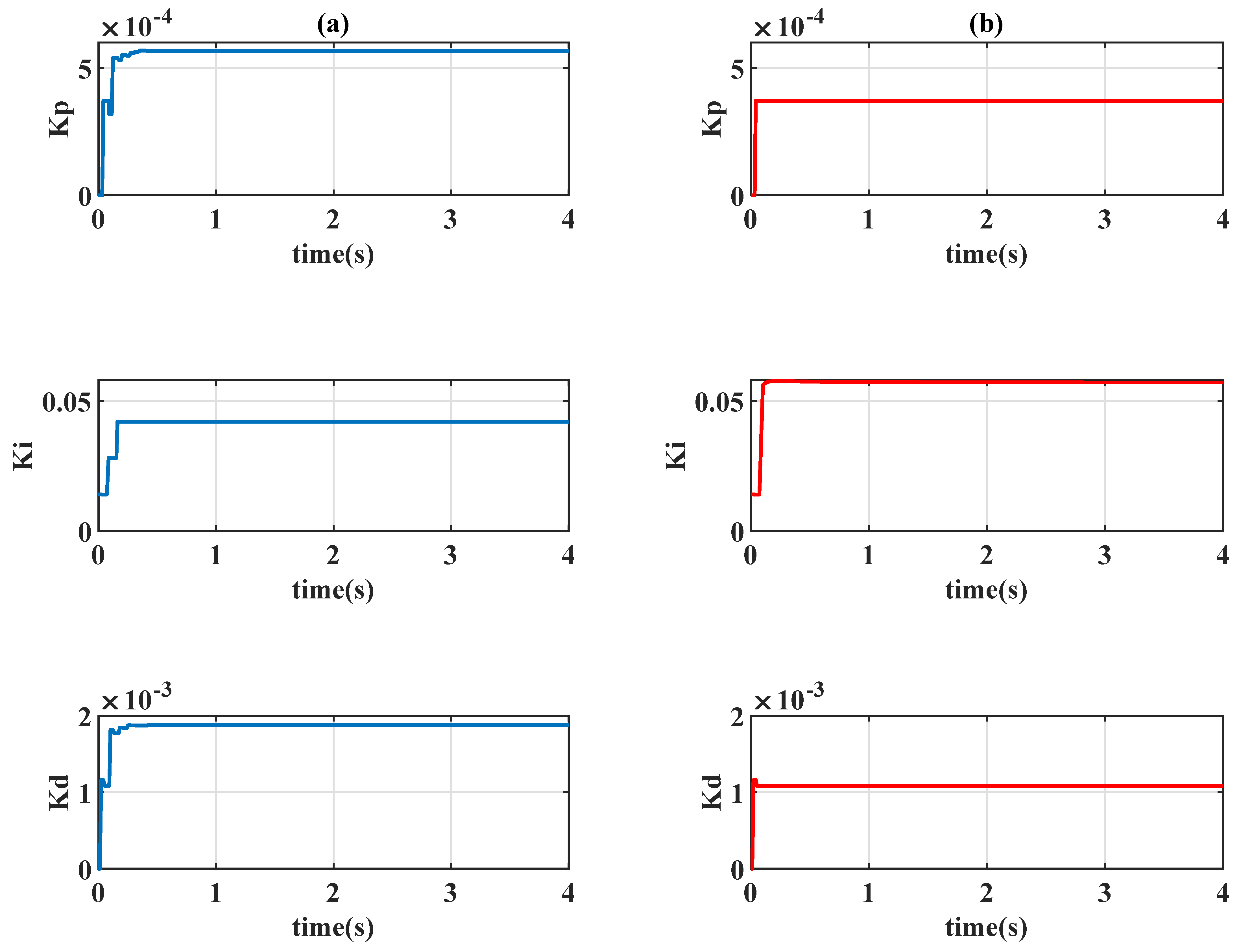
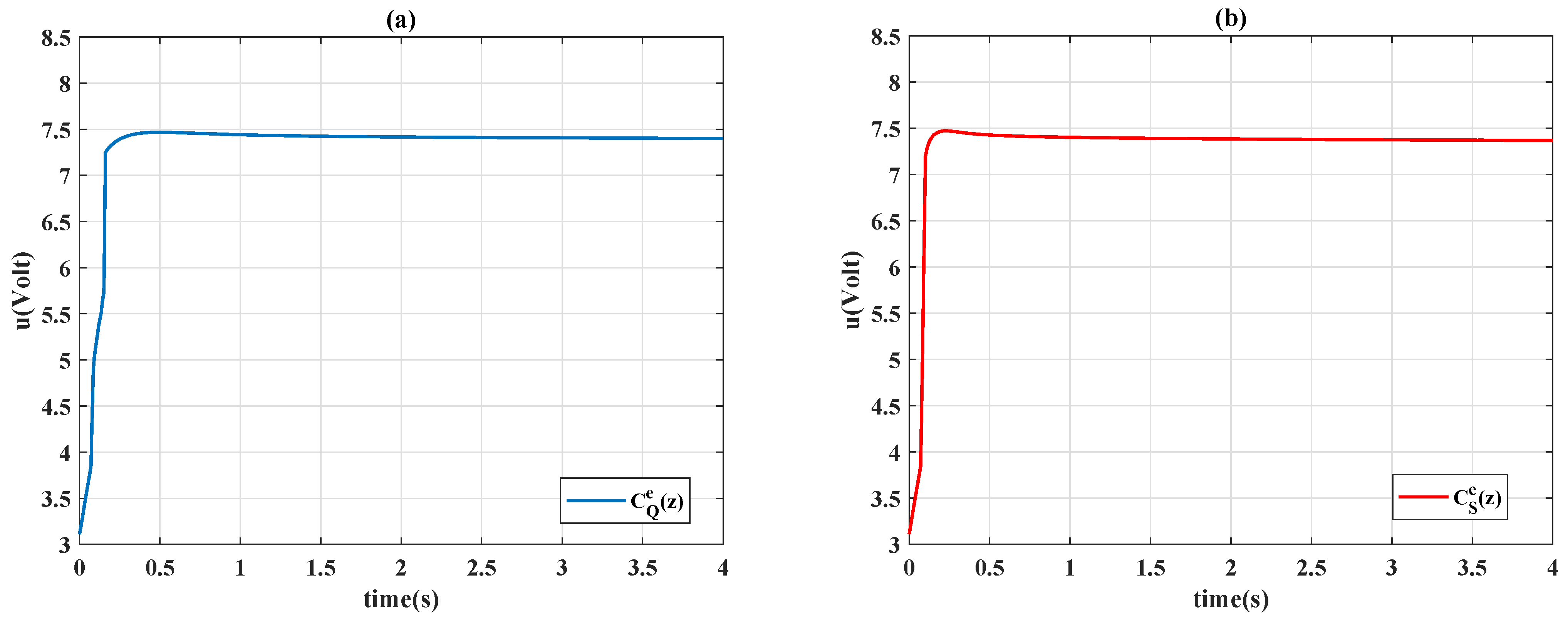
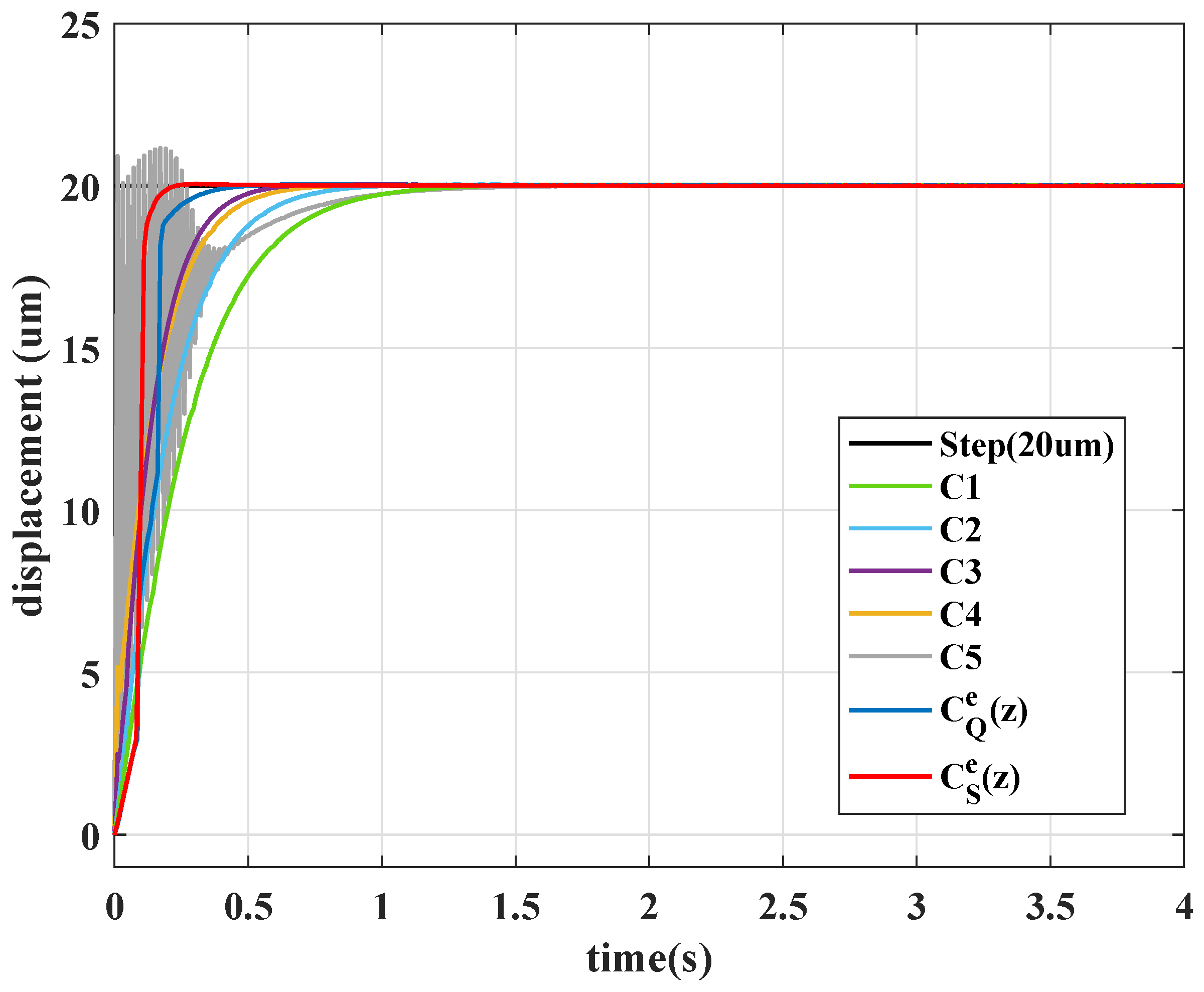
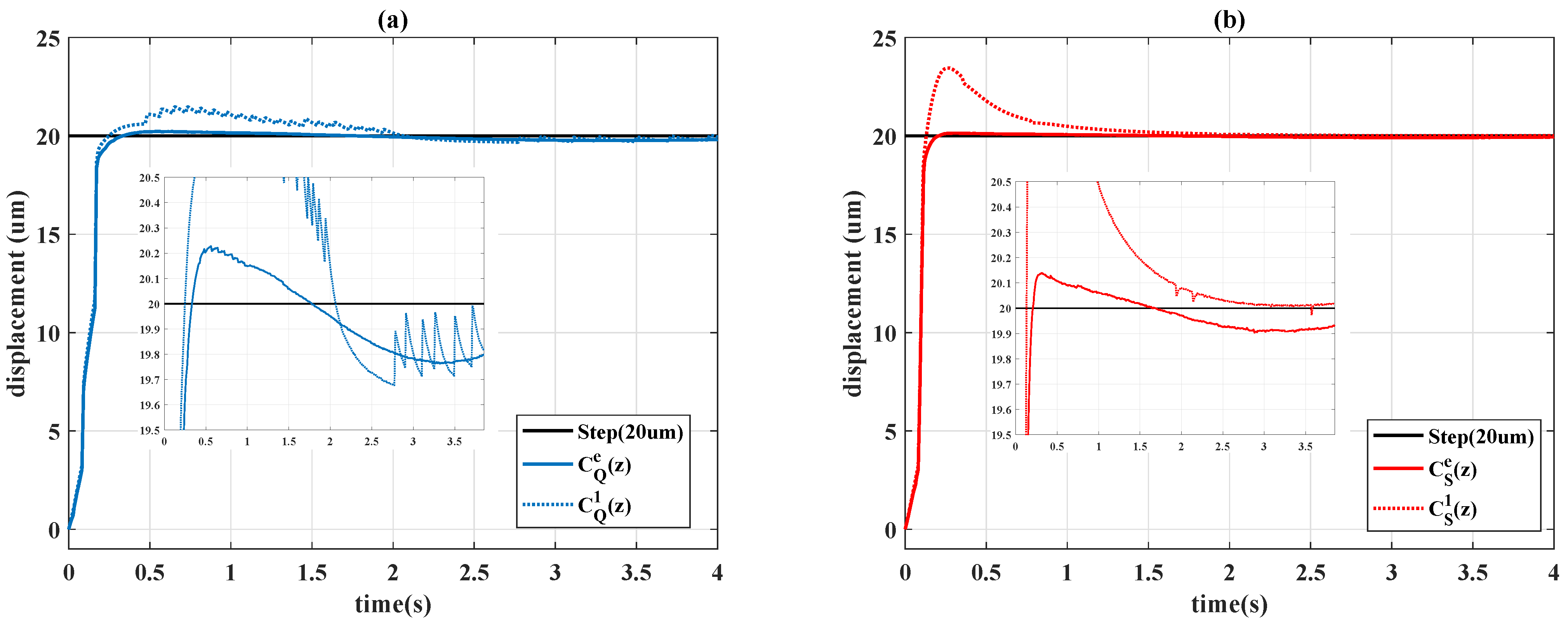
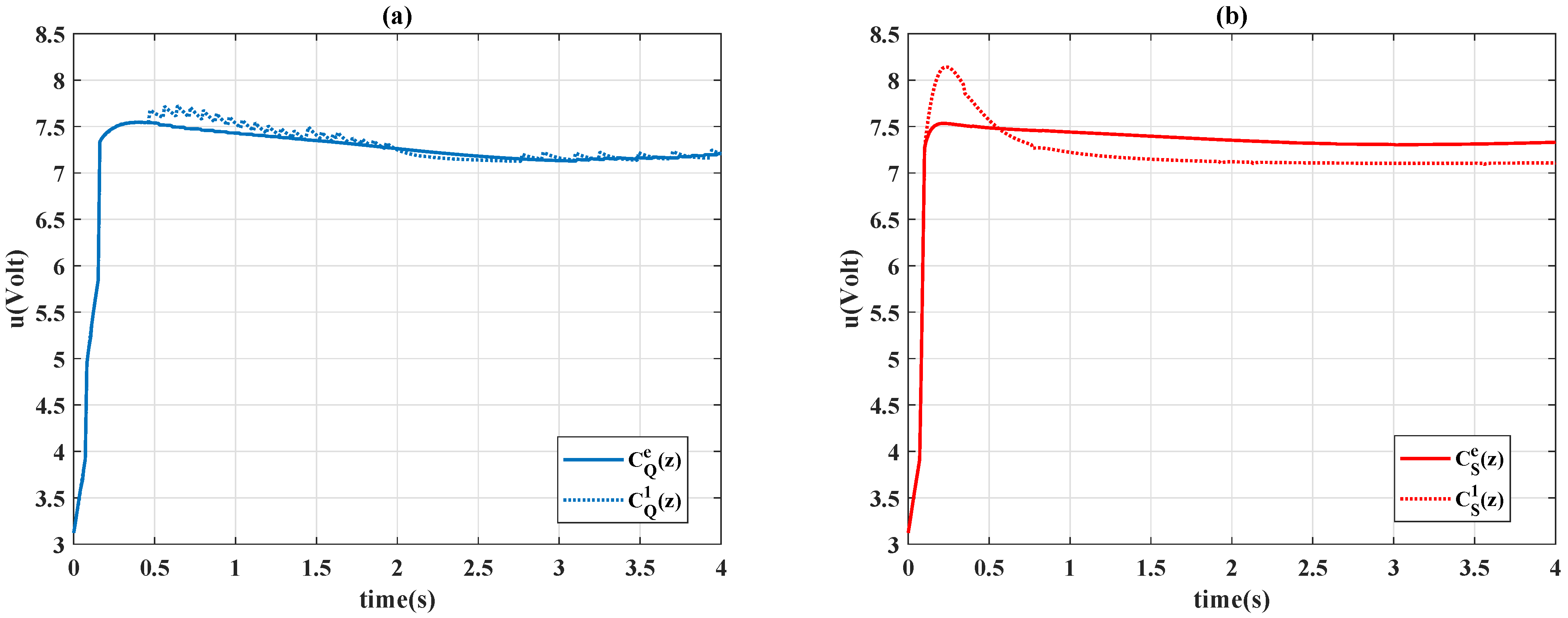
4.2. Comparison to Constant PID Controllers
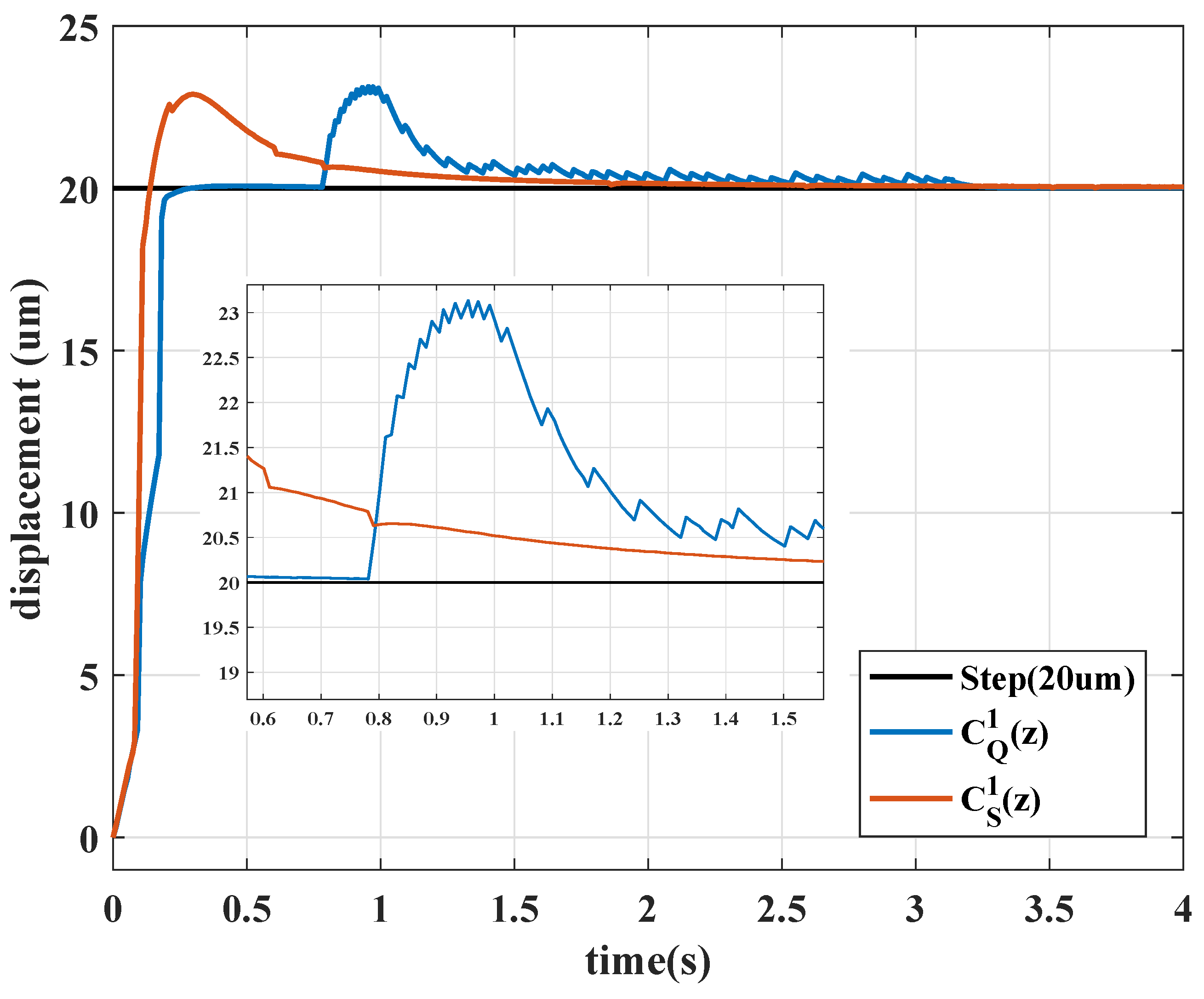
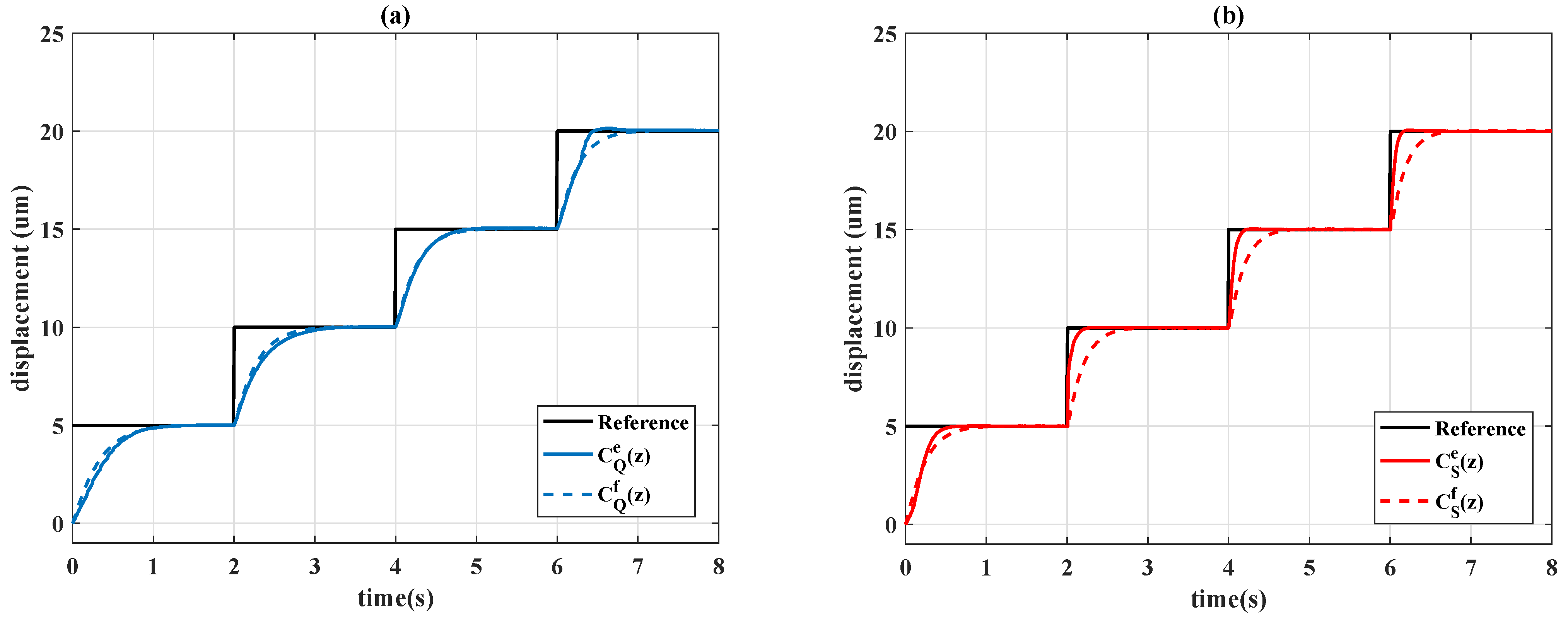
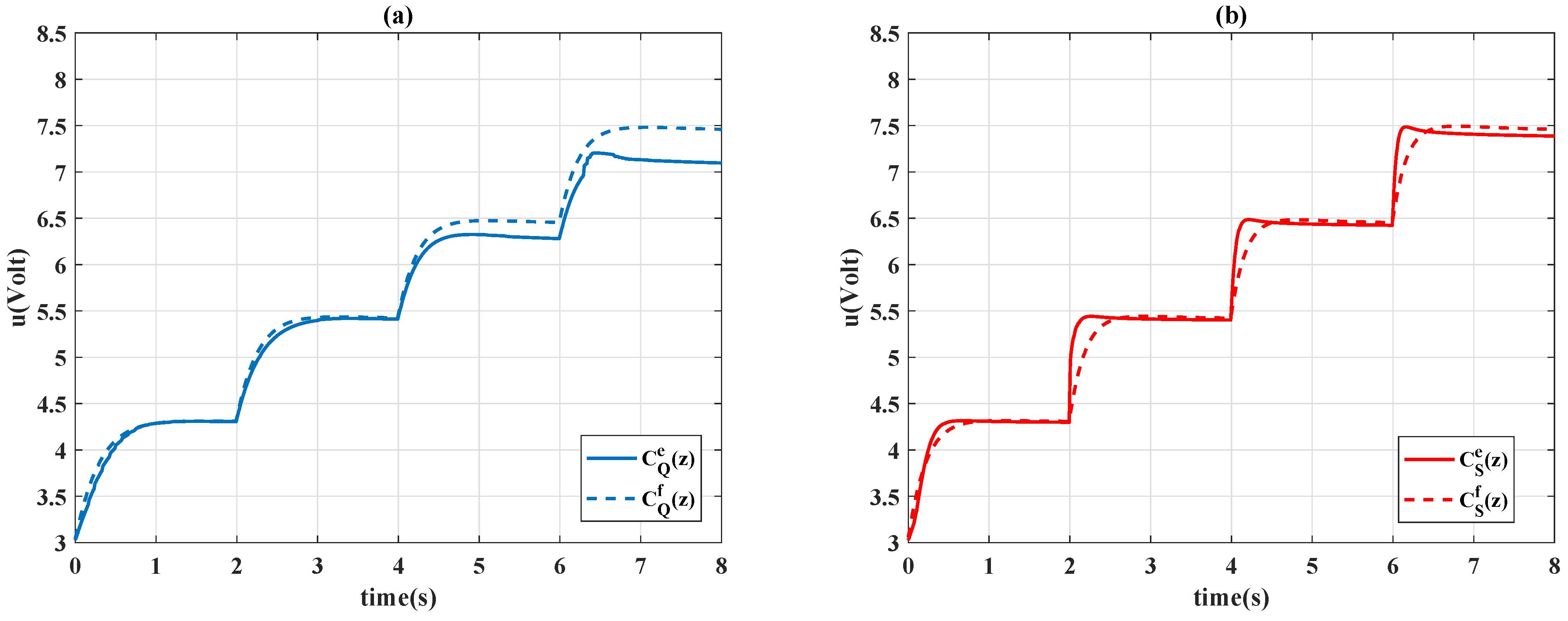
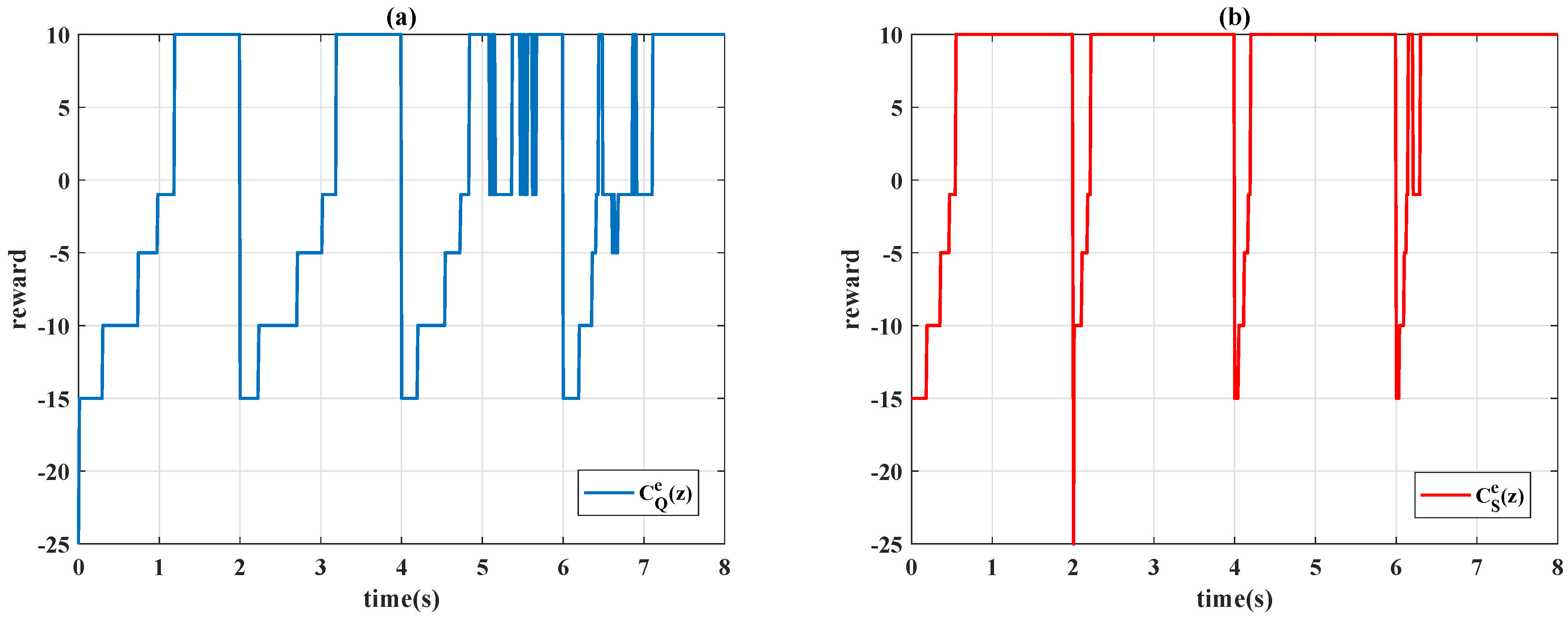
4.3. Time-Varying Reference
4.4. Robustness Test
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rozlosnik, A.E. Reimagining infrared industry with artificial intelligence and IoT/IIoT. In Thermosense: Thermal Infrared Applications XLII. International Society for Optics and Photonic; SPIE Digital library: Buenos Aires, Argentina, 2020; Volume 11409. [Google Scholar]
- Rathod, J. Branches in Artificial Intelligence to Transform Your Business! Medium.com. 24 November 2020. Available online: https://pub.towardsai.net/branches-in-artificial-intelligence-to-transform-your-business-f08103a91ab2 (accessed on 25 November 2021).
- Simeone, O. A very brief introduction to machine learning with applications to communication systems. IEEE Trans. Cogn. Commun. Netw. 2018, 4, 648–664. [Google Scholar] [CrossRef] [Green Version]
- Zhai, X.; Oliver, A.; Kolesnikov, A.; Beyer, L. S4L: Self-Supervised Semi-Supervised Learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 23 July 2019. [Google Scholar]
- Wang, L. Discovering phase transitions with unsupervised learning. Phys. Rev. B 2016, 94, 195105. [Google Scholar] [CrossRef] [Green Version]
- Herbrich, R. Learning Kernel Classifiers Theory and Algorithms; MIT Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; MIT Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Watkins, C.J.C.H. Learning from Delayed Rewards; King’s College: Cambridge, UK, 1989. [Google Scholar]
- Sutton, R.S. Temporal Credit Assignment in Reinforcement Learning. Doctoral Dissertation, University of Massachusetts Amherst, Amherst, MA, USA, 1985. [Google Scholar]
- Sutton, R.S. Learning to predict by the methods of temporal differences. Mach. Learn. 1988, 3, 9–44. [Google Scholar] [CrossRef]
- Rummery, G.A.; Niranjan, M. On-Line Q-Learning Using Connectionist Systems; University of Cambridge, Department of Engineering: Cambridge, UK, 1994. [Google Scholar]
- Tavakoli, F.; Derhami, V.; Kamalinejad, A. Control of Humanoid Robot Walking by Fuzzy Sarsa Learning. In Proceedings of the 2015 3rd RSI International Conference on Robotics and Mechatronics (ICROM), Tehran, Iran, 7–9 October 2015; pp. 234–239. [Google Scholar]
- Yuvaraj, N.; Raja, R.; Ganesan, V.; Dhas, S.G. Analysis on improving the response time with PIDSARSA-RAL in ClowdFlows mining platform. EAI Endorsed Trans. Energy Web 2018, 5, e2. [Google Scholar] [CrossRef] [Green Version]
- Shi, Q.; Lam, H.K.; Xiao, B.; Tsai, S.H. Adaptive PID controller based on Q-learning algorithm. CAAI Trans. Intell. Technol. 2018, 3, 235–244. [Google Scholar] [CrossRef]
- Hakim, A.E.; Hindersah, H.; Rijanto, E. Application of Reinforcement Learning on Self-Tuning PID Controller for Soccer Robot. In Proceedings of the Joint International Conference on Rural Information & Communication Technology and Electric-Vehicle Technology (rICT & ICeV-T), Bandung, Indonesia, 26–28 November 2013; pp. 26–28. [Google Scholar]
- Koszałka, L.; Rudek, R.; Poz’niak-Koszałka, I. An Idea of Using Reinforcement Learning in Adaptive Control Systems. In Proceedings of the International Conference on Networking, International Conference on Systems and International Conference on Mobile Communication and Learning Technologie (ICNICONSMCL’06), Morne, Mauritius, 23–29 April 2006; p. 190. [Google Scholar]
- Yang, Y.; Wan, Y.; Zhu, J.; Lewis, F.L. H∞ Tracking Control for Linear Discrete-Time Systems: Model-Free Q-Learning Designs. IEEE Control. Syst. Lett. 2020, 5, 175–180. [Google Scholar] [CrossRef]
- Sun, W.; Zhao, G.; Peng, Y. Adaptive optimal output feedback tracking control for unknown discrete-time linear systems using a combined reinforcement Q-learning and internal model method. IET Control. Theory Appl. 2019, 13, 3075–3086. [Google Scholar] [CrossRef]
- Liu, Y.; Yu, R. Model-free optimal tracking control for discrete-time system with delays using reinforcement Q-learning. Electron. Lett. 2018, 54, 750–752. [Google Scholar] [CrossRef]
- Fu, H.; Chen, X.; Wang, W.; Wu, M. MRAC for unknown discrete-time nonlinear systems based on supervised neural dynamic programming. Neurocomputing 2020, 384, 130–141. [Google Scholar] [CrossRef]
- Radac, M.-B.; Lala, T. Hierarchical Cognitive Control for Unknown Dynamic Systems Tracking. Mathematics 2021, 9, 2752. [Google Scholar] [CrossRef]
- Veselý, V.; Ilka, A. Gain-scheduled PID controller design. J. Process Control 2013, 23, 1141–1148. [Google Scholar] [CrossRef]
- Poksawat, P.; Wang, L.; Mohamed, A. Gain scheduled attitude control of fixed-wing UAV with automatic controller tuning. IEEE Trans. Control. Syst. Technol. 2017, 26, 1192–1203. [Google Scholar] [CrossRef]
- Mizumoto, M. Realization of PID controls by fuzzy control methods. Fuzzy Sets Syst. 1995, 70, 171–182. [Google Scholar] [CrossRef]
- Mann, G.K.; Hu, B.-G.; Gosine, R.G. Analysis of direct action fuzzy PID controller structures. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 1999, 29, 371–388. [Google Scholar] [CrossRef]
- Carvajal, J.; Chen, G.; Ogmen, H. Fuzzy PID controller: Design, performance evaluation, and stability analysis. Inf. Sci. 2000, 123, 249–270. [Google Scholar] [CrossRef]
- Tang, K.-S.; Man, K.F.; Chen, G.; Kwong, S. An optimal fuzzy PID controller. IEEE Trans. Ind. Electron. 2001, 48, 757–765. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Z.-Y.; Tomizuka, M.; Isaka, S. Fuzzy gain scheduling of PID controllers. IEEE Trans. Syst. Man Cybern. 1993, 23, 1392–1398. [Google Scholar] [CrossRef] [Green Version]
- Blanchett, T.; Kember, G.; Dubay, R. PID gain scheduling using fuzzy logic. ISA Trans. 2000, 39, 317–325. [Google Scholar] [CrossRef]
- Bingul, Z.; Karahan, O. A novel performance criterion approach to optimum design of PID controller using cuckoo search algorithm for AVR system. J. Frankl. Inst. 2018, 355, 5534–5559. [Google Scholar] [CrossRef]
- Jin, X.; Chen, K.; Zhao, Y.; Ji, J.; Jing, P. Simulation of hydraulic transplanting robot control system based on fuzzy PID controller. Measurement 2020, 164, 108023. [Google Scholar] [CrossRef]
- Van, M. An enhanced robust fault tolerant control based on an adaptive fuzzy PID-nonsingular fast terminal sliding mode control for uncertain nonlinear systems. IEEE/ASME Trans. Mechatronics 2018, 23, 1362–1371. [Google Scholar] [CrossRef] [Green Version]
- Berry, D.A.; Fristedt, B. Bandit Problems: Sequential Allocation of Experiments; Chapman and Hall: London, UK, 1985. [Google Scholar]
- Dearden, R.; Friedman, N.; Russell, S. Bayesian Q-learning. In Aaai/iaai; American Association for Artificial Intelligence: Palo Alto, CA, USA, 1998; pp. 761–768. [Google Scholar]
- Goldfarb, M.; Celanovic, N. Modeling piezoelectric stack actuators for control of micromanipulation. IEEE Control. Syst. Mag. 1997, 17, 69–79. [Google Scholar]
- Yeh, Y.L.; Yen, J.Y.; Wu, C.J. Adaptation-Enhanced Model-Based Control with Charge Feedback for Piezo-Actuated Stage. Asian J. Control 2020, 22, 104–116. [Google Scholar] [CrossRef]
- Åström, K.J.; Hägglund, T. Advanced PID Control; ISA—The Instrumentation, Systems, and Automation Society: Research Triangle Park, NC, USA, 2006. [Google Scholar]
- Rugh, W.J.; Shamma, J.S. Research on gain scheduling. Automatica 2000, 36, 1401–1425. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Range of Partition | |
|---|---|
| 1 | −25 |
| 0.5 1 | −15 |
| 0.1 0.5 | −10 |
| 0.03 0.1 | −5 |
| 0.01 0.03 | −1 |
| others | 10 |
| Action | Adjustment |
|---|---|
| 1 | if 1, , else |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | no action |
| 8 |
| Q-Learning Controller | Sarsa Controller | |||
|---|---|---|---|---|
| Rise Time (s) | 0.1226 | 0.1152 | 0.0559 | 0.0548 |
| Settling Time (s) | 6.142 | 0.2886 | 1.1533 | 0.1592 |
| Overshoot (%) | 15.6647 | 0.1838 | 14.4465 | 0.2477 |
| RMSE (um) | 0.4224 | 0.4026 | 0.3783 | 0.3652 |
| 0.000567 | 0.000371 | 0.022680 | 0.2 | 1.2 | |
| 0.041982 | 0.056906 | 0.083964 | 0.083964 | 0.083964 | |
| 0.00185 | 0.001085 | 0.074 | 0.074 | 0.074 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yeh, Y.-L.; Yang, P.-K. Design and Comparison of Reinforcement-Learning-Based Time-Varying PID Controllers with Gain-Scheduled Actions. Machines 2021, 9, 319. https://doi.org/10.3390/machines9120319
Yeh Y-L, Yang P-K. Design and Comparison of Reinforcement-Learning-Based Time-Varying PID Controllers with Gain-Scheduled Actions. Machines. 2021; 9(12):319. https://doi.org/10.3390/machines9120319
Chicago/Turabian StyleYeh, Yi-Liang, and Po-Kai Yang. 2021. "Design and Comparison of Reinforcement-Learning-Based Time-Varying PID Controllers with Gain-Scheduled Actions" Machines 9, no. 12: 319. https://doi.org/10.3390/machines9120319
APA StyleYeh, Y. -L., & Yang, P. -K. (2021). Design and Comparison of Reinforcement-Learning-Based Time-Varying PID Controllers with Gain-Scheduled Actions. Machines, 9(12), 319. https://doi.org/10.3390/machines9120319