


Pneumonia and Pulmonary Thromboembolism Classification Using Electronic Health Records
 ,
,  , , , and
, , , and
Abstract
:1. Introduction
1.1. Respiratory Diseases
1.2. Pneumonia and PTE Diagnosis
1.3. Computational Tools for Data Analysis
1.4. State-of-the-Art
1.5. Aim
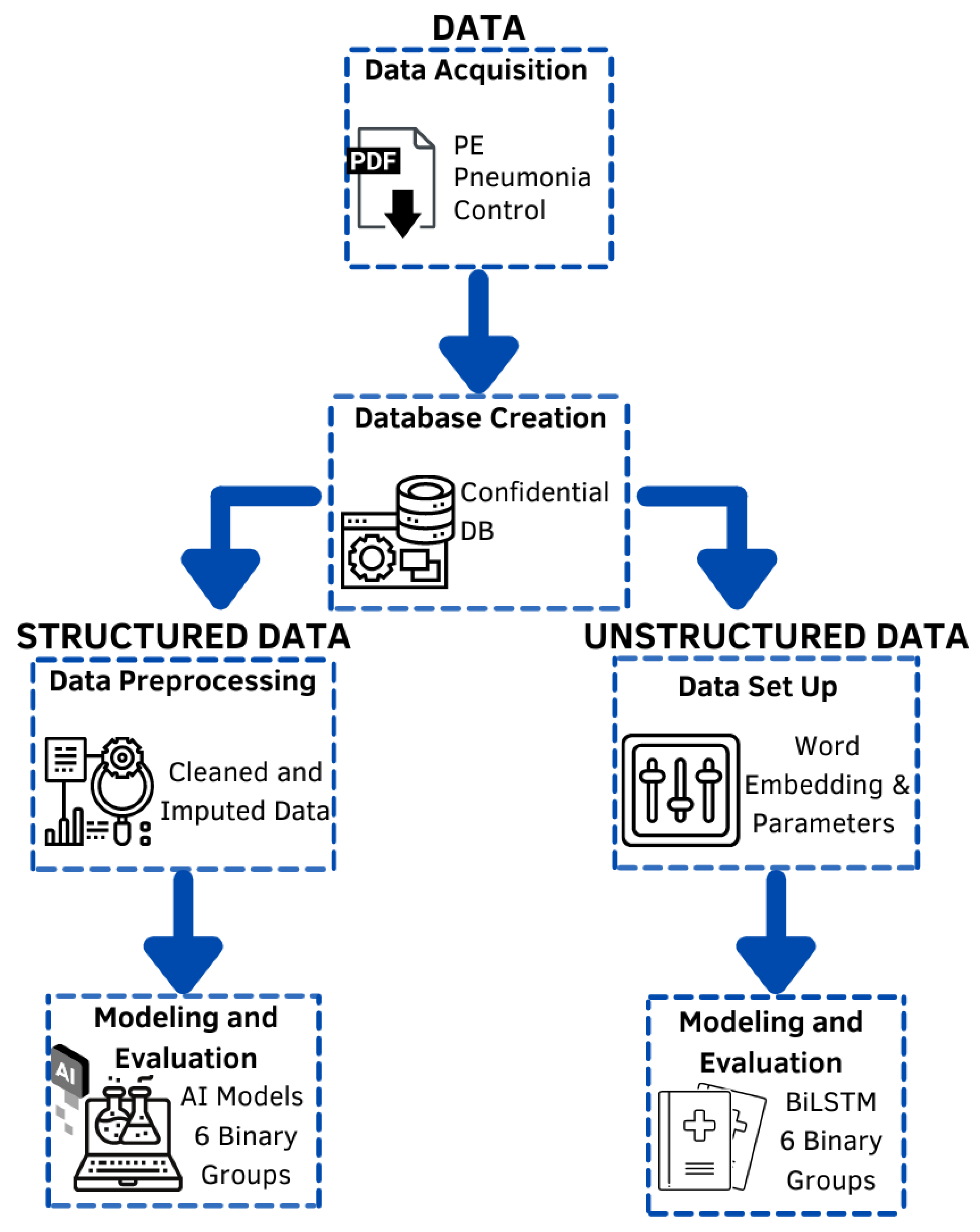
2. Materials and Methods
2.1. Data—Data Acquisition
2.2. Data—Database Creation
2.3. Structured Data—Data Preprocessing
2.4. Structured Data—Modeling and Evaluation
2.5. Unstructured Data—Data Set Up
- Tokenization;
- Stopwords removal;
- Unnecessary characters removal;
- Text conversion to lowercase;
- Text stemming;
- Text lemmatization.
2.6. Unstructured Data—Modeling and Evaluation
3. Results
3.1. Structured Data
3.2. Unstructured Data
4. Discussion
4.1. Structured Data
4.1.1. 1-Group vs. 1-Group
4.1.2. 1-Group vs. Rest
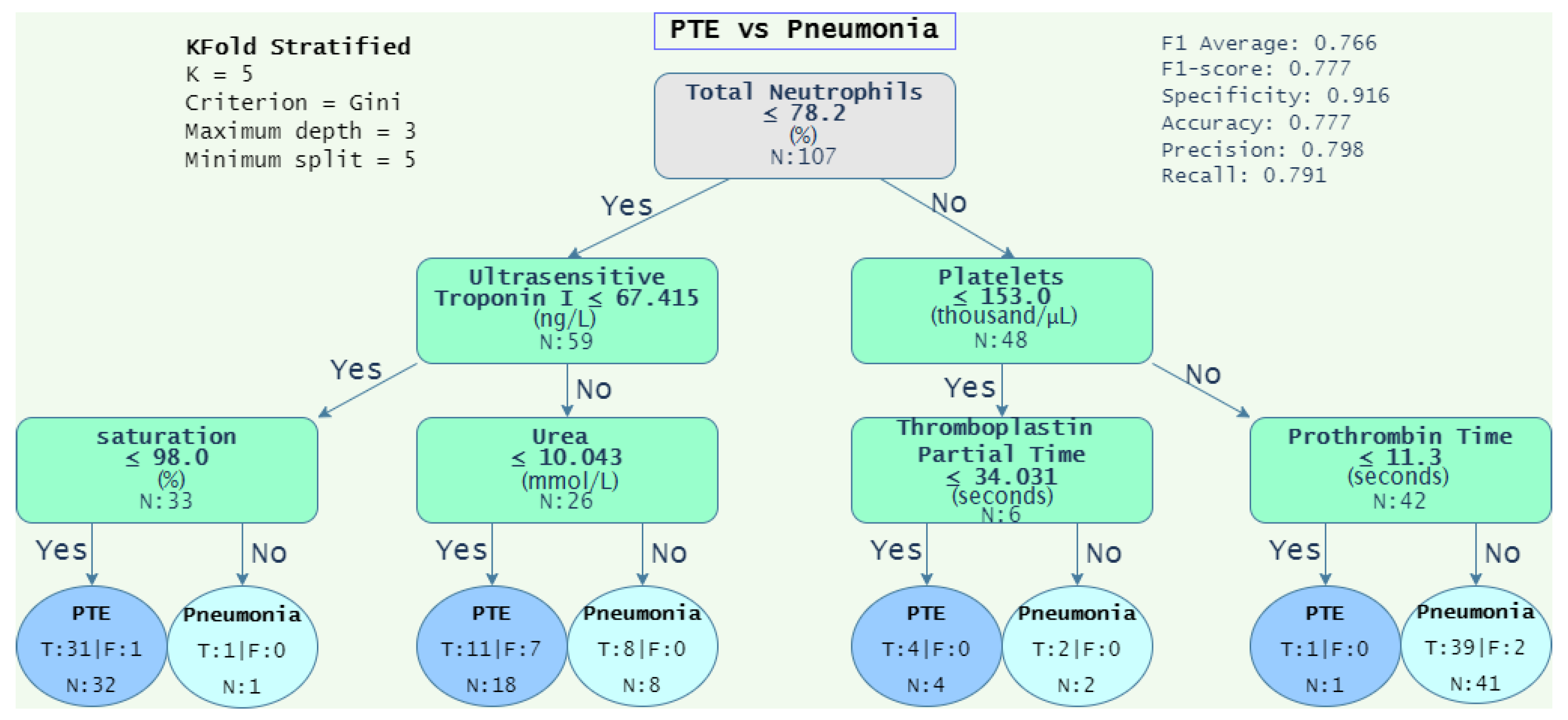
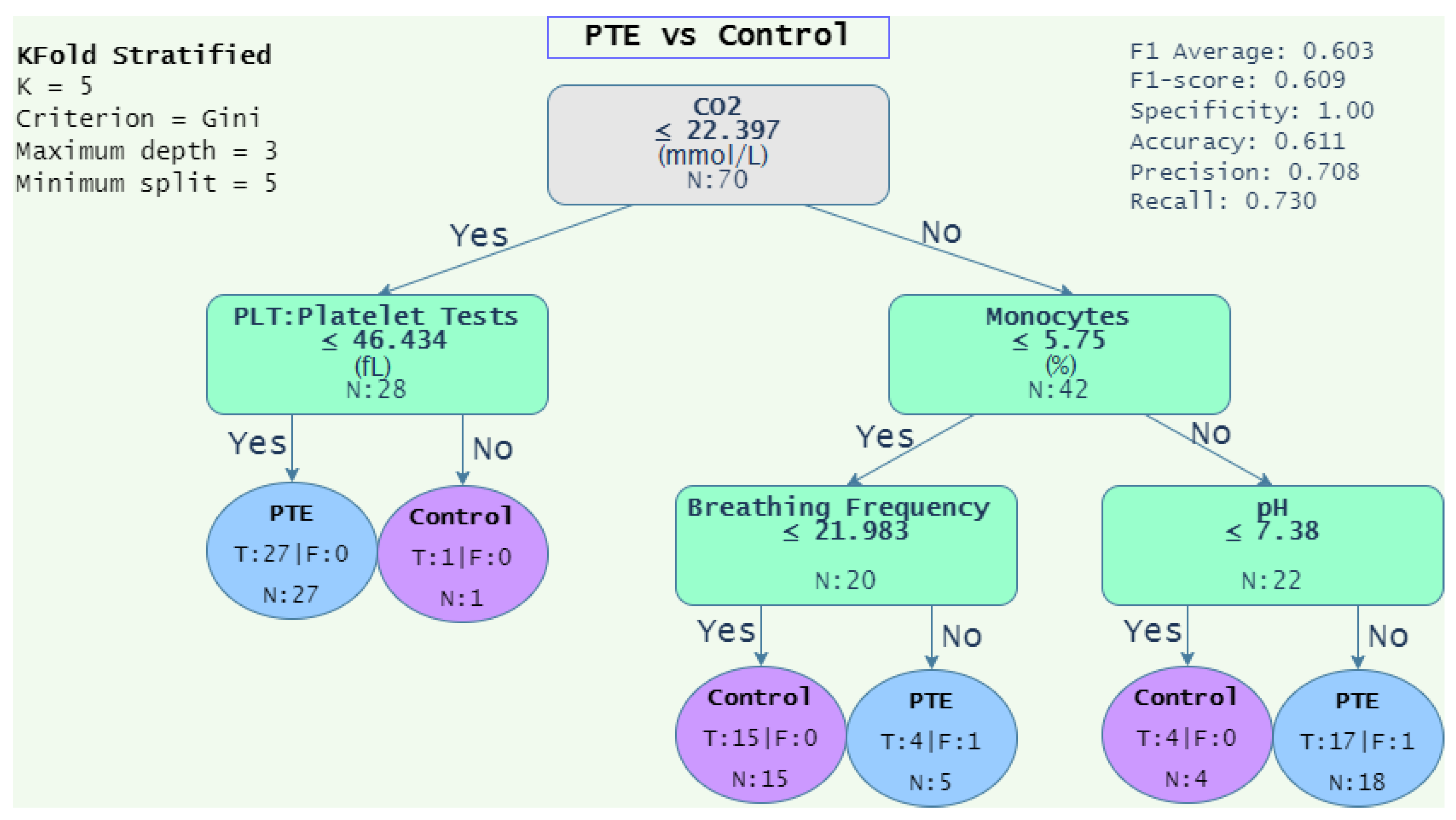
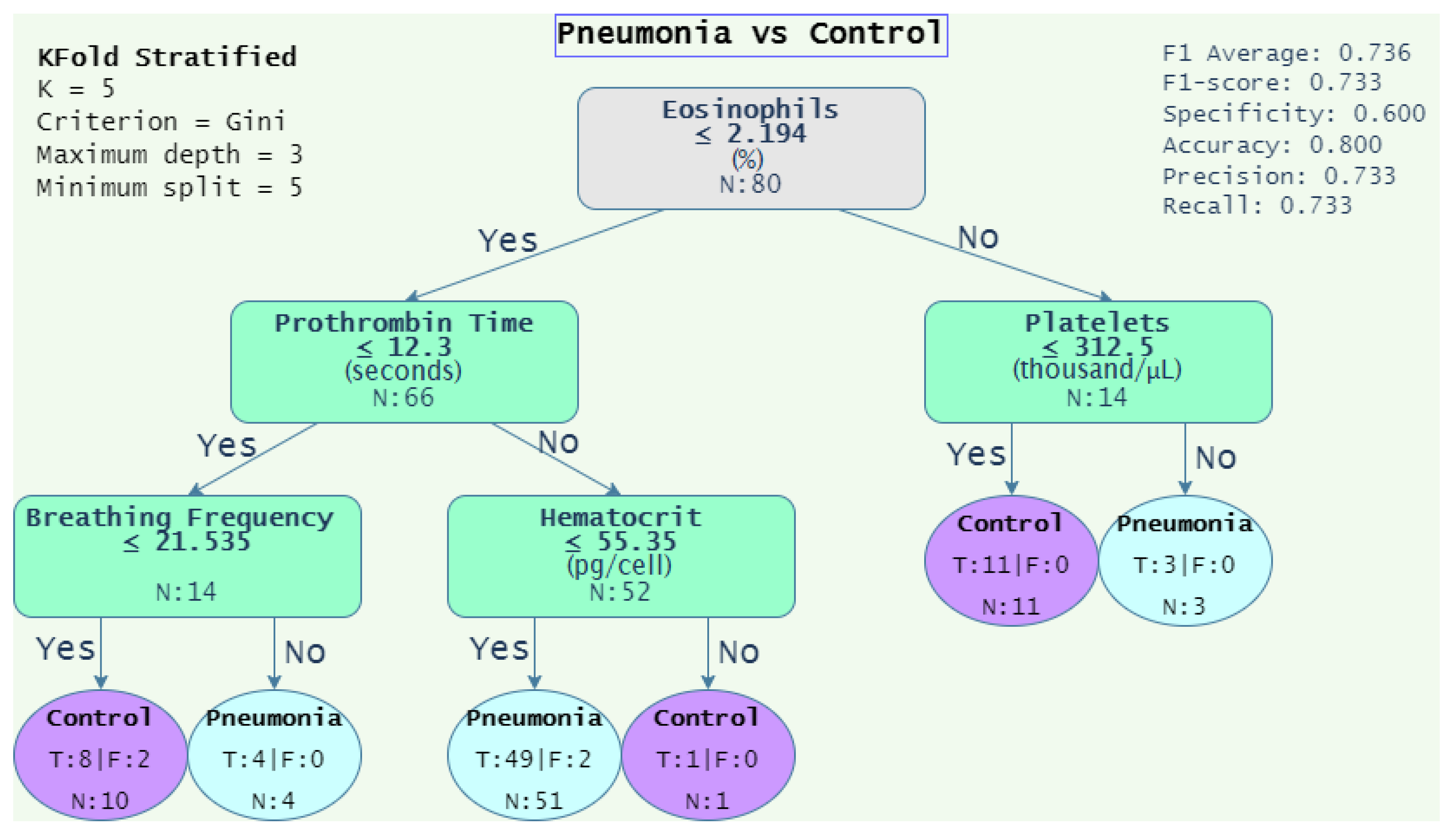
4.1.3. Decision Rules
4.2. Unstructured Data
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| USA | United States of America |
| PTE | Pulmonary Thromboembolism |
| VTE | Venous Thromboembolism |
| IMSS | Mexican Social Security Institute (by its acronym in Spanish) |
| EHR | Electronic Health Records |
| KDD | Knowledge Discovery From Data |
| ML | Machine Learning |
| NLP | Natural Language Processing |
| ICD-9 | International Classification of Disease, Ninth Revision |
| ICD-10 | International Classification of Disease, Tenth Revision |
| RNN | Recurrent Neural Network |
| LSTM | Long-Short Term Memory |
| ARDS | Respiratory Distress Syndrome |
| AUC-ROC | Area Under Curve-Receiver Operating Characteristic |
| SVM | Support Vector Machine |
| API | Asthma Predictive Index |
| WE | Word Embeddings |
| RF | Random Forest |
| Portable Document Format | |
| NB | Naïve Bayes |
| NSS | Social Security Number (by its acronym in Spanish) |
| DT | Decision Tree |
| ANN | Artificial Neural Network |
| SGD | Stochastic Gradient Descent |
| CBOW | Continuous Bag of Words |
| BiLSTM | Bidirectional Long-Short Term Memory |
| CA | Classification Accuracy |
| DPApC | Dataset Performance Average per Classifier |
| CPApD | Classifier Performance Average per Dataset |
| TN | Total Neutrophils |
| UTI | Ultrasensitive Troponin I |
| Sat | Saturation |
| Ur | Urea |
| Plat | Platelets |
| PT | Prothrombin Time |
| PLT | Platelet Test |
| Mono | Monocytes |
| BF | Breathing Frequency |
| pH | Potential Hydrogen |
| CO2 | Carbon Dioxide |
| Eos | Eosinophils |
| ProTime | Prothrombin Time |
| Hema | Hematocrit |
| TPT | Tromboplatin Partial Time |
| PCO2 | Partial Pressure of Carbon Dioxide |
| SC | Serum Calcium |
| Pro | Procalcitonin |
References
- Paramothayan, S. Essential Respiratory Medicine; Wiley-Blackwell: Hoboken, NJ, USA, 2018. [Google Scholar]
- Ramirez, J.A.; Wiemken, T.L.; Peyrani, P.; Arnold, F.W.; Kelley, R.; Mattingly, W.A.; Nakamatsu, R.; Pena, S.; Guinn, B.E.; Furmanek, S.P.; et al. Adults Hospitalized With Pneumonia in the United States: Incidence, Epidemiology, and Mortality. Clin. Infect. Dis. 2017, 65, 1806–1812. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- INEGI. Características De Las Defunciones Registradas En México Durante 2020. 2020. Available online: https://www.inegi.org.mx/contenidos/saladeprensa/boletines/2021/EstSociodemo/DefuncionesRegistradas2020preliminar.pdf (accessed on 6 May 2022).
- Huisman, M.V.; Barco, S.; Cannegieter, S.C.; Le Gal, G.; Konstantinides, S.V.; Reitsma, P.H.; Rodger, M.; Vonk Noordegraaf, A.; Klok, F.A. Pulmonary embolism. Nat. Rev. Dis. Prim. 2018, 4, 18028. [Google Scholar] [CrossRef] [PubMed]
- Debnath, J.; Sharma, V. Diagnosing pulmonary thromboembolism: Concerns and controversies. Med. J. Armed Forces India 2022, 78, 17–23. [Google Scholar] [CrossRef] [PubMed]
- Konstantinides, S.V.; Meyer, G.; Becattini, C.; Bueno, H.; Geersing, G.J.; Harjola, V.P.; Huisman, M.V.; Humbert, M.; Jennings, C.S.; Jiménez, D.; et al. 2019 ESC Guidelines for the diagnosis and management of acute pulmonary embolism developed in collaboration with the European Respiratory Society (ERS): The Task Force for the diagnosis and management of acute pulmonary embolism of the European Society of Cardiology (ESC). Eur. Heart J. 2019, 41, 543–603. [Google Scholar] [CrossRef] [Green Version]
- Cabrera-Rayo, A.; Nellen-Hummel, H. Epidemiología de la enfermedad tromboembólica venosa. Gac. Médica De México 2007, 143, 3–5. [Google Scholar]
- Machado Villarroel, L.; Dimakis RamÃrez, D.A. Enfoque diagnóstico de la tromboembolia pulmonar. Acta Médica Grupo Ángeles 2017, 15, 36–46. [Google Scholar] [CrossRef]
- Musher, D.M.; Thorner, A.R. Community-Acquired Pneumonia. N. Engl. J. Med. 2014, 371, 1619–1628. [Google Scholar] [CrossRef]
- Ruaro, B.; Baratella, E.; Caforio, G.; Confalonieri, P.; Wade, B.; Marrocchio, C.; Geri, P.; Pozzan, R.; Andrisano, A.G.; Cova, M.A.; et al. Chronic Thromboembolic Pulmonary Hypertension: An Update. Diagnostics 2022, 12, 235. [Google Scholar] [CrossRef]
- Metlay, J.P.; Waterer, G.W.; Long, A.C.; Anzueto, A.; Brozek, J.; Crothers, K.; Cooley, L.A.; Dean, N.C.; Fine, M.J.; Flanders, S.A.; et al. Diagnosis and Treatment of Adults with Community-acquired Pneumonia. An Official Clinical Practice Guideline of the American Thoracic Society and Infectious Diseases Society of America. Am. J. Respir. Crit. Care Med. 2019, 200, e45–e67. [Google Scholar] [CrossRef]
- Kaul, V.; Enslin, S.; Gross, S.A. History of artificial intelligence in medicine. Gastrointest. Endosc. 2020, 92, 807–812. [Google Scholar] [CrossRef]
- Fayyad, U.; Piatetsky-Shapiro, G.; Smyth, P. From Data Mining to Knowledge Discovery in Databases. AIMag 1996, 17, 37. [Google Scholar]
- Han, J.; Kamber, M.; Pei, J. Data Mining: Concepts and Techniques, 3rd ed.; Morgan Kaufmann Series in Data Management Systems (eBook); Morgan Kaufmann: Burlington, MA, USA, 2014. [Google Scholar]
- Nemethova, A.; Nemeth, M.; Michalconok, G.; Bohm, A. Identification of KDD Problems from Medical Data. In Artificial Intelligence Methods in Intelligent Algorithms; Silhavy, R., Ed.; Springer International Publishing: Cham, Switzerland, 2019; pp. 191–199. [Google Scholar]
- Kreimeyer, K.; Foster, M.; Pandey, A.; Arya, N.; Halford, G.; Jones, S.F.; Forshee, R.; Walderhaug, M.; Botsis, T. Natural language processing systems for capturing and standardizing unstructured clinical information: A systematic review. J. Biomed. Inform. 2017, 73, 14–29. [Google Scholar] [CrossRef] [PubMed]
- Choi, E.; Taha Bahadori, M.; Schuetz, A.; Stewart, W.F.; Sun, J. Doctor AI: Predicting Clinical Events via Recurrent Neural Networks. arXiv 2015, arXiv:1511.05942. [Google Scholar]
- Lipton, Z.C.; Kale, D.C.; Elkan, C.; Wetzel, R. Learning to Diagnose with LSTM Recurrent Neural Networks. arXiv 2015, arXiv:1511.03677. [Google Scholar]
- Suresh, H.; Hunt, N.; Johnson, A.; Celi, L.A.; Szolovits, P.; Ghassemi, M. Clinical Intervention Prediction and Understanding using Deep Networks. arXiv 2017, arXiv:1705.08498. [Google Scholar]
- Li, J.; Wan, L.; Feng, Y.; Zuo, H.; Zhao, Q.; Ren, J.; Zhang, X.; Xia, M. Laboratory Predictors of COVID-19 Pneumonia in Patients with Mild to Moderate Symptoms. Lab. Med. 2021, 52, e104–e114. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, Z.; Razavian, N. Deep EHR: Chronic Disease Prediction Using Medical Notes. arXiv 2018, arXiv:1808.04928. [Google Scholar]
- Bagheri, A.; Groenhof, T.K.J.; Veldhuis, W.B.; de Jong, P.A.; Asselbergs, F.W.; Oberski, D.L. Multimodal learning for cardiovascular risk prediction using EHR data. arXiv 2020, arXiv:2008.11979. [Google Scholar]
- Jones, B.E.; South, B.R.; Shao, Y.; Lu, C.C.; Leng, J.; Sauer, B.C.; Gundlapalli, A.V.; Samore, M.H.; Zeng, Q. Development and Validation of a Natural Language Processing Tool to Identify Patients Treated for Pneumonia across VA Emergency Departments. Appl. Clin. Inf. 2018, 9, 122–128. [Google Scholar] [CrossRef] [Green Version]
- Kaur, H.; Sohn, S.; Wi, C.I.; Ryu, E.; Park, M.A.; Bachman, K.; Kita, H.; Croghan, I.; Castro-Rodriguez, J.A.; Voge, G.A.; et al. Automated chart review utilizing natural language processing algorithm for asthma predictive index. BMC Pulm. Med. 2018, 18, 34. [Google Scholar] [CrossRef] [Green Version]
- Villena, F.; Pérez, J.; Lagos, R.; Dunstan, J. Supporting the classification of patients in public hospitals in Chile by designing, deploying and validating a system based on natural language processing. BMC Med. Inform. Decis. Mak. 2021, 21, 208. [Google Scholar] [CrossRef]
- Bujang, M.A.; Adnan, T.H. Requirements for Minimum Sample Size for Sensitivity and Specificity Analysis. J. Clin. Diagn. Res. 2016, 10, YE01–YE06. [Google Scholar] [CrossRef] [PubMed]
- Silberschatz, A.; Korth, H.F.; Sudarshan, S. Database System Concepts, 6th ed.; McGraw-Hill Professional: New York, NY, USA, 2010. [Google Scholar]
- Xu, H.; Deng, Y. Dependent Evidence Combination Based on Shearman Coefficient and Pearson Coefficient. IEEE Access 2018, 6, 11634–11640. [Google Scholar] [CrossRef]
- Kowsari, K.; Jafari Meimandi, K.; Heidarysafa, M.; Mendu, S.; Barnes, L.; Brown, D. Text Classification Algorithms: A Survey. Information 2019, 10, 150. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Hsu, C.W.; Chang, C.C.; Lin, C.J. A Practical Guide to Support Vector Classification. 2003. Available online: https://www.csie.ntu.edu.tw/~cjlin/papers/guide/guide.pdf (accessed on 13 July 2022).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- LeCun, Y.A.; Bottou, L.; Orr, G.B.; Müller, K.R. Efficient backprop. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 9–48. [Google Scholar]
- Freund, Y.; Schapire, R.E. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Zhu, J.; Rosset, S.; Zou, H.; Hastie, T. Multi-class AdaBoost. Stat. Its Interface 2006, 2, 349–360. [Google Scholar] [CrossRef]
- Loper, E.; Bird, S. NLTK: The Natural Language Toolkit. In Proceedings of the the ACL-02 Workshop on Effective Tools and Methodologies for Teaching Natural Language Processing and Computational Linguistics, Philadelphia, PA, USA, 7 July 2002; ETMTNLP ’02. Association for Computational Linguistics: Stroudsburg, PA, USA, 2002; Volume 1, pp. 63–70. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Douze, M.; Jégou, H.; Mikolov, T. Fasttext. zip: Compressing text classification models. arXiv 2016, arXiv:1612.03651. [Google Scholar]
- Gutiérrez-Fandiño, A.; Armengol-Estapé, J.; Carrino, C.P.; De Gibert, O.; Gonzalez-Agirre, A.; Villegas, M. Spanish Biomedical and Clinical Language Embeddings. arXiv 2021, arXiv:2102.12843. [Google Scholar]
- Chiu, J.P.C.; Nichols, E. Named Entity Recognition with Bidirectional LSTM-CNNs. arXiv 2015, arXiv:1511.08308. [Google Scholar] [CrossRef]
- Ramos-Vargas, R.E.; Román-Godínez, I.; Torres-Ramos, S. Comparing general and specialized word embeddings for biomedical named entity recognition. PeerJ Comput. Sci. 2021, 7, e384. [Google Scholar] [CrossRef]
- Ali, M.N.A.; Tan, G.; Hussain, A. Bidirectional Recurrent Neural Network Approach for Arabic Named Entity Recognition. Future Internet 2018, 10, 123. [Google Scholar] [CrossRef] [Green Version]
- Elgeldawi, E.; Sayed, A.; Galal, A.R.; Zaki, A.M. Hyperparameter Tuning for Machine Learning Algorithms Used for Arabic Sentiment Analysis. Informatics 2021, 8, 79. [Google Scholar] [CrossRef]
- Lanks, C.W.; Musani, A.I.; Hsia, D.W. Community-acquired Pneumonia and Hospital-acquired Pneumonia. Med. Clin. N. Am. 2019, 103, 487–501. [Google Scholar] [CrossRef] [PubMed]
- Ibarra, I.J.S.; Arroyo, N.V.A.; Romero, E.F.R.; Dávila, A.P.; Escobar, M.G.H.; Aldama, J.C.G. Perfil tromboelastográfico en pacientes con neumonía por SARS-CoV-2. Med. Crítica 2021, 35, 312–318. [Google Scholar] [CrossRef]
- Rae, N.; Finch, S.; Chalmers, J.D. Cardiovascular disease as a complication of community-acquired pneumonia. Curr. Opin. Pulm. Med. 2016, 22, 212–218. [Google Scholar] [CrossRef]
- Lim, W.S.; van der Eerden, M.M.; Laing, R.; Boersma, W.G.; Karalus, N.; Town, G.I.; Lewis, S.A.; Macfarlane, J.T. Defining community acquired pneumonia severity on presentation to hospital: An international derivation and validation study. Thorax 2003, 58, 377–382. [Google Scholar] [CrossRef] [Green Version]
- Goldhaber, S.Z.; Elliott, C.G. Acute pulmonary embolism: Part I: Epidemiology, pathophysiology, and diagnosis. Circulation 2003, 108, 2726–2729. [Google Scholar] [CrossRef]
- Fleming, S.; Thompson, M.; Stevens, R.; Heneghan, C.; Plüddemann, A.; Maconochie, I.; Tarassenko, L.; Mant, D. Normal ranges of heart rate and respiratory rate in children from birth to 18 years of age: A systematic review of observational studies. Lancet 2011, 377, 1011–1018. [Google Scholar] [CrossRef] [Green Version]
- Pavord, I.D.; Lettis, S.; Anzueto, A.; Barnes, N. Blood eosinophil count and pneumonia risk in patients with chronic obstructive pulmonary disease: A patient-level meta-analysis. Lancet Respir. Med. 2016, 4, 731–741. [Google Scholar] [CrossRef]
- Facchini, F.S.; Carantoni, M.; Jeppesen, J.; Reaven, G.M. Hematocrit and hemoglobin are independently related to insulin resistance and compensatory hyperinsulinemia in healthy, non-obese men and women. Metabolism 1998, 47, 831–835. [Google Scholar] [CrossRef]
- Sakai, A.; Nakano, H.; Ohira, T.; Maeda, M.; Okazaki, K.; Takahashi, A.; Kawasaki, Y.; Satoh, H.; Ohtsuru, A.; Shimabukuro, M.; et al. Relationship between the prevalence of polycythemia and factors observed in the mental health and lifestyle survey after the Great East Japan Earthquake. Medicine 2020, 99, e18486. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hartl, S.; Breyer, M.K.; Burghuber, O.C.; Ofenheimer, A.; Schrott, A.; Urban, M.H.; Agusti, A.; Studnicka, M.; Wouters, E.F.; Breyer-Kohansal, R. Blood eosinophil count in the general population: Typical values and potential confounders. Eur. Respir. J. 2020, 55, 1901874. [Google Scholar] [CrossRef]
- Névéol, A.; Dalianis, H.; Velupillai, S.; Savova, G.; Zweigenbaum, P. Clinical Natural Language Processing in languages other than English: Opportunities and challenges. J. Biomed. Semant. 2018, 9, 12. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subjects with PTE or Pneumonia | Control Subjects |
|---|---|
| Patients over 18 years old | Patients over 18 years old |
| Patients with an admission note from the emergency department. | Patients without a final diagnosis of pneumonia or pulmonary embolism |
| Patients with one or more laboratory studies requested by the emergency department | Admission notes for preoperative assessment for bariatric surgery |
| Laboratory studies not older than one week with respect to the patient’s admission note | Patients with one or more laboratory studies for pre-surgical assessment of bariatric surgery |
| Laboratory studies with one or more studies of blood biometry, procalcitonin, blood chemistry, serum electrolytes, coagulation times, and/or arterial blood gases | Laboratory studies with one or more studies of blood biometry, procalcitonin, blood chemistry, serum electrolytes, coagulation times, and/or arterial blood gases |
| Patients with discharge summary from pulmonology | Discharge summary for pre-surgical assessment for bariatric surgery |
| Discharges summaries with final diagnosis of PTE or pneumonia | Discharge summary with final diagnosis of obesity due to excess calories |
| Final diagnosis according to ICD-10 classification | Final diagnosis according to ICD-10 classification |
| Clinical records from the year 2017 to 2022 | Clinical records from the year 2017 to 2022 |
| Field | Nature | Type | Field | Nature | Type |
|---|---|---|---|---|---|
| NSS (unique identifier) | Ql | N | Health indications and status | Ql | T |
| Date of admission | Qt | D | Weight | Qt | C |
| Subject’s gender | Ql | D | Height | Qt | C |
| Admission specialty | Ql | T | Temperature | Qt | C |
| Reason for admission | Ql | T | Respiratory rate | Qt | D |
| Interrogation | Ql | T | Blood pressure | Qt | D |
| Initial diagnosis | Ql | T | BMI (body mass index) | Qt | C |
| Treatment plan | Ql | T | Peripheral oxygen saturation | Qt | D |
| Prognosis | Ql | T | Capillary glucose | Qt | D |
| Field | Nature | Type | Field | Nature | Type |
|---|---|---|---|---|---|
| NSS (unique identifier) | Ql | N | Health indications and status | Ql | T |
| Date of admission | Qt | D | Prognosis of health | Ql | T |
| Date of discharge | Qt | D | Health status | Ql | T |
| Subject’s gender | Ql | T | Diagnosis discharge/demise | Ql | T |
| Specialty of discharge | Ql | T | Weight | Qt | C |
| Reason for egress | Ql | T | Size | Qt | C |
| Referral to specialty | Ql | T | Temperature | Qt | C |
| Admission diagnosis | Ql | T | Respiratory rate | Qt | D |
| Summary of progress | Ql | T | Blood pressure | Qt | D |
| Treatment plan | Ql | T | BMI (body mass index) | Qt | C |
| Recommendations | Ql | T | Peripheral oxygen saturation | Qt | D |
| Risk factors | Ql | T | Capillary blood glucose | Qt | D |
| Field | Nature | Type | Extracted Field | Nature | Type |
|---|---|---|---|---|---|
| NSS (unique identifier) | Ql | N | Patient’s age | Qt | D |
| Order folio requested | Ql | N | Qualitative service | Ql | T |
| Date of order | Qt | D |
| Field | Operational Definition | Nature | Type |
|---|---|---|---|
| Determination | Contains the name of the variable | Ql | T |
| Result | Contains the value of the variable | Qt | D/C |
| Unit | Contains the unit of the variable | Ql | T |
| Normal value | Contains the limiting values of the variable | Qt | D/C |
| Variables | Studies | Variables | Studies |
|---|---|---|---|
| Dimer II | Coagulation | Plateletocrit | Hematology |
| Thromboplastin partial time | Coagulation | Platelet Count (PLT) | Hematology |
| Prothrombin time | Coagulation | Red cell blood distribution width (RDW) | Hematology |
| Age | Vital signs | Mean corpuscular volume (MCV) | Hematology |
| Breathing frequency | Vital signs | Procalcitonin | Immune infect |
| Gender | Vital signs | High-sensitive troponin I | Immune infect |
| Diastolic blood pressure | Vital signs | Serum calcium | Clinical chemistry |
| Systolic blood pressure | Vital signs | Chlorine | Clinical chemistry |
| Saturation | Vital signs | CO2 | Clinical chemistry |
| Temperature | Vital signs | Serum creatinine | Clinical chemistry |
| Platelet distribution width (PDW) | Hematology | Base excess | Clinical chemistry |
| Basophils | Hematology | Phosphorus | Clinical chemistry |
| Mean corpuscular hemoglobin concentration (MCHC) | Hematology | Blood glucose | Clinical chemistry |
| Eosinophils | Hematology | HCO3 | Clinical chemistry |
| Erythrocytes | Hematology | Magnesium | Clinical chemistry |
| Mean corpuscular hemoglobin (MCH) | Hematology | PCO2 | Clinical chemistry |
| Hematocrit | Hematology | pH | Clinical chemistry |
| Leukocytes | Hematology | PO2 | Clinical chemistry |
| Lymphocytes | Hematology | potassium | Clinical chemistry |
| Monocytes | Hematology | O2 saturation | Clinical chemistry |
| Mean platelet volume (MPV) | Hematology | Sodium | Clinical chemistry |
| Total neutrophils | Hematology | Urea | Clinical chemistry |
| Platelets | Hematology |
| r Value | Selected | Discarded |
|---|---|---|
| +1 | Urea | Calculated Urea |
| +0.965 | Hematocrit | Hemoglobin |
| +0.965 | PT: Prothrombin Time | INR: International Normalized Ratio |
| Algorithm | Parameter | Value |
|---|---|---|
| Decision tree | Minimum number of instances in leaves | 3 |
| Limit of subsets splits | 5 | |
| Maximal tree depth | 3 | |
| Majority reaches (%) | 95 | |
| Random forest | Number of trees | 5 |
| Limit of subsets splits | 5 | |
| Support vector machine | Cost | 1 |
| Regression loss epsilon | 0.10 | |
| Kernel | RBF | |
| Numerical tolerance | 0.001 | |
| Iteration limit | 100 | |
| Neural networks | Neurons in hidden layers | 10, 6 |
| Activation | Tanh | |
| Solver | Adam | |
| Regularization | 0.03 | |
| Maximal iterations | 2500 | |
| Adaboost | Base of estimator | Tree |
| Number of estimators | 50 | |
| Learning rate | 1 | |
| Classification algorithm | SAMME.R | |
| Regression loss function | Linear |
| Parameter | Proposed Values | Selected Values |
|---|---|---|
| Optimizer | [‘adam’, ‘SGD’] | SGD |
| Learning rate | [0.01, 0.025, 0.05, 0.1, 0.5] | 0.1 |
| Momentum | [0.01, 0.025, 0.05, 0.075, 0.1, 0.5] | 0.1 |
| Neurons | [5, 10, 20, 50, 100] | 50 |
| Density | [1, 2, 3, 4, 5] | 1 |
| Epochs | [5, 10, 25, 50, 100] | 25 |
| Metric | Dataset | DT | SVM | RF | ANN | NB | AdaBoost | CPApD 1 |
|---|---|---|---|---|---|---|---|---|
| AUC | PTE vs. Control | 59.1 | 63.1 | 70.1 | 54.8 | 71.8 | 77.2 | 66 |
| Pneumonia vs. Control | 61.1 | 77.55 | 78.5 | 78.2 | 83.7 | 71.9 | 75.2 | |
| PTE vs. Pneumonia | 69.0 | 83.2 | 71.8 | 81.5 | 85.8 * | 64.6 | 76.0 | |
| DPApC 2 | 63.1 | 74.6 | 73.5 | 71.5 | 80.4 | 71.2 | ||
| CA | PTE vs. Control | 61.4 | 71.6 | 71.6 | 61.4 | 61.4 | 78.4 | 67.6 |
| Pneumonia vs. Control | 65.0 | 83.0 * | 79.0 | 77.0 | 73.0 | 76.0 | 75.5 | |
| PTE vs. Pneumonia | 66.4 | 73.9 | 66.4 | 70.9 | 79.9 | 64.2 | 70.3 | |
| DPApC 2 | 64.3 | 76.2 | 72.3 | 69.8 | 71.4 | 72.9 | ||
| F1-score | PTE vs. Control | 62.5 | 66.8 | 67.7 | 61.4 | 62.8 | 78.9 | 66.7 |
| Pneumonia vs. Control | 65.6 | 81.4 * | 77.9 | 76.9 | 74.5 | 76.5 | 75.5 | |
| PTE vs. Pneumonia | 66.5 | 73.8 | 66.3 | 70.9 | 79.9 | 64.2 | 70.3 | |
| DPApC 2 | 64.9 | 74.0 | 70.6 | 69.7 | 72.4 | 73.2 |
| Metric | Dataset | DT | SVM | RF | ANN | NB | AdaBoost | CPApD 1 |
|---|---|---|---|---|---|---|---|---|
| AUC | PTE vs. Rest | 71.9 | 75.9 | 75.2 | 75.4 | 79.4 | 61.9 | 73.3 |
| Pneumonia vs. Rest | 76.1 | 81.8 | 77.9 | 79.5 | 86.5 * | 64.1 | 77.7 | |
| Control vs. Diseases | 69.5 | 69.8 | 74.3 | 67.6 | 74.3 | 71.1 | 71.1 | |
| DPApC 2 | 72.5 | 75.8 | 75.8 | 74.2 | 80.1 | 65.7 | ||
| CA | PTE vs. Rest | 71.4 | 69.6 | 72.0 | 69.6 | 69.6 | 64.6 | 69.5 |
| Pneumonia vs. Rest | 68.9 | 71.4 | 72.7 | 73.3 | 80.1 | 64.6 | 71.8 | |
| Control vs. Diseases | 82.6 | 82.6 | 85.1 | 80.1 | 65.8 | 86.3 * | 80.4 | |
| DPApC 2 | 74.3 | 74.5 | 76.6 | 74.3 | 71.8 | 71.8 | ||
| F1-score | PTE vs. Rest | 70.1 | 66.1 | 71.2 | 70.0 | 70.0 | 64.4 | 68.6 |
| Pneumonia vs. Rest | 68.5 | 71.3 | 72.5 | 73.3 | 80.2 | 64.5 | 71.7 | |
| Control vs. Diseases | 81.3 | 75.3 | 83.3 | 80.1 | 70.1 | 85.6 * | 79.3 | |
| DPApC 2 | 73.3 | 70.9 | 75.7 | 74.5 | 73.4 | 71.5 |
| Metric | Datasets | DT | SVM | RF | ANN | NB | AdaBoost | CPApD 1 |
|---|---|---|---|---|---|---|---|---|
| AUC | PTE vs. Control | 55.0 | 66.8 | 59.5 | 58.3 | 75.1 | 67.8 | 63.8 |
| Pneumonia vs. Control | 57.3 | 76.3 | 75.0 | 74.4 | 85.2 | 65.7 | 72.3 | |
| PTE vs. Pneumonia | 69.1 | 80.1 | 73.4 | 79.0 | 87.0 * | 68.8 | 76.2 | |
| DPApC 2 | 60.5 | 74.4 | 69.3 | 70.6 | 82.4 | 67.4 | ||
| CA | PTE vs. Control | 62.5 | 70.5 | 64.8 | 67.0 | 67.0 | 68.2 | 66.7 |
| Pneumonia vs. Control | 69.0 | 82.0 * | 80.0 | 75.0 | 75.0 | 67.0 | 74.7 | |
| PTE vs. Pneumonia | 60.4 | 74.6 | 65.7 | 72.4 | 76.9 | 69.4 | 69.9 | |
| DPApC 2 | 64.0 | 75.7 | 70.2 | 71.5 | 73.0 | 68.2 | ||
| F1-score | PTE vs. Control | 58.4 | 66.8 | 62.5 | 66.5 | 68.3 | 69.2 | 65.3 |
| Pneumonia vs. Control | 69.5 | 80.5 | 78.4 | 75.1 | 76.3 | 68.6 | 74.7 | |
| PTE vs. Pneumonia | 60.5 | 74.5 | 65.7 | 72.4 | 76.9 | 69.3 | 69.9 | |
| DPApC 2 | 62.8 | 73.9 | 68.9 | 71.3 | 73.8 | 69.0 |
| Metric | Datasets | DT | SVM | RF | ANN | NB | AdaBoost | CPApD 1 |
|---|---|---|---|---|---|---|---|---|
| AUC | PTE vs. Rest | 74.0 | 74.8 | 76.0 | 75.2 | 79.7 | 67.8 | 74.6 |
| Pneumonia vs. Rest | 73.7 | 81.9 | 73.1 | 79.1 | 86.3 * | 66.3 | 76.7 | |
| Control vs. Diseases | 79.8 | 67.0 | 68.6 | 64.2 | 76.0 | 73.7 | 71.6 | |
| DPApC 2 | 75.8 | 74.6 | 72.6 | 72.8 | 80.7 | 69.3 | ||
| CA | PTE vs. Rest | 75.2 | 69.6 | 69.6 | 70.8 | 74.5 | 69.6 | 71.6 |
| Pneumonia vs. Rest | 73.3 | 72.7 | 65.8 | 69.6 | 80.1 | 66.5 | 71.3 | |
| Control vs. Diseases | 88.2 | 83.2 | 83.9 | 77.0 | 68.3 | 85.7 | 81.1 | |
| DPApC 2 | 78.9 | 75.2 | 73.1 | 72.5 | 74.3 | 73.9 | ||
| F1-score | PTE vs. Rest | 73.7 | 66.1 | 69.0 | 70.9 | 74.9 | 69.6 | 70.7 |
| Pneumonia vs. Rest | 72.5 | 72.6 | 65.7 | 69.6 | 80.2 | 66.5 | 71.2 | |
| Control vs. Diseases | 87.5 * | 75.6 | 81.4 | 77.8 | 72.2 | 85.6 | 80.0 | |
| DPApC 2 | 77.9 | 71.4 | 72.0 | 72.8 | 75.8 | 73.9 |
| Dataset | Average F1-Score | F1-Score | Spec | CA | Pr | Sens |
|---|---|---|---|---|---|---|
| PTE vs. Control | 0.603 | 0.609 | 1.000 | 0.611 | 0.708 | 0.730 |
| Pneumonia vs. Control | 0.736 | 0.733 | 0.600 | 0.800 | 0.733 | 0.733 |
| PTE vs. Pneumonia | 0.766 | 0.777 | 0.916 | 0.777 | 0.798 | 0.791 |
| PTE vs. Rest | 0.657 | 0.727 | 0.538 | 0.757 | 0.763 | 0.719 |
| Pneumonia vs. Rest | 0.636 | 0.619 | 0.571 | 0.625 | 0.619 | 0.619 |
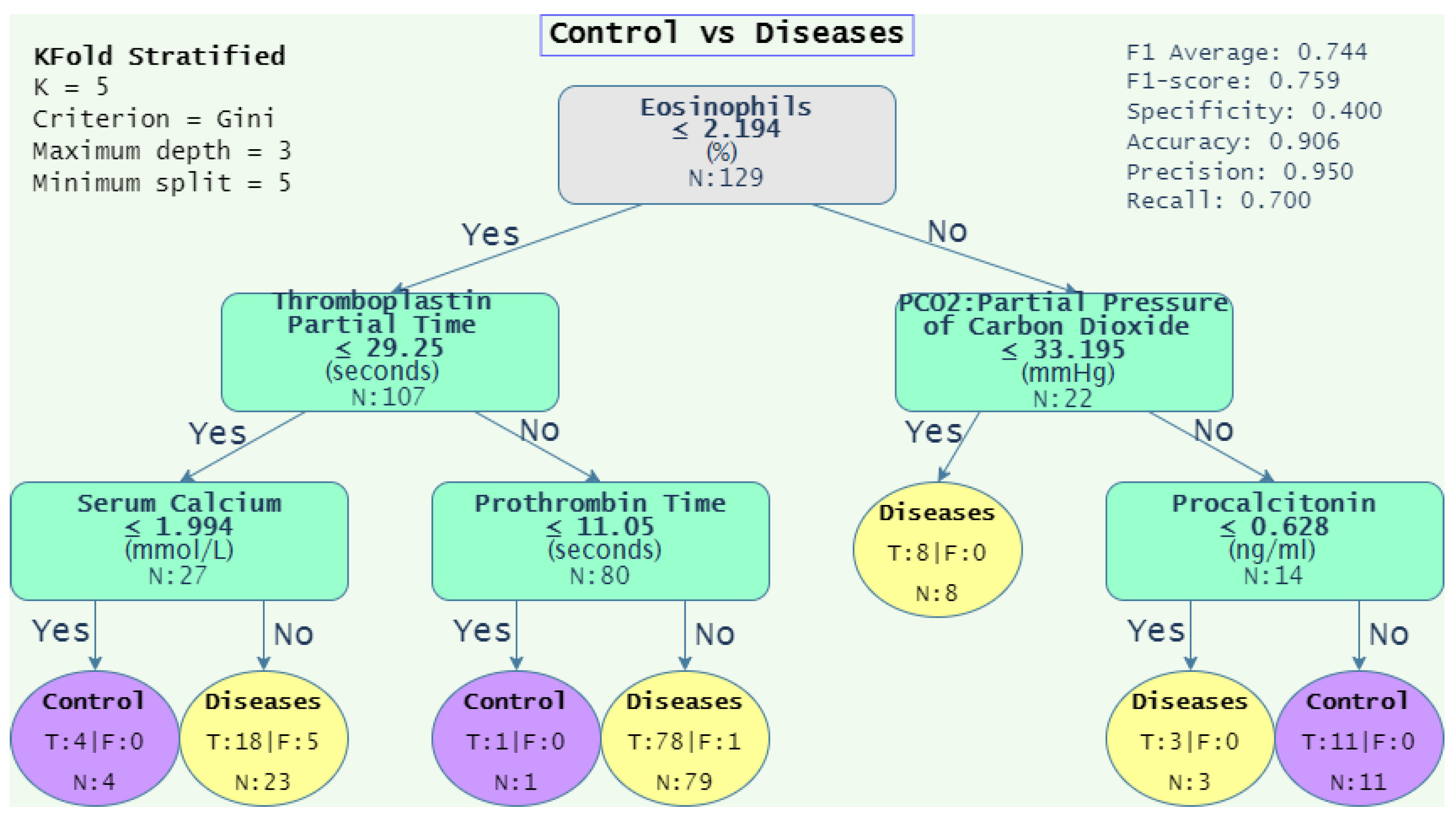
| Control vs. Diseases | 0.744 | 0.759 | 0.400 | 0.906 | 0.950 | 0.700 |
| Group | Accuracy | Precision | Recall | F1-Score | AUC |
|---|---|---|---|---|---|
| Control vs. Diseases | 61.3 | 77.1 | 71.6 | 72.7 | 50.3 |
| PTE vs. Rest | 51.3 | 60.4 | 63.2 | 60.5 | 46.3 |
| Pneumonia vs. Rest | 48.6 | 56.3 | 60.5 | 57.0 | 46.6 |
| Control vs. PTE | 52.9 | 64.0 | 57.0 | 58.5 | 52.1 |
| Control vs. Pneumonia | 54.3 | 65.7 | 65.3 | 63.6 | 48.4 |
| PTE vs. Pneumonia | 51.7 | 56.7 | 56.7 | 55.9 | 47.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Siordia-Millán, S.; Torres-Ramos, S.; Salido-Ruiz, R.A.; Hernández-Gordillo, D.; Pérez-Gutiérrez, T.; Román-Godínez, I. Pneumonia and Pulmonary Thromboembolism Classification Using Electronic Health Records. Diagnostics 2022, 12, 2536. https://doi.org/10.3390/diagnostics12102536
Siordia-Millán S, Torres-Ramos S, Salido-Ruiz RA, Hernández-Gordillo D, Pérez-Gutiérrez T, Román-Godínez I. Pneumonia and Pulmonary Thromboembolism Classification Using Electronic Health Records. Diagnostics. 2022; 12(10):2536. https://doi.org/10.3390/diagnostics12102536
Chicago/Turabian StyleSiordia-Millán, Sinhue, Sulema Torres-Ramos, Ricardo A. Salido-Ruiz, Daniel Hernández-Gordillo, Tracy Pérez-Gutiérrez, and Israel Román-Godínez. 2022. "Pneumonia and Pulmonary Thromboembolism Classification Using Electronic Health Records" Diagnostics 12, no. 10: 2536. https://doi.org/10.3390/diagnostics12102536
APA StyleSiordia-Millán, S., Torres-Ramos, S., Salido-Ruiz, R. A., Hernández-Gordillo, D., Pérez-Gutiérrez, T., & Román-Godínez, I. (2022). Pneumonia and Pulmonary Thromboembolism Classification Using Electronic Health Records. Diagnostics, 12(10), 2536. https://doi.org/10.3390/diagnostics12102536