
Optimized Intelligent Classifier for Early Breast Cancer Detection Using Ultra-Wide Band Transceiver

 , ,
, ,  ,
,  , ,
, ,  ,
,
Abstract
:1. Introduction
2. Related Works
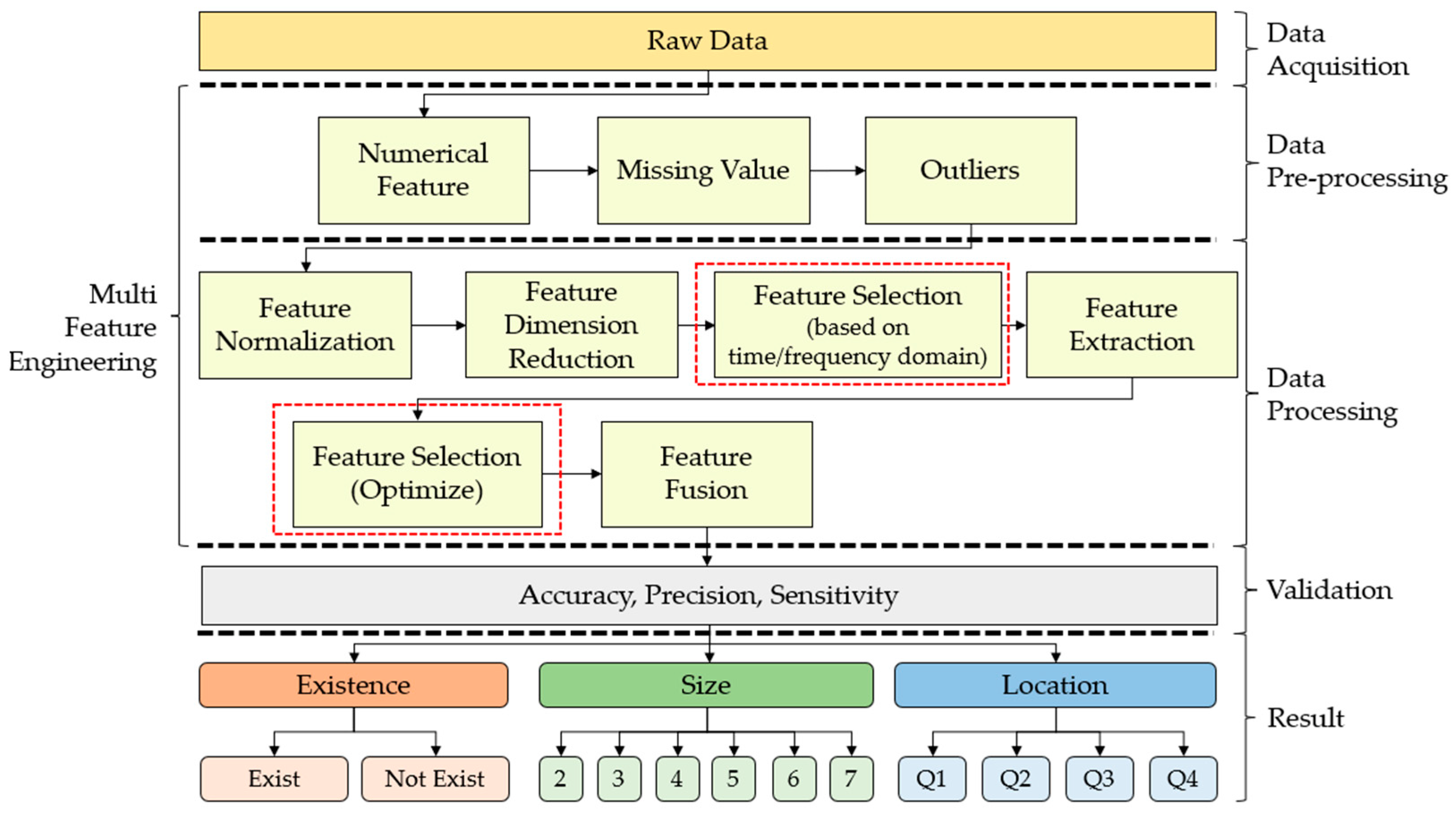
3. Materials and Methods
3.1. Breast Phantom and Tumor Development
3.2. Experimental Setup
- The 2 mm tumor is implanted in a heterogenous breast phantom;
- The single transmitting antenna (Tx) transmits UWB signals, and the opposite single receiving antenna (Rx) captures forward scattered UWB signals. Fifty repetitions are taken for each cycle;
- The tumor is placed in 65 different locations within the breast phantom. Each tumor (of the same size) is placed at different locations using the combination location of x coordinates (1 cm, 2 cm, 3.35 cm, 4 cm, 5 cm, 6 cm), y coordinates (1 cm, 2 cm, 3.35 cm, 4 cm, 5 cm, 6 cm), and z coordinates (4 cm, 5 cm, 6 cm, 7 cm, 8 cm);
- Steps 1 to 3 are repeated until all the locations in the breast phantom are covered. The tumor size is then changed to other sizes (3 mm, 4 mm, 5 mm, 6 mm, and 7 mm);
- For no-tumor data, the breast phantom will rotate 360 degrees (with 60 different angles). Three hundred twenty-five repetitions are taken for each cycle.
3.3. Multi-Stage Feature Selection
3.3.1. Feature Normalization
3.3.2. Feature Dimension Reduction
3.3.3. Feature Selection (Based on Time/Frequency Domain))
3.3.4. Feature Extraction
3.3.5. Feature Selection (Optimization)
| Algorithm 1: Pseudocode BPSO in Feature Selection. |
| Input: n—number of particles (swarm size); |
| T—number of iteration; |
| nVar—number of variables; |
| Objective function; |
| Output: Relevant features |
| 1. Start |
| 2. Initialize parameters of BPSO |
| 3. Initialize the swarm |
| 4. Repeat |
| 5. For each particle Do |
| 6. Evaluate particle’s fitness; (xbest) |
| 7. Update particle’s neighborhood best position; (gbest) |
| 8. End |
| 9. For each particle Do |
| 10. Update the particle’s velocity; |
| 11. Update the particle’s position; |
| 12. End |
| 13. Until the stopping condition is true; |
| 14. End |
3.3.6. Feature Fusion
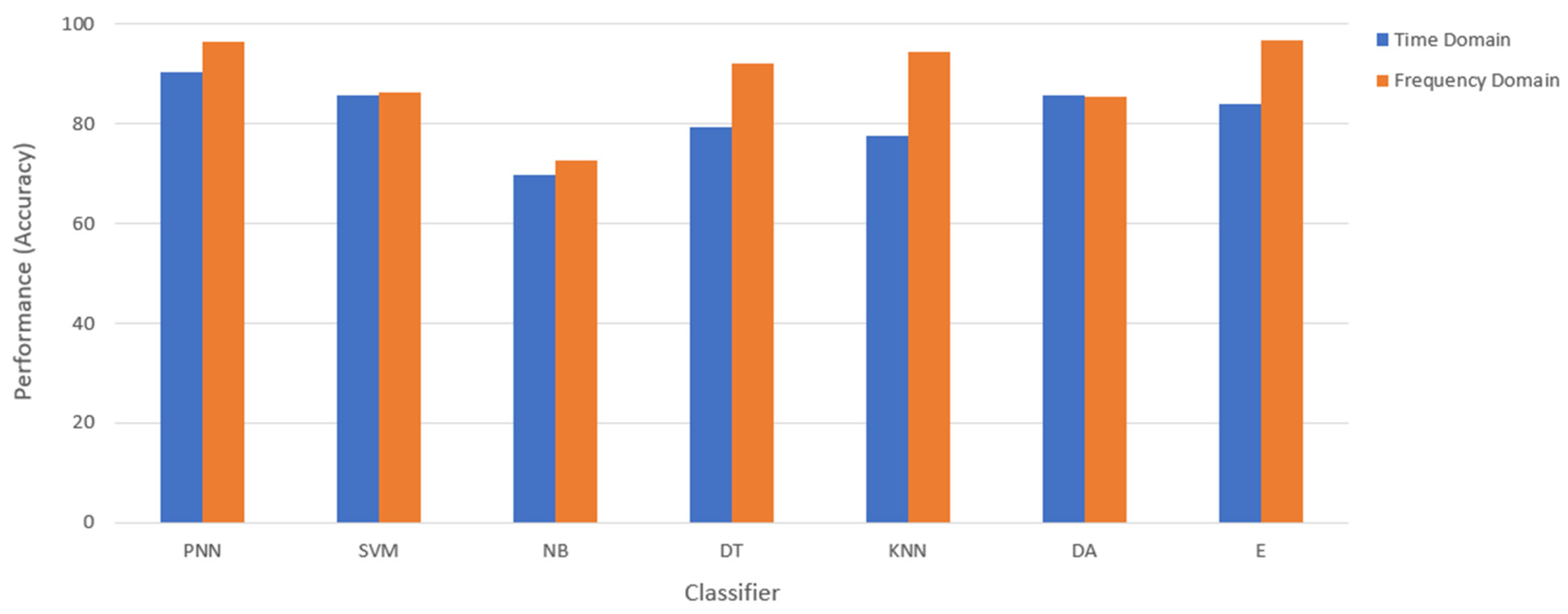
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shravya, C.; Pravalika, K.; Subhani, S. Prediction of Breast Cancer Using Supervised Machine Learning Techniques. Int. J. Innov. Technol. Explor. Eng. 2019, 8, 1106–1110. [Google Scholar]
- Iranmakani, S.; Mortezazadeh, T.; Sajadian, F.; Ghaziani, M.F.; Ghafari, A.; Khezerloo, D.; Musa, A.E. A review of various modalities in breast imaging: Technical aspects and clinical outcomes. Egypt. J. Radiol. Nucl. Med. 2020, 51, 57. [Google Scholar] [CrossRef] [Green Version]
- Bonsu, A.B.; Ncama, B.P. Integration of breast cancer prevention and early detection into cancer palliative care model. PLoS ONE 2019, 14, e0212806. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Amdaouch, I.; Saban, M.; El Gueri, J.; Chaari, M.Z.; Alejos, A.V.; Alzola, J.R.; Muñoz, A.R.; Aghzout, O. A Novel Approach of a Low-Cost UWB Microwave Imaging System with High Resolution Based on SAR and a New Fast Reconstruction Algorithm for Early-Stage Breast Cancer Detection. J. Imaging 2022, 8, 264. [Google Scholar] [CrossRef] [PubMed]
- Vaka, A.R.; Soni, B.; Reddy, K.S. Breast cancer detection by leveraging machine learning. Korean Inst. Commun. Inf. Sci. 2020, 6, 320–324. [Google Scholar] [CrossRef]
- Sadoughi, F.; Kazemy, Z.; Hamedan, F.; Owji, L.; Rahmanikatigari, M.; Azadboni, T.T. Artificial intelligence methods for the diagnosis of breast cancer by image processing: A review. Breast Cancer-Targets Ther. 2018, 10, 219–230. [Google Scholar] [CrossRef] [Green Version]
- Khan, F.; Khan, M.A.; Abbas, S.; Athar, A.; Siddiqui, S.Y.; Khan, A.H.; Saeed, M.A.; Hussain, M. Cloud-Based Breast Cancer Prediction Empowered with Soft Computing Approaches. J. Healthc. Eng. 2020, 2020, 8017496. [Google Scholar] [CrossRef]
- Khosravanian, A.; Ayat, S. Diagnosing Breast Cancer Type by Using Probabilistic Neural Network in Decision Support System. Int. J. Knowl. Eng. 2016, 2, 73–76. [Google Scholar] [CrossRef] [Green Version]
- Fedeli, A.; Maffongelli, M.; Monleone, R.; Pagnamenta, C.; Pastorino, M.; Poretti, S.; Randazzo, A.; Salvadè, A. A tomograph prototype for quantitative microwave imaging: Preliminary experimental results. J. Imaging 2018, 4, 139. [Google Scholar] [CrossRef] [Green Version]
- Aldhaeebi, M.A.; Alzoubi, K.; Almoneef, T.S.; Bamatra, S.M.; Attia, H.; Ramahi, O.M. Review of microwaves techniques for breast cancer detection. Sensors 2020, 20, 2390. [Google Scholar] [CrossRef] [Green Version]
- Alsawaftah, N.; El-Abed, S.; Dhou, S.; Zakaria, A. Microwave Imaging for Early Breast Cancer Detection: Current State, Challenges, and Future Directions. J. Imaging 2022, 8, 123. [Google Scholar] [CrossRef]
- Alani, S.; Zakaria, Z.; Saeidi, T.; Ahmad, A.; Imran, M.A.; Abbasi, Q.H. Microwave imaging of breast skin utilizing elliptical uwb antenna and reverse problems algorithm. Micromachines 2021, 12, 647. [Google Scholar] [CrossRef]
- Wörtge, D.; Moll, J.; Krozer, V.; Bazrafshan, B.; Hübner, F.; Park, C.; Vogl, T.J. Comparison of X-ray-Mammography and Planar UWB Microwave Imaging of the Breast: First Results from a Patient Study. Diagnostics 2018, 8, 54. [Google Scholar] [CrossRef] [Green Version]
- Mahmood, S.N.; Ishak, A.J.; Saeidi, T.; Soh, A.C.; Jalal, A.; Imran, M.A.; Abbasi, Q.H. Full ground ultra-wideband wearable textile antenna for breast cancer and wireless body area network applications. Micromachines 2021, 12, 322. [Google Scholar] [CrossRef]
- Song, H.; Li, Y.; Coates, M.; Men, A. Microwave breast cancer detection using empirical mode decomposition features. arXiv 2017, arXiv:1702.07608. [Google Scholar]
- AlShehri, S.A.; Khatun, S. UWB Imaging for Breast Cancer Detection using Neural Network. Prog. Electromagn. Res. C 2009, 7, 79–93. [Google Scholar] [CrossRef] [Green Version]
- Lavoie, B.R.; Okoniewski, M.; Fear, E.C. Estimating the effective permittivity for reconstructing accurate microwave-Radar images. PLoS ONE 2016, 11, e0160849. [Google Scholar] [CrossRef] [Green Version]
- Abdul Halim, A.A.; Andrew, A.M.; Mohd Yasin, M.N.; Abd Rahman, M.A.; Jusoh, M.; Veeraperumal, V.; Rahim, H.A.; Illahi, U.; Abdul Karim, M.K.; Scavino, E. Existing and Emerging Breast Cancer Detection Technologies and Its Challenges: A Review. Appl. Sci. 2021, 11, 10753. [Google Scholar] [CrossRef]
- Islam, M.T.; Mahmud, M.Z.; Islam, M.T.; Kibria, S.; Samsuzzaman, M. A Low Cost and Portable Microwave Imaging System for Breast Tumor Detection Using UWB Directional Antenna array. Nat. Res. 2019, 9, 15491. [Google Scholar] [CrossRef] [Green Version]
- Reza, K.J.; Mostafa, S.S.; Milon, M.H.; Khatun, S.; Jamlos, M.F. Scattering Behaviour Analysis for UWB Antenna in the Vicinity of Heterogeneous Breast Model. In Proceedings of the 2018 International Conference on Biomedical Engineering and Applications (ICBEA), Funchal, Portugal, 9–12 July 2018. [Google Scholar] [CrossRef]
- Reza, K.J.; Khatun, S.; Jamlos, M.F.; Fakir, M.M.; Morshed, M.N. Performance Enhancement of Ultra-Wideband Breast Cancer Imaging System: Proficient Feature Extraction and Biomedical Antenna Approach. J. Med. Imaging Health Inform. 2015, 5, 1246–1250. [Google Scholar] [CrossRef]
- Hassan, N.A.; Yassin, A.H.; Tayel, M.B.; Mohamed, M.M. Ultra-wideband Scaterred Microwave Signals for Detection of Breast Tumors Using Artificial Neural Networks. IEEE J. Electromagn. RF Microw. Med. Biol. 2016, 137–142. [Google Scholar]
- Conceição, R.C.; Medeiros, H.; Godinho, D.M.; Ohalloran, M.; Rodriguez-Herrera, D.; Flores-Tapia, D.; Pistorius, S. Classification of breast tumor models with a prototype microwave imaging system. Med. Phys. 2020, 47, 1860–1870. [Google Scholar] [CrossRef] [PubMed]
- Bari, B.S.; Khatun, S.; Ghazali, K.H.; Fakir, M.; Samsudin, W.N.A.W.; Jusof, M.F.M.; Rashid, M.; Islam, M.; Ibrahim, M.Z. Ultra Wide Band (UWB) Based Early Breast Cancer Detection Using Artificial Intelligence. Lect. Notes Electr. Eng. 2020, 632, 505–515. [Google Scholar] [CrossRef]
- Vijayasarveswari, V.; Andrew, A.M.; Jusoh, M.; Sabapathy, T.; Raof, R.A.A.; Yasin, M.N.M. Multi- Stage Feature Selection (MSFS) Algorithm for UWB- Based Early Breast Cancer Size Prediction. PLoS ONE 2020, 15, e0229367. [Google Scholar] [CrossRef]
- Lu, M.; Xiao, X.; Pang, Y.; Liu, G.; Lu, H. Detection and Localization of Breast Cancer Using UWB Microwave Technology and CNN-LSTM Framework. IEEE Trans. Microw. Theory Tech. 2022, 70, 5085–5094. [Google Scholar] [CrossRef]
- Liu, G.; Xiao, X.; Song, H.; Kikkawa, T. Precise Detection of Early Breast Tumor Using a Novel EEMD-Based Feature Extraction Approach by UWB Microwave. Med. Biol. Eng. Comput. 2021, 59, 721–731. [Google Scholar] [CrossRef]
- Alsheri, S.A.; Khatun, S.; Jantan, A.B.; Abdullah, R.S.A.; Mahmood, R.; Awang, Z. Experimental Breast Tumor Detection Using NN-Based UWB Imaging. Prog. Electromagn. Res. 2011, 111, 447–465. [Google Scholar] [CrossRef] [Green Version]
- Shirazi, A.Z.; Javad, S.; Mahdavi, S.; Mohammadi, Z. A Novel and Reliable Computational Intelligence System for Breast Cancer Detection. Int. Fed. Med. Biol. Eng. 2017, 1–12. [Google Scholar] [CrossRef]
- Huang, M.; Chen, C.; Lin, W.; Ke, S.; Tsai, C. SVM and SVM Ensembles in Breast Cancer Prediction. PLoS ONE 2017, 12, e0161501. [Google Scholar] [CrossRef]
- Chtihrakkannan, R.; Kavitha, P.; Mangayarkarasi, T.; Karthikeyan, R. Breast Cancer Detection Using Machine Learning. Int. J. Innov. Technol. Explor. Eng. 2019, 8, 3123–3126. [Google Scholar] [CrossRef]
- Santorelli, A.; Porter, E.; Kirshin, E.; Liu, Y.J.; Popović, M. Investigation of classifiers for tumor detection with an experimental time-domain breast screening system. Prog. Electromagn. Res. 2014, 144, 45–57. [Google Scholar] [CrossRef] [Green Version]
- Reza, K.J.; Khatun, S.; Jamlos, M.F.; Abdul, Z.I. Proficient Feature Extraction Strategy for Performance Enhancement of NN Based Early Breast Tumor Detection. Int. J. Eng. Technol. 2014, 5, 4689–4696. [Google Scholar]
- Chaurasia, V.; Pal, S.; Tiwari, B.B. Prediction of Benign and Malignant Breast Cancer Using Data Mining Techniques. J. Algorithm Comput. Technol. 2018, 12, 119–126. [Google Scholar] [CrossRef]
- Islam, M.M.; Haque, M.R.; Iqbal, H.; Hasan, M.M.; Hasan, M.; Kabir, M.N. Breast Cancer Prediction: A Comparative Study Using Machine Learning Techniques. SN Comput. Sci. 2020, 1, 290. [Google Scholar] [CrossRef]
- Karthikeyan, B.; Gollamudi, S.; Singamsetty, H.V.; Gade, P.K.; Mekala, S.Y. Breast Cancer Detection Using Machine Learning. Int. J. Adv. Trends Comput. Sci. Eng. 2020, 9, 981–984. [Google Scholar] [CrossRef]
- Vijayasarveswari, V.; Aliana, R.; Khatun, S.; Ahmad, Z.; Osman, M.N. Performance Verification on UWB Antennas for Breast Cancer Detection. MATEC Web Conf. 2017, 140, 01004. [Google Scholar] [CrossRef] [Green Version]
- Mahmud, M.Z.; Islam, M.T.; Misran, N.; Almutairi, A.F.; Cho, M. Ultra-wideband (UWB) antenna sensor based microwave breast imaging: A review. Sensors 2018, 18, 2951. [Google Scholar] [CrossRef] [Green Version]
- Bari, B.S.; Khatun, S.; Ghazali, K.H.; Fakir, M.; Ariff, M.H.M.; Jamlos, M.F.; Rashid, M.; Islam, M.; Ibrahim, M.Z.; Jusof, M.F.M. Bandwidth and Gain Enhancement of a Modified Ultra-wideband (UWB) Micro-strip Patch Antenna Using a Reflecting Layer. Lect. Notes Electr. Eng. 2020, 632, 463–473. [Google Scholar] [CrossRef]
- Lim, S.; Yoon, Y.J. Wideband-narrowband switchable tapered slot antenna for breast cancer diagnosis and treatment. Appl. Sci. 2021, 11, 3606. [Google Scholar] [CrossRef]
- Jambak, M.I.; Jambak, A.I.I. Comparison of dimensional reduction using the Singular Value Decomposition Algorithm and the Self Organizing Map Algorithm in clustering result of text documents. IOP Conf. Ser. Mater. Sci. Eng. 2019, 551, 012046. [Google Scholar] [CrossRef]
- Caltenco, J.H.; López, J.; Gámez, B.E.C. Singular Value Decomposition. Bull. Soc. Math. Serv. Stand. 2014, 11, 13–20. [Google Scholar] [CrossRef]
- Andrew, A.M.; Zakaria, A.; Saad, S.M.; Shakaff, A.Y.M. Multi-stage feature selection based intelligent classifier for classification of incipient stage fire in building. Sensors 2016, 16, 31. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vijayasarveswari, V.; Jusoh, M.; Khatun, S.; Fakir, M.M. Scattering performance verification based on UWB imaging and neural network. In Proceedings of the 2017 IEEE 13th International Colloquium on Signal Processing & its Applications (CSPA), Penang, Malaysia, 10–12 March 2017; pp. 238–242. [Google Scholar] [CrossRef]
- Sameer, F.O.; Bakar, M.R.A.; Zaidan, A.A.; Zaidan, B.B. A new algorithm of modified binary particle swarm optimization based on the Gustafson-Kessel for credit risk assessment. Neural Comput. Appl. 2019, 31, 337–346. [Google Scholar] [CrossRef]
- Reddy, M.J.; Kumar, D.N. Evolutionary algorithms, swarm intelligence methods, and their applications in water resources engineering: A state-of-the-art review. H2Open J. 2020, 3, 135–188. [Google Scholar] [CrossRef]
- Kumar, L.; Bharti, K.K. An improved BPSO algorithm for feature selection. Lect. Notes Electr. Eng. 2019, 524, 505–513. [Google Scholar] [CrossRef]
- Sazzed, S. ANOVA-SRC-BPSO: A hybrid filter and swarm optimization-based method for gene selection and cancer classification using gene expression profiles. In Proceedings of the 34th Canadian Conference on Artificial Intelligence, Vancouver, BC, Canada, 25–28 May 2021; pp. 1–12. [Google Scholar] [CrossRef]
- Vijayalakshmi, S.; John, A.; Sunder, R.; Mohan, S.; Bhattacharya, S.; Kaluri, R.; Feng, G.; Tariq, U. Multi-modal prediction of breast cancer using particle swarm optimization with non-dominating sorting. Int. J. Distrib. Sens. Netw. 2020, 16. [Google Scholar] [CrossRef]
- Bose, S.; Jha, V.K.; Hossain, S.T. An Artificial Neural Network based approach along with Recursive Elimination Feature Selection Combined Model to detect Breast Cancer. Int. J. Adv. Res. Comput. Commun. Eng. 2022, 11, 184–195. [Google Scholar] [CrossRef]
- Wardhani, N.W.S.; Rochayani, M.Y.; Iriany, A.; Sulistyono, A.D.; Lestantyo, P. Cross-validation Metrics for Evaluating Classification Performance on Imbalanced Data. In Proceedings of the 2019 International Conference on Computer, Control, Informatics and its Applications (IC3INA), Tangerang, Indonesia, 23–24 October 2019; pp. 14–18. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Dataset | Classification Technique | Limitation |
|---|---|---|---|
| Lu et al., 2022 [26] | Breast phantom (6400 data sample) | A Convolutional Neural Network Long Short-Term (CNN-LSTM) network | Detection and quadrant localization only |
| Liu et al., 2021 [27] | Breast phantom (11,232 data sample) | SVM | Detection and localization |
| Vijayasarveswari et. al., 2020 [25] | Breast phantom (6750 data sample) | MSFS | Focus on size detection only |
| Bari et. al., 2020 [24] | Breast phantom (448 data sample) | FFBPNN | Limited data sample |
| Nouralhuda et. al., 2016 [22] | Breast phantom (118 data sample) | FFBPNN | Single feature extraction |
| Reeza et. al., 2015 [21] | Breast phantom (1632 data points) | Feature extraction and ANN | Only detect for existence and size Single feature technique |
| Alsheri et al., 2011 [28] | Breast phantom (6400 data points) | Feature extraction and ANN | Single feature technique |
| Breast Phantom | Material | Permittivity | Conductivity |
|---|---|---|---|
| Fatty tissues | Pure petroleum jelly | 2.36 | 0.012 |
| Glandular | Soy oil | 2.7 | 0.061 |
| Tumor | Mixture of water and wheat flour | 6.98 | 0.785 |
| Skin | Glass | 3.5–10 | Negligible |
| No. | Data Sample | Accuracy (%) | Time |
|---|---|---|---|
| 1 | 1632 → 8 | 72.13 | <10 s |
| 2 | 1632 → 16 | 86.35 | <12 s |
| 3 | 1632 → 24 | 85.23 | <12 s |
| 4 | 1632 → 32 | 84.11 | <14 s |
| 5 | 1632 → 48 | 83.59 | <15 s |
| 6 | 1632 → 51 | 83.94 | <15 s |
| 7 | 1632 → 68 | 85.59 | <16 s |
| 8 | 1632 → 96 | 85.11 | <18 s |
| 9 | (Raw → Data BN → SVM) | 64.62 | 9 min 20 s |
| 10 | (Raw Data → SVM) | 35.45 | 28 min 30 s |
| Parameters | Value for Existence | Value for Size | Value for Location |
|---|---|---|---|
| No. of input neurons | - | - | - |
| No. of output neurons | - | - | - |
| Spread factor | 0.9 | 0.5 | 0.001 |
| Testing tolerance | 0.001 | 0.001 | 0.001 |
| No. of training samples | 13,650 | 11,700 | 11,700 |
| No. of the validation sample | 3900 | 1950 | 1950 |
| No. of testing samples | 6825 | 5850 | 5850 |
| Total number of samples | 39,000 | 19,500 | 19,500 |
| No. | Features | F-Value |
|---|---|---|
| 1 | MinLS | 33,554.17903 |
| 2 | MinDS | 33,554.17697 |
| 3 | MinBN | 31,176.84962 |
| 4 | MaxMM | 31,162.38708 |
| 5 | MZS | 18,605.08924 |
| 6 | MaxZS | 3889.195375 |
| 7 | SDZS | 3761.295512 |
| 8 | MinZS | 3301.983306 |
| 9 | SZS | 3180.094827 |
| 10 | SMM | 2585.315293 |
| 11 | SBN | 2445.623486 |
| 12 | SDS | 2168.639286 |
| 13 | SLS | 2168.639286 |
| 14 | MMM | 254.8622211 |
| 15 | MDS | 218.7147998 |
| 16 | MLS | 218.7147998 |
| 17 | VZS | 209.6064994 |
| 18 | MBN | 207.9607835 |
| 19 | SDMM | 33.87221416 |
| 20 | VMM | 26.23552913 |
| 21 | SDBN | 24.28454284 |
| 22 | SDDS | 23.59648288 |
| 23 | SDLS | 23.59648288 |
| 24 | MinMM | 17.13184682 |
| 25 | MaxBN | 12.48034536 |
| 26 | VBN | 12.10396575 |
| 27 | VLS | 11.44263249 |
| 28 | VDS | 11.44263248 |
| 29 | MaxLS | 8.799857161 |
| 30 | MaxDS | 8.799857155 |
| Parameter | Performance Evaluation | PNN | SVM | KNN |
|---|---|---|---|---|
| Existence | Accuracy (%) | 98.25 | 97.48 | 97.50 |
| Sensitivity (%) | 98.85 | 97.86 | 97.75 | |
| Specificity (%) | 96.23 | 95.48 | 95.22 | |
| Precision | 0.985 | 0.995 | 0.976 | |
| Recall | 0.99 | 0.98 | 0.985 | |
| F1-measure | 0.987 | 0.988 | 0.98 | |
| G-mean | 0.987 | 0.988 | 0.98 | |
| Size | Accuracy (%) | 96.85 | 94.61 | 95.21 |
| Sensitivity (%) | 95.35 | 94.48 | 96.62 | |
| Specificity (%) | 93.56 | 93.42 | 92.35 | |
| Precision | 0.975 | 0.966 | 0.984 | |
| Recall | 0.970 | 0.971 | 0.968 | |
| F1-measure | 0.973 | 0.969 | 0.976 | |
| G-mean | 0.973 | 0.969 | 0.96 | |
| Location | Accuracy (%) | 93.81 | 92.23 | 91.49 |
| Sensitivity (%) | 93.85 | 92.86 | 92.75 | |
| Specificity (%) | 92.87 | 91.71 | 90.82 | |
| Precision | 0.971 | 0.952 | 0.938 | |
| Recall | 0.926 | 0.966 | 0.961 | |
| F1-measure | 0.948 | 0.959 | 0.949 | |
| G-mean | 0.948 | 0.959 | 0.949 |
| Researcher | Data Sample | Method | Parameter | Test and Trains Sets | Accuracy |
|---|---|---|---|---|---|
| Vijayasarveswari [25] | 6750 | Multi-stage Feature Selection with Naïve Bayes classifier | Size | K-Fold Cross Validation | 91.98% |
| Conceicao [23] | 3744 | PCA (feature extraction) with kNN classifier | Size and shape | K-Fold Cross Validation | 96.2% |
| Bifta [24] | 448 | FFBPNN with feedforward net function | Existence, size, and location | 70% Training 15% Validation 15% Testing | 92.43% |
| Proposed work | 39,000 | Multi-stage Feature Selection (MSFS) with BPSO | Existence, size, and location | K-Fold Cross Validation | 96.3% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Halim, A.A.A.; Andrew, A.M.; Mustafa, W.A.; Mohd Yasin, M.N.; Jusoh, M.; Veeraperumal, V.; Abd Rahman, M.A.; Zamin, N.; Mary, M.R.; Khatun, S. Optimized Intelligent Classifier for Early Breast Cancer Detection Using Ultra-Wide Band Transceiver. Diagnostics 2022, 12, 2870. https://doi.org/10.3390/diagnostics12112870
Halim AAA, Andrew AM, Mustafa WA, Mohd Yasin MN, Jusoh M, Veeraperumal V, Abd Rahman MA, Zamin N, Mary MR, Khatun S. Optimized Intelligent Classifier for Early Breast Cancer Detection Using Ultra-Wide Band Transceiver. Diagnostics. 2022; 12(11):2870. https://doi.org/10.3390/diagnostics12112870
Chicago/Turabian StyleHalim, Ahmad Ashraf Abdul, Allan Melvin Andrew, Wan Azani Mustafa, Mohd Najib Mohd Yasin, Muzammil Jusoh, Vijayasarveswari Veeraperumal, Mohd Amiruddin Abd Rahman, Norshuhani Zamin, Mervin Retnadhas Mary, and Sabira Khatun. 2022. "Optimized Intelligent Classifier for Early Breast Cancer Detection Using Ultra-Wide Band Transceiver" Diagnostics 12, no. 11: 2870. https://doi.org/10.3390/diagnostics12112870
APA StyleHalim, A. A. A., Andrew, A. M., Mustafa, W. A., Mohd Yasin, M. N., Jusoh, M., Veeraperumal, V., Abd Rahman, M. A., Zamin, N., Mary, M. R., & Khatun, S. (2022). Optimized Intelligent Classifier for Early Breast Cancer Detection Using Ultra-Wide Band Transceiver. Diagnostics, 12(11), 2870. https://doi.org/10.3390/diagnostics12112870