
A Multi-Branch Convolutional Neural Network with Squeeze-and-Excitation Attention Blocks for EEG-Based Motor Imagery Signals Classification


Abstract
:1. Introduction
- Build an end-to-end multi-branch EEG MI classification model based on DL that can solve the subject-specific problem.
- Develop a lightweight multi-branch attention model that can accurately classify EEG MI signals with a small number of parameters.
- Create a robust general model with fixed hyperparameters.
- Using multiple datasets, test the usefulness and robustness of the proposed model against data fluctuations.
2. Related Works
3. Materials and Methods
3.1. EEG Data
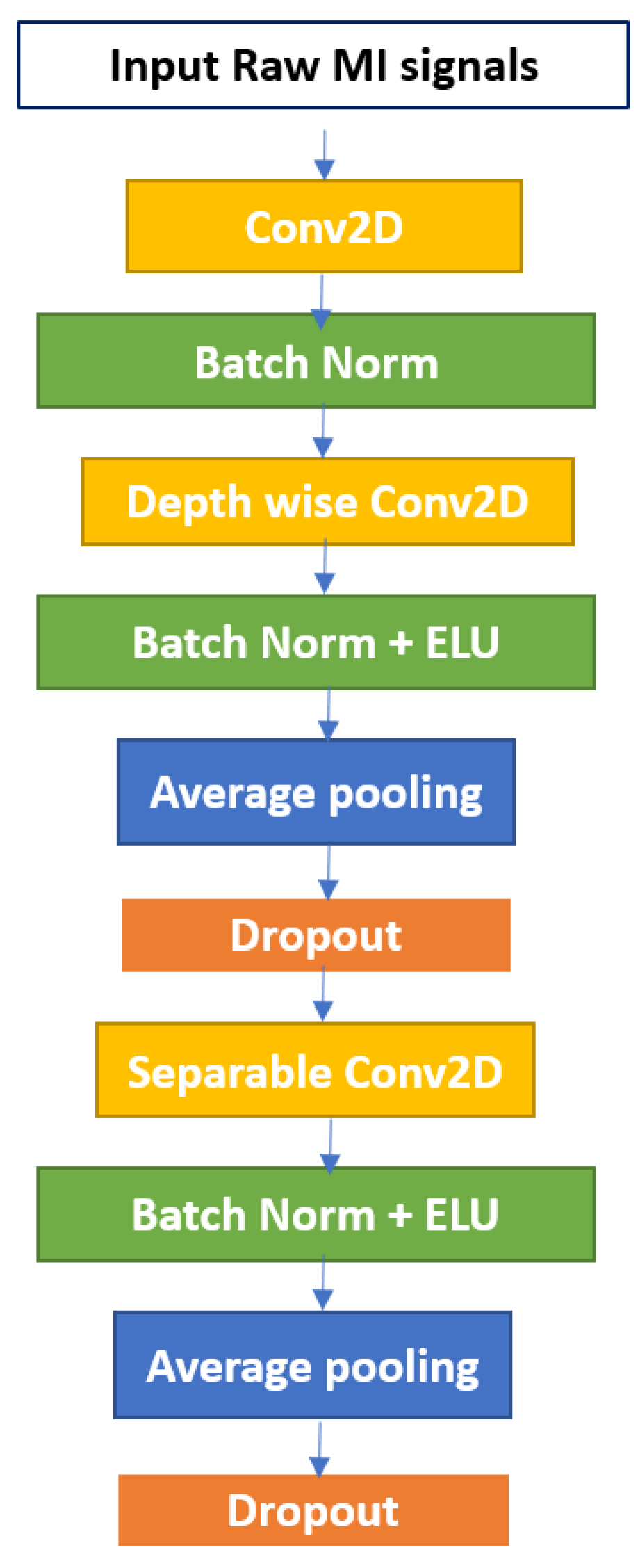
3.2. EEGNet Block
3.3. SE Attention Block
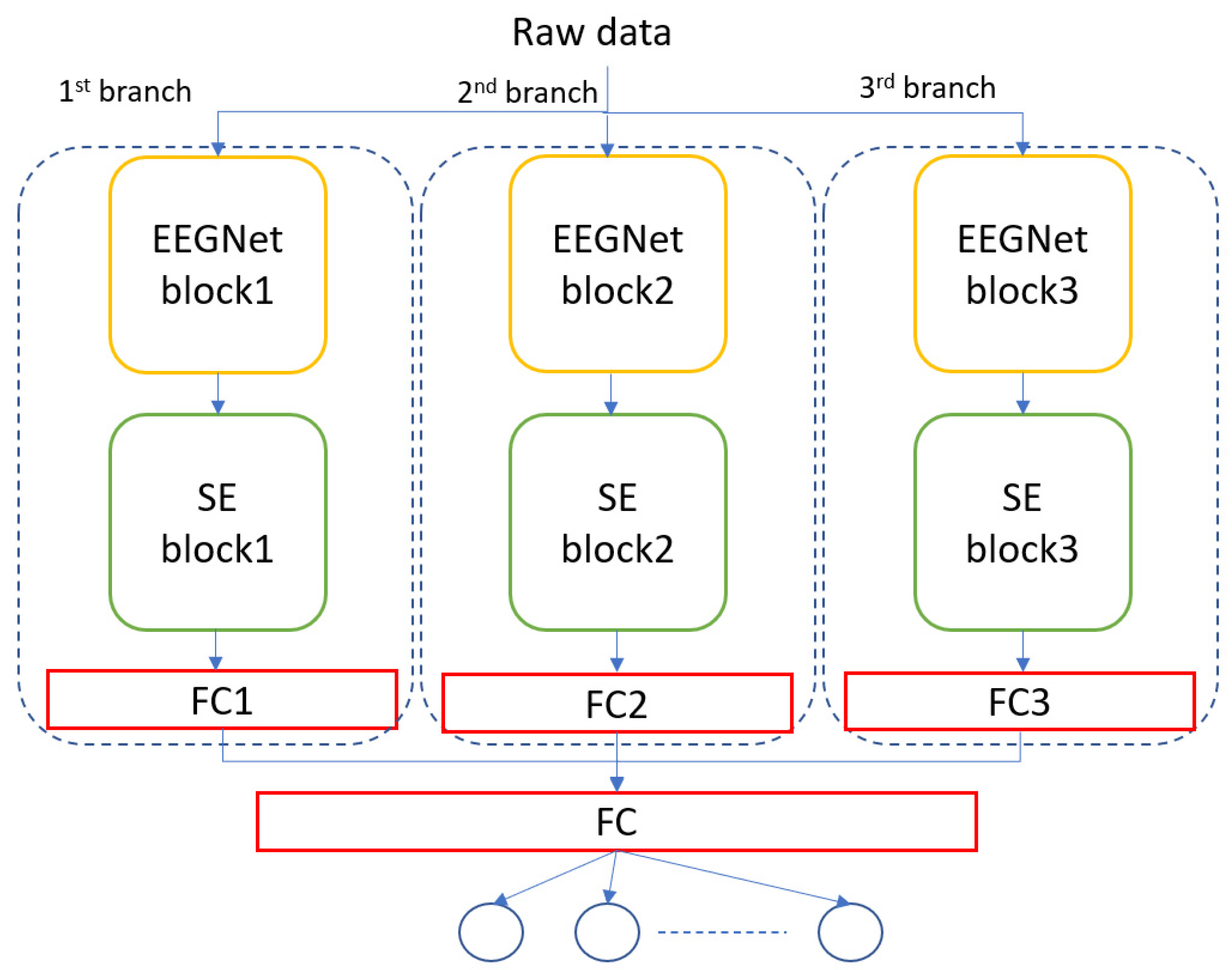
3.4. Proposed Models
4. Results and Discussion
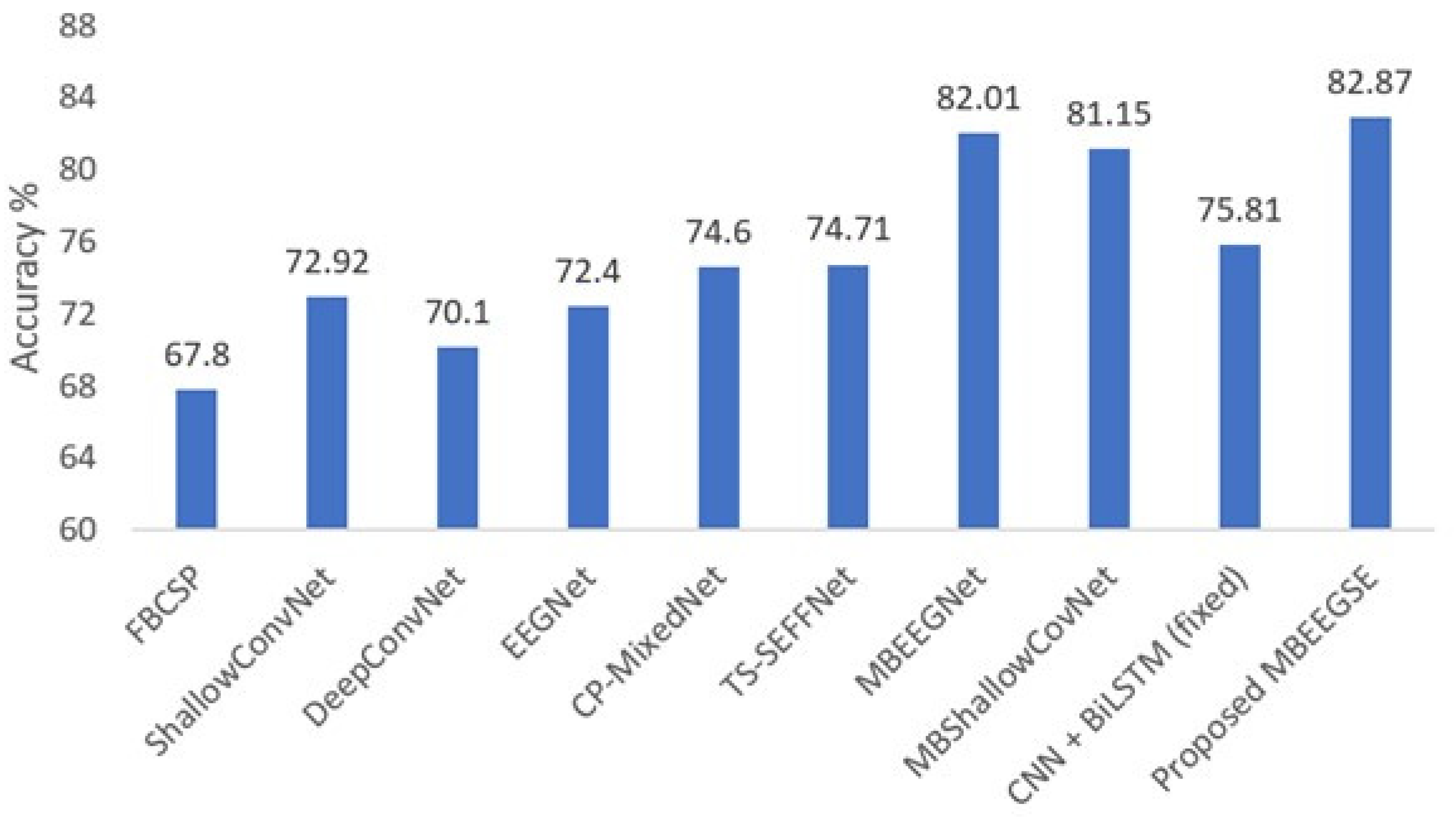
4.1. Overall Comparison
- FBCSP is a handcrafted model for classifying motor imagery EEG data that are often used as a baseline method [17]. It won several EEG decoding competitions, including the BCI competition IV in both datasets 2a and 2b. The CSP features are retrieved from different frequency bands in this model before being classified using the SVM [17].
- ShallowConvNet is a deep learning network that can categorize MI-EEG with only two convolution layers and a mean pooling layer [11].
- DeepConvNet is a deeper deep learning model than ShallowConvNet. It consists of four convolution and max-pooling layer blocks, followed by a softmax layer [11].
- EEGNet is a deep learning model that uses two-dimensional temporal convolution, depthwise convolution, and separable convolution to achieve a consistent approach to various BCI tasks [19].
- CP-MixedNet is a multi-scale model that extracts EEG features from many convolution layers, each of which captures EEG temporal information at different scales [27].
- TS-SEFFNet is a multi-block system that employs attention and fusion techniques. The spatio-temporal block, the deep-temporal convolution block, the multi-spectral convolution block, the squeeze-and-excitation feature fusion block, and the classification block are all part of a larger model [30].
- CNN + BiLSTM (fixed) is a hybrid deep learning model which contains an attention-based inception model and the LSTM model. It was tested and analyzed with fixed hyperparameter values, which were fixed for all subjects [15].
4.2. Results of BCI Competition IV-2a Dataset
4.3. Results of HGD
5. Conclusions
- The self-attention mechanism increases the accuracy of EEG-MI classification.
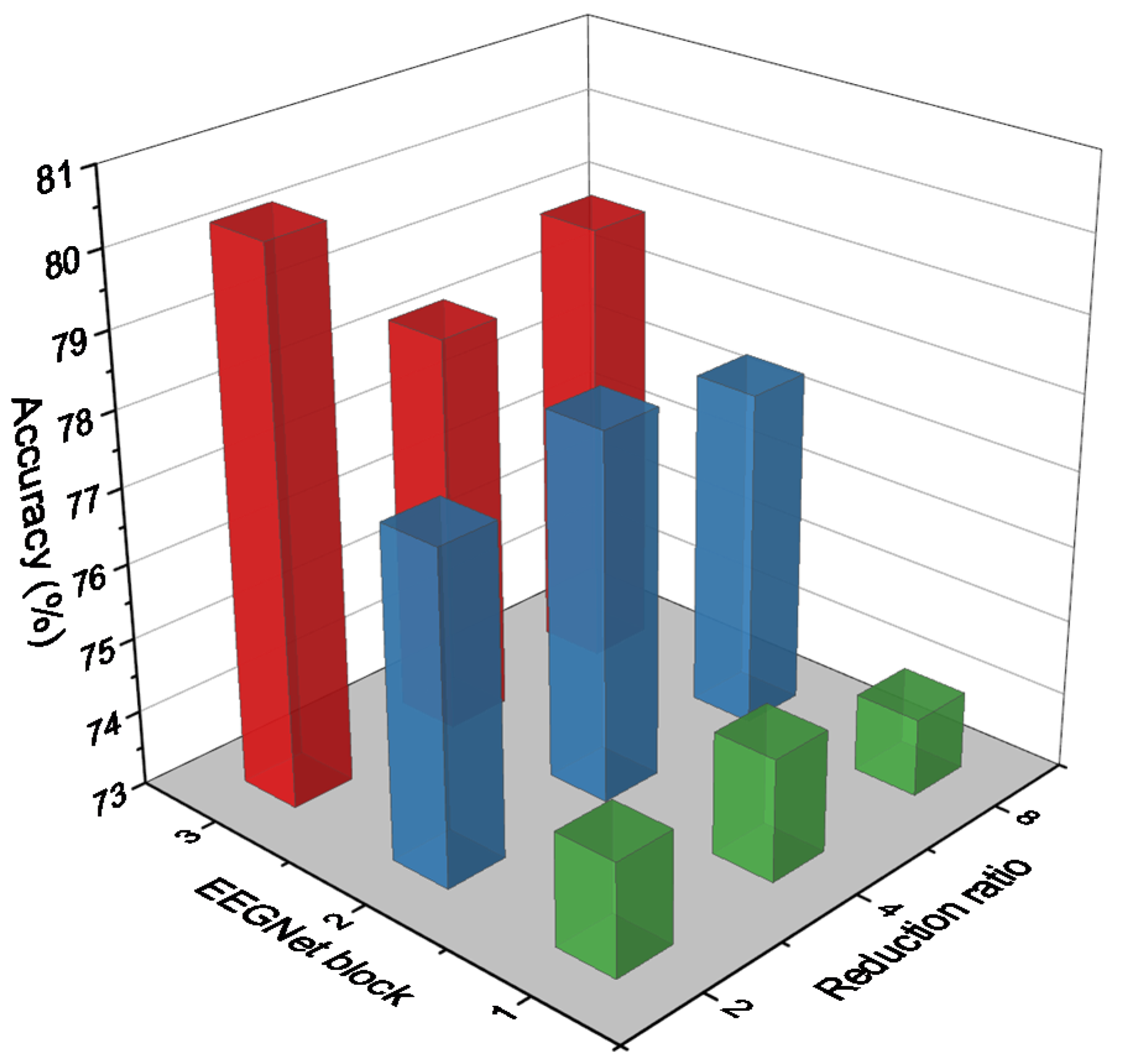
- By applying variable optimum reduction ratios of the attention mechanism in different branches, we can reduce the number of hyperparameters in the multibranch model of the EEG-MI classification.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Musallam, Y.K.; AlFassam, N.I.; Muhammad, G.; Amin, S.U.; Alsulaiman, M.; Abdul, W.; Altaheri, H.; Bencherif, M.A.; Algabri, M. Electroencephalography-based motor imagery classification using temporal convolutional network fusion. Biomed. Signal Processing Control 2021, 69, 102826. [Google Scholar] [CrossRef]
- Padfield, N.; Zabalza, J.; Zhao, H.; Masero, V.; Ren, J. EEG-Based Brain-Computer Interfaces Using Motor-Imagery: Techniques and Challenges. Sensors 2019, 19, 1423. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Caldwell, J.A.; Prazinko, B.; Caldwell, J.L. Body posture affects electroencephalographic activity and psychomotor vigilance task performance in sleep-deprived subjects. Clin. Neurophysiol. 2003, 114, 23–31. [Google Scholar] [CrossRef]
- Altaheri, H.; Muhammad, G.; Alsulaiman, M.; Amin, S.; Altuwaijri, G.; Abdul, W.; Bencherif, M.; Faisal, M. Deep Learning Techniques for Classification of Electroencephalogram (EEG) Motor Imagery (MI) Signals: A Review. Neural Comput. Appl. 2021, 1–42. [Google Scholar] [CrossRef]
- Lotte, F.; Guan, C. Regularizing Common Spatial Patterns to Improve BCI Designs: Unified Theory and New Algorithms. IEEE Trans. Biomed. Eng. 2011, 58, 355–362. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Yu, Y.; Xu, M.; Liu, Y.; Yin, E.; Zhou, Z. Towards a Hybrid BCI Gaming Paradigm Based on Motor Imagery and SSVEP. Int. J. Hum. Comput. Interact. 2019, 35, 197–205. [Google Scholar] [CrossRef]
- Müller-Putz, G.R.; Ofner, P.; Schwarz, A.; Pereira, J.; Luzhnica, G.; di Sciascio, C.; Veas, E.; Stein, S.; Williamson, J.; Murray-Smith, R.; et al. Moregrasp: Restoration of Upper Limb Function in Individuals with High Spinal Cord Injury by Multimodal Neuroprostheses for Interaction in Daily Activities. In Proceedings of the 7th Graz Brain-Computer Interface Conference, Graz, Austria, 18 September 2017; pp. 338–343. [Google Scholar]
- Elstob, D.; Secco, E.L. A Low Cost Eeg Based Bci Prosthetic Using Motor Imagery. arXiv 2016, arXiv:1603.02869v1. [Google Scholar] [CrossRef] [Green Version]
- Abiri, R.; Zhao, X.; Heise, G.; Jiang, Y.; Abiri, F. Brain computer interface for gesture control of a social robot: An offline study. In Proceedings of the 2017 Iranian Conference on Electrical Engineering (ICEE), Tehran, Iran, 2–4 May 2017; pp. 113–117. [Google Scholar]
- Gomez-Rodriguez, M.; Grosse-Wentrup, M.; Hill, J.; Gharabaghi, A.; Scholkopf, B.; Peters, J. Towards brain-robot interfaces in stroke rehabilitation. In Proceedings of the IEEE International Conference on Rehabilitation Robotics, Zurich, Switzerland, 29 June–1 July 2011; pp. 1–6. [Google Scholar]
- Schirrmeister, R.T.; Springenberg, J.T.; Fiederer, L.D.J.; Glasstetter, M.; Eggensperger, K.; Tangermann, M.; Hutter, F.; Burgard, W.; Ball, T. Deep learning with convolutional neural networks for EEG decoding and visualization. Hum. Brain Mapp. 2017, 38, 5391–5420. [Google Scholar] [CrossRef] [Green Version]
- Bashivan, P.; Rish, I.; Yeasin, M.; Codella, N. Learning Representations from EEG with Deep Recurrent-Convolutional Neural Networks. arXiv 2015, arXiv:1511.06448v3. [Google Scholar]
- Tabar, Y.R.; Halici, U. A novel deep learning approach for classification of EEG motor imagery signals. J. Neural Eng. 2017, 14, 016003. [Google Scholar] [CrossRef]
- Tang, Z.; Li, C.; Sun, S. Single-trial EEG classification of motor imagery using deep convolutional neural networks. Optik 2017, 130, 11–18. [Google Scholar] [CrossRef]
- Amin, S.U.; Altaheri, H.; Muhammad, G.; Alsulaiman, M.; Wadood, A. Attention-Inception and Long- Short-Term Memory-Based Electroencephalography Classification for Motor Imagery Tasks in Rehabilitation. IEEE Trans. Ind. Inform. 2022. [Google Scholar] [CrossRef]
- Cecotti, H.; Graser, A. Convolutional Neural Networks for P300 Detection with Application to Brain-Computer Interfaces. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 433–445. [Google Scholar] [CrossRef] [PubMed]
- Ang, K.K.; Chin, Z.Y.; Wang, C.; Guan, C.; Zhang, H. Filter Bank Common Spatial Pattern Algorithm on BCI Competition IV Datasets 2a and 2b. Front. Neurosci. 2012, 6, 39. [Google Scholar] [CrossRef] [Green Version]
- Lawhern, V.J.; Solon, A.J.; Waytowich, N.R.; Gordon, S.M.; Hung, C.P.; Lance, B.J. EEGNet: A compact convolutional neural network for EEG-based brain–computer interfaces. J. Neural Eng. 2018, 15, 056013. [Google Scholar] [CrossRef] [Green Version]
- Riyad, M.; Khalil, M.; Adib, A. Incep-EEGNet: A ConvNet for Motor Imagery Decoding. In Proceedings of the 9th International Conference on Image and Signal Processing (ICISP), Marrakesh, Morocco, 4–6 June 2020; pp. 103–111. [Google Scholar]
- Ingolfsson, T.M.; Hersche, M.; Wang, X.; Kobayashi, N.; Cavigelli, L.; Benini, L. EEG-TCNet: An Accurate Temporal Convolutional Network for Embedded Motor-Imagery Brain-Machine Interfaces. In Proceedings of the 2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Toronto, ON, Canada, 11–14 October 2020; pp. 2958–2965. [Google Scholar]
- Amin, S.; Alsulaiman, M.; Muhammad, G.; Amine, M.A.; Hossain, M.S. Deep Learning for EEG motor imagery classification based on multi-layer CNNs feature fusion. Future Gener. Comput. Syst. 2019, 101, 542–554. [Google Scholar] [CrossRef]
- Amin, S.; Altaheri, H.; Muhammad, G.; Alsulaiman, M.; Abdul, W. Attention based Inception model for robust EEG motor imagery classification. In Proceedings of the IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Glasgow, UK, 17–20 May 2021; pp. 1–6. [Google Scholar]
- Zhao, X.; Zhang, H.; Zhu, G.; You, F.; Kuang, S.; Sun, L. A Multi-Branch 3D Convolutional Neural Network for EEG-Based Motor Imagery Classification. IEEE Trans. Neural Syst. Rehabil. Eng. 2019, 27, 2164–2177. [Google Scholar] [CrossRef]
- Zhou, H.; Zhao, X.; Zhang, H.; Kuang, S. The Mechanism of a Multi-Branch Structure for EEG-Based Motor Imagery Classification. In Proceedings of the 2019 IEEE International Conference on Robotics and Biomimetics (ROBIO), Dali, China, 6–8 December 2019; pp. 2473–2477. [Google Scholar]
- Jin, J.; Dundar, A.; Culurciello, E. Flattened convolutional neural networks for feedforward acceleration. arXiv 2015, arXiv:1412.5474v4. [Google Scholar]
- Li, Y.; Zhang, X.-R.; Zhang, B.; Lei, M.-Y.; Cui, W.-G.; Guo, Y.-Z. A Channel-Projection Mixed-Scale Convolutional Neural Network for Motor Imagery EEG Decoding. IEEE Trans. Neural Syst. Rehabil. Eng. 2019, 27, 1170–1180. [Google Scholar] [CrossRef]
- Liu, X.; Shen, Y.; Liu, J.; Yang, J.; Xiong, P.; Lin, F. Parallel Spatial–Temporal Self-Attention CNN-Based Motor Imagery Classification for BCI. Front. Neurosci. 2020, 14, 587520. [Google Scholar] [CrossRef]
- Dai, G.; Zhou, J.; Huang, J.; Wang, N. HS-CNN: A CNN with hybrid convolution scale for EEG motor imagery classification. J. Neural Eng. 2020, 17, 016025. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Guo, L.; Liu, Y.; Liu, J.; Meng, F. A Temporal-Spectral-Based Squeeze-and- Excitation Feature Fusion Network for Motor Imagery EEG Decoding. IEEE Trans. Neural Syst. Rehabil. Eng. 2021, 29, 1534–1545. [Google Scholar] [CrossRef] [PubMed]
- Li, D.; Xu, J.; Wang, J.; Fang, X.; Ji, Y. A Multi-Scale Fusion Convolutional Neural Network Based on Attention Mechanism for the Visualization Analysis of EEG Signals Decoding. IEEE Trans. Neural Syst. Rehabil. Eng. 2020, 28, 2615–2626. [Google Scholar] [CrossRef] [PubMed]
- Jia, Z.; Lin, Y.; Wang, J.; Yang, K.; Liu, T.; Zhang, X. MMCNN: A multi-branch multi-scale convolutional neural network for motor imagery classification. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Ghent, Belgium, 19–23 September 2020; Springer: Cham, Switzerland, 2020; Volume 12459, pp. 736–751. [Google Scholar]
- Roots, K.; Muhammad, Y.; Muhammad, N. Fusion Convolutional Neural Network for Cross-Subject EEG Motor Imagery Classification. Computers 2020, 9, 27. [Google Scholar] [CrossRef]
- Muhammad, G.; Hossain, M.S.; Kumar, N. EEG-Based Pathology Detection for Home Health Monitoring. IEEE J. Sel. Areas Commun. 2021, 39, 603–610. [Google Scholar] [CrossRef]
- Muhammad, G.; Alshehri, F.; Karray, F.; El Saddik, A.; Alsulaiman, M.; Falk, T.H. A comprehensive survey on multimodal medical signals fusion for smart healthcare systems. Inf. Fusion 2021, 76, 355–375. [Google Scholar] [CrossRef]
- Larochelle, H.; Hinton, G.E. Learning to combine foveal glimpses with a third-order Boltzmann machine. Adv. Neural Inf. Processing Syst. 2010, 23, 1243–1251. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Altuwaijri, G.A.; Muhammad, G. A Multibranch of Convolutional Neural Network Models for Electroencephalogram-Based Motor Imagery Classification. Biosensors 2022, 12, 22. [Google Scholar] [CrossRef]
- Hersche, M.; Rellstab, T.; Schiavone, P.D.; Cavigelli, L.; Benini, L.; Rahimi, A. Fast and Accurate Multiclass Inference for MI-BCIs Using Large Multiscale Temporal and Spectral Features. In Proceedings of the 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 1690–1694. [Google Scholar]
- Belwafi, K.; Ghaffari, F.; Djemal, R.; Romain, O. A hardware/software prototype of EEG-based BCI system for home device control. J. Signal Processing Syst. 2017, 89, 263–279. [Google Scholar] [CrossRef]
- Shahbakhti, M.; Beiramvand, M.; Rejer, I.; Augustyniak, P.; Broniec-Wojcik, A.; Wierzchon, M.; Marozas, V. Simultaneous Eye Blink Characterization and Elimination From Low-Channel Prefrontal EEG Signals Enhances Driver Drowsiness Detection. IEEE J. Biomed. Health Inform. 2022, 26, 1001–1012. [Google Scholar] [CrossRef]
- Yuan, P.; Gao, X.; Allison, B.; Wang, Y.; Bin, G.; Gao, S. A study of the existing problems of estimating the information transfer rate in online brain-computer interfaces. J. Neural. Eng. 2013, 10, 026014. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Branch | Block | Activation Function | Hyperparameter | Value |
|---|---|---|---|---|
| First branch | EEGNet Block | ELU | Number of temporal filters | 4 |
| Kernel size | 16 | |||
| Dropout rate | 0 | |||
| SE Block | ReLU | Reduction ratio | 4 | |
| Second branch | EEGNet Block | ELU | Number of temporal filters | 8 |
| Kernel size | 32 | |||
| Dropout rate | 0.1 | |||
| SE Block | ReLU | Reduction ratio | 4 | |
| Third branch | EEGNet Block | ELU | Number of temporal filters | 16 |
| Kernel size | 64 | |||
| Dropout rate | 0.2 | |||
| SE Block | ReLU | Reduction ratio | 2 |
| Datasets | Methods | Accuracy (%) | Kappa | F1 Score |
|---|---|---|---|---|
| BCI-IV2a | FBCSP [17] | 67.80 | NA * | 0.675 |
| ShallowConvNet [29] | 72.92 | 0.639 | 0.728 | |
| DeepConvNet [11] | 70.10 | NA | 0.706 | |
| EEGNet [20] | 72.40 | 0.630 | NA | |
| CP-MixedNet [26] | 74.60 | NA | 0.743 | |
| TS-SEFFNet [29] | 74.71 | 0.663 | 0.757 | |
| MBEEGNet [37] | 82.01 | 0.760 | 0.822 | |
| MBShallowCovNet [37] | 81.15 | 0.749 | 0.814 | |
| CNN + BiLSTM (fixed) [15] | 75.81 | NA | NA | |
| Proposed (MBEEGSE) | 82.87 | 0.772 | 0.829 | |
| HGD | FBCSP [17] | 90.90 | NA | 0.914 |
| ShallowConvNet [29] | 88.69 | 0.849 | 0.887 | |
| DeepConvNet [11] | 91.40 | NA | 0.925 | |
| EEGNet [37] | 93.47 | 0.921 | 0.935 | |
| CP-MixedNet [26] | 93.70 | NA | 0.937 | |
| TS-SEFFNet [29] | 93.25 | 0.910 | 0.901 | |
| MBEEGNet [37] | 95.30 | 0.937 | 0.954 | |
| MBShallowCovNet [37] | 95.11 | 0.935 | 0.951 | |
| CNN + BiLSTM (fixed) [15] | 96.00 | NA | NA | |
| Proposed (MBEEGSE) | 96.15 | 0.949 | 0.962 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | Avg. | Std. Dev. | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Accuracy (%) | 89.14 | 69.73 | 95.27 | 81.42 | 80 | 63.25 | 94.06 | 89.57 | 83.35 | 82.87 | 0.108 | |
| K value | 0.855 | 0.596 | 0.937 | 0.752 | 0.733 | 0.510 | 0.921 | 0.861 | 0.778 | 0.772 | 0.144 | |
| F1 score | 0.892 | 0.696 | 0.953 | 0.816 | 0.800 | 0.633 | 0.943 | 0.896 | 0.835 | 0.829 | 0.108 | |
| Precision | LH | 0.857 | 0.602 | 0.955 | 0.872 | 0.760 | 0.594 | 0.967 | 0.968 | 0.857 | 0.826 | 0.145 |
| RH | 0.926 | 0.563 | 0.932 | 0.760 | 0.917 | 0.660 | 0.905 | 0.915 | 0.769 | 0.816 | 0.136 | |
| F | 0.906 | 0.850 | 0.954 | 0.718 | 0.739 | 0.703 | 0.934 | 0.857 | 0.871 | 0.837 | 0.094 | |
| Tou. | 0.876 | 0.774 | 0.970 | 0.907 | 0.783 | 0.574 | 0.956 | 0.843 | 0.837 | 0.836 | 0.120 | |
| Avg. | 0.891 | 0.697 | 0.953 | 0.814 | 0.800 | 0.633 | 0.941 | 0.896 | 0.834 | 0.829 | 0.108 | |
| Recall | LH | 0.907 | 0.690 | 0.958 | 0.824 | 0.833 | 0.626 | 0.846 | 0.907 | 0.833 | 0.825 | 0.106 |
| RH | 0.910 | 0.586 | 0.984 | 0.750 | 0.868 | 0.611 | 0.965 | 0.939 | 0.785 | 0.822 | 0.149 | |
| F | 0.859 | 0.832 | 0.917 | 0.896 | 0.774 | 0.636 | 0.984 | 0.869 | 0.797 | 0.840 | 0.099 | |
| Tou. | 0.892 | 0.675 | 0.955 | 0.805 | 0.728 | 0.661 | 0.987 | 0.868 | 0.931 | 0.833 | 0.122 | |
| Avg. | 0.892 | 0.696 | 0.953 | 0.819 | 0.801 | 0.634 | 0.945 | 0.896 | 0.837 | 0.830 | 0.109 | |
| Methods | Mean Accuracy (%) | Number of Parameters |
|---|---|---|
| FBCSB [38] | 73.70 | 261 × 103 |
| ShallowConvNet [20] | 74.31 | 47.31 × 103 |
| DeepConvNet [29] | 71.99 | 284 × 103 |
| EEGNet [20] | 72.40 | 2.63 × 103 |
| CP-MixedNet [29] | 74.60 | 836 × 103 |
| TS-SEFFNet [29] | 74.71 | 282 × 103 |
| MBEEGNet [37] | 82.01 | 8.908 × 103 |
| MBShallowConvNet [37] | 81.15 | 147.22 × 103 |
| CNN + BiLSTM (fixed) [15] | 75.81 | 55 × 103 |
| Proposed (MBEEGSE) | 82.87 | 10.17 × 103 |
| Subject | ITR (Bits/Min) |
|---|---|
| S1 | 17.76 |
| S2 | 8.47 |
| S3 | 22 |
| S4 | 13.50 |
| S5 | 12.81 |
| S6 | 6.25 |
| S7 | 21.07 |
| S8 | 18.02 |
| S9 | 14.48 |
| Average | 14.93 |
| Subject/Metric | Accuracy (%) | K Value | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| S1 | 97.05 | 0.961 | 0.971 | 0.971 | 0.971 |
| S2 | 95.14 | 0.935 | 0.952 | 0.953 | 0.952 |
| S3 | 100 | 1 | 1 | 1 | 1 |
| S4 | 98.80 | 0.984 | 0.988 | 0.988 | 0.988 |
| S5 | 98.15 | 0.975 | 0.981 | 0.982 | 0.982 |
| S6 | 99.40 | 0.992 | 0.994 | 0.994 | 0.994 |
| S7 | 93.84 | 0.918 | 0.938 | 0.939 | 0.939 |
| S8 | 96.75 | 0.957 | 0.968 | 0.971 | 0.969 |
| S9 | 98.77 | 0.984 | 0.988 | 0.988 | 0.988 |
| S10 | 92.77 | 0.904 | 0.928 | 0.930 | 0.929 |
| S11 | 94.70 | 0.929 | 0.947 | 0.948 | 0.948 |
| S12 | 97.49 | 0.967 | 0.975 | 0.975 | 0.975 |
| S13 | 96.25 | 0.950 | 0.963 | 0.963 | 0.963 |
| S14 | 87.02 | 0.827 | 0.870 | 0.874 | 0.872 |
| Average | 96.15 | 0.949 | 0.962 | 0.963 | 0.962 |
| Std. Dev. | 0.034 | 0.045 | 0.034 | 0.033 | 0.033 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Altuwaijri, G.A.; Muhammad, G.; Altaheri, H.; Alsulaiman, M. A Multi-Branch Convolutional Neural Network with Squeeze-and-Excitation Attention Blocks for EEG-Based Motor Imagery Signals Classification. Diagnostics 2022, 12, 995. https://doi.org/10.3390/diagnostics12040995
Altuwaijri GA, Muhammad G, Altaheri H, Alsulaiman M. A Multi-Branch Convolutional Neural Network with Squeeze-and-Excitation Attention Blocks for EEG-Based Motor Imagery Signals Classification. Diagnostics. 2022; 12(4):995. https://doi.org/10.3390/diagnostics12040995
Chicago/Turabian StyleAltuwaijri, Ghadir Ali, Ghulam Muhammad, Hamdi Altaheri, and Mansour Alsulaiman. 2022. "A Multi-Branch Convolutional Neural Network with Squeeze-and-Excitation Attention Blocks for EEG-Based Motor Imagery Signals Classification" Diagnostics 12, no. 4: 995. https://doi.org/10.3390/diagnostics12040995
APA StyleAltuwaijri, G. A., Muhammad, G., Altaheri, H., & Alsulaiman, M. (2022). A Multi-Branch Convolutional Neural Network with Squeeze-and-Excitation Attention Blocks for EEG-Based Motor Imagery Signals Classification. Diagnostics, 12(4), 995. https://doi.org/10.3390/diagnostics12040995