
A Combined Approach for Accurate and Accelerated Teeth Detection on Cone Beam CT Images


Abstract
:1. Introduction
2. Related Works
3. Dataset and Relevant Knowledge
- The incisors: teeth 22, 21, 11, and 12 of the upper jaw or teeth 32, 31, 41, and 42 of the lower jaw;
- The right canines and premolars: teeth 13, 14, and 15 of the upper jaw or teeth 43, 44, and 45 of the lower jaw;
- The left canines and premolars: teeth 23, 24, and 25 of the upper jaw or teeth 33, 34, and 35 of the lower jaw;
- The right molars: teeth 16, 17, and 18 of the upper jaw or teeth 46, 47, and 48 of the lower jaw;
- The left molars: teeth 26, 27, and 28 of the upper jaw or teeth 36, 37, and 38 of the lower jaw.
4. Methodology
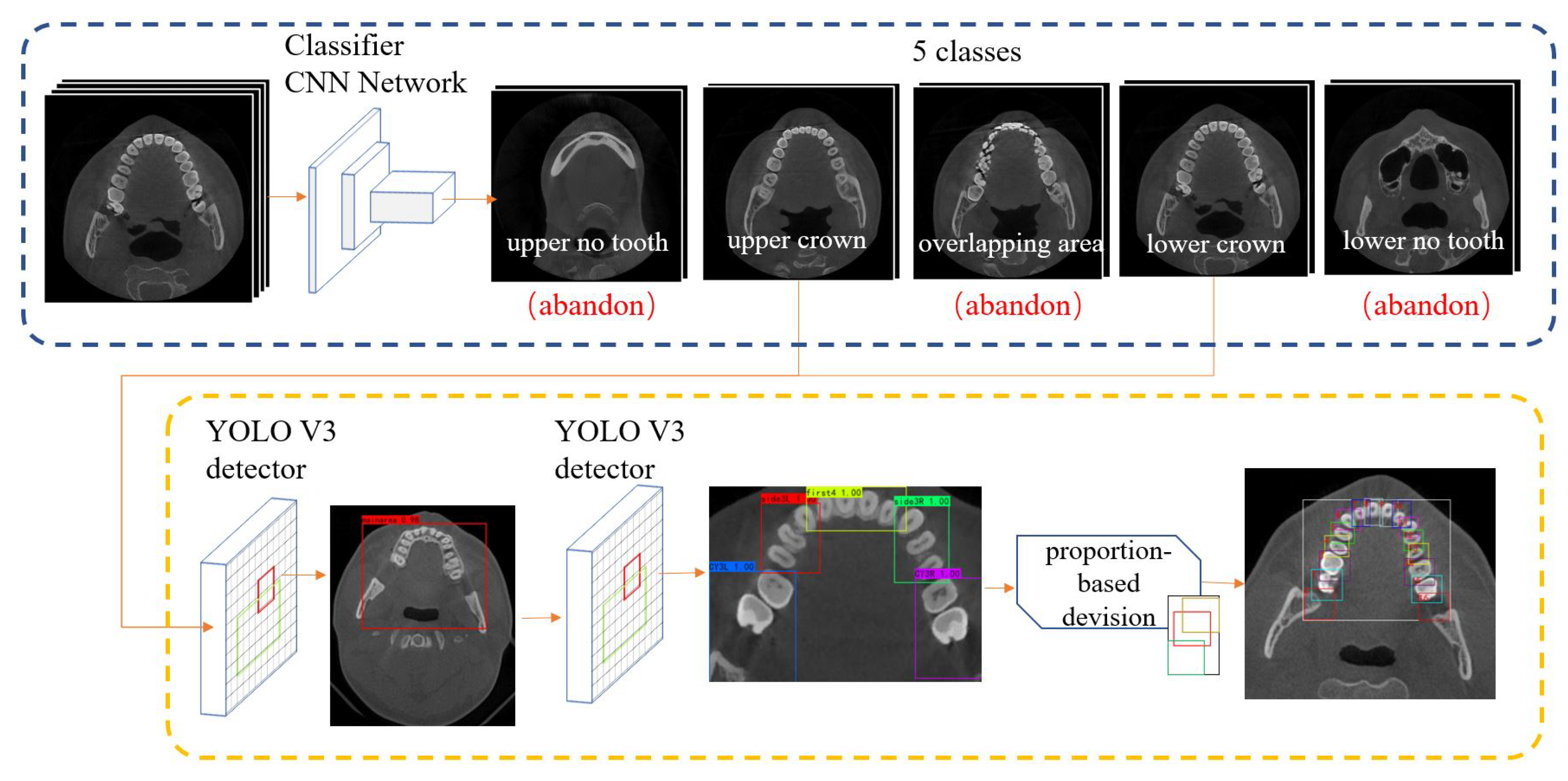
4.1. Pre-Processing
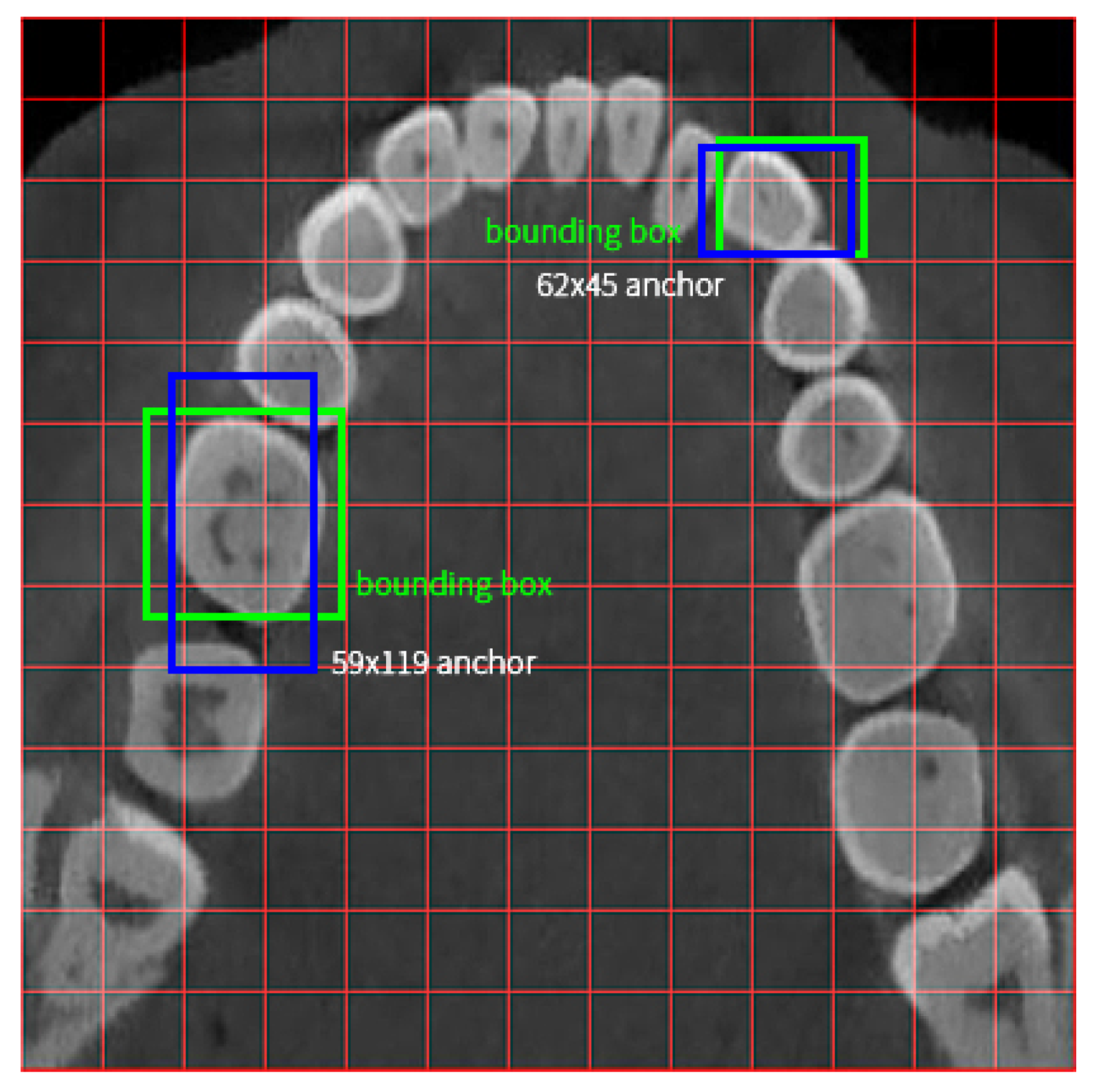
4.2. Teeth Detection
5. Experiment and Results
6. Analysis and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ko, C.C.; Shen, D.; Wang, L. Machine Learning in Dentistry; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Jacobs, R.; Salmon, B.; Codari, M.; Hassan, B.; Bornstein, M.M. Cone beam computed tomography in implant dentistry: Recommendations for clinical use. BMC Oral Health 2018, 18, 88. [Google Scholar] [CrossRef] [Green Version]
- Estrela, C.; Bueno, M.R.; Leles, C.R.; Azevedo, B.; Azevedo, J.R. Accuracy of cone beam computed tomography and panoramic and periapical radiography for detection of apical periodontitis. J. Endod. 2008, 34, 273–279. [Google Scholar] [CrossRef]
- Ramis-Alario, A.; Tarazona-Alvarez, B.; Cervera-Ballester, J.; Soto-Peñaloza, D.; Peñarrocha-Diago, M.; Peñarrocha-Oltra, D.; Peñarrocha-Diago, M. Comparison of diagnostic accuracy between periapical and panoramic radiographs and cone beam computed tomography in measuring the periapical area of teeth scheduled for periapical surgery. A cross-sectional study. J. Clin. Exp. Dent. 2019, 11, e732. [Google Scholar] [CrossRef]
- Takeshita, W.M.; Iwaki, L.C.V.; Da Silva, M.C.; Tonin, R.H. Evaluation of diagnostic accuracy of conventional and digital periapical radiography, panoramic radiography, and cone-beam computed tomography in the assessment of alveolar bone loss. Contemp. Clin. Dent. 2014, 5, 318. [Google Scholar] [CrossRef]
- Liang, Y.H.; Jiang, L.; Gao, X.J.; Shemesh, H.; Wesselink, P.R.; Wu, M.K. Detection and measurement of artificial periapical lesions by cone-beam computed tomography. Int. Endod. J. 2014, 47, 332–338. [Google Scholar] [CrossRef]
- Van Assche, N.; Vercruyssen, M.; Coucke, W.; Teughels, W.; Jacobs, R.; Quirynen, M. Accuracy of computer-aided implant placement. Clin. Oral Implants Res. 2012, 23 (Suppl. 6), 112–123. [Google Scholar] [CrossRef]
- Torres, A.; Shaheen, E.; Lambrechts, P.; Politis, C.; Jacobs, R. Microguided Endodontics: A case report of a maxillary lateral incisor with pulp canal obliteration and apical periodontitis. Int. Endod. J. 2019, 52, 540–549. [Google Scholar] [CrossRef]
- EzEldeen, M.; Wyatt, J.; Al-Rimawi, A.; Coucke, W.; Shaheen, E.; Lambrichts, I.; Willems, G.; Politis, C.; Jacobs, R. Use of CBCT Guidance for Tooth Autotransplantation in Children. J. Dent. Res. 2019, 98, 406–413. [Google Scholar] [CrossRef]
- Cui, Z.; Li, C.; Wang, W. ToothNet: Automatic Tooth Instance Segmentation and Identification From Cone Beam CT Images. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 6361–6370. [Google Scholar] [CrossRef]
- Shaheen, E.; Khalil, W.; Ezeldeen, M.; Van de Casteele, E.; Sun, Y.; Politis, C.; Jacobs, R. Accuracy of segmentation of tooth structures using 3 different CBCT machines. Oral Surg. Oral Med. Oral Pathol. Oral Radiol. 2017, 123, 123–128. [Google Scholar] [CrossRef]
- Viewer, R.D. Features. 2021. Available online: https://www.radiantviewer.com/dicom-viewer-manual/radiant_dicom_viewer_features.html (accessed on 30 May 2022).
- Lee, J.; Chung, M.; Lee, M.; Shin, Y.G. Tooth instance segmentation from cone-beam CT images through point-based detection and Gaussian disentanglement. Multimed. Tools Appl. 2022, 81, 18327–18342. [Google Scholar] [CrossRef]
- Muresan, M.P.; Barbura, A.R.; Nedevschi, S. Teeth Detection and Dental Problem Classification in Panoramic X-ray Images using Deep Learning and Image Processing Techniques. In Proceedings of the 2020 IEEE 16th International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 3–5 September 2020; pp. 457–463. [Google Scholar] [CrossRef]
- Arbeláez, P.; Maire, M.; Fowlkes, C.; Malik, J. Contour Detection and Hierarchical Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 898–916. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Fevens, T.; Krzyżak, A.; Li, S. An automatic variational level set segmentation framework for computer aided dental X-rays analysis in clinical environments. Comput. Med. Imaging Graph. 2006, 30, 65–74. [Google Scholar] [CrossRef]
- Carreira, J.; Sminchisescu, C. Constrained parametric min-cuts for automatic object segmentation. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3241–3248. [Google Scholar] [CrossRef]
- Kumar, R. Teeth recognition for person identification. In Proceedings of the 2016 International Conference on Computation System and Information Technology for Sustainable Solutions (CSITSS), Bengaluru, India, 6–8 October 2016; pp. 13–16. [Google Scholar] [CrossRef]
- Lin, P.; Lai, Y.; Huang, P. An effective classification and numbering system for dental bitewing radiographs using teeth region and contour information. Pattern Recognit. 2010, 43, 1380–1392. [Google Scholar] [CrossRef]
- Mahoor, M.H.; Abdel-Mottaleb, M. Classification and numbering of teeth in dental bitewing images. Pattern Recognit. 2005, 38, 577–586. [Google Scholar] [CrossRef]
- Tangel, M.L.; Fatichah, C.; Yan, F.; Betancourt, J.P.; Widyanto, M.R.; Dong, F.; Hirota, K. Dental classification for periapical radiograph based on multiple fuzzy attribute. In Proceedings of the 2013 Joint IFSA World Congress and NAFIPS Annual Meeting (IFSA/NAFIPS), Edmonton, AB, Canada, 24–28 June 2013; pp. 304–309. [Google Scholar] [CrossRef]
- Miki, Y.; Muramatsu, C.; Hayashi, T.; Zhou, X.; Hara, T.; Katsumata, A.; Fujita, H. Classification of teeth in cone-beam CT using deep convolutional neural network. Comput. Biol. Med. 2017, 80, 24–29. [Google Scholar] [CrossRef]
- Zhang, K.; Wu, J.; Chen, H.; Lyu, P. An effective teeth recognition method using label tree with cascade network structure. Comput. Med. Imaging Graph. 2018, 68, 61–70. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.; Zhang, K.; Lyu, P.; Li, H.; Zhang, L.; Wu, J.; Lee, C.H. A deep learning approach to automatic teeth detection and numbering based on object detection in dental periapical films. Sci. Rep. 2019, 9, 3840. [Google Scholar] [CrossRef] [Green Version]
- Mahdi, F.P.; Motoki, K.; Kobashi, S. Optimization technique combined with deep learning method for teeth recognition in dental panoramic radiographs. Sci. Rep. 2020, 10, 19261. [Google Scholar] [CrossRef]
- Tuzoff, D.V.; Tuzova, L.N.; Bornstein, M.M.; Krasnov, A.S.; Kharchenko, M.A.; Nikolenko, S.I.; Sveshnikov, M.M.; Bednenko, G.B. Tooth detection and numbering in panoramic radiographs using convolutional neural networks. Dento Maxillo Facial Radiol. 2019, 48, 20180051. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Zhang, K.; Chen, H.; Lyu, P.; Wu, J. A relation-based framework for effective teeth recognition on dental periapical X-rays. Comput. Med. Imaging Graph. 2022, 95, 102022. [Google Scholar] [CrossRef]
- Contributors, T. CROSSENTROPYLOSS. Website. 2019. Available online: https://pytorch.org/docs/stable/generated/torch.nn.CrossEntropyLoss.html (accessed on 30 May 2022).
- Chung, M.; Lee, M.; Hong, J.; Park, S.; Lee, J.; Lee, J.; Yang, I.H.; Lee, J.; Shin, Y.G. Pose-aware instance segmentation framework from cone beam CT images for tooth segmentation. Comput. Biol. Med. 2020, 120, 103720. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Cartucho, J.; Ventura, R.; Veloso, M. Robust Object Recognition Through Symbiotic Deep Learning In Mobile Robots. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 2336–2341. [Google Scholar]
- Wang, J.; Zhu, H.; Wang, S.H.; Zhang, Y.D. A review of deep learning on medical image analysis. Mob. Netw. Appl. 2021, 26, 351–380. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Contributor | Description |
|---|---|---|
| 1 | doctor 1 | 8 teeth on 112 images |
| 2 | doctor 2 | 8 teeth on 112 images |
| 3 | doctor 3 | 8 teeth on 112 images |
| Our Method | Faster R-CNN | p Value | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | Mean | SD | 1 | 2 | 3 | Mean | SD | ||
| mAP | 88.77% | 81.68% | 73.91% | 81.43% | 12.01% | 85.17% | 88.08% | 71.88% | 82.03% | 13.43% | 0.835 |
| Precision | 90.82% | 86.28% | 82.42% | 86.15% | 10.18% | 60.75% | 60.73% | 55.17% | 86.15% | 13.35% | <0.001 |
| Recall | 90.80% | 86.19% | 82.08% | 85.95% | 9.75% | 94.58% | 94.58% | 85.40% | 90.98% | 7.41% | 0.034 |
| F1 | 0.9 | 0.86 | 0.82 | 0.86 | 0.1 | 0.73 | 0.73 | 0.66 | 0.71 | 0.12 | <0.001 |
| Method | Average OIR | N | SD | SE |
|---|---|---|---|---|
| Faster R-CNN | 91.40% | 112 | 0.09832 | 0.00929 |
| Our method | 96.27% | 112 | 0.03946 | 0.00373 |
| Mean | SD | SE | = 0.05 | t | df | Sig. | |
|---|---|---|---|---|---|---|---|
| Down | Up | ||||||
| 0. 04866 | 0.1003 | 0.00948 | 0.02987 | 0. 06744 | 5.134 | 111 | 0 |
| Method | Training VRAM Consumption | Time Consumption per Training Epoch | Time Consumption per Predicting |
|---|---|---|---|
| Faster R-CNN | 15 GB | 53 s | 274 ms |
| our method | 9.5 GB | 20 s | 53 ms |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, M.; Wu, X.; Ye, Y.; Fang, S.; Zhang, H.; Chen, M. A Combined Approach for Accurate and Accelerated Teeth Detection on Cone Beam CT Images. Diagnostics 2022, 12, 1679. https://doi.org/10.3390/diagnostics12071679
Du M, Wu X, Ye Y, Fang S, Zhang H, Chen M. A Combined Approach for Accurate and Accelerated Teeth Detection on Cone Beam CT Images. Diagnostics. 2022; 12(7):1679. https://doi.org/10.3390/diagnostics12071679
Chicago/Turabian StyleDu, Mingjun, Xueying Wu, Ye Ye, Shuobo Fang, Hengwei Zhang, and Ming Chen. 2022. "A Combined Approach for Accurate and Accelerated Teeth Detection on Cone Beam CT Images" Diagnostics 12, no. 7: 1679. https://doi.org/10.3390/diagnostics12071679
APA StyleDu, M., Wu, X., Ye, Y., Fang, S., Zhang, H., & Chen, M. (2022). A Combined Approach for Accurate and Accelerated Teeth Detection on Cone Beam CT Images. Diagnostics, 12(7), 1679. https://doi.org/10.3390/diagnostics12071679