
An Unsupervised Neural Network Feature Selection and 1D Convolution Neural Network Classification for Screening of Parkinsonism


Abstract
:1. Introduction
1.1. Motivation
1.2. Research Problem and Objective
- The proposed CNN-1D is the first approach used for the classification of PD, and proves that the deep-learning model returns outstanding results in a large amount of data without feature selection;
- We conducted a comparison between a statistical recursive feature elimination technique (RFE) and a deep-learning-based unsupervised autoencoder to select the optimal subset of features;
- Our proposed approach performs analysis between different dimensionality reduction techniques and provides outstanding results.
2. Literature Review
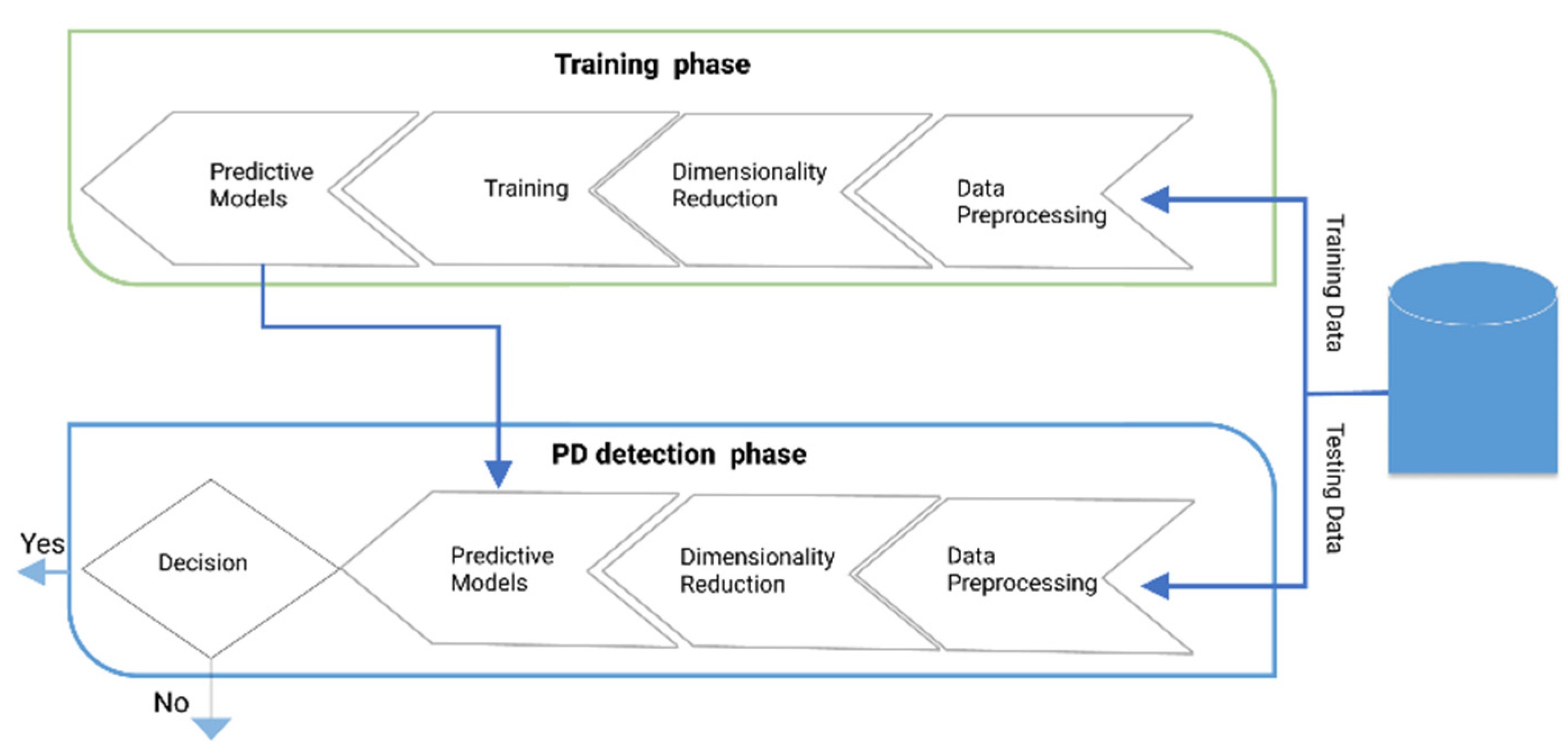
3. Methodology
3.1. Data Set
3.2. Proposed Models
3.2.1. Autoencoder
3.2.2. Logistic Regression Model
3.2.3. Support Vector Machine (SVM)
3.2.4. Naïve Bayes Model (NBM)
3.2.5. Random Forest Model (RFM)
3.2.6. Convolutional Neural Network-1D
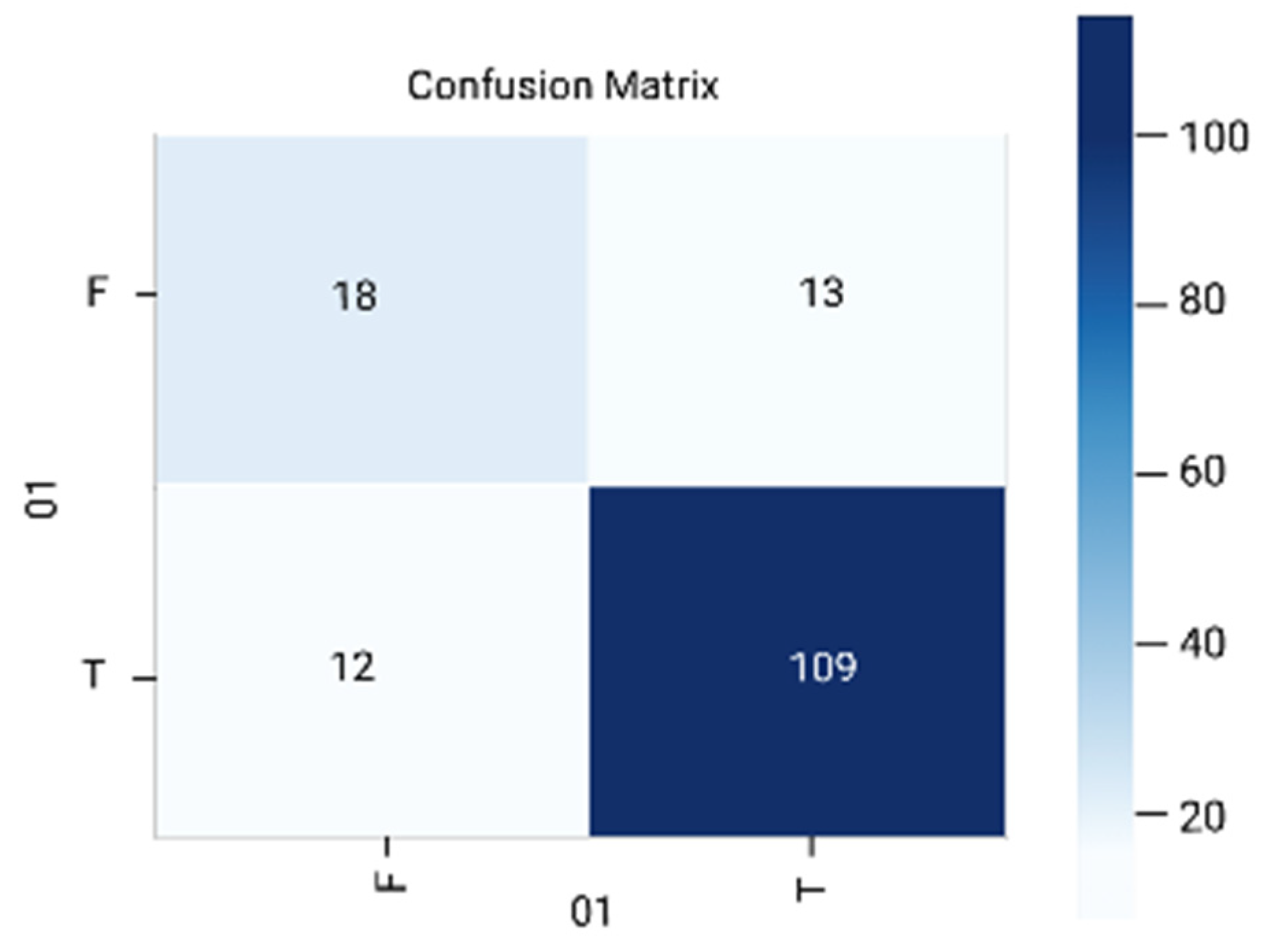
4. Results and Discussion
4.1. Evaluation Metrics
4.2. Discussion
5. Conclusions
Funding
Conflicts of Interest
References
- Fahn, S. Description of Parkinson’s disease as a clinical syndrome. Ann. N. Y. Acad. Sci. 2003, 991, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Cummings, J.L.; Henchcliffe, C.; Schaier, S.; Simuni, T.; Waxman, A.; Kemp, P. The role of dopaminergic imaging in patients with symptoms of dopaminergic system neurodegeneration. Brain 2011, 134, 3146–3166. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lang, A.E.; Lozano, A.M. Parkinson’s disease First of two parts. N. Engl. J. Med. 1998, 339, 1044–1053. [Google Scholar] [CrossRef] [PubMed]
- De Rijk, M.D.; Launer, L.J.; Berger, K.; Breteler, M.M.; Dartigues, J.F.; Baldereschi, M.; Hofman, A. Prevalence of Parkinson’s disease in Europe: A collaborative study of population-based cohorts. Neurologic Diseases in the Elderly Research Group. Neurology 2020, 54, S21–S23. [Google Scholar]
- Singh, N.; Pillay, V.; Choonara, Y.E. Advances in the treatment of Parkinson′s disease. Prog. Neurobiol. 2007, 81, 29–44. [Google Scholar] [CrossRef] [PubMed]
- Gunduz, H. Deep Learning-Based Parkinson’s Disease Classification Using Vocal Feature Sets. IEEE Access 2019, 7, 115540–115551. [Google Scholar] [CrossRef]
- Lahmiri, S.; Shmuel, A. Detection of Parkinson’s disease based on voice patterns ranking and optimized support vector machine. Biomed. Signal Process. Control 2019, 49, 427–433. [Google Scholar] [CrossRef]
- Braga, D.; Madureira, A.M.; Coelho, L.; Ajith, R. Automatic detection of Parkinson’s disease based on acoustic analysis of speech. Eng. Appl. Artif. Intell. 2018, 77, 148–158. [Google Scholar] [CrossRef]
- Bilgin, S. The impact of feature extraction for the classification of amyotrophic lateral sclerosis among neurodegenerative diseases and healthy subjects. Biomed. Signal Process. Control 2017, 31, 288–294. [Google Scholar] [CrossRef]
- Zhao, A.; Qi, L.; Li, J.; Dong, J.; Yu, H. A hybrid spatio-temporal model for detection and severity rating of Parkinson’s disease from gait data. Neurocomputing 2018, 315, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Cho, C.-W.; Chao, W.-H.; Lin, S.-H.; Chen, Y.-Y. A vision-based analysis system for gait recognition in patients with Parkinson’s disease. Expert Syst. Appl. 2009, 36, 7033–7039. [Google Scholar] [CrossRef]
- Betarbet, R.; Sherer, T.B.; Greenamyre, J.T. Animal models of Parkinson’s disease. Bioessays 2002, 24, 308–318. [Google Scholar] [CrossRef] [PubMed]
- Boyanov, B.; Hadjitodorov, S. Acoustic analysis of pathological voices. IEEE Eng. Med. Biol. Mag. 1997, 16, 74–82. [Google Scholar] [CrossRef]
- Rahn, D.A.; Chou, M.; Jiang, J.J.; Zhang, Y. Phonatory Impairment in Parkinson’s Disease: Evidence from Nonlinear Dynamic Analysis and Perturbation Analysis. J. Voice 2007, 21, 64–71. [Google Scholar] [CrossRef] [PubMed]
- Prashanth, R.; Roy, S.D. Early detection of Parkinson’s disease through patient questionnaire and predictive model-ling. Int. J. Med. Informat. 2018, 199, 75–87. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kumari, D.; Chokkalingam, S.P. Deep convolutional neural networks (CNN) for medical image analysis. Int. J. Eng. Adv. Technol. (IJEAT) 2019. [Google Scholar] [CrossRef]
- Song, Y.; Yu, Z.; Zhou, T.; Teoh, J.Y.C.; Lei, B.; Choi, K.S.; Qin, J. CNN in CT Image Segmentation: Beyond Loss Function for Exploiting Ground Truth Images. In Proceedings of the 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI), Iowa City, IA, USA, 3–7 April 2020; pp. 325–328. [Google Scholar] [CrossRef]
- Francis, M.; Deisy, C. Disease Detection and Classification in Agricultural Plants Using Convolutional Neural Networks—A Visual Understanding. In Proceedings of the 2019 6th International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 7–8 March 2019; pp. 1063–1068. [Google Scholar] [CrossRef]
- Sarvamangala, D.R.; Kulkarni, R.V. Convolutional neural networks in medical image understanding: A survey. Evol. Intell. 2021, 15, 1–22. [Google Scholar] [CrossRef]
- Alaskar, H. Convolutional neural network application in biomedical signals. J. Comput. Sci. Inform. Tech. 2018, 6, 45–59. [Google Scholar] [CrossRef]
- Arashpour, M.; Ngo, T.; Li, H. Scene understanding in construction and buildings using image processing methods: A comprehensive review and a case study. J. Build. Eng. 2021, 33, 101672. [Google Scholar] [CrossRef]
- Jang, B.; Kim, M.; Harerimana, G.; Kang, S.U.; Kim, J.W. Bi-LSTM model to increase accuracy in text classification: Combining Word2vec CNN and at-tention mechanism. Appl. Sci. 2020, 10, 5841. [Google Scholar] [CrossRef]
- Wang, W.; Lee, J.; Harrou, F.; Sun, Y. Early Detection of Parkinson’s disease Using Deep Learning and ML. IEEE Access 2016, 4, 147635–147646. [Google Scholar]
- Nissar, I.; Rizvi, D.R.; Masood, S.; Mir, A.N. Voice-Based Detection of Parkinson’s disease through Ensemble ML Approach: A Performance Study, 23 August. EAI Endorsed Trans. Pervasive Health Technol. 2019, 5, e2. [Google Scholar]
- Postuma, R.B.; Berg, D.; Stern, M.; Poewe, W.; Olanow, C.W.; Oertel, W.; Deuschl, G. MDS clinical diagnostic criteria for Parkinson’s disease. Mov. Disord. 2015, 30, 1591–1601. [Google Scholar] [CrossRef]
- Movement Disorder Society. The Unified Parkinson’s Disease Rating Scale (UParkinson’s diseaseRS): Status and rec-ommendations. Mov. Disord. Off. J. Mov. Disord. Soc. 2003, 18, 738–750. [Google Scholar] [CrossRef] [PubMed]
- Eskofier, B.M.; Lee, S.I.; Daneault, J.F.; Golabchi, F.N.; Ferreira-Carvalho, G.; Vergara-Diaz, G.; Bonato, P. Recent ML advancements in sensor-based mobility analysis: Deep learning for Parkinson’s disease assessment. In Proceedings of the 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 16–20 August 2016; pp. 655–658. [Google Scholar]
- Arora, S.; Venkataraman, V.; Donohue, S.; Biglan, K.M.; Dorsey, E.R.; Little, M.A. High accuracy discrimination of Parkinson’s disease participants from healthy controls using smartphones. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 3641–3644. [Google Scholar]
- Aha, D.W.; Bankert, R.L. Comparative Evaluation of Sequential Feature Selection Algorithms. In Learning from Data; Springer: Cham, Switzerland, 1996; pp. 199–206. [Google Scholar]
- Peng, H.; Long, F.; Ding, C. Feature selection based on mutual information criteria of max-dependency, max-relevanceand min-redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef]
- Chen, H.L.; Wang, G.; Ma, C.; Cai, Z.N.; Liu, W.B.; Wang, S.J. An efficient hybrid kernel extreme learning machine approach for early diagnosis of Parkinson’s disease. Nero Comput. 2016, 184, 131–144. [Google Scholar]
- Zaki, M.H.; Sayed, T. Using automated walking gait analysis for the identification of pedestrian attributes. Transp. Res. C Emerg. Technol. 2014, 48, 16–36. [Google Scholar] [CrossRef]
- Jatoba, L.C.; Grossmann, U.; Kunze, C.; Ottenbacher, J.; Stork, W. Context-aware mobile health monitoring: Evaluation of different pattern recognition methods for classification of physical activity. In Proceedings of the 2008 30th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Vancouver, BC, Canada, 20–25 August 2008; pp. 5250–5253. [Google Scholar]
- Tsanas, A.; Little, M.A.; McSharry, P.E.; Spielman, J.; Ramig, L.O. Novel speech signal processing algorithms for high-accuracy classification of Parkinson′s disease. IEEE Trans. Biomed. Eng. 2012, 59, 1264–1271. [Google Scholar] [CrossRef] [Green Version]
- Rouzbahani, H.K.; Daliri, M.R. Diagnosis of Parkinson’s disease in human using voice signals. Basic Clin. Neurosci. 2011, 2, 12. [Google Scholar]
- Parisi, L.; Chandran, N.; Manaog, M. Feature-driven ML to improve early diagnosis of Parkinson’s disease. Expert Syst. Appl. 2018, 110, 182–190. [Google Scholar] [CrossRef]
- Caliskan, A.; Badem, H.; Basturk, A.; Yuksel, M. Diagnosis of the parkinson disease by using deep neural network classifier. IU-J. Electr. Electron. Eng. 2017, 17, 3311–3318. [Google Scholar]
- Wroge, T.J.; Özkanca, Y.; Demiroglu, C.; Si, D.; Atkins, D.C.; Ghomi, R.H. Parkinson’s disease diagnosis using machine learning and voice. In Proceedings of the 2018 IEEE Signal Processing in Medicine and Biology Symposium (SPMB), IEEE, Philadelphia, PA, USA, 1 December 2018. [Google Scholar]
- Rathore, V.S.; Worring, M.; Mishra, D.K.; Joshi, A.; Maheshwari, S. Parkinson Disease Prediction Using ML Algorithm. In Emerging Trends in Expert Applications and Security; Springer: Singapore, 2019; pp. 357–363. [Google Scholar]
- Yasar, A.; Saritas, I.; Sahman, M.A.; Cinar, A.C. Classification of Parkinson Disease Data with Artificial Neural Networks. In IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2019; Volume 675. [Google Scholar]
- Oh, S.L.; Hagiwara, Y.; Raghavendra, U.; Yuvaraj, R.; Arunkumar, N.; Murugappan, M.; Acharya, U.R. A deep learning approach for Parkinson’s disease diagnosis from EEG signals. Neural. Comput. Appl. 2020, 32, 10927–10933. [Google Scholar] [CrossRef]
- Silveira-Moriyama, L.; Petrie, A.; Williams, D.R.; Evans, A.; Katzenschlager, R.; Barbosa, E.R.; Lees, A.J. The use of a color coded probability scale to interpret smell tests in sus-pected parkinsonism. Mov. Dis. 2009, 24, 1144–1153. [Google Scholar] [CrossRef] [PubMed]
- Chang, D.; Alban-Hidalgo, M.; Hsu, K. Diagnosing Parkinson’s Disease from Gait. In Stanford; NCPI: Bethesda, MD, USA, 2015. [Google Scholar]
- Ng, A. Sparse autoencoder. CS294A Lect. Notes 2011, 72, 1–19. [Google Scholar]
- Makhzani, A.; Frey, B. K-sparse autoencoders. arXiv 2013, arXiv:1312.5663. [Google Scholar]
- Ahed, F. Image Compression Using Autoencoders in Keras. Available online: https://blog.paperspace.com/autoencoder-image-compression-keras/ (accessed on 11 January 2022).
- Zhang, C.; Cheng, X.; Liu, J.; He, J.; Liu, G. Deep sparse autoencoder for feature extraction and diagnosis of locomotive adhesion status. J. Control Sci. Eng. 2018, 2018, 8676387. [Google Scholar] [CrossRef]
- Oommen, T.; Baise, L.G.; Vogel, R.M. Sampling Bias and Class Imbalance in Maximum-Likelihood Logistic Regression. Math. Geosci. 2011, 43, 99–120. [Google Scholar] [CrossRef]
- Cramer, J.S. The Origins of Logistic Regression (December 2002). Tinbergen Institute Working Paper No. 2002-119/4. Available online: https://ssrn.com/abstract=360300 (accessed on 11 January 2022).
- Ghosh, J.; Li, Y.; Mitra, R. On the Use of Cauchy Prior Distributions for Bayesian Logistic Regression. Bayesian Anal. 2018, 13, 359–383. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Techniques Used | Remarks |
|---|---|---|
| Tsanas and Athanasios, et al. [34] | Relief and local learning-based feature selection (LLBFS), minimum redundancy maximum relevance (mRMR), and least absolute shrinkage and selection operator | Features such as HNR, shimmer, and expiation of vocal fold produces 98.6% precision rate, while LLBFS produces the feature set with the lowest classification error. |
| Rouzbahani et al. [35] | Fisher’s discriminate ratio, correlation rates, and t-test. | Highest accuracy rate of 94% observed in kNN. |
| Parisi et al. [36] | Multi-layer perceptron (MLP) with custom cost function and Lagrangian support vector machine (LSVM) are used for classification. | The proposed algorithm achieves 100% of accuracy rate. |
| Abdullah et al. [37] | DNN classifier with softmax layer and stacked-auto-encoder (SAE). | Several different datasets were used to test the proposed model. DNN classifier is found to be the most suitable classifier for the early diagnosis of the disease. |
| Timothy et al. [38] | DNN classifier. Minimum redundancy maximum relevance and MFCC used to extract the features. | The study reports 85% accuracy for DNN model. |
| Mathur et al. [39] | kNN, Adaboost. | The study reports 91.28% classification accuracy for kNN and Adaboost |
| Yasar et al. [40] | Artificial neural networks (ANN). | The study reports that the proposed model achieves 94.93% accuracy in identifying diseased individuals. |
| ShuLih et al. [41] | Thirteen-layer CNN architecture was used on a dataset of EEG signals (20 normal subjects and 20 PD sufferers). | 88.25% accuracy reported for the proposed CNN architecture. |
| Laura et al. [42] | Logistic regression model on smell identification and Sniffin’ Sticks test. | Model shows 82.8% accuracy for smell identification and 85.3% accuracy for Sniffin’ Sticks test. |
| Daryl et al. [43] | SVM and random forest algorithm. | SVM shows AUC of 92.3% and an accuracy of 85.3%. A random forest achieves 76.3% AUC with 75.6% accuracy. |
| Detail | Source Information |
|---|---|
| Dataset property | UCI ML Repository |
| Dataset name | PD |
| Dataset attributes | 754 |
| Dataset records | 756 |
| Target variable | (0: control, 1: PD). Binary class problem |
| Task | Binary classification |
| Parameters | Values |
|---|---|
| No. of epochs | 200 |
| Weight decay | 20−5 |
| Optimization technique | Lbfgs |
| Sparse penalty weight | 3 |
| Sparsity | 0.1 |
| Classifiers | Classifiers with Autoencoder | ML without Dimensionality Reduction Technique |
|---|---|---|
| Logistic regression | 0.875 | 0.865 |
| Support vector machine | 0.863 | 0.842 |
| Random forest | 0.828 | 0.814 |
| Naïve Bayes | 0.836 | 0.711 |
| Classifiers | Classifiers with Autoencoder | Classifiers with RFE |
|---|---|---|
| Logistic regression | 0.875 | 0.840 |
| Support vector machine | 0.863 | 0.823 |
| Random forest | 0.828 | 0.822 |
| Naïve Bayes | 0.836 | 0.743 |
| Classifiers | Accuracy Score | Precision | Recall | F1 Score |
|---|---|---|---|---|
| Logistic regression | 0.875 | 0.918 | 0.926 | 0.922 |
| Support vector machine | 0.863 | 0.867 | 0.971 | 0.916 |
| Random forest | 0.828 | 0.823 | 0.989 | 0.898 |
| Naïve Bayes | 0.836 | 0.893 | 0.901 | 0.897 |
| 1D-CNN | 0.885 | 0.907 | 0.948 | 0.927 |
| ML Model | Accuracy | F1 Measure | ||||
|---|---|---|---|---|---|---|
| PCA | LDA | Autoencoder | PCA | LDA | Autoencoder | |
| Logistic regression | 0.737 | 0.618 | 0.875 | 0.829 | 0.707 | 0.922 |
| Support vector machine | 0.842 | 0.625 | 0.863 | 0.910 | 0.716 | 0.916 |
| Random forest | 0.816 | 0.618 | 0.828 | 0.885 | 0.704 | 0.898 |
| Naïve Bayes | 0.770 | 0.625 | 0.836 | 0.856 | 0.714 | 0.897 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mian, T.S. An Unsupervised Neural Network Feature Selection and 1D Convolution Neural Network Classification for Screening of Parkinsonism. Diagnostics 2022, 12, 1796. https://doi.org/10.3390/diagnostics12081796
Mian TS. An Unsupervised Neural Network Feature Selection and 1D Convolution Neural Network Classification for Screening of Parkinsonism. Diagnostics. 2022; 12(8):1796. https://doi.org/10.3390/diagnostics12081796
Chicago/Turabian StyleMian, Tariq Saeed. 2022. "An Unsupervised Neural Network Feature Selection and 1D Convolution Neural Network Classification for Screening of Parkinsonism" Diagnostics 12, no. 8: 1796. https://doi.org/10.3390/diagnostics12081796
APA StyleMian, T. S. (2022). An Unsupervised Neural Network Feature Selection and 1D Convolution Neural Network Classification for Screening of Parkinsonism. Diagnostics, 12(8), 1796. https://doi.org/10.3390/diagnostics12081796