1. Introduction
Recently, large AI models (LAMs) have been actively researched as they manifest impressive performance on various downstream tasks and offer a foundation to advance and foster future research in manifold AI areas, such as computer vision and natural language processing [
1,
2]. In medical and healthcare domains, LAMs are also transforming methodological designs and paradigms, and establishing new state-of-the-arts and breakthroughs in various sectors including medical informatics and decision-making [
3]. Despite the active development, advances in medical LAMs often lag behind their counterparts in general domains. To identify current discrepancies and guide the future development of medical LAMs, we select one of these LAMs in the general domain, i.e., Segment Anything Model (SAM) [
4], which is a foundational vision model recently proposed for image segmentation and has shown stunning performance on tasks ranging from edge detection to instance segmentation, and thoroughly evaluate its zero-shot segmentation performance on medical images. Although there are few studies out there that tested SAM on medical imaging, they either only focus on one imaging modality, i.e., pathology [
5], or only showcase a few qualitative segmentation samples [
6] without reporting quantitative results. To provide a comprehensive and objective evaluation of SAM on medical image segmentation, this work conducted extensive experiments on nine benchmarks using the zero-shot segmentation feature of SAM. The selected datasets contain a wide diversity of medical imaging modalities and organs.
Our key findings include:
SAM demonstrated better performance on endoscopic and dermoscopic images than other medical modalities, which is conjectured as SAM was trained with a large volume of RGB image data, and endoscopic and dermoscopic images are essentially images captured by RGB cameras. Therefore, when transferred to relevant medical images, SAM can demonstrate a relatively decent and consistent performance as it is tested on general RGB images.
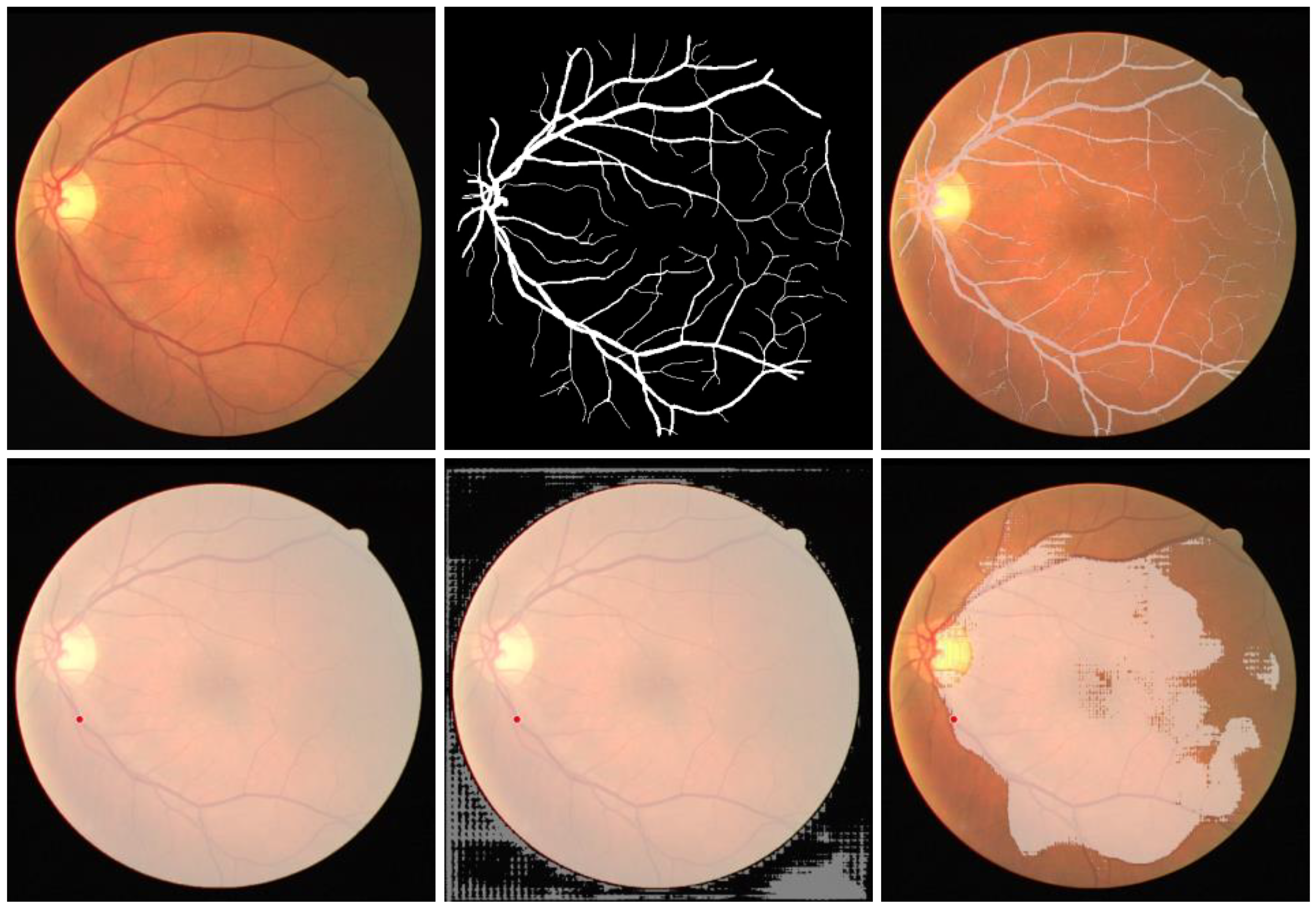
SAM failed to carry out zero-shot segmentation tasks on images that have continuous branching structures, such as blood vessels. Interestingly enough, when tested on images of tree branches, we found SAM was actually also unable to segment them in a zero-shot manner.
Compared to models specially designed for medical imaging, the zero-shot segmentation capability of SAM on medical images are decent but often inferior to those domain-specific models. Our experiments reveal that the Dice coefficients of SAM on medical benchmarks were generally lower by 0.1–0.4 compared to previous state-of-the-art (SOTA) models in medical image segmentation. In the worst case, the Dice score of the zero-shot SAM is even lower than the SOTA by 0.65.
4. Discussion
Through extensive experiments, it is found that SAM is unable to outperform models specially designed for medical imaging by simply using its zero-shot feature. It is worth noting that SAM is trained primarily on natural images and has limited access to diverse medical modalities containing pathological manifestations. As such, the medical segmentation results obtained using SAM’s zero-shot capability are actually decent and sometimes considered impressive as shown in
Figure 1. Nevertheless, given prompts in the same way, the performance of SAM varies significantly across different medical modalities. In endoscopy and dermoscopy, SAM demonstrated better performance compared to other medical modalities. In segmenting the skin lesion, if there are no clear boundaries of the lesion or if the skin itself has pigment deposition and erythematosus, the segmentation outcome of SAM is often unsatisfactory. This phenomenon resembles the concealed patterns observed in natural images, which have been previously shown to be a challenge for SAM [
43,
44]. Although the retinal fundus images are also RGB images, segmenting structural targets within the internal structure of retina is not encountered in natural scenes. This has resulted in suboptimal segmentation of optic disc and complete failure in retinal vessel segmentation of SAM using zero-shot segmentation.
Despite the SA-1B dataset used for training SAM contains 1B masks and 11M images, the multiple medical domains we tested in our study are entirely unseen domains for SAM. In particular, 3D imaging predominates as a critical medical methodology, such as MRI, CT, and OCT. The 2D slices employed for analysis are the unique aspects of medical imaging and cannot be found in natural domains. For instance, the features of OCT B-scan are layered structures stretching along the entire image width, instead of closed regions. Algorithms developed specifically for the prominent features of OCT have demonstrated excellent performance [
33,
45]. However, SAM is unable to discriminate the tissue layers in OCT images without any prior knowledge. In addition to the presence of domain differences between medical and natural images, it has been observed in
Table 3 that SAM exhibits significantly imbalanced segmentation accuracy when encountering different domain images under the same category.
To evaluate the capabilities of SAM under zero-shot settings, experiments in this study used a single prompt selection method and used the center point of the ground truth mask as the prompt for each sample. Although this approach did not fully harness the potential of SAM, it suffices to highlight the limitations of SAM in medical imaging. Recently, SAM-Adapter [
37] has been proposed for tackling complex scenario segmentation on natural image datasets including but not limited to camouflaged targets and defocus blur objects, which has shown better results than SAM and other task-specific approaches. Medical images can be regarded as a distinct category of rare scenes. Consequently, it is very likely that natural image-based large models after fine-tuning may yield excellent performance on medical imaging modalities as revealed by our preliminary results of SAM fine-tuned on retinal vessel data. Meanwhile, different prompt engineering techniques can be further explored in the future. Furthermore, it is worth investigating if training a large medical vision model from scratch using only medical data can lead to a better performance than continual-training/fine-tuning a large vision model using medical images, which has been previously pretrained on a large volume of natural image data. In addition, during the development phase of large medical AI models, it is recommended to prioritize a focus on diagnostic information and invariant features present in medical images. This can potentially mitigate issues related to domain transfer, thus enhancing the overall performance and interpretability of a large AI model.
The limitations of our testing method are also worth noting, and future works are encouraged to further explore SAM on medical segmentation. Firstly, we only used one of the three prompts provided in the official setting. For some cases, the centroid might not be inside the region of interest, other segment modes of SAM should be taken into consideration, such as the bounding box mode and automatically segment everything mode, which may provide a more comprehensive evaluation of its segmentation ability. Another limitation is that we only performed fine-tuning on retinal vessel datasets. Although the results indicate that the fine-tuned model demonstrates excellent segmentation quality compared to its zero-shot counterpart, we believe experiments on a wider range of datasets are needed to examine the segmentation performance of fine-tuned SAM, which could provide a more holistic view of its pros and cons on different medical modalities.
Nevertheless, our work is the first research work that focuses on evaluating and analyzing the performance of a recently developed large AI model, i.e., SAM on a wide range of medical image segmentation tasks both qualitatively and quantitatively, with detailed comparisons between SAM and baselines. The findings from our research help identify where SAM works and how it can be fine-tuned to provide better performance on medical imaging and applications. Our results may also help guide the future development of SAM and other medical generalist AI models on domain-specific tasks. Medical image segmentation is an important and challenging task. If the advanced large models such as SAM become highly accurate and robust on medical image segmentation, either in a zero-shot fashion or after fine-tuning, they may bring in far-reaching impact and help transform and improve medical diagnostics, treatment planning, and other healthcare applications that depend on medical imaging. This could eventually lead to great benefits to both clinicians and patients. In summary, our study lays an important groundwork for developing and applying large AI models on medical image segmentation. With continued progress, such models could positively impact healthcare by assisting with and improving critical tasks in medical diagnostics. Our current work not only highlights the potential significance and societal benefits of this line of research, but also identifies the limitations and the needs of further research before the achievement of substantial real-world impacts.
5. Conclusions
This work presents a benchmark study of SAM on a wide range of zero-shot medical image segmentation tasks. Through comprehensive experiments, we identify the challenges that SAM currently encounters in this context. Importantly, our analysis is performed on a standardized set of prompts devoid of any prior medical knowledge, covering a diverse range of imaging modalities, such as dermoscope, fundus, CT, MRI, endoscope, X-ray, endoscopic OCT and ophthalmic OCT. The provision of precise and interactive prompts, the use of specialized feature extraction methodologies tailored for medical images, and the well-designed fine-tuning strategies of large vision models originally trained on natural images can be explored in future works. Given the unique challenges associated with medical imaging, these aspects are critical for ensuring the optimal performance of generalist models in this domain. Additionally, it is crucial that large medical vision models possess cross-domain generalizability, akin to that exhibited by physicians. This is important to avoid any negative impact on diagnostic accuracy resulting from the use of new equipment and protocols. Overall, our findings highlight the needs for medical foundation models with careful consideration given to the specific challenges posed by this complex and rapidly evolving field.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}