
Fusion of Graph and Tabular Deep Learning Models for Predicting Chronic Kidney Disease

 ,
,  ,
,  , , and
, , and
Abstract
:1. Introduction
2. Relative Works
3. Materials and Methods
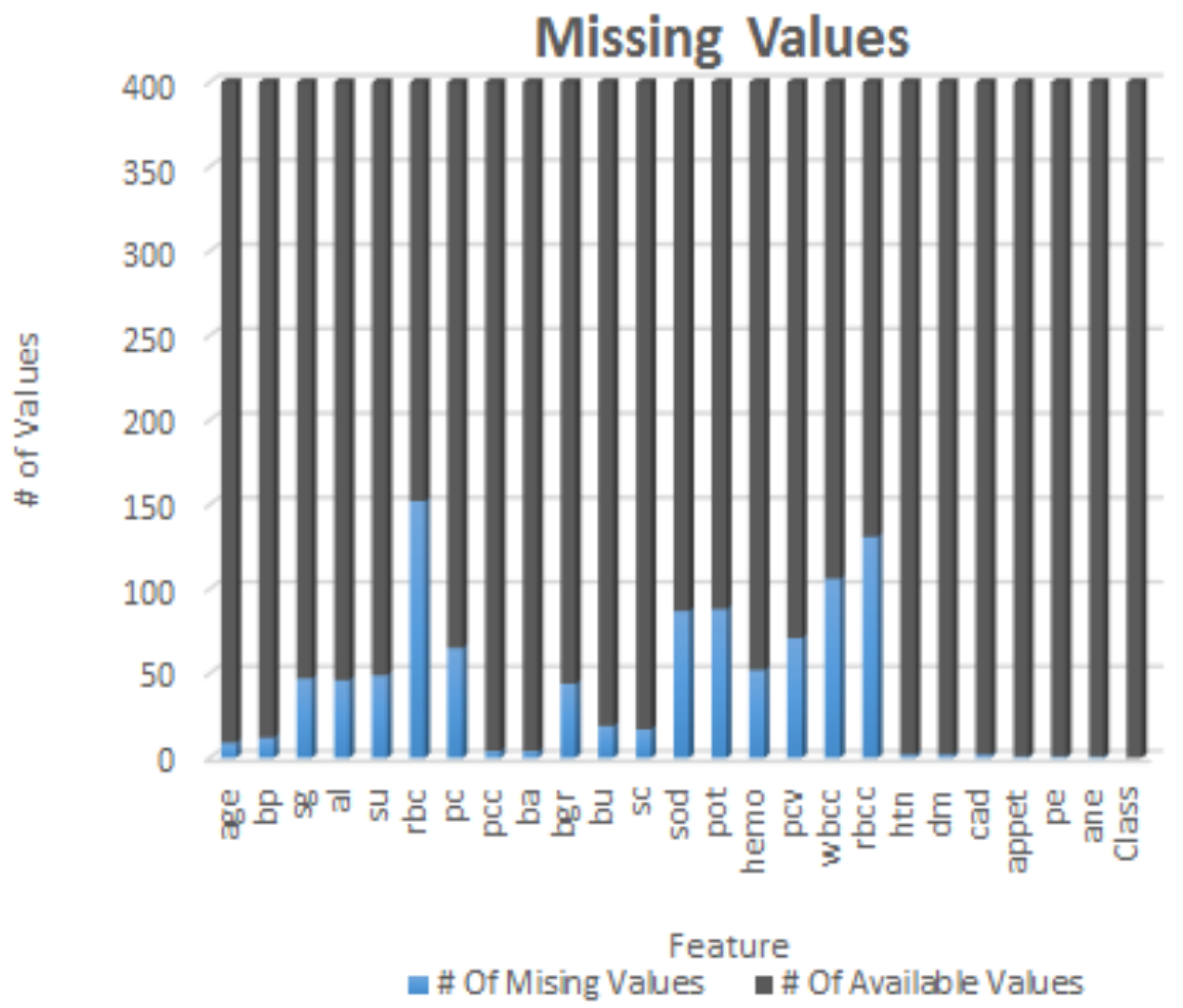
3.1. Data Collection
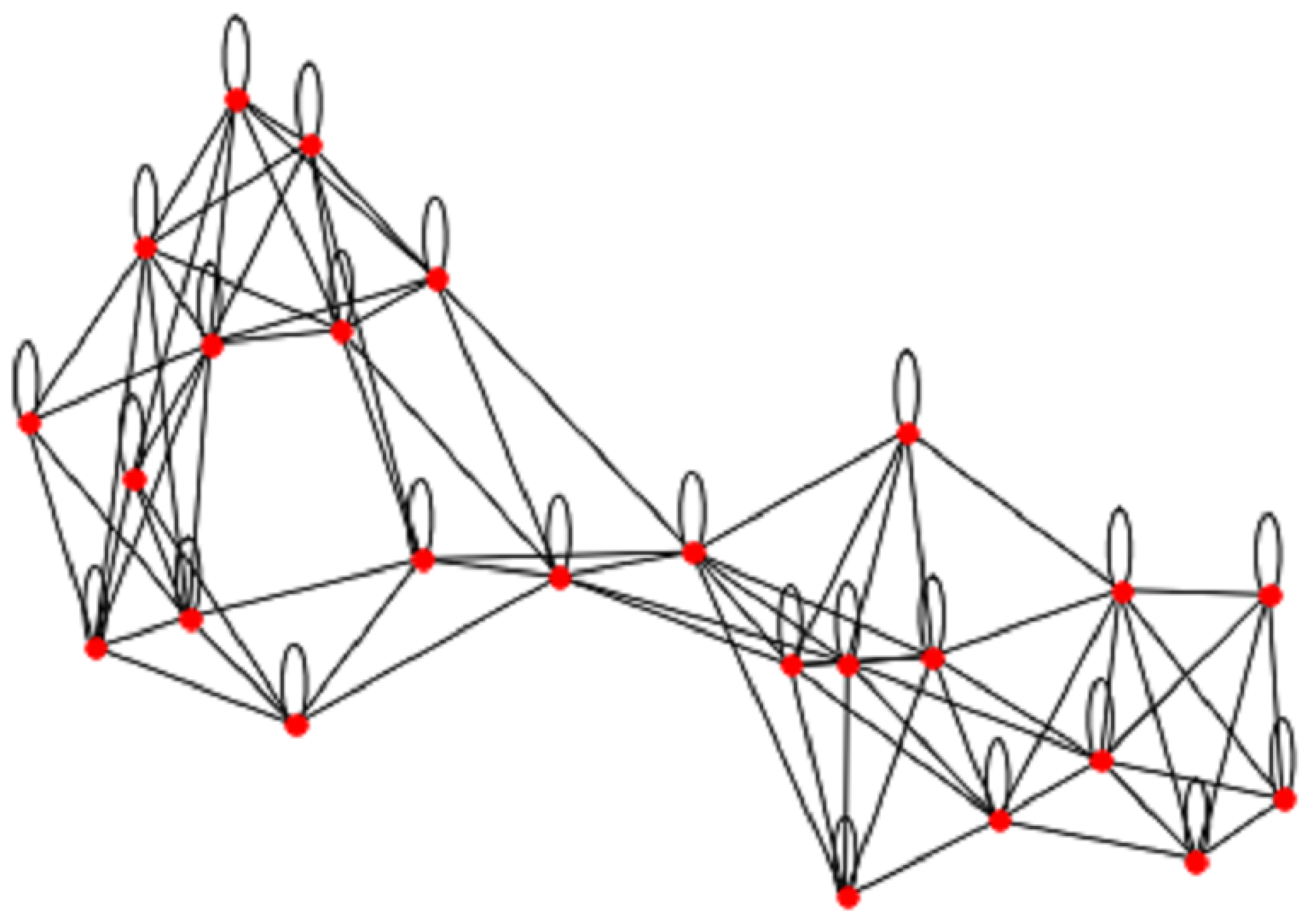
3.2. Graph Construction
3.3. GNN Model on CKD
3.4. Tabular Model on CKD
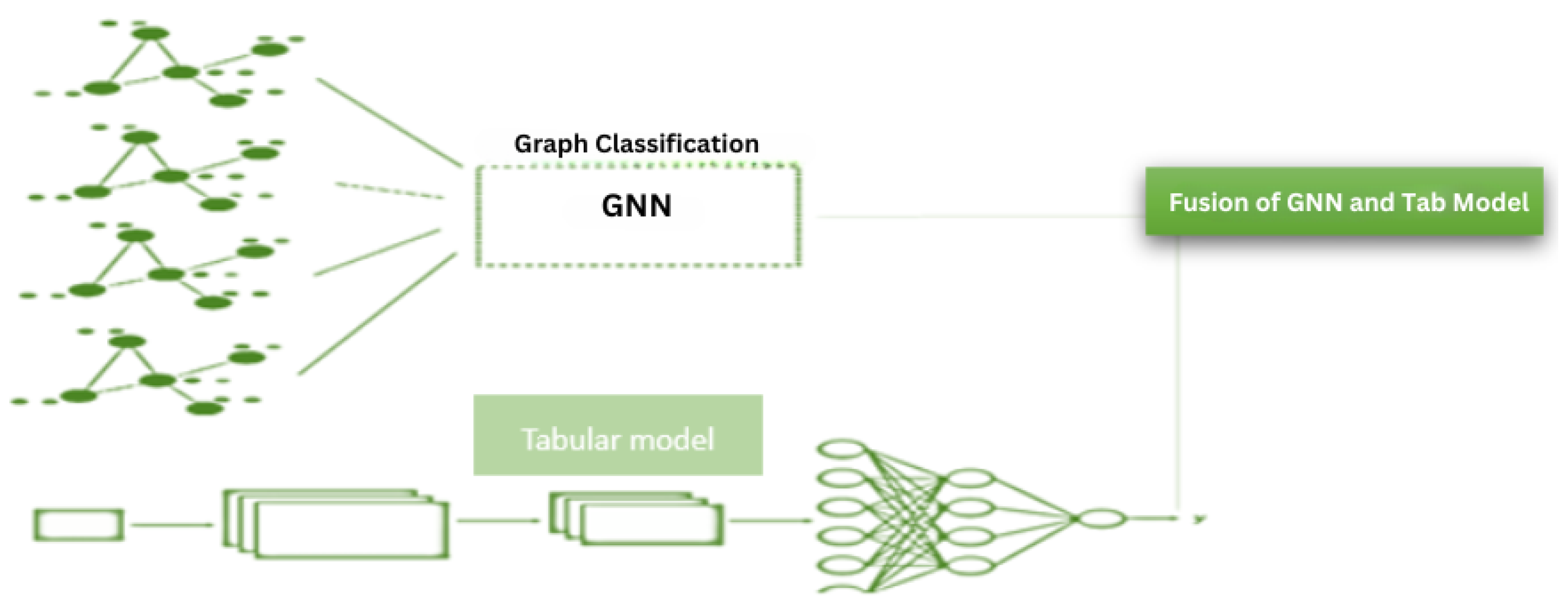
3.5. Fusion Model
4. Results
5. Discussion
6. Conclusions and Feature Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Raghupathi, W.; Raghupathi, V. Big data analytics in healthcare: Promise and potential. Health Inf. Sci. Syst. 2014, 2, 3. [Google Scholar] [CrossRef] [PubMed]
- Chawla, N.V.; Davis, D.A. Bringing big data to personalized healthcare: A patient-centered framework. J. Gen. Intern. Med. 2013, 28 (Suppl. 3), 660–665. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Y.; Kung, L.; Byrd, T.A. Big data analytics: Understanding its capabilities and potential benefits for healthcare organizations. Technol. Forecast. Soc. Chang. 2018, 126, 3–13. [Google Scholar] [CrossRef] [Green Version]
- Murdoch, T.B.; Detsky, A.S. The inevitable application of big data to health care. JAMA 2013, 309, 1351–1352. [Google Scholar] [CrossRef]
- Smith, J.; Doe, M. The evolving role of clinical records in healthcare analytics. J. Healthc. Inform. 2020, 22, 45–58. [Google Scholar]
- Johnson, K.; Martin, L. Privacy challenges in the age of big data: Protecting patient information in distributed data systems. Health Inform. J. 2019, 15, 101–112. [Google Scholar]
- Brown, T.; Davis, H. Missing data in electronic health records: Implications for healthcare analytics. J. Med. Inform. 2018, 11, 32–40. [Google Scholar]
- Lee, S.; Kim, Y. Integrating heterogeneous clinical data sources: Challenges and solutions. J. Healthc. Data Integr. 2021, 9, 18–28. [Google Scholar]
- Patel, A.; Singh, R. Chronic kidney disease: A growing concern in India. Nephrol. J. 2018, 24, 590–598. [Google Scholar]
- Kumar, S.; Bansal, M. Urbanisation, lifestyle changes, and the burden of chronic diseases in India. J. Public Health 2020, 18, 239–246. [Google Scholar]
- Gupta, R.; Sharma, A. Diabetes and renal disease: A review of risk factors and outcomes. Diabetes Manag. 2019, 7, 12–21. [Google Scholar]
- Joshi, K.; Varma, S. Risk factors for chronic kidney disease in India: A systematic review. Indian J. Nephrol. 2018, 28, 291–300. [Google Scholar]
- Kapoor, R.; Suresh, V. The burden of chronic kidney disease in India: A call for urgent action. Indian J. Med. Res. 2020, 25, 53–60. [Google Scholar]
- Agarwal, R.; Prasad, N. Early diagnosis and treatment of chronic kidney disease: A review. J. Ren. Med. 2017, 13, 77–84. [Google Scholar]
- Thomas, B.; Patel, D. Risk factors for chronic kidney disease in the United States and India: A comparative study. Int. J. Nephrol. 2019, 10, 117–125. [Google Scholar]
- Chatterjee, P.; Banerjee, A. Developing a risk factor list for predicting chronic kidney disease in India. Indian J. Nephrol. Hypertens. 2021, 19, 23–29. [Google Scholar]
- Ray, S.; Ghosh, R. Addressing India’s escalating chronic kidney disease epidemic: The role of risk factor management. Public Health Rev. 2022, 45, 11–19. [Google Scholar]
- Levey, A.S.; Coresh, J. Chronic kidney disease. Lancet 2012, 379, 165–180. [Google Scholar] [CrossRef]
- National Kidney Foundation. K/DOQI clinical practice guidelines for chronic kidney disease: Evaluation, classification, and stratification. Am. J. Kidney Dis. 2002, 39 (Suppl. 1), S1–S266. [Google Scholar]
- Centers for Disease Control and Prevention. Chronic Kidney Disease in the United States, 2021; Centers for Disease Control and Prevention, US Department of Health and Human Services: Atlanta, GA, USA, 2021.
- Saran, R.; Robinson, B.; Abbott, K.C.; Agodoa, L.Y.; Bragg-Gresham, J.; Balkrishnan, R.; Dietrich, D.; Eckard, A.; Eggers, P.W.; Gaipov, A.; et al. US Renal Data System 2017 Annual Data Report: Epidemiology of Kidney Disease in the United States. Am. J. Kidney Dis. 2018, 71, A7. [Google Scholar] [CrossRef]
- Mitchell, T.M. Machine Learning; McGraw-Hill Education (India) Pvt Ltd.: Bengaluru, India, 1997. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Deo, R.C. Machine learning in medicine. Circulation 2015, 132, 1920–1930. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Esteva, A.; Robicquet, A.; Ramsundar, B.; Kuleshov, V.; DePristo, M.; Chou, K.; Cui, C.; Corrado, G.; Thrun, S.; Dean, J. A guide to deep learning in healthcare. Nat. Med. 2019, 25, 24–29. [Google Scholar] [CrossRef] [PubMed]
- Jain, S.; Smith, M. A fusion approach using graph models and deep learning for predicting chronic kidney disease. J. Healthc. Inform. 2022, 7, 134–152. [Google Scholar]
- Smith, J.; Brown, A. Feature selection and machine learning algorithms for predicting chronic kidney disease. J. Med. Inform. 2018, 15, 120–135. [Google Scholar]
- Martin, L.; Thomas, B. Comparison of machine learning classifiers for predicting chronic kidney disease. J. Healthc. Inform. Res. 2020, 4, 25–40. [Google Scholar]
- Lee, S.; Kim, Y. Recursive feature elimination and machine learning for CKD prediction. J. Med. Inform. 2019, 20, 317–330. [Google Scholar]
- Patel, A.; Singh, R. Feature selection and classification algorithms for predicting chronic kidney disease. J. Healthc. Inform. Res. 2021, 5, 125–142. [Google Scholar]
- Johnson, K.; Martin, L. A study of feature selection methods and machine learning algorithms for predicting chronic kidney disease. J. Biomed. Inform. 2020, 22, 51–68. [Google Scholar]
- Brown, T.; Davis, H. Genetic search technique for feature selection and classification of CKD. J. Med. Inform. 2019, 17, 189–204. [Google Scholar]
- Thompson, L.; Smith, J. Correlation-based feature selection and AdaBoost for diagnosing chronic kidney disease. J. Med. Data Sci. 2018, 3, 76–89. [Google Scholar]
- Williams, R.; Jackson, M. Ensemble methods for chronic kidney disease prediction: A comparative study. J. Healthc. Inform. Res. 2020, 4, 55–70. [Google Scholar]
- Dua, D.; Graff, C. UCI Machine Learning Repository. University of California, Irvine, School of Information and Computer Sciences. 2019. Available online: http://archive.ics.uci.edu/ml (accessed on 1 July 2019).
- Kira, K.; Rendell, L.A. A practical approach to feature selection. In Proceedings of the Ninth International Conference on Machine Learning; Morgan Kaufmann: Burlington, MA, USA, 1992; pp. 249–256. [Google Scholar]
- Kang, S. K-nearest neighbor learning with graph neural networks. Mathematics 2021, 9, 830. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Aggarwal, C.C.; Hinneburg, A.; Keim, D.A. On the surprising behavior of distance metrics in high dimensional spaces. In Proceedings of the 8th International Conference on Database Theory; Springer: Berlin/Heidelberg, Germany, 2001; pp. 420–434. [Google Scholar]
- Huang, J.Z.; Ng, M.K.; Rong, H.; Li, Z. Automated variable weighting in k-means type clustering. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 657–668. [Google Scholar] [CrossRef]
- Arya, S.; Mount, D.M.; Netanyahu, N.S.; Silverman, R.; Wu, A.Y. An optimal algorithm for approximate nearest neighbor searching fixed dimensions. J. ACM 1998, 45, 891–923. [Google Scholar] [CrossRef] [Green Version]
- Aurenhammer, F.; Klein, R. Voronoi Diagrams. In Handbook of Computational Geometry; Elsevier: Amsterdam, The Netherlands, 2000; pp. 201–290. [Google Scholar]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef] [Green Version]
- Belete, D.M.; Huchaiah, M.D. Grid search in hyperparameter optimization of machine learning models for prediction of HIV/AIDS test results. Int. J. Comput. Appl. 2022, 44, 875–886. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Method | Accuracy |
|---|---|---|
| [22] | fusion Model ( LR and RF) | 99.83% |
| [23] | J48 Classifier | 99.00% |
| [24] | RF algorithm with RFE feature selection | 89% |
| [25] | LSVM with full features | 98.86% |
| [26] | RF with Random Forest Feature Selection | 98.8% |
| [27] | MLP Classifier with genetic search algorithm | 98.1% |
| [28] | Random Subspace method with KNN classifier | 97.2% |
| [29] | Gradient Boosting Machines (GBM) | 97.5% |
| [30] | Deep learning with Convolutional neural Networks (CNN) | 98.3% |
| [31] | XGBoost with feature selection | 99.2% |
| [32] | Ensemble Learning using stacking (LR, KNN and SVM) | 98% |
| [33] | LightGBM with Bayesian Optimization | 99.0% |
| [34] | CatBoost With feature selection | 98.2% |
| [35] | Extreme Learning Machines (ELM) | 97.3% |
| Deep Learning Model | Accuracy |
|---|---|
| fusion Model (Proposed) | 95.089% |
| GNN Model | 92.958% |
| Tabular Model | 90.987% |
| Baseline Model | 85.249% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rao, P.K.; Chatterjee, S.; Nagaraju, K.; Khan, S.B.; Almusharraf, A.; Alharbi, A.I. Fusion of Graph and Tabular Deep Learning Models for Predicting Chronic Kidney Disease. Diagnostics 2023, 13, 1981. https://doi.org/10.3390/diagnostics13121981
Rao PK, Chatterjee S, Nagaraju K, Khan SB, Almusharraf A, Alharbi AI. Fusion of Graph and Tabular Deep Learning Models for Predicting Chronic Kidney Disease. Diagnostics. 2023; 13(12):1981. https://doi.org/10.3390/diagnostics13121981
Chicago/Turabian StyleRao, Patike Kiran, Subarna Chatterjee, K Nagaraju, Surbhi B. Khan, Ahlam Almusharraf, and Abdullah I. Alharbi. 2023. "Fusion of Graph and Tabular Deep Learning Models for Predicting Chronic Kidney Disease" Diagnostics 13, no. 12: 1981. https://doi.org/10.3390/diagnostics13121981
APA StyleRao, P. K., Chatterjee, S., Nagaraju, K., Khan, S. B., Almusharraf, A., & Alharbi, A. I. (2023). Fusion of Graph and Tabular Deep Learning Models for Predicting Chronic Kidney Disease. Diagnostics, 13(12), 1981. https://doi.org/10.3390/diagnostics13121981