
Machine Learning Algorithm Predicts Mortality Risk in Intensive Care Unit for Patients with Traumatic Brain Injury

 , and
, and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Ethics
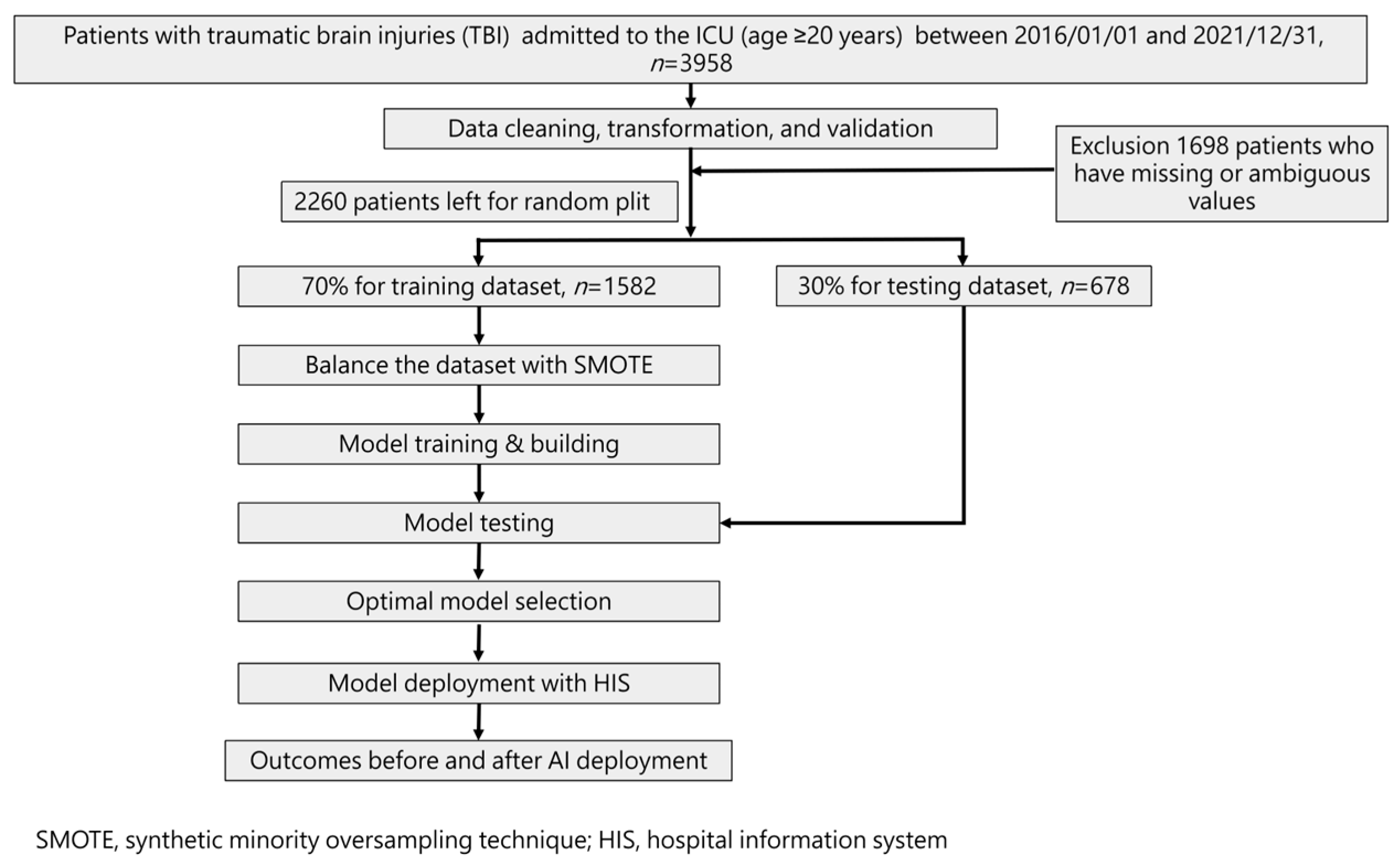
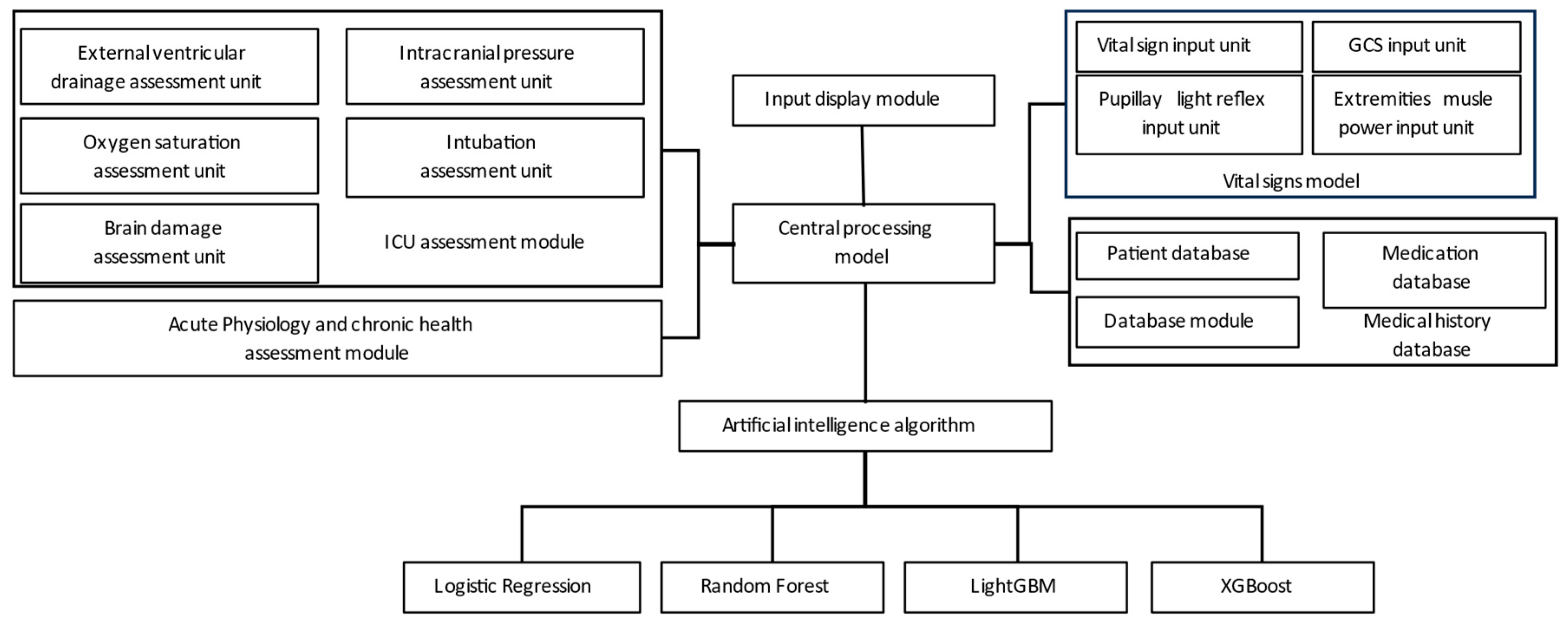
2.2. Flow Chart and AI Device of Current Study
2.3. Patient Selection
2.4. Feature Selection and Model Building
2.5. Model Performance Measurement
3. Results
3.1. Characteristics and Clinical Presentations of Individuals with Traumatic Brain Injury
3.2. The Correlation between Factors and Mortality (Spearman Correlation Coefficient)
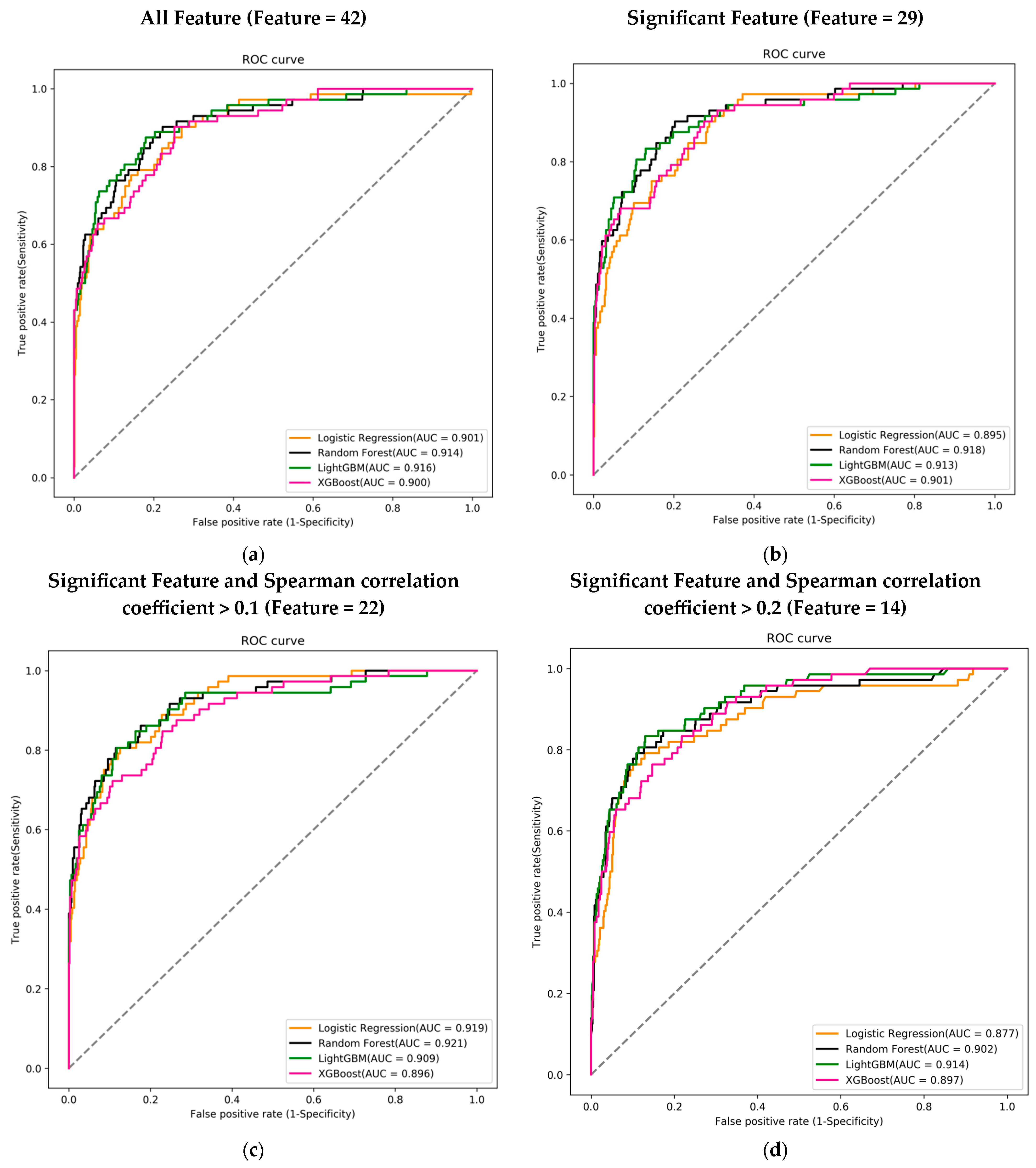
3.3. Predictive Models with Different Features Combinations
3.4. Comparing the Best-Performing Model with Traditional ICU Assessment Tools in Different Feature Combinations
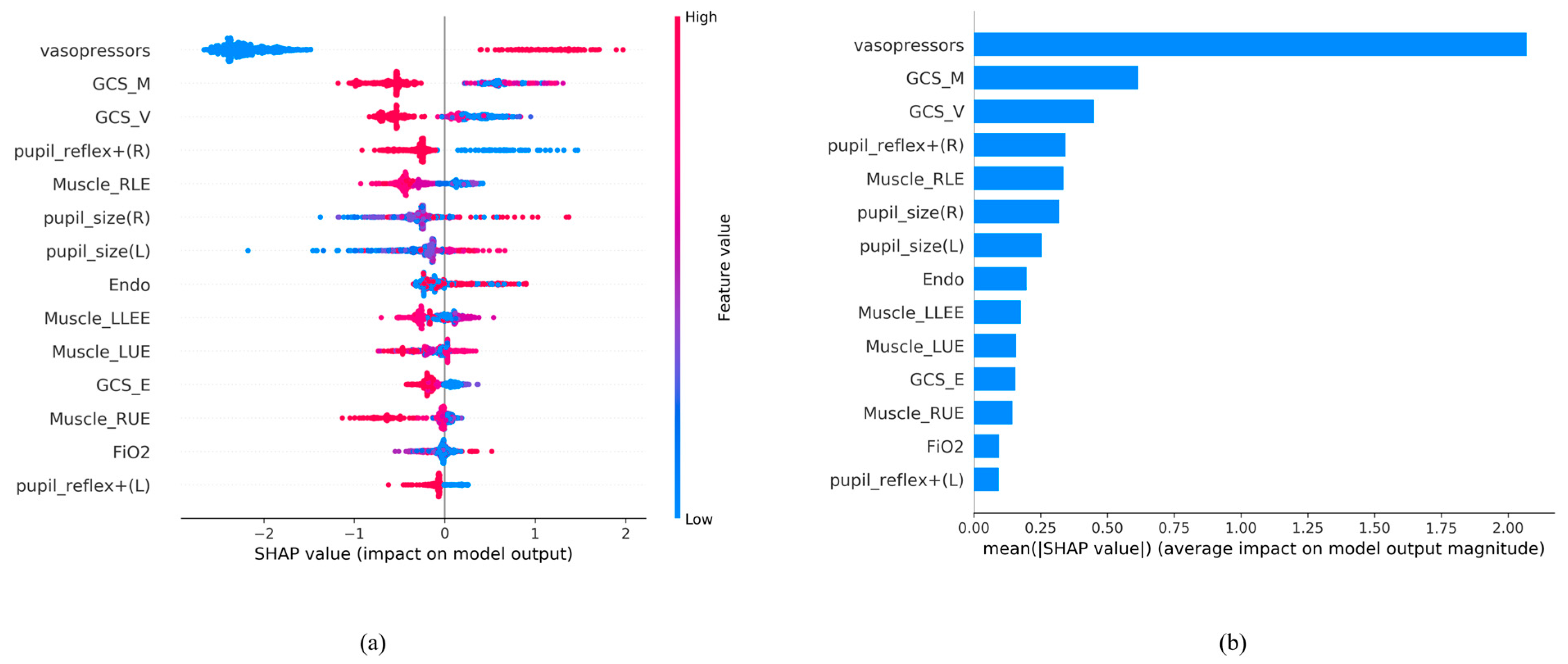
3.5. Feature Importance of AI Algorithm LightGBM Using 14 Feature Variables
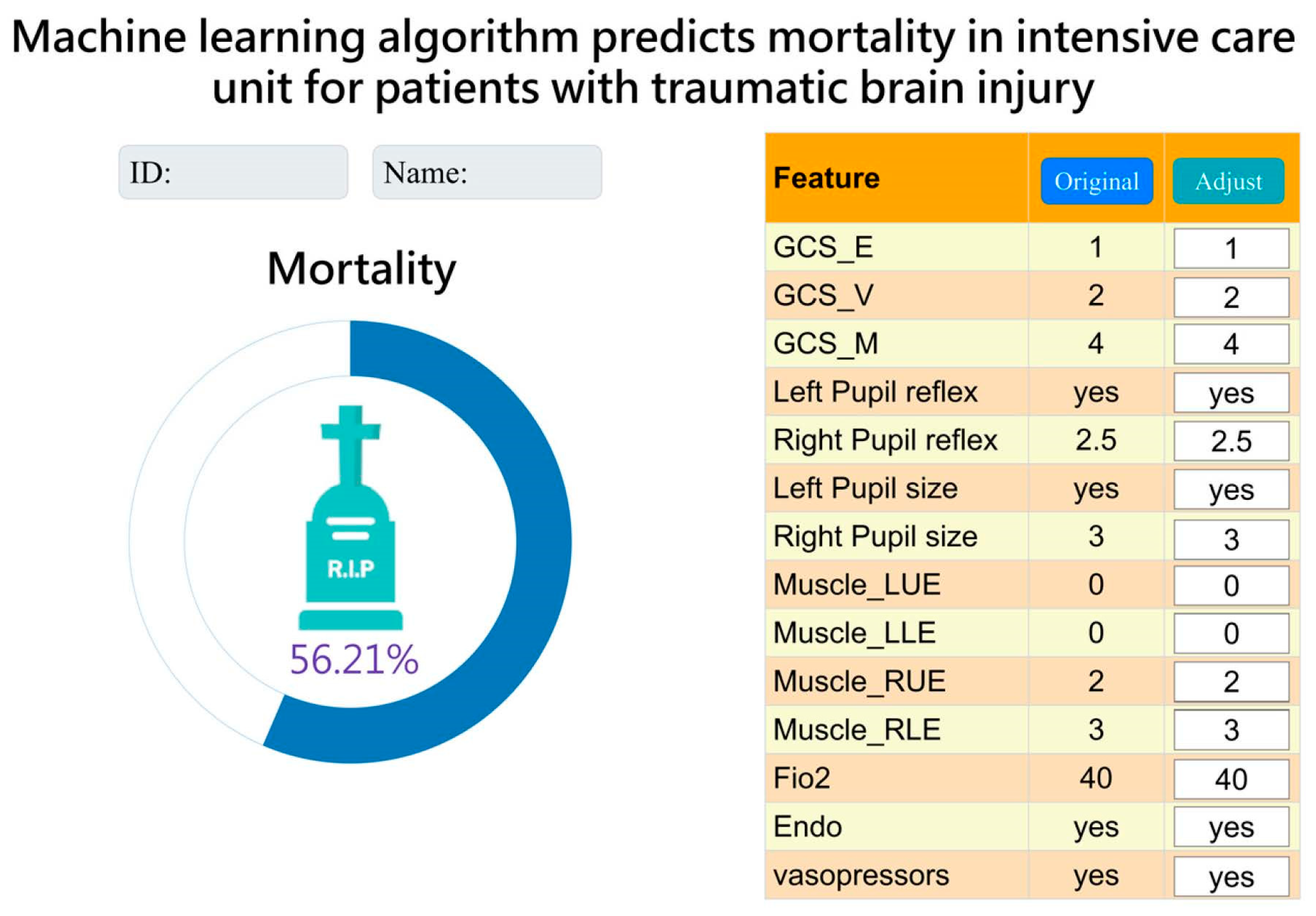
3.6. Integration and Application of AI with Clinical Systems
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- GBD 2016 Traumatic Brain Injury and Spinal Cord Injury Collaborators. Global, regional, and national burden of traumatic brain injury and spinal cord injury, 1990–2016: A systematic analysis for the Global Burden of Disease Study 2016. Lancet Neurol. 2019, 18, 56–87, Erratum in Lancet Neurol. 2021, 20, e7. [Google Scholar]
- Majdan, M.; Plancikova, D.; Brazinova, A.; Rusnak, M.; Nieboer, D.; Feigin, V.L.; Maas, A. Epidemiology of traumatic brain injuries in Europe: A cross-sectional analysis. Lancet Public Health 2016, 1, e76–e83. [Google Scholar] [CrossRef] [PubMed]
- Taylor, C.A.; Bell, J.M.; Breiding, M.J.; Xu, L. Traumatic Brain Injury-Related Emergency Department Visits, Hospitalizations, and Deaths—United States, 2007 and 2013. MMWR Surveill. Summ. 2017, 66, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Prasanthi, P.; Adnan, A.H. The burden of traumatic brain injury in asia: A call for research. Pak. J. Neurol. Sci. 2009, 4, 27–32. [Google Scholar]
- Hukkelhoven, C.W.; Steyerberg, E.W.; Rampen, A.J.; Farace, E.; Habbema, J.D.F.; Marshall, L.F.; Murray, G.D.; Maas, A.I.R. Patient age and outcome following severe traumatic brain injury: An analysis of 5600 patients. J. Neurosurg. 2003, 99, 666–673. [Google Scholar] [CrossRef]
- Ozyurt, E.; Goksu, E.; Cengiz, M.; Yilmaz, M.; Ramazanoglu, A. Retrospective Analysis of Prognostic Factors of Severe Traumatic Brain Injury in a University Hospital in Turkey. Turk. Neurosurg. 2015, 25, 877–882. [Google Scholar]
- Okidi, R.; Ogwang, D.M.; Okello, T.R.; Ezati, D.; Kyegombe, W.; Nyeko, D.; Scolding, N.J. Factors affecting mortality after traumatic brain injury in a resource-poor setting. BJS Open 2020, 4, 320–325. [Google Scholar] [CrossRef]
- Maas, A.I.; Steyerberg, E.W.; Butcher, I.; Dammers, R.; Lu, J.; Marmarou, A.; Mushkudiani, N.A.; McHugh, G.S.; Murray, G.D. Prognostic value of computerized tomography scan characteristics in traumatic brain injury: Results from the IMPACT study. J. Neurotrauma 2007, 24, 303–314. [Google Scholar] [CrossRef]
- Perel, P.; Edwards, P.; Wentz, R.; Roberts, I. Systematic review of prognostic models in traumatic brain injury. BMC Med. Inform. Decis. Mak. 2006, 6, 38. [Google Scholar] [CrossRef]
- Carter, E.L.; Hutchinson, P.J.; Kolias, A.G.; Menon, D.K. Predicting the outcome for individual patients with traumatic brain injury: A case-based review. Br. J. Neurosurg. 2016, 30, 227–232. [Google Scholar] [CrossRef]
- Vincent, J.L.; Moreno, R.; Takala, J.; Willatts, S.; De Mendonça, A.; Bruining, H.; Reinhart, C.K.; Suter, P.M.; Thijs, L.G. The SOFA (Sepsis-related Organ Failure Assessment) score to describe organ dysfunction/failure. On behalf of the Working Group on Sepsis-Related Problems of the European Society of Intensive Care Medicine. Intensive Care Med. 1996, 22, 707–710. [Google Scholar] [CrossRef] [PubMed]
- Singer, M.; Deutschman, C.S.; Seymour, C.W.; Shankar-Hari, M.; Annane, D.; Bauer, M.; Bellomo, R.; Bernard, G.R.; Chiche, J.-D.; Coopersmith, C.M.; et al. The Third International Consensus Definitions for Sepsis and Septic Shock (Sepsis-3). JAMA 2016, 315, 801–810. [Google Scholar] [CrossRef] [PubMed]
- Knaus, W.A.; Draper, E.A.; Wagner, D.P.; Zimmerman, J.E. APACHE II: A severity of disease classification system. Crit. Care Med. 1985, 13, 818–829. [Google Scholar] [CrossRef] [PubMed]
- Raj, R.; Skrifvars, M.; Bendel, S.; Selander, T.; Kivisaari, R.; Siironen, J.; Reinikainen, M. Predicting six-month mortality of patients with traumatic brain injury: Usefulness of common intensive care severity scores. Crit. Care 2014, 18, R60. [Google Scholar] [CrossRef]
- Ley, C.; Martin, R.K.; Pareek, A.; Groll, A.; Seil, R.; Tischer, T. Machine learning and conventional statistics: Making sense of the differences. Knee Surg. Sports Traumatol. Arthrosc. 2022, 30, 753–757. [Google Scholar] [CrossRef]
- Loh, H.W.; Ooi, C.P.; Seoni, S.; Barua, P.D.; Molinari, F.; Acharya, U.R. Application of Explainable Artificial Intelligence for Healthcare: A Systematic Review of the Last Decade (2011–2022). Comput. Methods Programs Biomed. 2022, 226, 107161. [Google Scholar] [CrossRef]
- Courville, E.; Kazim, S.F.; Vellek, J.; Tarawneh, O.; Stack, J.; Roster, K.; Roy, J.; Schmidt, M.; Bowers, C. Machine learning algorithms for predicting outcomes of traumatic brain injury: A systematic review and meta-analysis. Surg. Neurol. Int. 2023, 14, 262. [Google Scholar] [CrossRef]
- Abujaber, A.; Fadlalla, A.; Gammoh, D.; Abdelrahman, H.; Mollazehi, M.; El-Menyar, A. Prediction of in-hospital mortality in patients with post traumatic brain injury using National Trauma Registry and Machine Learning Approach. Scand. J. Trauma Resusc. Emerg. Med. 2020, 28, 44. [Google Scholar] [CrossRef]
- Hsu, S.D.; Chao, E.; Chen, S.J.; Hueng, D.Y.; Lan, H.Y.; Chiang, H.H. Machine Learning Algorithms to Predict In-Hospital Mortality in Patients with Traumatic Brain Injury. J. Pers. Med. 2021, 11, 1144. [Google Scholar] [CrossRef]
- Wang, R.; Wang, L.; Zhang, J.; He, M.; Xu, J. XGBoost Machine Learning Algorism Performed Better Than Regression Models in Predicting Mortality of Moderate-to-Severe Traumatic Brain Injury. World Neurosurg. 2022, 163, e617–e622. [Google Scholar] [CrossRef]
- Wu, X.; Sun, Y.; Xu, X.; Steyerberg, E.W.; Helmrich, I.R.A.R.; Lecky, F.; Guo, J.; Li, X.; Feng, J.; Mao, Q.; et al. Mortality Prediction in Severe Traumatic Brain Injury Using Traditional and Machine Learning Algorithms. J. Neurotrauma 2023, 40, 1366–1375. [Google Scholar] [CrossRef] [PubMed]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Hosmer, D.W.; Lemeshow, S., Jr.; Sturdivant, R.X. Applied Logistic Regression; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2013. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.F.; Chen, W.; Ma, W.D.; Ye, Q.; Liu, T.Y. LightGBM: A highly efficient gradient boosting decision tree. In Proceedings of the 31st Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Long Beach, CA, USA, 6–10 August 2016; pp. 785–794. [Google Scholar]
- Parikh, R.; Mathai, A.; Parikh, S.; Sekhar, G.C.; Thomas, R. Understanding and using sensitivity, specificity and predictive values. Indian J. Ophthalmol. 2008, 56, 45–50. [Google Scholar] [CrossRef] [PubMed]
- Patorno, E.; Najafzadeh, M.; Pawar, A.; Franklin, J.M.; Déruaz-Luyet, A.; Brodovicz, K.G.; Ortiz, A.J.S.; Bessette, L.G.; Kulldorff, M.; Schneeweiss, S. The EMPagliflozin compaRative effectIveness and SafEty (EMPRISE) study programme: Design and exposure accrual for an evaluation of empagliflozin in routine clinical care. Endocrinol. Diabetes Metab. 2019, 3, e00103. [Google Scholar] [CrossRef] [PubMed]
- Swets, J.A. Measuring the accuracy of diagnostic systems. Science 1988, 240, 1285–1293. [Google Scholar] [CrossRef]
- Jin, H.; Ling, C.X. Using AUC and accuracy in evaluating learning algorithms. Knowl. Data Eng. 2005, 17, 299–310. [Google Scholar]
- Hasraddin, G.; Eldayag, M. Predicting the changes in the WTI crude oil price dynamics using machine learning models. Resour. Policy 2022, 77, 102664. [Google Scholar]
- Inui, A.; Nishimoto, H.; Mifune, Y.; Yoshikawa, T.; Shinohara, I.; Furukawa, T.; Kato, T.; Tanaka, S.; Kusunose, M.; Kuroda, R. Screening for Osteoporosis from Blood Test Data in Elderly Women Using a Machine Learning Approach. Bioengineering 2023, 10, 277. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 4–9 December 2017. [Google Scholar]
- Breslow, M.J.; Badawi, O. Severity scoring in the critically ill: Part 1—Interpretation and accuracy of outcome prediction scoring systems. Chest 2012, 141, 245–252. [Google Scholar] [CrossRef]
- Lambden, S.; Laterre, P.F.; Levy, M.M.; Francois, B. The SOFA Score—Development, Utility and Challenges of Accurate Assessment in Clinical Trials. Crit. Care 2019, 23, 374. [Google Scholar] [CrossRef] [PubMed]
- Pinto, V.L.; Tadi, P.; Adeyinka, A. Increased Intracranial Pressure; [Updated 2022 Aug 1]; StatPearls Publishing: St. Petersburg, FL, USA, 2023. [Google Scholar]
- Saika, A.; Bansal, S.; Philip, M.; Devi, B.I.; Shukla, D.P. Prognostic value of FOUR and GCS scores in determining mortality in patients with traumatic brain injury. Acta Neurochir. 2015, 157, 1323–1328. [Google Scholar] [CrossRef] [PubMed]
- Huang, J.F.; Tsai, Y.C.; Rau, C.S.; Hsu, S.Y.; Chien, P.C.; Hsieh, H.Y.; Hsieh, C.H. Systolic blood pressure lower than the heart rate indicates a poor outcome in patients with severe isolated traumatic brain injury: A cross-sectional study. Int. J. Surg. 2019, 61, 48–52. [Google Scholar] [CrossRef] [PubMed]
- Steyerberg, E.W.; Mushkudiani, N.; Perel, P.; Butcher, I.; Lu, J.; McHugh, G.S.; Murray, G.D.; Marmarou, A.; Roberts, I.; Habbema, J.D.F.; et al. Predicting outcome after traumatic brain injury: Development and international validation of prognostic scores based on admission characteristics. PLoS Med. 2008, 5, 1251–1261. [Google Scholar] [CrossRef] [PubMed]
- MRC CRASH Trial Collaborators; Perel, P.; Arango, M.; Clayton, T.; Edwards, P.; Komolafe, E.; Poccock, S.; Roberts, I.; Shakur, H.; Steyerberg, E.; et al. Predicting outcome after traumatic brain injury: Practical prognostic models based on large cohort of international patients. BMJ 2008, 336, 425–429. [Google Scholar]
- Han, J.; King, N.; Neilson, S.; Gandhi, M.; Ng, I. External validation of the CRASH and IMPACT prognostic models in severe traumatic brain injury. J. Neurotrauma 2014, 31, 1146–1152. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Overall n = 2260 | Non-Mortality n = 2020 | Mortality n = 240 | p-Value |
|---|---|---|---|---|
| Female, n (%) | 813 (35.97) | 735 (36.39) | 78 (32.50) | 0.265 |
| male, n (%) | 1447 (64.03) | 1285 (63.61) | 162 (67.50) | |
| Age, mean (SD) | 63.89 (17.74) | 63.26 (17.76) | 69.22 (16.65) | <0.001 |
| height, mean (SD) | 162.74 (11.24) | 162.75 (10.95) | 162.60 (13.43) | 0.862 |
| weight, mean (SD) | 63.00 (14.16) | 63.24 (14.23) | 61.00 (13.42) | 0.016 |
| Systolic blood pressure (SBP), mean (SD) | 142.36 (29.41) | 143.33 (28.40) | 134.22 (35.86) | <0.001 |
| Diastolic blood pressure (DBP), mean (SD) | 78.02 (17.02) | 78.72 (16.36) | 72.13 (20.90) | <0.001 |
| Mean Arterial Pressure (MAP), mean (SD) | 100.04 (20.67) | 100.99 (19.86) | 92.06 (25.24) | <0.001 |
| Body temperature (BT), mean (SD) | 36.55 (0.63) | 36.57 (0.56) | 36.39 (1.01) | 0.005 |
| pulse, mean (SD) | 86.48 (16.95) | 85.93 (15.90) | 91.10 (23.57) | 0.001 |
| Respiratory rate (RR), mean (SD) | 17.67 (4.06) | 17.73 (3.95) | 17.10 (4.83) | 0.054 |
| Glasgow Coma Scale_eye opening (GCS_E), mean (SD) | 3.13 (1.26) | 3.31 (1.15) | 1.69 (1.18) | <0.001 |
| Glasgow Coma Scale_verbal response (GCS_V), mean (SD) | 3.52 (1.75) | 3.75 (1.66) | 1.65 (1.30) | <0.001 |
| Glasgow Coma Scale_motor response (GCS_M), mean (SD) | 4.99 (1.77) | 5.21 (1.60) | 3.08 (1.97) | <0.001 |
| Glasgow Coma Scale (GCS), mean (SD) | 11.64 (4.48) | 12.27 (4.11) | 6.41 (4.03) | <0.001 |
| Left Pupil | ||||
| Pupil reflex (−), n (%) | 230 (10.18) | 104 (5.15) | 126 (52.50) | <0.001 |
| Pupil reflex (+), n (%) | 2030 (89.82) | 1916 (94.85) | 114 (47.50) | |
| Pupil size (L), mean (SD) | 3.23 (0.99) | 3.10 (0.77) | 4.29 (1.70) | <0.001 |
| Right Pupil | ||||
| Pupil reflex (−), n (%) | 231 (10.22) | 103 (5.10) | 128 (53.33) | <0.001 |
| Pupil reflex (+), n (%) | 2029 (89.78) | 1917 (94.90) | 112 (46.67) | |
| Pupil size (R), mean (SD) | 3.22 (0.99) | 3.09 (0.76) | 4.34 (1.74) | <0.001 |
| Muscle power_left upper extremity (Muscle_LUE), mean (SD) | 3.03 (1.66) | 3.24 (1.54) | 1.30 (1.59) | <0.001 |
| Muscle power_left lower extremity (Muscle_LLEE), mean (SD) | 2.93 (1.67) | 3.13 (1.58) | 1.24 (1.48) | <0.001 |
| Muscle power_right upper extremity (Muscle_RUE), mean (SD) | 3.04 (1.66) | 3.25 (1.54) | 1.30 (1.57) | <0.001 |
| Muscle power_right lower extremity (Muscle_RLE), mean (SD) | 2.94 (1.67) | 3.14 (1.58) | 1.22 (1.46) | <0.001 |
| Inspired fraction of oxygen (FiO2), mean (SD) | 27.80 (11.52) | 26.49 (9.08) | 38.84 (20.50) | <0.001 |
| APACHE II, mean (SD) | 12.92 (7.44) | 11.71 (6.44) | 23.10 (7.49) | <0.001 |
| Sequential Organ Failure Assessment (SOFA score), mean (SD) | 3.10 (2.72) | 2.64 (2.26) | 6.94 (3.17) | <0.001 |
| Endotracheal tube (Endo) | ||||
| No, n (%) | 1283 (56.77) | 1229 (60.84) | 54 (22.50) | <0.001 |
| Yes, n (%) | 977 (43.23) | 791 (39.16) | 186 (77.50) | |
| External ventricular drain (EVD) | ||||
| No, n (%) | 2045 (90.49) | 1823 (90.25) | 222 (92.50) | 0.313 |
| Yes, n (%) | 215 (9.51) | 197 (9.75) | 18 (7.50) | |
| Intracranial pressure (ICP), n (%) | ||||
| No, n (%) | 2025 (89.60) | 1835 (90.84) | 190 (79.17) | <0.001 |
| Yes, n (%) | 235 (10.40) | 185 (9.16) | 50 (20.83) | |
| Cerebral perfusion pressure (CPP), n (%) | ||||
| No, n (%) | 2025 (89.60) | 1835 (90.84) | 190 (79.17) | <0.001 |
| Yes, n (%) | 235 (10.40) | 185 (9.16) | 50 (20.83) | |
| surgery, n (%) | 310 (13.72) | 247 (12.23) | 63 (26.25) | <0.001 |
| Drugs | ||||
| vasopressors, n (%) | 293 (12.96) | 157 (7.77) | 136 (56.67) | <0.001 |
| sedative_hypnotic, n (%) | 950 (42.04) | 787 (38.96) | 163 (67.92) | <0.001 |
| Perdipine, n (%) | 354 (15.66) | 295 (14.60) | 59 (24.58) | <0.001 |
| Underlying disease | ||||
| Hypertension, n (%) | 954 (42.21) | 829 (41.04) | 125 (52.08) | 0.001 |
| Diabetes mellitus, n (%) | 581 (25.71) | 510 (25.25) | 71 (29.58) | 0.169 |
| heart disease, n (%) | 363 (16.06) | 320 (15.84) | 43 (17.92) | 0.462 |
| Cerebrovascular disease, n (%) | 206 (9.12) | 181 (8.96) | 25 (10.42) | 0.534 |
| Gastrointestinal disease, n (%) | 168 (7.43) | 151 (7.48) | 17 (7.08) | 0.929 |
| Liver Disease, n (%) | 161 (7.12) | 135 (6.68) | 26 (10.83) | 0.026 |
| kidney disease, n (%) | 133 (5.88) | 100 (4.95) | 33 (13.75) | <0.001 |
| cancer, n (%) | 110 (4.87) | 97 (4.80) | 13 (5.42) | 0.795 |
| Thyroid disease, n (%) | 55 (2.43) | 53 (2.62) | 2 (0.83) | 0.139 |
| epilepsy, n (%) | 45 (1.99) | 40 (1.98) | 5 (2.08) | 0.809 |
| asthma, n (%) | 41 (1.81) | 39 (1.93) | 2 (0.83) | 0.310 |
| pneumonia, n (%) | 38 (1.68) | 32 (1.58) | 6 (2.50) | 0.286 |
| Feature | Mortality | Feature | Mortality |
|---|---|---|---|
| Gender | 0.025 | FiO2 | 0.294 |
| Age | 0.108 | APACHE II | 0.397 |
| Hight | 0.008 | SOFA | 0.398 |
| Weight | −0.045 | Endo | 0.238 |
| SBP | −0.066 | EVD | −0.024 |
| DBP | −0.108 | ICP | 0.118 |
| MAP | −0.110 | CPP | 0.118 |
| BT | −0.088 | surgery | 0.126 |
| pulse | 0.079 | vasopressors | 0.448 |
| RR | −0.066 | Sedative−hypnotic drugs | 0.181 |
| GCS_E | −0.371 | Perdipine | 0.085 |
| GCS_V | −0.348 | Hypertension | 0.069 |
| GCS_M | −0.398 | Diabetes mellitus | 0.031 |
| GCS | −0.363 | Cerebrovascular disease | 0.016 |
| pupil_reflex + (L) | −0.483 | heart disease | 0.017 |
| pupil_size(L) | 0.235 | asthma | −0.025 |
| pupil_reflex + (R) | −0.491 | pneumonia | 0.022 |
| pupil_size(R) | 0.241 | Gastrointestinal disease | −0.005 |
| Muscle_LUE | −0.325 | cancer | 0.009 |
| Muscle_LLEE | −0.326 | Liver Disease | 0.050 |
| Muscle_RUE | −0.328 | epilepsy | 0.002 |
| Muscle_RLE | −0.331 | kidney disease | 0.115 |
| Thyroid disease | −0.036 |
| Algorithm | Accuracy | Sensitivity | Specificity | AUC |
|---|---|---|---|---|
| 42 features | ||||
| Logistic Regression | 0.799 | 0.806 | 0.799 | 0.901 |
| Random Forest | 0.829 | 0.833 | 0.828 | 0.914 |
| LightGBM | 0.832 | 0.833 | 0.832 | 0.916 |
| XGBoost | 0.794 | 0.806 | 0.792 | 0.900 |
| 29 significant features | ||||
| Logistic Regression | 0.771 | 0.833 | 0.764 | 0.895 |
| Random Forest | 0.844 | 0.847 | 0.843 | 0.918 |
| LightGBM | 0.835 | 0.833 | 0.835 | 0.913 |
| XGBoost | 0.783 | 0.792 | 0.782 | 0.901 |
| 22 significant features and Spearman correlation coefficient > 0.1 | ||||
| Logistic Regression | 0.833 | 0.819 | 0.835 | 0.919 |
| Random Forest | 0.830 | 0.833 | 0.830 | 0.921 |
| LightGBM | 0.851 | 0.819 | 0.855 | 0.909 |
| XGBoost | 0.785 | 0.806 | 0.782 | 0.896 |
| 14 significant features and Spearman correlation coefficient > 0.2 | ||||
| Logistic Regression | 0.814 | 0.819 | 0.814 | 0.877 |
| Random Forest | 0.832 | 0.833 | 0.832 | 0.902 |
| LightGBM | 0.878 | 0.806 | 0.886 | 0.914 |
| XGBoost | 0.794 | 0.806 | 0.794 | 0.897 |
| Algorithm | Accuracy | Sensitivity | Specificity | AUC | Delong Test |
|---|---|---|---|---|---|
| Feature = 42 (LightGBM) | 0.832 | 0.833 | 0.832 | 0.916 | - |
| Feature = 29 (Random Forest) | 0.844 | 0.847 | 0.843 | 0.918 | 0.8376 |
| Feature = 22 (Random Forest) | 0.830 | 0.833 | 0.830 | 0.921 | 0.5641 |
| Feature = 14 (LightGBM) | 0.878 | 0.806 | 0.886 | 0.914 | 0.8198 |
| APACH II | 0.768 | 0.847 | 0.759 | 0.872 | 0.0180 |
| SOFA | 0.801 | 0.778 | 0.804 | 0.853 | 0.0156 |
| Study | Current Study, 2023 | Abujaber et al. [18], 2020 | Hsu et al. [19], 2021 | Wang et al. [20], 2022 | Wu et al. [21], 2023 |
|---|---|---|---|---|---|
| Setting | ICU | In-hospital | In-hospital | In-hospital | In-hospital |
| Patient number | 2260 | 1620 | 3331 | 368 | 2804 |
| Study models | Four ML models | Two ML models | Seven ML models | Two ML models | 4 ML models |
| Features | Different features (42, 29, 22, 14) combination | 20 | 8 | 21 | 26 |
| Outcome | Mortality | Mortality | Mortality | Mortality | Mortality |
| Testing result (AUC) | 0.915 | 0.96 | 0.82 | 0.955 | 0.87 |
| Comparing with other prediction models | APACHE II score, SOFA score | Nil. | Nil. | Nil. | IMPACT, CRASH |
| The best prediction model | LightGBM (14 features) | SVM | J48 | XGBoost | XGBoost |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tu, K.-C.; Tau, E.n.t.; Chen, N.-C.; Chang, M.-C.; Yu, T.-C.; Wang, C.-C.; Liu, C.-F.; Kuo, C.-L. Machine Learning Algorithm Predicts Mortality Risk in Intensive Care Unit for Patients with Traumatic Brain Injury. Diagnostics 2023, 13, 3016. https://doi.org/10.3390/diagnostics13183016
Tu K-C, Tau Ent, Chen N-C, Chang M-C, Yu T-C, Wang C-C, Liu C-F, Kuo C-L. Machine Learning Algorithm Predicts Mortality Risk in Intensive Care Unit for Patients with Traumatic Brain Injury. Diagnostics. 2023; 13(18):3016. https://doi.org/10.3390/diagnostics13183016
Chicago/Turabian StyleTu, Kuan-Chi, Eric nyam tee Tau, Nai-Ching Chen, Ming-Chuan Chang, Tzu-Chieh Yu, Che-Chuan Wang, Chung-Feng Liu, and Ching-Lung Kuo. 2023. "Machine Learning Algorithm Predicts Mortality Risk in Intensive Care Unit for Patients with Traumatic Brain Injury" Diagnostics 13, no. 18: 3016. https://doi.org/10.3390/diagnostics13183016
APA StyleTu, K. -C., Tau, E. n. t., Chen, N. -C., Chang, M. -C., Yu, T. -C., Wang, C. -C., Liu, C. -F., & Kuo, C. -L. (2023). Machine Learning Algorithm Predicts Mortality Risk in Intensive Care Unit for Patients with Traumatic Brain Injury. Diagnostics, 13(18), 3016. https://doi.org/10.3390/diagnostics13183016