
Vision-Transformer-Based Transfer Learning for Mammogram Classification

 ,
,  ,
, 
 , ,
, ,  ,
, 
Abstract
:1. Introduction
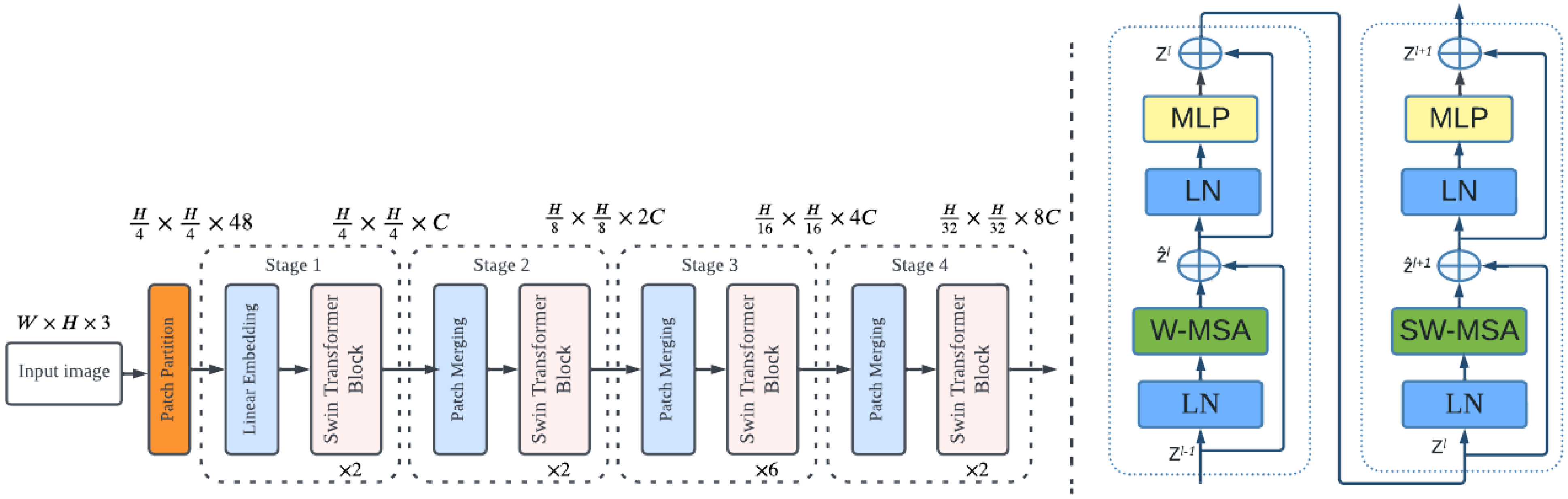
2. Related Works
3. Materials and Methods
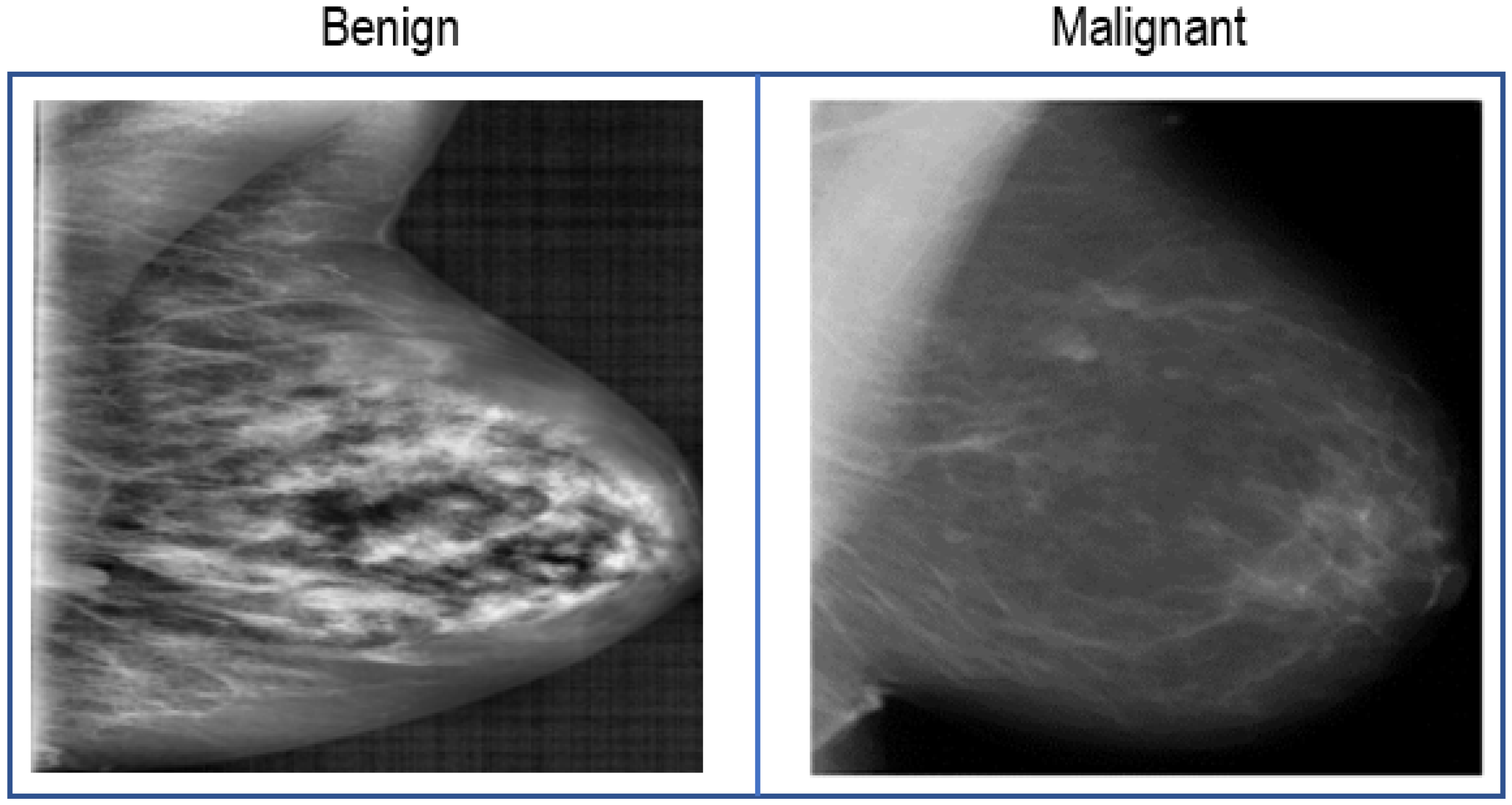
3.1. Dataset
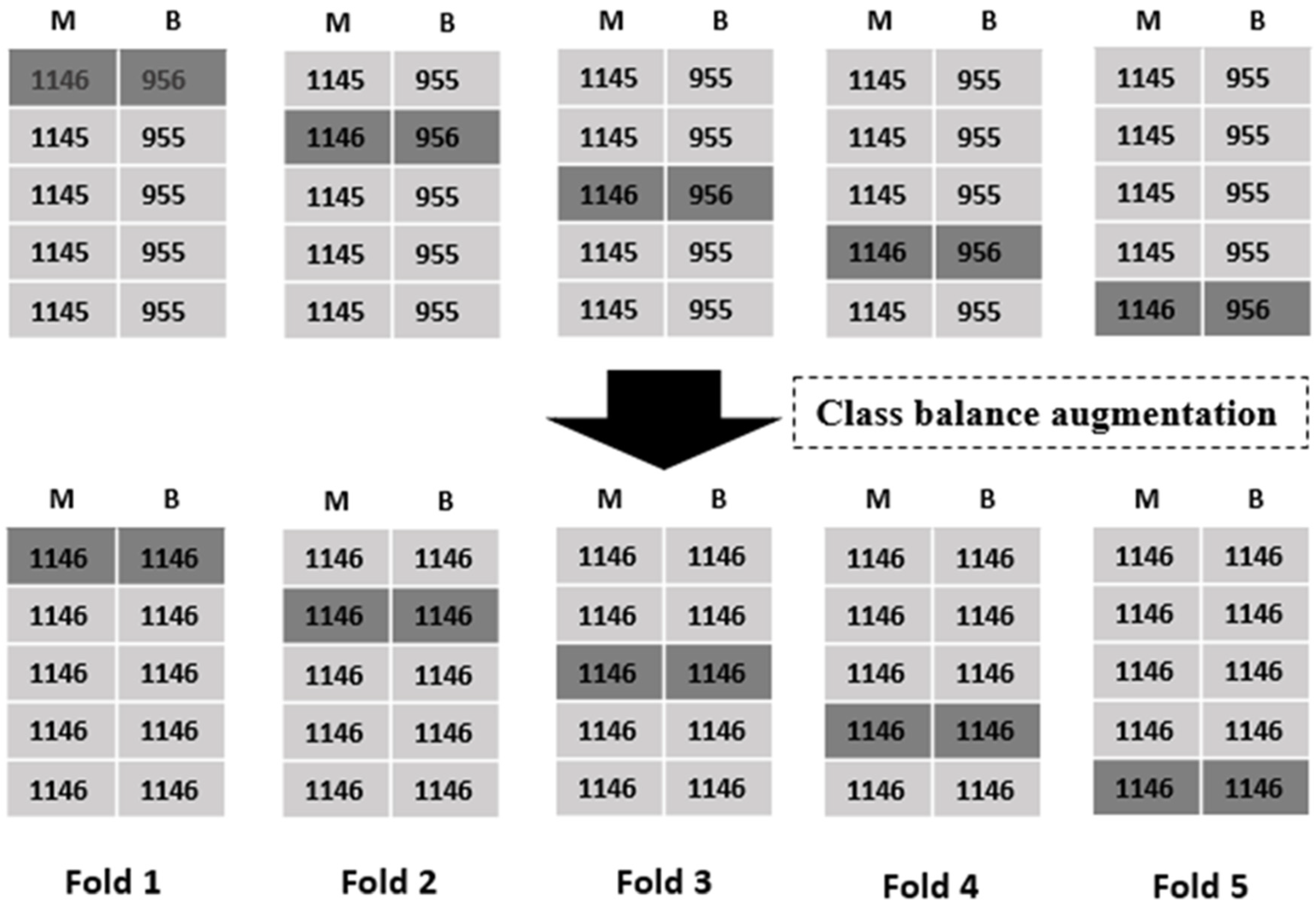
3.2. Class Balancing
3.3. Preprocessing
3.4. The Proposed Method
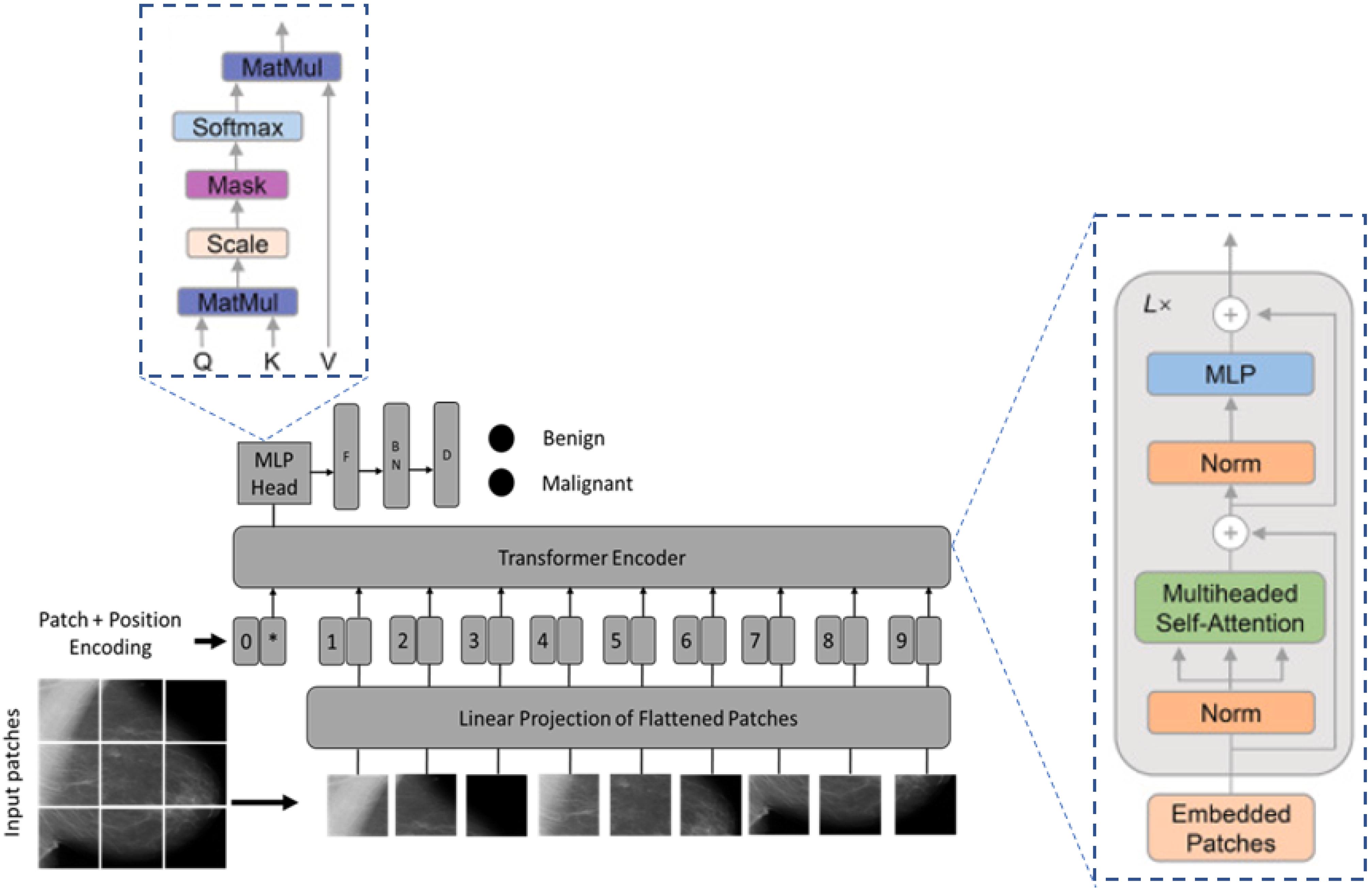
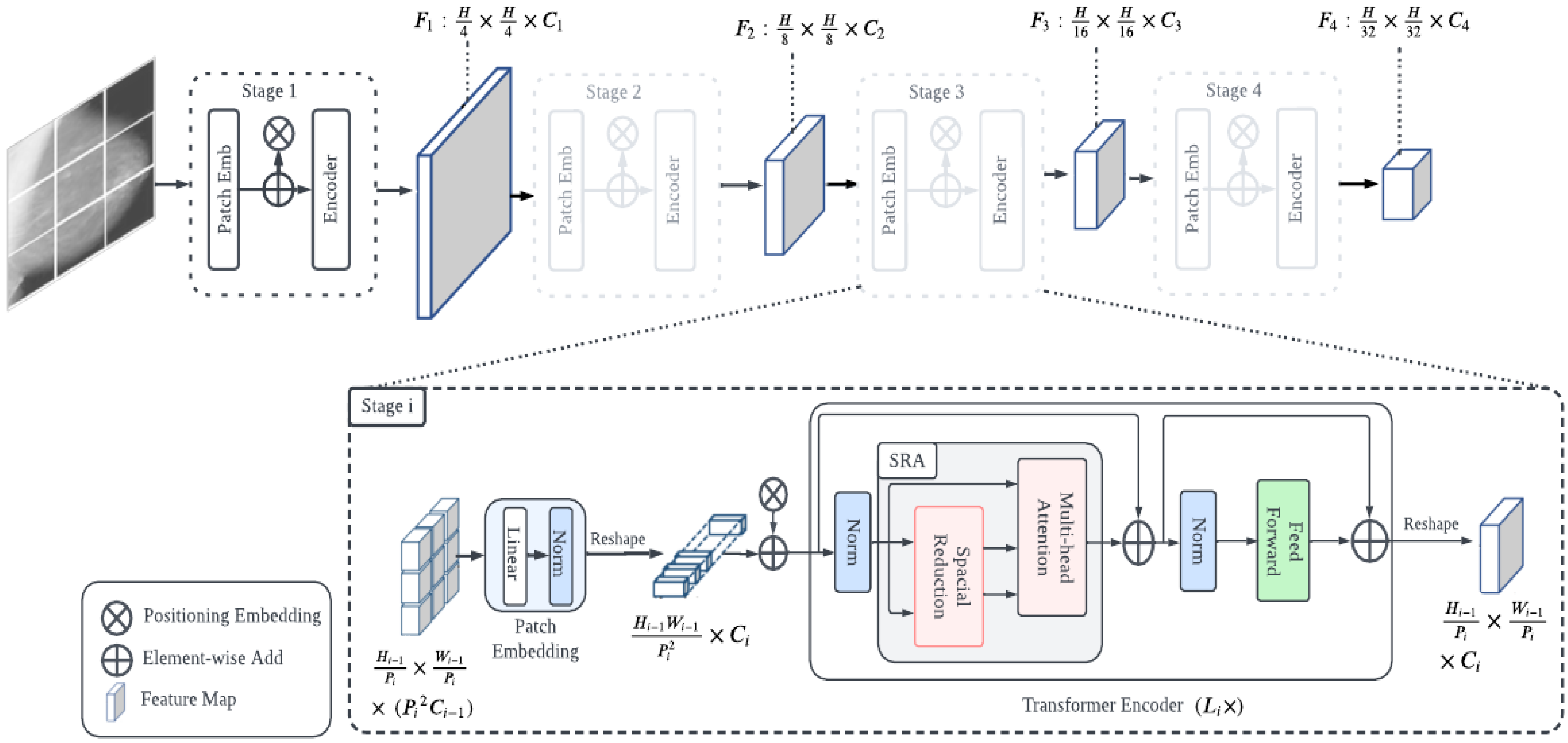
3.4.1. Vision Transformer Architecture
- Every patch was flattened into a vector, , with a length of , for .
- Mapping the flattened patches to dimensions using a trainable linear projection, , produced a series of embedded image patches.
- The sequence of the embedded image patches was prefixed with a learnable class embedding . The values correspond to the classification outcome .
- Finally, one-dimensional positional embeddings , which are also learned during training, are added to the patch embeddings to add positioning information to the input.
3.4.2. Transfer Learning
3.5. Experimental Settings
3.6. Implementation Details
3.7. Performance Metrics
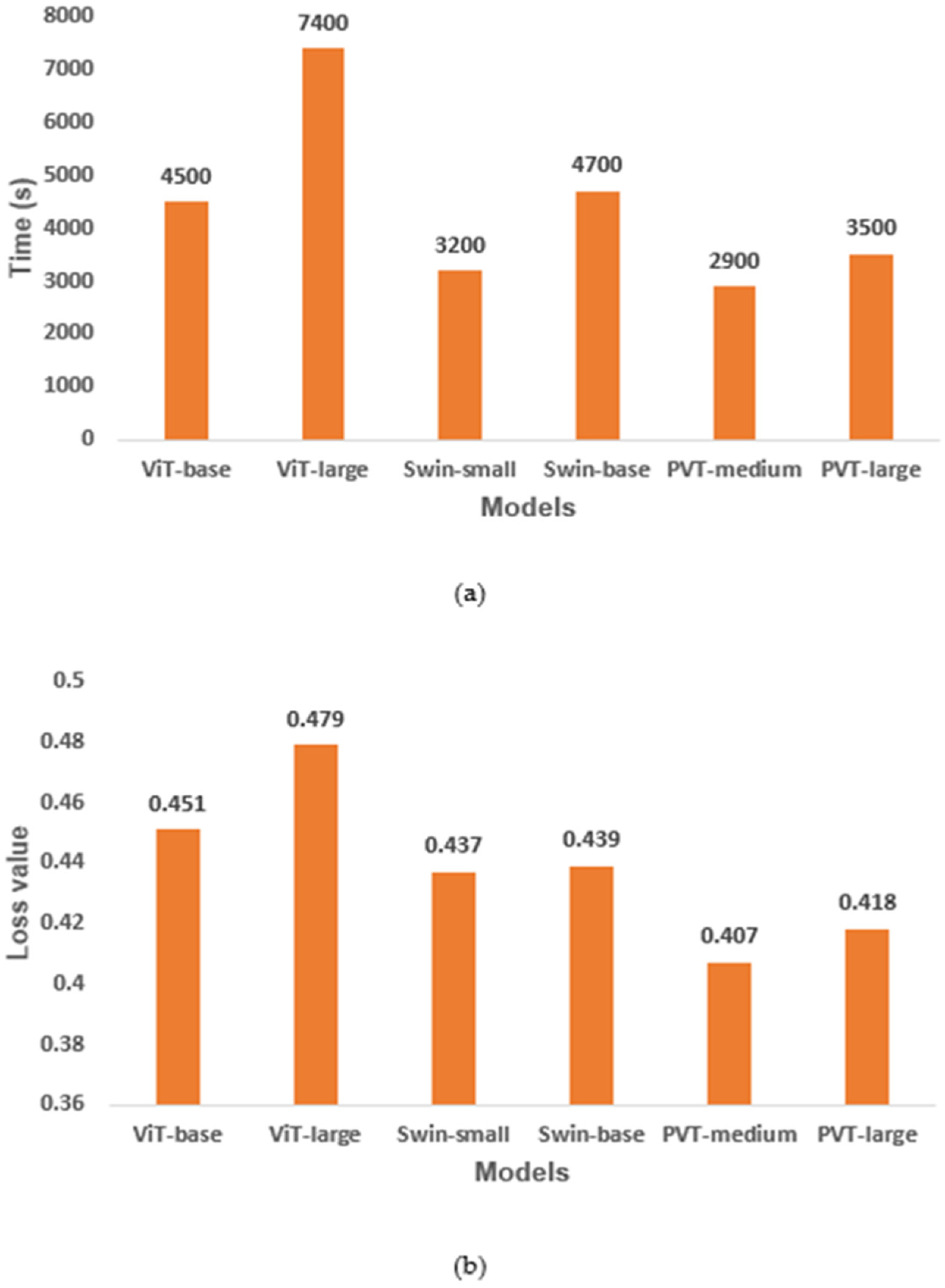
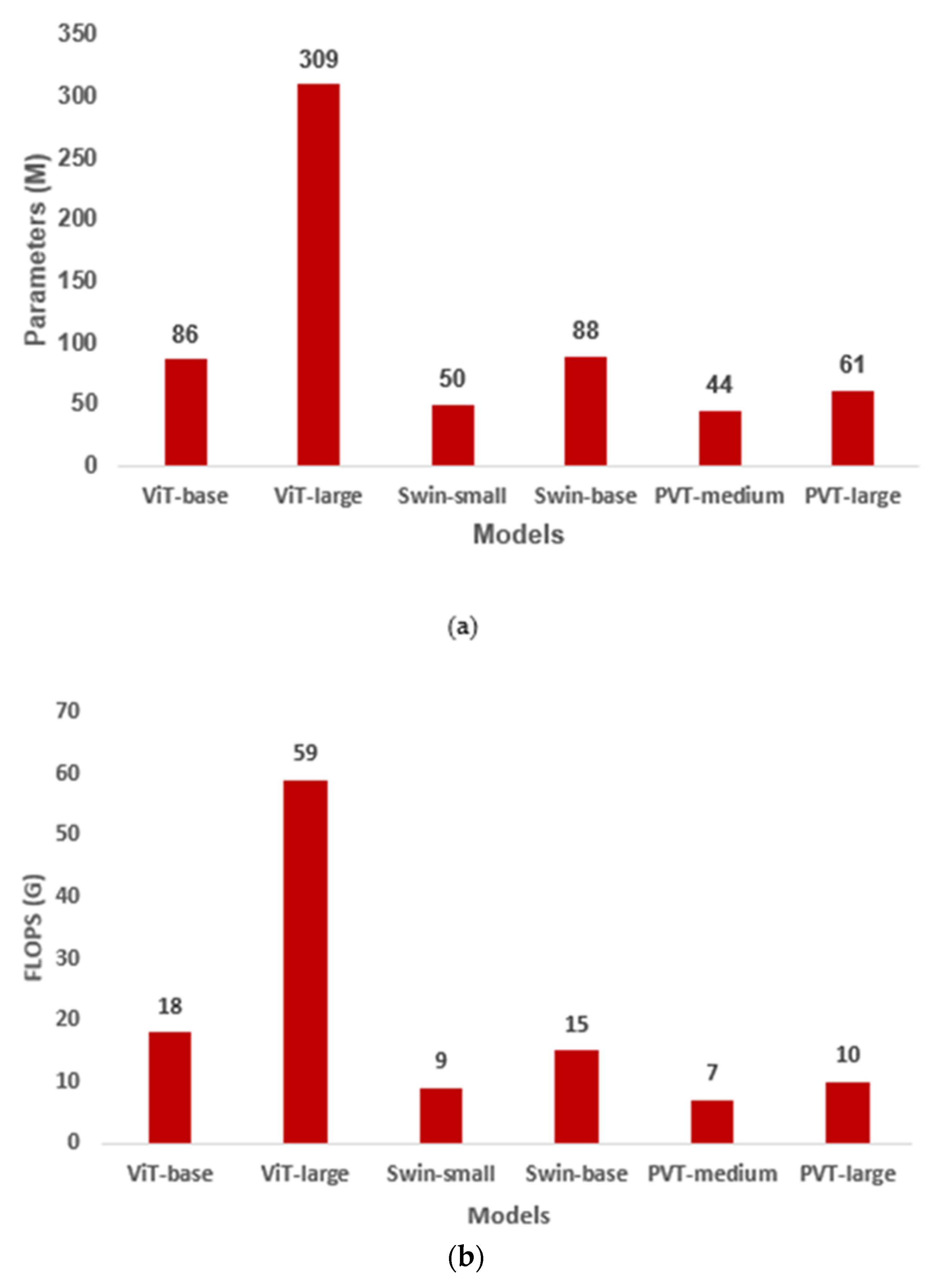
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- American Cancer Society. Cancer Facts & Figures 2022; American Cancer Society: Atlants, GA, USA, 2022. [Google Scholar]
- Sung, H.; Ferlay, J.; Siegel, R.L.; Laversanne, M.; Soerjomataram, I.; Jemal, A.; Bray, F. Global Cancer Statistics 2020: GLOBOCAN Estimates of Incidence and Mortality Worldwide for 36 Cancers in 185 Countries. CA Cancer J. Clin. 2021, 71, 209–249. [Google Scholar] [CrossRef] [PubMed]
- American Cancer Society. Cancer Facts & Figures 2021; American Cancer Society: Atlants, GA, USA, 2021. [Google Scholar]
- Dese, K.; Ayana, G.; Lamesgin Simegn, G. Low Cost, Non-Invasive, and Continuous Vital Signs Monitoring Device for Pregnant Women in Low Resource Settings (Lvital Device). HardwareX 2022, 11, e00276. [Google Scholar] [CrossRef] [PubMed]
- Seely, J.M.; Alhassan, T. Screening for Breast Cancer in 2018—What Should We Be Doing Today? Curr. Oncol. 2018, 25, 115–124. [Google Scholar] [CrossRef] [Green Version]
- Ayana, G.; Ryu, J.; Choe, S. Ultrasound-Responsive Nanocarriers for Breast Cancer Chemotherapy. Micromachines 2022, 13, 1508. [Google Scholar] [CrossRef] [PubMed]
- Weedon-Fekjaer, H.; Romundstad, P.R.; Vatten, L.J. Modern Mammography Screening and Breast Cancer Mortality: Population Study. BMJ 2014, 348, g3701. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pashayan, N.; Antoniou, A.C.; Ivanus, U.; Esserman, L.J.; Easton, D.F.; French, D.; Sroczynski, G.; Hall, P.; Cuzick, J.; Evans, D.G.; et al. Personalized Early Detection and Prevention of Breast Cancer: ENVISION Consensus Statement. Nat. Rev. Clin. Oncol. 2020, 17, 687–705. [Google Scholar] [CrossRef]
- Chougrad, H.; Zouaki, H.; Alheyane, O. Multi-Label Transfer Learning for the Early Diagnosis of Breast Cancer. Neurocomputing 2020, 392, 168–180. [Google Scholar] [CrossRef]
- Al-antari, M.A.; Han, S.M.; Kim, T.S. Evaluation of Deep Learning Detection and Classification towards Computer-Aided Diagnosis of Breast Lesions in Digital X-ray Mammograms. Comput. Methods Programs Biomed. 2020, 196, 105584. [Google Scholar] [CrossRef]
- Rocha García, A.M.; Mera Fernández, D. Breast Tomosynthesis: State of the Art. Radiology 2019, 61, 274–285. [Google Scholar] [CrossRef]
- Debelee, T.G.; Schwenker, F.; Ibenthal, A.; Yohannes, D. Survey of Deep Learning in Breast Cancer Image Analysis. Evol. Syst. 2020, 11, 143–163. [Google Scholar] [CrossRef]
- Sohns, C.; Angic, B.C.; Sossalla, S.; Konietschke, F.; Obenauer, S. CAD in Full-Field Digital Mammography-Influence of Reader Experience and Application of CAD on Interpretation of Time. Clin. Imaging 2010, 34, 418–424. [Google Scholar] [CrossRef] [PubMed]
- Jung, N.Y.; Kang, B.J.; Kim, H.S.; Cha, E.S.; Lee, J.H.; Park, C.S.; Whang, I.Y.; Kim, S.H.; An, Y.Y.; Choi, J.J. Who Could Benefit the Most from Using a Computer-Aided Detection System in Full-Field Digital Mammography? World J. Surg. Oncol. 2014, 12, 168. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guerriero, C.; Gillan, M.G.; Cairns, J.; Wallis, M.G.; Gilbert, F.J. Is Computer Aided Detection (CAD) Cost Effective in Screening Mammography? A Model Based on the CADET II Study. BMC Health Serv. Res. 2011, 11, 11. [Google Scholar] [CrossRef] [Green Version]
- Agrawal, S.; Rangnekar, R.; Gala, D.; Paul, S.; Kalbande, D. Detection of Breast Cancer from Mammograms Using a Hybrid Approach of Deep Learning and Linear Classification. In Proceedings of the 2018 International Conference on Smart City and Emerging Technology (ICSCET 2018), Mumbai, India, 5 January 2018. [Google Scholar] [CrossRef]
- Zebari, D.A.; Zeebaree, D.Q.; Abdulazeez, A.M.; Haron, H.; Hamed, H.N.A. Improved Threshold Based and Trainable Fully Automated Segmentation for Breast Cancer Boundary and Pectoral Muscle in Mammogram Images. IEEE Access 2020, 8, 1–20. [Google Scholar] [CrossRef]
- Fanizzi, A.; Pomarico, D.; Paradiso, A.; Bove, S.; Diotiaiuti, S.; Didonna, V.; Giotta, F.; La Forgia, D.; Latorre, A.; Pastena, M.I.; et al. Predicting of Sentinel Lymph Node Status in Breast Cancer Patients with Clinically Negative Nodes: A Validation Study. Cancers 2021, 13, 352. [Google Scholar] [CrossRef] [PubMed]
- Ayana, G.; Park, J.; Choe, S.W. Patchless Multi-Stage Transfer Learning for Improved Mammographic Breast Mass Classification. Cancers 2022, 14, 1280. [Google Scholar] [CrossRef]
- Kooi, T.; Litjens, G.; van Ginneken, B.; Gubern-Mérida, A.; Sánchez, C.I.; Mann, R.; den Heeten, A.; Karssemeijer, N. Large Scale Deep Learning for Computer Aided Detection of Mammographic Lesions. Med. Image Anal. 2017, 35, 303–312. [Google Scholar] [CrossRef]
- Chan, H.P.; Samala, R.K.; Hadjiiski, L.M. CAD and AI for Breast Cancer—Recent Development and Challenges. Br. J. Radiol. 2020, 93, 20190580. [Google Scholar] [CrossRef]
- Shen, L.; Margolies, L.R.; Rothstein, J.H.; Fluder, E.; McBride, R.; Sieh, W. Deep Learning to Improve Breast Cancer Detection on Screening Mammography. Sci. Rep. 2019, 9, 12495. [Google Scholar] [CrossRef]
- Hassan, N.M.; Hamad, S.; Mahar, K. Mammogram Breast Cancer CAD Systems for Mass Detection and Classification: A Review. Multimed. Tools Appl. 2022, 81, 20043–20075. [Google Scholar] [CrossRef]
- Bharati, S.; Podder, P.; Mondal, M.R.H. Artificial Neural Network Based Breast Cancer Screening: A Comprehensive Review. arXiv 2020, arXiv:2006.01767. [Google Scholar]
- Dese, K.; Raj, H.; Ayana, G.; Yemane, T.; Adissu, W.; Krishnamoorthy, J.; Kwa, T. Accurate Machine-Learning-Based Classification of Leukemia from Blood Smear Images. Clin. Lymphoma Myeloma Leuk. 2021, 21, e903–e914. [Google Scholar] [CrossRef] [PubMed]
- Mridha, M.F.; Hamid, M.A.; Monowar, M.M.; Keya, A.J.; Ohi, A.Q.; Islam, M.R.; Kim, J.-M. A Comprehensive Survey on Deep-Learning-Based Breast Cancer Diagnosis. Cancers 2021, 13, 6116. [Google Scholar] [CrossRef]
- Abdelhafiz, D.; Yang, C.; Ammar, R.; Nabavi, S. Deep Convolutional Neural Networks for Mammography: Advances, Challenges and Applications. BMC Bioinform. 2019, 20, 281. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Ding, H.; Bidgoli, F.A.; Zhou, B.; Iribarren, C.; Molloi, S.; Baldi, P. Detecting Cardiovascular Disease from Mammograms with Deep Learning. IEEE Trans. Med. Imaging 2017, 36, 1172–1181. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Niu, J.; Li, D.; Zhang, C. Classification of Breast Mass in Two-view Mammograms via Deep Learning. IET Image Process. 2021, 15, 454–467. [Google Scholar] [CrossRef]
- Yala, A.; Lehman, C.; Schuster, T.; Portnoi, T.; Barzilay, R. A Deep Learning Mammography-Based Model for Improved Breast Cancer Risk Prediction. Radiology 2019, 292, 60–66. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lehman, C.D.; Yala, A.; Schuster, T.; Dontchos, B.; Bahl, M.; Swanson, K.; Barzilay, R. Mammographic Breast Density Assessment Using Deep Learning: Clinical Implementation. Radiology 2019, 290, 52–58. [Google Scholar] [CrossRef] [Green Version]
- Lotter, W.; Diab, A.R.; Haslam, B.; Kim, J.G.; Grisot, G.; Wu, E.; Wu, K.; Onieva, J.O.; Boyer, Y.; Boxerman, J.L.; et al. Robust Breast Cancer Detection in Mammography and Digital Breast Tomosynthesis Using an Annotation-Efficient Deep Learning Approach. Nat. Med. 2021, 27, 244–249. [Google Scholar] [CrossRef]
- Wu, N.; Phang, J.; Park, J.; Shen, Y.; Huang, Z.; Zorin, M.; Jastrzebski, S.; Fevry, T.; Katsnelson, J.; Kim, E.; et al. Deep Neural Networks Improve Radiologists’ Performance in Breast Cancer Screening. IEEE Trans. Med. Imaging 2020, 39, 1184–1194. [Google Scholar] [CrossRef]
- Lotter, W.; Sorensen, G.; Cox, D. A Multi-Scale CNN and Curriculum Learning Strategy for Mammogram Classification. Lect. Notes Comput. Sci. (including Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinformatics) 2017, 10553 LNCS, 169–177. [Google Scholar] [CrossRef] [Green Version]
- McKinney, S.M.; Sieniek, M.; Godbole, V.; Godwin, J.; Antropova, N.; Ashrafian, H.; Back, T.; Chesus, M.; Corrado, G.C.; Darzi, A.; et al. International Evaluation of an AI System for Breast Cancer Screening. Nature 2020, 577, 89–94. [Google Scholar] [CrossRef] [PubMed]
- Mudeng, V.; Jeong, J.W.; Choe, S.W. Simply Fine-Tuned Deep Learning-Based Classification for Breast Cancer with Mammograms. Comput. Mater. Contin. 2022, 73, 4677–4693. [Google Scholar] [CrossRef]
- Salim, M.; Wåhlin, E.; Dembrower, K.; Azavedo, E.; Foukakis, T.; Liu, Y.; Smith, K.; Eklund, M.; Strand, F. External Evaluation of 3 Commercial Artificial Intelligence Algorithms for Independent Assessment of Screening Mammograms. JAMA Oncol. 2020, 6, 1581–1588. [Google Scholar] [CrossRef] [PubMed]
- Ayana, G.; Dese, K.; Raj, H.; Krishnamoorthy, J.; Kwa, T. De-Speckling Breast Cancer Ultrasound Images Using a Rotationally Invariant Block Matching Based Non-Local Means (RIBM-NLM) Method. Diagnostics 2022, 12, 862. [Google Scholar] [CrossRef]
- Frazer, H.M.L.; Qin, A.K.; Pan, H.; Brotchie, P. Evaluation of Deep Learning-Based Artificial Intelligence Techniques for Breast Cancer Detection on Mammograms: Results from a Retrospective Study Using a BreastScreen Victoria Dataset. J. Med. Imaging Radiat. Oncol. 2021, 65, 529–537. [Google Scholar] [CrossRef]
- Samala, R.K.; Chan, H.P.; Hadjiiski, L.M.; Helvie, M.A.; Richter, C.D. Generalization Error Analysis for Deep Convolutional Neural Network with Transfer Learning in Breast Cancer Diagnosis. Phys. Med. Biol. 2020, 65, 105002. [Google Scholar] [CrossRef]
- Xu, Q.; Wang, X.; Jiang, H. Convolutional Neural Network for Breast Cancer Diagnosis Using Diffuse Optical Tomography. Vis. Comput. Ind. Biomed. Art 2019, 2, 1–6. [Google Scholar] [CrossRef] [Green Version]
- Saini, M.; Susan, S. Deep Transfer with Minority Data Augmentation for Imbalanced Breast Cancer Dataset. Appl. Soft Comput. J. 2020, 97, 106759. [Google Scholar] [CrossRef]
- Gardezi, S.J.S.; Elazab, A.; Lei, B.; Wang, T. Breast Cancer Detection and Diagnosis Using Mammographic Data: Systematic Review. J. Med. Internet Res. 2019, 21, 1–22. [Google Scholar] [CrossRef]
- Kyono, T.; Gilbert, F.J.; van der Schaar, M. MAMMO: A Deep Learning Solution for Facilitating Radiologist-Machine Collaboration in Breast Cancer Diagnosis. arXiv 2018, arXiv:1811.02661. [Google Scholar]
- Van Tulder, G.; Tong, Y.; Marchiori, E. Multi-View Analysis of Unregistered Medical Images Using Cross-View Transformers. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2021; pp. 104–113. [Google Scholar] [CrossRef]
- Carneiro, G.; Nascimento, J.; Bradley, A.P. Automated Analysis of Unregistered Multi-View Mammograms with Deep Learning. IEEE Trans. Med. Imaging 2017, 36, 2355–2365. [Google Scholar] [CrossRef] [PubMed]
- Ayana, G.; Dese, K.; Choe, S. Transfer Learning in Breast Cancer Diagnoses via Ultrasound Imaging. Cancers 2021, 13, 738. [Google Scholar] [CrossRef] [PubMed]
- Ayana, G.; Park, J.; Jeong, J.W.; Choe, S.W. A Novel Multistage Transfer Learning for Ultrasound Breast Cancer Image Classification. Diagnostics 2022, 12, 135. [Google Scholar] [CrossRef] [PubMed]
- Shen, T.; Wang, J.; Gou, C.; Wang, F.Y. Hierarchical Fused Model with Deep Learning and Type-2 Fuzzy Learning for Breast Cancer Diagnosis. IEEE Trans. Fuzzy Syst. 2020, 28, 3204–3218. [Google Scholar] [CrossRef]
- Xie, X.; Niu, J.; Liu, X.; Chen, Z.; Tang, S.; Yu, S. A Survey on Incorporating Domain Knowledge into Deep Learning for Medical Image Analysis. Med. Image Anal. 2021, 69, 101985. [Google Scholar] [CrossRef]
- Falconi, L.; Perez, M.; Aguilar, W.; Conci, A. Transfer Learning and Fine Tuning in Mammogram Bi-Rads Classification. In Proceedings of the 2020 IEEE 33rd International Symposium on Computer-Based Medical Systems (CBMS), Rochester, MN, USA, 28–30 July 2020; pp. 475–480. [Google Scholar] [CrossRef]
- Jaehwan, L.; Donggeun, Y.; Hyo-Eun, K. Photometric Transformer Networks and Label Adjustment for Breast Density Prediction. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019; pp. 460–466. [Google Scholar] [CrossRef] [Green Version]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial Transformer Networks. In Proceedings of the ACM International Conference Proceeding Series, Niagara Falls, ON, Canada, 6–9 November 2016; Volume 2, pp. 45–48. [Google Scholar]
- Su, Y.; Liu, Q.; Xie, W.; Hu, P. YOLO-LOGO: A Transformer-Based YOLO Segmentation Model for Breast Mass Detection and Segmentation in Digital Mammograms. Comput. Methods Programs Biomed. 2022, 221, 106903. [Google Scholar] [CrossRef]
- Garrucho, L.; Kushibar, K.; Jouide, S.; Diaz, O.; Igual, L.; Lekadir, K. Domain Generalization in Deep Learning Based Mass Detection in Mammography: A Large-Scale Multi-Center Study. Artif. Intell. Med. 2022, 132, 102386. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, K.; Abdoli, N.; Gilley, P.W.; Wang, X.; Liu, H.; Zheng, B.; Qiu, Y. Transformers Improve Breast Cancer Diagnosis from Unregistered Multi-View Mammograms. Diagnostics 2022, 12, 1549. [Google Scholar] [CrossRef]
- Ayana, G.; Choe, S. BUViTNet: Breast Ultrasound Detection via Vision Transformers. Diagnostics 2022, 12, 2654. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar] [CrossRef]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 548–558. [Google Scholar] [CrossRef]
- Chicco, D.; Jurman, G. The Advantages of the Matthews Correlation Coefficient (MCC) over F1 Score and Accuracy in Binary Classification Evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics | Formula |
|---|---|
| Architecture | Model | Accuracy (95%) | AUC (95%) | F1 Score (95%) | Precision (95%) | Recall (95%) | MCC (95%) | Kappa (95%) |
|---|---|---|---|---|---|---|---|---|
| Vision transformer | ViT-base | 1 ± 0 | 1 ± 0 | 1 ± 0 | 1 ± 0 | 1 ± 0 | 1 ± 0 | 1 ± 0 |
| ViT-large | 1 ± 0 | 1 ± 0 | 1 ± 0 | 1 ± 0 | 1 ± 0 | 1 ± 0 | 1 ± 0 | |
| Swin transformer | Swin-small | 1 ± 0 | 1 ± 0 | 1 ± 0 | 1 ± 0 | 1 ± 0 | 1 ± 0 | 1 ± 0 |
| Swin-base | 1 ± 0 | 1 ± 0 | 1 ± 0 | 1 ± 0 | 1 ± 0 | 1 ± 0 | 1 ± 0 | |
| Pyramid vision transformer | PVT-medium | 1 ± 0 | 1 ± 0 | 1 ± 0 | 1 ± 0 | 1 ± 0 | 1 ± 0 | 1 ± 0 |
| PVT-large | 1 ± 0 | 1 ± 0 | 1 ± 0 | 1 ± 0 | 1 ± 0 | 1 ± 0 | 1 ± 0 |
| Architecture | Model | Accuracy (95%) | AUC (95%) | F1 Score (95%) | Precision (95%) | Recall (95%) | MCC (95%) | Kappa (95%) |
|---|---|---|---|---|---|---|---|---|
| Vision transformer | ViT-base | 0.74 ± 0.02 | 0.73 ± 0.03 | 0.74 ± 0.01 | 0.74 ± 0.01 | 0.74 ± 0.01 | 0.73 ± 0.03 | 0.73 ± 0.02 |
| ViT-large | 0.72 ± 0.04 | 0.72 ± 0.02 | 0.72 ± 0.03 | 0.72 ± 0.04 | 0.72 ± 0.03 | 0.71 ± 0.02 | 0.72 ± 0.01 | |
| Swin transformer | Swin-small | 0.75 ± 0.02 | 0.75 ± 0.03 | 0.75 ± 0.01 | 0.75 ± 0.02 | 0.75 ± 0.02 | 0.74 ± 0.03 | 0.74 ± 0.02 |
| Swin-base | 0.76 ± 0.01 | 0.75 ± 0.02 | 0.75 ± 0.02 | 0.75 ± 0.01 | 0.76 ± 0.01 | 0.75 ± 0.01 | 0.75 ± 0.02 | |
| Pyramid vision transformer | PVT-medium | 0.78 ± 0.02 | 0.77 ± 0.02 | 0.78 ± 0.01 | 0.78 ± 0.02 | 0.78 ± 0.02 | 0.77 ± 0.01 | 0.77 ± 0.02 |
| PVT-large | 0.77 ± 0.03 | 0.77 ± 0.01 | 0.77 ± 0.02 | 0.77 ± 0.02 | 0.77 ± 0.02 | 0.77 ± 0.01 | 0.77 ± 0.01 |
| Architecture | Model | Accuracy (95%) | AUC (95%) | F1 Score (95%) | Precision (95%) | Recall (95%) | MCC (95%) | Kappa (95%) |
|---|---|---|---|---|---|---|---|---|
| ResNet | ResNet50 | 0.95 ± 0.01 | 0.96 ± 0.01 | 0.95 ± 0.01 | 0.95 ± 0.01 | 0.95 ± 0.01 | 0.94 ± 0.01 | 0.94 ± 0.02 |
| ResNet101 | 0.95 ± 0.01 | 0.95 ± 0.02 | 0.95 ± 0.01 | 0.95 ± 0.01 | 0.95 ± 0.01 | 0.94 ± 0.02 | 0.94 ± 0.02 | |
| EfficientNet | EfficientNetB0 | 0.94 ± 0.02 | 0.94 ± 0.01 | 0.94 ± 0.01 | 0.94 ± 0.01 | 0.94 ± 0.01 | 0.93 ± 0.03 | 0.93 ± 0.02 |
| EfficientNetB2 | 0.95 ± 0.01 | 0.95 ± 0.01 | 0.95 ± 0.01 | 0.95 ± 0.01 | 0.95 ± 0.01 | 0.95 ± 0.01 | 0.95 ± 0.01 | |
| InceptionNet | InceptionNetV2 | 0.93 ± 0.02 | 0.93 ± 0.01 | 0.93 ± 0.02 | 0.93 ± 0.02 | 0.93 ± 0.02 | 0.93 ± 0.03 | 0.92 ± 0.02 |
| InceptionNetV3 | 0.94 ± 0.01 | 0.94 ± 0.01 | 0.94 ± 0.01 | 0.94 ± 0.01 | 0.94 ± 0.01 | 0.93 ± 0.02 | 0.93 ± 0.02 |
| Paper | Purpose | Dataset | AUC |
|---|---|---|---|
| Lee et al. [52] | Classification | Private | 0.9663 ± 0.033 |
| Tulder et al. [45] | Classification | DDSM | 0.803 ± 0.003 |
| Su et al. [54] | Detection | DDSM | 0.65 |
| Garrucho et al. [55] | Detection | OPTIMAM | 0.948 |
| Chen et al. [56] | Classification | Private | 0.818 ± 0.039 |
| Current work | Classification | DDSM | 1 ± 0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ayana, G.; Dese, K.; Dereje, Y.; Kebede, Y.; Barki, H.; Amdissa, D.; Husen, N.; Mulugeta, F.; Habtamu, B.; Choe, S.-W. Vision-Transformer-Based Transfer Learning for Mammogram Classification. Diagnostics 2023, 13, 178. https://doi.org/10.3390/diagnostics13020178
Ayana G, Dese K, Dereje Y, Kebede Y, Barki H, Amdissa D, Husen N, Mulugeta F, Habtamu B, Choe S-W. Vision-Transformer-Based Transfer Learning for Mammogram Classification. Diagnostics. 2023; 13(2):178. https://doi.org/10.3390/diagnostics13020178
Chicago/Turabian StyleAyana, Gelan, Kokeb Dese, Yisak Dereje, Yonas Kebede, Hika Barki, Dechassa Amdissa, Nahimiya Husen, Fikadu Mulugeta, Bontu Habtamu, and Se-Woon Choe. 2023. "Vision-Transformer-Based Transfer Learning for Mammogram Classification" Diagnostics 13, no. 2: 178. https://doi.org/10.3390/diagnostics13020178
APA StyleAyana, G., Dese, K., Dereje, Y., Kebede, Y., Barki, H., Amdissa, D., Husen, N., Mulugeta, F., Habtamu, B., & Choe, S. -W. (2023). Vision-Transformer-Based Transfer Learning for Mammogram Classification. Diagnostics, 13(2), 178. https://doi.org/10.3390/diagnostics13020178