
Natural Language Processing Applications for Computer-Aided Diagnosis in Oncology


Abstract
:1. Introduction
- RQ1: What are the current trends of NLP applications for CAD in oncology?
- RQ2: What are the limitations and challenges?
- RQ3: What are the promising future directions?
- Conclude some AI- and NLP-related concepts and algorithms to help people quickly understand the basics in the field;
- Summarize and analyze the recent decade of research and application of NLP for CAD to various tumors or cancers;
- Provide a more detailed discussion of the current models in the field;
- Identify challenges with the development of NLP in oncology;
- Give some suggestions and directions for the future development of NLP;
2. Theoretical Foundation
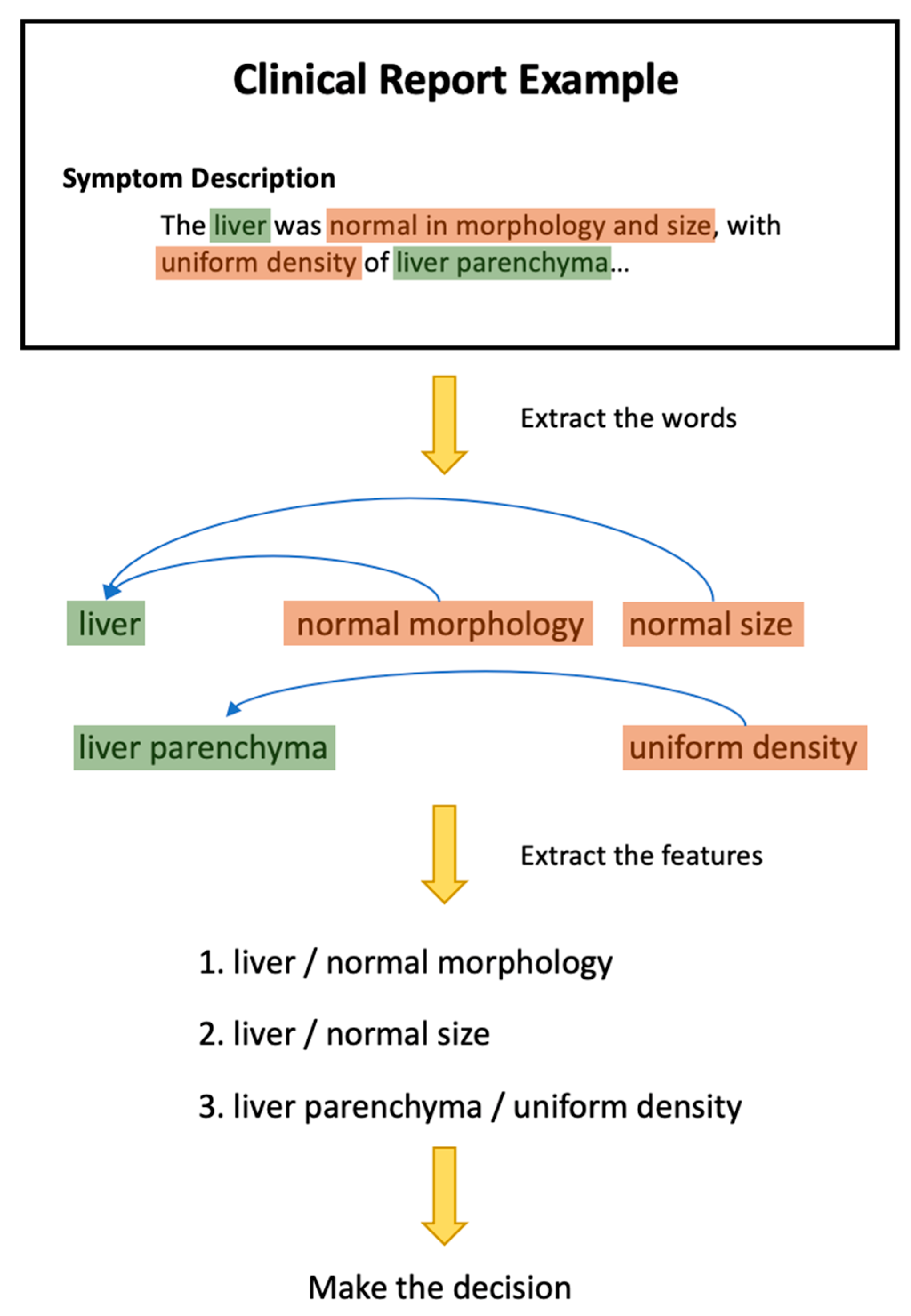
2.1. Related NLP Concepts
2.2. Related AI Methods
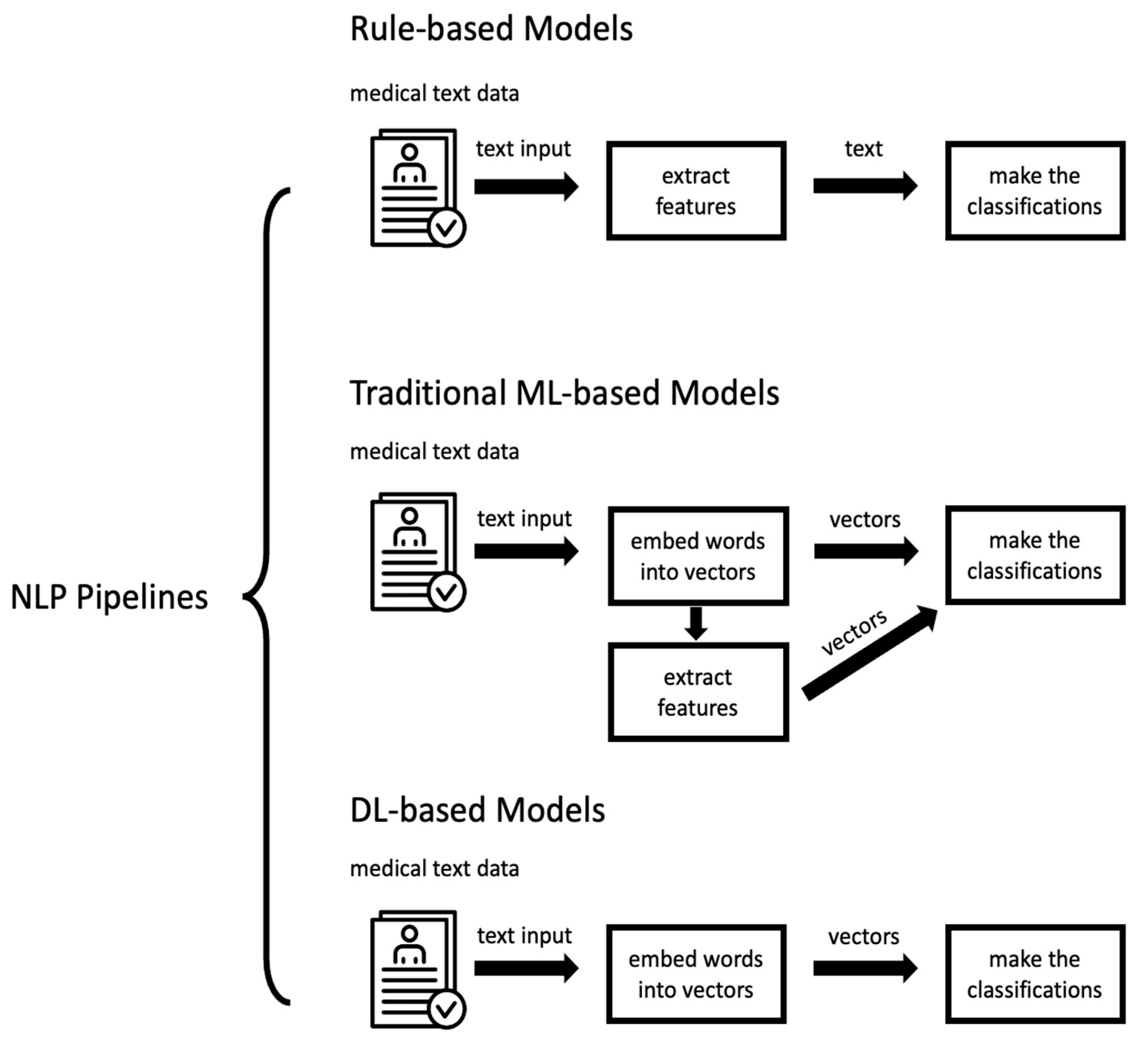
2.3. NLP Pipelines
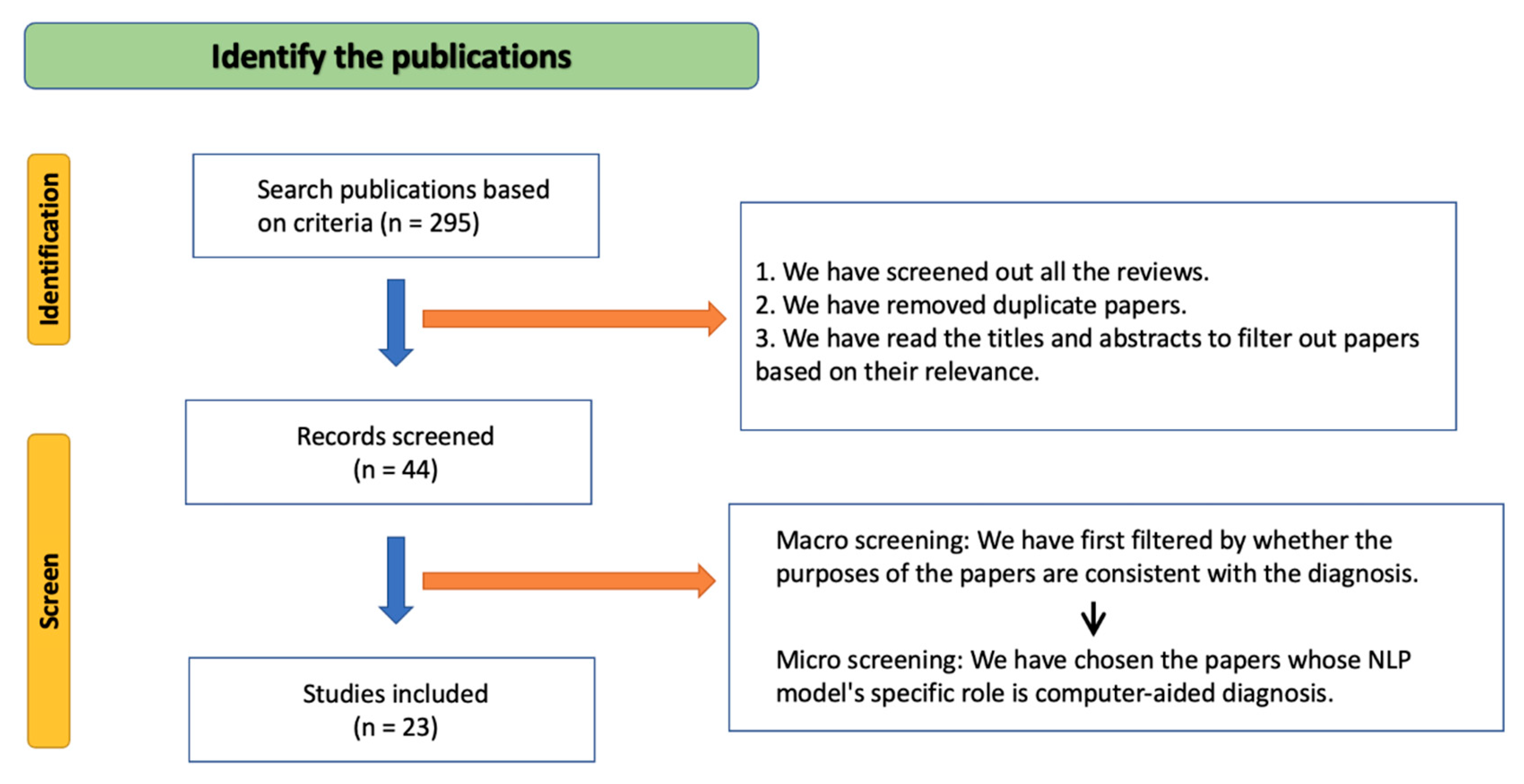
3. Materials and Methods
4. Results
4.1. Breast Cancer

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SN | Reference | Year | Source of Text | Language | Cancer Type | Aim | Algorithm | Evaluation Metrics | Validation | Dataset Size | Dataset Source |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | [16] | 2022 | Medical Notes (Unstructured) | English | Breast Cancer, Colorectal Cancer | Classify Cancer Recurrence | Bidirectional Encoder Representations from Transformers (BERT) [15] | Breast Cancer: AUC: 0.9892; Colorectal Cancer: AUC: 0.9810; | 5-fold Cross-validation | Breast Cancer: 190,754 Notes; 8067 Positive; 182,687 Negative Colorectal Cancer: 238,408 Notes; 8452 Positive; 229,956 Negative | Private: From Cancer Care Manitoba |
| 2 | [18] | 2021 | Medical Records (Unstructured) | English | Breast Cancer | Classify Breast Cancer Anatomic and Prognostic Stage | Decision Tree | Anatomic: Rural Accuracy: 0.93; Urban Accuracy 0.86; Rural F1-score 0.9638; Urban F1-score 0.9123; Prognostic: Rural Accuracy: 0.92; Urban Accuracy: 0.82; Rural F1-score: 0.9521; Urban F1-score: 0.8765; | 5-fold Cross-validation | 465 Medical Records * | Private: From India’s cancer treatment institutions (Nurgis Dutta Memorial Cancer Hospital in the rural region and Jehangir Hospital urban and laboratories in the urban region) |
| 3 | [19] | 2021 | Free-text Clinical Notes (Unstructured) | English | Breast Cancer | Classify Breast Cancer Recurrence | Long Short-Term Memory (LSTM) | AUC 0.94; Sensitivity 0.89; Specificity 0.84; | 5-fold Cross-validation | Embedding: 92.6 million Clinical Notes Prediction: 892,550 Clinical Notes * | Public: Clinical language space: I2B2 NLP research database [30], MIMIC-III critical care database [31], Oncoshare breast cancer database [32] |
| 4 | [20] | 2021 | Mammography Reports (Unstructured) | Chinese | Breast Cancer | Classify Breast Cancer | BERT | Micro: AUC: 0.94; Precision: 0.9158; Recall: 0.9158; F1-score: 0.9158; Macro: AUC: 0.85; Precision: 0.7595; Recall: 0.7973; F1-score: 0.7714 | N/A | 2857 Mammography Reports; 2078 Benign; 448 Suspected of Malignant; 331 Malignant | Private: From Shanghai Ruijin Hospital |
| 5 | [21] | 2021 | Histopathology Report (Unstructured) | English | Breast Cancer | Classify Breast Cancer Recurrence | One Rule (OneR) | Accuracy: 0.901; Sensitivity: 0.901; Specificity: 0.722; | 10-fold Cross-validation | 142 Histopathology Report * | Private: From King Abdullah University Hospital (KAUH) in Jordan |
| 6 | [22] | 2020 | Progress Notes and Pathology Notes of EHR (Unstructured + Structured) | English | Breast Cancer | Classify Breast Cancer Recurrence | Knowledge-guided Convolutional Neural Networks (K-CNN) | AUC: 0.888; Precision: 0.537; Recall: 0.468; F1-score: 0.500; Specificity: 0.968; | 5-fold Cross-validation | 6447 Subjects; 446 Positive; 6001 Negative | Private: From Northwestern Medicine Enterprise Data Warehouse (NMEDW) |
| 7 | [24] | 2019 | Clinical Notes (Unstructured) | English | Breast Cancer | Classify Breast Cancer Recurrence | Neural Network | Quarter-Level: AUC 0.9; Definite Recurrence: Specificity 0.82; Sensitivity 0.73; F1-score 0.77; No Recurrence: Specificity 0.99; Sensitivity 0.99; F1-score 0.99; Patient-Level: Specificity 0.95; Sensitivity 0.93; F1-score 0.94; | Validation | 894 Subjects * | Public: Oncoshare breast cancer database [32] |
| 8 | [25] | 2018 | Pathology Reports of EHR (Unstructured) | English | Breast Cancer | Classify Breast Cancer Recurrence | Support Vector Machine (SVM) | Precision 0.5; Recall 0.81; F1-score: 0.62; AUC: 0.87; | 5-fold Cross-validation | 6899 Subjects; 581 Positive; 6318 Negative; | Private: From Northwestern Medicine Enterprise Data Warehouse (NMEDW). |
| 9 | [26] | 2018 | EHR (Unstructured + Structured) | English | Breast Cancer | Classify Derived Breast Cancer (BC) Receptor Status Phenotypes | Rule-based | Estrogen Receptor (ER): Precision: 0.9758; Recall: 0.9877; F1-score: 0.9818; Progesterone Receptor (PR): Precision: 0.9857; Recall: 0.9418; F1-score: 0.9632; Human Epidermal Growth Factor Receptor 2 (HER2): Precision: 0.6977; Recall: 0.6667; F1-score: 0.6818; Triple Negative (TN): Precision: 0.7222; Recall: 0.6848; F1-score: 0.7027 | N/A | 871 Subjects * | Private: From Mayo Clinic, Rochester, Minnesota |
| 10 | [27] | 2016 | Mammography Reports (Unstructured) | English | Breast Cancer | Classify Breast Cancer | Bayesian Network (BN) | Accuracy 0.9815; | N/A | 300 Mammography Reports * | Private: From An Academic Radiology Practice |
| 11 | [28] | 2015 | Pathology reports (Unstructured) | English | Breast Cancer | Classify the Breast Cancer Stages | Rule-based | Tumor (T) Classification: Precision: 0.79; Recall: 0.75; Accuracy: 0.76, Lymph Nodes (N) Classification: Precision: 0.81; Recall: 0.63; Accuracy: 0.66; Cancer Stage Classification: Precision: 0.729; Recall: 0.825; Specificity: 0.587; NPV: 0.711; Accuracy: 0.722 | N/A | 150 Pathology Reports * | Private: From Christian Medical College and Hospital |
| 12 | [29] | 2014 | Clinical Text of EHR (Unstructured) | English | Breast Cancer | Classify Breast Cancer Recurrence | Clinical Text Analysis and Knowledge Extraction System (cTAKES) | Sensitivity: 0.92; Specificity: 0.96; PPV: 0.66; F1-score: 0.76; | N/A | 1472 Subjects; 141 Positive; 1331 Negative | Private: From the Commonly Used Medications and Breast Cancer Recurrence (COMBO) Study Conducted at Group Health, An Integrated Health Care Delivery System in the Pacific Northwest |
4.2. Colorectal Cancer
| SN | Reference | Year | Source of Text | Language | Cancer Type | Aim | Algorithm | Evaluation Metrics | Validation | Dataset Size | Dataset Source |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | [34] | 2022 | Pathology Reports (Unstructured) | English | Colorectal Cancer | Classify Cases with Primary Colonic Adenocarcinoma | CNN | Accuracy: 0.92; AUC 0.957 | Validation | 1000 Anatomic Pathology Reports; 713 Positive; 287 Negative | N/A |
| 2 | [35] | 2020 | Colonoscopy and Pathology Reports of EMR (Unstructured) | English | Colorectal Cancer | Classify Serrated Polyposis Syndrome (SPS) | Rule-based | Accuracy: 0.93 | N/A | 255,074 Patients; 71 Positive; 255,003 Negative | Private: From Cleveland Clinic, Cleveland, Ohio |
| 3 | [36] | 2015 | Pathology and Colonoscopy Reports (Unstructured) | English | Colorectal Cancer | Classify Adenomas and Sessile Serrated Adenomas (SSAs) | Rule-based | Screening Accuracy: 0.913; Adenomas Accuracy: 0.994; SSAs Accuracy: 1; | N/A | 12,748 Patients; 2288 Positive; 10,460 Negative | Private: From the University of Texas MD Anderson Cancer Center |
| 4 | [37] | 2012 | EHR (Unstructured + Structured) | English | Colorectal Cancer | Classify the Colorectal Cancer (CRC) Test, Classify Patients in Need of Screening | Knowledge Map Concept Identifier (KMCI) | CRC Classification: Recall: 0.93; Precision: 0.94; F1-score: 0.94; Patients Classification: Recall: 0.95; Precision: 0.88; F1-score: 0.91; | N/A | 500 EHR Records * | Private: From four Vanderbilt University Medical Center (VUMC)-affiliated ambulatory health care clinics in Nashville, Tennessee |
4.3. Lung Cancer
| SN | Reference | Year | Source of Text | Language | Cancer Type | Aim | Algorithm | Evaluation Metrics | Validation | Dataset Size | Dataset Source |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | [39] | 2021 | Free-text Radiological Reports (Unstructured) | English | Lung Cancer | Classify T-stage and T-substage | Rule-based | T-stage: Accuracy: 0.89; T-substage: Accuracy: 0.84; Average Precision: 0.8375; Average Recall: 0.825; Average F1-score: 0.81375; | N/A | 425 Radiological Reports * | Private: From the Departments of Radiation Oncology and Radiology, Brigham and Women’s Hospital/Dana-Farber Cancer Institute (Boston, United States of America) |
| 2 | [40] | 2021 | EHR (Unstructured + Structured) | English | Lung Cancer | Classify Lung Cancer and Prognostic | Lung Cancer Classification: Logistic Regression, Prognostic Classification: Cox Regression | Lung Cancer: AUC: 0.927; Specificity: 0.9; Sensitivity: 0.752; Precision: 0.994; F1-score: 0.837; Prognostic: AUC (1-year): 0.828; AUC (2-year): 0.825; AUC (3-year): 0.814; AUC (4-year): 0.814; AUC (5-year): 0.812; | Cross-validation | 76,643 Patients * | Private: From Massachusetts General Hospital (MGH) and Brigham and Women’s Hospital |
| 3 | [41] | 2018 | CT Reports (Unstructured) | English | Lung Cancer | Classify Lung Cancer | cTAKES | Sensitivity: 0.773; Specificity: 0.725; PPV: 0.884; NPV: 0.54; | N/A | 446 Chest CT Reports; 326 Positive; 120 Negative | Private: From Veterans Affairs Connecticut Healthcare System |
4.4. Other Cancers
| SN | Reference | Year | Source of Text | Language | Cancer Type | Aim | Algorithm | Evaluation Metrics | Validation | Dataset Size | Dataset Source |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | [42] | 2020 | Radiology Reports of EMR (Unstructured) | Chinese | Liver Cancer | Named Entity Recognition (NER), Classify Liver Cancer | NER: Bidirectional Long Short-term Memory (BiLSTM), Liver Cancer Classification: Random Forest | NER: Precision: 0.9235; Recall: 0.9366; F1-score: 0.9300; Liver Cancer Classification: Precision: 0.8771; Recall: 0.8625; F1-score: 0.8697 | 5-fold Cross-validation | 609 Radiology Reports * | Private: From Beijing Friendship Hospital, Capital Medical University, Beijing, China |
| 2 | [44] | 2020 | Magnetic Resonance Imaging (MR) Reports (Unstructured + Structured) | English | Brain Tumor | Classify Brain Tumor | Ensemble Model (ElasticNet + RandomForest + Gradient boosting (XGBoost)) | Structured Text (Tf-idf + Ensemble): F1-score: 0.98; Unstructured Text (word2vec + Ensemble): 0.72; | N/A | 26,000 Brain MR Reports; 1410 BT-RADS Reports * | Private: From a Single Academic Institution |
| 3 | [47] | 2020 | Clinical Notes of EHR (Unstructured) | English | Prostate Cancer | Classify Urinary Incontinence (UI) | Rule-based | Accuracy 0.86; Average Precision: 0.957; Average Recall: 0.833; Average F1-score: 0.887; | 5-fold Cross-validation for CNN | 259 Clinical Notes; 87 Mild; 79 Moderate; 93 Severe | Private: From the Stanford University EHR with the Stanford Cancer Institute Research Database (SCIRDB) and the California Cancer Registry (CCR) |
| 4 | [48] | 2015 | Free Text of EMR (Unstructured) | English | Pancreatic Cancer | Classify Pancreatic cyst | Rule-based | Mean Sensitivity: 0.9985; Mean Specificity: 0.988; | N/A | 566,233 Reports * | Private: From Wishard Memorial Hospital |
5. Discussion
5.1. Current Trends
5.1.1. NLP Algorithms
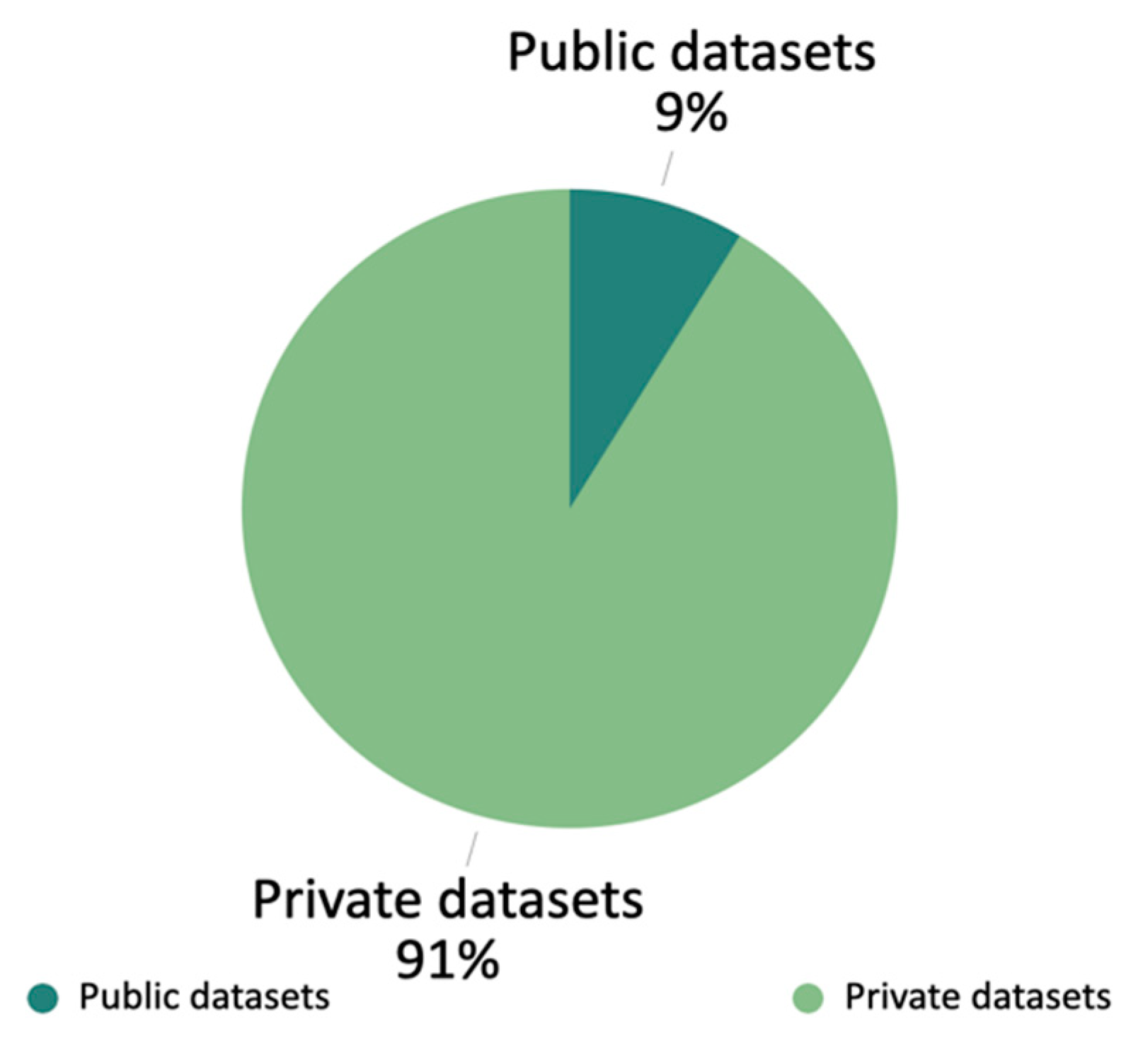
5.1.2. Datasets and Disease Types
5.2. Challenges
5.2.1. Dataset Limitations
5.2.2. Validation Limitations
5.3. Future Trends
5.3.1. Federated Learning
5.3.2. Explainable Artificial Intelligence
5.3.3. Semi-Supervised Learning
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Savova, G.K.; Danciu, I.; Alamudun, F.; Miller, T.; Lin, C.; Bitterman, D.S.; Tourassi, G.; Warner, J.L. Use of Natural Language Processing to Extract Clinical Cancer Phenotypes from Electronic Medical RecordsNatural Language Processing for Cancer Phenotypes from EMRs. Cancer Res. 2019, 79, 5463–5470. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ribelles, N.; Jerez, J.M.; Rodriguez-Brazzarola, P.; Jimenez, B.; Diaz-Redondo, T.; Mesa, H.; Marquez, A.; Sanchez-Muñoz, A.; Pajares, B.; Carabantes, F. Machine Learning and Natural Language Processing (NLP) Approach to Predict Early Progression to First-Line Treatment in Real-World Hormone Receptor-Positive (HR+)/HER2-Negative Advanced Breast Cancer Patients. Eur. J. Cancer 2021, 144, 224–231. [Google Scholar] [CrossRef]
- Zhang, D.; Yin, C.; Zeng, J.; Yuan, X.; Zhang, P. Combining Structured and Unstructured Data for Predictive Models: A Deep Learning Approach. BMC Med. Inform. Decis. Mak. 2020, 20, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Zebari, D.A.; Ibrahim, D.A.; Zeebaree, D.Q.; Haron, H.; Salih, M.S.; Damaševičius, R.; Mohammed, M.A. Systematic Review of Computing Approaches for Breast Cancer Detection Based Computer Aided Diagnosis Using Mammogram Images. Appl. Artif. Intell. 2021, 35, 2157–2203. [Google Scholar] [CrossRef]
- Luo, J.W.; Chong, J.J.R. Review of Natural Language Processing in Radiology. Neuroimaging Clin. 2020, 30, 447–458. [Google Scholar] [CrossRef] [PubMed]
- Zhou, M.; Duan, N.; Liu, S.; Shum, H.-Y. Progress in Neural NLP: Modeling, Learning, and Reasoning. Engineering 2020, 6, 275–290. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Xiong, W.; Wu, L.; Alleva, F.; Droppo, J.; Huang, X.; Stolcke, A. The Microsoft 2017 Conversational Speech Recognition System. In Proceedings of the 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP), Calgary, AB, Canada, 15–20 April 2015; pp. 5934–5938. [Google Scholar]
- Jakkula, V. Tutorial on Support Vector Machine (Svm). Sch. EECS Wash. State Univ. 2006, 37, 3. [Google Scholar]
- Quinlan, J.R. Learning Decision Tree Classifiers. ACM Comput. Surv. (CSUR) 1996, 28, 71–72. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Elman, J.L. Finding Structure in Time. Cogn. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. Adv. Neural. Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Giaquinto, A.N.; Sung, H.; Miller, K.D.; Kramer, J.L.; Newman, L.A.; Minihan, A.; Jemal, A.; Siegel, R.L. Breast Cancer Statistics, 2022. CA Cancer J. Clin. 2022, 72, 524–541. [Google Scholar] [CrossRef] [PubMed]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Kaka, H.; Michalopoulos, G.; Subendran, S.; Decker, K.; Lambert, P.; Pitz, M.; Singh, H.; Chen, H. Pretrained Neural Networks Accurately Identify Cancer Recurrence in Medical Record. In Challenges of Trustable AI and Added-Value on Health; IOS Press: Amsterdam, The Netherlands, 2022; pp. 93–97. [Google Scholar]
- Alsentzer, E.; Murphy, J.R.; Boag, W.; Weng, W.-H.; Jin, D.; Naumann, T.; McDermott, M. Publicly Available Clinical BERT Embeddings. arXiv 2019, arXiv:1904.03323. [Google Scholar]
- Deshmukh, P.R.; Phalnikar, R. Information Extraction for Prognostic Stage Prediction from Breast Cancer Medical Records Using NLP and ML. Med Biol. Eng. Comput. 2021, 59, 1751–1772. [Google Scholar] [CrossRef]
- Sanyal, J.; Tariq, A.; Kurian, A.W.; Rubin, D.; Banerjee, I. Weakly Supervised Temporal Model for Prediction of Breast Cancer Distant Recurrence. Sci. Rep. 2021, 11, 1–11. [Google Scholar] [CrossRef]
- Chen, D.; Zhong, K.; He, J. BDCN: Semantic Embedding Self-Explanatory Breast Diagnostic Capsules Network. In Proceedings of the China National Conference on Chinese Computational Linguistics; Springer: Hohhot, China, 2021; pp. 419–433. [Google Scholar]
- Alzu’bi, A.; Najadat, H.; Doulat, W.; Al-Shari, O.; Zhou, L. Predicting the Recurrence of Breast Cancer Using Machine Learning Algorithms. Multimedia Tools Appl. 2021, 80, 13787–13800. [Google Scholar] [CrossRef]
- Wang, H.; Li, Y.; Khan, S.A.; Luo, Y. Prediction of Breast Cancer Distant Recurrence Using Natural Language Processing and Knowledge-Guided Convolutional Neural Network. Artif. Intell. Med. 2020, 110, 101977. [Google Scholar] [CrossRef]
- Yao, L.; Mao, C.; Luo, Y. Clinical Text Classification with Rule-Based Features and Knowledge-Guided Convolutional Neural Networks. BMC Med. Inform. Decis. Mak. 2019, 19, 31–39. [Google Scholar] [CrossRef] [Green Version]
- Banerjee, I.; Bozkurt, S.; Caswell-Jin, J.L.; Kurian, A.W.; Rubin, D.L. Natural Language Processing Approaches to Detect the Timeline of Metastatic Recurrence of Breast Cancer. JCO Clin. Cancer Inform. 2019, 3, 1–12. [Google Scholar] [CrossRef]
- Zeng, Z.; Espino, S.; Roy, A.; Li, X.; Khan, S.A.; Clare, S.E.; Jiang, X.; Neapolitan, R.; Luo, Y. Using Natural Language Processing and Machine Learning to Identify Breast Cancer Local Recurrence. BMC Bioinform. 2018, 19, 65–74. [Google Scholar] [CrossRef] [PubMed]
- Breitenstein, M.K.; Liu, H.; Maxwell, K.N.; Pathak, J.; Zhang, R. Electronic Health Record Phenotypes for Precision Medicine: Perspectives and Caveats from Treatment of Breast Cancer at a Single Institution. Clin. Transl. Sci. 2018, 11, 85–92. [Google Scholar] [CrossRef] [PubMed]
- Bozkurt, S.; Gimenez, F.; Burnside, E.S.; Gulkesen, K.H.; Rubin, D.L. Using Automatically Extracted Information from Mammography Reports for Decision-Support. J. Biomed. Inform. 2016, 62, 224–231. [Google Scholar] [CrossRef]
- Gladis, D.; Manipadam, M.T.; Ishitha, G. Breast Cancer Staging Using Natural Language Processing. In Proceedings of the 2015 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Kochi, India, 10–13 August 2015; pp. 1552–1558. [Google Scholar]
- Carrell, D.S.; Halgrim, S.; Tran, D.-T.; Buist, D.S.M.; Chubak, J.; Chapman, W.W.; Savova, G. Using Natural Language Processing to Improve Efficiency of Manual Chart Abstraction in Research: The Case of Breast Cancer Recurrence. Am. J. Epidemiol. 2014, 179, 749–758. [Google Scholar] [CrossRef] [PubMed]
- Uzuner, Ö.; Stubbs, A. Practical Applications for Natural Language Processing in Clinical Research: The 2014 I2b2/UTHealth Shared Tasks. J. Biomed. Inform. 2015, 58, S1. [Google Scholar] [CrossRef]
- Johnson, A.E.W.; Pollard, T.J.; Shen, L.; Lehman, L.H.; Feng, M.; Ghassemi, M.; Moody, B.; Szolovits, P.; Anthony Celi, L.; Mark, R.G. MIMIC-III, a Freely Accessible Critical Care Database. Sci. Data 2016, 3, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Weber, S.C.; Seto, T.; Olson, C.; Kenkare, P.; Kurian, A.W.; Das, A.K. Oncoshare: Lessons Learned from Building an Integrated Multi-Institutional Database for Comparative Effectiveness Research. In Proceedings of the AMIA Annual Symposium Proceedings, San Diego, CA, USA, 5–9 November 2012; Volume 2012, p. 970. [Google Scholar]
- Biller, L.H.; Schrag, D. Diagnosis and Treatment of Metastatic Colorectal Cancer: A Review. JAMA 2021, 325, 669–685. [Google Scholar] [CrossRef]
- Cheng, J. Neural Network Assisted Pathology Case Identification. J. Pathol. Inform. 2022, 13, 100008. [Google Scholar] [CrossRef]
- Parthasarathy, G.; Lopez, R.; McMichael, J.; Burke, C.A. A Natural Language–Based Tool for Diagnosis of Serrated Polyposis Syndrome. Gastrointest. Endosc. 2020, 92, 886–890. [Google Scholar] [CrossRef]
- Raju, G.S.; Lum, P.J.; Slack, R.S.; Thirumurthi, S.; Lynch, P.M.; Miller, E.; Weston, B.R.; Davila, M.L.; Bhutani, M.S.; Shafi, M.A. Natural Language Processing as an Alternative to Manual Reporting of Colonoscopy Quality Metrics. Gastrointest. Endosc. 2015, 82, 512–519. [Google Scholar] [CrossRef] [Green Version]
- Denny, J.C.; Choma, N.N.; Peterson, J.F.; Miller, R.A.; Bastarache, L.; Li, M.; Peterson, N.B. Natural Language Processing Improves Identification of Colorectal Cancer Testing in the Electronic Medical Record. Med. Decis. Mak. 2012, 32, 188–197. [Google Scholar] [CrossRef] [PubMed]
- Schabath, M.B.; Cote, M.L. Cancer Progress and Priorities: Lung Cancer. Cancer Epidemiol. Biomark. Prev. 2019, 28, 1563–1579. [Google Scholar] [CrossRef] [Green Version]
- Nobel, J.M.; Puts, S.; Weiss, J.; Aerts, H.J.W.L.; Mak, R.H.; Robben, S.G.F.; Dekker, A.L.A.J. T-Staging Pulmonary Oncology from Radiological Reports Using Natural Language Processing: Translating into a Multi-Language Setting. Insights Imaging 2021, 12, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Yuan, Q.; Cai, T.; Hong, C.; Du, M.; Johnson, B.E.; Lanuti, M.; Cai, T.; Christiani, D.C. Performance of a Machine Learning Algorithm Using Electronic Health Record Data to Identify and Estimate Survival in a Longitudinal Cohort of Patients with Lung Cancer. JAMA Netw. Open 2021, 4, e2114723. [Google Scholar] [CrossRef] [PubMed]
- Wadia, R.; Akgun, K.; Brandt, C.; Fenton, B.T.; Levin, W.; Marple, A.H.; Garla, V.; Rose, M.G.; Taddei, T.; Taylor, C. Comparison of Natural Language Processing and Manual Coding for the Identification of Cross-Sectional Imaging Reports Suspicious for Lung Cancer. JCO Clin. Cancer Inform. 2018, 2, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Xu, Y.; Zhang, Z.; Wang, N.; Huang, Y.; Hu, Y.; Yang, Z.; Jiang, R.; Chen, H. A Natural Language Processing Pipeline of Chinese Free-Text Radiology Reports for Liver Cancer Diagnosis. Ieee Access 2020, 8, 159110–159119. [Google Scholar] [CrossRef]
- Ho, T.K. Random Decision Forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; Volume 1, pp. 278–282. [Google Scholar]
- Lee, S.J.; Weinberg, B.D.; Gore, A.; Banerjee, I. A Scalable Natural Language Processing for Inferring BT-RADS Categorization from Unstructured Brain Magnetic Resonance Reports. J. Digit. Imaging 2020, 33, 1393–1400. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and Variable Selection via the Elastic Net. J. R Stat. Soc. Ser. B Stat. Methodol. 2005, 67, 301–320. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Bozkurt, S.; Paul, R.; Coquet, J.; Sun, R.; Banerjee, I.; Brooks, J.D.; Hernandez-Boussard, T. Phenotyping Severity of Patient-centered Outcomes Using Clinical Notes: A Prostate Cancer Use Case. Learn Health Syst. 2020, 4, e10237. [Google Scholar] [CrossRef]
- Roch, A.M.; Mehrabi, S.; Krishnan, A.; Schmidt, H.E.; Kesterson, J.; Beesley, C.; Dexter, P.R.; Palakal, M.; Schmidt, C.M. Automated Pancreatic Cyst Screening Using Natural Language Processing: A New Tool in the Early Detection of Pancreatic Cancer. Hpb 2015, 17, 447–453. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Esteva, A.; Chou, K.; Yeung, S.; Naik, N.; Madani, A.; Mottaghi, A.; Liu, Y.; Topol, E.; Dean, J.; Socher, R. Deep Learning-Enabled Medical Computer Vision. NPJ Digit. Med. 2021, 4, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M. Huggingface’s Transformers: State-of-the-Art Natural Language Processing. arXiv 2019, arXiv:1910.03771. [Google Scholar]
- Baldi, P.; Sadowski, P.J. Understanding Dropout. In Proceedings of the Advances in Neural Information Processing Systems 26 (NIPS 2013), Lake Tahoe, NV, USA, 5–8 December 2013. [Google Scholar]
- Inoue, H. Multi-Sample Dropout for Accelerated Training and Better Generalization. arXiv 2019, arXiv:1905.09788. [Google Scholar]
- Rahib, L.; Wehner, M.R.; Matrisian, L.M.; Nead, K.T. Estimated Projection of US Cancer Incidence and Death to 2040. JAMA Netw. Open 2021, 4, e214708. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Ma, Z.; Liu, X.; Ma, S.; Nepal, S.; Deng, R. Boosting Privately: Privacy-Preserving Federated Extreme Boosting for Mobile Crowdsensing. arXiv 2019, arXiv:1907.10218. [Google Scholar]
- Roy, A.G.; Siddiqui, S.; Pölsterl, S.; Navab, N.; Wachinger, C. Braintorrent: A Peer-to-Peer Environment for Decentralized Federated Learning. arXiv 2019, arXiv:1905.06731. [Google Scholar]
- Li, W.; Milletarì, F.; Xu, D.; Rieke, N.; Hancox, J.; Zhu, W.; Baust, M.; Cheng, Y.; Ourselin, S.; Cardoso, M.J. Privacy-Preserving Federated Brain Tumour Segmentation. In Proceedings of the International Workshop on Machine Learning in Medical Imaging; Springer: Berlin/Heidelberg, Germany, 2019; pp. 133–141. [Google Scholar]
- Basu, P.; Roy, T.S.; Naidu, R.; Muftuoglu, Z.; Singh, S.; Mireshghallah, F. Benchmarking Differential Privacy and Federated Learning for Bert Models. arXiv 2021, arXiv:2106.13973. [Google Scholar]
- Xie, Y.; Gao, G.; Chen, X. Outlining the Design Space of Explainable Intelligent Systems for Medical Diagnosis. arXiv 2019, arXiv:1902.06019. [Google Scholar]
- Zhang, Y.; Weng, Y.; Lund, J. Applications of Explainable Artificial Intelligence in Diagnosis and Surgery. Diagnostics 2022, 12, 237. [Google Scholar] [CrossRef]
- Nurdin, N. Explainable Artificial Intelligence (XAI) towards Model Personality in NLP Task. IPTEK J. Eng. 2021, 7, 11–15. [Google Scholar]
- Trigueros, O.; Blanco, A.; Lebeña, N.; Casillas, A.; Pérez, A. Explainable ICD Multi-Label Classification of EHRs in Spanish with Convolutional Attention. Int. J. Med. Inform. 2022, 157, 104615. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Nan, F.; Yang, P.; Meng, Q.; Xie, Y.; Zhang, D.; Muhammad, K. GAN-Based Semi-Supervised Learning Approach for Clinical Decision Support in Health-IoT Platform. IEEE Access 2019, 7, 8048–8057. [Google Scholar] [CrossRef]
- Liu, L.; Wu, X.; Liu, H.; Cao, X.; Wang, H.; Zhou, H.; Xie, Q. A Semi-Supervised Approach for Extracting TCM Clinical Terms Based on Feature Words. BMC Med. Inform. Decis. Mak. 2020, 20, 1–7. [Google Scholar] [CrossRef] [PubMed]







| Method | Formula | Description |
|---|---|---|
| Accuracy | Percentage of total sample with correct predictions | |
| Precision | The probability of all samples predicted to be positive being truly positive | |
| Recall/Sensitivity/TPR | The probability of samples that are truly positive being predicted as positive samples | |
| Specificity/PPV | The probability of samples that are truly negative being predicted as negative samples | |
| NPV | The probability that following a negative test result, that samples will truly be negative | |
| FPR | The probability between the number of negative samples incorrectly classified as positive and the total number of actual negative samples | |
| F-score/F1 | The maximum balance between recall and precision of the model | |
| ROC | N/A | A more comprehensive evaluation of the model using the curves constructed from sensitivity and specificity |
| AUC | N/A | Area under the ROC curve |
| First Screening | Second Screening |
|---|---|
| To screen out the reviews (exclusion criterion) | To filter out whether the purposes in full text are consistent with diagnosis (inclusion criterion) |
| To remove the duplicate papers (exclusion criterion) | To choose the papers whose specific role of NLP models in full text is the computer-aided diagnosis (inclusion criterion) |
| To filter out the papers based on their titles and abstracts (exclusion criterion) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Zhang, Y.; Weng, Y.; Wang, B.; Li, Z. Natural Language Processing Applications for Computer-Aided Diagnosis in Oncology. Diagnostics 2023, 13, 286. https://doi.org/10.3390/diagnostics13020286
Li C, Zhang Y, Weng Y, Wang B, Li Z. Natural Language Processing Applications for Computer-Aided Diagnosis in Oncology. Diagnostics. 2023; 13(2):286. https://doi.org/10.3390/diagnostics13020286
Chicago/Turabian StyleLi, Chengtai, Yiming Zhang, Ying Weng, Boding Wang, and Zhenzhu Li. 2023. "Natural Language Processing Applications for Computer-Aided Diagnosis in Oncology" Diagnostics 13, no. 2: 286. https://doi.org/10.3390/diagnostics13020286
APA StyleLi, C., Zhang, Y., Weng, Y., Wang, B., & Li, Z. (2023). Natural Language Processing Applications for Computer-Aided Diagnosis in Oncology. Diagnostics, 13(2), 286. https://doi.org/10.3390/diagnostics13020286