

Prediction of Acid-Base and Potassium Imbalances in Intensive Care Patients Using Machine Learning Techniques
 , , , and
, , , and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Dataset
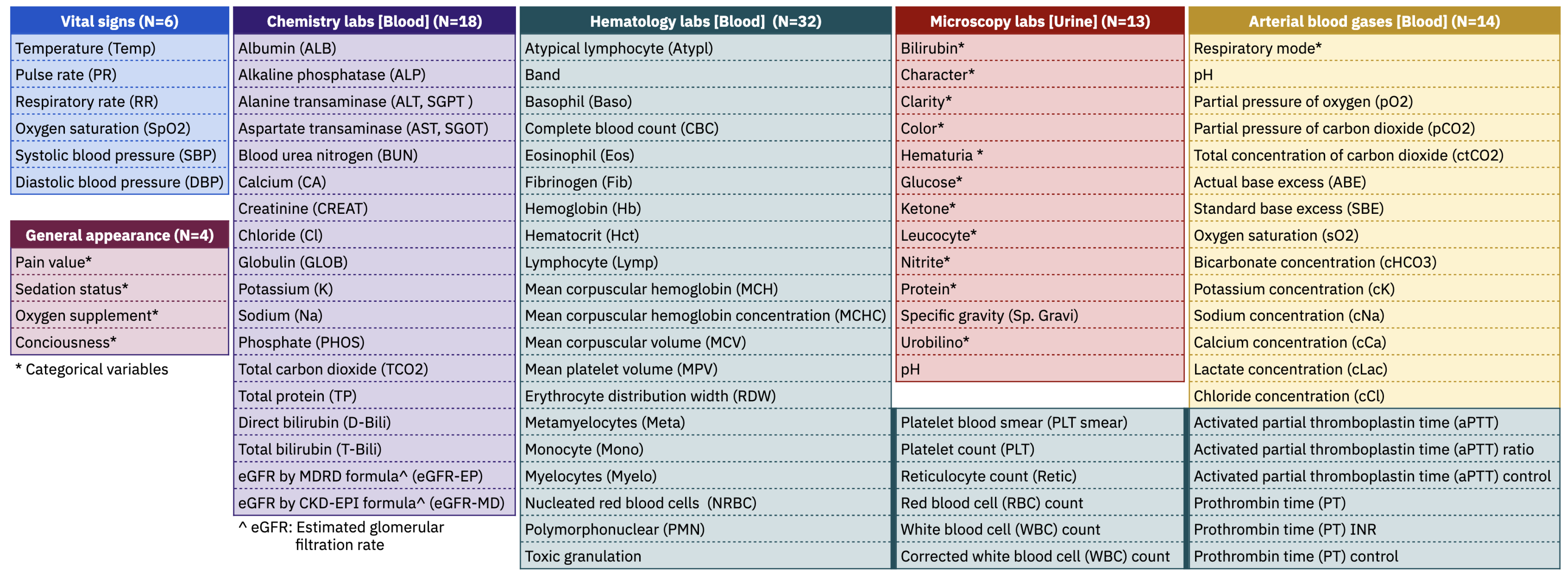
2.2. Clinical Variables
2.3. Clinical Conditions
2.3.1. Mortality
2.3.2. Hypocapnia and Hypercapnia
2.3.3. Hypokalemia and Hyperkalemia
2.3.4. Metabolic Acidosis and Metabolic Alkalosis
2.3.5. Respiratory Acidosis and Respiratory Alkalosis
2.3.6. Annotation of Clinical Conditions
2.4. Data Preparation
2.5. Machine Learning Models
2.5.1. K Nearest Neighbours
2.5.2. Random Forests
2.5.3. Support Vector Machine
2.5.4. Gradient Boosting
2.6. Evaluation Metrics
3. Results
4. Discussion
4.1. Comparison to Other Studies
4.2. Calibration Curves
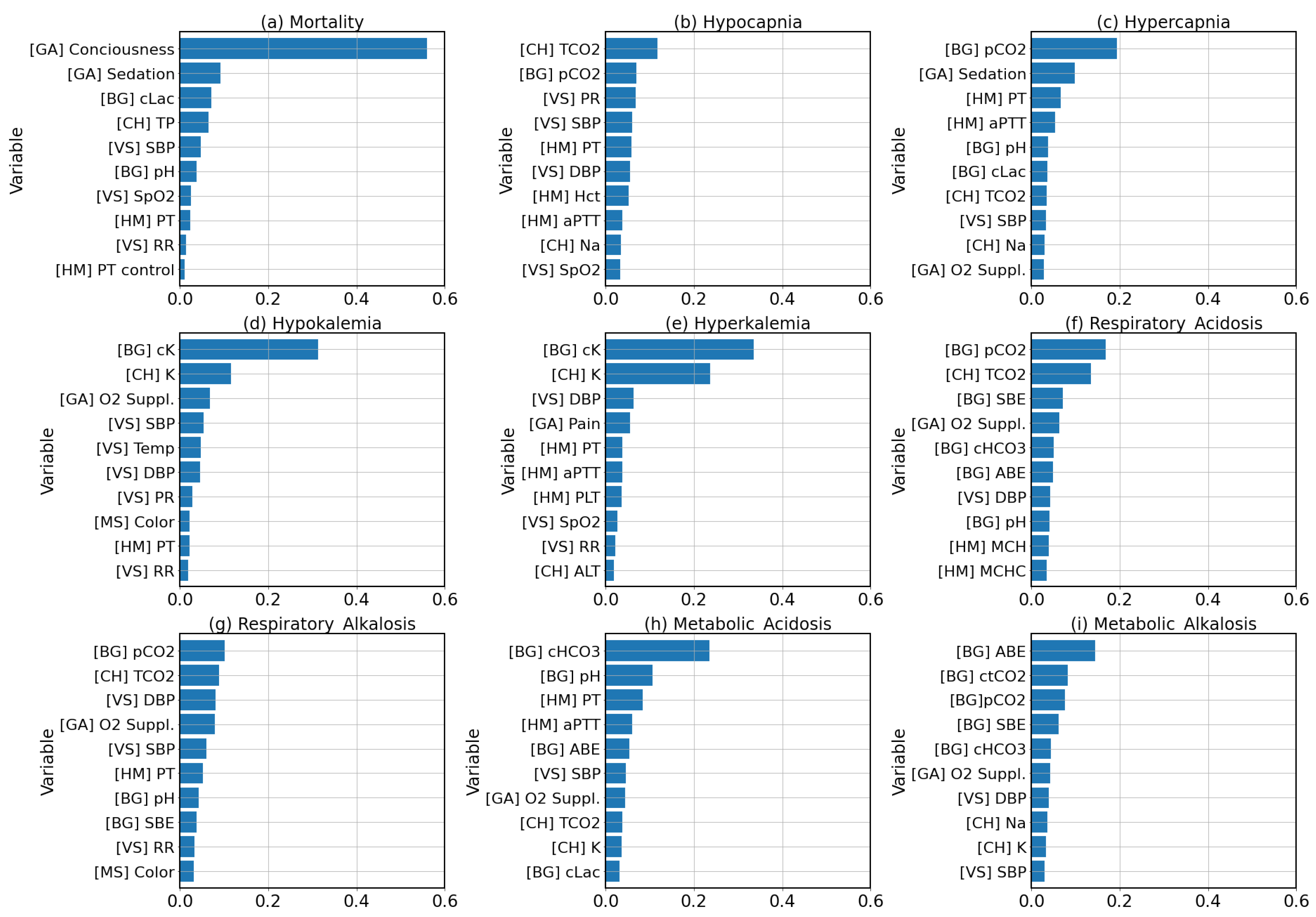
4.3. Feature Importance
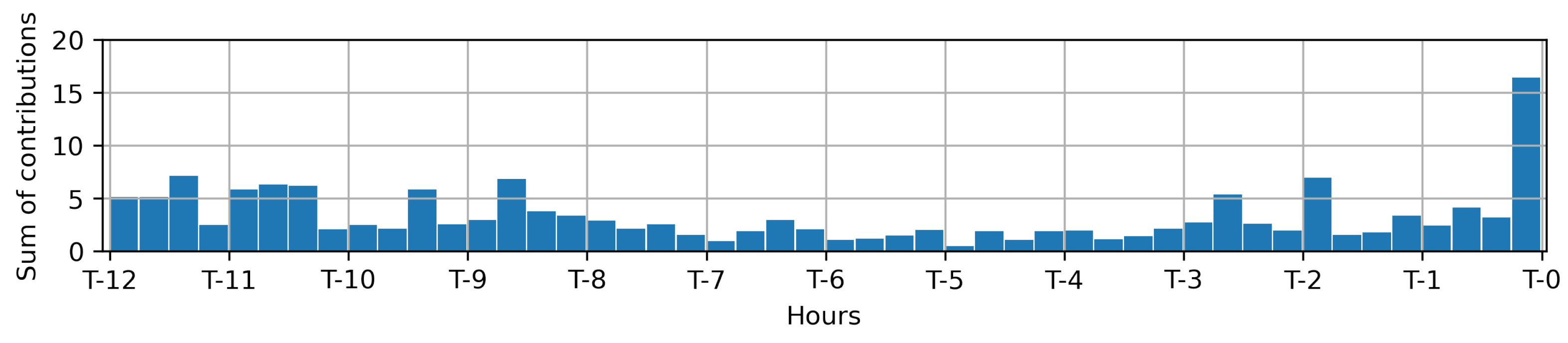
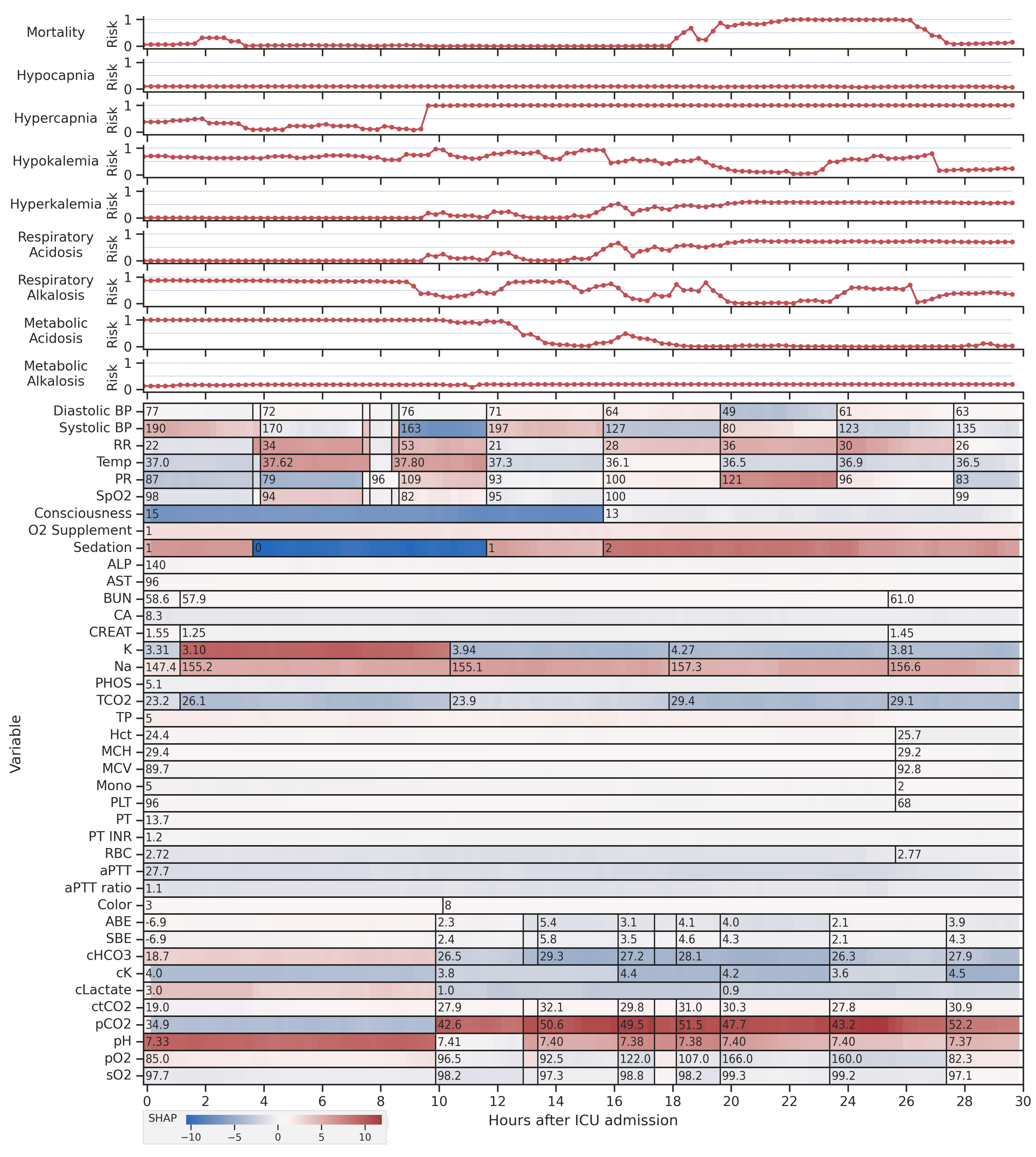
4.4. Feature Explanations
4.5. Limitations
4.6. Future Work
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ABE | Actual Base Excess |
| ALB | Albumin |
| ALP | Alkaline Phosphatase |
| ALT | Alanine Transaminase |
| APACHE | Acute Physiology And Chronic Health Evaluation |
| aPTT | Activated Partial Thromboplastin Time |
| AST | Aspartate Transaminase |
| AUPRC | Area Under The Precision Recall Curve |
| AUROC | Area Under The Receiver Operating Characteristic Curve |
| BUN | Blood Urea Nitrogen |
| CA | Calcium |
| cCa2+ | Calcium Concentration |
| cCl− | Chloride Concentration |
| cHCO3− | Bicarbonate Concentration |
| cK+ | Potassium Concentration |
| CKD | Chronic Kidney Disease |
| Cl− | Chloride |
| cLac | Lactate Concentration |
| cNa+ | Sodium Concentration |
| CO | Carbon Dioxide |
| CREAT | Creatinine |
| ctCO2 | Total Concentration Of Carbon Dioxide |
| DBP | Diastolic Blood Pressure |
| EHR | Electronic Health Record |
| EWS | Early Warning Score |
| GB | Gradient Boosting |
| GLOB | Globulin |
| ICU | Intensive Dare Unit |
| K+ | Potassium |
| KNN | K Nearest Neighbours |
| LSTM | Long Short-Term Memory |
| MCH | Mean Corpuscular Hemoglobin |
| MCHC | Mean Corpuscular Hemoglobin Concentration |
| MCV | Mean Corpuscular Volume |
| MEWS | Modified Early Warning Score |
| MICU | Medical Intensive Care Unit |
| Mono | Monocyte |
| Na+ | Sodium |
| NEWS | National Early Warning Score |
| pCO2 | Partial Pressure Of Carbon Dioxide |
| PHOS | Phosphate |
| PLT | Platelet |
| pO2 | Partial Pressure Of Oxygen |
| PR | Pulse Rate |
| PT | Prothrombin Time |
| RBC | Red Blood Cell |
| RF | Random Forest |
| ROC | Receiver Operating Characteristic |
| RR | Respiratory Rate |
| SAPS | Simplified Acute Physiology Score |
| SBE | Standard Base Excess |
| SBP | Systolic Blood Pressure |
| SHAP | Shapley Additive Explanations |
| SIRS | Systemic Inflammatory Response Syndrome |
| sO2 | Oxygen Saturation |
| SpO2 | Oxygen Saturation |
| SQL | Structured Query Language |
| SVM | Support Vector Machine |
| TCO2 | Total Carbon Dioxide |
| TP | Total Protein |
References
- Adhikari, N.K.; Fowler, R.A.; Bhagwanjee, S.; Rubenfeld, G.D. Critical care and the global burden of critical illness in adults. Lancet 2010, 376, 1339–1346. [Google Scholar] [CrossRef] [PubMed]
- Bhagavan, N.; Ha, C.E. Water, Electrolytes, and Acid–Base Balance. In Essentials of Medical Biochemistry; Elsevier: Amsterdam, The Netherlands, 2015; pp. 701–713. [Google Scholar] [CrossRef]
- Quinteros, L.M.; Roque, J.B.; Kaufman, D.; Raventós, A.A. Importance of carbon dioxide in the critical patient: Implications at the cellular and clinical levels. Med. Intensiv. (Engl. Ed.) 2019, 43, 234–242. [Google Scholar] [CrossRef]
- Forsal, I.; Bodelsson, M.; Wieslander, A.; Nilsson, A.; Pouchoulin, D.; Broman, M. Analysis of acid–base disorders in an ICU cohort using a computer script. Intensive Care Med. Exp. 2022, 10. [Google Scholar] [CrossRef] [PubMed]
- Hamm, L.L.; Hering-Smith, K.S.; Nakhoul, N.L. Acid-Base and Potassium Homeostasis. Semin. Nephrol. 2013, 33, 257–264. [Google Scholar] [CrossRef] [PubMed]
- Kazda, A.; Jabor, A.; Zámečník, M.; Mašek, K. Monitoring Acid-Base and Electrolyte Disturbances in Intensive Care. In Advances in Clinical Chemistry; Elsevier: Amsterdam, The Netherlands, 1989; Volume 27, pp. 201–268. [Google Scholar] [CrossRef]
- Adrogué, H.J.; Madias, N.E. Changes in plasma potassium concentration during acute acid–base disturbances. Am. J. Med. 1981, 71, 456–467. [Google Scholar] [CrossRef]
- Charlton, P.H.; Pimentel, M.; Lokhandwala, S. Data Fusion Techniques for Early Warning of Clinical Deterioration. In Secondary Analysis of Electronic Health Records; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 325–338. [Google Scholar] [CrossRef] [Green Version]
- Subbe, C. Validation of a modified Early Warning Score in medical admissions. QJM 2001, 94, 521–526. [Google Scholar] [CrossRef] [Green Version]
- Knaus, W.A.; Draper, E.A.; Wagner, D.P.; Zimmerman, J.E. APACHE II: A Severity of Disease Classification System. Crit. Care Med. 1985, 13, 818–829. [Google Scholar] [CrossRef] [PubMed]
- Moreno, R.P.; Metnitz, P.G.H.; Almeida, E.; Jordan, B.; Bauer, P.; Campos, R.A.; Iapichino, G.; Edbrooke, D.; Capuzzo, M.; Le Gall, J.-R. SAPS 3—From evaluation of the patient to evaluation of the intensive care unit. Part 2: Development of a prognostic model for hospital mortality at ICU admission. Intensive Care Med. 2005, 31, 1345–1355. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jones, M. NEWSDIG: The National Early Warning Score Development and Implementation Group. Clin. Med. 2012, 12, 501–503. [Google Scholar] [CrossRef]
- Cosgriff, C.V.; Celi, L.A.; Stone, D.J. Critical Care, Critical Data. Biomed. Eng. Comput. Biol. 2019, 10, 117959721985656. [Google Scholar] [CrossRef] [PubMed]
- Johnson, A.E.W.; Ghassemi, M.M.; Nemati, S.; Niehaus, K.E.; Clifton, D.; Clifford, G.D. Machine Learning and Decision Support in Critical Care. Proc. IEEE 2016, 104, 444–466. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kam, H.J.; Kim, H.Y. Learning representations for the early detection of sepsis with deep neural networks. Comput. Biol. Med. 2017, 89, 248–255. [Google Scholar] [CrossRef] [PubMed]
- Nemati, S.; Holder, A.; Razmi, F.; Stanley, M.D.; Clifford, G.D.; Buchman, T.G. An Interpretable Machine Learning Model for Accurate Prediction of Sepsis in the ICU. Crit. Care Med. 2018, 46, 547–553. [Google Scholar] [CrossRef] [PubMed]
- Zhang, D.; Yin, C.; Hunold, K.M.; Jiang, X.; Caterino, J.M.; Zhang, P. An interpretable deep-learning model for early prediction of sepsis in the emergency department. Patterns 2021, 2, 100196. [Google Scholar] [CrossRef] [PubMed]
- Kwon, J.; Lee, Y.; Lee, Y.; Lee, S.; Park, J. An Algorithm Based on Deep Learning for Predicting In-Hospital Cardiac Arrest. J. Am. Heart Assoc. 2018, 7, e008678. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tomašev, N.; Glorot, X.; Rae, J.W.; Zielinski, M.; Askham, H.; Saraiva, A.; Mottram, A.; Meyer, C.; Ravuri, S.; Protsyuk, I.; et al. A clinically applicable approach to continuous prediction of future acute kidney injury. Nature 2019, 572, 116–119. [Google Scholar] [CrossRef] [PubMed]
- Wanyan, T.; Honarvar, H.; Jaladanki, S.K.; Zang, C.; Naik, N.; Somani, S.; Freitas, J.K.D.; Paranjpe, I.; Vaid, A.; Zhang, J.; et al. Contrastive learning improves critical event prediction in COVID-19 patients. Patterns 2021, 2, 100389. [Google Scholar] [CrossRef]
- Lee, J.M.; Hauskrecht, M. Modeling multivariate clinical event time-series with recurrent temporal mechanisms. Artif. Intell. Med. 2021, 112, 102021. [Google Scholar] [CrossRef]
- Kaji, D.A.; Zech, J.R.; Kim, J.S.; Cho, S.K.; Dangayach, N.S.; Costa, A.B.; Oermann, E.K. An attention based deep learning model of clinical events in the intensive care unit. PLoS ONE 2019, 14, e0211057. [Google Scholar] [CrossRef] [Green Version]
- Na Pattalung, T.; Chaichulee, S. Comparison of machine learning algorithms for mortality prediction in intensive care patients on multi-center critical care databases. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1163, 012027. [Google Scholar] [CrossRef]
- Na Pattalung, T.; Ingviya, T.; Chaichulee, S. Feature Explanations in Recurrent Neural Networks for Predicting Risk of Mortality in Intensive Care Patients. J. Pers. Med. 2021, 11, 934. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.; Lundberg, S.M.; Erion, G.; Kim, J.H.; Lee, S.I. Forecasting adverse surgical events using self-supervised transfer learning for physiological signals. NPJ Digit. Med. 2021, 4, 167. [Google Scholar] [CrossRef] [PubMed]
- Fan, Y.; Ye, T.; Huang, T.; Xiao, H. Machine learning-based construction of a clinical prediction model for hypercapnia during one-lung ventilation for lung surgery. Res. Sq. 2022. [Google Scholar] [CrossRef]
- Zhou, Z.; Huang, C.; Fu, P.; Huang, H.; Zhang, Q.; Wu, X.; Yu, Q.; Sun, Y. Prediction of in-hospital hypokalemia using machine learning and first hospitalization day records in patients with traumatic brain injury. CNS Neurosci. Ther. 2022, 29, 181–191. [Google Scholar] [CrossRef] [PubMed]
- Kwak, G.H.; Chen, C.; Ling, L.; Ghosh, E.; Celi, L.A.; Hui, P. Predicting Hyperkalemia in the ICU and Evaluation of Generalizability and Interpretability. arXiv 2021, arXiv:2101.06443. [Google Scholar]
- Cherif, A.; Maheshwari, V.; Fuertinger, D.; Schappacher-Tilp, G.; Preciado, P.; Bushinsky, D.; Thijssen, S.; Kotanko, P. A mathematical model of the four cardinal acid–base disorders. Math. Biosci. Eng. 2020, 17, 4457–4476. [Google Scholar] [CrossRef] [PubMed]
- Laserna, E.; Sibila, O.; Aguilar, P.R.; Mortensen, E.M.; Anzueto, A.; Blanquer, J.M.; Sanz, F.; Rello, J.; Marcos, P.J.; Velez, M.I.; et al. Hypocapnia and Hypercapnia Are Predictors for ICU Admission and Mortality in Hospitalized Patients With Community-Acquired Pneumonia. Chest 2012, 142, 1193–1199. [Google Scholar] [CrossRef] [Green Version]
- Soar, J.; Perkins, G.D.; Abbas, G.; Alfonzo, A.; Barelli, A.; Bierens, J.J.; Brugger, H.; Deakin, C.D.; Dunning, J.; Georgiou, M.; et al. European Resuscitation Council Guidelines for Resuscitation 2010 Section 8. Cardiac arrest in special circumstances: Electrolyte abnormalities, poisoning, drowning, accidental hypothermia, hyperthermia, asthma, anaphylaxis, cardiac surgery, trauma, pregnancy, electrocution. Resuscitation 2010, 81, 1400–1433. [Google Scholar] [CrossRef]
- Berend, K.; de Vries, A.P.; Gans, R.O. Physiological Approach to Assessment of Acid–Base Disturbances. N. Engl. J. Med. 2014, 371, 1434–1445. [Google Scholar] [CrossRef] [Green Version]
- Constable, P.D. Clinical Assessment of Acid-Base Status: Comparison of the Henderson-Hasselbalch and Strong Ion Approaches. Vet. Clin. Pathol. 2000, 29, 115–128. [Google Scholar] [CrossRef]
- Rawat, D.; Modi, P.; Sharma, S. Hypercapnea; StatPearls Publishing: St. Petersburg, FL, USA, 2022. [Google Scholar]
- Gennari, F.J. Hypokalemia. N. Engl. J. Med. 1998, 339, 451–458. [Google Scholar] [CrossRef] [PubMed]
- GALLA, J.H. Metabolic Alkalosis. J. Am. Soc. Nephrol. 2000, 11, 369–375. [Google Scholar] [CrossRef] [PubMed]
- Plant, P.K. One year period prevalence study of respiratory acidosis in acute exacerbations of COPD: Implications for the provision of non-invasive ventilation and oxygen administration. Thorax 2000, 55, 550–554. [Google Scholar] [CrossRef] [Green Version]
- Lundberg, S.M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.I. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2020, 2, 56–67. [Google Scholar] [CrossRef]
- Johnson, A.; Bulgarelli, L.; Pollard, T.; Horng, S.; Celi, L.A.; Mark, R. MIMIC-IV. Phys. Net. 2022. [Google Scholar] [CrossRef]
- Pollard, T.J.; Johnson, A.E.W.; Raffa, J.D.; Celi, L.A.; Mark, R.G.; Badawi, O. The eICU Collaborative Research Database, a freely available multi-center database for critical care research. Sci. Data 2018, 5, 180178. [Google Scholar] [CrossRef] [PubMed]
- Cihan, P.; Ozger, Z.B. A new approach for determining SARS-CoV-2 epitopes using machine learning-based in silico methods. Comput. Biol. Chem. 2022, 98, 107688. [Google Scholar] [CrossRef]
- Desautels, T.; Calvert, J.; Hoffman, J.; Mao, Q.; Jay, M.; Fletcher, G.; Barton, C.; Chettipally, U.; Kerem, Y.; Das, R. Using Transfer Learning for Improved Mortality Prediction in a Data-Scarce Hospital Setting. Biomed. Inform. Insights 2017, 9, 117822261771299. [Google Scholar] [CrossRef] [PubMed] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristics | |
|---|---|
| Number of patients | 1089 |
| Number of admissions | 1137 |
| Age | 63.8 (18.1) |
| Gender | |
| Male | 602 (55.3%) |
| Female | 487 (44.7%) |
| Length of hospital stay | 27.2 (27.5) |
| Length of ICU stay | 7.0 (8.0) |
| Clinical Condition | Criteria | Admissions with Condition |
|---|---|---|
| Mortality | Death during ICU stay | 213 (18.7%) |
| Hypocapnia | pCO2 < 35 mmHg | 360 (31.7%) |
| Hypercapnia | pCO2 > 45 mmHg | 296 (26.0%) |
| Hypokalemia | K+ < 3.5 mmol/L | 598 (52.6%) |
| Hyperkalemia | K+ > 5.5 mmol/L | 83 (7.3%) |
| Metabolic Acidosis | pH < 7.35, and cHCO3− < 22 mmol/L | 202 (17.8%) |
| Metabolic Alkalosis | pH > 7.45, and cHCO3− > 26 mmol/L | 430 (37.8%) |
| Respiratory Acidosis | pH < 7.35, and pCO2 > 45 mmHg | 258 (22.7%) |
| Respiratory Alkalosis | pH > 7.45, and pCO2 < 35 mmHg | 397 (34.9%) |
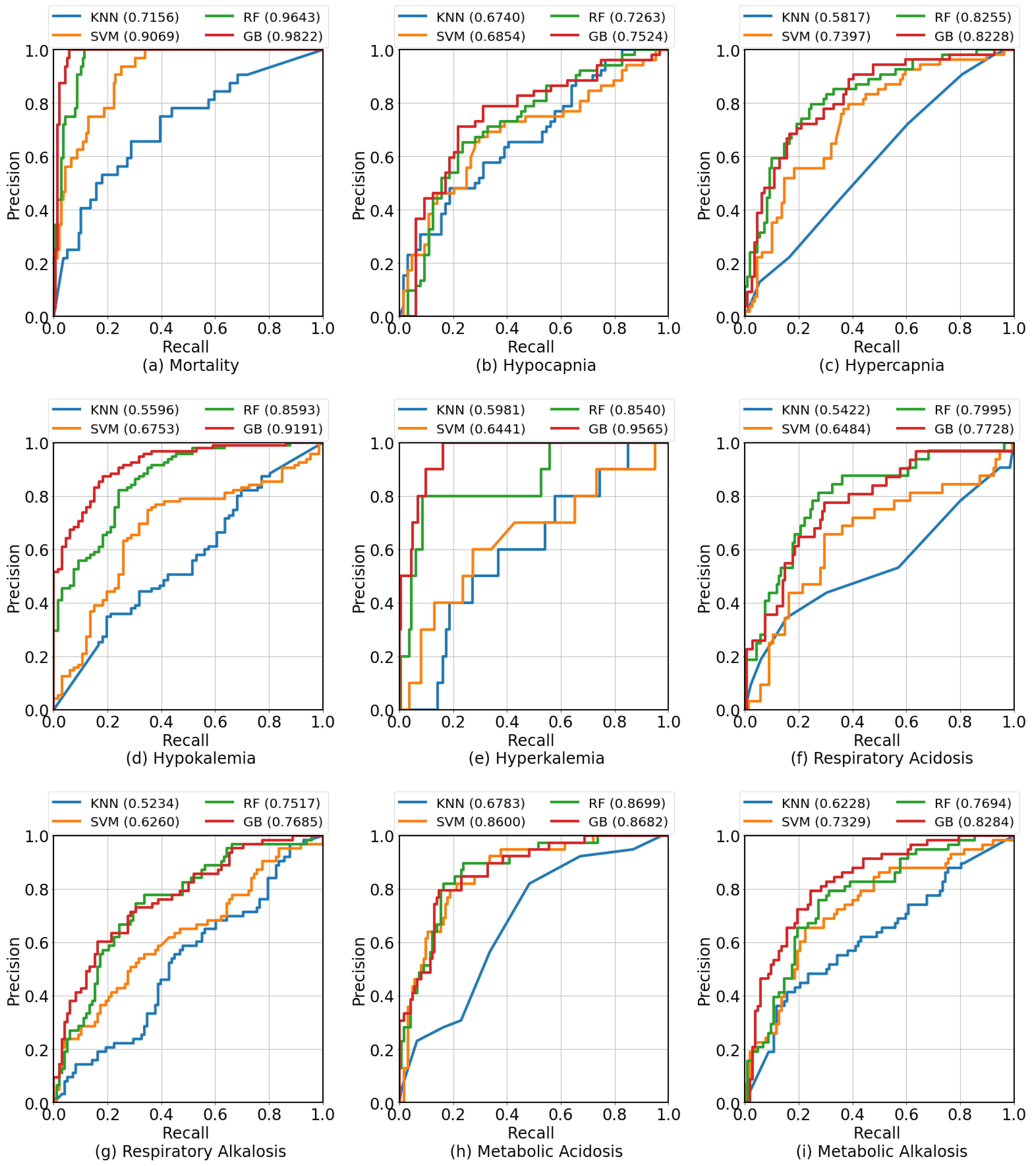
| Clinical Condition | N/N | Algorithm | Precision | Sensitivity | Specificity | F1 Score | AUROC | AUPRC |
|---|---|---|---|---|---|---|---|---|
| Mortality | 213/ | K Nearest Neighbours | 0.3333 | 0.5625 | 0.7410 | 0.4186 | 0.7156 | 0.4347 |
| 924 | Support Vector Machine | 0.4746 | 0.8750 | 0.7770 | 0.6154 | 0.9069 | 0.6796 | |
| Random Forests | 0.6154 | 1.000 | 0.8561 | 0.7619 | 0.9643 | 0.8378 | ||
| Gradient Boosting | 0.6809 | 1.000 | 0.8921 | 0.8101 | 0.9822 | 0.8557 | ||
| Hypocapnia | 360/ | K Nearest Neighbours | 0.5484 | 0.6538 | 0.5625 | 0.5965 | 0.674 | 0.6353 |
| 777 | Support Vector Machine | 0.6471 | 0.6346 | 0.7188 | 0.6408 | 0.6854 | 0.6282 | |
| Random Forests | 0.6429 | 0.6923 | 0.6875 | 0.6667 | 0.7263 | 0.615 | ||
| Gradient Boosting | 0.7115 | 0.7115 | 0.7656 | 0.7115 | 0.7524 | 0.6442 | ||
| Hypercapnia | 296/ | K Nearest Neighbours | 0.381 | 0.4444 | 0.6422 | 0.4103 | 0.5817 | 0.4107 |
| 841 | Support Vector Machine | 0.5063 | 0.7407 | 0.6422 | 0.6015 | 0.7397 | 0.5382 | |
| Random Forests | 0.6056 | 0.7963 | 0.7431 | 0.6880 | 0.8255 | 0.7036 | ||
| Gradient Boosting | 0.5909 | 0.7222 | 0.7523 | 0.6500 | 0.8228 | 0.6731 | ||
| Hypokalemia | 598/ | K Nearest Neighbours | 0.6067 | 0.5684 | 0.4697 | 0.5870 | 0.5596 | 0.6779 |
| 539 | Support Vector Machine | 0.75 | 0.7263 | 0.6515 | 0.738 | 0.6753 | 0.7359 | |
| Random Forests | 0.8061 | 0.8316 | 0.7121 | 0.8187 | 0.8593 | 0.8971 | ||
| Gradient Boosting | 0.8646 | 0.8737 | 0.8030 | 0.8691 | 0.9191 | 0.9455 | ||
| Hyperkalemia | 83/ | K Nearest Neighbours | 0.0909 | 0.6000 | 0.6273 | 0.1579 | 0.5981 | 0.0714 |
| 1054 | Support Vector Machine | 0.0921 | 0.7000 | 0.5714 | 0.1628 | 0.6441 | 0.0981 | |
| Random Forests | 0.1600 | 0.8000 | 0.7391 | 0.2667 | 0.854 | 0.3053 | ||
| Gradient Boosting | 0.2083 | 1.0000 | 0.7640 | 0.3448 | 0.9565 | 0.6497 | ||
| Respiratory Acidosis | 202/ | K Nearest Neighbours | 0.2545 | 0.4375 | 0.6963 | 0.3218 | 0.5422 | 0.2938 |
| 935 | Support Vector Machine | 0.3182 | 0.6562 | 0.6667 | 0.4286 | 0.6484 | 0.2797 | |
| Random Forests | 0.4237 | 0.7812 | 0.7481 | 0.5495 | 0.7995 | 0.5324 | ||
| Gradient Boosting | 0.4068 | 0.7500 | 0.7407 | 0.5275 | 0.8125 | 0.5945 | ||
| Respiratory Alkalosis | 430/ | K Nearest Neighbours | 0.4405 | 0.5873 | 0.5204 | 0.5034 | 0.5234 | 0.4175 |
| 707 | Support Vector Machine | 0.4815 | 0.6190 | 0.5714 | 0.5417 | 0.6260 | 0.5335 | |
| Random Forests | 0.6269 | 0.6667 | 0.7449 | 0.6462 | 0.7517 | 0.6265 | ||
| Gradient Boosting | 0.6081 | 0.7143 | 0.7041 | 0.6569 | 0.7685 | 0.6924 | ||
| Metabolic Acidosis | 258/ | K Nearest Neighbours | 0.3492 | 0.5641 | 0.6639 | 0.4314 | 0.6783 | 0.4081 |
| 879 | Support Vector Machine | 0.4648 | 0.8462 | 0.6885 | 0.6000 | 0.8600 | 0.5921 | |
| Random Forests | 0.5385 | 0.8974 | 0.7541 | 0.6731 | 0.8699 | 0.6870 | ||
| Gradient Boosting | 0.5333 | 0.8205 | 0.7705 | 0.6465 | 0.8682 | 0.7150 | ||
| Metabolic Alkalosis | 397/ | K Nearest Neighbours | 0.4583 | 0.5690 | 0.6176 | 0.5077 | 0.6228 | 0.5258 |
| 740 | Support Vector Machine | 0.5846 | 0.6552 | 0.7353 | 0.6179 | 0.7329 | 0.6153 | |
| Random Forests | 0.5946 | 0.7586 | 0.7059 | 0.6667 | 0.7694 | 0.6143 | ||
| Gradient Boosting | 0.6389 | 0.7931 | 0.7451 | 0.7077 | 0.8284 | 0.6719 |
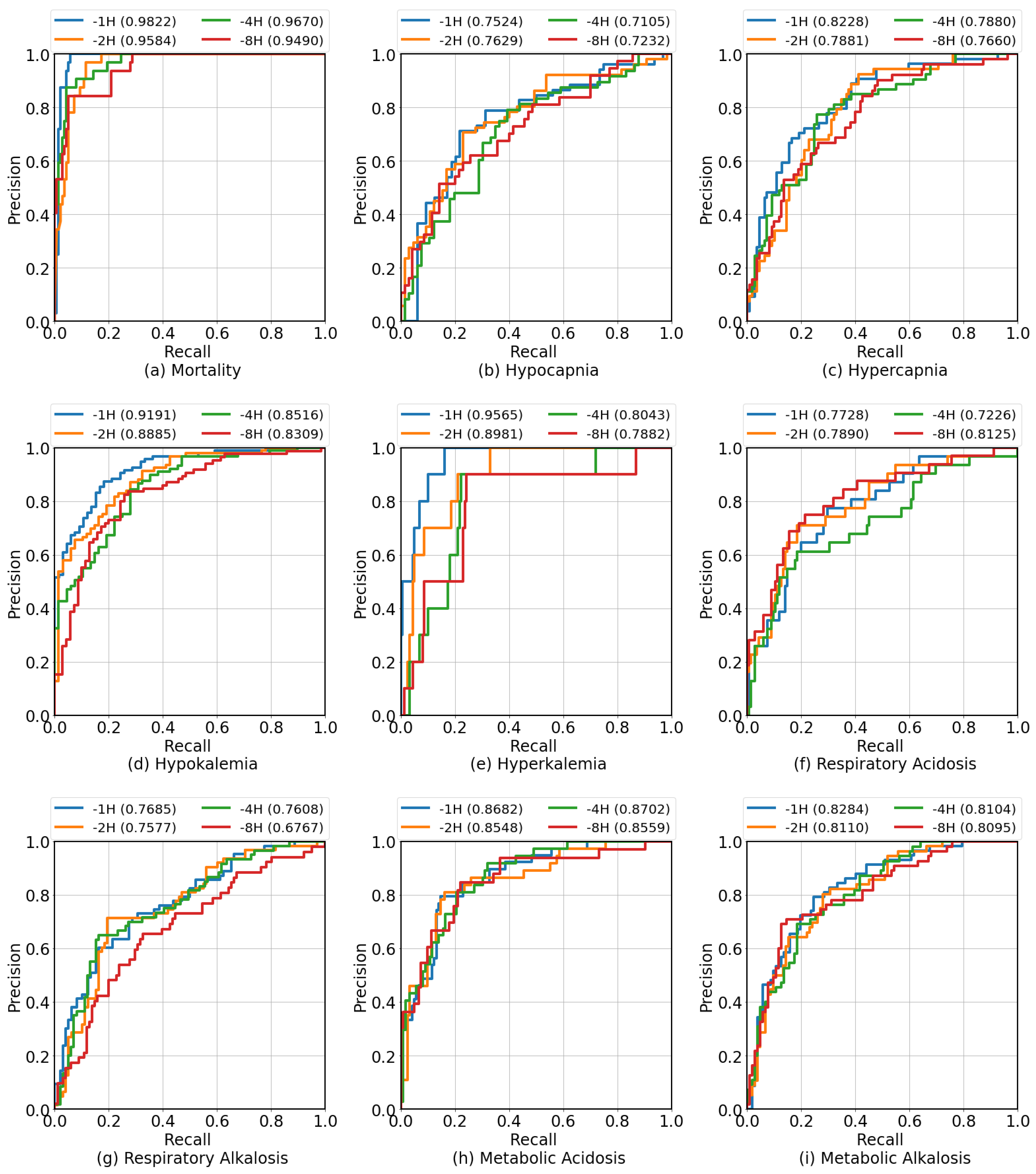
| Clinical Condition | N/N | Before Onset | Precision | Sensitivity | Specificity | F1 Score | AUROC | AUPRC |
|---|---|---|---|---|---|---|---|---|
| Mortality | 213/ | 1 h | 0.6809 | 1.000 | 0.8921 | 0.8101 | 0.9822 | 0.8557 |
| 924 | 2 h | 0.6078 | 0.9688 | 0.8561 | 0.7470 | 0.9584 | 0.8148 | |
| 4 h | 0.5769 | 0.9375 | 0.8417 | 0.7143 | 0.9670 | 0.8820 | ||
| 8 h | 0.5400 | 0.8438 | 0.8345 | 0.6585 | 0.9490 | 0.8462 | ||
| Hypocapnia | 360/ | 1 h | 0.7115 | 0.7115 | 0.7656 | 0.7115 | 0.7524 | 0.6442 |
| 777 | 2 h | 0.6491 | 0.7255 | 0.6923 | 0.6852 | 0.7629 | 0.7207 | |
| 4 h | 0.6034 | 0.7292 | 0.6515 | 0.6604 | 0.7105 | 0.5997 | ||
| 8 h | 0.4808 | 0.6757 | 0.6143 | 0.5618 | 0.7232 | 0.6099 | ||
| Hypercapnia | 296/ | 1 h | 0.5909 | 0.7222 | 0.7523 | 0.6500 | 0.8228 | 0.6731 |
| 841 | 2 h | 0.5217 | 0.6792 | 0.6972 | 0.5902 | 0.7881 | 0.6081 | |
| 4 h | 0.5600 | 0.7925 | 0.6972 | 0.6562 | 0.7880 | 0.6496 | ||
| 8 h | 0.4857 | 0.6667 | 0.6727 | 0.5620 | 0.7660 | 0.6142 | ||
| Hypokalemia | 598/ | 1 h | 0.8646 | 0.8737 | 0.8030 | 0.8691 | 0.9191 | 0.9455 |
| 539 | 2 h | 0.8191 | 0.828 | 0.7500 | 0.8235 | 0.8885 | 0.9127 | |
| 4 h | 0.7895 | 0.8427 | 0.7059 | 0.8152 | 0.8516 | 0.8866 | ||
| 8 h | 0.7907 | 0.8000 | 0.7429 | 0.7953 | 0.8309 | 0.8475 | ||
| Hyperkalemia | 83/ | 1 h | 0.2083 | 1.0000 | 0.7640 | 0.3448 | 0.9565 | 0.6497 |
| 1054 | 2 h | 0.1579 | 0.9000 | 0.7019 | 0.2687 | 0.8981 | 0.2761 | |
| 4 h | 0.1636 | 0.9000 | 0.7143 | 0.2769 | 0.8043 | 0.1573 | ||
| 8 h | 0.1667 | 0.9000 | 0.7205 | 0.2812 | 0.7882 | 0.1628 | ||
| Respiratory Acidosis | 202/ | 1 h | 0.4068 | 0.7500 | 0.7407 | 0.5275 | 0.8125 | 0.5945 |
| 935 | 2 h | 0.3382 | 0.7419 | 0.6667 | 0.4646 | 0.7890 | 0.5339 | |
| 4 h | 0.3607 | 0.7097 | 0.7111 | 0.4783 | 0.7728 | 0.4539 | ||
| 8 h | 0.3333 | 0.6129 | 0.7185 | 0.4318 | 0.7226 | 0.3975 | ||
| Respiratory Alkalosis | 430/ | 1 h | 0.6081 | 0.7143 | 0.7041 | 0.6569 | 0.7685 | 0.6924 |
| 707 | 2 h | 0.6618 | 0.7143 | 0.7653 | 0.6870 | 0.7577 | 0.6250 | |
| 4 h | 0.5733 | 0.7167 | 0.6768 | 0.6370 | 0.7608 | 0.6250 | ||
| 8 h | 0.5082 | 0.5962 | 0.7030 | 0.5487 | 0.6767 | 0.5167 | ||
| Metabolic Acidosis | 258/ | 1 h | 0.5333 | 0.8205 | 0.7705 | 0.6465 | 0.8682 | 0.7150 |
| 879 | 2 h | 0.5000 | 0.8378 | 0.7480 | 0.6263 | 0.8548 | 0.6490 | |
| 4 h | 0.4918 | 0.8108 | 0.7459 | 0.6122 | 0.8702 | 0.6686 | ||
| 8 h | 0.4375 | 0.8485 | 0.7073 | 0.5773 | 0.8559 | 0.6923 | ||
| Metabolic Alkalosis | 397/ | 1 h | 0.6389 | 0.7931 | 0.7451 | 0.7077 | 0.8284 | 0.6719 |
| 740 | 2 h | 0.5970 | 0.7143 | 0.7404 | 0.6504 | 0.8110 | 0.6571 | |
| 4 h | 0.5455 | 0.7636 | 0.6602 | 0.6364 | 0.8104 | 0.6775 | ||
| 8 h | 0.5513 | 0.7818 | 0.6602 | 0.6466 | 0.8095 | 0.6799 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Phetrittikun, R.; Suvirat, K.; Horsiritham, K.; Ingviya, T.; Chaichulee, S. Prediction of Acid-Base and Potassium Imbalances in Intensive Care Patients Using Machine Learning Techniques. Diagnostics 2023, 13, 1171. https://doi.org/10.3390/diagnostics13061171
Phetrittikun R, Suvirat K, Horsiritham K, Ingviya T, Chaichulee S. Prediction of Acid-Base and Potassium Imbalances in Intensive Care Patients Using Machine Learning Techniques. Diagnostics. 2023; 13(6):1171. https://doi.org/10.3390/diagnostics13061171
Chicago/Turabian StylePhetrittikun, Ratchakit, Kerdkiat Suvirat, Kanakorn Horsiritham, Thammasin Ingviya, and Sitthichok Chaichulee. 2023. "Prediction of Acid-Base and Potassium Imbalances in Intensive Care Patients Using Machine Learning Techniques" Diagnostics 13, no. 6: 1171. https://doi.org/10.3390/diagnostics13061171
APA StylePhetrittikun, R., Suvirat, K., Horsiritham, K., Ingviya, T., & Chaichulee, S. (2023). Prediction of Acid-Base and Potassium Imbalances in Intensive Care Patients Using Machine Learning Techniques. Diagnostics, 13(6), 1171. https://doi.org/10.3390/diagnostics13061171