

Multimodality Medical Image Fusion Using Clustered Dictionary Learning in Non-Subsampled Shearlet Transform
 , , ,
, , ,  ,
,  and
and 
Abstract
:1. Introduction
- i.
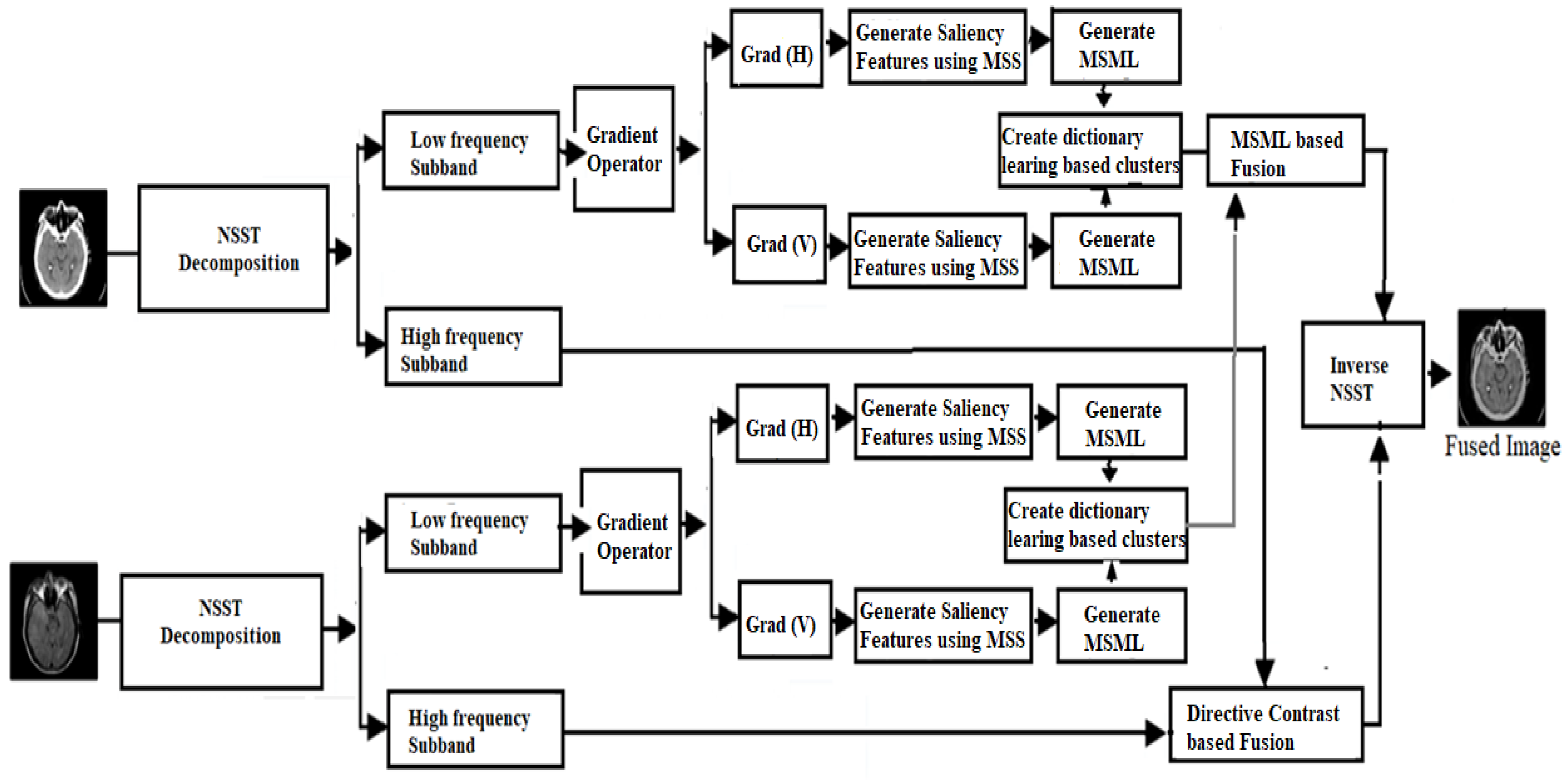
- A dictionary learning method based on cluster analysis is introduced in low-frequency sub-band fusion. In this technique, structural image patch attributes are pooled and mathematically connected to increase computation efficiency;
- ii.
- For low sub-band fusion, the modified sum-modified Laplacian (MSML) constructs artificially sparse vectors by employing saliency features to calculate low-frequency sub-band local features;
- iii.
- A directive contrast-based fusion is introduced by calculating the local facts of high-frequency sub-band MSML.
2. Related Work
3. Preliminaries
3.1. Non-Subsampled Shearlet Transform (NSST)
3.2. Clustered Dictionary Learning
3.3. Visual Saliency Features
4. Proposed Methodology
- (a)
- Find the gradient information GA and GB in horizontal and vertical directions from both input images;
- (b)
- Estimate modified Laplacian (ML), as shown in Equation (4);
- (c)
- Develop MSML by adding the ML as shown in Equation (5);where is the size of ;
- (d)
- Acquire the clusters using MSML:
- (i)
- Separate the source images into patches, , respectively;
- (ii)
- Combine to make a joint patch set ;
- (iii)
- Search the MSML for every ;
- (iv)
- Fix the thresholds by utilizing as shown in Equations (6) and (7):
- (e)
- Perform the equation below to make the clusters. The categorization approach is described, as shown in Equation (8);
- (f)
- The sum-modified-Laplacian (SML) is a technique that has proven effective in the field of medical picture fusion. When applied to the altered image, fusion rules based on a larger SML always lead to either information loss in the fused spatial domain or image distortion. New filters, the average filter, and the median filter, are available in the latest version of SML, which is utilized for medical picture fusion. MSML is the main computation to evaluate all activity levels of the image patch. It elaborates on the small information, the image constraint. Increasing the value gives more details as it exists. Suppose and represent the patch’s modified SML of low-frequency sub-images , the recommended fusion approach is described, as shown in Equation (9):where and the fusion mean value is followed by Equation (10),
- (a)
- Estimate the directive contrast ( of NSST high-frequency coefficients using low sub-band coefficients as shown in Equations (11) and (12):Similarly,
- (b)
- Apply the following fusion rule to the high-frequency coefficients () as shown in Equation (13):
5. Experimental Results
5.1. Dataset
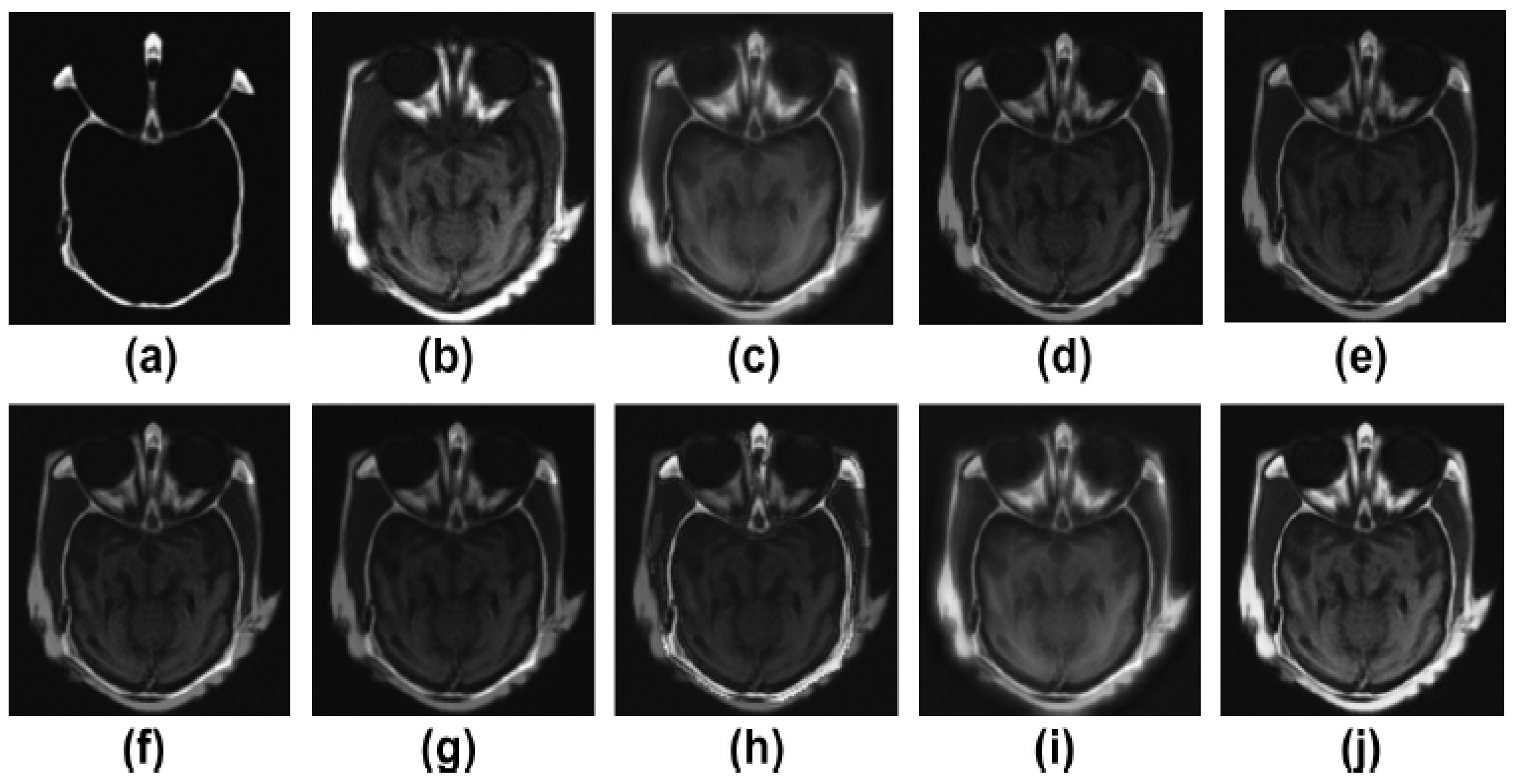
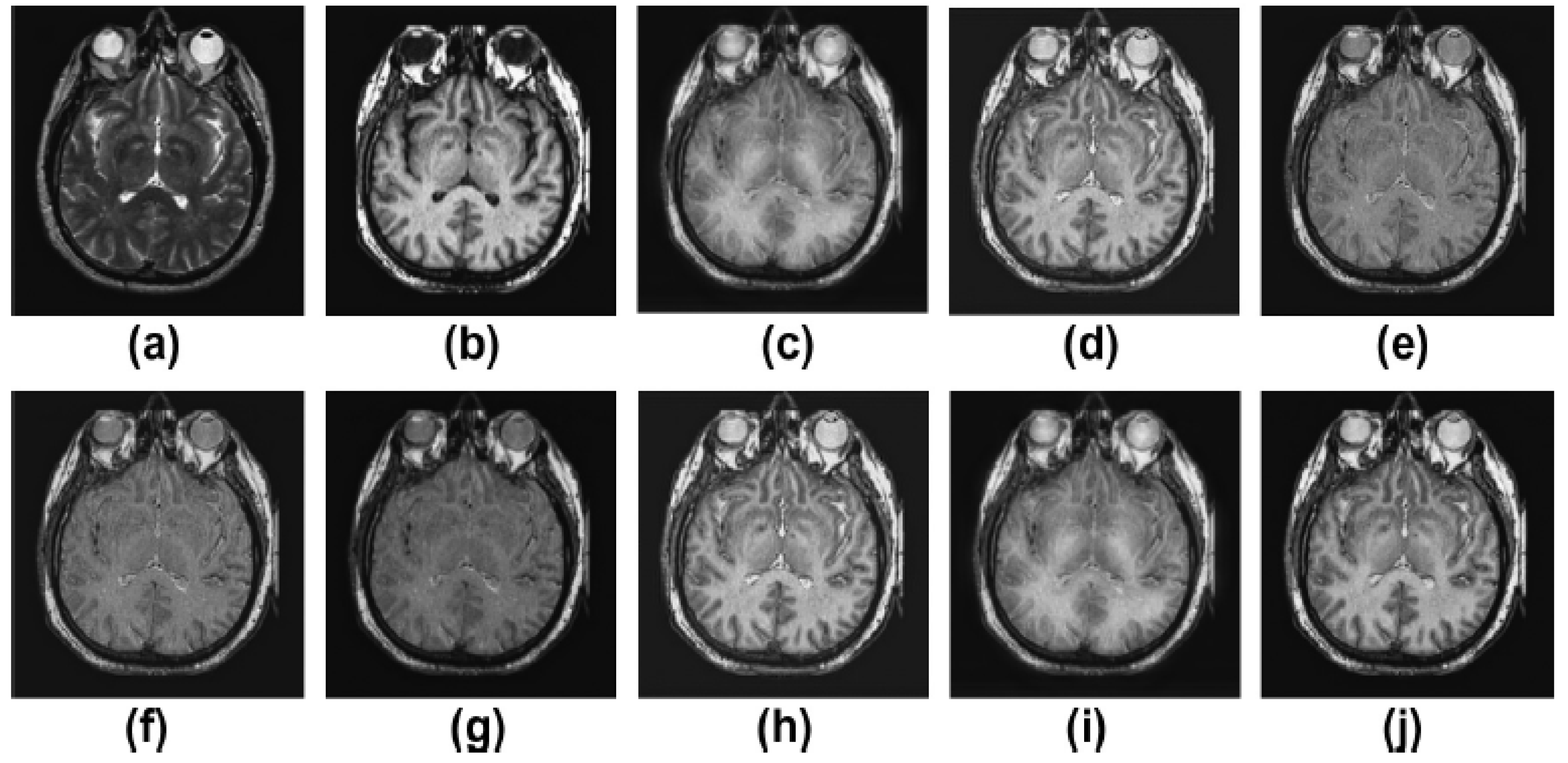
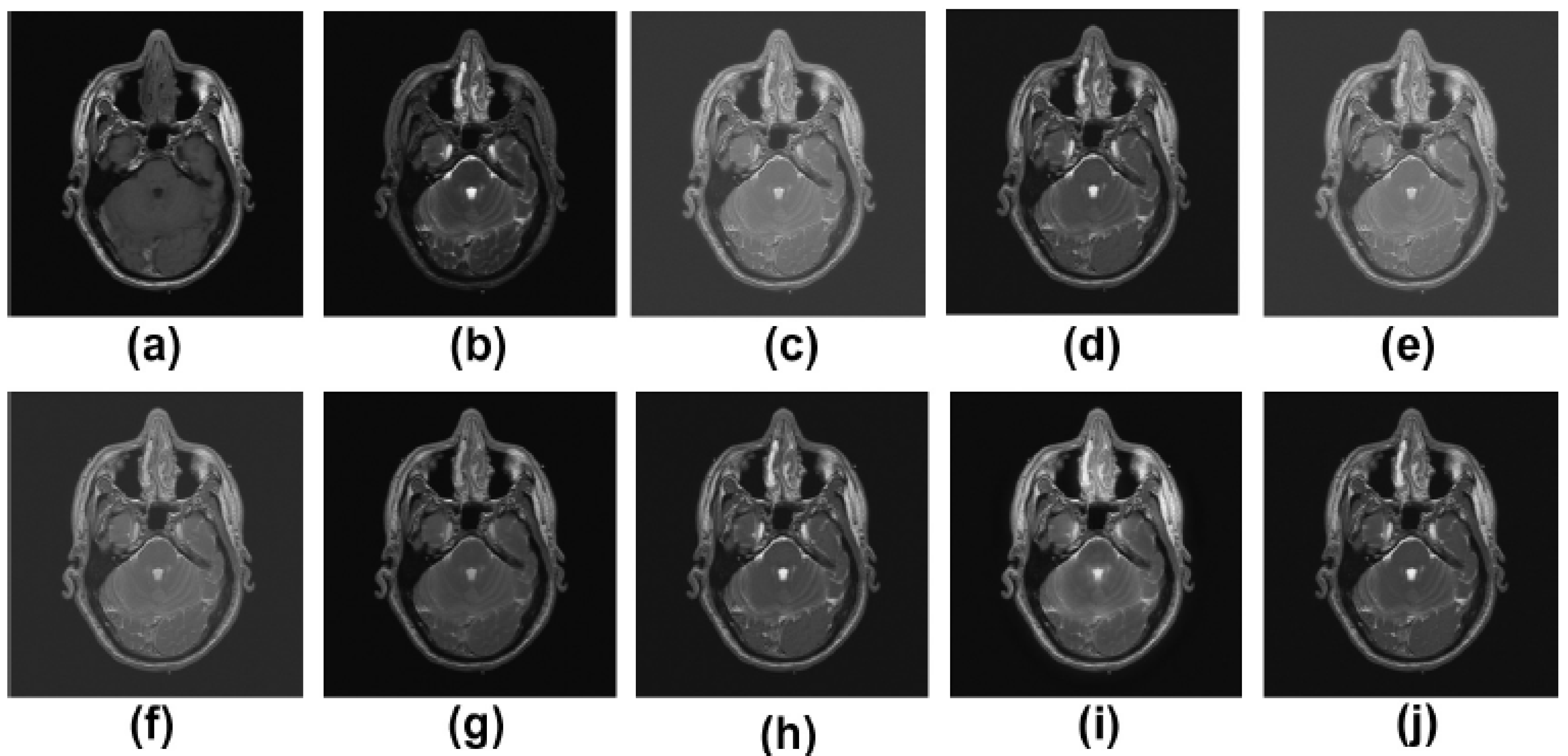
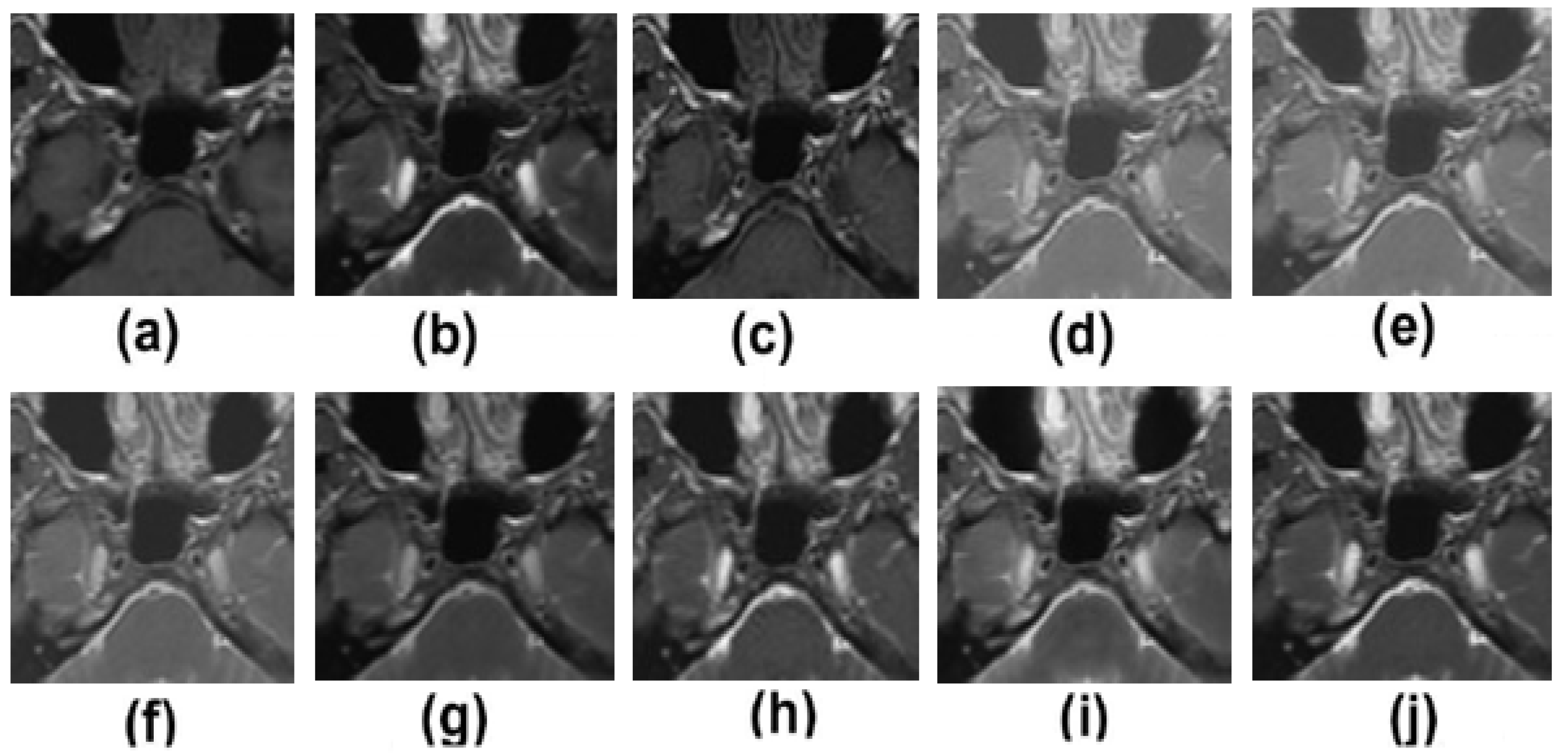
5.2. Results and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| NSST | Non-subsampled shearlet transform |
| MSML | Modified sum-modified Laplacian |
| CAD | Coronary artery disease |
| ACCD | Adaptive, clustered, and condensed sub-dictionary |
| SWT | Stationary wavelet transform |
| DWT | Discrete wavelet transform |
| FLICM | Fuzzy Local Information C-Means Clustering |
| SML | Sum-modified Laplacian |
| CoF | Co-occurrence filter |
| LE | Local extrema |
| NSCT | Non-subsampled contourlet transform |
| ML | Modified Laplacian |
| MRI | Magnetic resonance imaging |
| CT | Computed tomography |
References
- Xu, Z. Medical image fusion using multi-level local extrema. Inf. Fusion 2014, 19, 38–48. [Google Scholar]
- Zhang, P.; Yuan, Y.; Fei, C.; Pu, T.; Wang, S. Infrared and visible image fusion using co-occurrence filter. Infrared Phys. Technol. 2018, 93, 223–231. [Google Scholar] [CrossRef]
- Li, S.; Yin, H.; Fang, L. Group-sparse representation with dictionary learning for medical image denoising and fusion. IEEE Trans. Biomed. Eng. 2012, 59, 3450–3459. [Google Scholar] [CrossRef] [PubMed]
- Sharma, D.; Kudva, V.; Patil, V.; Kudva, A.; Bhat, R.S. A Convolutional Neural Network Based Deep Learning Algorithm for Identification of Oral Precancerous and Cancerous Lesion and Differentiation from Normal Mucosa: A Retrospective Study. Eng. Sci. 2022, 18, 278–287. [Google Scholar] [CrossRef]
- Yin, M.; Liu, W.; Zhao, X.; Yin, Y.; Guo, Y. A novel image fusion algorithm based on non subsampled shearlet transform. Optik 2014, 125, 2274–2282. [Google Scholar] [CrossRef]
- Ganasala, P.; Kumar, V. Multi-modality medical image fusion based on new features in NSST domain. Biomed. Eng. Lett. 2014, 4, 414–424. [Google Scholar] [CrossRef]
- Shah, M.; Naik, N.; Somani, B.K.; Hameed, B.Z. Artificial intelligence (AI) in urology-Current use and future directions: An iTRUE study. Turk. J. Urol. 2020, 46 (Suppl. S1), S27–S39. [Google Scholar] [CrossRef]
- Ganasala, P.; Kumar, V. Feature-motivated simplified adaptive PCNN-based medical image fusion algorithm in NSST domain. J. Digit. Imaging 2016, 29, 73–85. [Google Scholar] [CrossRef] [Green Version]
- Singh, R.; Srivastava, R.; Prakash, O.; Khare, A. Multi-modal medical image fusion in dual tree complex wavelet transform domain using maximum and average fusion rules. J. Med. Imaging Health Inform. 2012, 2, 168–173. [Google Scholar] [CrossRef]
- Qu, X.-B.; Yan, J.-W.; Xiao, H.-Z.; Zhu, Z.-Q. Image fusion algorithm based on spatial frequency-motivated pulse coupled neural networks in nonsubsampledcontourlet transform domain. Acta Autom. Sin. 2008, 34, 1508–1514. [Google Scholar] [CrossRef]
- Patil, V.; Vineetha, R.; Vatsa, S.; Shetty, D.K.; Raju, A.; Naik, N.; Malarout, N. Artificial neural network for gender determination using mandibular morphometric parameters: A comparative retrospective study. Cogent Eng. 2020, 7, 1723783. [Google Scholar] [CrossRef]
- Zhang, Y.; Jin, M.; Huang, G. Medical image fusion based on improved multi-scale morphology gradient-weighted local energy and visual saliency map. Biomed. Signal Process. Control 2022, 74, 103535. [Google Scholar] [CrossRef]
- Ramlal, S.D.; Sachdeva, J.; Ahuja, C.K.; Khandelwal, N. An improved multi-modal medical image fusion scheme based on hybrid combination of nonsubsampledcontourlet transform and stationary wavelet transform. Int. J. Imaging Syst. Technol. 2019, 29, 146–160. [Google Scholar] [CrossRef]
- Dogra, A.; Kumar, S. Multi-modality medical image fusion based on guided filter and image statistics in multidirectional shearlet transform domain. J. Ambient. Intell. Humaniz. Comput. 2022, 1–15. [Google Scholar] [CrossRef]
- Ullah, H.; Ullah, B.; Wu, L.; Abdalla, F.Y.; Ren, G.; Zhao, Y. Multi-modality medical images fusion based on local-features fuzzy sets and novel sum-modified-Laplacian in non-subsampled shearlet transform domain. Biomed. Signal Process. Control 2020, 57, 101724. [Google Scholar] [CrossRef]
- Huang, D.; Tang, Y.; Wang, Q. An Image Fusion Method of SAR and Multispectral Images Based on Non-Subsampled Shearlet Transform and Activity Measure. Sensors 2022, 22, 7055. [Google Scholar] [CrossRef]
- Liu, X.; Mei, W.; Du, H. Multi-modality medical image fusion based on image decomposition framework and nonsubsampledshearlet transform. Biomed. Signal Process. Control 2018, 40, 343–350. [Google Scholar] [CrossRef]
- Mehta, N.; Budhiraja, S. Multi-modal Medical Image Fusion using Guided Filter in NSCT Domain. Biomed. Pharmacol. J. 2018, 11, 1937–1946. [Google Scholar] [CrossRef]
- Maqsood, S.; Javed, U. Multi-modal medical image fusion based on two-scale image decomposition and sparse representation. Biomed. Signal Process. Control 2020, 57, 101810. [Google Scholar] [CrossRef]
- Hu, Q.; Hu, S.; Zhang, F. Multi-modality medical image fusion based on separable dictionary learning and Gabor filtering. Signal Process. Image Commun. 2020, 83, 115758. [Google Scholar] [CrossRef]
- Zhu, Z.; Chai, Y.; Yin, H.; Li, Y.; Liu, Z. A novel dictionary learning approach for multi-modality medical image fusion. Neurocomputing 2016, 214, 471–482. [Google Scholar] [CrossRef]
- Zhu, Z.; Yin, H.; Chai, Y.; Li, Y.; Qi, G. A novel multi-modality image fusion method based on image decomposition and sparse representation. Inf. Sci. 2018, 432, 516–529. [Google Scholar] [CrossRef]
- Cao, Y.; Li, S.; Hu, J. Multi-Focus Image Fusion by Nonsubsampledshearlet Transform. In Proceedings of the 2011 Sixth International Conference on Image and Graphics, Hefei, China, 12–15 August 2011; pp. 17–21. [Google Scholar]
- Gao, G.; Xu, L.; Feng, D. Multi-focus image fusion based on non-subsampled shearlet transform. IET Image Process. 2013, 7, 633–639. [Google Scholar]
- Fu, Z.; Zhao, Y.; Xu, Y.; Xu, L.; Xu, J. Gradient structural similarity based gradient filtering for multi-modal image fusion. Inf. Fusion 2020, 53, 251–268. [Google Scholar] [CrossRef]
- Goyal, S.; Singh, V.; Rani, A.; Yadav, N. FPRSGF denoised non-subsampled shearlet transform-based image fusion using sparse representation. Signal Image Video Process. 2020, 14, 719–726. [Google Scholar] [CrossRef]
- Benjamin, J.R.; Jayasree, T. An Efficient MRI-PET Medical Image Fusion Using Non-Subsampled Shearlet Transform. In Proceedings of the 2019 IEEE International Conference on Intelligent Techniques in Control, Optimization and Signal Processing (INCOS), Tamilnadu, India, 11–13 April 2019; pp. 1–5. [Google Scholar]
- Luo, X.; Zhang, Z.; Zhang, B.; Wu, X. Image fusion with contextual statistical similarity and nonsubsampledshearlet transform. IEEE Sens. J. 2016, 17, 1760–1771. [Google Scholar] [CrossRef]
- Zhao, C.; Guo, Y.; Wang, Y. A fast fusion scheme for infrared and visible light images in NSCT domain. Infrared Phys. Technol. 2015, 72, 266–275. [Google Scholar] [CrossRef]
- Moonon, A.U.; Hu, J.; Li, S. Remote sensing image fusion method based on nonsubsampledshearlet transform and sparse representation. Sens. Imaging 2015, 16, 23. [Google Scholar] [CrossRef]
- Ghimpeţeanu, G.; Batard, T.; Bertalmío, M.; Levine, S. A decomposition framework for image denoising algorithms. IEEE Trans. Image Process. 2015, 25, 388–399. [Google Scholar] [CrossRef] [Green Version]
- Hou, R.; Zhou, D.; Nie, R.; Liu, D.; Ruan, X. Brain CT and MRI medical image fusion using convolutional neural networks and a dual-channel spiking cortical model. Med. Biol. Eng. Comput. 2019, 57, 887–900. [Google Scholar] [CrossRef]
- Asha, C.S.; Lal, S.; Gurupur, V.P.; Saxena, P.P. Multi-modal medical image fusion with adaptive weighted combination of NSST bands using chaotic grey wolf optimization. IEEE Access 2019, 7, 40782–40796. [Google Scholar] [CrossRef]
- Tannaz, A.; Mousa, S.; Sabalan, D.; Masoud, P. Fusion of multi-modal medical images using nonsubsampledshearlet transform and particle swarm optimization. Multidimens. Syst. Signal Process. 2020, 31, 269–287. [Google Scholar] [CrossRef]
- Yin, M.; Liu, X.; Liu, Y.; Chen, X. Medical image fusion with parameter-adaptive pulse coupled neural network in nonsubsampledshearlet transform domain. IEEE Trans. Instrum. Meas. 2018, 68, 49–64. [Google Scholar] [CrossRef]
- Ouerghi, H.; Mourali, O.; Zagrouba, E. Non-subsampled shearlet transform based MRI and PET brain image fusion using simplified pulse coupled neural network and weight local features in YIQ colour space. IET Image Process. 2018, 12, 1873–1880. [Google Scholar] [CrossRef]
- Wadhwa, P.; Tripathi, A.; Singh, P.; Diwakar, M.; Kumar, N. Predicting the time period of extension of lockdown due to increase in rate of COVID-19 cases in india using machine learning. Mater. Today Proc. 2020, 37 Pt 2, 2617–2622. [Google Scholar] [CrossRef]
- Dhaka, A.; Singh, P. Comparative Analysis of Epidemic Alert System Using Machine Learning for Dengue and Chikungunya. In Proceedings of the Confluence 2020 10th International Conference on Cloud Computing, Data Science and Engineering, Noida, India, 29–31 January 2020; pp. 798–804. [Google Scholar] [CrossRef]
- Diwakar, M.; Tripathi, A.; Joshi, K.; Sharma, A.; Singh, P.; Memoria, M.; Kumar, N. A comparative review: Medical image fusion using SWT and DWT. Mater. Today Proc. 2020, 37 Pt 2, 3411–3416. [Google Scholar] [CrossRef]
- Dhaundiyal, R.; Tripathi, A.; Joshi, K.; Diwakar, M.; Singh, P. Clustering based multi-modality medical image fusion. J. Phys. Conf. Ser. 2020, 1478, 012024. [Google Scholar] [CrossRef]
- Diwakar, M.; Singh, P.; Shankar, A. Multi-modal medical image fusion framework using co-occurrence filter and local extrema in NSST domain. Biomed. Signal Process. Control 2021, 68, 102788. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Dataset | Zhang et al. [12] | Ramlal et al. [13] | Dogra et al. [14] | Ullah et al. [15] | Huang et al. [16] | Liu et al. [17] | Mehta et al. [18] | Proposed Method |
|---|---|---|---|---|---|---|---|---|---|
| Mutual information (MI) | #1 | 2.1298 | 2.7849 | 3.0512 | 3.4810 | 3.3952 | 3.2967 | 3.1719 | 3.4917 |
| #2 | 2.7972 | 3.1168 | 2.4757 | 2.5788 | 2.2534 | 3.1270 | 3.5670 | 3.7710 | |
| #3 | 2.5610 | 2.6513 | 2.8315 | 2.4103 | 2.4124 | 2.7109 | 2.3709 | 2.8709 | |
| #4 | 2.1268 | 2.3103 | 2.2330 | 2.6150 | 2.2612 | 2.7120 | 2.1720 | 2.8710 | |
| #5 | 2.2111 | 2.2171 | 2.3212 | 2.1167 | 2.1019 | 2.1418 | 2.1178 | 2.6418 | |
| Standard deviation (SD) | #1 | 66.2122 | 81.0191 | 75.9053 | 84.2526 | 82.8310 | 81.0198 | 82.0498 | 85.0563 |
| #2 | 58.5118 | 72.0111 | 72.8118 | 75.1325 | 76.4587 | 77.1798 | 78.1448 | 78.7798 | |
| #3 | 55.2596 | 71.2195 | 71.1124 | 71.2723 | 71.1187 | 71.2272 | 71.2710 | 72.2350 | |
| #4 | 58.5555 | 72.5422 | 71.1446 | 73.3550 | 74.2444 | 75.0320 | 72.2320 | 75.1180 | |
| #5 | 67.8141 | 66.1515 | 69.0115 | 71.5219 | 72.2217 | 71.8761 | 72.8716 | 73.2276 | |
| QAB/F | #1 | 0.5101 | 0.5115 | 0.5202 | 0.5113 | 0.5218 | 0.5103 | 0.5301 | 0.5397 |
| #2 | 0.5183 | 0.5140 | 0.5178 | 0.5218 | 0.5187 | 0.5251 | 0.5211 | 0.5288 | |
| #3 | 0.5919 | 0.6151 | 0.6281 | 0.6271 | 0.6171 | 0.6311 | 0.6351 | 0.6398 | |
| #4 | 0.6141 | 0.6117 | 0.6220 | 0.6217 | 0.6428 | 0.6363 | 0.6151 | 0.6486 | |
| #5 | 0.6171 | 0.6312 | 0.6151 | 0.6222 | 0.6123 | 0.6454 | 0.6352 | 0.6510 | |
| Spatial frequency (SF) | #1 | 23.1212 | 27.7511 | 25.5710 | 26.8186 | 26.714 | 27.0110 | 27.5504 | 27.9822 |
| #2 | 21.1113 | 22.7833 | 22.6141 | 21.6113 | 21.5422 | 22.4123 | 22.7233 | 22.8123 | |
| #3 | 19.0926 | 21.1813 | 21.0111 | 20.1818 | 20.0718 | 20.0019 | 21.0019 | 21.3319 | |
| #4 | 17.3556 | 18.2313 | 18.1112 | 20.1122 | 19.4554 | 20.0013 | 20.1313 | 20.2923 | |
| #5 | 20.0961 | 18.8329 | 21.4140 | 18.3431 | 19.9129 | 18.2390 | 19.0120 | 21.4190 | |
| Mean | #1 | 49.3249 | 58.2346 | 53.8543 | 57.1209 | 56.0238 | 57.5120 | 57.5121 | 58.5350 |
| #2 | 44.1433 | 51.7246 | 47.4440 | 51.3356 | 52.1270 | 53.8219 | 51.3409 | 53.9609 | |
| #3 | 41.3453 | 41.1233 | 39.1753 | 41.0125 | 39.1241 | 38.1240 | 38.2134 | 42.7970 | |
| #4 | 40.4680 | 41.3643 | 39.1233 | 41.3430 | 38.3252 | 41.1122 | 41.1414 | 41.8324 | |
| #5 | 33.1282 | 36.8872 | 35.9921 | 34.4503 | 35.5453 | 33.4657 | 36.4457 | 37.0057 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Diwakar, M.; Singh, P.; Singh, R.; Sisodia, D.; Singh, V.; Maurya, A.; Kadry, S.; Sevcik, L. Multimodality Medical Image Fusion Using Clustered Dictionary Learning in Non-Subsampled Shearlet Transform. Diagnostics 2023, 13, 1395. https://doi.org/10.3390/diagnostics13081395
Diwakar M, Singh P, Singh R, Sisodia D, Singh V, Maurya A, Kadry S, Sevcik L. Multimodality Medical Image Fusion Using Clustered Dictionary Learning in Non-Subsampled Shearlet Transform. Diagnostics. 2023; 13(8):1395. https://doi.org/10.3390/diagnostics13081395
Chicago/Turabian StyleDiwakar, Manoj, Prabhishek Singh, Ravinder Singh, Dilip Sisodia, Vijendra Singh, Ankur Maurya, Seifedine Kadry, and Lukas Sevcik. 2023. "Multimodality Medical Image Fusion Using Clustered Dictionary Learning in Non-Subsampled Shearlet Transform" Diagnostics 13, no. 8: 1395. https://doi.org/10.3390/diagnostics13081395
APA StyleDiwakar, M., Singh, P., Singh, R., Sisodia, D., Singh, V., Maurya, A., Kadry, S., & Sevcik, L. (2023). Multimodality Medical Image Fusion Using Clustered Dictionary Learning in Non-Subsampled Shearlet Transform. Diagnostics, 13(8), 1395. https://doi.org/10.3390/diagnostics13081395