
AI-Based CXR First Reading: Current Limitations to Ensure Practical Value

 ,
,
Abstract
:1. Introduction
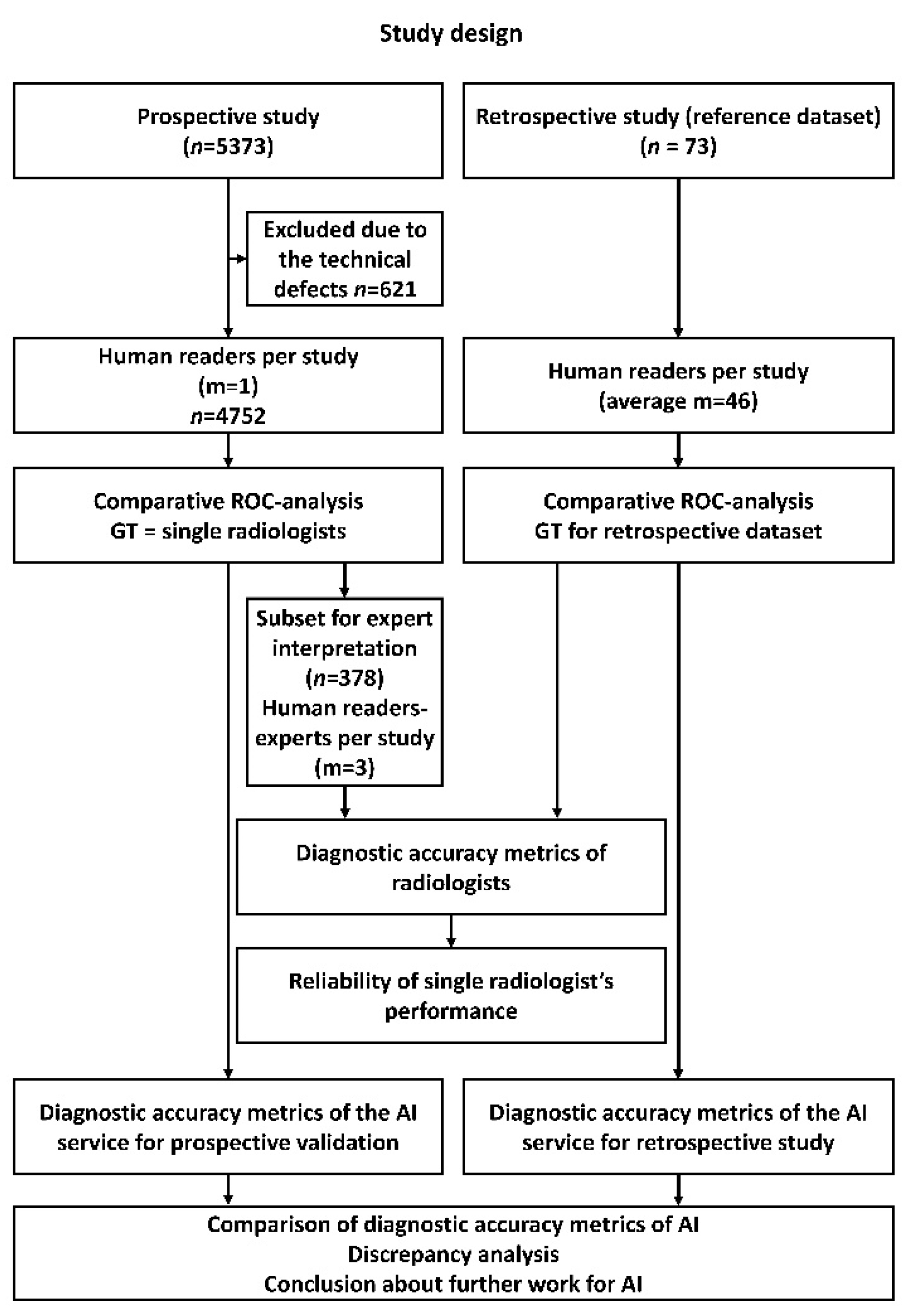
2. Materials and Methods
2.1. AI System
2.2. Retrospective Evaluation
- Pneumothorax;
- Atelectasis;
- Parenchymal opacification;
- Infiltrate or consolidation (infiltrate remains a controversial but applied term);
- Miliary pattern, or dissemination;
- Cavity;
- Pulmonary calcification;
- Pleural effusion;
- Fracture, or cortical irregularity.
2.3. Prospective Evaluation
2.4. Statistical Analysis
3. Results
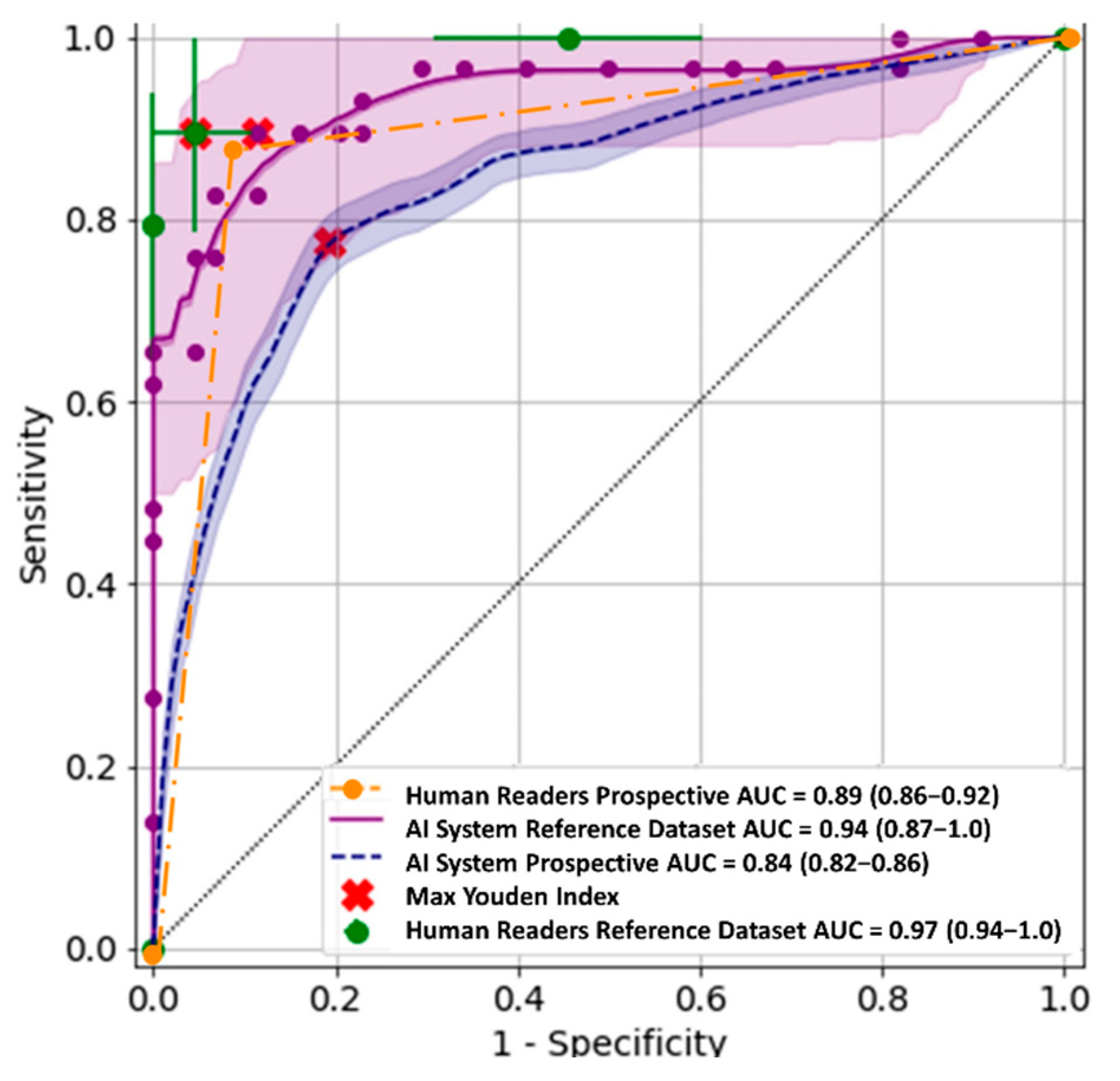
3.1. Retrospective Evaluation
3.2. Prospective Evaluation
4. Discussion
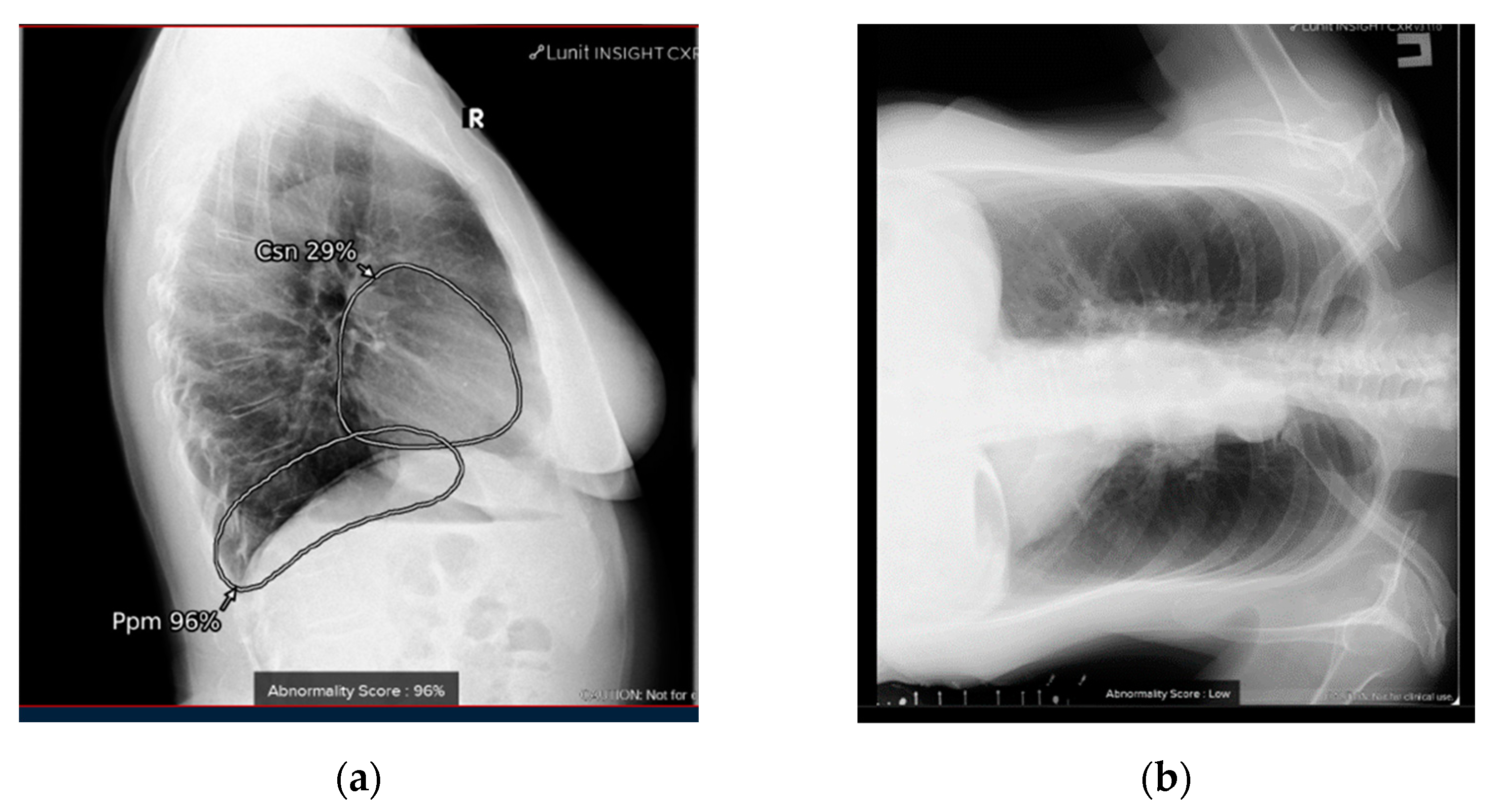
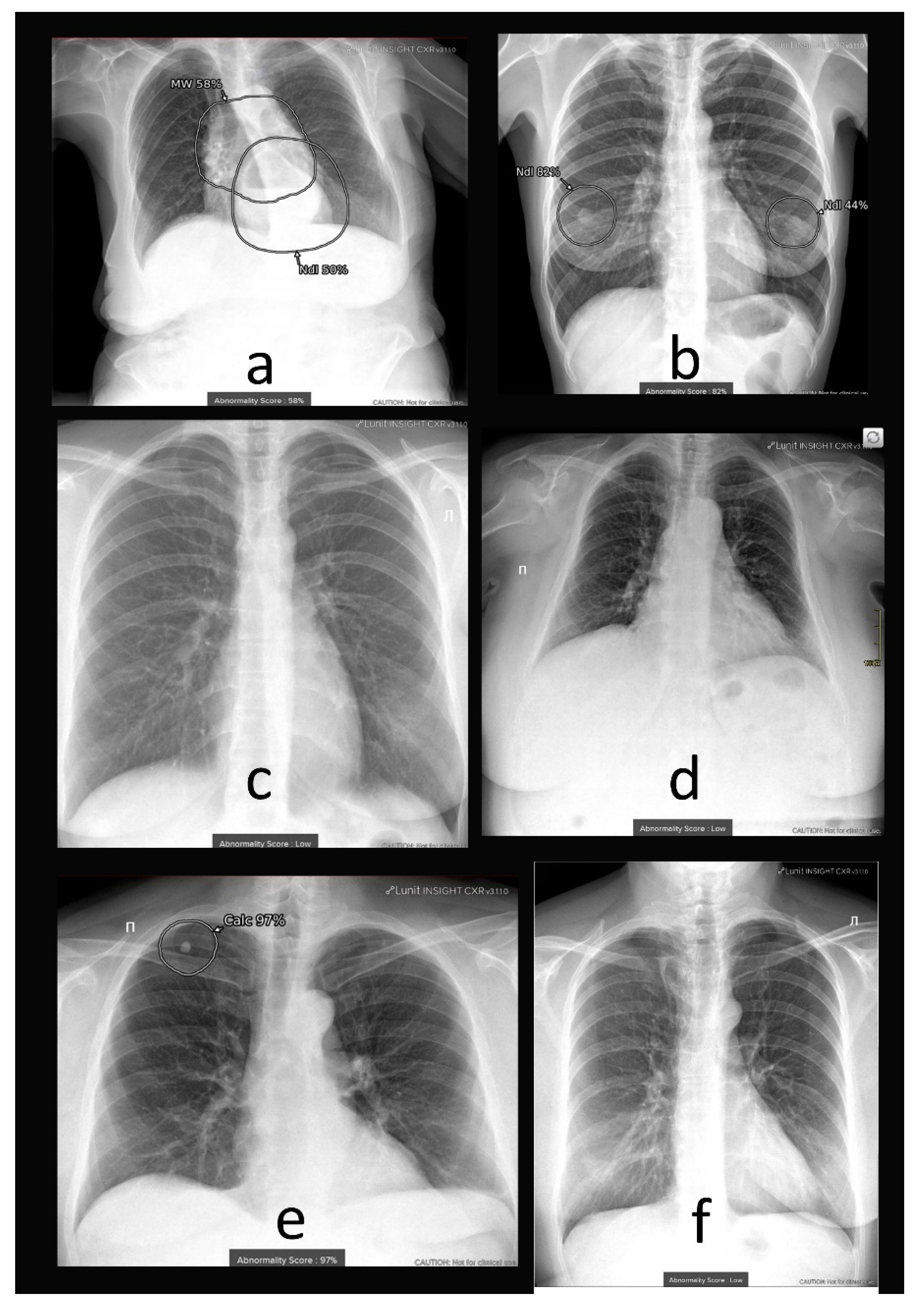
4.1. Additional Data and Technical Assessment of the Quality of Input CXR
4.2. Comprehensive Assessment of Identified Radiographic Features
4.3. Fine-Tuning of AI System
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Estimates, Global Health. Disease Burden by Cause, Age, Sex, by Country and by Region, 2000–2015; World Health Organization: Geneva, Switzerland, 2016. [Google Scholar]
- Watanabe, A.T.; Lim, V.; Vu, H.X.; Chim, R.; Weise, E.; Liu, J.; Bradley, W.G.; Comstock, C.E. Improved cancer detection using artificial intelligence: A retrospective evaluation of missed cancers on mammography. J. Digit. Imaging 2019, 32, 625–637. [Google Scholar] [CrossRef]
- Posso, M.C.; Puig, T.; Quintana, M.J.; Solà-Roca, J.; Bonfill, X. Double versus single reading of mammograms in a breast cancer screening programme: A cost-consequence analysis. Eur. Radiol. 2016, 26, 3262–3271. [Google Scholar] [CrossRef] [PubMed]
- Wuni, A.R.; Courtier, N.; Kelly, D. Developing a policy framework to support role extension in diagnostic radiography in Ghana. J. Med. Imaging Radiat. Sci. 2021, 52, 112–120. [Google Scholar] [CrossRef]
- Annarumma, M.; Withey, S.J.; Bakewell, R.J.; Pesce, E.; Goh, V.; Montana, G. Automated triaging of adult chest radiographs with deep artificial neural networks. Radiology 2019, 291, 196–202. [Google Scholar] [CrossRef] [PubMed]
- Hwang, E.J.; Park, S.; Jin, K.N.; Im Kim, J.; Choi, S.Y.; Lee, J.H.; Goo, J.M.; Aum, J.; Yim, J.J.; Cohen, J.G.; et al. Development and validation of a deep learning–based automated detection algorithm for major thoracic diseases on chest radiographs. JAMA Netw. Open 2019, 2, e191095. [Google Scholar] [CrossRef] [PubMed]
- Harris, M.; Qi, A.; Jeagal, L.; Torabi, N.; Menzies, D.; Korobitsyn, A.; Pai, M.; Nathavitharana, R.R.; Ahmad Khan, F. A systematic review of the diagnostic accuracy of artificial intelligence-based computer programs to analyze chest x-rays for pulmonary tuberculosis. PLoS ONE 2019, 14, e0221339. [Google Scholar] [CrossRef]
- Codlin, A.J.; Dao, T.P.; Vo, L.N.Q.; Forse, R.J.; Van Truong, V.; Dang, H.M.; Nguyen, L.H.; Nguyen, H.B.; Nguyen, N.V.; Sidney-Annerstedt, K.; et al. Independent evaluation of 12 artificial intelligence solutions for the detection of tuberculosis. Sci. Rep. 2021, 11, 23895. [Google Scholar] [CrossRef]
- Adams, S.J.; Henderson, R.D.; Yi, X.; Babyn, P. Artificial Intelligence Solutions for Analysis of X-ray Images. Can. Assoc. Radiol. J. 2021, 72, 60–72. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.T.; Wong, K.C.; Gur, Y.; Ansari, N.; Karargyris, A.; Sharma, A.; Morris, M.; Saboury, B.; Ahmad, H.; Boyko, O.; et al. Comparison of Chest Radiograph Interpretations by Artificial Intelligence Algorithm vs Radiology Residents. JAMA Netw. Open 2020, 3, e2022779. [Google Scholar] [CrossRef] [PubMed]
- Catalina, Q.M.; Fuster-Casanovas, A.; Solé-Casals, J.; Vidal-Alaball, J. Developing an Artificial Intelligence Model for Reading Chest X-rays: Protocol for a Prospective Validation Study. JMIR Res. Protoc. 2022, 11, e39536. [Google Scholar] [CrossRef]
- Ahn, J.S.; Ebrahimian, S.; McDermott, S.; Lee, S.; Naccarato, L.; Di Capua, J.F.; Wu, M.Y.; Zhang, E.W.; Muse, V.; Miller, B.; et al. Association of Artificial Intelligence–Aided Chest Radiograph Interpretation with Reader Performance and Efficiency. JAMA Netw. Open 2022, 5, e2229289. [Google Scholar] [CrossRef] [PubMed]
- AI for Radiology. Available online: https://grand-challenge.org/aiforradiology/?subspeciality=Chest&modality=X-ray&ce_under=All&ce_class=All&fda_class=All&sort_by=lastmodified&search= (accessed on 2 April 2023).
- CE Mark for First Autonomous AI Medical Imaging Application. Available online: https://oxipit.ai/news/first-autonomous-ai-medical-imaging-application/ (accessed on 2 April 2023).
- Irmici, G.; Cè, M.; Caloro, E.; Khenkina, N.; Della Pepa, G.; Ascenti, V.; Martinenghi, C.; Papa, S.; Oliva, G.; Cellina, M. Chest X-ray in Emergency Radiology: What Artificial Intelligence Applications Are Available? Diagnostics 2023, 13, 216. [Google Scholar] [CrossRef] [PubMed]
- Govindarajan, A.; Govindarajan, A.; Tanamala, S.; Chattoraj, S.; Reddy, B.; Agrawal, R.; Iyer, D.; Srivastava, A.; Kumar, P.; Putha, P. Role of an Automated Deep Learning Algorithm for Reliable Screening of Abnormality in Chest Radiographs: A Prospective Multicenter Quality Improvement Study. Diagnostics 2022, 12, 2724. [Google Scholar] [CrossRef] [PubMed]
- Morozov, S.P.; Kokina, D.Y.; Pavlov, N.A.; Kirpichev, Y.S.; Gombolevskiy, V.A.; Andreychenko, A.E. Clinical aspects of using artificial intelligence for the interpretation of chest X-rays. Tuberc. Lung Diseases 2021, 99, 58–64. [Google Scholar] [CrossRef]
- Pot, M.; Kieusseyan, N.; Prainsack, B. Not all biases are bad: Equitable and inequitable biases in machine learning and radiology. Insights Into Imaging 2021, 12, 1–10. [Google Scholar] [CrossRef]
- Nam, J.G.; Kim, M.; Park, J.; Hwang, E.J.; Lee, J.H.; Hong, J.H.; Goo, J.M.; Park, C.M. Development and validation of a deep learning algorithm detecting 10 common abnormalities on chest radiographs. Eur. Respir. J. 2021, 57, 2003061. [Google Scholar] [CrossRef] [PubMed]
- Lunit Inc. Available online: https://www.lunit.io/en/products/cxr (accessed on 2 April 2023).
- Hansell, D.M.; Bankier, A.A.; MacMahon, H.; McLoud, T.C.; Muller, N.L.; Remy, J. Fleischner Society: Glossary of terms for thoracic imaging. Radiology 2008, 246, 697–722. [Google Scholar] [CrossRef]
- Polishchuk, N.S.; Vetsheva, N.N.; Kosarin, S.P.; Morozov, S.P.; Kuz’Mina, E.S. Unified radiological information service as a key element of organizational and methodical work of Research and Practical Center of Medical Radiology. Radiologiya–Praktika (Radiology–Practice) 2018, 1, 6–17. [Google Scholar]
- Morozov, S.; Guseva, E.; Ledikhova, N.; Vladzymyrskyy, A.; Safronov, D. Telemedicine-based system for quality management and peer review in radiology. Insights Into Imaging 2018, 9, 337–341. [Google Scholar] [CrossRef]
- Kokina, D.Y.; Gombolevskiy, V.A.; Arzamasov, K.M.; Andreychenko, A.E.; Morozov, S.P. Possibilities and limitations of using machine text-processing tools in Russian radiology reports. Digit. Diagnostics 2022, 3, 374–383. [Google Scholar] [CrossRef]
- Sun, X.; Xu, W. Fast implementation of DeLong’s algorithm for comparing the areas under correlated receiver operating characteristic curves. IEEE Signal Process. Lett. 2014, 21, 1389–1393. [Google Scholar] [CrossRef]
- Eliasziw, M.; Donner, A. Application of the McNemar test to non-independent matched pair data. Statist. Med. 1991, 10, 1981–1991. [Google Scholar] [CrossRef] [PubMed]
- Youden, W. Index for rating diagnostic tests. Cancer 1950, 3, 32–35. [Google Scholar] [CrossRef]
- Ruopp, M.; Perkins, N.; Whitcomb, B.; Schisterman, E. Youden Index and Optimal Cut-Point Estimated from Observations Affected by a Lower Limit of Detection. Biom. J. 2008, 50, 419–430. [Google Scholar] [CrossRef]
- Landis, J.R.; Koch, G.G. The measurement of observer agreement for categorical data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef] [PubMed]
- Larson, D.B.; Harvey, H.; Rubin, D.L.; Irani, N.; Justin, R.T.; Langlotz, C.P. Regulatory frameworks for development and evaluation of artificial intelligence-based diagnostic imaging algorithms: Summary and recommendations. J. Am. Coll. Radiol. 2021, 18, 413–424. [Google Scholar] [CrossRef]
- Sounderajah, V.; Ashrafian, H.; Aggarwal, R.; De Fauw, J.; Denniston, A.K.; Greaves, F.; Karthikesalingam, A.; King, D.; Liu, X.; Markar, S.R.; et al. Developing specific reporting guidelines for diagnostic accuracy studies assessing AI interventions: The STARD-AI Steering Group. Nat. Med. 2020, 26, 807–808. [Google Scholar] [CrossRef]
- Liu, X.; Rivera, S.C.; Moher, D.; Calvert, M.J.; Denniston, A.K.; Ashrafian, H.; Beam, A.L.; Chan, A.W.; Collins, G.S.; Deeks, A.D.J.; et al. Reporting guidelines for clinical trial reports for interventions involving artificial intelligence: The CONSORT-AI extension. Nat. Med. 2020, 26, 1364–1374. [Google Scholar] [CrossRef] [PubMed]
- Nam, J.G.; Hwang, E.J.; Kim, D.S.; Yoo, S.J.; Choi, H.; Goo, J.M.; Park, C.M. Undetected Lung Cancer at Posteroanterior Chest Radiography: Potential Role of a Deep Learning–based Detection Algorithm. Radiol. Cardiothorac. Imaging 2020, 2, e190222. [Google Scholar] [CrossRef] [PubMed]
- Yoo, H.; Kim, K.H.; Singh, R.; Digumarthy, S.R.; Kalra, M.K. Validation of a deep learning algorithm for the detection of malignant pulmonary nodules in chest radiographs. JAMA Netw. Open 2020, 3, e2017135. [Google Scholar] [CrossRef]
- Ebrahimian, S.; Homayounieh, F.; Rockenbach, M.A.; Putha, P.; Raj, T.; Dayan, I.; Bizzo, B.C.; Buch, V.; Wu, D.; Kim, K.; et al. Artificial intelligence matches subjective severity assessment of pneumonia for prediction of patient outcome and need for mechanical ventilation: A cohort study. Sci. Rep. 2021, 11, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Akselrod-Ballin, A.; Chorev, M.; Shoshan, Y.; Spiro, A.; Hazan, A.; Melamed, R.; Barkan, E.; Herzel, E.; Naor, S.; Karavani, E.; et al. Predicting Breast Cancer by Applying Deep Learning to Linked Health Records and Mammograms. Radiology 2019, 292, 331–342. [Google Scholar] [CrossRef] [PubMed]
- Morozov, S.P.; Vladzymyrskyy, A.V.; Klyashtornyy, V.G.; Andreychenko, A.E.; Kulberg, N.S.; Gombolevsky, V.A.; Sergunova, K.A. Clinical Acceptance of Software Based on Artificial Intelligence Technologies (Radiology). arXiv 2019, arXiv:1908.00381. [Google Scholar]
- Ahmad, H.K.; Milne, M.R.; Buchlak, Q.D.; Ektas, N.; Sanderson, G.; Chamtie, H.; Karunasena, S.; Chiang, J.; Holt, X.; Tang, C.H.; et al. Machine Learning Augmented Interpretation of Chest X-rays: A Systematic Review. Diagnostics 2023, 13, 743. [Google Scholar] [CrossRef] [PubMed]
- Sverzellati, N.; Ryerson, C.J.; Milanese, G.; Renzoni, E.A.; Volpi, A.; Spagnolo, P.; Bonella, F.; Comelli, I.; Affanni, P.; Veronesi, L.; et al. Chest radiography or computed tomography for COVID-19 pneumonia? Comparative study in a simulated triage setting. Eur. Respir. J. 2021, 58, 2004188. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristic | Local Test Set | Prospective Dataset | Sample from the Prospective Dataset Additionally Interpreted by Experts |
|---|---|---|---|
| No. of patients (abnormal * cases) | 73 (29) | 4752 (694) | 378 (185) |
| Number of radiologists | 160 (average 46 per study) | 226 (1 per study) | 99 (1 per study) |
| Confirmation of (ab)normality by | consensus two experts (>5 years of experience) | radiology report | consensus of at least two experts (>5 years of experience) |
| Male/female/unknown | 30/42/1 | 1746/3005/1 | 140/238 |
| Age (y) ** | 50 ± 19 | 49 ± 16 | 55 ± 17 |
| No. of diagnostic devices | 38 | 113 | 79 |
| Vendors | GE HealthCare, Chicago, IL, USA S.P.Helpic LLC, Moscow, Russia Fujifilm, Tokyo, Japan Philips, Amsterdam, The Netherlands Toshiba Medical Systems Corporation, Tokyo, Japan NIPK Electron Co., Saint Petersburg, Russia MEDICAL TECHNOLOGIES Co., Ltd., Moscow, Russia. | ||
| Diagnostic Performance Metrics | AI System | Human Readers | p-Value |
|---|---|---|---|
| AUC (CI 95%) | 0.94 (0.87–1.0) | 0.97 (0.94–1.0) | 0.51 |
| Sensitivity * (CI 95%) | 0.9 (0.79–1.0) | 0.9 (0.79–1.0) | 1.0 |
| Specificity * (CI 95%) | 0.89 (0.79–0.98) | 0.95 (0.89–1.0) | 0.26 |
| Cappa Kohen * for GT | 0.74 (0.58–0.9) | 0.86 (0.74–0.98) | |
| Agreement * for GT | 93% | 88% | |
| Cohen’s Kappa * for radiologists and AI | 0.71 (0.54–0.88) | ||
| Agreement * for radiologists and AI | 86% |
| Diagnostic Performance Metrics | AI System | Human Readers (Sample from the Prospective Dataset for Expert Interpretation) |
|---|---|---|
| AUC (CI 95%) | 0.84 (0.82–0.86) | 0.89 (0.86–0.92) |
| Sensitivity (CI 95%) | 0.77 * (0.73–0.80) | 0.86 ** (0.82–0.91) |
| Specificity (CI 95%) | 0.81 * (0.80–0.82) | 0.92 ** (0.88–0.96) |
| Cappa Kohen * for radiologists and AI | 0.42 (0.38–0.45) | |
| Agreement * for radiologists and AI | 81% | |
| Cohen’s Kappa ** for radiologists and experts | 0.79 (0.72–0.85) | |
| Agreement ** for radiologists and experts | 89% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vasilev, Y.; Vladzymyrskyy, A.; Omelyanskaya, O.; Blokhin, I.; Kirpichev, Y.; Arzamasov, K. AI-Based CXR First Reading: Current Limitations to Ensure Practical Value. Diagnostics 2023, 13, 1430. https://doi.org/10.3390/diagnostics13081430
Vasilev Y, Vladzymyrskyy A, Omelyanskaya O, Blokhin I, Kirpichev Y, Arzamasov K. AI-Based CXR First Reading: Current Limitations to Ensure Practical Value. Diagnostics. 2023; 13(8):1430. https://doi.org/10.3390/diagnostics13081430
Chicago/Turabian StyleVasilev, Yuriy, Anton Vladzymyrskyy, Olga Omelyanskaya, Ivan Blokhin, Yury Kirpichev, and Kirill Arzamasov. 2023. "AI-Based CXR First Reading: Current Limitations to Ensure Practical Value" Diagnostics 13, no. 8: 1430. https://doi.org/10.3390/diagnostics13081430
APA StyleVasilev, Y., Vladzymyrskyy, A., Omelyanskaya, O., Blokhin, I., Kirpichev, Y., & Arzamasov, K. (2023). AI-Based CXR First Reading: Current Limitations to Ensure Practical Value. Diagnostics, 13(8), 1430. https://doi.org/10.3390/diagnostics13081430