1. Introduction
Single-plane fluoroscopy remains a valuable modality due to its real-time temporal resolution, positional flexibility, and potentially lower radiation dosage relative to other cross-sectional imaging systems [
1] such as computed tomography (CT) scans. The advantages of fluoroscopy make it particularly suitable for minimally invasive image-guided interventions [
2] where temporal resolution is paramount.
Fluoroscopy systems have traditionally involved the use of an image intensifier. However, newer-generation, solid-state systems have also become available. The latter benefits from significantly reduced distortion [
3] compared to the former, with the former also requiring quality control programs to monitor inevitable changes caused from the intensifier [
4]. Despite the benefits of newer-generation, solid-state systems, image intensifier systems are still widely adopted. This work therefore specifically focuses on fluoroscopy systems with image intensifiers, addressing the critical issue of their image quality.
The advent of high-precision robotic platforms has been effective in supporting patient outcomes in several interventions [
5,
6,
7,
8]. The accuracy of such robotic tools is closely linked with that of fluoroscopic imaging systems due to their use in the navigation and application of these tools. Consequently, enhanced image quality in pursuit of higher accuracy than the robotic system itself instills increased confidence in the performed intervention. A critical determinant of this accuracy is the understanding of a camera system’s internal characteristics, achieved through the estimation of its interior orientation parameters (IOPs). The IOPs comprise key elements of the “internal” geometry of an imaging system as well as distortion coefficients that characterize the departures from ideal imaging geometry.
Several types of distortion can significantly impact the system’s IOPs, resulting in image warping and decreased accuracy. This distortion can be particularly troublesome in applications where the quantification of imaging features is required for diagnosis [
9] or anatomical navigation [
10,
11].
This distortion is composed of the following elements: radial, decentering, affinity, s-shaped sigmoidal, and local distortions. Radial distortion, characterized by a pincushion effect, emerges from non-planar projection through the imaging system optics (such as from the curved image intensifier) [
10] or onto a non-planar sensor surface [
12]. Decentering distortion can result from the misalignment of imaging system components [
13]. Affinity distortion is typically associated with an unequal imaging sensor array on the x- and y-axes [
12], comprising non-orthogonality in the resulting image due to several potential factors. Sigmoid distortion arises as a function of the system’s external orientation to the Earth’s magnetic field [
14,
15]. Conversely, local non-homogenous magnetic fields from surrounding equipment and the environment induce local distortion [
11,
16]. The five distortion effects all result in the displacement of the image points from their expected locations.
The estimation and correction of these distortions can be achieved using global polynomial estimation [
16]. This approach fits a generalized polynomial across the fluoroscopy system’s orientation range. However, due to its generalized nature, it does not provide insights on the characteristics of the types of distortion modeled. Recent studies have also detailed the use of self-supervised methods for the accurate modeling of systematic distortion within fluoroscopy systems. This is accomplished through the integration of iterative maximum likelihood estimation and k-nearest-neighbor regression [
17].
Alternatively, the rigorous self-calibrating bundle adjustment has been effectively used to estimate and rectify distortion within imagery captured from a dual-fluoroscopy system [
18]. This method has been previously explored in the context of research lab systems. This study aims to explore the application of this method within the context of single-plane fluoroscopy in the estimation and correction of image distortion in systems used in outpatient radiology clinics and hospital settings.
The application of this method within the context of a clinical setting introduces the possibility of improved quantitative analysis and observation of anatomical and clinically relevant features. This form of calibration creates a set of common and calibrated imagery which can be used to establish new measurement baselines. This concept has been successfully explored within the context of diaphragm paralysis analysis [
19].
2. Materials and Methods
Data from a target field were collected at two Canadian academic hospitals to determine three distinct fluoroscopy machines’ distortion profiles and calibration parameters. This study further provided quality control of the fluoroscopy systems through the analysis of accuracy for systems used clinically on a daily basis.
This was achieved by implementing a free-network, self-calibrating bundle adjustment [
20], a rigorous and flexible calibration method. This method fundamentally relies on the principle of the collinearity condition, which postulates that a target—whether a patient or phantom—in 3-dimensional (3D) object space aligns in a straight (collinear) line with its 2-dimensional (2D) projection captured in image space.
This model can be expressed in terms of object point
i, image point
j, and imaging system
k, in the following expression with respect to the
x-,
y-axes.
The terms on the left of Equations (1) and (2) include the coordinates of the observed image points (
) in an image space coordinate system. The additive terms of (
) represent the zero-mean white noise error to the observation. The right of the equation includes the imaging system’s principal point (
) and principal distance (
). The geometric distortion correction coefficients of the imaging system are represented by (
). It is worth noting that the principal point, principal distance, and geometric distortion correction coefficients all contribute to the overall image distortion between the expected and observed image points. The transformation between the object space coordinates to the image space coordinates is seen in the relational term multiplied by the principal distance. This relationship is typically between the coordinates in millimeters (mm) and pixels (pix), with the transformation defined in the following.
In Equation (3), the difference between the object space coordinates (
) and the principal center coordinates (
) is taken. The coordinate difference is multiplied by the rotation sequence of
, where
are rotations with respect to the (
) primary, secondary, and tertiary axes. For additional information and robust implementation of the collinearity equation and self-calibrating bundle adjustment, please refer to additional resources [
12,
13,
20].
We can estimate the parameters of this relationship using a weighted least-squares adjustment (LSA). The LSA can also estimate exterior orientation parameters (EOPs) which represent the orientation and position of the captured fluoroscopy imagery relative to the phantom/target of interest.
Moreover, the functional model can be augmented by incorporating empirically determined image distortion models to account for systematic errors introduced by the fluoroscopy system. These parameters are estimated within the LSA framework, offering a robust strategy to mitigate the impact of distortions in the imaging process.
A low-cost, custom-made target field was utilized as the calibration frame for this study. It comprises a 25.4 mm × 25.4 mm acrylic sheet embedded with 121 regularly spaced radiopaque and solid tantalum beads. The 3D coordinates of these beads were estimated approximately from the machine-drilled holes in the acrylic sheet, serving as initial values in the bundle adjustment. It is important to note that the beads were also surveyed with high accuracy to provide additional quality control and to assess accuracy, surpassing what is achievable via the self-calibration bundle adjustment for comparison. Such precision is not necessary in a clinical deployment, in order to keep costs low. Other radiopaque materials could be chosen to keep costs low, such as steel beads [
18], which have been successfully utilized. The size of the radiopaque material is a balance between the density of points on the calibration frame and the visibility of the target in the imagery. The shape of the radiopaque material should be one in which it is easy to estimate the center of the object. A sphere is a strong choice, as ellipse fitting algorithms or centroid algorithms can be used to determine its position.
Fluoroscopic images were obtained using three distinct radiography/fluoroscopy rooms across two academic hospitals, each equipped with an image intensifier (Easy Diagnost, Phillips Medical Systems, Amsterdam, The Netherlands). These systems were chosen due to their clinical relevancy, as they are used for patient care on a daily basis. This further increases the opportunity for improving patient care in systems that are being actively utilized.
Fluoroscopic spot images and exposure images (lower and higher X-ray radiation, respectively) were captured. The acquired images were stored in a 512 × 512 8-bit digital format for subsequent processing.
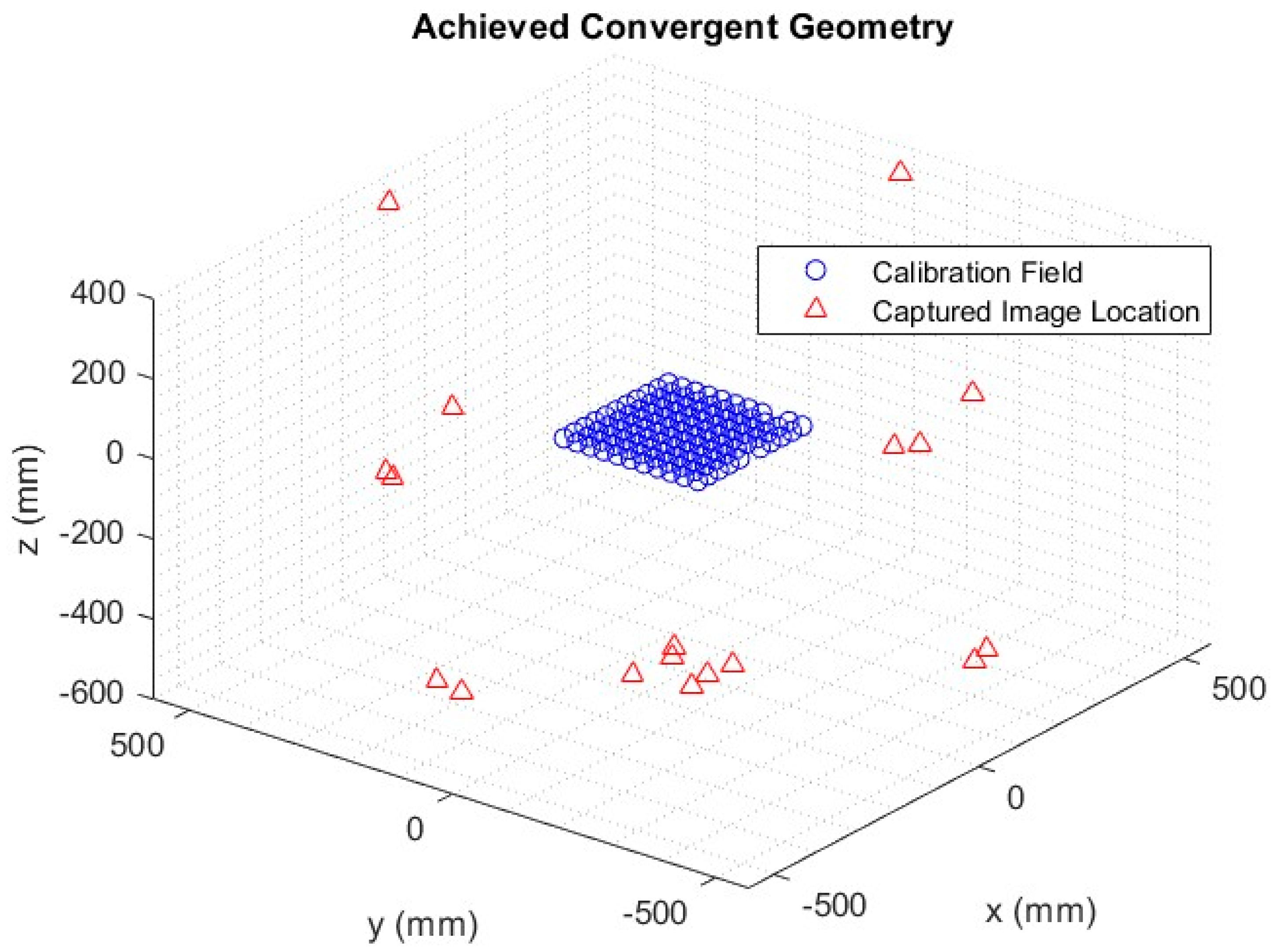
For accurate distortion modeling of systematic errors within the imagery, it is imperative to have a highly redundant set of observations as part of the LSA. However, the LSA estimation process often yields a high level of correlation between the IOPs and EOPs, leading to poor numerical conditioning of the model. To de-correlate these parameters, an established approach to the network design of the captured imagery is required. This strategy should include highly convergent imagery, varying orientations (i.e., landscape and portrait imagery), a dense array of targets, and a wide distribution of targets across the field of view (FOV) [
13].
These principles were incorporated into the network used for image capture (
Figure 1) across all three fluoroscopy suites. The image capture process commenced with the target field positioned parallel to the image intensifier. This was followed by capturing multiple images with translation across the intensifier’s FOV. Subsequently, the target field was positioned at a 30° angle using a wooden stand and captured in one quadrant. The stand was then moved 90° to the next quadrant while the frame was also rotated by 90° within the stand, ensuring the same front face was maintained. This process was repeated for all four quadrants.
A distinctive feature of X-ray imaging systems, as compared to conventional camera systems, is their ability to “see through” or penetrate objects. We exploited this unique characteristic by rotating the target field 180° to its back face, with the rotations across all four quadrants repeated from this perspective. This allowed for highly convergent imagery across the entirety of the FOV. Alternatively, the data acquisition can be semi-automated by introducing a self-moving platform, such as a robotic arm or turn-table [
18]; however, it would increase the operational cost.
The 2D image coordinates of the tantalum beads were identified and labeled from the captured imagery using a custom-developed MATLAB program (MathWorks Inc., Version R2021a, Natick, MA, USA). In the captured imagery, the beads appeared only several pixels wide due to the small image format size and its required FOV. This necessitated morphological differencing to enhance the available detection area [
21], with the resulting targets subsequently thresholded and converted into binary labels. The binary labels provide vertices that can be used to construct a polygon, with the resulting centroid equaling the average geometric center of the shape (
Figure 2). The resulting targets were semi-automatically labeled based on their sequence, requiring minimal manual labeling and intervention (
Figure 2). Labels were based on a predefined numeric identifier, which allowed for associating their 2D image coordinates with the corresponding 3D object coordinates.
The total statistics of the captured image point are summarized in the following table (
Table 1).
The calibration model concurrently estimates all parameters, including IOPs, EOPs, and object space coordinates, within a single application of the LSA. The distortion parameters representing several types of distortion can all be modeled at once, as well. However, this can lead to overparameterization and poor determination of distortion correction coefficients, which necessitates an iterative and interactive approach. This can be conducted through statistical and graphical analyses, ensuring that each distortion parameter introduced in the model contributes significantly to the overall solution [
13] and the model complexity minimizes the bias–variance tradeoff.
To assess the resulting accuracy, detached from the fitted model, an independent assessment was performed using a separate set of images (i.e., test dataset). This is accomplished with a limited image set with and without correction parameters applied. The external standard against which these results were compared is the independently surveyed target frame, which was captured with additional images. This approach allows for the evaluation of the effectiveness of the applied corrections effectively serving as a comparison to an external standard.
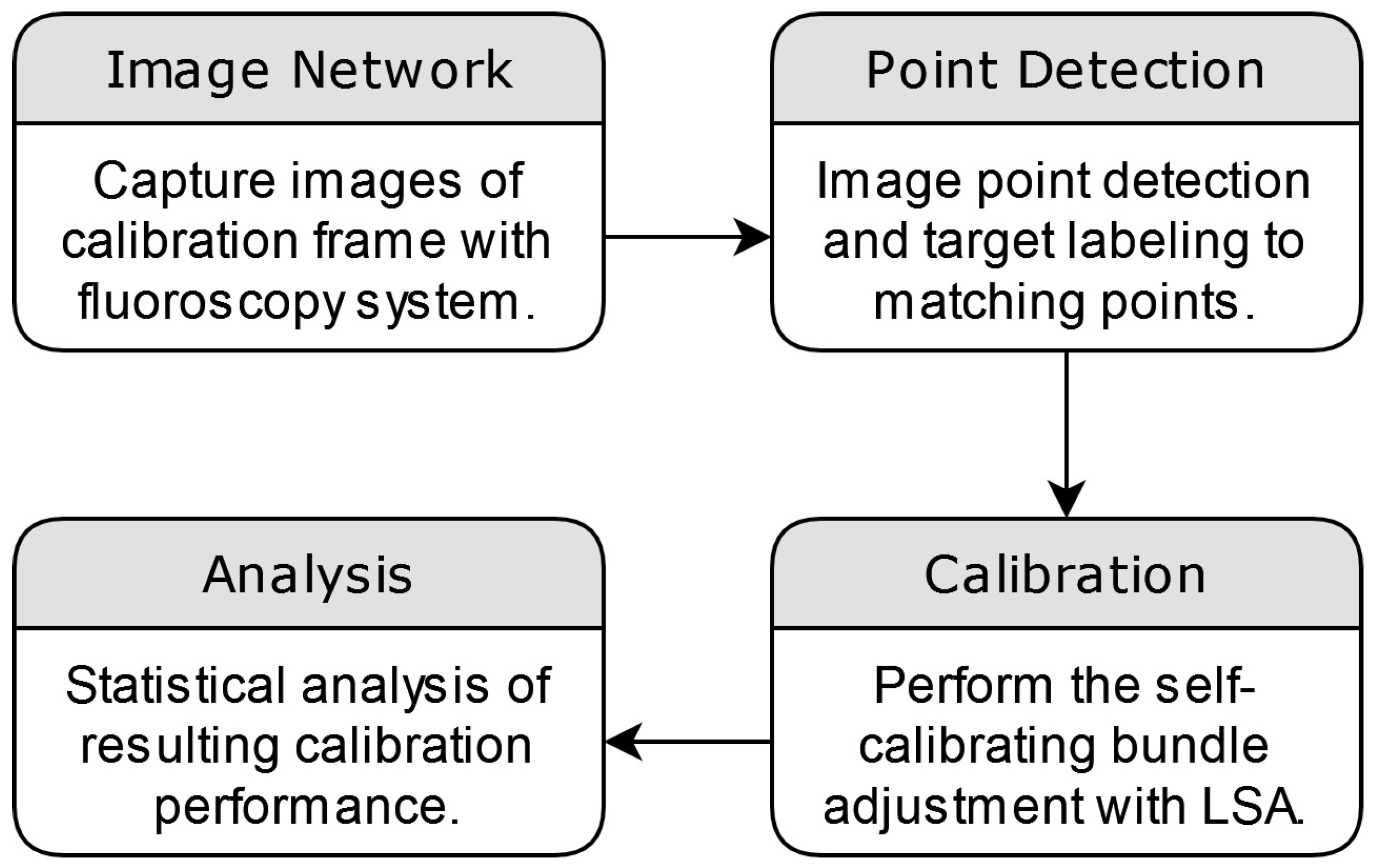
As this study’s primary focus was on the geometric distortion of the imagery, the statistical methods chosen were specifically designed to evaluate the geometric differences between the estimated points derived from the calibration process and the pre-surveyed coordinates of the calibration frame. These statistics were further calculated to evaluate the estimated overall model quality. This included the root mean square error (RMSE) of the image residuals, which signifies overall model fit; 3D reconstruction accuracy through RMSE between the estimated and surveyed distance between coordinates; and the standard deviation of the estimated correction parameters, an indicator of the significance of the applied correction. The overall methodology from image capture to analysis is summarized in
Figure 3.
3. Results
All evaluated fluoroscopy systems were similar regarding total captured imagery, the relative orientation of imagery, and the number of targets detected, as described in
Table 1. All systems were evaluated with a highly redundant and well-conditioned functional model. This functional model consisted of five distortion parameters for system F1, eight for C1, and five for C2. These comprise the distortion categories of radial, decentering, affinity, s-shaped sigmoidal, and local distortions. Each resulting functional model was statistically significant with a standard deviation at least an order of magnitude smaller than the parameters.
Functional models were developed using both fluoroscopic spot imagery and exposure imagery. No differences were found with models developed using either form of the captured imagery.
The captured image point observations can be first evaluated through the RMSE of their residuals (observation error estimates) to quantify their fit to the functional model. The imaging systems were evaluated with pre- and post-application of distortion parameters (
Table 2). All systems achieved a similar level of improvement, between 83 and 85%. The estimated variance factor (quadratic form of the residuals) can be further evaluated between pre- and post-application of estimated distortion parameters to provide an indication of the overall fit of the stochastic model to the observed image points. The imaging systems experienced an average enhancement of ~98% (
Table 2), indicating effective modeling within the stochastic framework through the incorporation of distortion parameters.
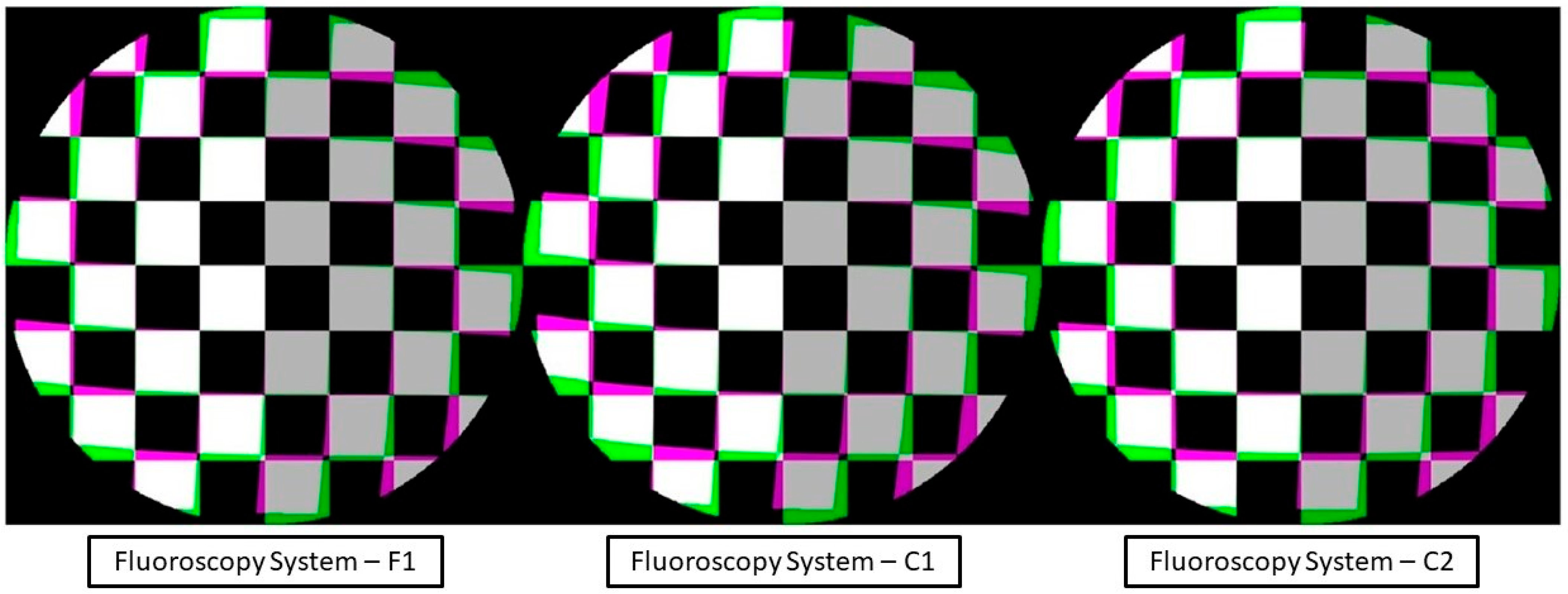
The distortion profile could then be displayed in conjunction with the corresponding correction applied to the imagery. The estimated distortion parameters from the self-calibrating bundle adjustment were calculated and mapped to each pixel within the captured imagery. This in effect corrected the distortion field of the imagery. The distortion field could be further visualized by its application to a regularly spaced virtual image of a checkerboard. The resulting image (
Figure 4) displays the difference in the checkerboard to its mapped distortion profile.
The distortion correction models can be applied to the captured imagery of the calibration frame to visualize the pre- and post-distortion correction (
Figure 5).
The imaging systems’ 3D reconstruction accuracy was evaluated with pre- and post-application of distortion parameters (
Table 3). Two independent accuracy assessments (with and without the modeled distortion parameters) were used to determine the overall model improvement in the fluoroscopy imaging systems. A subset of test images from each fluoroscopy system underwent the application of the bundle adjustment to estimate the 3D coordinates of the tantalum beads. Distances were subsequently calculated between the estimated coordinates and compared to the distances of the pre-surveyed ground truth coordinates. The residuals were then evaluated through their mean, standard deviation, and RMSE. The resulting improvement ranged from 83 to 97% for the test dataset (
Table 3).
4. Diagnostic Application
The use of quantitative measurements in medical imaging can significantly enhance the accuracy and efficiency of diagnostics and surgical planning, offering a more precise and data-driven approach to patient care. Different quantitative methods have been successfully developed and have seen various levels of clinical adoption. One challenging diagnosis area that could benefit from quantitative measurements is detecting paradoxical diaphragm motion and diagnosing hemidiaphragm paralysis [
19].
The gold-standard method for diagnosis is the fluoroscopic sniff test. The motion of the diaphragm is analyzed following inspiration to evaluate the presence of potential abnormalities in muscular contraction. However, the paradoxical motion between hemidiaphragms can be subtle and occur quickly [
19]. The extraction of the diaphragm surface and temporal motion from fluoroscopic imagery can provide an objective measure of the statistical significance of any potential paradoxical motion. This can be an essential indicator in the prognosis and selection of treatment plans such as diaphragm plication [
19].
The geometric calibration of fluoroscopic imagery provides improved confidence in the statistics and detection of diaphragm motion. This is important, as potential abnormalities can be missed due to sensitive geometry.
To demonstrate this, fluoroscopic imagery from a patient with chronic left hemidiaphragm paralysis [
19] was calibrated to observe the changes in movement.
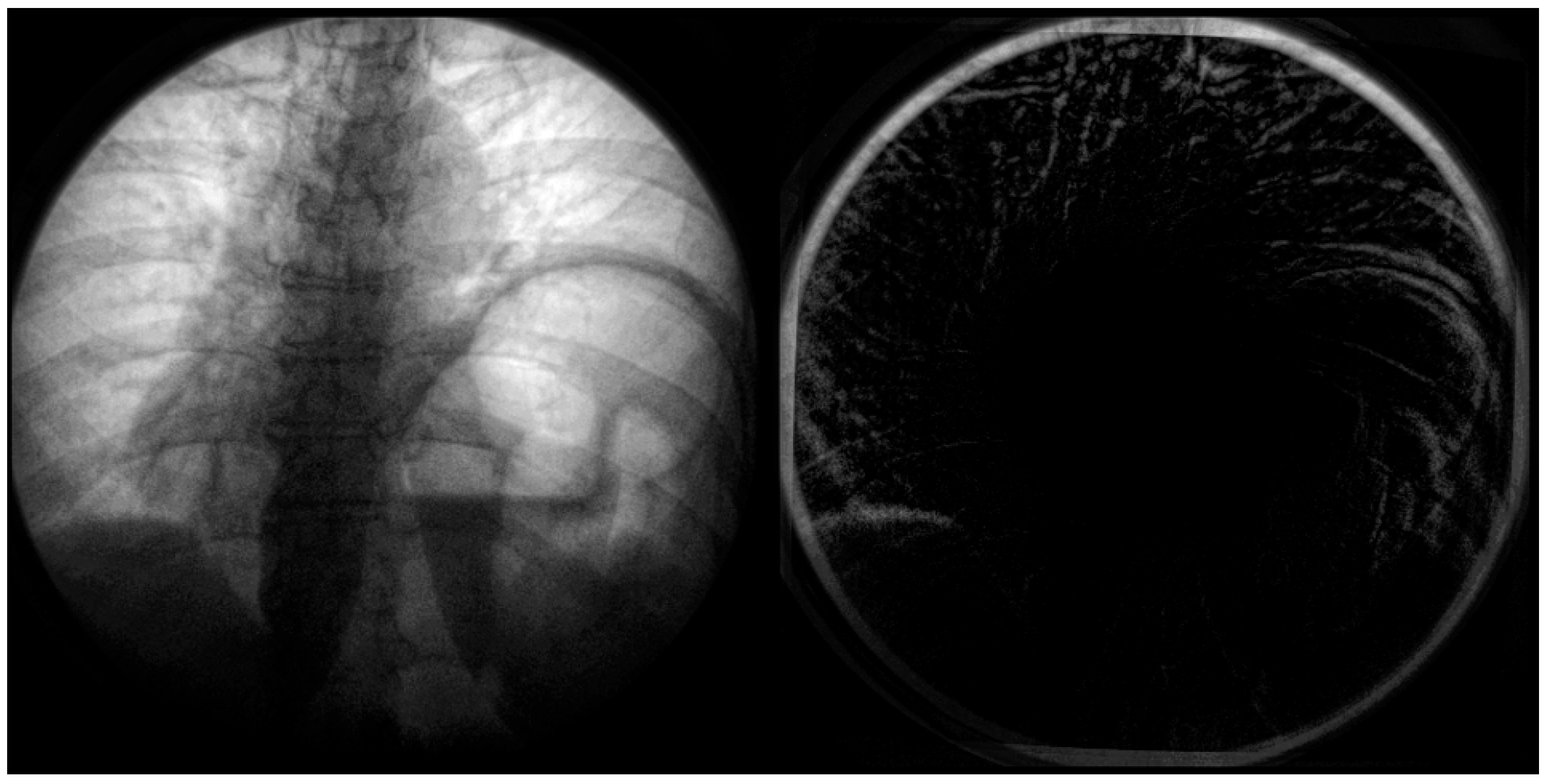
In the below
Figure 6, the distortion is most significant radially from the center. This distortion appears primarily on anatomical features such as the ribcage, sternum, and diaphragm (
Figure 7). This could significantly impact quantitative assessment if these features were used as landmarks. A side-by-side comparison can be used at the point of the diaphragm to visualize the difference between the calibrated and non-calibrated imagery.
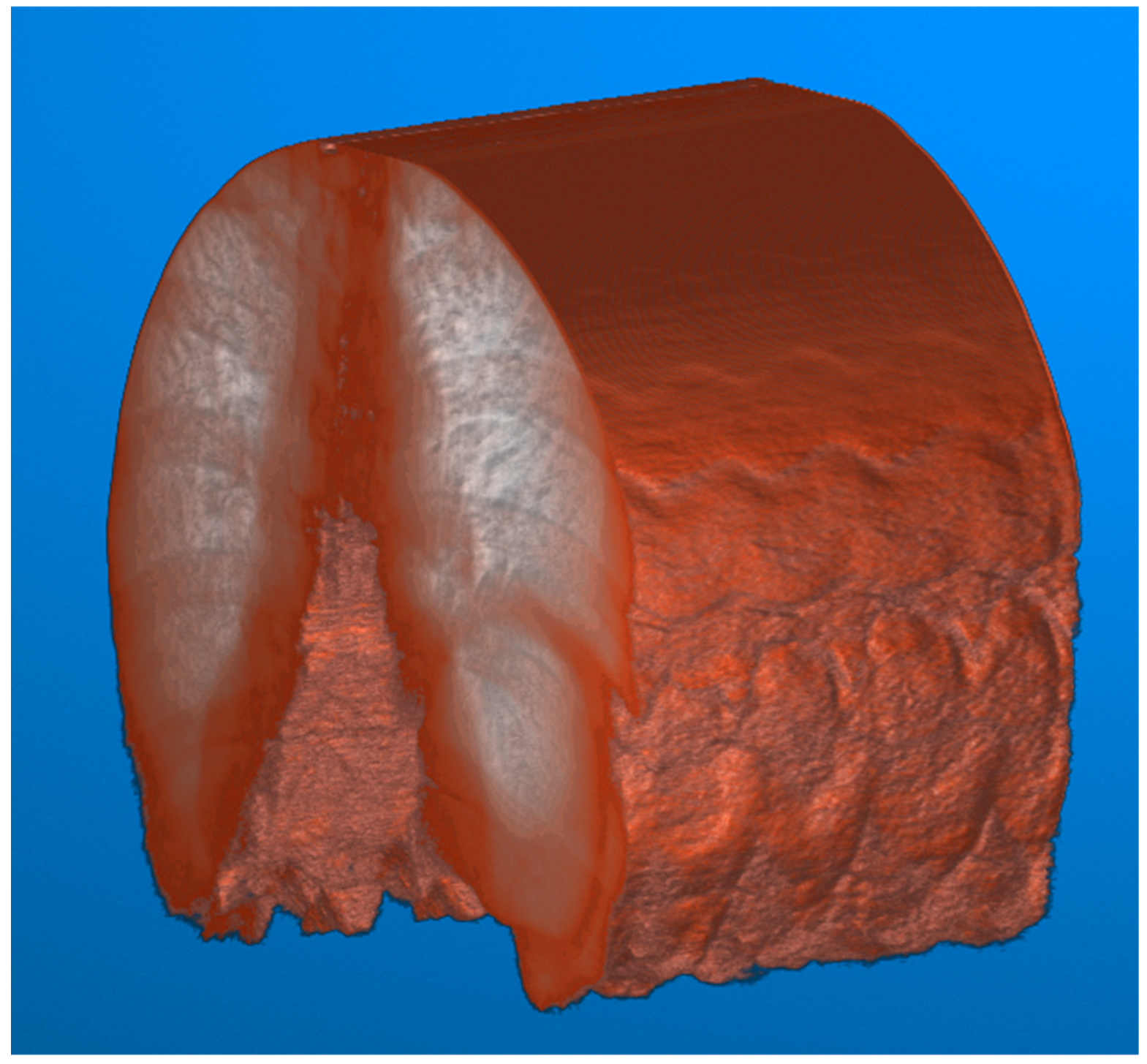
To illustrate the difference between the calibrated and non-calibrated imagery across the range of motion of the diaphragm during normal inspiration, a volumetric approach to image analysis can be taken. The video fluoroscopy imagery can be stacked on the z-axis to form a volume. This volume can subsequently be sliced at a point near the diaphragm along the x-axis to visualize the contraction and relaxation of the muscle.
This visualization (
Figure 8) results in a series of troughs representing the inspiration and contraction of the diaphragm and peaks representing the relaxation of the diaphragm. Each video frame of the video fluoroscopy can subsequently be calibrated to visualize the effect of distortion across the range of motion of the diaphragm.
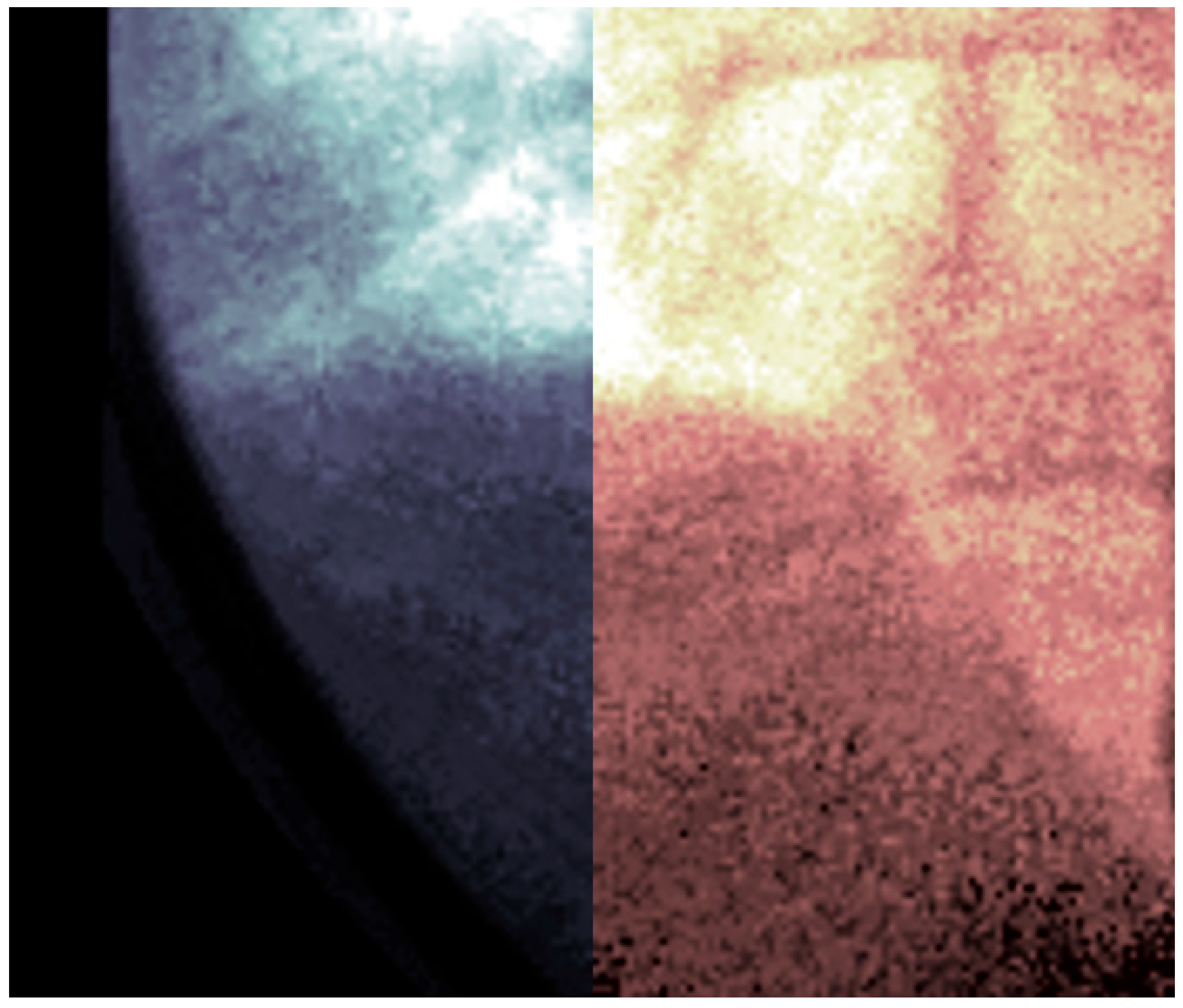
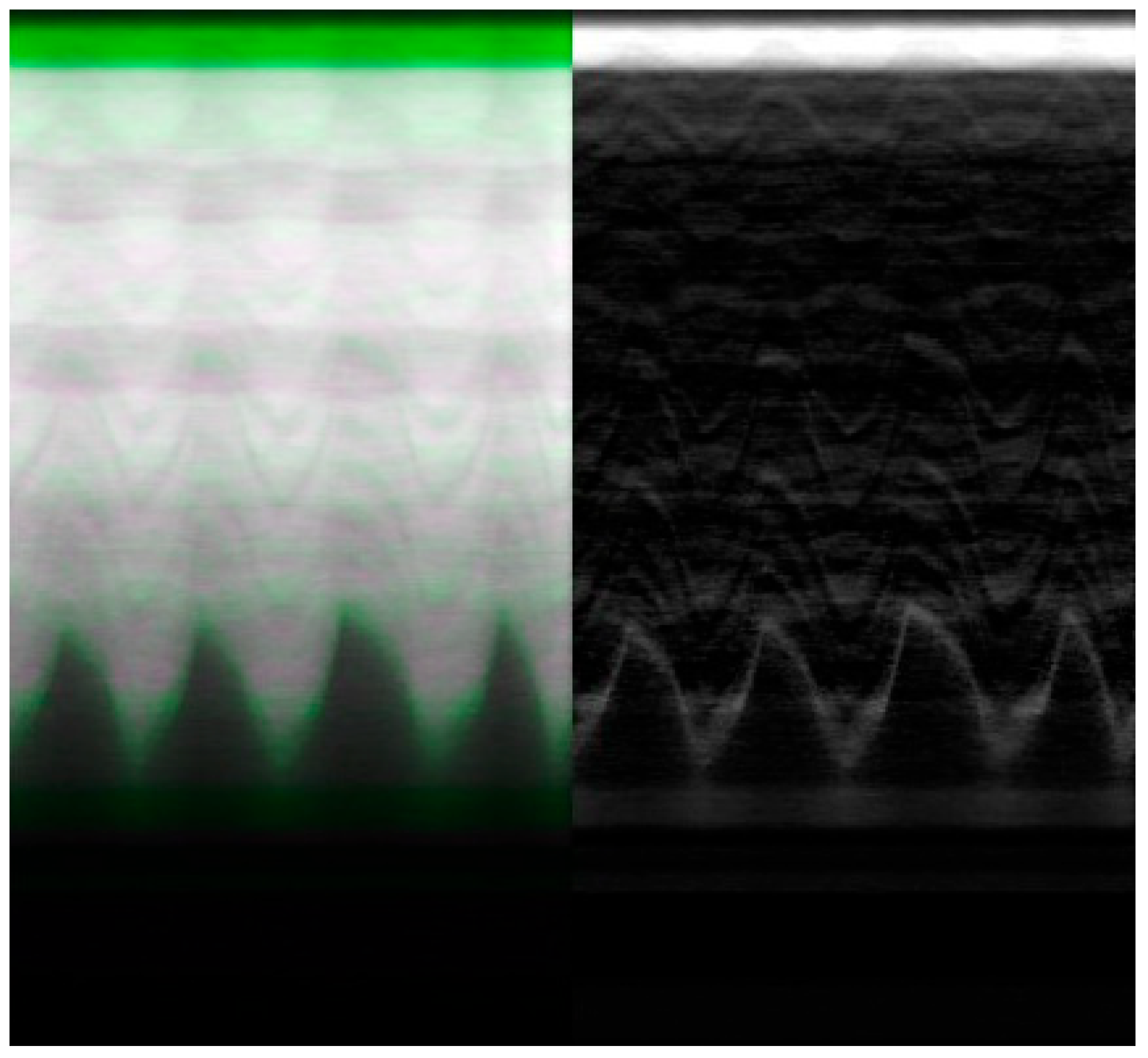
The resulting imagery (
Figure 9) demonstrates a potential expected difference between calibrated and non-calibrated imagery for the analysis of diaphragm motion. The distortion varies based on the movement of the diaphragm, with maximum distortion found at the contraction and relaxation of the diaphragm. The imagery (
Figure 9) showcases the effects of distortion represented as the green overlay (left) and gray (right). This distortion can result in a difference of 10 pixels or more between calibrated and non-calibrated imagery.
5. Discussion
To a radiologist or surgeon, the visual difference in
Figure 4 and
Figure 5 may not be of utmost relevancy for routine diagnostic examination or interventions because our brains can automatically compensate for small distortions during interpretation. However, from a quantitative standpoint, the potential benefits are magnified. In quantitative fluoroscopy applications, such considerable distortion could lead to potential measurement inaccuracies of various anatomical features. This effect is further pronounced in applications where the imaging target spans the full FOV where the increased distortion lays. This is a crucial factor to consider when precise measurement is paramount, for example, in identifying and monitoring disease progression [
9] or in planning and navigating for surgical intervention [
10,
11].
Specifically, in terms of 3D point reconstruction, the data underscore a consistent and marked improvement in object space accuracy. Before calibration, the 3D point accuracy as measured by RMSE across systems was, on average, 7.91 mm. Post-calibration, this error metric witnessed a sharp decline, registering an average of 0.68 mm. This denotes an average enhancement of approximately 91% across the three systems. This corrected distortion can be seen evidently across
Figure 4 and
Figure 5, with increasing distortion seen radially from the center.
The calibration performed has the potential to be incorporated into existing quality assurance programs and workflows when the fluoroscopy system is being used outside of regular clinical diagnostics. The materials required to perform the calibration are low-cost, as the imaging phantom only requires acrylic sheets and embedded radiopaque beads. The time requirement for image capture is minimal, taking a maximum of twenty minutes to carefully capture the required image network per fluoroscopy machine. This time can be further reduced if a device such as a turn-table or other device optimizes the motion of the calibration frame. Following image network capture, the calibration analysis is performed fully through software, allowing for remote analysis by a technician. Once the calibration parameters are determined, the imagery can be corrected in real time if integrated into manufacturers’ existing software architecture.
Calibrating the system appropriately can also potentially enhance the FOV in the captured images. Post-calibration, the decrease in distortion near the edges of the imagery could eliminate the need to limit the FOV to a circular shape. Instead, it becomes potentially feasible to expand the collimation cone mask to nearly the full size of the rectangular detector. This enhancement could be particularly beneficial for patients who face challenges in positioning during image capture, as it allows for greater flexibility and coverage in imaging.
In the realm of robot-assisted endovascular surgery, calibration holds paramount importance, given the intricate interdependence between the precision of robotic tools and fluoroscopy imaging systems [
5,
6,
7,
8]. Any distortion or inaccuracy in fluoroscopy can significantly skew measurements used in and before surgical procedures. The quantitative improvements in both 3D point precision and external orientation ensure that the utilized imagery is not compromised or the limiting factor is in precision, ultimately bolstering confidence in surgical interventions.
This is particularly valuable in endovascular procedures such as transcatheter aortic valve implantation (TAVI) where fluoroscopy is used extensively [
22]. Fluoroscopy plays a critical role in guiding implantation and the confirmation of final valve sizing [
23,
24]. Through image fusion with preoperative imaging, fluoroscopic imaging angles can be determined, reducing the use of repeat contrast media [
25].
The calibration of fluoroscopic Imagery was further demonstrated in its impact on the quantitative diagnosis of hemidiaphragm paralysis and detection of paradoxical diaphragm motion [
19]. Specifically, significant differences between calibrated and non-calibrated imagery can be observed in the position of the diaphragm at peak contraction and relaxation as visualized by the peaks and troughs of the periodic motion of regular breathing (
Figure 9). This difference could potentially skew the significance and confidence in any paradoxical motion.
The study, as described, is limited to the exploration of single-plane fluoroscopic systems. Traditionally in surgical intervention, C-Arm-based systems are preferred. Due to the prevalence of distortion that is tied to its spatial location within the magnetic field, it is to be seen to what degree of movement of the C-Arm within a surgical setting would affect the resulting distortion profile. This future suggests research in exploring the possibility of a transformation profile to correct for differences in the distortion field across the movement. The calibration as described further has the potential to be extended to other radiation-emitting imaging technologies. In particular, portable C-Arm imaging systems and cone-beam CT are strong candidates for the application of this calibration methodology. Furthermore, future investigations into the application of quantitative surgical navigation would be useful.
Several methods have been successfully implemented for the geometric calibration of fluoroscopy imaging systems, including global polynomial estimation [
16] and maximum likelihood estimation [
17]. These methods each have their relative strengths and weaknesses; the self-calibrating bundle adjustment method presented in this study also faces unique challenges. Specifically, our method requires additional setup and effort in capturing the image network to obtain the robust initial estimations of EOPs necessary for the model. Additionally, it necessitates precise image point detection of the calibration frame. However, these challenges can be mitigated with further research and development. There is also substantial value in future studies focusing on the quantitative and qualitative comparison of different geometric calibration procedures and algorithms. Ultimately, there is a need to provide a clearer understanding of different methods’ comparative advantages and limitations.
As computer vision systems become more reliant on artificial intelligence (AI), as it provides the possibility for segment-anything models (SAMs), how the level of geometric distortion affects these algorithms is to be seen. It has been reported that an increase in several noise profiles affects the labeling from convolutional neural networks (CNNs) [
26], and geometric distortion can potentially be thought of as another systematic distortion that varies based on the system’s unique implementation characteristics. This study’s authors propose incorporating geometric distortion into the training of foundational CNN models. This approach, widely recognized as image augmentation [
26], plays a critical role in both comprehensive end-to-end training and in the process of domain transfer learning for CNNs. Specifically, by enriching the training dataset of a foundational model with diverse distortion profiles that mimic a variety of fluoroscopy systems, the model’s robustness and its ability to generalize across different real-world scenarios can potentially be significantly enhanced. This strategy points to a promising research direction, emphasizing the potential benefits of integrating geometric distortion profiles into the process of augmenting training datasets for future image-based models.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}