Prediction of Stroke Outcome Using Natural Language Processing-Based Machine Learning of Radiology Report of Brain MRI

 , , and
, , and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Participants
2.2. Data Collection Using MRI Radiology Reports
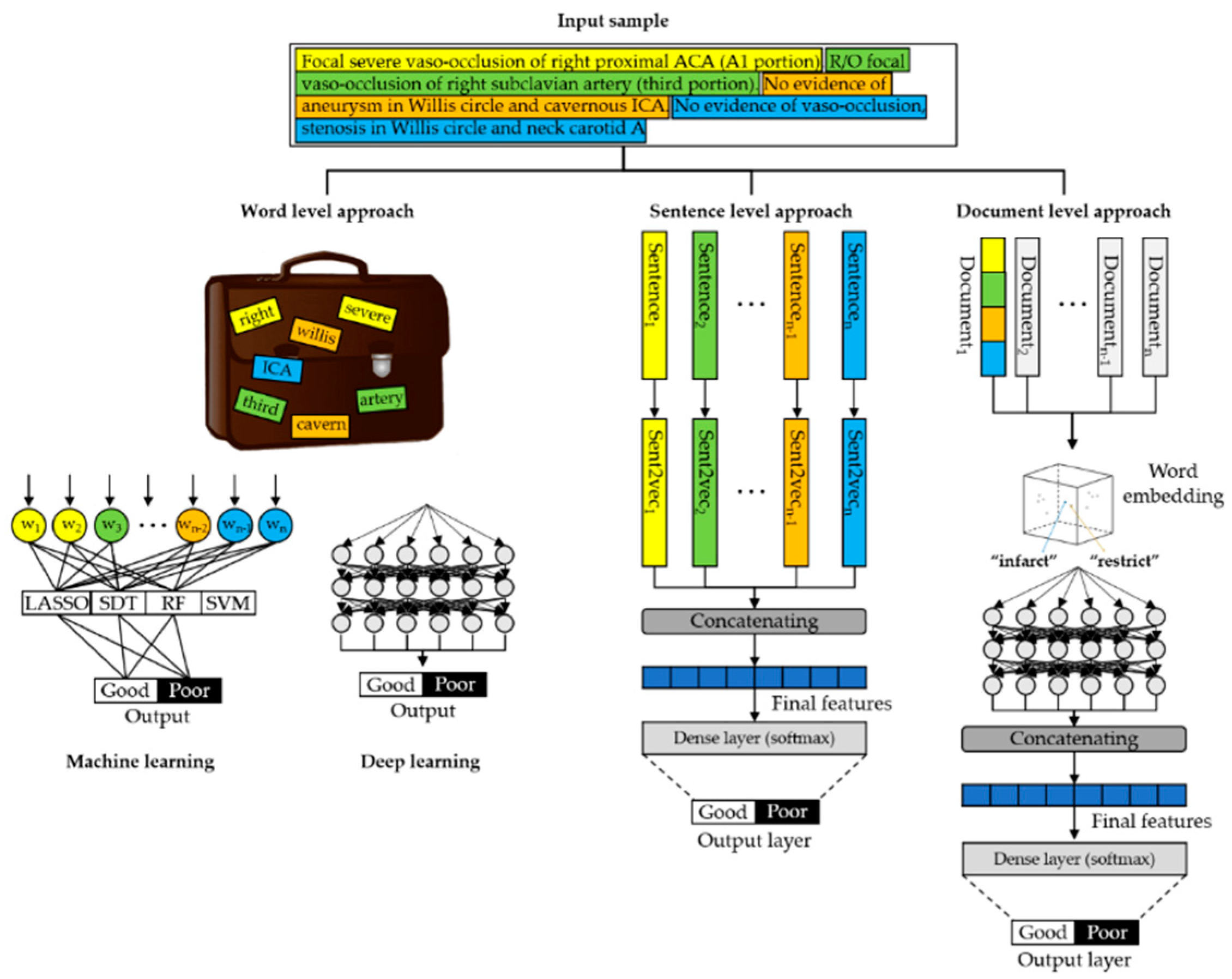
2.3. NLP and ML Algorithms
2.3.1. Word-level Approach
2.3.2. Sentence-Level Approach
2.3.3. Document-Level Approach
2.4. Primary Outcome Measure
2.5. ML Task
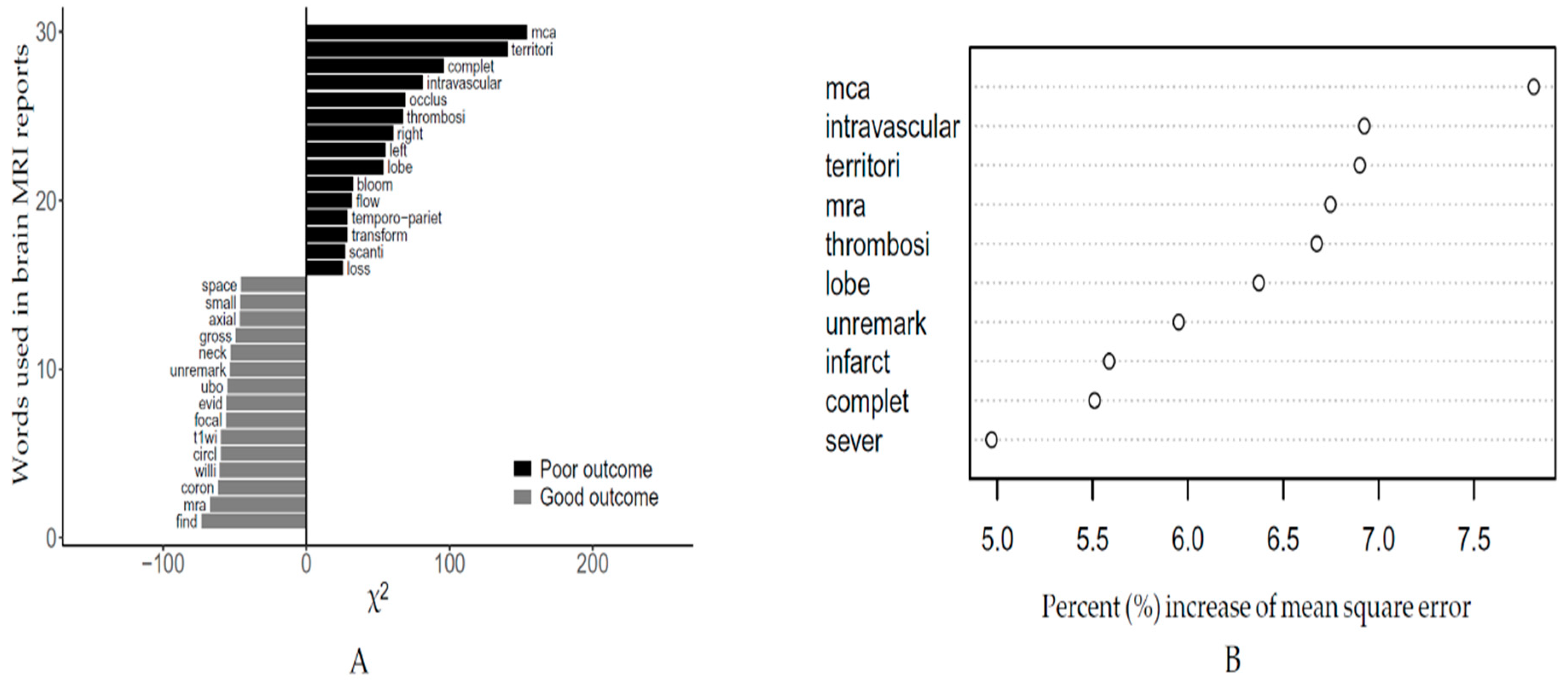
2.6. Statistical Methods
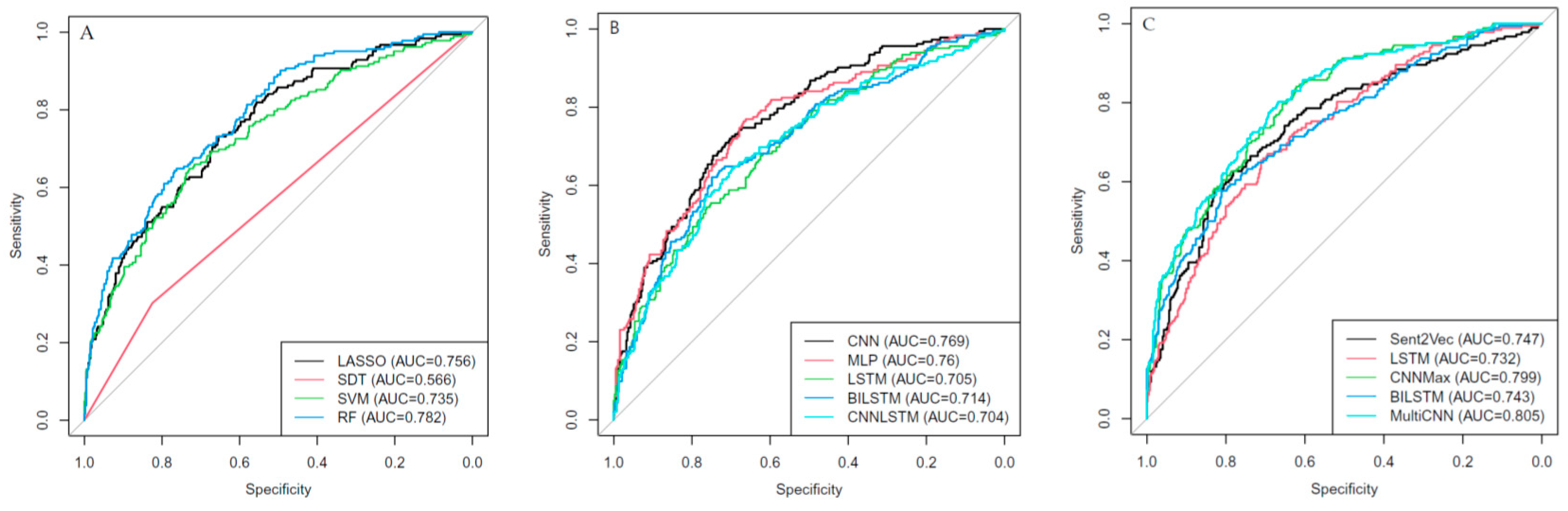
3. Results
Performance of ML Algorithm for Poor Outome Brain MRI Texts
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Krishnamurthi, R.V.; Ikeda, T.; Feigin, V.L. Global, regional and country-specific burden of ischaemic stroke, intracerebral haemorrhage and subarachnoid haemorrhage: A systematic analysis of the global burden of disease study 2017. Neuroepidemiology 2020, 54, 171–179. [Google Scholar] [CrossRef] [PubMed]
- Lin, C.H.; Hsu, K.C.; Johnson, K.R.; Fann, Y.C.; Tsai, C.H.; Sun, Y.; Lien, L.M.; Chang, W.L.; Chen, P.L.; Lin, C.L.; et al. Evaluation of machine learning methods to stroke outcome prediction using a nationwide disease registry. Comput. Meth. Progr. Biomed. 2020, 190, 105381. [Google Scholar] [CrossRef] [PubMed]
- Heo, J.; Yoon, J.G.; Park, H.; Kim, Y.D.; Nam, H.S.; Heo, J.H. Machine learning–based model for prediction of outcomes in acute stroke. Stroke 2019, 50, 1263–1265. [Google Scholar] [CrossRef] [PubMed]
- Yu, Y.; Xie, Y.; Thamm, T.; Gong, E.; Ouyang, J.; Huang, C.; Christensen, S.; Marks, M.P.; Lansberg, M.G.; Albers, G.W.; et al. Use of deep learning to predict final ischemic stroke lesions from initial magnetic resonance imaging. JAMA Netw. Open 2020, 3, e200772. [Google Scholar] [CrossRef] [Green Version]
- Hilbert, A.; Ramos, L.A.; van Os, H.J.; Olabarriaga, S.D.; Tolhuisen, M.L.; Wermer, M.J.; Barros, R.S.; Schaaf, I.D.; Dippel, D.; Roos, Y.B.; et al. Data-efficient deep learning of radiological image data for outcome prediction after endovascular treatment of patients with acute ischemic stroke. Comput. Biol. Med. 2019, 115, 103516. [Google Scholar] [CrossRef]
- Spasic, I.; Nenadic, G. Clinical text data in machine learning: Systematic review. JMIR Med. Inform. 2020, 8, e17984. [Google Scholar] [CrossRef]
- Elkins, J.S.; Friedman, C.; Boden-Albala, B.; Sacco, R.L.; Hripcsak, G. Coding neuroradiology reports for the Northern Manhattan Stroke Study: A comparison of natural language processing and manual review. Comput. Biomed. Res. 2000, 33, 1–10. [Google Scholar] [CrossRef]
- Garg, R.; Oh, E.; Naidech, A.; Kording, K.; Prabhakaran, S. Automating ischemic stroke subtype classification using machine learning and natural language processing. J. Stroke Cerebrovasc. Dis. 2019, 28, 2045–2051. [Google Scholar] [CrossRef]
- Kim, C.; Zhu, V.; Obeid, J.; Lenert, L. Natural language processing and machine learning algorithm to identify brain MRI reports with acute ischemic stroke. PLoS ONE 2019, 14, e0212778. [Google Scholar] [CrossRef]
- Ong, C.J.; Orfanoudaki, A.; Zhang, R.; Caprasse, F.M.; Hutch, M.; Ma, L.; Fard, D.; Balogun, O.; Miller, M.I.; Minnig, M.; et al. Machine learning and natural language processing methods to identify ischemic stroke, acuity and location from radiology reports. PLoS ONE 2020, 15, e0234908. [Google Scholar] [CrossRef]
- Bacchi, S.; Oakden-Rayner, L.; Zerner, T.; Kleinig, T.; Patel, S.; Jannes, J. Deep learning natural language processing successfully predicts the cerebrovascular cause of transient ischemic attack-like presentations. Stroke 2019, 50, 758–760. [Google Scholar] [CrossRef] [PubMed]
- Merino, J.G.; Warach, S. Imaging of acute stroke. Nat. Rev. Neurol. 2010, 6, 560. [Google Scholar] [CrossRef] [PubMed]
- Rivas, R.; Montazeri, N.; Le, N.X.; Hristidis, V. Automatic classification of online doctor reviews: Evaluation of text classifier algorithms. J. Med. Internet Res. 2018, 20, e11141. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Chen, Q.; Yang, Z.; Lin, H.; Lu, Z. BioWordVec, improving biomedical word embeddings with subword information and MeSH. Sci. Data 2019, 6, 1–9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sulter, G.; Steen, C.; De Keyser, J. Use of the Barthel index and modified Rankin scale in acute stroke trials. Stroke 1999, 30, 1538–1541. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Probst, P.; Wright, M.N.; Boulesteix, A.L. Hyperparameters and Tuning Strategies for Random Forest. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery; Wiley: Hoboken, NJ, USA, 2019. [Google Scholar]
- Kaur, S.; Aggarwal, H.; Rani, R. Hyperparameter optimization of deep learning model for prediction of Parkinson’s disease. Mach. Vision Appl. 2020, 31, 1–15. [Google Scholar] [CrossRef]
- Culpeper, J. Keyness: Words, parts-of-speech and semantic categories in the character-talk of Shakespeare’s Romeo and Juliet. Int. J. Corpus. Linguist. 2009, 14, 29–59. [Google Scholar] [CrossRef]
- Lee, K.; Latour, L.; Luby, M.; Hsia, A.; Merino, J.; Warach, S. Distal hyperintense vessels on FLAIR: An MRI marker for collateral circulation in acute stroke? Neurology 2009, 72, 1134–1139. [Google Scholar] [CrossRef]
- Zaidi, S.F.; Aghaebrahim, A.; Urra, X.; Jumaa, M.A.; Jankowitz, B.; Hammer, M.; Nogueira, R.; Horowitz, M.; Reddy, V.; Jovin, T.G. Final infarct volume is a stronger predictor of outcome than recanalization in patients with proximal middle cerebral artery occlusion treated with endovascular therapy. Stroke 2012, 43, 3238–3244. [Google Scholar] [CrossRef] [Green Version]
- Paciaroni, M.; Bandini, F.; Agnelli, G.; Tsivgoulis, G.; Yaghi, S.; Furie, K.L.; Tadi, P.; Becattini, C.; Zedde, M.; Abdul-Rahim, A.H.; et al. Hemorrhagic transformation in patients with acute ischemic stroke and atrial fibrillation: Time to initiation of oral anticoagulant therapy and outcomes. J. Am. Heart Assoc. 2018, 7, e010133. [Google Scholar] [CrossRef] [Green Version]
- Chen, P.H.; Zafar, H.; Galperin-Aizenberg, M.; Cook, T. Integrating natural language processing and machine learning algorithms to categorize oncologic response in radiology reports. J. Digit. Imaging 2018, 31, 178–184. [Google Scholar] [CrossRef]
- Hassanpour, S.; Langlotz, C.P.; Amrhein, T.J.; Befera, N.T.; Lungren, M.P. Performance of a machine learning classifier of knee MRI reports in two large academic radiology practices: A tool to estimate diagnostic yield. AJR Am. J. Roentgenol. 2017, 208, 750–753. [Google Scholar] [CrossRef] [PubMed]
- Senders, J.T.; Karhade, A.V.; Cote, D.J.; Mehrtash, A.; Lamba, N.; DiRisio, A.; Muskens, I.S.; Gormley, W.B.; Smith, T.R.; Broekman, M.L.; et al. Natural language processing for automated quantification of brain metastases reported in free-text radiology reports. JCO Clin. Cancer Inform. 2019, 3, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Huhdanpaa, H.T.; Tan, W.K.; Rundell, S.D.; Suri, P.; Chokshi, F.H.; Comstock, B.A.; Heagerty, P.J.; James, K.T.; Avins, A.L.; Nedeljkovic, S.S.; et al. Using natural language processing of free-text radiology reports to identify type 1 Modic endplate changes. J. Digit. Imaging 2018, 31, 84–90. [Google Scholar] [CrossRef] [PubMed]
- Takase, S.; Suzuki, J.; Nagata, M. Character n-gram embeddings to improve RNN language models. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 5074–5082. [Google Scholar]
- Huang, Y.; Chen, C.H.; Huang, C.J. Motor fault detection and feature extraction using RNN-based variational autoencoder. IEEE Access 2019, 7, 139086–139096. [Google Scholar] [CrossRef]
- Deng, L.; Wang, Y.; Liu, Y.; Wang, F.; Li, S.; Liu, J. A CNN-based vortex identification method. J. Vis. 2019, 22, 65–78. [Google Scholar] [CrossRef]
- Zhang, J.; Li, Y.; Tian, J.; Li, T. LSTM-CNN hybrid model for text classification. In Proceedings of the 2018 IEEE 3rd Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 12–14 October 2018; IEEE: New York, NY, USA, 2018; pp. 1675–1680. [Google Scholar]
- Mirzaei, H. Stroke in women: Risk factors and clinical biomarkers. J. Cell Biochem. 2017, 118, 4191–4202. [Google Scholar] [CrossRef]
- Shin, D.H.; Han, S.K.; Lee, J.H.; Choi, P.C.; Park, S.O.; Lee, Y.H.; Na, J.U. Proximal hyper-intense vessel sign on initial FLAIR MRI in hyper-acute middle cerebral artery ischemic stroke: A retrospective observational study. Acta Radiol. 2020, 0284185120946718. [Google Scholar] [CrossRef]
- Yu, I.; Bang, O.Y.; Chung, J.W.; Kim, Y.C.; Choi, E.H.; Seo, W.K.; Kim, K.M.; Menon, B.K.; Demchuk, A.M.; Goyal, M.; et al. Admission diffusion-weighted imaging lesion volume in patients with large vessel occlusion stroke and Alberta stroke program early CT score of ≥ 6 points: Serial computed tomography-magnetic resonance imaging collateral measurements. Stroke 2019, 50, 3115–3120. [Google Scholar] [CrossRef]
- Wilson, D.; Ambler, G.; Shakeshaft, C.; Brown, M.M.; Charidimou, A.; Salman, R.A.; Lip, G.Y.; Cohen, H.; Banerjee, G.; Houlden, H.; et al. Cerebral microbleeds and intracranial haemorrhage risk in patients anticoagulated for atrial fibrillation after acute ischaemic stroke or transient ischaemic attack (CROMIS-2): A multicentre observational cohort study. Lancet. Neurol. 2018, 17, 539–547. [Google Scholar] [CrossRef]
- Andrade, J.B.; Mohr, J.P.; Lima, F.O.; de Carvalho, J.J.; Barros, L.C.; Nepomuceno, C.R.; Ferror, J.V.; Silva, G.S. The role of hemorrhagic transformation in acute ischemic stroke upon clinical complications and outcomes. J. Stroke Cerebrovasc. Dis. 2020, 29, 104898. [Google Scholar] [CrossRef] [PubMed]
- Nielsen, A.; Hansen, M.B.; Tietze, A.; Mouridsen, K. Prediction of tissue outcome and assessment of treatment effect in acute ischemic stroke using deep learning. Stroke 2018, 49, 1394–1401. [Google Scholar] [CrossRef] [PubMed]
- Varghese, N.R.; Gopan, N.R. Performance analysis of automated detection of diabetic retinopathy using machine learning and deep learning techniques. In Proceedings of the International Conference on Innovative Data Communication Technologies and Application, Coimbatore, India, 17–18 October 2019; Springer: Cham, Switzerland, 2019; Volume 46, pp. 156–164. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Type of ML Algorithm | Level of Approach | ||
|---|---|---|---|
| Word Level | Sentence Level | Document Level | |
| LASSO regression | |||
| SDT | |||
| RF | |||
| SVM | |||
| CNN | |||
| MLP | |||
| LSTM | |||
| Bi-LSTM | |||
| CNN&LSTM | |||
| CNNmax | |||
| Multi-CNN |
| Training (n = 1288) | Test (n = 522) | p Value | |
|---|---|---|---|
| Age, years | 69.3 ± 12.7 | 69.1 ± 12.8 | 0.773 |
| Male, % | 736 (57.1) | 321 (58.2) | 0.726 |
| Height, cm | 165.0 ± 13.1 | 164.4 ± 67.5 | 0.603 |
| Weight, kg | 68.5 ± 12.7 | 67.3 ± 13.5 | 0.698 |
| NIHSS scale, mg/dL | 4.8 ± 5.6 | 4.4 ± 5.3 | 0.226 |
| Risk factors | |||
| Hypertension | 835 (64.8) | 353 (63.9) | 0.758 |
| Diabetes | 420 (32.6) | 198 (35.9) | 0.192 |
| Dyslipidemia | 228 (17.7) | 94 (17.0) | 0.779 |
| Current smoking | 301 (23.4) | 130 (23.6) | 0.981 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Heo, T.S.; Kim, Y.S.; Choi, J.M.; Jeong, Y.S.; Seo, S.Y.; Lee, J.H.; Jeon, J.P.; Kim, C. Prediction of Stroke Outcome Using Natural Language Processing-Based Machine Learning of Radiology Report of Brain MRI. J. Pers. Med. 2020, 10, 286. https://doi.org/10.3390/jpm10040286
Heo TS, Kim YS, Choi JM, Jeong YS, Seo SY, Lee JH, Jeon JP, Kim C. Prediction of Stroke Outcome Using Natural Language Processing-Based Machine Learning of Radiology Report of Brain MRI. Journal of Personalized Medicine. 2020; 10(4):286. https://doi.org/10.3390/jpm10040286
Chicago/Turabian StyleHeo, Tak Sung, Yu Seop Kim, Jeong Myeong Choi, Yeong Seok Jeong, Soo Young Seo, Jun Ho Lee, Jin Pyeong Jeon, and Chulho Kim. 2020. "Prediction of Stroke Outcome Using Natural Language Processing-Based Machine Learning of Radiology Report of Brain MRI" Journal of Personalized Medicine 10, no. 4: 286. https://doi.org/10.3390/jpm10040286
APA StyleHeo, T. S., Kim, Y. S., Choi, J. M., Jeong, Y. S., Seo, S. Y., Lee, J. H., Jeon, J. P., & Kim, C. (2020). Prediction of Stroke Outcome Using Natural Language Processing-Based Machine Learning of Radiology Report of Brain MRI. Journal of Personalized Medicine, 10(4), 286. https://doi.org/10.3390/jpm10040286