
Navigating the Landscape of Personalized Medicine: The Relevance of ChatGPT, BingChat, and Bard AI in Nephrology Literature Searches

 , ,
, ,  , ,
, , 
Abstract
:
1. Introduction
2. Materials and Methods
2.1. Search Strategy and Criteria
2.2. Statistical Analysis
3. Results
3.1. Correlation Analysis
3.1.1. Validity Metrics
3.1.2. Incorrect Information Metrics
3.1.3. Missed and Duplicate Metrics
4. Discussion
5. Limitations
- AI platforms: Our assessment exclusively focused solely on ChatGPT (GPT-3.5 and GPT-4.0), Bing Chat, and Bard AI, excluding other emerging AI platforms that may exhibit distinct citation accuracy profiles.
- Lack of clinical implications: We did not explore the downstream impact of reference inaccuracies on downstream research, clinical decision-making, or patient outcomes, which could provide crucial insights into the practical implications of AI-generated references in the medical domain.
- Limited citation assessment: While the study accounted for discrepancies in citation elements such as DOIs and author names, we did not investigate potential errors in other bibliographic elements, such as the accuracy of the Vancouver format or page ranges. This omission could underestimate the full scope of inaccuracies present in AI-generated references.
- Variability due to updates: The AI models used in this study are subject to updates and modifications. The investigation was conducted with specific versions of AI models, and as these models undergo continuous refinement, their citation accuracy may evolve.
- Scope: The study’s sample size of Nephrology topics and AI-generated references might not fully capture the breadth of medical literature or the complexity of citation accuracy in other medical specialties. The study’s exclusive focus on AI chatbots limits the exploration of potential variations in citation accuracy among different AI-powered tools, such as summarization algorithms or natural language processing applications.
- Validity of databases: The assessment of AI-generated references relied on cross-referencing with established databases, assuming the accuracy of these databases. Any errors or discrepancies present in the reference databases could influence the study’s findings and conclusions.
- Chatbot Extensions and Web Search: As the technological landscape evolves, chatbots are increasingly being equipped with the ability to integrate extensions and external resources, including web search functions. While this feature augments the utility of chatbots, it simultaneously introduces another layer of complexity in terms of citation accuracy and source validation. There is an imperative for future studies to critically evaluate the accuracy and reliability of references generated through these additional features.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Blanco-Gonzalez, A.; Cabezon, A.; Seco-Gonzalez, A.; Conde-Torres, D.; Antelo-Riveiro, P.; Pineiro, A.; Garcia-Fandino, R. The Role of AI in Drug Discovery: Challenges, Opportunities, and Strategies. Pharmaceuticals 2023, 16, 891. [Google Scholar] [CrossRef] [PubMed]
- Salim, H. Living in the digital era: The impact of digital technologies on human health. Malays. Fam. Physician 2022, 17, 1. [Google Scholar] [CrossRef] [PubMed]
- Djulbegovic, B.; Guyatt, G.H. Progress in evidence-based medicine: A quarter century on. Lancet 2017, 390, 415–423. [Google Scholar] [CrossRef]
- Cooper, C.; Booth, A.; Varley-Campbell, J.; Britten, N.; Garside, R. Defining the process to literature searching in systematic reviews: A literature review of guidance and supporting studies. BMC Med. Res. Methodol. 2018, 18, 85. [Google Scholar] [CrossRef]
- National Library of Medicine. PubMed. Available online: https://pubmed.ncbi.nlm.nih.gov/ (accessed on 20 August 2023).
- Kuper, A. Literature and medicine: A problem of assessment. Acad. Med. 2006, 81, S128–S137. [Google Scholar] [CrossRef] [PubMed]
- Temsah, O.; Khan, S.A.; Chaiah, Y.; Senjab, A.; Alhasan, K.; Jamal, A.; Aljamaan, F.; Malki, K.H.; Halwani, R.; Al-Tawfiq, J.A.; et al. Overview of Early ChatGPT’s Presence in Medical Literature: Insights From a Hybrid Literature Review by ChatGPT and Human Experts. Cureus 2023, 15, e37281. [Google Scholar] [CrossRef]
- OpenAI. Introducing ChatGPT. Available online: https://openai.com/blog/chatgpt (accessed on 20 August 2023).
- Edge, M. Bing Chat. Available online: https://www.microsoft.com/en-us/edge/features/bing-chat?form=MT00D8 (accessed on 20 August 2023).
- Google. An Important Next Step on Our AI Journey. Available online: https://blog.google/technology/ai/bard-google-ai-search-updates/ (accessed on 20 August 2023).
- Wagner, M.W.; Ertl-Wagner, B.B. Accuracy of Information and References Using ChatGPT-3 for Retrieval of Clinical Radiological Information. Can. Assoc. Radiol. J. 2023. [Google Scholar] [CrossRef]
- King, M.R. Can Bard, Google’s Experimental Chatbot Based on the LaMDA Large Language Model, Help to Analyze the Gender and Racial Diversity of Authors in Your Cited Scientific References? Cell. Mol. Bioeng. 2023, 16, 175–179. [Google Scholar] [CrossRef]
- Miao, J.; Thongprayoon, C.; Cheungpasitporn, W. Assessing the Accuracy of ChatGPT on Core Questions in Glomerular Disease. Kidney Int. Rep. 2023, 8, 1657–1659. [Google Scholar] [CrossRef]
- Barroga, E.F. Reference accuracy: Authors’, reviewers’, editors’, and publishers’ contributions. J. Korean Med. Sci. 2014, 29, 1587–1589. [Google Scholar] [CrossRef]
- OpenAI. GPT-4 Is OpenAI’s Most Advanced System, Producing Safer and More Useful Responses. Available online: https://openai.com/gpt-4 (accessed on 20 August 2023).
- OpenAI. ChatGPT-3.5. Available online: https://chat.openai.com/ (accessed on 20 August 2023).
- Google. Google Scholar. Available online: https://scholar.google.co.th/ (accessed on 26 August 2023).
- Clarivate. Web of Science. Available online: https://www.webofscience.com/wos/author/search (accessed on 26 August 2023).
- University of Hawai’i at Manoa Library. Available online: https://manoa.hawaii.edu/library/ (accessed on 26 August 2023).
- Yeung, A.W.K.; Kulnik, S.T.; Parvanov, E.D.; Fassl, A.; Eibensteiner, F.; Volkl-Kernstock, S.; Kletecka-Pulker, M.; Crutzen, R.; Gutenberg, J.; Hoppchen, I.; et al. Research on Digital Technology Use in Cardiology: Bibliometric Analysis. J. Med. Internet Res. 2022, 24, e36086. [Google Scholar] [CrossRef]
- Li, J.O.; Liu, H.; Ting, D.S.J.; Jeon, S.; Chan, R.V.P.; Kim, J.E.; Sim, D.A.; Thomas, P.B.M.; Lin, H.; Chen, Y.; et al. Digital technology, tele-medicine and artificial intelligence in ophthalmology: A global perspective. Prog. Retin. Eye Res. 2021, 82, 100900. [Google Scholar] [CrossRef] [PubMed]
- Qarajeh, A.; Tangpanithandee, S.; Thongprayoon, C.; Suppadungsuk, S.; Krisanapan, P.; Aiumtrakul, N.; Garcia Valencia, O.A.; Miao, J.; Qureshi, F.; Cheungpasitporn, W. AI-Powered Renal Diet Support: Performance of ChatGPT, Bard AI, and Bing Chat. Clin. Pract. 2023, 13, 1160–1172. [Google Scholar] [CrossRef]
- Lee, C.; Kim, S.; Kim, J.; Lim, C.; Jung, M. Challenges of diet planning for children using artificial intelligence. Nutr. Res. Pract. 2022, 16, 801–812. [Google Scholar] [CrossRef] [PubMed]
- Dumitru, M.; Berghi, O.N.; Taciuc, I.A.; Vrinceanu, D.; Manole, F.; Costache, A. Could Artificial Intelligence Prevent Intraoperative Anaphylaxis? Reference Review and Proof of Concept. Medicina 2022, 58, 1530. [Google Scholar] [CrossRef]
- Segura-Bedmar, I.; Colon-Ruiz, C.; Tejedor-Alonso, M.A.; Moro-Moro, M. Predicting of anaphylaxis in big data EMR by exploring machine learning approaches. J. Biomed. Inform. 2018, 87, 50–59. [Google Scholar] [CrossRef]
- Levivien, C.; Cavagna, P.; Grah, A.; Buronfosse, A.; Courseau, R.; Bezie, Y.; Corny, J. Assessment of a hybrid decision support system using machine learning with artificial intelligence to safely rule out prescriptions from medication review in daily practice. Int. J. Clin. Pharm. 2022, 44, 459–465. [Google Scholar] [CrossRef]
- Zhang, T.; Leng, J.; Liu, Y. Deep learning for drug-drug interaction extraction from the literature: A review. Brief. Bioinform. 2020, 21, 1609–1627. [Google Scholar] [CrossRef]
- Bhattacharyya, M.; Miller, V.M.; Bhattacharyya, D.; Miller, L.E. High Rates of Fabricated and Inaccurate References in ChatGPT-Generated Medical Content. Cureus 2023, 15, e39238. [Google Scholar] [CrossRef]
- Hill-Yardin, E.L.; Hutchinson, M.R.; Laycock, R.; Spencer, S.J. A Chat(GPT) about the future of scientific publishing. Brain Behav. Immun. 2023, 110, 152–154. [Google Scholar] [CrossRef]
- Garattini, S.; Jakobsen, J.C.; Wetterslev, J.; Bertele, V.; Banzi, R.; Rath, A.; Neugebauer, E.A.; Laville, M.; Masson, Y.; Hivert, V.; et al. Evidence-based clinical practice: Overview of threats to the validity of evidence and how to minimise them. Eur. J. Intern. Med. 2016, 32, 13–21. [Google Scholar] [CrossRef] [PubMed]
- Alkaissi, H.; McFarlane, S.I. Artificial Hallucinations in ChatGPT: Implications in Scientific Writing. Cureus 2023, 15, e35179. [Google Scholar] [CrossRef]
- Garcia Valencia, O.A.; Suppadungsuk, S.; Thongprayoon, C.; Miao, J.; Tangpanithandee, S.; Craici, I.M.; Cheungpasitporn, W. Ethical Implications of Chatbot Utilization in Nephrology. J. Pers. Med. 2023, 13, 1363. [Google Scholar] [CrossRef] [PubMed]
- Garcia Valencia, O.A.; Thongprayoon, C.; Jadlowiec, C.C.; Mao, S.A.; Miao, J.; Cheungpasitporn, W. Enhancing Kidney Transplant Care through the Integration of Chatbot. Healthcare 2023, 11, 2518. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
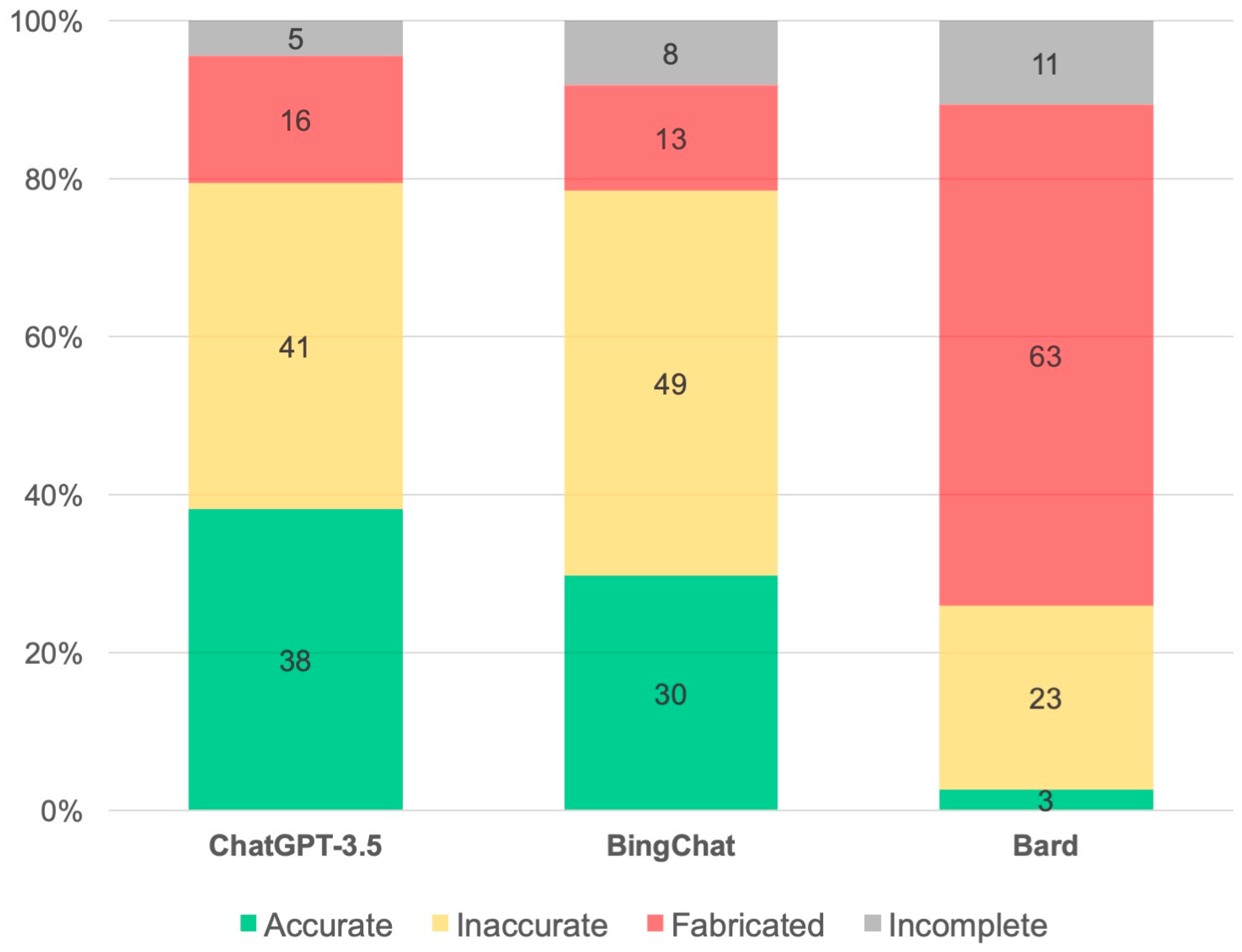
| ChatGPT-3.5 (n = 199) | Bing Chat (n = 158) | Bard (n = 112) | p-Value | |
|---|---|---|---|---|
| Accurate | 76 (38.2%) * | 47 (29.8%) ** | 3 (2.7%) *,** | <0.001 |
| Inaccurate | 82 (41.2%) * | 77 (48.7%) ** | 26 (23.2%) *,** | <0.001 |
| Fabricated | 32 (16.1%) * | 21 (13.3%) ** | 71 (63.4%) *,** | <0.001 |
| Incomplete | 9 (4.5%) | 13 (8.2%) | 12 (10.7%) | 0.11 |
| ChatGPT-3.5 (n = 82) | Bing Chat (n = 77) | Bard (n = 26) | p-Value | |
|---|---|---|---|---|
| Inaccurate DOI | 74 (90.3%) * | 68 (88.3%) ** | 18 (69.2%) *,** | 0.02 |
| Inaccurate title | 4 (4.9%) * | 2 (2.6%) ** | 7 (26.9%) *,** | <0.001 |
| Inaccurate author | 18 (22.0%) * | 13 (16.9%) ** | 19 (73.1%) *,** | <0.001 |
| Inaccurate journal/book | 10 (12.2%) * | 6 (7.8%) ** | 8 (30.8%) *,** | 0.010 |
| Inaccurate year/issue | 14 (17.1%) * | 7 (9.1%) ** | 15 (57.7%) *,** | <0.001 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aiumtrakul, N.; Thongprayoon, C.; Suppadungsuk, S.; Krisanapan, P.; Miao, J.; Qureshi, F.; Cheungpasitporn, W. Navigating the Landscape of Personalized Medicine: The Relevance of ChatGPT, BingChat, and Bard AI in Nephrology Literature Searches. J. Pers. Med. 2023, 13, 1457. https://doi.org/10.3390/jpm13101457
Aiumtrakul N, Thongprayoon C, Suppadungsuk S, Krisanapan P, Miao J, Qureshi F, Cheungpasitporn W. Navigating the Landscape of Personalized Medicine: The Relevance of ChatGPT, BingChat, and Bard AI in Nephrology Literature Searches. Journal of Personalized Medicine. 2023; 13(10):1457. https://doi.org/10.3390/jpm13101457
Chicago/Turabian StyleAiumtrakul, Noppawit, Charat Thongprayoon, Supawadee Suppadungsuk, Pajaree Krisanapan, Jing Miao, Fawad Qureshi, and Wisit Cheungpasitporn. 2023. "Navigating the Landscape of Personalized Medicine: The Relevance of ChatGPT, BingChat, and Bard AI in Nephrology Literature Searches" Journal of Personalized Medicine 13, no. 10: 1457. https://doi.org/10.3390/jpm13101457
APA StyleAiumtrakul, N., Thongprayoon, C., Suppadungsuk, S., Krisanapan, P., Miao, J., Qureshi, F., & Cheungpasitporn, W. (2023). Navigating the Landscape of Personalized Medicine: The Relevance of ChatGPT, BingChat, and Bard AI in Nephrology Literature Searches. Journal of Personalized Medicine, 13(10), 1457. https://doi.org/10.3390/jpm13101457