Hard Negative Samples Contrastive Learning for Remaining Useful-Life Prediction of Bearings


Abstract
:1. Introduction
- Unlike existing supervised RUL prediction methods, this study explores a more practical self-supervised-leaning RUL prediction method that directly learns the sequence relationship from the original vibration data instead of using any HIs as labels for the model supervised training. We propose the HNCPM with the encoder module, GRU regression module and decoder module, respectively used for feature embedding, regression RUL prediction and vibration data reconstruction.
- To encounter this dilemma that the subtle variability between the positive and negative samples in the healthy stage makes the model fail to learn the latent sequence features, we select the negative sample that is most similar to the positive sample as the hard negative sample. Correspondingly, we design a novel loss function combining the MSE with infoNCE loss to improve the fine-grained feature representation of the model.
- The performance of the proposed HNCPM is comprehensively evaluated on the IEEE PHM Challenge 2012 dataset. The comparative experimental results show that the HNCPM is superior for the excellent prediction accuracy than the state-of-the-art methods with respect to different bearings.
2. Related Works
2.1. Deep-Learning-Based Approaches for Rul Prediction
2.2. Contrastive Learning
3. Proposed Method
3.1. Positive Sample and Hard Negative Sample Construction
3.2. Hard Negative Contrastive Prediction Model (Hncpm)
3.3. Optimization Function
| Algorithm 1 Hard Contrastive Prediction Model |
| Input: original bearing samples: . positive samples: , , , . hard negative samples: , , select by (2). F consists of encoder, gated recurrent unit, decoder. is the proposed model parameters. is the test bearing data |
|
| Output: the model prediction |
4. Experimental Section
4.1. Data Description
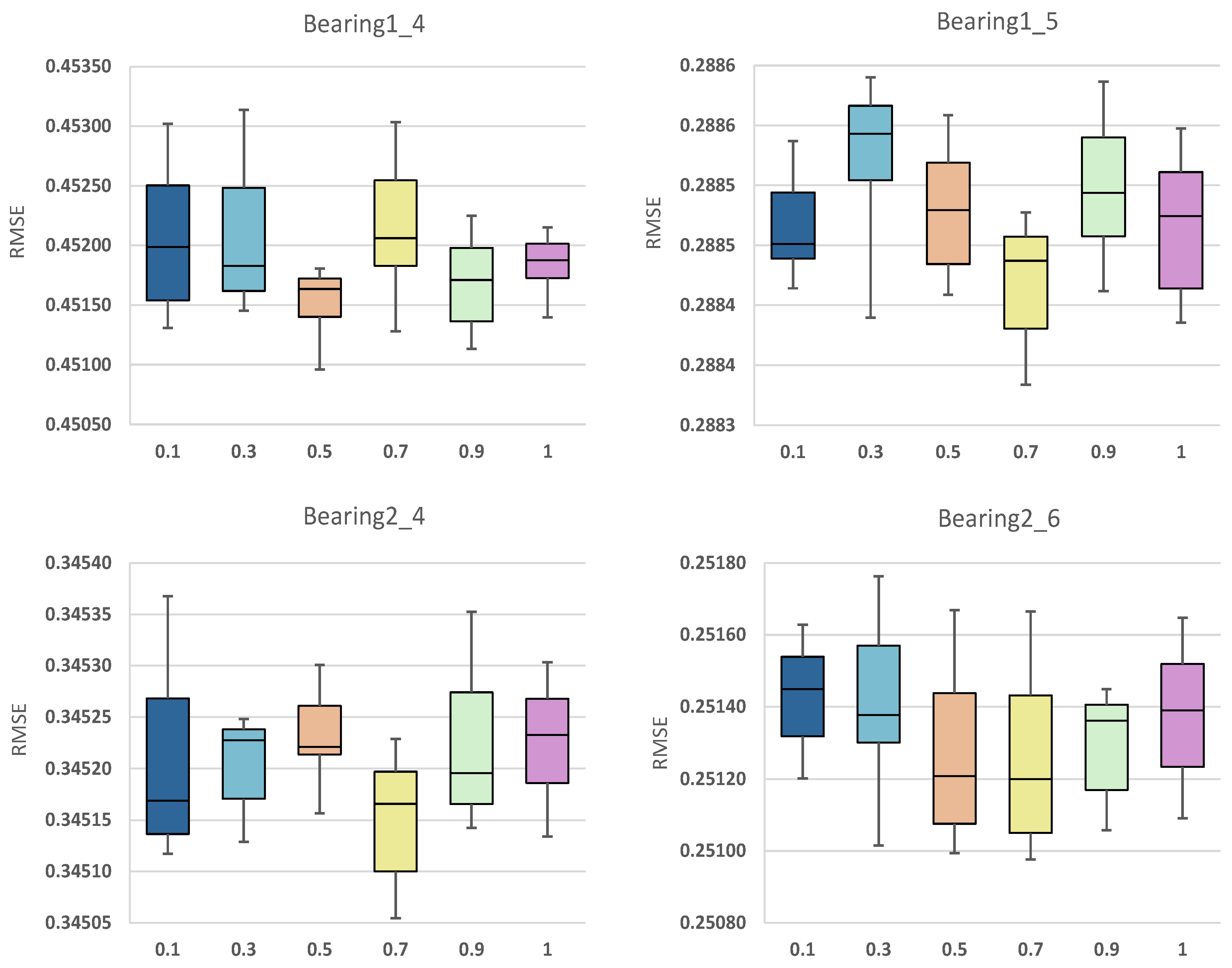
4.2. Weighting Factor Analysis
4.3. Ablation Experiments
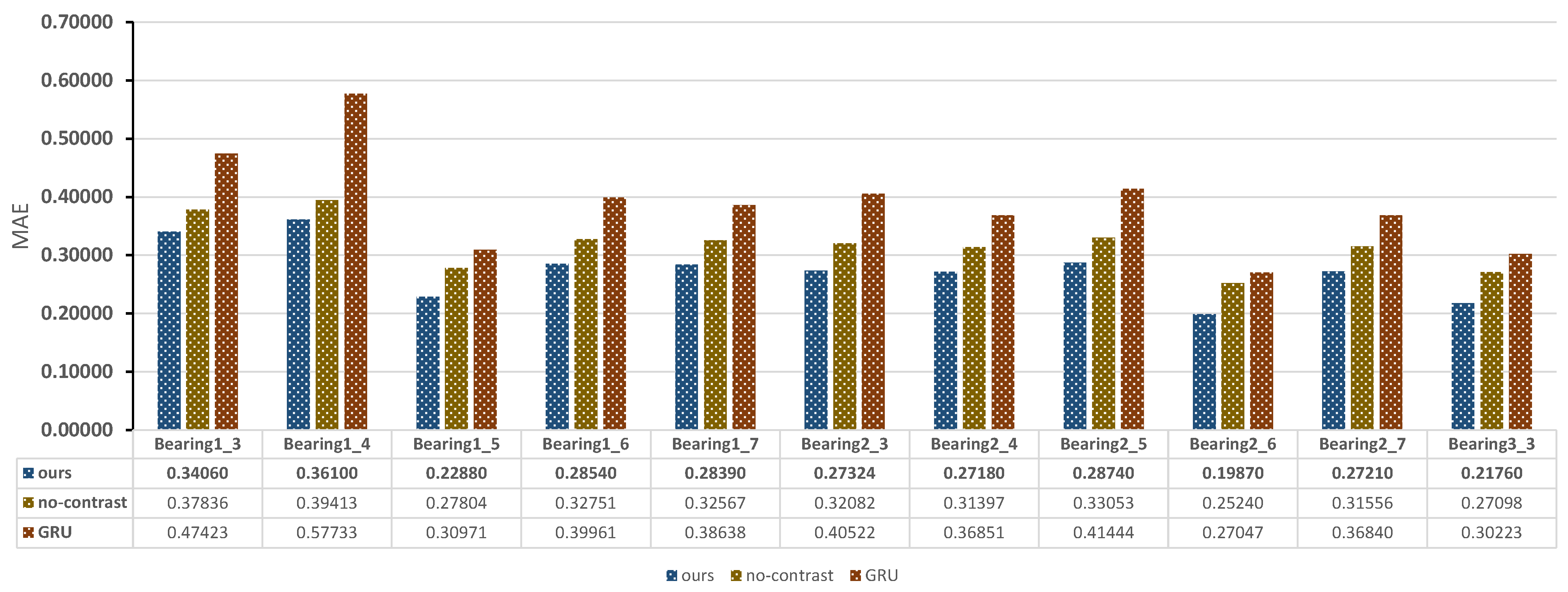
4.4. Comparison with State-of-the Art Methods
4.5. Prediction Results Visualization
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Uckun, S.; Kai, G.; Lucas, P. Standardizing research methods for prognostics. In Proceedings of the International Conference on Prognostics & Health Management, Denver, CO, USA, 25 March 2008. [Google Scholar]
- Zhang, M.; Amaitik, N.; Wang, Z.; Xu, Y.; Maisuradze, A.; Peschl, M.; Tzovaras, D. Predictive Maintenance for Remanufacturing Based on Hybrid-Driven Remaining Useful Life Prediction. Appl. Sci. 2022, 12, 3218. [Google Scholar] [CrossRef]
- Jardine, A.; Lin, D.; Banjevic, D. A review on machinery diagnostics and prognostics implementing condition-based maintenance-ScienceDirect. Mech. Syst. Signal Process. 2006, 20, 1483–1510. [Google Scholar] [CrossRef]
- Heng, A.; Zhang, S.; Tan, A.C.; Mathew, J. Rotating machinery prognostics: State of the art, challenges and opportunities. Mech. Syst. Signal Process. 2009, 23, 724–739. [Google Scholar] [CrossRef]
- Lei, Y.; Li, N.; Guo, L.; Li, N.; Yan, T.; Lin, J. Machinery health prognostics: A systematic review from data acquisition to RUL prediction. Mech. Syst. Signal Process. 2018, 104, 799–834. [Google Scholar] [CrossRef]
- Li, N.; Gebraeel, N.; Lei, Y.; Bian, L.; Si, X. Remaining useful life prediction of machinery under time-varying operating conditions based on a two-factor state-space model. Reliab. Eng. Syst. Saf. 2019, 186, 88–100. [Google Scholar] [CrossRef]
- Prakash, G.; Narasimhan, S.; Pandey, M. A probabilistic approach to remaining useful life prediction of rolling element bearings. Struct. Health Monit. 2019, 18, 466–485. [Google Scholar] [CrossRef]
- Rai, A.; Kim, J.M. A novel health indicator based on the Lyapunov exponent, a probabilistic self-organizing map, and the Gini-Simpson index for calculating the RUL of bearings. Measurement 2020, 164, 108002. [Google Scholar] [CrossRef]
- Jiang, J.R.; Lee, J.E.; Zeng, Y.M. Time Series Multiple Channel Convolutional Neural Network with Attention-Based Long Short-Term Memory for Predicting Bearing Remaining Useful Life. Sensors 2020, 20, 166. [Google Scholar] [CrossRef] [Green Version]
- Cui, L.; Wang, X.; Wang, H.; Ma, J. Research on Remaining Useful Life Prediction of Rolling Element Bearings Based on Time-Varying Kalman Filter. IEEE Trans. Instrum. Meas. 2019, 69, 2858–2867. [Google Scholar] [CrossRef]
- Cheng, C.; Ma, G.; Zhang, Y.; Sun, M.; Teng, F.; Ding, H.; Yuan, Y. A Deep Learning-Based Remaining Useful Life Prediction Approach for Bearings. IEEE/Asme Trans. Mechatron. 2020, 25, 1243–1254. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Peng, G.; Zhu, Z.; Li, S. A novel deep learning method based on attention mechanism for bearing remaining useful life prediction. Appl. Soft Comput. 2019, 86, 105919. [Google Scholar] [CrossRef]
- Shao, S.Y.; Sun, W.J.; Yan, R.Q.; Peng, W.; Gao, R.X. A Deep Learning Approach for Fault Diagnosis of Induction Motors in Manufacturing. Chin. J. Mech. Eng. 2017, 30, 1347–1356. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.M.; Sohaib, M. Reliable Fault Diagnosis of Rotary Machine Bearings Using a Stacked Sparse Autoencoder-Based Deep Neural Network. Shock Vib. 2018, 2018, 2919637.1–2919637.11. [Google Scholar]
- Bienefeld, C.; Kirchner, E.; Vogt, A.; Kacmar, M. On the Importance of Temporal Information for Remaining Useful Life Prediction of Rolling Bearings Using a Random Forest Regressor. Lubricants 2022, 10, 67. [Google Scholar] [CrossRef]
- Xia, M.; Li, T.; Shu, T.; Wan, J.; de Silva, C.W.; Wang, Z. A Two-Stage Approach for the Remaining Useful Life Prediction of Bearings Using Deep Neural Networks. IEEE Trans. Ind. Inform. 2019, 15, 3703–3711. [Google Scholar] [CrossRef]
- Guo, L.; Li, N.; Jia, F.; Lei, Y.; Lin, J. A recurrent neural network based health indicator for remaining useful life prediction of bearings. Neurocomputing 2017, 240, 98–109. [Google Scholar] [CrossRef]
- Rui, Z.; Yan, R.; Chen, Z.; Mao, K.; Gao, R.X. Deep learning and its applications to machine health monitoring. Mech. Syst. Signal Process. 2019, 115, 213–237. [Google Scholar]
- Van den Oord, A.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Graves, A.; Mohamed, A.R.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 6645–6649. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A.; Bottou, L. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Xu, F.; Huang, Z.; Yang, F.; Wang, D.; Tsui, K.L. Constructing a health indicator for roller bearings by using a stacked auto-encoder with an exponential function to eliminate concussion. Appl. Soft Comput. 2020, 89, 106119. [Google Scholar] [CrossRef]
- Wang, B.; Lei, Y.; Li, N.; Yan, T. Deep separable convolutional network for remaining useful life prediction of machinery. Mech. Syst. Signal Process. 2019, 134, 106330. [Google Scholar] [CrossRef]
- Wu, J.; Hu, K.; Cheng, Y.; Zhu, H.; Shao, X.; Wang, Y. Data-driven remaining useful life prediction via multiple sensor signals and deep long short-term memory neural network. Isa Trans. 2020, 97, 241–250. [Google Scholar] [CrossRef]
- Cheng, H.; Kong, X.; Chen, G.; Wang, Q.; Wang, R. Transferable convolutional neural network based remaining useful life prediction of bearing under multiple failure behaviors. Measurement 2021, 168, 108286. [Google Scholar] [CrossRef]
- Luo, J.; Zhang, X. Convolutional neural network based on attention mechanism and Bi-LSTM for bearing remaining life prediction. Appl. Intell. 2022, 52, 1076–1091. [Google Scholar] [CrossRef]
- Ma, M.; Mao, Z. Deep-convolution-based LSTM network for remaining useful life prediction. IEEE Trans. Ind. Inform. 2020, 17, 1658–1667. [Google Scholar] [CrossRef]
- She, D.; Jia, M.; Pecht, M.G. Sparse auto-encoder with regularization method for health indicator construction and remaining useful life prediction of rolling bearing. Meas. Sci. Technol. 2020, 31, 105005. [Google Scholar] [CrossRef]
- Li, X.; Zhang, W.; Ma, H.; Luo, Z.; Li, X. Data alignments in machinery remaining useful life prediction using deep adversarial neural networks. Knowl.-Based Syst. 2020, 197, 105843. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, Y.; Li, L.; Wang, S.; Xiao, Y. An effective health indicator for rolling elements bearing based on data space occupancy. Struct. Health Monit. 2018, 17, 3–14. [Google Scholar] [CrossRef]
- Jing, L.; Tian, Y. Self-supervised visual feature learning with deep neural networks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4037–4058. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2014, arXiv:1312.6114. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 June 2020; pp. 1597–1607. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Jaiswal, A.; Babu, A.R.; Zadeh, M.Z.; Banerjee, D.; Makedon, F. A survey on contrastive self-supervised learning. Technologies 2020, 9, 2. [Google Scholar] [CrossRef]
- Ragab, M.; Chen, Z.; Wu, M.; Foo, C.S.; Kwoh, C.K.; Yan, R.; Li, X. Contrastive adversarial domain adaptation for machine remaining useful life prediction. IEEE Trans. Ind. Inform. 2020, 17, 5239–5249. [Google Scholar] [CrossRef]
- Robinson, J.; Chuang, C.Y.; Sra, S.; Jegelka, S. Contrastive learning with hard negative samples. arXiv 2020, arXiv:2010.04592. [Google Scholar]
- Cheng, Y.; Hu, K.; Wu, J.; Zhu, H.; Shao, X. A convolutional neural network based degradation indicator construction and health prognosis using bidirectional long short-term memory network for rolling bearings. Adv. Eng. Inform. 2021, 48, 101247. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, Z.; Zhang, Y.; Zheng, X.; Xie, J. Degradation-trend-dependent Remaining Useful Life Prediction for Bearing with BiLSTM and Attention Mechanism. In Proceedings of the 2021 IEEE 10th Data Driven Control and Learning Systems Conference (DDCLS), Suzhou, China, 14–16 May 2021; pp. 1177–1182. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Symbol | Operator | Shape | Kernel Size | Stride |
|---|---|---|---|---|---|
| 1 | Input | Input signal | (62,560) | - | - |
| 2 | Conv1d1 | Convolution | (6512) | 4 | 4 |
| 3 | Conv1d2 | Convolution | (6256) | 2 | 2 |
| 4 | Conv1d3 | Convolution | (650) | 1 | 2 |
| 5 | GRU | prediction | 50 | - | 1 |
| 6 | FC1 | Fully-connected | 256 | - | - |
| 7 | FC2 | Fully-connected | 512 | - | - |
| 8 | FC3 | Fully-connected | 2560 | - | - |
| Data Set | Sample Number | Sample Dimension | Rotation Speed | Load | Division |
|---|---|---|---|---|---|
| Bearing 1_2 | 871 | (8,712,560) | 1800 rpm | 4000 N | training |
| Bearing 1_3 | 1802 | (18,022,560) | testing | ||
| Bearing 1_4 | 1139 | (11,392,560) | testing | ||
| Bearing 1_5 | 2302 | (23,022,560) | testing | ||
| Bearing 1_6 | 2302 | (23,022,560) | testing | ||
| Bearing 1_7 | 1502 | (25,022,560) | testing | ||
| Bearing 2_3 | 1202 | (12,022,560) | 1650 rpm | 4200 N | testing |
| Bearing 2_4 | 612 | (6,122,560) | testing | ||
| Bearing 2_5 | 2002 | (20,022,560) | testing | ||
| Bearing 2_6 | 572 | (5,722,560) | testing | ||
| Bearing 2_7 | 172 | (1,722,560) | testing | ||
| Bearing 3_3 | 352 | (3,522,560) | 1500 rpm | 5000 N | testing |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, J.; Qian, L.; Chen, W.; Ding, X. Hard Negative Samples Contrastive Learning for Remaining Useful-Life Prediction of Bearings. Lubricants 2022, 10, 102. https://doi.org/10.3390/lubricants10050102
Xu J, Qian L, Chen W, Ding X. Hard Negative Samples Contrastive Learning for Remaining Useful-Life Prediction of Bearings. Lubricants. 2022; 10(5):102. https://doi.org/10.3390/lubricants10050102
Chicago/Turabian StyleXu, Juan, Lei Qian, Weiwei Chen, and Xu Ding. 2022. "Hard Negative Samples Contrastive Learning for Remaining Useful-Life Prediction of Bearings" Lubricants 10, no. 5: 102. https://doi.org/10.3390/lubricants10050102
APA StyleXu, J., Qian, L., Chen, W., & Ding, X. (2022). Hard Negative Samples Contrastive Learning for Remaining Useful-Life Prediction of Bearings. Lubricants, 10(5), 102. https://doi.org/10.3390/lubricants10050102